기 술 동 향
인공신경망의 기초와 소성가공에의 응용Ⅰ
김영석1, # · 김진재2
1. 경북대학교 기계공학부 교수 2. 경북대학교 기계공학과 박사과정
Basics of Artificial Neural Network and its Applications to Material Forming ProcessⅠ
Y. S. Kim, J. J. Kim
1. School of Mechanical Engineering, Kyungpook National University 2. Graduate School of Mechanical Engineering, Kyungpook National University
1. 서 론
인공신경망(artificial neural network (ANN), 또는 간단히 신경망(neural network, NN)는 인간 뇌의 원 리와 정보처리 과정을 모방해서 만든 머신러닝 (machine learning, 기계학습) 알고리즘이며, 딥러닝 (deep learning, 심층학습)의 기본을 이룬다. 이 인공 신경망은 1940년대 중반에 임계논리(threshold logic) 라 불리는 알고리즘을 바탕으로 신경망을 위한 수 학적 모델이 제안된 이후 최근까지 다양한 분야에 서 활발하게 적용되고 있는 알고리즘이다. 이 인 공신경망은 최근에 국내 소성가공분야에서 최적가 공조건의 탐색, 파단및 스프링백 불량 원인분석 그리고 고부가가치 신소재의 개발과 재질예측 등 에 활발히 적용되고 있다.[1-12] 여기서는 인공신 경망의 기본적인 개요와 알고리즘에 대해서 알기 쉽게 설명하여 소성가공 연구와 기술개발에 도움 을 주고자 한다.
2. 인공신경망의 개요
Fig. 1 에 인공지능(artificial Intelligence, AI), 머신 러닝, 딥러닝, 인공신경망의 범위를 나타내었다.
여기서 인공지능은 인간의 지능이 갖고 있는 기능
을 갖춘 컴퓨터 시스템을 뜻하며, 인간의 지능을 기계 등에 인공적으로 구현한 것을 말한다.
머신러닝은 인공지능의 한 분야로, 컴퓨터가 데 이 터를 학습할 수 있도록 하는 알고리즘과 기술 을 개 발하는 분야를 말하고, 딥러닝은 여러 비선 형 변환 기법의 조합을 통해 높은 수준의 추상화 (다량의 복 잡한 자료들에서 핵심적인 내용만 추 려내는 작업)을 시도하는 다층 인경신경망의 일종 이다.
이 딥러닝 기술은 이미지처리(image processing), 객체탐지(object detection), 자연어처리(natural language processing), 강화학습(reinforcement learning), 자동음 성 인식(automatic speech recognition), 자율주행차량, 최적 경로 탐색(optimal path search) 등등 다양한 산 업 분야에서 최근 널리 사용되고 있으며, 딥러닝 으로 훈련된 시스템의 인식 능력은 이미 인간을 앞서고 있다고 알려져 있다.
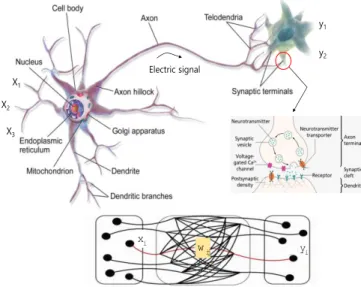
사람의 뇌는 Fig. 2 에서와 같이 엄청나게 많은 뉴런(neuron, 신경세포)들과 외부 자극을 받아들이 는 가지돌기(dendrite 또는 수상돌기) 그리고 뉴런 들 사이에 자극을 전기적 신호로 전달하는 축삭돌 기 (axon)의 신경망 구조(architecture)로 구성되어 있다. 사람의 뇌에서는 각기 다른 뉴런들이 활성 화되고 그 결과(전기화학적 신호)가 시넵스(synapse
Fig. 1 Range of AI, deep learning, and artificial neural network
Fig. 2 Schematic of artificial neural network and its framework
신경 접합부)를 통해 다음 뉴런에 전달하는 방식 에 따라 정보를 처리하게 된다.
뉴런은 여러 방향으로 뻗어 나와 있는 가지돌기 들에서 받아들인 자극(입력신호)들의 크기의 합이 일정 크기 이상의 강도, 즉 임계값을 넘어서면 활 성 화 되 고 그 렇 지 않 으 면 활 성 화 되 지 않 는 다 .
즉, 뇌에 들어온 자극, 신호는 인공신경망에서 입력 값(input)이며 임계값은 가중값(weight), 자극 에 의해 어떤 행동을 하는 것은 출력값(output) 에 해당한다.
인간의 뇌에서 회백색을 띠고 있는 대뇌의 표면
을 대뇌피질이라고 부르며, 이 대뇌피질에는 약 100 억개의 뉴런이 존재하며, 뉴런 한 개당 약 7,000 개 정도의 시냅스를 가지고 있는 것으로 추 산되고 있다.
이런 인간 뇌의 생물학적 신경망 알고리즘을 모 방하여 컴퓨터를 통해 산술, 연산, 학습 및 추론을 할 수 있도록 한 것이 인공신경망이다. 인공신경 망에서는 가지돌기들에서 받아들인 자극을 입력으 로 간주하고, 가지돌기들의 폭(두께)을 입력과 관 련한 가중값으로 간주한다.
