137
자료기반 학습 알고리즘을 이용한 지하수위 변동 예측 모델의 국가지하수관측망 자료 적용에 대한 비교 평가 연구
윤희성1·김용철1*·하규철1·김규범2
1한국지질자원연구원 지구환경연구본부, 2K-water연구원 수변지하수연구단
Application of groundwater-level prediction models using data-based learning algorithms to National Groundwater Monitoring Network data
Heesung Yoon1, Yongcheol Kim1,*, Kyoochul Ha1, and Gyoo-Bum Kim2
1Korea Institute of Geoscience and Mineral Resources
2Geowater+ Research Center, K-water Institute
지하수자원의 효율적인 관리를 위해 강우에 대한 지하수위 변화를 예측하는 것은 중요한 문제이다. 본 연구에서는 자료기반 학 습 알고리즘인 인공신경망과 지지벡터기계를 이용하여 시계열 예측 모델을 만들고 이를 국가지하수관측망 중 가산, 신광, 청성 관 측소 지하수위 변화 예측에 적용하였다. 모델의 입력 성분 구성 방법에 따라 네 가지 모형을 설정하고 각 관측소 및 모델 별 예 측 결과를 비교 평가하였다. 강우 입력 모형의 경우 지하수위 감쇠 및 기저 변화 예측을 위해 큰 규모의 입력 성분 구성이 필요 하지만 강우 및 지하수위 입력 모형은 보다 작은 규모의 입력 성분으로 효과적으로 지하수위 변화를 예측하는 것으로 나타났다.
강우 및 지하수위 입력 모형의 활용성 증대를 위해 고안된 반복 예측 모형의 경우 관측값과 예측값 사이에 0.75~0.95의 상관계 수를 보여 적용 가능성이 큰 것으로 판단된다. 전체적으로 강우-지하수위 교차상관계수가 낮은 신광 관측소의 예측 오차가 크게 나타났고 ANN 모델에 비해 SVM의 예측력이 다소 높은 것으로 조사되었다. 또한 반복 예측 모형의 모델 파라미터 선정 과정에 서 보정 단계 오차에 대한 예측 단계 오차의 비의 분포를 조사한 결과 SVM의 경우가 더 작게 나타나 SVM이 본 연구 자료에 대해 보다 안정적이고 효율적인 모델임을 평가하였다.
주요어 : 인공신경망, 지지벡터기계, 강우, 지하수위, 국가지하수관측망
For the effective management of groundwater resources, it is necessary to predict groundwater level fluctuations in response to rainfall events. In the present study, time series models using artificial neural networks (ANNs) and support vec- tor machines (SVMs) have been developed and applied to groundwater level data from the Gasan, Shingwang, and Cheon- gseong stations of the National Groundwater Monitoring Network. We designed four types of model according to input structure and compared their performances. The results show that the rainfall input model is not effective, especially for the prediction of groundwater recession behavior; however, the rainfall-groundwater input model is effective for the entire pre- diction stage, yielding a high model accuracy. Recursive prediction models were also effective, yielding correlation coeffi- cients of 0.75-0.95 with observed values. The prediction errors were highest for Shingwang station, where the cross- correlation coefficient is lowest among the stations. Overall, the model performance of SVM models was slightly higher than that of ANN models for all cases. Assessment of the model parameter uncertainty of the recursive prediction models, using the ratio of errors in the validation stage to that in the calibration stage, showed that the range of the ratio is much narrower for the SVM models than for the ANN models, which implies that the SVM models are more stable and effective for the present case studies.
Key words : artificial neural network, support vector machine, rainfall, groundwater level, National Groundwater Moni- toring Network
*Corresponding author: [email protected]
ⓒ 2013, The Korean Society of Engineering Geology
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons. org/
licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is prop- erly cited.
서 론
최근 지하수 이용량이 꾸준히 증가하고 기후변화가 수자원에 미치는 영향에 대한 관심이 고조되면서 지하 수자원의 지속가능하고 안정적인 활용을 위한 체계적인 관리의 중요성이 대두되고 있다. 지하수자원의 효율적인 관리를 위해 지하수위 변화를 정확히 예측하는 것이 중 요하며 이에 대한 다양한 각도의 연구가 진행되어 왔다.
대표적인 접근 방법인 물리 모델링 기법은 대상 영역에 대한 물리적인 개념을 바탕으로 수학적인 지배방정식을 세우고 이를 해석적 혹은 수치적 풀이를 통해 지하수위 변화를 예측 한다(Rai and Singh, 1995; Knotters and Bierkens, 2000; Srivastava et al., 2002; Park and Parker, 2008). 또 다른 접근 방법으로 자료기반 시계열 예측 모델링 기법을 들 수 있다. 이는 대상 지역의 입·
출력 관측 자료를 이용하여 자료간의 반응함수를 설정 하는 방법으로 수자원과 관련된 관측 자료의 양과 질이 증가 및 향상되면서 그 활용도가 높아지고 있다 (Coppola et al., 2005). 전통적으로 입·출력 시계열 간 의 선형적 상관성과 통계적 이론을 바탕으로 한 전이 함수 모델 개발 및 적용 연구가 진행되어 왔다(Box and Jenkins, 1976; Tankersley et al., 1993; van Geer and Zuur, 1997; Yi and Lee, 2004). 최근에는 입·출 력 자료 간의 비선형성 문제를 해결하기 위해 자료기반 학습 모델들의 수자원 분야에 대한 적용 연구가 활발하 게 이루어지고 있다.
