딥러닝과 전이학습을 이용한 콘크리트 균열 인식 및 시각화
Recognition and Visualization of Crack on Concrete Wall using Deep Learning and Transfer Learning
이상익
a⋅양경모
b⋅이제명
c⋅이종혁
d⋅정영준
e⋅이준구
f⋅최원
g,✝Lee, Sang-Ik⋅Yang, Gyeong-Mo⋅Lee, Jemyung⋅Lee, Jong-Hyuk⋅Jeong, Yeong-Joon⋅Lee, Jun-Gu⋅Choi, Won
ABSTRACT
Although crack on concrete exists from its early formation, crack requires attention as it affects stiffness of structure and can lead demolition of structure as it grows. Detecting cracks on concrete is needed to take action prior to performance degradation of structure, and deep learning can be utilized for it. In this study, transfer learning, one of the deep learning techniques, was used to detect the crack, as the amount of crack’s image data was limited.
Pre-trained Inception-v3 was applied as a base model for the transfer learning. Web scrapping was utilized to fetch images of concrete wall with or without crack from web. In the recognition of crack, image post-process including changing size or removing color were applied. In the visualization of crack, source images divided into 30px, 50px or 100px size were used as input data, and different numbers of input data per category were applied for each case. With the results of visualized crack image, false positive and false negative errors were examined. Highest accuracy for the recognizing crack was achieved when the source images were adjusted into 224px size under gray-scale. In visualization, the result using 50 data per category under 100px interval size showed the smallest error. With regard to the false positive error, the best result was obtained using 400 data per category, and regarding to the false negative error, the case using 50 data per category showed the best result.
Keywords: Deep Learning; transfer learning; concrete crack; visualization
Ⅰ. 서 론
콘크리트는 균열 잠재성이 있는 재료로 균열을 가지는 것 이 일반적이지만, 균열의 성장으로 파괴가 일어날 수 있다.
콘크리트의 균열은 일반적으로 부재의 인장 변형률에 의해서 발생하며 (Byun et al., 2000), 콘크리트를 선형, 탄성 재료라고 가정했을 경우 콘크리트의 인장 응력이 그 인장강도를 넘어
설 때 균열이 발생한다고 가정하기도 한다 (Yoon, 1991). 콘크 리트 구조물에 균열이 발생하면 구조물의 성능저하 문제가 발생하며, 구체적으로는 구조물의 미관 저하, 구조물의 이용 가능성 저하, 철근 부식 보호 실패가 일어날 수 있다 (Yoon, 1991). 콘크리트에 발생하는 균열은 설계적으로 의도한 균열, 단기적으로 발생하는 균열, 장기적으로 발생하는 균열이 있 다. 앞의 두 균열은 진전될 시 철근이 부식될 수 있으므로 그 대로 방치해서는 안되며, 장기균열의 경우 그 정도가 구조물 의 수명을 결정하기도 하므로 주의가 필요하다 (Kang and Hong, 2008). 콘크리트 구조물의 성능저하 정도는 임의성 및 변화폭이 크므로 성능이 서서히 저하되기도 하지만, 한순간에 붕괴하기도 한다. 균열에 의한 구조물 성능저하는 보수 및 개축 필요성에 의한 경제적 손실로 이어질 수도 있다 (Kim, 1995).
균열 탐지 방법 중 비파괴방식은 구조물을 유지하며 균열 을 탐지하는 방법이다. 비파괴 균열 탐지 방법으로 Song et al. (2007)은 콘크리트 타설 과정 이전에 압전 세라믹 전환기 (Piezoceramic transducer)를 넣어 콘크리트 구조물의 상태에 따른 센서에서 감지된 출력의 크기 변화를 감지하여 균열을 감지하였으며, Chen et al. (2004)은 동축케이블과 ETDR (Electronic Time Domain Relfectometry)을 이용하여 철근 콘 크리트의 균열과 스트레인을 측정하였다. 콘크리트 내부에 센서를 삽입하지 않는 방법으로는 Suaris et al. (1987)이 초음 파를 이용하여 균열을 검출한 바 있으며, Pour-Ghaz et al.
