2019, 30
(6)
,1277–1287
낙동강 유역의 SPI 예측을 위한 심층신경망 개발 및 검증
†ᄎ
ᅬ영태1·이경은2· 김광섭3
12경북대학교 통계학과 ·3경북대학교 토목공학과
ᄌ ᅥ
ᆸᄉ ᅮ 2019ᄂ ᅧ ᆫ 10ᄋ ᅯ ᆯ 31ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 11ᄋ ᅯ ᆯ 15ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 11ᄋ ᅯ ᆯ 15ᄋ ᅵ ᆯ
요 약
ᄇ
ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥ, ᄂ ᅡ ᆨᄃ ᅩ ᆼ ᄀ ᅡ ᆼ ᄋ ᅲᄋ ᅧ ᆨᄋ ᅴ SPI6ᄅ ᅳ ᆯ ᄋ ᅨᄎ ᅳ ᆨ ᄒ ᅡᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄆ ᅩᄒ ᅧ ᆼ ᄌ ᅮ ᆼ ᄒ ᅡᄂ ᅡᄋ ᅵ ᆫ ᄃ ᅡᄎ ᅳ ᆼ ᄑ ᅥᄉ ᅦ ᆸᄐ ᅳᄅ ᅩ ᆫ (MLP;
multilayer perceptron)ᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼᄒ ᅢ ᆻᄃ ᅡ. ᄋ ᅯ ᆯᄇ ᅧ ᆯ ᄑ ᅭᄌ ᅮ ᆫ ᄀ ᅡ ᆼᄉ ᅮᄌ ᅵᄉ ᅮ, ᄀ ᅵᄋ ᅩ ᆫ, ᄀ ᅵᄋ ᅩ ᆫ ᄑ ᅧ ᆼᄂ ᅧ ᆫᄀ ᅡ ᆹ, ᄀ ᅡ ᆼᄉ ᅮᄅ ᅣ ᆼ, ᄀ ᅡ ᆼᄉ ᅮ ᄑ ᅧ ᆼᄂ ᅧ ᆫ ᄀ ᅡ ᆹ, ᄀ
ᅡ ᆼᄉ ᅮᄋ ᅵ ᆯᄉ ᅮ, ᄀ ᅳᄅ ᅵᄀ ᅩ ᄋ ᅧᄅ ᅥᄀ ᅡᄌ ᅵ ᄉ ᅦᄀ ᅨᄀ ᅵᄒ ᅮᄌ ᅵᄉ ᅮᄅ ᅳ ᆯ ᄉ ᅥ ᆯᄆ ᅧ ᆼ ᄇ ᅧ ᆫᄉ ᅮᄅ ᅩ ᄉ ᅡᄋ ᅭ ᆼᄒ ᅢ ᆻᄋ ᅳᄆ ᅧ, ᄎ ᅬᄌ ᅥ ᆨᄋ ᅴ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄎ ᅡ ᆽᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄃ ᅮ ᄀ ᅡ ᄌ
ᅵᄋ ᅴ ᄒ ᅪ ᆯᄉ ᅥ ᆼᄒ ᅡ ᆷᄉ ᅮ, ᄂ ᅦ ᄀ ᅡᄌ ᅵᄋ ᅴ ᄋ ᅳ ᆫᄂ ᅵ ᆨᄎ ᅳ ᆼᄇ ᅧ ᆯ ᄂ ᅲᄅ ᅥ ᆫ ᄉ ᅮ, ᄃ ᅡᄉ ᅥ ᆺ ᄀ ᅡᄌ ᅵ ᄌ ᅮ ᆼ ᄃ ᅩᄐ ᅡ ᆯᄅ ᅡ ᆨ ᄇ ᅵᄋ ᅲ ᆯ (dropout rate), ᄃ ᅡᄉ ᅥ ᆺ ᄀ ᅡᄌ ᅵ ᄋ ᅳ ᆫ ᄂ ᅵ
ᆨᄎ ᅳ ᆼ ᄉ ᅮ, ᄃ ᅮ ᄀ ᅡᄌ ᅵ ᄉ ᅩ ᆫᄉ ᅵ ᆯ ᄒ ᅡ ᆷᄉ ᅮᄅ ᅳ ᆯ ᄀ ᅩᄅ ᅧᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄆ ᅩᄒ ᅧ ᆼ ᄑ ᅧ ᆼᄀ ᅡ ᄀ ᅵᄌ ᅮ ᆫ ᄋ ᅳᄅ ᅩ ᄀ ᅥ ᆷᄌ ᅳ ᆼᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄌ ᅦᄀ ᅩ ᆸ ᄋ ᅩᄎ ᅡ (validation mean square error)ᄅ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄀ ᅡᄌ ᅡ ᆼ ᄌ ᅩ ᇂᄋ ᅳ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄎ ᅡ ᆽᄀ ᅩᄌ ᅡ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. SPI6ᄅ ᅳ ᆯ ᄋ ᅨᄎ ᅳ ᆨ ᄒ ᅡ ᆷᄋ ᅦ ᄋ ᅵ ᆻᄋ ᅥᄉ ᅥ, L
1ᄌ ᅥ ᆼᄀ ᅲᄒ ᅪᄅ ᅳ ᆯ ᄌ
ᅥ
ᆨᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅵ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄌ ᅵ ᄋ ᅡ ᆭᄋ ᅳ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄇ ᅩᄃ ᅡ ᄀ ᅥ ᆷᄌ ᅳ ᆼᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄌ ᅦᄀ ᅩ ᆸ ᄋ ᅩᄎ ᅡ (validation mean square error)ᄀ ᅡ ᄒ ᅡ ᆼᄉ ᅡ ᆼ ᄃ
ᅥ ᄂ ᅡ ᆽᄋ ᅡ ᆻᄋ ᅳᄆ ᅧ, ᄃ ᅢᄇ ᅮᄇ ᅮ ᆫ ᄋ ᅴ ᄌ ᅵᄋ ᅧ ᆨᄋ ᅦᄉ ᅥ ᄋ ᅳ ᆫᄂ ᅵ ᆨᄎ ᅳ ᆼ ᄉ ᅮᄀ ᅡ ᄌ ᅥ ᆨᄋ ᅳ ᆯ ᄉ ᅮᄅ ᅩ ᆨ ᄀ ᅥ ᆷᄌ ᅳ ᆼᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄌ ᅦᄀ ᅩ ᆸ ᄋ ᅩᄎ ᅡ (validation mean square error)ᄀ ᅡ ᄃ ᅥ ᄂ ᅡ ᆽᄋ ᅳ ᆫ ᄀ ᅧ ᆼᄒ ᅣ ᆼᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄀ ᅥ ᆷᄌ ᅳ ᆼᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄌ ᅦᄀ ᅩ ᆸ ᄋ ᅩᄎ ᅡ, ᄃ ᅡᄎ ᅳ ᆼ ᄑ ᅥᄉ ᅦ ᆸᄐ ᅳᄅ ᅩ ᆫ, ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄆ ᅩᄒ ᅧ ᆼ, ᄋ ᅳ ᆫᄂ ᅵ ᆨᄎ ᅳ ᆼ ᄉ ᅮ, ᄉ ᅩ ᆫᄉ ᅵ ᆯ ᄒ ᅡ ᆷᄉ ᅮ, L
1ᄌ ᅥ ᆼᄀ ᅲᄒ ᅪ, SPI6.
1. 서론 ᄀ
ᅡ뭄은 일종의 자연재해로, 수 개월 혹은수 년에 걸쳐 물 공급이 부족한 상황을 일컫는다. 가뭄의 영 ᄒ
ᅣᆼ을 받은지역에서는 생태계와 농업에 막대한 피해가 있을수 있고, 더 나아가서 지역 경제에 피해를 ᄁ
ᅵ칠 수 있다. 실제 미국에서 가뭄으로 인한 피해 비용추정치가 매년 6-80억 달러에 이르고, 유럽에서 느
ᆫ 53억 유로에 이르는것으로 추산된다. 중국에서는 가뭄이 가장 피해가 많은자연재해이며, 한국 또 ᄒ
ᅡᆫ 지리적으로 여름에 극단적으로 비가 많고, 봄, 가을에는 극단적으로 비가 적어서 가뭄에 더 민감한 겨
ᆼ향이 있다. 따라서 가뭄의 피해를 줄이기 위한 여러가지 방법들이 모색되고 있는데, 가뭄의 정확한 예 ᄎ
ᅳ
ᆨ은효과적인 가뭄모니터링 시스템과 효율적인완화 전략 개발에 중요한 요소이다. 가뭄예측은가뭄 ᄋ
ᅳ로 인한 피해에 더 빠르고 정확하게 대응할 수 있게 해주며, 자원을효과적으로 할당할 수 있게 도와 ᄌ
ᅮ기 때문에 가뭄비용을 줄이는데 중요한 역할을수행한다. 기상, 수자원, 농업, 사회분야에서 상대적 ᄋ
ᅳ로 간단한 지수부터 매우 복잡한 지수 등여러 형태의 가뭄지수가 개발되어왔으나 계산과정과 사용성 ᄋ
ᅦ 있어서 간단하면서도 물리적 설득력을가지는지수가 요구되고 있다. 이러한 필요를 충족시키는 대 ᄑ
ᅭ적 가뭄지수로서 강수량만을 입력자료로 활용하여 평년값에 비하여 당월 누적강수량의 확률적 위치 르
ᆯ나타내고 단기, 중기, 장기 가뭄의 심도를유연하게 나타낼 수 있는 SPI (standardized precipitation
†
ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ ᄒ ᅪ ᆫᄀ ᅧ ᆼᄇ ᅮ/ᄒ ᅡ ᆫᄀ ᅮ ᆨᄒ ᅪ ᆫᄀ ᅧ ᆼᄉ ᅡ ᆫᄋ ᅥ ᆸᄀ ᅵᄉ ᅮ ᆯᄋ ᅯ ᆫ ᄋ ᅴ ᄌ ᅵᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ (ᄀ ᅪᄌ ᅦᄇ ᅥ ᆫᄒ ᅩ 83067).