인공신경망(artificial neural network: ANN)은 수많은 시냅스의 결합 및 반응 전달을 통해 복잡한 문제들을 병렬처리를 통해 효과적으로 해결해내는 인간의 뇌 구 조를 모방하여 고안된 연산 체계로 패턴인식, 음성인식, 적응제어 및 예측 등 다양한 분야 적용되어 그 효율성 인 인정받고 있다. 수자원 분야에서는 1990년대 후반 이후 하천수위 예측(Zealand et al., 1999; Hsu et al., 2002; Jain and Kumar, 2007), 수질 오염(Suen and Eheart, 2003; Sahoo et al., 2006) 등 주로 지표수 중 심의 연구로 시작하여 지하수위 및 수질 예측 분야 (Coppola et al., 2005; Almasri and Kaluarachchi, 2005; Nayak et al., 2006)에 대한 적용연구로 확대되고 있다. 러시아 과학자 Vapnik (1995)에 의해 개발된 지 지벡터기계(support vector machine: SVM)는 구조적 오류 최소화(structural risk minimization) 원리에 기반 한 방법으로 경험적 오류 최소화(empirical risk minimization) 원리를 바탕으로 ANN 등의 학습 모델들
에 비해 높은 일반화 성능을 보여준다(Vapnik, 1995;
Scholkopf and Smola, 2002). 일반적인 자료 기반 학습 모델들의 주 관심 적용 분야인 자료의 분류 측면에서 살펴보면 ANN은 학습 자료에 대해 발생하는 분류 오 차를 이용하여 이를 최소화 하도록 분류면을 보정해나 가는 반면 SVM은 분류될 자료 집단 사이에서 같은 크 기만큼 떨어진 위치에 분류면을 설정한다. 이러한 특성 은 자료 집단 사이에 존재하는 여백(margin)을 최대화 시키게 되어 모델의 일반화 능력을 향상시킨다. 최근 이 러한 특징을 가지는 SVM 모델의 수문학 분야에 대한 적용성 검토에 대한 연구 또한 진행되고 있다(Asefa et al., 2006; Khan and Coulibaly, 2006; Yoon et al., 2011).
이와 관련하여 본 연구에서는 ANN 및 SVM을 이용 한 시계열 예측 모델을 구성하고 이를 국가지하수관측 망 중 경북칠곡가산, 전남함평신광, 충북옥천청성 관측 소의 강우에 대한 지하수위 변화 예측에 적용하였다. 입 력 자료의 구성 방법에 따라 네 가지 경우의 모형을 설 정하여 각 관측소 및 모델별 예측 결과를 비교하고 적 용성을 평가하였다.
연구방법 및 자료 인공신경망 모델
ANN은 수많은 시냅스의 결합 및 반응 전달을 통해 복잡한 문제들을 병렬처리를 통해 효과적으로 해결해내 는 인간의 뇌 구조를 모방하여 고안되었다. 일반적으로 ANN의 구조는 입력층, 은닉층, 출력층으로 나뉘어 있고 각 층은 다중 노드들로 구성되어 있으며 층간 노드들은 일정한 연결강도로 연결되어 있다(Fig. 1(a)). 입력의 각 노드에 입력 자료가 들어왔을 때 은닉층을 거쳐 출력값 이 연산되는 과정은 다음의 식과 같이 표현된다.
(1)
xi는 이전 층의 i번째 노드값, yj는 현재 층의 j번째 노드 값, bj는 현재 층의 j번째 노드의 편중값, wji는 xi와 yi
의 연결강도, m은 이전 층의 노드 개수를 의미한다.
f는 은닉층 및 출력층의 전이함수로 본 연구에서는 일 반적으로 가장 빈번히 사용되는 조합인 은닉층의 전이 함수로 로그-시그모이드(log-sigmoid) 함수와 출력층의 전이함수로 선형 함수를 이용하였다. 본 연구에서 사용 된 은닉층 전이함수와 출력층의 선형함수는 각각 식 (2)
yi f wji xi
i=1
∑
m +bj⎝ ⎠
⎛ ⎞
=
와 식 (3)으로 표현된다.
(2)
(3) ANN 모델 구성을 위해서는 주어진 입·출력 자료를 이용하여 연결강도 및 중값을 최적화하는 학습과정이 필 요하다. 본 연구에서는 ANN의 학습 방법으로 역전파 알고리즘(back propagation algorithm)을 이용하였다 (Rumelhart et al., 1986). 역전파 알고리즘은 ANN을 통해 연산과정에서 발생하는 오차를 이용하여 출력층에 서 입력층 방향으로 연결강도 및 편중값을 연속적으로 수정하게 된다. 역전파 알고리즘을 이용한 ANN의 학습 과정은 다음과 같이 표현된다.