인공신경망 이론의 가장 간단한 모델이 Fig. 3 과 같이 입력층과 출력층으로만 구성되어 있는 단층 퍼셉트론(single-layer perceptron) 구조이다. 여기서 𝑥1, 𝑥2 는 입력값(input)이고 𝑤1, 𝑤2 는 각 입력값에 대한 가중값(weight)이다. 또한 𝑏 는 바이어스(bias 또는 편향)이고, 𝜑 (또는 𝑓 )는 활성화 함수 (activation function)이다. 입력값이 주어지는 위치를 노드(node, 뉴런에 해당)라고 부른다. 따라서 만약 n 개의 입력값이 있다면 입력층은 n 개의 노드를 가진다. 이 활성화 함수는 입력값에 대해서 로지 스틱(비선형) 회귀분석 (logistic regression)을 통해 결과를 추론하는 역할을 한다. [13]
이 단층 퍼셉트론 이론은 센서 역할을 하는 입 력층(input layer)과 반응 역할을 하는 출력층 (output layer)으로 이루어진 구조로 볼 수 있다.
Fig. 3 Framework of single-layer perceptron
Artificial Intelligence(AI)
Machine Learning
Deep Learning Neural Network
Electric signal
xi
yi
wij X1
X2
X3
y1
y2
X1
X2
w1
w2
Σ
inputs
weights
transfer
function activation function output
/target X3 w3
u=wixi+b O=φ(u)
wb
b=1
net input φ
O
w=w -α * { E =1
2Σ(target-output)2}min
(dendrite) (synapse) (soma) (axon)
3. 활성화 함수
이 활성화 함수는 가중값이 곱해진 입력값들의 합의 함수로 생물학적 뉴런이 일정 크기 이상의 신호에서만 활성화하도록 해서 의미 없는 데이터 는 사전에 필터링하는 역할을 한다.
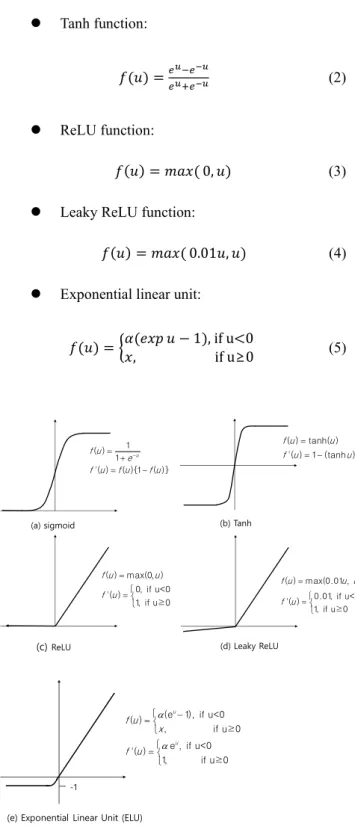
ANN 에서 주로 사용되고 있는 활성화 함수는 시그모이드 함수(sigmoid function), 쌍곡 탄젠트 함 수 (hyperbolic tangent function), 레루 함수(retified linear unit, ReLU function), 기울기 렐루 함수(leaky ReLU function). 지수 선형유닛 함수(exponential linear unit function, ELU), 소프트맥스 함수(softmax function) 등의 연속이면서 비선형 함수이다. Fig. 4 에 이들 함수의 형태를 나타내었다.
시그모이드 함수는 입력 신호의 총합을 0 에서 1 사이의 값으로 변환해주는 역할을 한다. 또한 입 력 신호의 절대값이 커질수록(작아질수록) 함수값 이 1 또는 0 으로 수렴한다. 쌍곡 탄젠트 함수는 시 그모이드 함수의 대체제로 사용할 수 있는 활성화 함수이며 입력값의 총합을 -1 에서 1 사이의 값으로 변환해준다.
한편 렐루 함수는 단순히 입력값을 그대로 출력 으로 내보내기 때문에 시그모이드 함수에 비해 계 산 속도가 빠르다. 또한 시그모이드 함수나 쌍곡 탄젠트 함수와 같이 도함수(구배)가 소실되는 (killed) 문제가 발생하지 않고, 이들 함수에 비해 은닉층이 원활한 학습이 가능하며 학습속도도 매 우 뛰어나기 때문에 널리 사용된다.
한편 기울기 렐루 함수는 렐루 함수을 변형한 형태로 0 이하인 입력에 대해 활성화 함수가 0 만 을 출력하지 않고 입력값에 α(=0.01)만큼 곱해진 값을 출력으로 내보내어 dead ReLU 문제(일부 뉴런 이 0 만을 출력하여 활성화되지 않는 문제)를 해결 한다.
각각의 활성화 함수의 구체적인 형태는 다음과 같다.
