1. 서 론
최근 국내 미세먼지 문제는 이미 그 심각성이 인 식되어 전문가 그룹 뿐 아니라 일반 국민들의 관심도 높아지고 있다. 특히 고농도 초미세먼지가 발생하는 경우는 3∼4일간 혹은 그 이상 지속되는 경향이 있고 습도가 높은 경우에 생성속도가 가속되기 때문에 짙 은 스모그 형태로 나타나고 있다[1].
미세먼지는 국민 건강에 직접적으로 영향을 미치 기 때문에 예보의 중요성은 점점 커지고 있다. 이에 환경부에서는 2014년 2월부터 미세먼지 예보를 전국 적으로 시행중이나, 실제 시민이 느끼는 체감 오염도 와 많은 차이를 보이고 있다. 미세먼지 예보가 국민 건강보호를 위한 예방적 기능을 수행하기 위해서는 예보 성능의 개선이 시급하다.
현재 미세먼지 예보는 수치모델 결과를 중심으로 수행되고 있으나 수치예보는 배출량 및 기상자료 등 으로 대표되는 입력 자료의 불확실성과 수치모델 자 체가 복잡한 대기현상을 완전하게 반영하지 못하는 근본적인 한계를 가지고 있다.
본 연구에서는 이러한 한계를 극복하기 위해서 기 상 및 대기질 측정 자료와 예보 자료, 이를 기반으로 하는 2차 데이터를 심층신경망(DNN: Depp Neural Network)에 학습시켜 불완전한 수치모델(CASE04) 의 결과를 보정하고, 정확도를 향상시킬 수 있는 예 보모델들을 개발했다.
본 논문에서 개발한 예보 모델들의 성능 비교 대 상인 CASE04는 CMAQ을 사용하여 PM10예측 농도 를 생성하는 수치예보 모델이다. CMAQ은 가스상, 입자상 대기오염물질을 통합하여 ‘one-atmosphere’
DNN과 2차 데이터를 이용한 PM
10
예보 성능 개선유숙현†, 전영태††
Improvement of PM
10Forecasting Performance using DNN and Secondary Data
SukHyun Yu†, YoungTae Jeon††
ABSTRACT
In this study, we propose a new PM
10forecasting model for Seoul region using DNN(Deep Neural Network) and secondary data. The previous numerical and Julian forecast model have been developed using primary data such as weather and air quality measurements. These models give excellent results for accuracy and false alarms, but POD is not good for the daily life usage. To solve this problem, we develop four secondary factors composed with primary data, which reflect the correlations between primary factors and high PM
10concentrations. The proposed 4 models are A(Anomaly), BT(Back trajectory), CB(Contribution), CS(Cosine similarity), and ALL(model using all 4 secondary data). Among them, model ALL shows the best performance in all indicators, especially the PODs are improved.
Key words: PM
10Forecasting, Air Quality Index, Deep Neural Network, AI
※ Corresponding Author : SukHyun Yu, Address: (14028) 22 Samdeokro 37beon-gil, Manan-gu, Anyang-si, Gyeonggi-do, Korea, TEL : +82-31-467-1272, FAX : +82-31-463-1249, E-mail : [email protected]
Receipt date : Aug. 14, 2019, Revision date : Sep. 11, 2019
Approval date : Sep. 26, 2019
††
Dept. of Information & Communication Eng., Anyang University
††
Dept. of Computer Eng., Anyang University
(E-mail : [email protected])
평가를 할 수 있는 오일러리안 화학수송 모델로 기상 모델링 자료, 배출량 모델링 자료, 광분해 모델 자료 등을 입력 자료로 대기 중 오염물질의 균질 및 비균 질 화학반응, 이류 및 확산을 계산한다[1]. 현재 CMAQ은 U.S EPA(United States Environmental Protection Agency) 산하 CMAS(Community Mod- eling and Analysis System) 센터를 중심으로 꾸준 히 개발 보완되고 있다. CASE04는 CMAQ 대기질 모델링 시스템에 기상 모델인 WRF v3.6.1과 아시아 배출량 자료인 MEIC(2010)과 REAS(2008), 국내 배 출량 자료인 2011 CAPSS를 입력하고, 자료동화를 적용하여 모델링하였다.
개발한 예보모델은 6가지로 크게 기상 및 대기질 측정 자료와 예보자료로 대표되는 1차 데이터를 학 습 자료로 사용한 모델인 Julian과 1차 데이터와 이 를 기반으로 생성한 아노말리, 역 궤적, 기여도, 코사 인유사도 등의 2차 데이터를 학습 자료로 사용한 모 델인 A, BT, CB, CS, ALL이 있다. 개발한 예보모델 들의 성능을 평가하기 위해서 동일한 평가기간에 대 해서 수치모델인 CASE04와 상호 비교했다.