(4)
(5)
(6)
Ek는 k번째 연산과정에서 발생하는 오차, ti는 관측값, LR은 학습속도, MM은 학습과정에서 ANN이 지역해를 탐색하게 되는 것을 보완하기 위해 제안된 모멘텀이다 (Rumelhart et al., 1986).
ANN 모델을 구성하는데 결정되어야 할 모델 파라미 터는 은닉층 노드 개수(HN), LR 및 MM의 세 가지이 다. 본 연구에서는 모델 학습을 위해 필요한 자료를 모 델 훈련과 보정의 두 단계로 나누어 할당하였다. ANN 의 연결강도 및 가중값의 최적화는 훈련 단계 자료를 이용하여 수행하였고 모델 파라미터들은 보정 단계 자 료의 오차를 최소화는 것으로 결정하였다. 모델 파라미 터 탐색은 시행착오법을 이용하였으며 각 파라미터 군 에 대해 100개의 임의 초기 연결강도 군을 생성하고 가 장 오차가 작은 경우를 선택하였다.
지지벡터기계 모델
SVM은 구조는 ANN과 유사하지만 그 원리 및 연산 과정은 상이하다. 자료 입력의 경우 ANN은 입력 자료 의 각 성분들이 입력층의 노드에 할당되는데 비해 SVM은 모델 훈련에 이용될 입력 벡터들 중 모델 구조 를 ‘지지’ 하기에 적합한 벡터들과 그 연결강도 및 편중 값이 학습을 통해 결정되고 임의의 입력 벡터가 주어질 때 선정된 지지벡터들과의 연산을 통해 출력값을 예측 한다(Fig. 1(b)). 지지벡터들과 임의의 입력 벡터와의 관 계는 커널함수로 정의되는 비선형 전이 함수에 의해 연 산되는데 본 연구에서는 가우시안(Gaussian)형태의 커널 함수를 이용하였다.
(7) f x( ) 1
1 e+ –x ---
=
f x( ) x=
Ek (tik–yik)2
∑
i=
wk+1–wk MM w( k–wk–1) 1 MM( – )LR ∂Ek
∂wk ---
⎝– ⎠
⎛ ⎞ +
=
bk+1–bk MM b( k–bk–1) 1 MM( – )LR ∂Ek
∂bk ---
⎝– ⎠
⎛ ⎞ +
=
K x( s,x) xs–x2 2σ2 ---
⎝– ⎠
⎛ ⎞
exp
= Fig. 1. Schematic diagram of the model structure for (a) ANN and (b) SVM.
xs는 지지벡터, x는 임의의 입력 벡터, σ는 가우시안 함 수 파라미터이다.
SVM 예측 함수와 모델 학습을 위한 목적함수는 다 음과 같이 표현된다(Vapnik, 1995).
(8)
maximize (9)
subject to
w는 연결강도 벡터, b는 편중값, φ는 비선형 전이함수 를 나타낸다. C는 최적화 과정에서 경험오차를 고려할 정도를 제공하는 길항 파라미터, ξ는 모델 훈련 과정에 서 발생하는 오차, ε은 오차 허용율을 의미한다.
본 연구에서는 SVM 학습 방법으로 Platt (1999)에
의해 제안된 순차적 최소규모 최적화 알고리즘 (sequential minimal optimization algorithm: SMO)을 이용하였다. SMO는 먼저 SVM의 조건부 최적화 문제 를 라그랑지 승수(Lagrangian multiplier)와 KKT 조건 (Karush-Kuhn-Tucker condition)을 이용하여 다음 식과 같이 변환한다.
maximize (10)
subject to
α는 라그랑지 승수이다. SMO는 로 치환하 고 두 개의 β를 임의 선정하여 식 (10)을 β 구간에 대 f x( ) wφ x= ( ) b+
1
2--- w2 C (ξi+ξi*)
i=1
∑
N+
yi–wTφ x( ) bi – ≤ε ξ+ i
wTφ x( ) b yi + – i≤ε ξ+ i
ξi,ξi*≥0
⎩⎪
⎪⎨
⎪⎪
⎧
1
2--- (αi–αi*)
i j,=1
∑
N (αj–αj*)K x( i,xj)–
ε (αi–αi*)
i=1
∑
N yi(αi–αi*) i=1∑
N+
⎩–
⎪⎪
⎨⎪
⎪⎧
αi–αi*
( )
i=1
∑
N =00 α≤ i,αi*≤C
⎩⎪
⎨⎪
⎧
βi=αi–αi*
Fig. 2. Locations of stations and time series of rainfall and groundwater level data. (a) Location map, (b) Gasan station (GS), (c) Shingwang station (SG), and (d) Chengseong station (CS).
한 2차 함수 최대값 산정 문제로 변환한 뒤 그 해석해 를 반복적으로 풀이한다(Platt, 1995; Scholkopf and Smola, 2002).
SVM 구성을 위해 결정해야 할 모델 파라미터는 C, ε, σ의 세 가지이고 ANN과 마찬가지로 보정 단계에서 시행착오법으로 선정하였다. 위와 같은 ANN 및 SVM 모델은 C 언어로 프로그래밍 한 뒤 국가지하수관측망 지하수위 자료에 적용하였다.