a
MS Student, Department of Rural Systems Engineering, Seoul National University
b
Undergraduate Student, Department of Rural Systems Engineering, Seoul National University
c
Postdoctoral Research Associate, Division of Environmental Science and Technology, Kyoto University
d
MS Student, Department of Rural Systems Engineering, Seoul National University
e
Undergraduate Student, Department of Rural Systems Engineering, Seoul National University
f
Senior Researcher, Rural Research Institute, Korea Rural Community Corporation
g
Assistant Professor, Department of Rural Systems Engineering, Research Institute of Agriculture and Life Sciences, Seoul National University Co-first authors contributed equally to this work.
†
Corresponding authorTel.: +82-2-880-4715 Fax: +82-2-873-2087 E-mail: [email protected]
Received: February 28, 2019
Revised: May 2, 2019
Accepted: May 2, 2019
(2014)이 RFID기반의 센서를 이용해 콘크리트 표면에 발라진 전도성 물체의 전기저항 변화를 측정하여 균열을 검출하였다. 그러나 이러한 방법들은 많은 시간이 소요되거나 큰 비용이 필요하며, 사람이 직접 접근할 수 없는 부분은 탐지하기 어렵 다는 공간적 한계를 가지고 있다. 따라서 단시간에 저렴한 비 용으로 균열을 탐지할 수 있는 방법이 시급히 요구되고 있다. 이에 딥러닝을 활용하여 균열을 탐지하면, 균열의 깊이 등을 알기 어렵다는 한계가 있으나 소요되는 시간과 비용을 크게 줄일 수 있고, 구조물에 별도로 장착 혹은 삽입하는 장치 없이 적용될 수 있으며, 드론 항공 촬영의 적용을 통해 공간적 한계 역시 극복할 수 있다.
딥러닝은 인공지능 연구의 한 분야로, 그 모델이 여러 개의 프로세싱 계층으로 구성되어있고 여러 레벨의 추상화로 데이 터를 대표하는 것을 학습하는 계산적 모델이다 (LeCun et al., 2015). 딥러닝의 대표적 응용예시에는 음성인식과 시각자료 인식이 있다. 그중 시각자료 인식에는 딥러닝 모델 중 합성곱 신경망 (Convolutional Neural Network, CNN)이 널리 사용되 고 있으며 다른 모델들보다 간단하고 일반적인 구조를 사용 하며 시각자료 인식에 더 높은 정확도를 나타낸다 (Simard et al., 2003). Krizhevsky et al. (2012)는 CNN으로 여러 이미지 에 대해 훈련한 모델을 사용하였고, CNN을 사용하지 않은 모델이 top-1 error가 45.7%, top-5 error가 25.7%로 나타난 것 과 비교했을 때 CNN을 활용한 모델이 37.5%의 top-1 error, 17.0%의 top-5 error를 나타내어 약 8%의 정확도 개선 효과를 나타낸 것으로 분석되었다. 그 외에 CNN을 사용한 모델인 Inception 모델의 개량형인 Inception-v2 모델의 top-1 error는 21.2%, top-5 error는 5.6%로 나타났다((Szegedy et al., 2016).
딥러닝을 실용적으로 이용하기에 대부분의 경우 많은 데이 터를 구할 수 없어 학습에 불리하지만, 전이학습을 통해 학습 의 성능을 크게 향상하고 데이터 라벨링에 들어가는 노력을 경감할 수 있어 적은 양의 데이터로도 우수한 성능을 나타낼 수 있다 (Pan and Yang, 2010). 전이학습은 이미 학습된 모델 을 기반으로 학습 과정을 반복하여 새로운 모델을 얻고, 얻은 모델을 예측에 사용하는 방법이다. 전이학습에 사용하는 모 델의 예시로는 합성곱 신경망의 일종인 AlexNet, Inception-v3 모델 등이 있다. AlexNet과 Inception-v3는 이미지를 분류하기 위해 고안된 딥러닝 모델으로, 합성곱 신경망 등의 기법을 이 용하여 구성된 모델이다. AlexNet은 합성곱 신경망 등의 기법을 이용하여 ILSVRC (ImageNet Large Scale Visual Recognition Competition) 2010에서 우수한 성능을 나타내어 이후 이 모델 에서 사용된 기법이 빈번히 사용되었다. Inception-v3 모델은 GoogLeNet을 개선한 것으로, 이는 한 계층에 여러 개의 필터 등을 적용하는 inception 모듈을 이용해 성능을 개선한 모델이
다. Xia et al. (2017)은 꽃 분류를 위해 Inception-v3 모델을 전이 학습하여 94∼95%의 정확도를 얻었으며, Devikar (2016) 은 개 품종 분류를 위해 Inception-v3 모델을 개 사진에 대해 재훈련하여 96%의 정확도를 얻은 바 있다.