미세먼지를 비롯한 대기 오염물질을 예보하는데 인공신경망의 성능은 이미 입증되어 관련 연구들이 진행되고 있다. 관련 연구로는 인공신경망에 날짜 데 이터(month, weekly day, julian day), 대기질 데이 터, 지형 데이터와 기상 측정 및 예보 데이터를 입력 하여 PM10과 PM2.5의 예보와 성능을 평가 분석한 연 구[2-10], RNN(Recurrent Neural Network)을 이용 하여 O3 및 PM10, PM2.5의 농도를 예측한 연구[11- 12], RBF(Redial Based Function)를 이용하여 PM10
의 농도를 예측한 연구[13]가 있다. 그 밖에 시계열 대기질 자료의 결측치를 처리하기 위해서 DRNN (Deep Recurrent Neural Network)를 기반으로 시공 간 예측 프레임워크를 제안한 연구[14], PM10 예보 성능의 향상을 위해서 민감도 분석을 사용하여 역모 델 파라메타를 추정한 연구[15], 대기질 예보의 성능 향상을 위해서 커널 삼중대각 희소행렬을 이용해 고 속으로 자료동화 수행한 연구[16] 등이 있다.
본 연구에서는 서울 권역을 대상으로 당일(D+0), 내일(D+1), 모레(D+2)의 PM10 예보를 위해서 심층 신경망을 기반으로 한 6가지 예보 모델을 개발했다.
제안한 연구는 다음과 같은 순서로 기술한다. 이어지 는 2장에서는 예보에 사용한 입력인자와 심층신경망 의 네트워크 구조에 대해서 설명하고, 3장에서는 각 예보모델들을 기술하며, 4장에서는 제안한 모델별 PM10예보결과를 나타내고, 5장에서 결론을 맺는다.
2. 입력인자와 네트워크 구조
2.1 입력인자
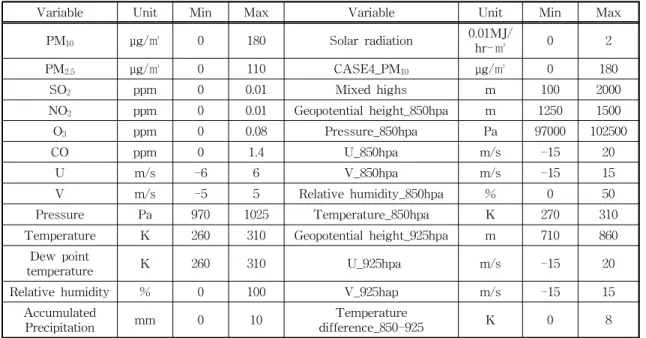
본 연구에서는 대기질, 기상 측정데이터와 예보 데이터로 대표되는 1차 데이터와 이를 기반으로 생 성한 2차 데이터인 아노말리, 역 궤적, 기여도, 코사 인유사도를 심층신경망에 입력하여 서울 권역의 PM10예보 값을 생성했다. 예보에 사용한 인자들은 선행연구[1]에서 생산된 자료로 ㈜애니텍의 AI 데이 터베이스의 자료를 사용했으며, Table 1과 Table 2 에 구체적으로 기술했다.
아노말리는 동북아시아의 기상패턴을 분석하기
Fig. 1. CMAQ air quality modeling system.
위해서 WRF 예보 자료를 활용하여 고도별로 tem- perature, geopotential height, relative humidity, U, V, W 변수에 대해서 생성된 2차 데이터이다. 그 중
본 연구에서 사용한 변수를 Table 2에 제시했다.
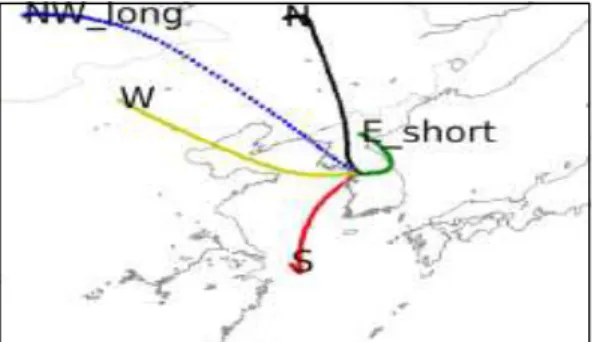
역 궤적은 우리나라에서 발생하는 미세먼지 사례 를 남풍류, 짧은 기류, 북서풍류, 서풍류의 5 가지 군
Table 1. Primary data
Variable Unit Min Max Variable Unit Min Max
PM
10μ g/㎥ 0 180 Solar radiation 0.01MJ/
hr-㎡ 0 2
PM
2.5μ g/㎥ 0 110 CASE4_PM
10μ g/㎥ 0 180
SO
2ppm 0 0.01 Mixed highs m 100 2000
NO
2ppm 0 0.01 Geopotential height_850hpa m 1250 1500
O
3ppm 0 0.08 Pressure_850hpa Pa 97000 102500
CO ppm 0 1.4 U_850hpa m/s -15 20
U m/s -6 6 V_850hpa m/s -15 15
V m/s -5 5 Relative humidity_850hpa % 0 50
Pressure Pa 970 1025 Temperature_850hpa K 270 310
Temperature K 260 310 Geopotential height_925hpa m 710 860
Dew point
temperature K 260 310 U_925hpa m/s -15 20
Relative humidity % 0 100 V_925hap m/s -15 15
Accumulated
Precipitation mm 0 10 Temperature
difference_850-925 K 0 8
Table 2. Secondary data
Kind Variable Min Max
Anomaly
1000hpa_Temperature -80.29 388.73
1000hpa_Relative humidity -14.68 14.40
925hpa_Geopotential height -62.75 59.06
925hpa_U -22.81 22.28
850hpa_Geopotential height -76.73 72.60
850hpa_U -22.48 25.60
500hpa_Geopotential height -53.75 77.24
300hpa_Geopotential height -54.28 59.21
Back Trajectory BT Pattern 1 5
Contribution Contribution of 20 region 0 1
Cosine Similarity
1000hpa_Temperature -0.89 0.88
1000hpa_Relative humidity -0.88 0.90
925hpa_Temperature -0.77 0.77
925hpa_Relative humidity -0.89 0.89
850hpa_Temperature -0.63 0.68
850hpa_Relative humidity -0.87 0.86
500hpa_Geopotential height -0.61 0.59
300hpa_Geopotential height -0.57 0.54
집으로 분류한 패턴으로 Fig. 2에 나타냈다.