⚫ Sigmoid function:
𝑓(𝑢) = 1
1+𝑒−𝑢 (1)
⚫ Tanh function:
𝑓(𝑢) =𝑒𝑢−𝑒−𝑢
𝑒𝑢+𝑒−𝑢 (2)
⚫ ReLU function:
𝑓(𝑢) = 𝑚𝑎𝑥( 0, 𝑢) (3)
⚫ Leaky ReLU function:
𝑓(𝑢) = 𝑚𝑎𝑥( 0.01𝑢, 𝑢) (4)
⚫ Exponential linear unit:
𝑓(𝑢) = {𝛼(𝑒𝑥𝑝 𝑢 − 1), if u<0
𝑥, if u≥0 (5)
Fig. 4 Shape of sigmoid, tanh, ReLu, and leaky ReLu function
시그모이드 함수는 로지스틱 함수의 특별한 경 우이다. 이 시그모이드 함수가 인공신경망 해석에 서 자주 사용되는 이유는 인공신경망 해석에서 후
(a) sigmoid (b) Tanh
(c) ReLU (d) Leaky ReLU
( ) 1 1 '( ) ( ){1 ( )}
f u u
e f u f u f u
= −
+
= −
2
( ) tanh( ) '( ) 1 (tanh )
f u u
f u u
=
= −
( ) max(0, ) 0, if u<0 '( ) 1, if u≥0
f u u
f u
=
=
( ) max(0.01 , ) 0.01, if u<0 '( ) 1, if u≥0
f u u u
f u
=
=
(e) Exponential Linear Unit (ELU)
(e 1), if u<0 ( ) , if u≥0
e , if u<0 '( ) 1, if u≥0
u
u
f u x
f u
−
=
=
-1
술하는 구배하강법을 적용하는 과정에서 활성화 함수의 도함수(gradient, 기울기, 구배)를 구해야 하 는데 이 시그모이드 함수 𝑓(𝑢) 는 함수 특성상 도 함수 𝑓′(𝑢) 가 𝑓(𝑢) ∗ (1 − 𝑓(𝑢)) 로 간단히 표현 되기 때문이다. 즉,
𝑑𝑓(𝑢) 𝑑𝑢 = 𝑑
𝑑𝑢( 1
1+𝑒−𝑢) = (−1)(1 + 𝑒−𝑢)−2(−1)𝑒−𝑢 = 𝑒−𝑢
(1+𝑒−𝑢)2=𝑒−𝑢+1−1
(1+𝑒−𝑢)2= 1
1+𝑒−𝑢− 1
(1+𝑒−𝑢)2 = = ( 1
1+𝑒−𝑢)(1 − 1
1+𝑒−𝑢) = 𝑓(𝑢)(1 − 𝑓(𝑢)) (6) 이 시그모이드 함수와 도함수에 10, -10, 0 을 대 입해보면 함수 형태의 특성을 알 수 있다. 즉,
𝑓(10) ≈ 1, 𝑓′(10) ≈ 0, 𝑓(−10) = 𝑓′(10) ≈ 0 𝑓(0) = 0.5, 𝑓′(0) = 0.25
한편 입력층과 출력층 사이에 1 개 이상의 복수 의 연계층(association layer 또는 은닉층(hidden layer)) 이 존재하는 구조를 다층 퍼셉트론(multi-layer Perceptron)이라고 부른다. 이 퍼셉트론의 개념은 미국 의 심리학자 프랭크 로센블래드(Frank Rosenblatt, 1958) 가 제안한 것으로 인공신경망 이론을 설명한 최초 의 모델이다. 로센블래드는 이 개념을 인공적인 시각인지 과정을 구현하는데 적용하였다. 한편 심 층 신경망(deep neural network, DNN)은 입력층과 출 력층 사이에 여러 개의 은닉층들로 이뤄진 다층 퍼셉트론의 인공신경망을 말한다. 단층 퍼셉트론 은 단층 신경망 모델(single-layer neural network, SLNN), 다층 퍼셉트론은 다층 신경망 모델(multi- layer neural network, MLNN)이라고도 불린다.
4. 손실함수와 역전파 알고리즘
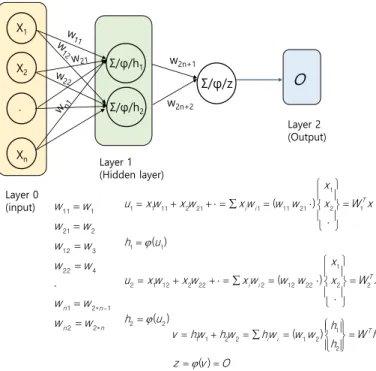
Fig. 5 에 n 개의 입력 뉴런을 갖고 2 개의 뉴런을 갖는 하나의 은닉층과 출력층에서 한 개의 뉴런을 갖는 2 층 퍼셉트론을 나타내었다. 여기서 ∑/𝜑/ℎ 는 그림에 설명한 것과 같이 입력값과 가중값의 합(Σ) 들을 활성화 함수( 𝜑 )에 작용시켜 h 값을 출력하는 것을 나타낸다.
Fig. 5 Framework of two-layers perceptron
다층 퍼셉트론으로 대표되는 인공신경망에서 정보는 입력층에서 시작하여 은닉층을 거쳐 출력층 으로 순차적으로 전달된다. 이렇게 정보가
전방으로 전달되는 것으로부터 인공신경망을
순방향신경망 (feed-forward neural network) 라고 부른다.
그림의 2 층 퍼셉트론에서 정보의 전달은 순방향 으로 다음과 같이 순차적으로 이루어진다. 먼저 입력층과 은닉층 사이에서는
𝑢1= 𝑥1𝑤11+ 𝑥2𝑤21+⋅= ∑𝑥𝑖𝑤𝑖1= (𝑤11 𝑤21 ⋅) { 𝑥1
𝑥2
⋅ } ℎ1= 𝜑(𝑢1)
𝑢2= 𝑥1𝑤12+ 𝑥2𝑤22+ ⋅ = ∑𝑥𝑖𝑤𝑖2= (𝑤12 𝑤22 ⋅) { 𝑥1
𝑥2
⋅ } ℎ2= 𝜑(𝑢2) (7)
또한 은닉층과 출력층 사이에서는
𝑣 = ℎ1𝑤𝑛1+ ℎ2𝑤𝑛2= ∑𝑦𝑖𝑤𝑛𝑖= (𝑤𝑛1, 𝑤𝑛2) {ℎ1 ℎ2} 𝑧 = 𝜑(𝑣) = 𝑂 (8)
X1
X2
Σ/φ/z
Layer 0 (input)
Layer 2 (Output) Layer 1
(Hidden layer) w2n+2
w2n+1 Σ/φ/h1 O
Σ/φ/h2
1
1 1 2 2 1 2
2
( )
( )
T i i
v hw h w hw w w h W h
h z v O
= + = = =
= =
1
1 1 11 2 21 1 11 21 2 1
1 1
1
2 1 12 2 22 2 12 22 2 2
2 2
( )
( )
( )
( )
T i i
T i i
x
u x w x w x w w w x W x
h u
x
u x w x w x w w w x W x
h u
= + + = = =
=
= + + = = =
= Xn
.