연구자료
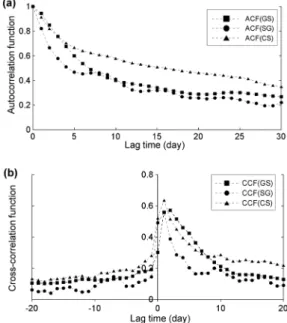
본 연구에서는 ANN 및 SVM 모델의 적용성 평가를 위해 국가지하수관측망 중 자료의 연속성과 강우와의 상 관성을 고려하여 경북칠곡가산(GS), 전남함평신광(SG), 충북옥천청성(CS) 관측소의 2003년부터 2008년까지 지 하수위 일변화 자료와 왜관, 신광, 묘금 강우 관측소의 일 강우 자료를 이용하였다. Fig. 2는 대상 관측소의 위 치와 관련 시계열 자료를 보여준다. 이 중 2003년 자료 를 모델 훈련 단계로 2004년부터 2005년 자료를 모델 보정 단계로 설정하고 결정된 모델을 이용하여 2006년 부터 2008년까지의 지하수위 변화를 예측하였다. 각 관 측소 자료에 대한 시계열 분석 결과 지하수위의 자기상 관함수는 완만하게 감소하는 형태를 보여주고 있어 시 계열 모형 설정 시 자기회귀성분의 필요성을 제시해주 고 있다(Fig. 3(a)). 강우에 대한 지하수위 시계열 자료 의 교차상관분석 결과 가산관측소에서는 2일, 신광 및 청성 관측소에서는 1일의 지연시간에서 각각 0.57, 0.56, 0.64의 최대 상관 계수를 보여주고 있어 강우에 의한 지 하수위 반응이 비교적 빠른 것으로 관찰되었다(Fig.
3(b)).
시계열 모델의 설정에 있어 입력 시계열의 구성 방법 에 대해 시행착오법, 통계적 접근 방법, 최적화 기법 연 계 등 다양한 접근방법이 있지만 본 연구의 목적은 국 가지하수관측망 지하수위 자료 예측에 대한 ANN과 SVM 모델의 적용성을 평가하는 것이므로 다음과 같이 네 가지 입력 구조를 가지는 모형들을 설정하고 각 경 우에 대한 두 모델의 적합성을 비교하였다.
(1) 강우 입력 모형 (과거 3일까지의 강우 정보 이용) (2) 강우 입력 모형 (과거 15일까지의 강우 정보 이용) (3) 강우 및 지하수위 입력 모형 (과거 3일까지의 강
우 및 지하수위 정보 이용)
(4) 반복 예측 모형 ((3)의 모형을 이용한 지하수위 반복 예측)
연구결과 및 토의 모형 예측력 평가를 위한 오차 지표
본 연구에서는 각 모형에 대한 적합성 및 예측 능력의 비교 평가를 위해 평균 제곱 오차 제곱근(RMSE), 상관 계수(CORR), 절대 백분율 오차 평균(MAPE)의 세 가지 오차 지표를 이용하였다. RMSE는 각 오차를 제곱값을 이용함으로써 큰 오차에 대한 가중값을 주어 모형의 정 밀도를 측정하는 지표이고 CORR은 모형의 선형적인 일 치성 및 방향성을 측정하는 지표이다. MAPE는 각 오차 의 측정값에 대한 백분율을 구함으로써 관측 범위가 다 른 자료에 대한 모형의 정확도를 비교할 수 있는 지표이 다. 각 오차 지표의 수학적 표현은 다음의 식과 같다.
RMSE = (11)
CORR = (12)
MAPE = (13)
1
n--- (ti–oi)2
i=1
∑
n1
n--- (ti–ti) o( i–oi)
i=1
∑
n1
n--- t(i–ti)2 1 n--- o( i–oi)2 ---
1
n--- ti–oi ti ---
i=1
∑
n⎝ ⎠
⎛ ⎞ 100×
Fig. 3. Time series analyses for the data from three stations, showing (a) autocorrelation functions and (b) cross-correlation functions.
여기서 n은 자료의 수, t는 관측값, o는 예측값, 와 는 각각 관측값과 예측값의 평균값을 의미한다.
강우 입력 모형 예측 결과
강우 입력 모형은 강우 과거 자료의 이용 규모에 따 라 두 가지의 모형을 구성하였고 각 모형의 수학적 표 현은 다음과 같다.
(14)
(15) 여기서 y는 지하수위 예측값, yP3와 yP15는 각각 과거 3 일과 15일까지의 강우자료를 이용하는 모형에 대한 지 하수위 예측값, F는 각 경우에 대한 ANN 혹은 SVM 모델, x는 입력 벡터, p는 강우량, t는 시간을 의미한다.
또한 P3 및 P15는 각각 과거 3일과 15일까지의 강우자 료를 이용하는 모형임을 나타낸다.