콘크리트 균열은 그 특징이 분명하여 딥러닝을 이용한 콘 크리트 균열 탐지에 대해 다양한 연구가 진행되었다. Lee et al. (2007)은 이진화 등의 방법으로 이미지 프로세싱한 사진에 대해 인공 신경회로망을 이용하여 패턴을 학습시킨 결과, 시 험에 사용된 균열을 모두 검출하였다. Hassan et al. (2018)은 환경변화에 대한 사전 처리를 한 CCTV 영상을 이용해 딥러 닝을 수행하여 98.76%의 인식률을 얻었다. 딥러닝을 활용하 여 콘크리트 균열을 탐지하기 위해서는, 균열이 일어난 부분 의 사진이 필요하지만, 다양한 형태로 충분한 양의 사진을 확 보하는 것에 한계가 있기에, 사전학습을 시행한 전이학습법 을 이용하여, 콘크리트 균열 인식에 적용하려는 연구가 진행 되어 왔다. Lee et al. (2018)은 콘크리트 박락 사진에 대해 AlexNet을 전이 학습하여 박락을 탐지하고 확률지도를 구성 했으며, 모든 경우에 박락 탐지에 성공하고 확률지도에서는 박락의 80%를 탐지하였다.
본 연구에서는 콘크리트 균열 사진을 활용하여 전이학습을 위한 Inception-v3 모델을 재학습하고, 재학습된 모델을 이용 하여 콘크리트 사진에서의 균열을 인식 및 시각화한다. 입력 자료로는 웹 스크레이핑을 통해 수집한 콘크리트 균열 사진 및 균열이 없는 콘크리트 사진을 이용한다. 균열 인식을 위해 서 콘크리트 사진에 크기 변경 및 색 제거를 적용하며, 이미지 프로세싱 여부에 따른 결과를 비교해 적합한 프로세싱 방법 을 분석한다. 균열 시각화를 위한 확률지도 제작을 위해서는 균열 감지에서의 적합한 이미지 프로세싱이 적용된 수집자료 를 일정한 크기로 나누고, 나눠진 사진의 특정 개수를 Inception-v3 모델에 입력자료로 사용하여 전이학습한다. 이 때 분할된 크기와 입력된 자료 개수에 따른 확률지도 결과의 오류를 비교한다.
Ⅱ. 재료 및 방법
1. 입력자료
콘크리트 균열 자료 및 균열이 없는 콘크리트 자료를 수집 하기 위해 웹 스크레이핑을 이용하였다. 웹 스크레이핑은 사 람이 읽을 수 있는 자료에서 구조화된 데이터셋을 자동으로 추출하는 방법이다 (Boeing et al., 2016). Lee et al. (2018)은 웹 스크레이핑 도구인 Scrape Box를 이용하여 박락 이미지를 수집한 바 있었다. 본 연구에서는 웹 스크레이핑 기능을 수행 하는 오픈소스 프로그램을 이용하여 입력자료를 수집하였다.