11 1
21 2
12 3
22 4
1 2* 1
2 2*
n n
n n
w w
w w
w w
w w
w w
w w
−
=
=
=
=
=
=
식 (7), (8)은 각각 간단히 다음 같이 행렬관계로 나타낼 수 있다.
{𝑢1
𝑢2}
2𝑥1= [𝑤11 𝑤21 ⋅ 𝑤12 𝑤22 ⋅]2𝑥𝑛{
𝑥1
𝑥2
⋅ }
1𝑥𝑛
→ 𝑢[1]= 𝑊[1]𝑇𝑥
{ℎ1
ℎ2} = 𝜑 {𝑢1
𝑢2} → ℎ[1]= 𝜑(𝑢[1]) (9) 𝑣 = ℎ1𝑤𝑛1+ ℎ2𝑤𝑛2= ∑𝑦𝑖𝑤𝑛𝑖= 𝑊[2]𝑇ℎ[1]
𝑧 = 𝜑(𝑣) = 𝑂 (10)
따라서 최종적으로는 출력은 다음과 같이 나타내 진다.
𝑧 = 𝜑(𝑣) = 𝜑[𝑊[2]𝑇ℎ[1]] = 𝜑 [𝑊[2]𝑇{𝜑 (𝑊[1]𝑇𝑥)}]
= 𝑂 (11)
다양한 문제에서 은닉층의 뉴런수와 은닉층의 개수는 계산 효율과 계산 정밀도 등에 따라 정해 진다. 은닉층의 개수가 너무 많으면 계산 효율이 좋지 않고 너무 적으면 해석 정밀도가 좋지 않을 수 있다. 많은 경우에 인공신경망의 구성은 경험 과 컴퓨터 실험에 의존하게 되는데, 이 경우에 시 간도 많이 소요될 수 있고 그 결과가 전역 최적해 에 도달하였는지 확실하지 않다. 따라서 실험계획 법(design of experiment, DOE)을 다층 퍼셉트론 신경 망에 적용하여 적은 실험횟수로 적합한 신경망 모 델을 구성하는 방법이 제안되어 있다.[15, 16]
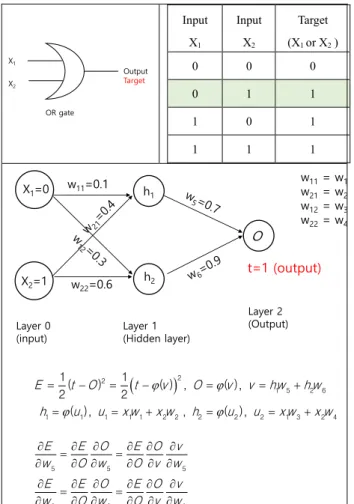
인공신경망 모델로 가장 간단한 경우에 대한 예 로 OR 논리회로(OR logic gate)에 대해서 설명해보 자. 아래 표에 나타낸 OR 논리회로에서와 같이 입력 데이터(또는 데이터 세트)들이 주어지고 일 부 결과들이 알려진 경우에 인공신경망 알고리즘 을 통해서 원하는 결과를 얻기 위해서는 뉴런 사 이의 정보를 전달하는 과정에 작용하는 적당한 파 라미터값(가중값과 바이어스)을 알아야 한다. 즉 파라미터값의 최적화가 필요하다. 파라미터값을 최적화하여 결과를 추론(inference)하는 과정을 학 습(training)이라고 한다. 즉, 이 학습 과정에서는 각 층의 링크가 전달하는 신호를 증폭하거나 감쇠
하는 가중값을 조정하여 결과를 향상시키는 역할 을 한다.
신경망에서 최적의 파라미터값을 찾기 위한 방법 으로 얀 르쿤 ( Yann LeCun), 제프리 힌튼 (Geoffrey Hinton) 등이 개발한 역전파 알고리즘(backpropagation algorithm, BP)이 널리 이용되고 있다. 이 역전파 알고 리즘은 구배하강법(gradient descent 또는 경사하강법) 을 연쇄법칙(chain rule)을 사용하여 단순화시킨 것으 로 볼 수 있다.[17, 18]
일반적으로 인공신경망에서는 초기에 랜덤으로 무작위의 가중값(random weights)을 각 입력에 부여 하고 신경망 모델을 순방향으로 적용하여 결과를 예측한 후에 예측된 결과와 실제 결과(목표값)의 차이값, 즉, 평균제곱오차(mean squared error, MSE) 가 최소가 되도록 정보전달의 순방향과 반대방향 으로 순차적으로 가중값을 갱신하는 과정을 반복 한다. 모든 학습 데이타에 대해서 순방향 계산과 정과 역전파 계산과정을 1 회 완료시킨 것을 1 에 포크( 1 epoch)라고 부른다.
평균제곱오차(이하 간단히 오차)는 다음과 같이 정의된다.
𝐸(𝑡, 𝑂) = 12(𝑡 − 𝑂)2 (= L(t,O)): MSE (12) t: target output, O: computed output (predicted value)
이 오차는 최적화 문제에서는 자주 손실함수 (loss function 또는 비용함수(cost function)) 𝐿(𝑡, 𝑂) 로 불려지기도 한다.