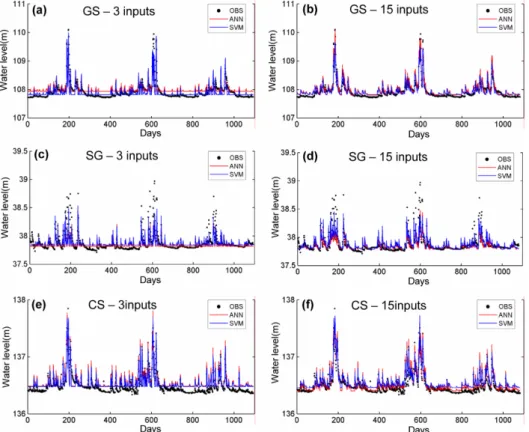
ANN 모델 파라미터 결정을 위해 HN [1, 10], LR [0.0005, 0.05], MM [0.0, 0.9]의 범위에서 총 1000개 의 파라미터 조합을 설정하고 이 중 보정단계 자료 오 차를 최소화 하는 파라미터를 선정하였다. SVM 모델 파라미터 결정을 위해서는 C [1.0, 10.0], ε [0.01, 0.1], σ [0.1, 4.5]의 범위에서 ANN과 마찬가지로 총 1000개의 조합을 이용하여 선정하였다(Table 1과 Table 2). 선정된 각 모델에 대한 가산, 신광, 청성 관측소에서 의 예측 결과를 살펴보면 P3의 경우 ANN과 SVM 모 두 강우 후 지하수위 상승에 대한 반응은 효과적으로
나타나고 있으나 무강우 시기에는 일정한 값만을 보여 주어 지하수위 감쇠 및 기저 변화를 효과적으로 예측하 지 못하는 것을 알 수 있다(Fig. 4(a), (c), (e)). 이는 과거 3일까지의 강우 자료를 입력으로 이용할 때 강우 시기 외의 대부분의 경우에 입력 벡터의 성분이 모두 0 값만으로 채워지게 되어 일정한 값만을 계산할 수밖에 없기 때문이다. 반면 P15 모형의 경우 P3 모형에 비해 지하수위 감쇠 및 기저변화를 보다 정확하게 예측하는 것을 알 수 있다(Fig. 4(b), (d), (f)). 이는 과거 15일까 지의 강우 자료를 사용할 때 입력 성분이 모두 0이 되 는 경우가 크게 줄어들고 최종 강우 이후 지하수위 변 화 패턴을 모델이 충분히 학습할 수 있었기 때문인 것 으로 판단된다. 하지만 입력 자료를 늘리면서 모형의 형 태가 복잡해지고 학습에 필요한 연산 시간이 늘어나는 제한점이 있다. ANN 및 SVM 모델에 대한 P3 모형의 오차지표를 살펴보면 큰 차이가 나타나지는 않지만 가 산과 청성 관측소의 경우 SVM 모델이 신광 관측소의 경우 ANN 모델이 비교적 높은 예측력을 보여준다 (Table 3). P15 모형의 경우에는 가산과 신광 관측소에 서는 SVM이 청성 관측소에서는 ANN 모델이 비교적 높은 예측력을 보여주었다(Table 4). MAPE의 경우 모 든 모형에서 청성 관측소가 가장 낮았고 신광 관측소가 가장 높게 계산되었다. 앞선 교차상관분석 결과 상관계 수가 청성 관측소가 가장 높고 신광 관측소가 가장 낮 게 계산되었는데 강우에 대한 지하수위의 선형적인 상 관성 정도가 모델의 정확성에 영향을 미칠 수 있음을 시사한다.
t o
ytP3=FP3( ) xx, ={pt–3,pt–2,pt–1}
ytP15=FP15( ) xx, ={pt–15,pt–14,…pt–1}
Table 1. Parameters of the rainfall input models: 3 inputs.
Station ANN SVM
HN MM LR C ε σ
GS 4 0.0 0.010 2.0 0.10 0.5
SG 6 0.9 0.001 9.0 0.09 4.0
CS 4 0.0 0.005 2.0 0.08 1.5
Table 2. Parameters of the rainfall input models: 15 inputs.
Station
ANN SVM
HN MM LR C ε σ
GS 6 0.9 0.0005 6.0 0.10 4.5
SG 2 0.1 0.0050 1.0 0.10 1.0
CS 5 0.3 0.0010 2.0 0.08 2.5
강우 및 지하수위 입력 모형
강우 및 지하수위 입력 모형은 강우 과거 자료 이외 에 관측 지하수위 과거 자료를 입력으로 이용하는 모형 으로 각각 과거 3일까지의 자료를 사용하였고 다음과
같이 표현할 수 있다.
(16) rtP3G3=FP3G3( ) xx, ={pt–3,pt–2,pt–1,gt–3,gt–2,gt–1} Fig. 4. Prediction results of the rainfall input models for GS station [(a), (b)], SG station [(c), (d)], and CS station [(e), (f)].
Table 3. Performance criteria of the rainfall input models: 3 inputs.
Station ANN SVM
RMSE (m) CORR MAPE (%) RMSE (m) CORR MAPE (%)
GS 0.21 0.79 0.15 0.18 0.806 0.11
SG 0.12 0.70 0.17 0.12 0.668 0.19
CS 0.12 0.81 0.072 0.12 0.816 0.066
Table 4. Performance criteria of the rainfall input models: 15 inputs.