기여도는 Fig. 3에 제시한 바와 같이 동아시아 권 역을 총 20개의 지역으로 구분하여 각 권역에 해당하 는 기여농도를 도출한 값으로 0에서 1사의 값으로 표현된다.
코사인 유사도는 고도별, 변수별 기상 데이터를 미세먼지 예측에 보다 용이한 형태로 변환하고자 수 식 (1)에 의해 재생산한 값이다[18]. 코사인 유사도를 구하는 기준은 먼저, 고농도일의 평균 패턴
들을 계산하고 이를 기준 패턴으로 삼는다. 그리고, 기준 패턴들과 예측하고자 하는 날짜들의 패턴
들을 비 교하여 얼마나 유사하였는지를 구하는 방법이다. 코 사인 유사도 계산 결과 기준패턴과 유사할수록 1에 가까운 값을 정 반대되는 패턴일수록 –1에 가까운 값을 가지게 된다. ∥∥∥∥
·
(1)
2.2 네트워크
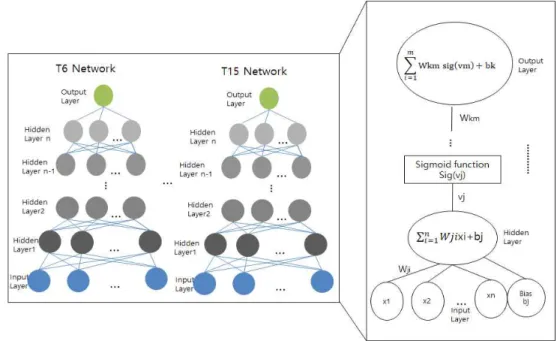
본 연구에서는 입력데이터의 종류 및 개수를 달리 하는 6 개의 예보모델들을 제안했다. 제안한 예보 모 델별로 네트워크 구조가 다소 상이하나 기본적으로 는 1개의 입력층과 여러 개의 은닉층, 1개의 출력층 을 가지는 심층신경망으로 Fig. 4에 이를 나타냈다.
제안한 예보모델들은 6시간 평균 데이터를 입력 하여, 6시간 단위로 3일치(D+0, D+1, D+2) 예보를 수행하는 것이 목적으로 Fig. 4에 제시한 시간 프레 임에 따라 예보 값을 생성한다. Fig. 4에 나타낸 하나 의 T는 6시간 단위로 구성되어 있고, 이 중 T1∼T5 는 과거에 해당하는 구간, T6∼T15 예보구간에 해당 한다.
입력층에는 과거 6시간(T5)의 측정 데이터들과 예보구간(T6∼T15)의 예보 데이터들이 입력되고, 출력층에는 각 예보구간의 미세먼지 측정 값이 목표 값으로 입력되어 학습이 진행된다. 학습 은 경사하강 법에 의해 가중치 및 파라메타를 최적화 하는 과정으 로 이때, 비용함수는 MSE(Mean Square Error), 활 성화함수는 시그모이드를 사용했다.
3. 제안한 예보모델
3.1 예보모델의 개요
본 논문에서는 PM10의 3일(D+0, D+1, D+2) 예보 를 수행하기 위해서 학습인자를 달리한 6개의 예보 모델을 개발했다. 이 중 Julian 예보모델은 1차 데이 터인 대기질 및 기상 측정 데이터와 예보 자료, 날짜 데이터를 사용한 모델로 구체적인 학습인자는 Table 3에 제시했다.
날짜 데이터는 미세먼지의 농도와 높은 상관성을 갖는 기본적인 인자로 주어진 날짜를 어떻게 표현하 느냐에 따라 미세먼지와의 상관성을 더 정확하게 표 현할 수 있다. Julian 예보모델에서는 날짜를 제안한
Fig. 2. Back trajectory pattern of Seoul region.
Fig. 3. Contribution region.