인공신경망 해석에서 입력값들과 활성화 함수 형태가 정해져 있다면 예측값은 결국 가중값에 따 라 결정된다. 따라서 인공신경망 해석은 가중값의 변화에 따른 오차의 변화를 조사하여 평균제곱 오 차를 최소로 하는 최적의 가중값을 찾는 문제로 귀착한다. 가중값의 변화에 따른 오차의 변화는 편미분 𝜕𝐸
𝜕𝑤 (또는 𝜕𝐿
𝜕𝑤 )으로 나타내진다. 윗 식의 우 변에서 예측값 𝑂 는 활성화 함수 𝜑(𝑢) 로부터 예 측되기 때문에 편미분 𝜕𝐸
𝜕𝑤를 구하기 위해서는 연쇄 법칙(chain rule)을 적용해야 한다. 즉,
𝜕𝐸
𝜕𝑤=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕𝑤
𝜕𝑂
𝜕𝑤=𝜕𝑂
𝜕𝑢
𝜕𝑢
𝜕𝑤, 𝑂 = 𝜑(𝑢), 𝑢 = 𝑢(𝑥, 𝑤) (13)
∴𝜕𝐸
𝜕𝑤=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕𝑢
𝜕𝑢
𝜕𝑤
위 식의 우변 각각의 항을 구해보자. 활성화 함수로 시그모이드 함수를 사용하는 경우에 우변 첫 번째 식, 두 번째 식, 세 번째 식은 각각 다음과 같이 나타내진다.
𝜕𝐸
𝜕𝑂= 𝜕
𝜕𝑂(1
2(𝑡 − 𝑂)2) = (𝑡 − 𝑂)(−1) = 𝑂 − 𝑡 (14)
𝜕𝑂
𝜕𝑢= 𝜑(1 − 𝜑) (15)
𝜕𝑢
𝜕𝑤= 𝑥 (16)
따라서,
𝜕𝐸
𝜕𝑤𝑖=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕𝑢
𝜕𝑢
𝜕𝑤𝑖= (𝑂 − 𝑡) ∗ {𝜑 ∗ (1 − 𝜑)} ∗ 𝑥𝑖 (17)
이 과정을 통해 계산된 가중값의 변화에 따른 오 차의 편미분 𝜕𝐸
𝜕𝑤을 이용하여 오차가 감소하는 방향, 즉 구배(gradient)의 반대 방향으로 스텝크기 (step size) 𝛥𝑤 (= 𝛼 ∗𝜕𝐸
𝜕𝑤 ) 만큼 가중값을 갱신해가는 과 정을 반복하여 최적의 가중값을 찾아낸다.
𝑤 = 𝑤 − 𝛼 ∗𝜕𝐸
𝜕𝑤 (18)
여기서 α (0< α <1)는 학습률(learning rate)이다.
수학적으로 말하면 인공신경망 해석은 입력 x를 출력 z에 매핑할 수 있는 수학 함수 z = f(x)를 찾는 것이다. 이 해석의 정확성은 입력 데이터의 분포와 사용된 신경망의 구조에 따라 결정된다.
입력 데이터 개수가 너무 작은 경우에는 데이터를 과평가(overfitting)하는 경우가 있으므로 충분히 많은 데이터를 확보하는 것이 필요하다. 데이터 개수가 작은 경우에는 인공신경망을 적용하기 전에 회귀함수(regression function)를 적용하여 인공신경망 결과와의 비교를 통해서 인공신경망 해석의 효용성을 체크해보는 것을 추천한다.
5. OR 논리회로의 예
다음의 OR 논리회로를 대상으로 인공신경망 모 델이 어떻게 구체적으로 작동하는지를 알기 쉽게 설명한다. OR 논리회로는 은닉층을 고려하고 초기 의 적당한 가중값을 부여하면 다음과 같이 나타낼 수 있다. 이 인공신경망은 1 개의 입력층과 1 개의 은닉층으로 구성되어 있으며 입력층에는 2 개의 노 드, 은닉층에는 2 개의 노드를 갖고 있다. 여기서는 바이어스는 고려하지 않는 것으로 하였다.
이 경우에 따라서 신경망 해석에서 결정해야 할 파라미터값은 w1, w2, ., , w6 모두 6 개이다. 만일 은 닉층에 2 개, 출력층에 1 개의 바이어스를 가정한다 면 파라미터값은 모두 9 개가 된다. 이 바이어스를 고려하면 순방향신경망 계산에서 식 (7)과 (8)은 각각 다음과 같이 수정된다.
ℎ1= 𝜑(𝑢1+ 𝑏1), ℎ2= 𝜑(𝑢2+ 𝑏2), 𝑧 = 𝜑(𝑣 + 𝑏3),
출력층과 은닉층 사이에서 가중값 𝑤5, 𝑤6 의 변화에 따른 오차의 변화 𝜕𝐸
𝜕𝑤5 , 𝜕𝐸
𝜕𝑤6는 다음과 같이 구해진다.