Station ANN SVM
RMSE (m) CORR MAPE (%) RMSE (m) CORR MAPE (%)
GS 0.14 0.93 0.099 0.12 0.93 0.086
SG 0.11 0.76 0.15 0.11 0.75 0.16
CS 0.097 0.90 0.052 0.10 0.91 0.063
여기서 g는 지하수위 자료, P3G3은 강우 및 지하수위 과거 자료를 이용한 모형을 의미한다.
ANN 및 SVM 모델 파라미터 설정 방법은 강우 입 력 모형과 동일하며 선택된 파라미터 값은 Table 5에
표시하였다. 선택된 모델의 관측소별 예측 결과는 Fig.
5와 같다. P3G3 모형은 P3 및 P15에 비해 지하수위 상승, 감쇠 및 기저 변화를 보다 효과적으로 예측하고 있음을 알 수 있다. 이는 앞서 지하수위 자료의 자기상 관분석에서 언급한 바와 같이 자기회귀성분의 활용이 모 델의 지하수위 변화 예측력 향상에 큰 도움을 주기 때 문인 것으로 판단된다. P3G3 모형의 예측 오차지표를 살펴보면 ANN 및 SVM 모델 모두 RMSE 0.089 이 하, CORR 0.84 이상의 높은 예측력을 보여준다(Table 6). P3G3 모형에서는 SVM 모델이 ANN에 비해 모든 관측소에서 다소 높은 예측 결과를 보여주었다. MAPE 의 경우 강우 입력 모형과 마찬가지로 신광 관측소가 가장 높고 청성 관측소가 가장 낮게 계산되었다.
강우 및 지하수위 입력 모형은 강우 입력 모형에 비 해 입력 성분의 규모를 크게 늘리지 않고도 지하수위 감쇠 및 무강우시 변화를 효과적으로 예측할 수 있는 장점이 있다. 이러한 모형은 실시간 지하수위 관측망 관 리 등에 효율적으로 활용될 수 있을 것이다. 하지만 실 제 관측된 과거 지하수위를 항상 입력으로 사용해야 되 기 때문에 지하수 관측이 지속적으로 이루어지지 않는 상황에서는 적용되기 어렵다. 또한 임의의 강우 입력에 대한 지하수위 변화를 모의하는 것이 불가능하다. 이에 대한 해결방안으로 가용한 관측 자료를 이용하여 강우 및 지하수위 입력 모형을 만들고 이를 이용하여 예측할 때 예측된 지하수위 값을 연속적으로 지하수위 입력 값 으로 활용하는 반복 예측 방법을 고려할 수 있다.
반복 예측 모형
본 연구에서는 ANN 및 SVM 기반 P3G3 모형을 Table 5. Parameters of the rainfall-groundwater level input models.
Station ANN SVM
HN MM LR C ε σ
GS 9 0.3 0.0005 7.0 0.06 1.0
SG 4 0.2 0.0010 3.0 0.09 2.5
CS 9 0.2 0.0010 7.0 0.07 2.5
Fig. 5. Prediction results of the rainfall-groundwater level input models for (a) GS station, (b) SG station, and (c) CS station.
Table 6. Performance criteria of the rainfall-groundwater level input models.
Station ANN SVM
RMSE (m) CORR MAPE (%) RMSE (m) CORR MAPE (%)
GS 0.06 0.99 0.030 0.045 0.99 0.028
SG 0.09 0.84 0.088 0.085 0.85 0.094
CS 0.07 0.93 0.026 0.065 0.94 0.026
활용하여 반복 예측 모형을 만들고 지하수위 변화 예측 에 대한 적용성을 평가하였다. 반복 예측 모형은 다음과 같이 표현될 수 있다.
(17) 여기서 는 예측된 지하수위 값, RPR(recursive prediction)은 반복 예측 모형을 의미한다.
RPR 모형의 예측 결과 P3G3 모형에 비해 예측 오 차가 증가하지만(Table 7) 지하수 상승, 감쇠 및 기저
변화를 효과적으로 예측하는 것을 볼 수 있다(Fig. 6).
RMSE를 기준으로 P15 모형의 오차 지표와 비교해보면 (Table 4) ANN 모델의 경우 RPR 모형의 오차가 더 크지만 SVM의 경우 RPR 모형의 오차가 더 작은 것을 알 수 있다. 이는 일반화 능력이 높은 SVM 구조가 본 연구에 적용된 자료들에 대해 반복 예측 모형을 구현하 는데 있어 강우와 지하수위의 반응 관계를 보다 효과적 으로 학습하였기 때문인 것으로 판단된다.
ANN, SVM과 같은 자료기반 학습 알고리즘을 이용 하여 시계열 예측 모델을 설정하는데 있어 모델이 입·
출력 자료를 포함하는 시스템의 반응 함수를 효과적으 로 반영하도록 모델 파라미터를 선정하는 것이 중요하 다. Yoon et al.(2011)은 이를 판단하는 지표로 학습단 계 오차에 대한 예측단계 오차의 비율을 활용한 바 있 다. 반복 예측 모형의 경우 실제 관측 자료 학습을 통 해 결정된 모델 파라미터들을 그대로 사용하기 때문에 이로 인해 발생할 수 있는 모델 파라미터의 불확실성을 평가하는 것이 필요하다. 본 연구에서는 이를 위해 모델 ytRPR=FP3G3( ) xx, ={pt–3,pt–2,pt–1,gˆt–3,gˆt–2,gˆt–1}
gˆ
Table 7. Performance criteria of the recursive prediction models.