Fig. 4. Time unit concept of forecast model.
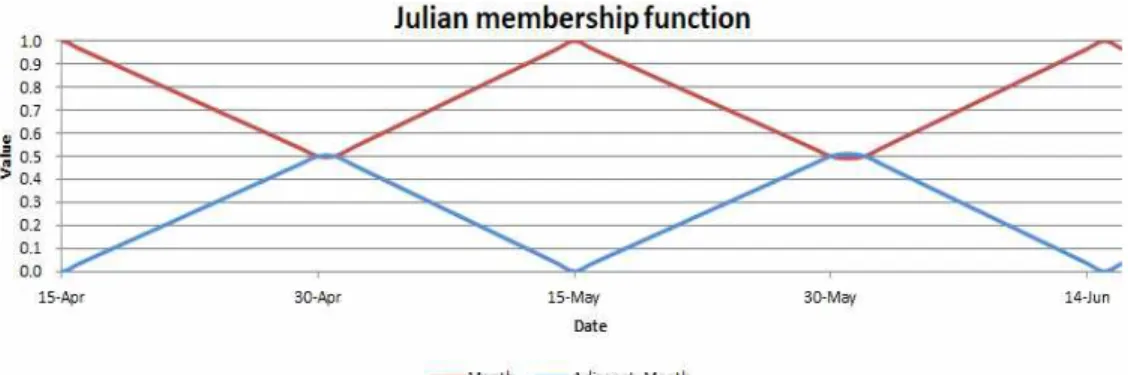
줄리안 멤버십 함수(Fig. 6)에 의해 12개의 인자로 표현된다. 줄리안 멤버십 함수는 시간의 연속성 및 미세먼지의 계절적 특성을 고려하여 날짜를 1월에서 12월을 대표하는 12개의 연속적인 인자로 나타낸다.
12개의 인자 중 2개만이 활성화되고, 나머지 10개의 인자는 0으로 설정하는데, 활성화되는 2개의 인자는 각각 주어진 날짜의 월(Month)과 인접 월(Adjacent_
Month)이다. 예를 들어, 주어진 날짜가 4월 20일 이 라면 제안한 줄리안 멤버십 함수에 의해서 인접 월 (Adjacent_Month)은 5, 해당 월의 값(Month_value) 는 0.8, 인접 월의 값(Adjacent_Month_value)는 0.2
가 되어 날짜를 나타내는 12개 인자는 0, 0, 0, 0.8, 0.2, 0, 0, 0, 0, 0, 0, 0가 된다. 이 인자들의 의미는 주어진 날짜(4월 20일)가 4월에 해당되는 날짜이지 만, 5월에 인접해있는 날짜이므로, 4월에 해당하는 4번째 인자는 0.8, 5월에 해당하는 5번째 인자는 0.2 로 설정하여 날짜의 연속성 및 미세먼지의 계절적 추이를 표현한 것이다.
위에서 기술한 Julian 예보모델에 2차 데이터인 아 노말리, 역 궤적, 기여도, 코사인 유사도를 학습 인자 로 추가한 모델들의 개요를 Table 4에 기술하고, 예 보 모델별 네트워크 파라메타는 Table 5에 제시했다.
Fig. 5. Proposed DNN architecture.
Table 3. Julian forecast model
Time Kind Data
T5 Observation data(14)
Weather U, V, Pressure, Temperature, Dew point temperature, Relative humidity, Precipitation, Solar radiation
Air quality PM
2.5, O
3, NO
2, CO, SO
2, PM
10T#
(#:6∼15) Forecast data(16)
Air quality CASE4_PM
10Weather
Temperature, Pressure, Relative humidity, Mixed highs, U, V, Geopotential height_850hpa, Pressure_850hpa,
U_850hpa, V_850hpa, Relative humidity_850hpa, Temperature_
850hpa, Geopotential height_925hpa, U_925hpa, V_925hap, Temperature difference_850-925
T#
(#:6∼15) Date(12) Julian: 12 factor expressed by the Julian membership function
A는 아노말리 변수 8개를 사용, BT는 역 궤적 인자 5개를 사용, CB는 20개 권역의 기여도 20개를 사용, CS는 8개의 코사인 유사도 변수를 사용, ALL은 모 든 2차 변수를 학습인자로 적용한 모델이다.
4. 실험 결과 및 고찰
4.1 성능평가 도구
제안한 예보 모델의 성능을 평가하기 위해서 U.S.
EPA의 O3와 PM2.5의 모델링 정합도 분석을 위한 지 침[17]을 참고했다. 이 지침의 통계항목 중 MBIAS (Mean Bias), NMB(Mormalized Mean Bias), IOA (Index Of Agreement)를 사용하고, R(Correlation Coefficient)을 분석도구로 추가했다. 각 통계 항목의 상세 수식은 식 (2)∼(5)에 기술했다.