𝜕𝐸
𝜕𝑤5=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕𝑣
𝜕𝑣
𝜕𝑤5= (𝑂 − 1) ∗ 𝜑(𝑣) ∗ (1 − 𝜑(𝑣)) ∗ ℎ1 = (0.7310 − 1) ∗ 0.7316 ∗ (1 − 0.7361) ∗ 0.5986 = −0.03161
∵ {
𝑂 = 𝜑(𝑣) = 𝑂(ℎ1𝑤5+ ℎ2𝑤6) = 𝜑(1.00006) = 0.7310 ℎ1= 𝜑(𝑥1𝑤1+ 𝑥2𝑤2) = 𝜑(0.4) = 0.5986
ℎ2= 𝜑(𝑥1𝑤3+ 𝑥2𝑤4) = 𝜑(0.6) = 0.6456
마찬가지로 𝜕𝐸
𝜕𝑤6= −0.0375.
따라서 학습률은 0.05로 한 경우에 가중값 𝑤5, 𝑤6
은 다음과 같이 갱신된다.
𝑤5= 𝑤5− 𝛼 ∗ 𝜕𝐸
𝜕𝑤5= 0.7 − 0.05 ∗ (−0.03161) = 0.7015
𝑤6= 𝑤6− 𝛼 ∗ 𝜕𝐸
𝜕𝑤6 = 0.9 − 0.05 ∗ (−0.0375) = 0.9018
Input X1
Input X2
Target (X1 or X2 )
0 0 0
0 1 1
1 0 1
1 1 1
Fig. 6 Framework of multi-layer perceptron with different weight values
한편 이 문제에서 은닉층과 입력층 사이에서 가 중값 𝑤1의 변화에 따른 오차의 변화는 다음과 같 이 나타내 진다.
𝜕𝐸
𝜕𝑤1= 𝜕𝐸
𝜕ℎ1
𝜕ℎ1
𝜕𝑤1 여기서 𝜕𝐸
𝜕ℎ1은 다음과 같이 나타낼 수 있다.
𝜕𝐸
𝜕ℎ1=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕ℎ1=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕𝑣
𝜕𝑣
𝜕ℎ1
따라서 식 (12)의 평균제곱오차를 손실함수로 사용하면
𝜕𝐸
𝜕𝑂= 𝑂 − 𝑡
한편 𝑣 = ℎ1𝑤5+ ℎ2𝑤6, 𝑂 = 𝜑(𝑣) = 𝜑(ℎ1𝑤5+ ℎ2𝑤6) 이므로 시그모이드 활성화 함수를 사용하는 경우에
𝜕𝑂
𝜕ℎ1=𝜕𝑂
𝜕𝑣
𝜕𝑣
𝜕ℎ1 =𝜕𝑂
𝜕𝑣∗ 𝑤5= {𝜑(𝑣) ∗ (1 − 𝜑(𝑣))} ∗ 𝑤5
또한 𝑢1= 𝑥1𝑤1+ 𝑥2𝑤2이므로
𝜕ℎ1
𝜕𝑤1=𝜕ℎ1
𝜕𝑢1
𝜕𝑢1
𝜕𝑤1=𝜕ℎ1
𝜕𝑢1∗ 𝑥1= {𝜑(𝑢1) ∗ (1 − 𝜑(𝑢1))} ∗ 𝑥1
따라서 가중값 𝑤1의 변화에 따른 오차 𝑂 의 변 화는 다음과 같이 나타내진다.
∂𝐸
∂𝑤1= ∂𝐸
∂ℎ1
∂ℎ1
∂𝑤1= {∂𝐸
∂𝑂
∂𝑂
∂𝑣
∂𝑣
∂ℎ1} {∂ℎ1
∂𝑢1
∂𝑢1
∂𝑤1}
= {(𝑂 − 𝑡) ∗ 𝜑(𝑣) ∗ (1 − 𝜑(𝑣)) ∗ 𝑤5} ∗ {𝜑(𝑢1) ∗ (1 − 𝜑(𝑢1)) ∗ 𝑥1}
구체적인 값들을 구해보자.
ℎ1= 𝜑(𝑥1𝑤1+ 𝑥2𝑤2) = 𝜑(0 ∗ 0.1 + 1 ∗ 0.4) = 1
1+𝑒−0.4 = 0.5986
ℎ2= 𝜑(𝑥1𝑤3+ 𝑥2𝑤4) = 𝜑(0 ∗ 0.3 + 1 ∗ 0.6) = 1
1+𝑒−0.61= 0.6456 출력은 1.0 이므로
𝑣 = ℎ1𝑤5+ ℎ2𝑤6= 0.5986 ∗ 0.7 + 0.6456 ∗ 0.9 = 1.0006
𝑂 = 𝜑(𝑣) = 𝜑(1.0006) = 1
1+𝑒−1.0006= 0.7310 따라서,
𝜕𝐸
𝜕𝑂 = 𝑂 − 𝑡 = 0.7310 − 1 = −0.269
𝜕𝑂
𝜕ℎ11= 𝜑(𝑣) ∗ {1 − 𝜑(𝑣)} ∗ 𝑤5
= 𝜑(1.0006) ∗ {1 − 𝜑(1.0006)} ∗ 0.7 = 0.7310 ∗ (1 − 0.7310) ∗ 0.7 ≈ 0.137
X1=0
O w11=0.1
X2=1 t=1 (output)
h1
h2
Layer 0
(input) Layer 1 (Hidden layer)
Layer 2 (Output) w22=0.6
w11= w1 w21= w2 w12= w3 w22= w4
( )2
2
1 5 2 6
1 1 1 1 1 2 2 2 2 2 1 3 2 4
1 1
( ) ( ) , ( ),
2 2
( ), , ( ),
E t O t v O v v hw h w
h u u x w x w h u u x w x w
= − = − = = +
= = + = = +
5 5 5
6 6 6
E E O E O v
w O w O v w
E E O E O v
w O w O v w
= =
= =
OR gate
Output Target X1
X2
또한 𝑢 = 𝑥1𝑤1+ 𝑥2𝑤2= 𝑂 ∗ 0.1 + 1 ∗ 0.4 = 0.4
𝜕ℎ1
𝜕𝑤1= {𝜑(𝑢) ∗ (1 − 𝜑(𝑢))} ∗ 𝑥1
= {𝜑(0.4) ∗ (1 − 𝜑(0.4))} ∗ 0 = 0 그러므로,
𝜕𝐸
𝜕𝑤1=𝜕𝐸
𝜕𝑂
𝜕𝑂
𝜕ℎ1
𝜕ℎ1
𝜕𝑤1= −0.269 ∗ 0.137 ∗ 0 = 0 따라서 학습률을 0.05 로 한 경우에 가중값 𝑤1은 다음과 같이 갱신된다.