1
(41566) ᄃ ᅢᄀ ᅮᄉ ᅵ ᄇ ᅮ ᆨ ᄀ ᅮ ᄉ ᅡ ᆫᄀ ᅧ ᆨᄃ ᅩ ᆼ ᄃ ᅢᄒ ᅡ ᆨᄅ ᅩ 80, ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅡ ᆨᄉ ᅡᄀ ᅪᄌ ᅥ ᆼ.
2
(41566) ᄃ ᅢᄀ ᅮᄉ ᅵ ᄇ ᅮ ᆨ ᄀ ᅮ ᄉ ᅡ ᆫᄀ ᅧ ᆨᄃ ᅩ ᆼ ᄃ ᅢᄒ ᅡ ᆨᄅ ᅩ 80, ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅮᄀ ᅭᄉ ᅮ.
3
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (41566) ᄃ ᅢᄀ ᅮᄉ ᅵ ᄇ ᅮ ᆨ ᄀ ᅮ ᄉ ᅡ ᆫᄀ ᅧ ᆨᄃ ᅩ ᆼ ᄃ ᅢᄒ ᅡ ᆨᄅ ᅩ 80, ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩᄆ ᅩ ᆨᄀ ᅩ ᆼ ᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
Index)가 개발되었다 (McKee 등, 1993). SPI지수 개발 이후, 이를적용한 가뭄 분석과 예측연구가 전 ᄉ
ᅦ계적으로 많이 이루어지고 있다 (Ali 등, 2019; Bonaccorso 등, 2015; Wu 등, 2007).
ᄇ
ᅩᆫ 연구에서는 가뭄지수 중 하나인 SPI6를 예측하는 심층신경망 모형 개발에 그 목적을 둔다. 예측 ᄇ
ᅧᆫ수로는 23개의 세계기후지수 (Table 3.1 참고)를사용하였으며, 추가적으로 월별 표준강수지수, 기온, ᄀ
ᅵ온 평년값, 강수량, 강수 평년값, 강수일수 또한 사용하였다. 제 2절에서는 인공 신경망의 한 종류인 ᄃ
ᅡ층퍼셉트론에 대한 내용을, 제 3절에서는 본연구에서 사용한 자료와 모형 적용방법에관한 정리, 그 ᄅ
ᅵ고 그 결과들을서술하고 있으며, 제 4절은결론으로, 전체적인 내용을정리하고 있다.
2. 심층신경망 모형 보
ᆫ 연구에서는 인공 신경망의 한 종류인 다층 퍼셉트론 (multilayer perceptron; MLP)을사용하였 ᄃ
ᅡ. 다층퍼셉트론은 입력층 (input layer)과 출력층 (output layer)사이에 하나 이상의 은닉층 (hidden layer)을 가지는 구조로, 단층 퍼셉트론과 다르게 배타적 논리합 (exclusive or; XOR) 함수를 학습할 ᄉ
ᅮ 있는 등 더 좋은 성능을 낸다는 사실이 알려져 있다 (Minsky and Papert, 1988). 은닉층이 하나 ᄋ
ᅵᆫ 다층 퍼셉트론을 바닐라 신경망 (vanilla neural networks)이라고 부르기도 한다. 은닉층과 출력층 ᄋ
ᅳ
ᆫ여러 개의 인공뉴런 (artificial neuron)이라고 하는간단한 연산기능을갖는처리기로 이루어져 있는 ᄃ
ᅦ, 이 인공뉴런의 자세한 기능은다음과 같다. 단순히 입력된신호 x = (x1, x2, . . . , xn)를연결가중치 w = (w0, w1, w2, . . . , wn)와 내적한 다음,그 결과에 비선형 함수 f를취하는것이다. 즉, 출력 y의 값 ᄋ
ᅳ
ᆫ다음과 같은 식 2.1에 의해 계산된다.
y = f w0+
n
X
i=1
wi· xi
!
, (2.1)
ᄋ
ᅵ 때 동일한 입력 x를 가했을때의 출력은 w에 따라 다른값이된다. 따라서 정보는 바로 연결 가중 ᄎ
ᅵ 벡터 w에 저장된다고 볼수 있다. 또한, f 는활성함수 (activation function)라고 하며, 일반적으로 ᄇ
ᅵ선형 함수를사용한다. 만일 다층퍼셉트론의활성함수가 모두 선형이라면, 선형대수에 의해서 어떤 ᄃ
ᅡ층퍼셉트론도 2층의 입력-출력 모형 (two-layer input-output model)으로 축약될수 있으므로, 선형 ᄒ
ᅡᆷ수를 사용할 경우, 선형회귀분석과 같은 결과를 얻게 된다. 대중적인 활성함수로는 렐루 (Rectified linear unit; ReLU),시그모이드 함수 (sigmoid function), 하이퍼볼릭 탄젠트 함수 (hyperbolic tangent function)와 맥스아웃 (maxout)이 있으며, 이들 중몇 가지의 자세한 내용은다음과 같다.