해당 프로그램에서는 키워드를 이용하여 웹상에서 이미지를 얻을 수 있었다. 콘크리트 균열 사진의 수집에 사용한 키워드 로는 ‘콘크리트 크랙’, ‘concrete wall crack’이었으며, 균열이 없는 콘크리트 사진은 ‘콘크리트’, ‘clear concrete wall’을 키워 드로 사용하였고, 분류 당 100개의 사진을 수집하여 균열 여 부를 확인하고 이를 입력자료로 사용하였다. Fig. 1은 수집한 사진의 예시이며, 균열이 없는 콘크리트 사진은 Fig. 1 (b)와 같이 육안으로 확인했을 때 균열이 없는 사진을 이용하였다.
2. Inception-v3
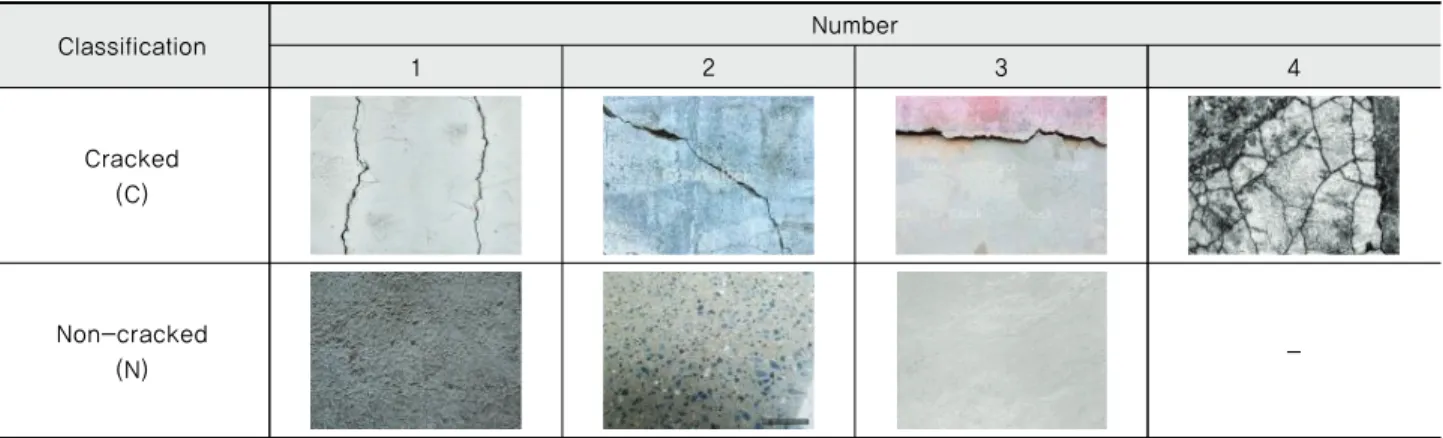
본 연구에서는 전이학습에 Inception 모델을 개선한 모델인 Inception-v3 모델을 사용하였다. 본 모델은 ILSVRC (ImageNet Large Scale Visual Recognition Competition) 2012에서 제시된 분류 1,000개, 총 개수 120만개의 사진을 이용하여 학습된 모 델이다. 이 모델의 기초가 되는 Inception 모델은 Fig. 2의 (a)와 같이 여러 층의 합성곱 계층으로 구성되어있고, Inception-v3 모델은 Fig. 2의 (b)와 같이 3x3 합성곱 계층을 사용하며, 그 외의 계층으로 이루어진 총 42개의 계층으로 구성된다. 이때 합성곱 계층은 어떤 NxN 크기인 행렬 w를 입력 행렬 A의 각 NxN 부분을 순회하며 곱한 결과를 출력으로 한다. 즉 입력 행렬 의 크기가 MxM이라면, 출력 행렬의 크기는 (M-N+1)x(M-N+1)이 된다. 이 계층은 이미지의 특징을 추출하는데 우수한 성능을 보인다. 모델의 정확도를 판단하는 일반적인 방법은 top-1 error와 top-5 error를 이용하는 것이다. 모델은 어떤 사진이
주어졌을 때 다양한 카테고리에 대한 예측값을 나타낸다. 이 때 두 지표는 여러 사진이 주어졌을 때 각 사진의 예측 결과에 서 예측한 카테고리에 정답이 없을 확률을 나타낸다. Top-1 error는 예측 확률이 가장 높은 카테고리에 정답이 아닐 확률, top-5 error는 상위 5개의 예측 결과를 나타내는 카테고리에 정답이 없을 확률을 나타낸다. Inception 모델의 초기 형태인 GoogLeNet의 top-1 error는 29%, top-5 error는 9.2%인데 비해 Inception-v3 모델의 최종 형태는 top-1 error가 21.2%, top-5 error가 5.6%를 나타냈으며 ILSVRC 2012의 다른 모델에 의한 결과에 비해서도 더 우수한 성능을 보였다 (Szegedy, 2016).