Station ANN SVM
RMSE (m) CORR MAPE (%) RMSE (m) CORR MAPE (%)
GS 0.17 0.94 0.14 0.12 0.95 0.084
SG 0.12 0.78 0.15 0.10 0.76 0.17
CS 0.14 0.85 0.076 0.099 0.90 0.057
Fig. 6. Results of the recursive prediction models for (a) GS station, (b) SG station, and (c) CS station.
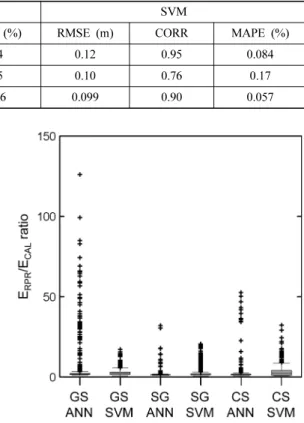
Fig. 7. Comparison of the distributions of the ERPR/ECAL ratio between the applications of ANN and SVM model.
파라미터 탐색에 이용된 각 파라미터 군에 대해 보정 단계 오차(ECAL)에 대한 반복 예측 단계 오차(ERPR)의 비율을 계산하고 비교 평가 하였다. ERPR/ECAL비율이 크고 분포 범위가 넓다는 것은 반복 예측에 활용되는데 부적합한 모델이 학습될 가능성이 높음을 의미한다. Fig.
7은 각 관측소 및 모델 별 ERPR/ECAL비율 값의 분포 를 보여준다. 각 관측소 별로 분포 양상이 다르게 나타 나지만 ANN 모델의 ERPR/ECAL비율 값이 SVM에 비 해 크고 넓은 범위를 보이는 것을 알 수 있다. 이는 SVM 모델이 보다 안정적으로 반복 예측 모형을 구현할 수 있음을 지시한다.
요약 및 결론
본 연구에서는 인공지능 기반 학습 알고리즘 중 ANN과 SVM을 이용한 시계열 모델의 국가지하수관측 망 지하수위 변화 예측에 대한 적용성을 비교 평가하였 다. ANN 모델 구성을 위한 자료 학습 방법으로 역전파 알고리즘을 이용하였고 SVM에는 순차적 최소규모 최 적화 알고리즘을 적용하였으며 시행착오법을 통해 모델 파라미터를 결정하였다. 입력 성분 구성에 따라 강우 입 력 모형, 강우 및 지하수위 입력 모형, 반복 예측 모형 을 설정하고 이를 가산, 신광, 청성 국가지하수관측소 자 료에 적용하였다.
강우 입력 모형의 경우 무강우 기간이 길어질 때 지 하수위 감쇠 및 기저 변화를 적절하게 예측하지 못하는 것으로 조사되었다. 과거 강우 자료 사용량을 늘리면 이 러한 현상이 개선될 수 있지만 모형의 규모가 커지고 학습에 필요한 시간이 늘어나게 된다. 강우 및 지하수위 입력 모형은 보다 작은 규모의 입력 성분으로 지하수위 변화를 효과적으로 예측하는 것으로 나타났다. 그러나 과거 관측 지하수위 자료를 연속적으로 이용해야 하므 로 활용성에 제한이 있다. 반복 예측 모형의 활용은 이 에 대한 대안이 될 수 있다.
각 관측소 및 모형에 대해 ANN과 SVM 모델의 예 측력은 큰 차이가 나지는 않았지만 SVM이 다소 우세 한 경우가 더 많았다. 특히 반복 예측 모형의 경우 ANN 모델은 강우 입력 모형에 비해 예측 오차가 증가 하였지만 SVM은 감소하였다. 모델 보정단계 오차에 대 한 반복 예측 단계 오차 비율의 분포를 조사한 결과 ANN 모델이 SVM 보다 더 크고 넓은 범위를 보여주 어 본 연구 자료에 대해 SVM이 반복 예측 모형 구현
에 있어 보다 정확하고 안정적인 도구임을 알 수 있다.
본 연구에서 제안된 지하수위 변화 예측 방법 및 적용 결과들은 지하수 관측망 관리 및 강우 패턴 변화에 대 한 지하수자원 영향 평가 등의 연구에 활용될 수 있을 것으로 기대한다.
사 사
본 연구는 국토해양부가 출연하고 한국건설교통기술 평가원에서 위탁시행한 물관리연구사업(11기술혁신C05) 에 의한 ‘수변지하수활용 고도화’ 연구단의 연구비 지원 에 의해 수행되었습니다.
References
Almasri, M. N. and Kaluarachchi, J. J., 2005, Modular neural networks to predict the nitrate distribution in ground water using the on-ground nitrate loading and recharge data. Environmental Modelling and Software, 20, 851-871.