• 렐루 (rectified linear unit; ReLU)
f (x) = max(0, x), (2.2)
• 시그모이드 함수 (sigmoid function)
f (x) = 1
1 + e−x, (2.3)
• 하이퍼볼릭 탄젠트 함수 (hyperbolic tangent function)
f (x) = ex− e−x
ex+ e−x, (2.4)
• 맥스아웃 (maxout)
f (x1, x2, . . . , xk) = max
j∈J xj, J = {1, 2, . . . , k}, (2.5)
• 아크탄젠트 (arctangent function)
f (x) = tan−1(x), (2.6)
• 리키 렐루 (leaky rectified linear unit; leaky ReLU)
f (x) = max(0.01x, x). (2.7) 보
ᆫ연구에서는이 중성능은다른활성함수에 비해 크게 뒤쳐지지 않으나 학습 속도가 비교적 빠르다 ᄀ
ᅩ 알려진 두 가지 활성함수인 렐루와 맥스아웃을사용하였다 (Nair와 Hinton, 2010; Goodfellow 등, 2013).
ᄒ
ᅡᆨ습 (learning)이란, 이러한 인공뉴런의 연결가중치를주어진 손실함수 (loss function)에 대해 최적 ᄒ
ᅪ하는과정이다. 다음은 딥러닝에서 흔히 사용하는최적화 방법이다.
• SGD (stochastic gradient descent)
• NAG (Nesterov-accelerated gradient; Yurii Nesterov., 1983)
• Adagrad (adaptive gradient algorithm; John Duchi, 2011)
• Adadelta (adaptive learning rate method; Matthew D. Zeiler., 2012.)
• Adam (adaptive moment estimation; Kingma and Ba, 2014)
• Nadam (Nesterov-accelerated adaptive moment estimation; Timothy Dozat., 2016) 보
ᆫ연구에서는 이들 중하나인 Adam을사용하였다. 이 방법은 그래디언트 (gradient)가 커져도 이동 ᄏ
ᅳ기 (stepsize)에는한계가 있어, 어떤 손실함수를사용한다 하더라도 안정적으로 최적화가 가능하다는 ᄌ
ᅡᆼ점이 있다.
ᄄ
ᅩ한 손실함수는 평균제곱오차 (mean square error; MSE)와 L1 정규화를 사용한 평균제곱오차 (mean square error with L1 regularization)를사용하였다. L1 정규화를 이용하면 인공뉴런의 연결 ᄀ
ᅡ중치 중 일부를 0 혹은 0에 매우 가까운값으로 만들어주게 되므로, 입력된신호 중 일부를고려하지 ᄋ
ᅡ
ᆭ게 되는, 변수선택의 역할을하게된다. 두 평균제곱오차의 수식은다음과 같다.
• 평균제곱오차
L(ˆy) =1
n||y − ˆy||22, (2.8)
• L1정규화를사용한 평균제곱오차
L(ˆy) = 1
n||y − ˆy||22+ λ||w||1. (2.9) ᄋ
ᅵ 때, n은관측치 갯수이고, || · ||p는 Lp-노름 (norm)이다.
보
ᆫ연구에서는각 지역의 현재 시점에 대한 SPI6를 종속변수로, 월별 표준강수지수, 기온,기온평년 ᄀ
ᅡ
ᆹ, 강수량, 강수 평년값, 강수일수, 그리고 여러 가지의 세계기후지수를설명변수로 두었다. 이를 다 ᄎ
ᅳ
ᆼ퍼셉트론을이용하여 분석하였으며,활성함수로는 렐루와 맥스아웃,두 가지를, 은닉층별 뉴런수로는 10, 30, 50과 100, 네 가지를, 중도탈락 비율 (dropout rate)로는 0%, 10%, 30%, 50%, 80%,다섯 가지 르
ᆯ, 은닉층수로는 1, 2, 3, 4, 5다섯가지를, 손실함수로는평균제곱오차와 L1 정규화를사용한 평균제 고
ᆸ오차를각각 적용하여 이들 중최적의 모형을 찾고자 하였다. 세부적인 사항은 3절에서 다루도록 하 게
ᆻ다.