MBIAS N
N Model Obs
(2)
NMB
NObs
NModel Obs
×
(3)IOA
N
Model Obs
Obs Obs
NModel Obs
(4)
R Model Model Model Model ×Obs
× Obs Obs Obs
(5)또한, 현 미세먼지 예보가 지수 예보로 시행되기 때문에 적중률, 감지확률, 오경보율 등의 지수 평가 도구를 사용했다. 적중률(Accuracy)는 전체 예보 성 능을 평가하고, 감지확률(POD: Probability of De- tection)은 고농도 성능을 평가하며, 오경보율(FAR:
False Alarm Rate)는 잘못 예보된 고농도 비율을 분 석하는 도구이다. 자세한 내용은 Fig. 6에 기술했다.
통합 대기환경지수는 대기오염도에 따른 인체 영 향 및 체감오염도를 고려하여 개발된 표현방식으로 좋음(1), 보통(2), 나쁨(3), 매우 나쁨(4)로 구분되며, PM10 지수구간 범위는 Table 6에 나타냈다.
4.2 실험 결과
본 연구에서는 서울 권역의 3일(D+0, D+1, D+2) PM10 예보를 위해서 Julian, A, BT, CB, CS, ALL 예보모델을 개발했다. 실험에 사용된 데이터는 서울 권역의 2015년∼2018년 기간의 6시간 평균 데이터로 2015년 01월 01일에서 2017년 12월 31일까지는 학습 에 사용하고 2018년 데이터는 평가에 사용했다.
Table 7에 2차 데이터를 활용한 5개의 예보모델과 비교 대상인 수치모델 CASE04의 예보 결과를 나타
Table 4. Forecast models using 2 th data
Model Number of inputs Model features
A (Anomaly) 50 Julian(42) + A(8)
BT (Back Trajectory) 47 Julian(42) + BT(5)
CB (Contribution) 62 Julian(42) +CB(20)
CS (Cosine Similarity) 50 Julian(42) + CS(8)
ALL 83 Julian(42) + A(8) + CB(20) + CS(8) + BT(5)
Table 5. Network parameter of forecast models
Model Input
layer Hidden
layer1 Hidden
layer2 Hidden
layer3 Hidden
layer4 Output
layer Learning rate
Julian 42 21 10 5 2 1 0.009
A 50 25 12 6 3 1 0.009
BT 47 23 11 5 2 1 0.009
CB 62 31 15 7 3 1 0.009
CS 50 25 12 6 3 1 0.009
ALL 83 41 20 10 5 1 0.009
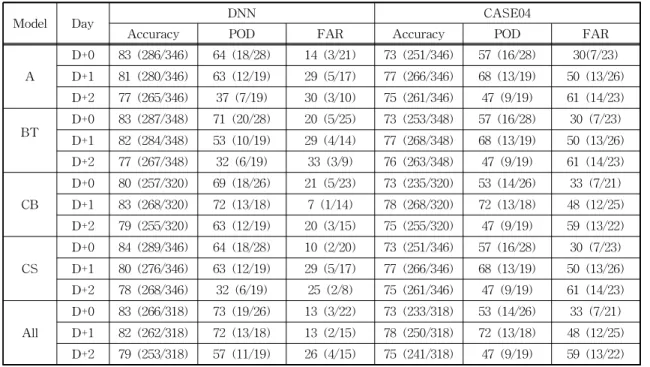
냈다. 기존모델인 CASE04와 5개의 예보모델의 동등 한 비교를 위해서 예보 결과를 같은 행에 기술했는 데, 세 번째 열인 DNN에는 개발한 각 예보모델의 결과를 표기하고, 네 번째 열인 CASE04에는 수치모 델 CASE04의 예보 결과를 나타냈다. Table 7의 각 셀 안에는 2줄의 수치가 표기 되어 있는데, 첫 번째 줄은 Fig. 7에 제시한 성능 평가 도구에 의해 백분율 로 표기된 예보 결과이고, 두 번째 줄의 수치는 전체 패턴수와 예보 모델의 평가결과에 의한 패턴 수를
나타낸 것이다. 예를 들어, A 모델과 CASE04의 D+0 예보 결과를 기술한 두 번째 행을 보면 A의 Accuracy 는 전체 평가 패턴 346개 중에 286개를 적중해서 83
%, 동일한 평가 패턴에 대한 CASE04의 결과는 346 개의 평가 패턴 중에 251개를 적중해서 73%의 지수 적중률을 갖는다는 의미이다. 각 모델별로 동일한 평 가 기간의 자료를 대상으로 평가했음에도평가 패턴 수의 차이가 나는 것은 일부 인자의 결측으로 인해 해당 평가 패턴을 사용하지 못했기 때문이다. POD
Fig. 6. Julian membership function.
Level Prediction value
1 2 3 4
Observation value
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
4 a4 b4 c4 d4
Ⅰ: , Ⅱ: , Ⅲ: , Ⅳ:
Evaluation item Equation
A: Accuracy N
a b c d
×
POD: Probability of Detection III IV IV ×
FAR: False Alarm Rate II IV
II ×
Fig. 7. Items and methods for evaluating the performance of the forecast model.