𝑤1= 𝑤1− 𝛼 ∗ 𝜕𝐸
𝜕𝑤1= 0.1 − 0.05 ∗ 0 = 0.1 마찬가지로 방법으로 𝜕𝐸
𝜕𝑤2과 𝑤2, 𝜕𝐸
𝜕𝑤3, 𝑤3 등 모든 파라미터값을 구할 수 있다. 이들 파라미터값 들 을 순방향으로 적용해 가면 예측된 결과를 얻을 수 있다. 이 예측된 결과와 목표값의 평균제곱 오 차가 매우 작아질 때까지 이 과정을 반복하면 최 적의 가중값을 찾을 수 있다. 결국 인공 신경망의 최적화 알고리즘은 손실함수를 정의하고 구배하강 법을 적용하여 반복적인 학습을 통해서 결과를 잘 나타내는 파라미터값을 찾는 방법이라는 것을 알 수 있다.
이 예제에서는 가중값의 초기값을 𝑤1, 𝑤2, 𝑤3,⋅⋅=
0.1,0.4,0.3,⋅⋅ 으로 부여하였다. 신경망 학습에서는 학습시킬 때의 가중값의 초기값을 어떤 값으로 하 는가가 중요하다. 왜냐하면 가중값의 초기값을 어 떻게 취하느냐에 따라 학습이 잘 될 때가 있고 잘 안될 때가 있기 때문이다. 일반적으로 가중값의 초기값을 가능한 작게 잡아야 하며 입력값들에 대 해서 동일한 초기값을 갖지 않도록 랜덤하게 초기 화해야 한다. 이때 가중값 초기값은 평균이 0 이고 표준편차가 0.01 인 정규분포(가우시안 분포)를 따 르는 값으로 랜덤하게 초기화하는 것을 추천한다.
시그모이드 활성화 함수가 인공신경망 해석에서 자주 사용되지만 이 함수는 다음과 같은 단점을 가지고 있다. 즉, 입력 신호의 절대값이 커질수록 (작아질수록) 함수값이 1 또는 0 으로 수렴하지만 뉴런의 도함수는 0 으로 소실된다. 따라서 역전파 과정에서 0 이 곱해지기 때문에 역전파가 진행됨에 따라 아래 층(layer)에는 아무 정보도 전달되지 않 는 문제가 있다. 또한 시그모이드 함수는 원점 중
심이 아니기(not zero-centered) 때문에 항상 양수를 출력하므로 출력의 가중치 합이 입력의 가중치 합 보다 커질 가능성이 높다. 이것을 편향 이동(bias shift)이라 한다. 따라서 순방향 계산에서 각 층을 지날 때마다 분산이 계속 커져서 가장 높은 층에 서는 활성화 함수의 출력이 0 이나 1 로 수렴하게 되어 도함수 소실 문제가 일어나게 된다.
많은 인공신경망 교재에서 활성화 함수로는 가능한 ReLU 를 먼저 사용하고, 그 다음으로 LeakyReLU 나 ELU 같은 ReLU Family 를 쓰며, 가능한 시그모이 드 함수는 사용하지 않는 것이 좋다고 제안하고 있다.
입력층의 뉴런과 은닉층이 많은 일반적인 인공 신경 망 모델을 풀기 위해서는 Python 언어로 쓰 여진 전용 프로그램 또는 Matlab 프로그램을 이용 하는 것이 일반적이다.
파이썬(Python)[19]은 1991 년 프로그래머인 귀도 반 로섬(Guido van Rossum)이 발표한 고급 프로그 래밍 언어로, 플랫폼에 독립적이며 인터프리 터식, 객체지향적, 동적 타이핑 대화형 언어이다. 파이썬 은 문법이 매우 쉬워서 초보자들이 처음 프로그래 밍을 배울 때 추천되는 언어로 타 프로그래밍 언 어와 비교하면 접근성과 응용력이 좋다고 알려져 있다.
과학적 프로그래밍에 사용되는 기본 연산에는 배열, 행렬, 적분, 미분방정식 연산, 통계 등이 있 다. 파이썬은 행렬이나 배열이 아닌 일반적 변수 에 대한 기초적 수학 연산을 제공하지만 기본적인 과학계산 기능은 내장되어 있지 않다. 따라서 사 이파이(SciPy)[20], 넘파이(NumPy)[21]와 심파이 (SymPy)[22]와 같이 과학계산을 효율적으로 수행 할 수 있는 패키지들을 제공한다.
한편 딥 러닝과 같은 인공지능 기법들을 쉽게 구 현할 수 있게 도와주도록 개발된 딥러닝 프레임워 크로는 텐서플로우(Tensorflow)[23], 파이 토치(pytorch) [24], 카페(caffe)[25], 시아노(theano) 등이 있다. 이 들은 대부분 파이썬 과 C/C++을 지원한다.