3. 전이학습
특정 영역에 대해 일반화를 진행하고 싶은 경우, 직접 각각 의 레이어를 설계하여 모델을 만들고 많은 입력자료를 이용 해 모델을 학습시켜 예측값을 얻는다. 그러나 직접 모델을 설 계하는 과정은 전문성이 필요하며 많은 시간이 필요하다. 뿐 만 아니라 훈련에 많은 입력자료가 필요하므로 자료량이 적 은 영역의 경우 일반화가 어려울 수 있다. 따라서 Inception-v3 와 같은 이미 설계된 모델을 사용하면 설계에 필요한 시간을 크게 단축시킬 수 있다. 또한 이미 학습된 설계된 모델을 재훈 련하여 이용할 경우 상대적으로 적은 양의 입력자료로도 효 과적인 일반화 결과를 얻을 수 있다. 이처럼 학습된 모델을 다른 영역에서 재학습하는 것을 전이학습이라고 한다.
(a) Cracked input data (b) Non-cracked input data
Fig. 1 Example photo of cracked input data and non-cracked input data
Fig. 2 Structure of Inception Model (Szegedy, 2015)
Pan and Yang (2010)은 분류 작업이 필요한 목표 영역과 별개의 영역에 충분한 학습 데이터가 가정되었을 때 데이터 라벨링에 들어가는 노력을 줄이면서 성능을 크게 향상할 방 법으로 전이학습을 제시하였다. 전이학습은 기존영역에서 학 습된 가중치를 초깃값으로 하여 새로운 데이터를 대상으로 재학습시키는 것으로, 많은 데이터가 존재하는 영역에서 학 습된 모델의 가중치를 데이터가 적은 다른 영역에 이용할 수 있다. 이를 이용하면 입력자료가 적은 영역에 대해 효과적인 학습 효과를 얻을 수 있다. Python 언어를 기반으로 하는 딥러 닝 프레임워크인 PyTorch의 경우 분류당 75개의 검증용 이미 지는 바닥부터 학습하기에는 적은 숫자이지만, 전이학습을 사용할 경우 해당 개수로도 합리적으로 일반화할 수 있다.
본 연구에서는 앞서 수집된 입력자료를 기반으로 Inception-v3 모델을 재훈련하였다. 콘크리트 균열 사진의 경우 자료 수집 이 한정적이므로 수집 가능한 자료의 수가 적다. 그러나 본 연구의 초점이 전이학습에 있고, 딥러닝 모델을 직접 설계하 여 기초부터 학습시키는 것이 아닌 이미 많은 데이터를 이용 하여 학습된 Inception-v3 모델을 이용하여 전이학습을 하므 로 많은 데이터를 사용하지 않아도 효과적인 결과를 얻을 수 있을 것으로 분석되었다. 따라서 본 모델에 콘크리트 균열 사 진으로 재훈련시키는 방법을 적용할 시 적은 입력자료에 대 해서도 높은 성능을 얻을 수 있었다.