3. 모형 적용 ᄀ
ᅢ발된심층신경망 가뭄예측모형의 적용성을검증하기 위하여 유역 연강수량이 5대강 유역에서 가 ᄌ
ᅡᆼ 작으며 가뭄피해의 발생빈도가 높은낙동강 유역을대상 지역으로 선정하였다. 낙동강 유역에 위치 ᄒ
ᅡᆫ 기상청에서 운영하는 20개 종관기상관측지점에서관측된1974년에서 2018년 강수량 자료를사용하 ᄋ
ᅧ SPI6를산정하였다. 낙동강 유역의 기후지수 자료가 존재하는 24개 지역 중,관측기간이 비교적 짧 ᄋ
ᅳᆫ 4개 지역 (안동, 상주, 마산, 봉화)을제외한 나머지 20개 지역 (울진, 포항, 대구, 울산, 부산, 통영, ᄌ
ᅵᆫ주, 태백, 영주, 문경, 영덕, 의성, 구미, 영천, 거창, 합천, 밀양, 산청, 거제, 남해)에 대해서 분석을 시
ᆯ시하였다.
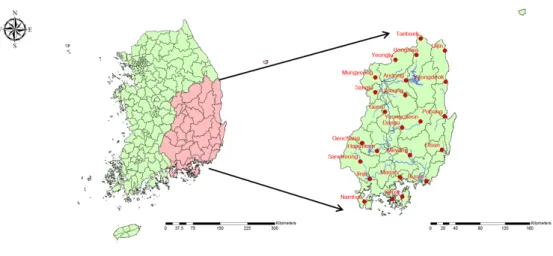
Figure 3.1은 20개 지역을우리나라 지도상에 표시한 것이다. 1974년 1월부터 2017년 6월까지 522개 ᄋ
ᅯ
ᆯ간의 월별 표준강수지수, 기온,기온평년값, 강수량, 강수 평년값, 강수일수, 그리고 여러가지 세계기 ᄒ
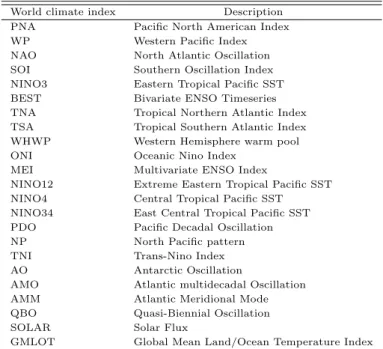
ᅮ지수를사용했으며, Table 3.1은 본연구에 사용한 총 23가지 지수의 세부사항이다. 또한 모형을 평 ᄀ
ᅡ하기 위해 522개월을시간 순으로 105, 105, 104, 104, 104 개월으로 5등분하여 다중교차타당성 방법 으
ᆯ사용하였다.
Figure 3.1 The map for the 20 region. To evaluate the model, we used the Validation Mean Square error as an evaluation standard. in Nakdong River Basin.
보
ᆫ연구에서는각 지역의 현재 시점에 대한 SPI6를 종속변수로 두고, 각 지역별로 월별 표준강수지수, ᄀ
ᅵ온, 기온평년값, 강수량, 강수 평년값, 강수일수, 그리고 여러 가지의 세계기후지수와 같은각 변수들 ᄋ
ᅴ 1개월 전부터 12개월 전까지의관측값을설명변수로 두었다. 이를다층퍼셉트론을이용하여 분석하 ᄋ
ᅧᆻ으며, 활성함수로는 렐루와 맥스아웃, 두 가지를, 은닉 층 별 뉴런수로는 10, 30, 50와 100, 네 가지 르
ᆯ, 중도탈락 비율 (dropout rate)로는 0%, 10%, 30%, 50%, 80%, 다섯 가지를적용한 후 최적 모형을 ᄉ
ᅥᆫ택하고자 하였다. 특히 은닉층수로는 1, 2, 3, 4, 5,다섯 가지를적용하여, 최적의 은닉층수를찾고 ᄌ
ᅡ 하였으며, 손실함수로는평균제곱오차와 L1 정규화를사용한 평균제곱오차를각각 적용하여, L1 정 ᄀ
ᅲ화 적용전과 후의 결과를비교하고, 최적의 모형을찾고자 하였다.
Table 3.2는 20개 지역 중 지역 인구가 많은대표 5개 지역에 대해 각 지역별 400가지 모형 중검증 펴
ᆼ균제곱오차 (validation mean square error)가 가장 작은모형을선택하여 나타낸 표이다. 이 표에 나 ᄐ
ᅡ난 대표지역 외 15개 지역도 모두 고려했을때, L1 정규화를적용한 모형이 항상 최적의 모형으로 선
Table 3.1 23 World climate indices
World climate index Description
PNA Pacific North American Index
WP Western Pacific Index
NAO North Atlantic Oscillation SOI Southern Oscillation Index NINO3 Eastern Tropical Pacific SST
BEST Bivariate ENSO Timeseries
TNA Tropical Northern Atlantic Index TSA Tropical Southern Atlantic Index
WHWP Western Hemisphere warm pool
ONI Oceanic Nino Index
MEI Multivariate ENSO Index
NINO12 Extreme Eastern Tropical Pacific SST NINO4 Central Tropical Pacific SST NINO34 East Central Tropical Pacific SST PDO Pacific Decadal Oscillation
NP North Pacific pattern
TNI Trans-Nino Index
AO Antarctic Oscillation
AMO Atlantic multidecadal Oscillation
AMM Atlantic Meridional Mode
QBO Quasi-Biennial Oscillation
SOLAR Solar Flux
GMLOT Global Mean Land/Ocean Temperature Index
Table 3.2 MLP having the lowest validation MSE in each representative region.