Asefa, T., Kemblowski, M., McKee, M., and Khalil, A., 2006, Multi-time scale stream flow predictions: The support vector machines approach. Journal of Hydrology, 318, 7-16.
Box, G. E. P. and Jenkins, G. M., 1976, Time Series Analysis- Forecasting and Control, Holden-Day, San Francisco, California, USA, 575p.
Coppola, E., Rana, A. J., Poulton, M. M., Szidarovszky, F., and Uhl, V. V., 2005, A neural network model for predicting aquifer water level elevations, Ground Water 43(2), 231-241.
Hsu, K. L., Gupta, H. V., Gao, X. G., Sorooshian, S., and Imam, B., 2002, Self-organizing linear output map (SOLO): an artificial neural network suitable for hydrologic modeling and analysis, Water Resources Research, 38(12), 381-3817.
Jain, A. and Kumar, A. M., 2007, Hybrid neural network models for hydrologic time series forecasting, Applied Soft Computing, 7, 585-592.
Khan, M. S. and Coulibaly, P., 2006, Application of sup- port vector machine in lake water level prediction, Journal of Hydrologic Engineering, 11(3), 199-205.
Knotters, M. and Bierkens, M. F. P., 2000, Physical basis of time series models for water table depths, Water Resources Research, 36(1), 181-188.
Nayak, P. C., Satyaji Rao, Y. R., and Sudheer, K. P., 2006, Groundwater level forecasting in a shallow aquifer using artificial neural network approach, Water Resources Management, 20, 77-90.
Park, E. and Parker, J. C., 2008, A simple model for water table fluctuations in response to precipitation, Journal of Hydrology, 356, 344-349.
Platt, J. C., 1999, Fast training of support vector machines using sequential minimal optimization. In:
Scholkopf, B., Burges, C.J.C., Smolar, A.J. (Eds.), Advances in Kernel Methods-Support Vector Learn- ing, MIT Press, Cambridge, Massachusetts, USA, 376p.
Rai, S. N. and Singh, R. N., 1995, Two-dimensional mod- elling of water table fluctuation in response to local- ized transient recharge, Journal of Hydrology, 167, 167-174.
Rumelhart, D. E., McClelland, J. L., and The PDP Research Group, 1986, Parallel Distributed Pro- cessing: Explorations in the Microstructure of Cog- nition. MIT Press, Cambridge, Massachusetts, USA, 516p.
Sahoo, G. B., Ray, C., and De Carlo, E. H., 2006, Use of neural network to predict flash flood and attendant water qualities of a mountainous stream on Oahu, Hawaii, Journal of Hydrology 327, 525-538.
Suen, J. P. and Eheart, J. W., 2003, Evaluation of neural networks for modeling nitrate concentrations in riv- ers, Journal of Water Resources Planning and Man- agement-ASCE 129(6), 505-510.
Scholkopf, B. and Smola, A. J., 2002, Learning with Ker- nels: Support Vector Machines, Regularization, Opti- mization, and Beyond. MIT Press, Cambridge, Massachusetts, USA, 656p.
Srivastava, K., Rai, S. N., and Singh, R. N., 2002, Mod- eling water-table fluctuations in a sloping aquifer with random hydraulic conductivity. Environmental Geology, 41(5), 520-524.
Tankersley, C. D., Graham, W. D., and Hatfield, K., 1993, Comparison of univariate and transfer function mod- els of groundwater fluctuations. Water Resources Research, 29, 3517-3533.
van Geer, F. C. and Zuur, A. F., 1997, An extension of Box-Jenkins transfer/noise models for spatial inter- polation of groundwater head series. Journal of Hydrology, 192, 65-80.
Vapnik, V. N., 1995, The Nature of Statistical Learning Theory, Springer-Verlag, New York, USA, 314p.
Yi, M. J. and Lee, K. K., 2004, Transfer function-noise modeling of irregularly observed groundwater heads using precipitation data. Journal of Hydrology, 288, 272-287.
Yoon, H., Jun, S. C., Hyun, Y., Bae, G. O., and Lee, K.
K., 2011, A comparative study of artificial neural net- work and support vector machines for predicting
groundwater levels in a coastal aquifer, Journal of Hydrology, 396, 128-138.
Zealand, C. M., Burn, D. H., and Simonovic, S. P., 1999, Short-term streamflow forecasting using artificial neural networks, Journal of Hydrology, 214, 32-48.
원고접수일 : 2013년 5월 16일 수정본채택 : 2013년 6월 20일 게재확정일 : 2013년16월 24일
윤희성
한국지질자원연구원 지구환경연구본부 305-350 대전광역시 유성구 과학로 124 Tel : 042-868-3200
E-mail : [email protected] 김용철
한국지질자원연구원 지구환경연구본부 305-350 대전광역시 유성구 과학로 124 Tel : 042-868-3086
E-mail : [email protected] 하규철
한국지질자원연구원 지구환경연구본부 305-350 대전광역시 유성구 과학로 124 Tel : 042-868-3081
E-mail : [email protected] 김규범
한국수자원공사 K-water연구원
305-730 대전광역시 유성구 전민동 462-1번지 Tel : 042-870-7640
E-mail : [email protected]