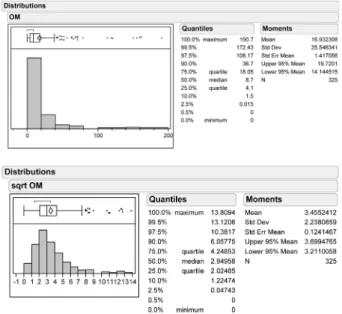
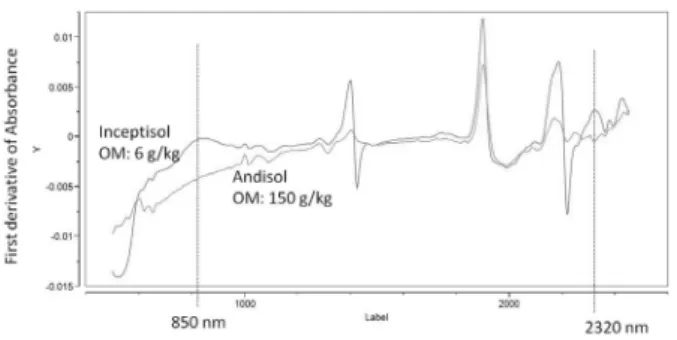
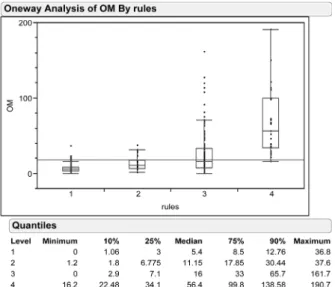
Predicting Organic Matter content in Korean Soils Using Regression rules on Visible-Near Infrared Diffuse Reflectance Spectra
Hyen Chung Chun, Suk Young Hong*, Kwan Cheol Song, Yihyun Kim, Byung Keun Hyun, and Budiman Minasny
1National Academy of Agricultural Science, Suwon, 441-707, Korea
1