4. 균열 인식
본 연구에서는 입력자료 사진의 크기 및 색 제거 여부에 따른 결과의 변화가 있을 것으로 예측하고 크기 조정 및 색 제거에 따라 결과를 비교하였다. 사진 크기의 영향에 따른 비 교의 기준으로 가로 및 세로 224px를 이용하여 원본 사진을 이용했을 때와 가로 및 세로 224px로 크기 조정을 한 사진을 이용해 재학습했을 때의 예측 결과를 비교했다. 이때, 원본 사진은 가로 및 세로 크기가 224px보다 작은 사진과 큰 사진
이 균일하게 사용되었다. 가로, 세로가 224px인 사진을 만들 기 위해 원본 사진의 중심에서 원본 사진의 가로, 세로 길이 중 최솟값 크기의 정사각형 범위 외 영역을 제거하고 사진의 가로, 세로 길이를 224px로 조정하였다. 콘크리트 사진에서 색에 따른 균열 인식의 영향을 평가하기 위해 사진에서 색을 제거한 사진을 이용했을 때와 제거하지 않은 사진을 이용해 학습했을 때의 예측 결과를 비교하였다. 사진에서 색을 제거 하기 위한 방법으로 그레이스케일을 이용하였다. 최종적으로 원본, 그레이스케일만 적용한 사진, 가로 및 세로 224px로 크 기 변경한 사진 그리고 가로 및 세로를 224px로 크기 변경하 고 그레이스케일을 적용한 사진을 각각 입력자료로 사용한 총 4개의 모델을 얻었다.
얻은 모델들로 각 검정 자료가 균열일 확률과 균열이 아닐 확률을 구하고 각 모델의 정확도를 이용하여 최적 모델을 선 정한다. 모델의 정확도는 균열인 검정 자료는 균열일 확률, 균열이 아닌 검정 자료는 균열이 아닐 확률이다. 모델의 각 검정 자료에 대한 정확도의 평균을 최적 모델 선정 기준으로 하여 정확도의 평균이 가장 높은 모델을 선정한다. 검정에는 Table 1의 각 사진을 이용하였다. 각 자료의 명칭은 균열인지 아닌지에 따라 C와 N을 앞에 적고 순서대로 그 번호를 뒤에 적었다. 첫 균열 자료는 C1으로 표기했으며, 첫 균열이 아닌 자료는 N1으로 표기하였다. 검정 자료는 입력자료와 겹치지 않는 새로운 자료를 이용하였다.
5. 균열 시각화
가. 균열 시각화 방법균열 시각화는 딥러닝을 이용하여 주어진 사진에 대해 균 열의 구체적인 위치를 얻는 것을 목적으로 한다. 균열이 존재 하는 사진의 일정 영역에 대해 학습이 완료된 모델로 예측값 을 얻으면 그 영역에 균열이 존재할 확률을 얻을 수 있으며, 그 확률이 매우 높을 경우 해당 영역에 균열이 있을 것으로
Classification Number
1 2 3 4
Cracked (C)
Non-cracked
(N) -
Table 1 Examination data for crack recognition
추측할 수 있다. 균열일 확률을 얻는 일정 영역을 단위 조사 영역이라고 할 때, 단위 조사 영역으로 사진 전체에 대해 예측 값을 얻어 균열로 추측되는 영역에 색을 입히면 최종적으로 균열을 시각화할 수 있다. 단위 조사 영역의 크기를 줄이거나 겹치게 하여 간격을 줄이면 실제 균열 위치와 근사한 시각화 결과를 얻을 수 있으며, 이를 활용해 균열에 대한 특징 해석과 균열의 길이 및 폭 등에 대한 정량적 데이터를 확보할 수 있다.
본 연구에서 단위 조사 영역은 정사각형으로 하여 한 변의 길이가 30px, 50px 그리고 100px일 경우에 대해 실험을 진행 한다. 예측값을 얻기 위해 훈련할 모델의 입력자료는 단위 조 사 영역과 같은 크기의 사진을 이용하며 그 크기만큼 균열 인식에서 사용한 입력자료를 분할한 것을 사용한다. 이용하 는 자료의 개수는 균열 탐지에서 이용한 분류별 자료 개수인 50개부터 2배씩 늘려 분류 별 50개, 100개, 200개 그리고 400 개로 총 4개의 경우를 이용해 분류별 자료 개수에 따른 결과 의 정확도를 비교하였다.