Region Busan Daegu Ulsan Pohang Gumi
Activation function Maxout Maxout Maxout Maxout ReLU
# of neuron in a layer 100 100 100 100 100
Dropout rate 0.5 0.5 0.5 0.5 0.3
# of hidden layers 1 1 1 1 4
L1regularization Applied Applied Applied Applied Applied
MSE 0.2575 0.2573 0.1011 0.2085 0.3938
태
ᆨ됨을알 수 있다.
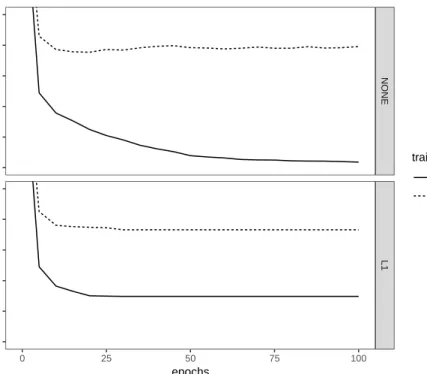
Figure 3.2은 부산지역의 훈련자료 (training data)와 검증자료 (validation data)에 대한 학습반복 ᄉ
ᅮ (epochs)에 따른제곱근평균제곱오차 (root mean square error)에 대한 추적 그림 (trace plot)이다.
ᄉ
ᅡᆼ단은 L1 정규화를적용하지 않은경우이고, 하단은 L1 정규화를적용한 경우이며, 실선은 훈련자료 (training data), 점선은 검증자료 (validation data)의 평균을각각 나타내었다. 이 때, 활성함수로는 매
ᆨ스아웃, 은닉층별 뉴런 수는 100개, 중도탈락비율은 0.5, 은닉층수는 1로 고정하였다. 이 그림에 따 ᄅ
ᅳ면, L1 정규화를적용하지 않은경우, 중도탈락을적용했음에도 불구하고 학습수가 늘어남에 따라 과 ᄌ
ᅥᆨ합 (overfitting)이 일어나고 있으나, L1 정규화를적용한 경우 과적합도 일어나지 않고 검증집합의 최 ᄌ
ᅥᆨ 제곱근평균제곱오차도 L1정규화를적용하지 않은경우보다 더 낮게 나옴을알 수 있다.
Figure 3.3은지역별로 은닉층수와 L1 정규화 적용유무를고정하고활성함수, 은닉층별 뉴런 수, 중 ᄃ
ᅩ탈락비율의 여러 조합 중최적 모형의 제곱근평균제곱오차 선그림이다. 여기서 지속 (persistant)은 ᄋ
ᅵ전 달의 SPI6 값이 다음달에 계속이어진다고 가정 했을때의 값이며, 제곱근평균제곱오차가 이 값보 ᄃ
ᅡ 크면 추론이 아무런 의미가 없으므로 최저 기준으로 사용할 수 있는값이다. 여기서 제시된제곱근평 규
ᆫ제곱오차는 검증자료의 제곱근평균제곱오차이다. 이 선그림을보면 대다수의 지역에서 L1 정규화를
NONEL1
0 25 50 75 100
0.2 0.3 0.4 0.5 0.6 0.7
0.2 0.3 0.4 0.5 0.6 0.7
epochs
RMSE
train
TRAINING VALIDATIONFigure 3.2 RMSE according to epochs for training data and validation data in Busan
0.3 0.4 0.5 0.6 0.7
Persistent H1 H2 H3 H4 H5 H1+L1 H2+L1 H3+L1 H4+L1 H5+L1 Models
RMSE
Busan Daegu
Geochang Geoje
Gumi Hapcheon
Jinju Miryang
Mungyeong Namhae
Persistent H1 H2 H3 H4 H5 H1+L1 H2+L1 H3+L1 H4+L1 H5+L1 Models
Pohang Sancheong
Taebaek Tongyeong
Uiseong Uljin
Ulsan Yeongcheon
Yeongdeok Yeongju
Figure 3.3 The line plot of optimal RMSE according to the number of hidden layers and L1regularization. The number following H means the number of hidden layers, and L1 means L1regularization on the ”Models” axis.
0.4 0.6 0.8 1.0
Persistent H1 H2 H3 H4 H5 H1+L1 H2+L1 H3+L1 H4+L1 H5+L1
Models
RMSE
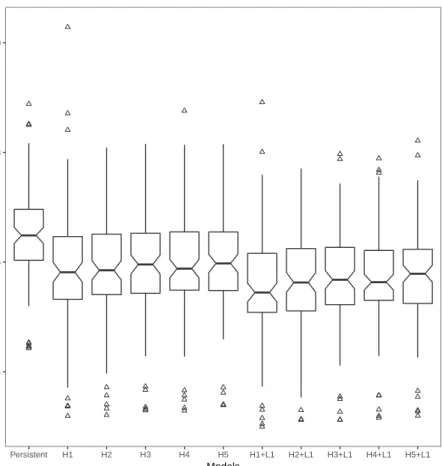
Figure 3.4 The box plot of optimal RMSE according to the number of hidden layers and L1regularization. The number following H means the number of hidden layers, and L1 means L1regularization on the ”Models” axis.