Table 6. Integrated Air Quality Index of PM
10level 1 2 3 4
Min Max Min Max Min Max -
PM
10(μg/㎥) 0 30 31 80 81 150 151 or more
의 경우도 Accuracy와 마찬가지로 전체 고농도 평가 패턴 수에 대해 각 예보모델이 적중한 고농도 패턴의 수와 백분율을 기술했다. FAR은 ‘/’를 기준으로 왼쪽 수치가 예보 결과 고농도로 평가한 패턴 중 실제 측 정은 저농도인 패턴의 개수이고, 오른쪽 수치가 예보 결과 고농도로 평가된 패턴의 수이므로 각 예보모델 별로 수치가 상이할 수 있다.
제안한 A, BT, CB, CS 예보모델들과 기존 모델인 CASE04의 결과를 비교해보면 지수적중률과 오경보 율은 전반적으로 제안한 예보 모델들이 우수하나, D+1과 D+2의 감지확률의 성능이 떨어지는 경향을
보인다. 이에 반해 모든 2차 데이터를 학습에 사용한 All 모델은 모든 성능 평가 지표에 있어서 CASE04 보다 우수하다.
Table 8에는 1차 데이터를 사용한 예보모델 중 가 장 좋은 성능을 보인 Julian 모델과 2차 데이터를 사 용한 모델 중 가장 좋은 성능을 보인 All 모델, 기존 수치 모델인 CASE04를 상호 비교한 결과를 기술했 다. Julian 예보모델은 지수적중률과 오경보율은 우 수하나 감지확률이 D+1 이상의 구간에서 50%이하 로 성능이 떨어진다. 이를 개선하기 위해서 2차 데이 터를 학습인자로 추가한 모델 중 베스트 모델인 ALL
Table 7. PM
10prediction results of model using secondary data (unit: %)
Model Day DNN CASE04
Accuracy POD FAR Accuracy POD FAR
A
D+0 83 (286/346) 64 (18/28) 14 (3/21) 73 (251/346) 57 (16/28) 30(7/23) D+1 81 (280/346) 63 (12/19) 29 (5/17) 77 (266/346) 68 (13/19) 50 (13/26) D+2 77 (265/346) 37 (7/19) 30 (3/10) 75 (261/346) 47 (9/19) 61 (14/23)
BT D+0 83 (287/348) 71 (20/28) 20 (5/25) 73 (253/348) 57 (16/28) 30 (7/23) D+1 82 (284/348) 53 (10/19) 29 (4/14) 77 (268/348) 68 (13/19) 50 (13/26) D+2 77 (267/348) 32 (6/19) 33 (3/9) 76 (263/348) 47 (9/19) 61 (14/23)
CB
D+0 80 (257/320) 69 (18/26) 21 (5/23) 73 (235/320) 53 (14/26) 33 (7/21) D+1 83 (268/320) 72 (13/18) 7 (1/14) 78 (268/320) 72 (13/18) 48 (12/25) D+2 79 (255/320) 63 (12/19) 20 (3/15) 75 (255/320) 47 (9/19) 59 (13/22)
CS
D+0 84 (289/346) 64 (18/28) 10 (2/20) 73 (251/346) 57 (16/28) 30 (7/23) D+1 80 (276/346) 63 (12/19) 29 (5/17) 77 (266/346) 68 (13/19) 50 (13/26) D+2 78 (268/346) 32 (6/19) 25 (2/8) 75 (261/346) 47 (9/19) 61 (14/23)
All
D+0 83 (266/318) 73 (19/26) 13 (3/22) 73 (233/318) 53 (14/26) 33 (7/21) D+1 82 (262/318) 72 (13/18) 13 (2/15) 78 (250/318) 72 (13/18) 48 (12/25) D+2 79 (253/318) 57 (11/19) 26 (4/15) 75 (241/318) 47 (9/19) 59 (13/22)
Table 8. Comparison of PM
10prediction results of existing model and All (unit: %)
Model Day Accuracy POD FAR
Julian
D+0 84 (290/347) 70 (19/28) 5 (1/20)
D+1 81 (282/347) 50 (9/18) 10 (1/10)
D+2 75 (259/347) 32 (6/19) 25 (2/8)
ALL
D0 83 (266/318) 73 (19/26) 13 (3/22)
D1 82 (262/318) 72 (13/18) 13 (2/15)
D2 79 (253/318) 57 (11/19) 26 (4/15)
CASE04 D+0 73 (233/318) 53 (14/26) 33 (7/21)
D+1 78 (250/318) 72 (13/18) 48 (12/25)
D+2 75 (241/318) 47 (9/19) 59 (13/22)
모델은 지수적중률, 감지확률, 오경보율 모두 수치모 델인 CASE04보다 우수하고, 지수적중률은 83%(D+
0), 82%(D+1), 79%(D+2)로 전 예보구간 좋은 성능을 보인다. 오경보율은 13%(D+0), 13%(D+1), 26%(D+
2)로 모든 예보구간에서 30% 이하로 우수하고, 감지 확률은 73%(D+0), 72(D+1) 57%(D+2)로 D+2예보 성능이 떨어지나, 예보에 있어서 가장 중요한 구간인 D+1의 성능이 우수하다.