AI 를 전문으로 하는 사람들은 이들 소프트웨어 를 사용하는 것을 추천하지만 간단한 공학문제를 풀려고 하는 학생들은 구글 크라우드 상에서 운영 하는 프리웨어 소프트웨어 https://colab.research.
google.com/ 를 이용하길 추천한다.
4. 결 론
본 해설에서는 최근 다양한 산업분야와 소성가 공 분야에서 활발이 사용되고 있는 인공신경망의 기본적인 개요와 알고리즘에 대해서 설명하였다.
또한 간단한 OR 논리회로를 대상으로 한 인공신 경망 모델에서 매개변수값이 역전파 과정을 통해 어떻게 갱신되어가는 지를 알기 쉽게 설명하였다.
다음 호에서는 소성가공문제에 구체적인 적용 예와 파이썬 프로그램을 설명한다.
후 기
이 논문은 2021 대한민국 교육부와 한국연구재 단의 지원을 받아 수행된 연구임(NRF-2019R1A2C 1011224).
REFERENCES
[1] D. H. Kim, D. J. Kim, B. M. Kim, J. C. Choi, 1997, Process Design of Multi-Step Drawing using Artificial Neural Network, Conf. on Trans. Mater.
Process, pp. 144-147
[2] A. J. Hong, K. D. Cheol, L. C. Joo, B. M. Kim, 2008, Springback Compensation of Sheet Metal Bending Process Based on DOE & ANN, Trans. Kor. Soc.
Mech. Eng., Vol. 32, No. 11, pp. 990~996.
[3] S. K. Lee, S. M. Kim, S. B. Lee, B. M. Kim, 2010, Optimization of Process Variables of Shape Drawing for Steering Spline Shaft, Trans. Mater. Process, Vol.
19, No. 2, pp. 132-137.
[4] D. T. Nguyen, Y. S. Kim, D. W. Jung, Formability Predictions of Deep Drawing Process for Aluminum Alloy A1100-O Sheets by Using Combination FEM with ANN, 2012, Advanced Mat. Research, Vol. 472, pp. 781~786.
[5] J. I. Choi, J. M. Lee, S. H. Baek, B. M. Kim, D. H.
Kim, 2015, The Shoe Mold Design for Korea Standard Using Artificial Neural Network, Trans.
Mater. Process, Vol. 24, No. 3, pp. 167-175.
[6] V. C. Do, Y. S. Kim, Effect of Hole Lancing on the Forming Characteristic of Single Point Incremental
Forming, 2017, Proc. Eng., Vol. 184, pp. 35~42.
[7] M. A. Woo, S. M. Lee, K. H. Lee, W. J. Song, J. Kim, 2018, Application of an Artificial Neural Network Model to Obtain Constitutive Equation Parameters of Materials in High Speed Forming Process, Trans.
Mater. Process, Vol. 27, No. 6, pp. 331-338.
[8] S. C. Ma, E. P. Kwon, S. D. Moon, Y. Choi, 2020, Prediction of Springback after V-Bending of High- Strength Steel Sheets Using Artificial Neural Networks, Trans. Mater. Process, Vol. 29, No. 6, pp.
338~346.
[9] D. C. Yang, J. H. Lee, K. H. Yoon, J. S. Kim, 2020, A Study on the Prediction of Optimized Injection Molding Condition using Artificial Neural Network (ANN), Trans. Mater. Process, Vol. 29, No. 4, pp.
218-228.
[10] M. J. Kwak, J. W. Park, K. T. Park, B. S. Kang, 2020, A Development of Optimal Design Model for Initial Blank Shape Using Artificial Neural Network in Rectangular Case Forming with Large Aspect Ratio, Trans. Mater. Process, Vol. 29, No. 5, pp. 272-281.
[11] M. J. Kwak, J. W. Park, K. T. Park, B. S. Kang., 2020, A Development of Longitudinal and Transverse Springback Prediction Model Using Artificial Neural Network in Multipoint Dieless Forming of Advanced High Strength Steel, Trans. Mater. Process, Vol. 29, No. 2, pp. 76-88.
[12] S. H. Oh, X. Xiao, Y. S. Kim, 2021, Modeling of AA5052 Sheet Incremental Sheet Forming Process Using RSM-BPNN and Multi-optimization Using Genetic Algorithms, Trans. Mater. Process, Vol. 30, No. 3, pp. 125-133.
[13] H. B. Demuth, M. H. Beale, O. De Jess, & M. T.
Hagan, 2014, Neural network design (2nd Edition.
Martin Hagan.
[14] https://cs230.stanford.edu/files/C1M3.pdf
[15] S. H. Lee, D. C. Kang, C. Lee, M. J. Kang, Structural Design of Artificial Neural Network using DOE, 1996, Proc. of spring Conf. on Korean Soc. Prec. Eng., pp.
536~540.
[16] F. Rosenblatt, A probabilistic model for information storage and organization in the brain, 2000, Psychological Review, Vol. 65, No. 3, pp. 383~408.
[17] M.Hassoun, Fundamentals of artificial networks, 1995, MIT press
[18] Ian J. Goodfellow, Yoshua Bengio and Aaron Couville, Deep learning, 2015, MIT Press
[19] https://www.python.org/
[20] www.scipy.org
[21] www.numpy.org [22] www.sympy.org
[23] https://www.tensorflow.org [24] https://pytorch.org
[25] https:// caffe.berkeleyvision.org/