ᄌ ᅥ
ᆨ용시키고 은닉층수가 1개인 모형의 제곱근평균제곱오차가 가장 낮음을 볼수 있다. 또한, L1 정규화 ᄅ
ᅳᆯ적용시킨 모형의 제곱근평균제곱오차가 적용시키지 않은모형보다 낮으며, 은닉층수가 적을수록더 ᄂ
ᅡ
ᆽ음은경향이 있음을알 수 있다.
Figure 3.4는 은닉층수와 L1 정규화 적용유무를고정하고활성함수, 은닉층별 뉴런 수, 중도탈락비 ᄋ
ᅲᆯ의 여러 조합 중최적 모형의 제곱근평균제곱오차에 대한 상자그림이다. 여기서도 마찬가지로 은닉층 ᄉ
ᅮ가 많은모형보다 적은모형이, L1정규화를적용시키지 않은모형보다 적용시킨 모형이 더 낮은제곱 ᄀ
ᅳᆫ평균제곱오차를산출하는경향이 있음을시각적으로 알 수 있다.
Table 3.3은지역별 최적 모형을모형별로 정리한 표이다. 선택된 최종 모형들은모두 L1 정규화가 ᄌ
ᅥ
ᆨ용됨을알 수 있고, 많은지역에서 은닉층 1개인 모형이 선택되었음을알 수 있다.
Table 3.3 Regions and the number of regions by optimal model Model
Regions # of regions
# of hidden layers L1regularization
Busan, Daegu, Mungyeong, Namhae,
1 Applied Pohang, Sancheong, Taebaek, Uiseong, 12
Uljin, Ulsan, Yeongcheon, Yeongju
2 Applied Geochang, Geoje, Hapcheon, Miryang 4
3 Applied Tongyeong, Yeongdeok 2
4 Applied Gumi 1
5 Applied Jinju 1
4. 결론
Figure 4.1 The maps based on regional forecasts. From top, April, May, and June 2017. Three maps on the left are drawn based on actual observed values, and three on the right are drawn based on predicted values.
Month Observed Predicted
April
May
June
ᄀ
ᅡ뭄은서서히 퍼지면서도 시공간적으로큰부정적 영향을미치는자연재해로 현황 파악 및 예측의 정 화
ᆨ도를 높여야 하는요구가 높다. 본연구에서는여러 가뭄지수 중다양한 시간스케일의 가뭄현상을나 ᄐ
ᅡ낼 수 있으며 강수량이란 하나의 변수로 가뭄의 심도를제시하는 SPI에 대한 예측모형을구성하였다.
ᄀ
ᅡ뭄예측모형 구성에 있어 가뭄현상의 비선형적 변화특성을 반영하기 위하여 심층신경망기법을적용하 ᄋ
ᅧᆻ다. 개발된예측모형은 가뭄피해 발생빈도가 우리나라 5대강 유역 중에서 가장 높은 낙동강 유역의 ᄀ
ᅡ뭄예측을 통하여 적용성을검증하였다.
ᄄ
ᅡ라서 본연구에서는 1974년부터 522개월간 낙동강 유역의 20개 지역 (울진, 포항, 대구, 울산, 부 ᄉ
ᅡᆫ, 통영, 진주, 태백, 영주, 문경, 영덕, 의성, 구미, 영천, 거창, 합천, 밀양, 산청, 거제, 남해)의 자료 르
ᆯ이용하여 SPI6 값의 예측을수행하였다. SPI6의 예측을위해 지역의 기후자료는 물론세계 기후자 ᄅ
ᅭ를함께 사용하여 예측력을한층 높이고자 하였다. 이를위한 모형으로는 인공 신경망의 한 종류인 다 ᄎ
ᅳ
ᆼ퍼셉트론 (multilayer perceptron; MLP)을사용하였으며, 활성함수, 은닉층별 뉴런 수, 중도탈락 비 유
ᆯ, 은닉층수, L1 정규화 적용유무를고려하여 지역당 400가지 모형 중최적의 모형을찾고자 하였다.
ᄌ
ᅵ역별 최적의 모형으로 예측한 2017년 4-6월 예측값을바탕으로 지도를그리면 Table 4.1 와 같다. 왼 ᄍ
ᅩ
ᆨ그림 3개는 실제관측된값을기반으로 그린 그림이고, 오른쪽그림 3개는예측한 값을기반으로 그 ᄅ
ᅵᆫ 그림이다. 지역별 SPI6를예측함에 있어서, L1 정규화를적용한 모형이 적용하지 않은모형보다 검 ᄌ
ᅳᆼ평균제곱오차 (validation mean square error)가 항상 더 낮았으며, 대부분의 지역에서 은닉층수가 ᄌ
ᅥ
ᆨ을수록검증평균제곱오차 (validation mean square error)가 더 낮은경향을보였다.