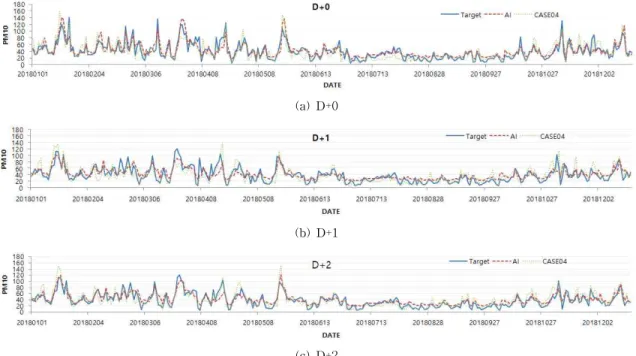
Table 9에는 개발된 예보모델 중 가장 좋은 성능 을 보이는 ALL 모델의 통계평가 결과를 나타냈고, Fig. 8에는 ALL 모델과 수치모델인 CASE04의 시계 열, Fig. 9에는 ALL 모델과 CASE04의 산포도를 제 시했다. Fig. 9에서 (a),(c),(e)의 가로축은 ALL 예보 모델, (b),(d),(f)의 가로축은 CASE04 수치 모델, 세 로축은 PM10측정값을 나타낸다. 제안한 ALL 모델
과 수치모델인 CASE04를 산포도와 시계열 그래프 상에서 비교해 보면 CASE04에서 과 평가(over pre- diction)된 패턴들이 ALL 모델에서는 상당부분 감소 한 것을 확인할 수 있다. 이것은 ALL 모델이 수치모 델의 문제점인 감지확률과 오경보율이 같이 상승하 는 문제를 개선하여 감지확률이 향상되면서도 오경 보율은 감소되는 신뢰도 높은 고농도 예보 결과를 보이는 것을 알 수 있다.
5. 결 론
본 논문에서는 서울 권역 PM10의 3일 예보(D+0, D+1, D+2)를 위해서 6가지 예보모델을 개발했다. 먼 저 1차 데이터를 사용한 Julian 예보모델이 그 중 하 나이다. Julian 예보모델은 지수적중률과 오경보율 은 우수했으나, D+1 이상의 감지확률은 성능이 떨어 졌다. 이점을 개선하기 위해 Julian 예보모델에 고농 도와 상관성을 반영하여 생성한 아노말리, 역궤적, 기여도, 코사인 유사도 등의 2차 데이터들을 추가한 예보모델인 A, BT, CB, CS, ALL을 개발했다. 그 중 ALL 모델이 지수적중률 83%(D+0), 82%(D+1), 79%
(D+2)이고, 감지확률이 73%(D+0), 72%(D+1), 57%
(D+2)이며, 오경보율은 13%(D+0), 13%(D+1), 26%
Table 9. Statistical evaluation result of ALL (Seoul re- gion)
Day MBIAS NMB IOA R
D+0 2.84 7.09 0.92 0.86
D+1 3.62 9.42 0.91 0.87
D+2 3.09 7.99 0.87 0.81
(a) D+0
(b) D+1
(c) D+2
Fig. 8. Time series for ALL and CASE04 (Seoul region).
(a) All(D+0) (b) CASE04(D+0)
(c) All(D+1) (d) CASE04(D+1)
(e) All(D+2) (f) CASE04(D+2)
Fig. 9. Scatter of ALL and CASE04(Seoul region).
(D+2)로 가장 우수한 결과를 보였다. 이는 학습에 추 가한 2차 데이터들이 고농도와의 상관성을 잘 반영 한 결과로 고농도의 미세먼지가 장기간 정체되는 현 재의 미세먼지의 추이를 볼 때, 고농도 예보에 적합 한 모델임을 알 수 있다.
향후 미세먼지 예보의 성능을 더욱 향상시키기 위 한 연구로 예보에 동아시아 광역 데이터를 사용하는 방안과 오버피팅(overfitting) 문제를 개선하기 위한 연구가 필요할 것으로 보인다.
REFERENCE
[ 1 ] NIER,A Study of Construction of Air Quality Forecasting System using Artificial Intelli- gence (I), NIER-SP2017-148, 11-1480523- 0003221-01, 2017.
[ 2 ] L.G. McKendry, “Evaluation of Artificial Neural Networks for Fine Particulate Pollu- tion(PM10 and PM2.5) Forecasting,” Journal of the Air and Waste Management Association, Vol. 52, No. 9, pp. 1096-1101, 2002.
[ 3 ] D. Voukantsis, K. Karatzas, J. Kukkonen, T.
Rasanen, A. Karppinen, and M. Kolehmainen,
“Intercomparison of Air Quality Data Using Principal Component Analysis, and Forecast- ing of PM10 and PM2.5Concentrations Using Artificial Neural Network, in Thessaloniki and Helsinki,”Science of the Total Environment, Vol. 409, No. 7, pp. 1266-1276, 2011.
[ 4 ] H. Zhang, Y. Liu, R. Shi, and Q. Yao, “Evalu- ation of PM10 Forecasting Based on the Artificial Neural Network Model and Intake Fraction in an Urban Area: A Case Study in Taiyuan City, China,”J ournal of the Air and Waste Management Association, Vol. 63, No.
7, pp. 755-763, 2013.
[ 5 ] S. Thomas and R.B. Jacko, “Model for Fore- casting Expressway Fine Particulate Matter and Carbon Monoxide Concentration: Appli- cation of Regression and Neural Network Models,”Journal of the Air and Waste Mana- gement Association, Vol. 58, No. 4, pp. 480- 488, 2012.
[ 6 ] F. Franceschi, M. Cobo, and M. Figueredo,
“Discovering Relationships and Forecasting PM10 and PM2.5 Concentrations in Bogota, Colombia, Using Artificial Neural Networks, Principal Component Analysis, and K-mean Clustering,”Atmospheric Pollution Research, Vol. 9, Issue 5, pp. 912-922, 2018.
[ 7 ] S. Park, M. Kim, M. Kim, H. Namgung, K.
Kim, K. Cho, et al, “Predicting PM10 Concen- tration in Seoul Metropolitan Subway Stations Using Artificial Neural Network (ANN),”
Journal of Hazardous Materials, Vol. 341, pp.
75-82, 2018.
[ 8 ] G.D. Gennaro, L. Trizio, A.D. Gilio, J. Pey, N.
Perez, M. Cusack, et al, “Neural Network Model for The Prediction of PM10 Daily Concentrations in Two Sites in The Western Mediterranean,”Science of The Total Envir- onment, Vol. 463-464, pp. 875-883, 2013.
[ 9 ] Y. Bai, Y. Li, X. Wang, J. Xie, and C. Li, “Air Pollutants Concentrations Forecasting Using Back Propagation Neural Network Based on Wavelet Decomposition with Meteorological Condition,”Atmospheric Pollution Research, Vol. 7, Issue 3, pp. 557-566, 2016.
[10] X. Feng, Q. Li, J. Hou, L. Jin, and J. Wang,
“Artificial Neural Networks Forecasting of PM2.5 Pollution Using Air Mass Trajectory Based Geographic Model and Wavelet Trans- formation,” Atmospheric Environment, Vol.
107, pp. 118-128, 2015.
[11] B.S. Freeman, G. Taylor, B. Gharabaghi, and J. The, “Forecasting Air Quality Time Series Using Deep Learning,”Journal of the Air and Waste Management Association, Vol. 68, No.
8, pp. 866-886, 2018.
[12] F. Biancofiore, M. Busilacchio, M. Verdecchia, B. Tomassetti, E. Aruffo, et al, “Recursive Neural Network Model for Analysis and Fore- cast of PM10and PM2.5,”Atmospheric Pollu- tion Research, Vol. 8, Issue 4, pp. 652-659, 2017.
[13] W. Lu, W. Wang, X. Wang, S. Yan, and J.C.
Lam, “Potential Assessment of A Neural Net- work Model with PCA/RBF Approach for Forecasting Pollutant Trends in Mong Kok Urban Air, Hong Kong,”Environmental Res- earch, Vol. 96, No. 1, pp. 79-87, 2004.
[14] J. Fan, Q. Li, J. Hou, X. Feng, H. Karimian, and S. Lin, “A Spatiotemporal Prediction Framework for Air Pollution Based on Deep RNN,” P roceeding of ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume IV-4/W2, 2017 2nd International Symposium on Spatiotem- poral Computing, pp. 15-22, 2017.
[15] S. Yu, Y. Koo, and H. Kwon, “Inverse Model Parameter Estimation Based on Sensitivity Analysis for Improvement of PM10Forecast- ing,” J ournal of Korea Multimedia Society, Vol. 18, No. 7, pp. 886-894, 2015.
[16] H. Bae, S. Yu, and H. Kwon, “Fast Data Assi- milation using Kernel Tridiagonal Sparse Matrix for Performance Improvement of Air Quality Forecasting,”Journal of Korea Mul- timedia Society, Vol. 20, No. 2, pp. 363-370, 2017.
[17] EPA, Guidance on the Use of Models and Other Analyses for Demonstrating Attain- ment of Air Quality Goals for Ozone, P M2.5, and Regional Haze, EPA-454/B-07-002, 2007.
[18] S. Hur, H. Oh, C. Ho, J. Kim, C. Song, and L. Chang, et al, “Evaluating the Predictability of PM10grades in Seoul, Korea Using a Neural Network Model Based on Synoptic Patterns,”
Environmental P ollution, Vol. 218, pp. 1324- 1333, 2016.
유 숙 현
1999년 안양대학교 컴퓨터공학과 학사
2002년 안양대학교 컴퓨터공학과 석사
2011년 안양대학교 컴퓨터공학과 박사
2012년∼현재 안양대학교 정보통신공학과 조교수 관심분야 : 패턴인식, 신경망, 영상처리, 병렬처리응용,
딥러닝
전 영 태