이
ᆯ반적으로 심층 신경망 모형은자료가 많이 축적될수록예측력이 높아지게 되므로, 보다 더 오랜 기 ᄀ
ᅡᆫ의 자료를수집하여 분석하게된다면 검증평균제곱오차가 더 낮은모형을찾을수 있을것으로 기대된 ᄃ
ᅡ. 또한 이러한 모형을낙동강 유역의 자료 뿐만 아니라 다른지역의 자료에 마찬가지로 적용할 수 있 ᄋ
ᅳ므로, 전국모든지역에서 SPI6를예측하는데 유용하게 사용될 것이라 기대된다.
References
Ali, M., Deo, R., Maraseni, T. and Downs, N. (2019). Improving spi-derived drought forecasts incorpo- rating synoptic-scale climate indices in multi-phase multivariate empirical mode decomposition model hybridized with simulated annealing and kernel ridge regression algorithms. Journal Of Hydrology, 576, 164-184.
Bonaccorso, B., Cancelliere, A. and Rossi, G. (2015). Probabilistic forecasting of drought class transitions in Sicily (Italy) using Standardized Precipitation Index and North Atlantic Oscillation Index. Journal Of Hydrology, 526, 136-150.
Duchi, J., Hazan, E. and Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. The Journal Of Machine Learning Research, 12, 2121-2159.
Goodfellow, I., Warde-Farley, D., Mirza, M., Courville, A. and Bengio, Y. (2013). Maxout networks.
Proceedings of the 30th International Conference on Machine Learning, PMLR, 28:1319-1327 Kingma, D. P. and Ba, J. (2014). Adam: A method for stochastic optimization. CoRR, abs/1412.6980.
Matthew D. Zeiler. (2012). Adadelta: An adaptive learning rate method. arXiv preprint arXiv:1212.5701.
Mckee, T. B., Doesken, N.J. and Kleist, J. (1993) The relationship of drought frequency and duration to time scales. Proceedings of 8th Conference on Applied Climatology, Anaheim, 179-184.
Minsky, M., and Papert, S. (1988). Perceptions. An introduction to computational geometry, The MIT Press: Cambridge.
Nair, V. and Hinton, G. (2010). Rectified linear units improve restricted boltzmann machines. Proceedings of ICML. 27. 807-814.
The H2O.ai team (2017). R interface for h2o, CRAN.
Dozat, T. (2016). Incorporating nesterov momentum into adam. ICLR Workshop, 1, 2013-2016.
Wickham. H., L. (2016). Ggplot2: Elegant graphics for data analysis, New York, NY: Springer-Verlag.
Wu, H., Svoboda, M., Hayes, M., Wilhite, D. and Wen, F. (2007). Appropriate application of the stan-
dardized precipitation index in arid locations and dry seasons. International Journal Of Climatology,
27, 65-79.
Nesterov, Y. (1983). A method for unconstrained convex minimization problem with the rate of convergence
o(1/k
2). Doklady ANSSSR (translated as Soviet.Math.Docl.), 269, 543-547.
2019, 30
(6)
,1277–1287
Development and validation of a deep neural network for predicting SPI of Nakdong river basin
†Youngtae Choi1· Kyeong Eun Lee2· Gwangseob Kim3
12Department of Statistics, Kyungpook National University
3Department of Civil Engineering, Kyungpook National University
Received 31 October 2019, revised 15 November 2019, accepted 15 November 2019
Abstract
In this study, we applied a kind of deep neural network, a multilayer perceptron (MLP), to predict SPI6 of Nakdong River Basin. The monthly standard precipitation indices, temperature, temperature normal value, precipitation, normal precipitation, precipitation date, and various global climate indexes are used as explanatory variables.
To find the optimal model, we consider two active functions, four types of the neurons per a hidden layer, five types of dropout rates, five types of the number of hidden layers, and two loss functions. We use the validation mean square error for the evaluation.
The validation mean square error was always lower in the model with (L1normalization than in the model without the normalization. In most areas, the smaller the number of hidden layers, the lower the validation mean square error.
Keywords: Deep neural network, L1 regularization, Mean square error, Multilayer perceptron, Neural network, SPI6, Validation dataset.
†
This work was supported by Korea Environmet Industry & Technology Institute (KEITI) through Advanced Water Management Research Program, funded by Korea Ministry of Environment (Grant.
83067).
1
Ph.D. student, Department of Statistics, Kyungpook National University, 80 Daehak-ro, Buk-gu, Daegu 41566, Korea.
2
Associate professor, Department of Statistics, Kyungpook National University, 80 Daehak-ro, Buk-gu, Daegu 41566, Korea.
3