각 인식 간격에 대한 예측값에 따라 Table 2의 기준을 따라 색을 입혔다. 이때 예측값이 0.9인 지점을 균열 판단의 경계선 으로 하여 0.9 이상은 균열인 것으로, 0.9 미만은 균열이 아닌 것으로 예측하였다고 판단하였다. 균열이 아닐 경우의 범위 가 넓으므로 확률 범위를 단조 증가하여 예측값 0.7 이상, 0.4 이상, 0.4 이하로 세부적으로 분류하였다. 이 세부적 분류는 분석에 사용되지는 않고 예측값을 구체적으로 시각화하기 위 해 사용되었으며 명확한 구분을 위해 삼원색이 사용되었다.
최종적으로 한 사진에 대해 시각화된 확률지도를 얻을 수 있 었다.
Region Color
0.9 ≤ Probability < 1.0 Red 0.7 ≤ Probability < 0.9 Green 0.4 ≤ Probability < 0.7 Blue 0.0 ≤ Probability < 0.4 -
Table 2 Color by region of estimated probability from crack visualization
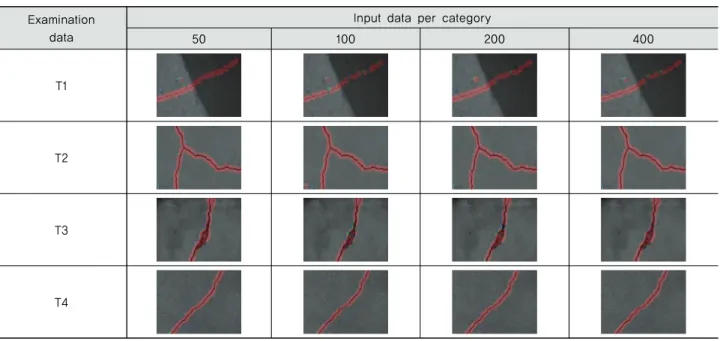
검정 자료는 Fig. 3 (a)∼(d)를 이용하며, 각각 T1∼T4로 나 타내었다.
나. 균열 시각화 오류 검정
각 검정 자료는 학습된 모델에 의한 예측값을 통해 균열을 시각화한다. 그러나 예측의 정확도가 0.9 이상으로 나타나 모 든 경우에 균열을 정확히 탐지하는 것으로 보일 경우 결과가 단색으로 나타나 시각적으로는 결과의 적합성을 알기 어려울
수 있다. 따라서 결과의 정확성을 판단하기 위해 정량적으로 오류를 측정할 필요가 있다. 예측되는 오류에는 크게 두 종류 가 있다. 첫 번째는 균열이 아닌데 균열이라고 추측한 경우이며 두 번째는 균열이 맞는데 균열이 아니라고 추측한 경우이다.
통계적 가설 검증 이론에서는 통계적 오류를 1종 오류와 2종 오류로 구분한다. 1종 오류는 실제 음성인 것을 양성으로 판단하는 경우이며, 2종 오류는 실제 양성인 것을 음성으로 판단하는 오류이다. 위에서 언급한 두 오류는 전자가 1종 오 류, 후자가 2종 오류에 해당하며 각각 false positive (FP), false negative (FN)라고도 한다. 본 연구에서는 FP를 균열 음성을 양성으로 판단한 경우로, FN을 균열 양성을 음성으로 판단한 경우로 한다.
오류 검정은 시각화 검정 자료의 중심선을 이용하며 시각 화가 완료된 자료를 대상으로 했다. 검정 자료의 중심선은 균 열의 중심선으로 판단되는 지점을 선으로 이어 제작했다. 오 류의 발생은 검정 대상이 되는 자료의 원 조사 간격과 같은 간격으로 조사하여 한 영역이 FN 또는 FP로 판단되었을 때 오류가 1회 발생한 것으로 하고 명확히 균열이 맞거나 아닌 경우를 측정했다. 30px로 학습된 모델이 예측한 시각화 자료 에 대해 검정을 하는 경우 오류 검정 역시 30px 간격으로 진행 하며 가로, 세로가 모두 30px인 한 영역에서 FN 또는 FP가 한 번 발생하면 1회 오류로 판단하였다. FP는 영역이 높은 확률로 균열로 판단되었지만 영역 내에 중심선이 지나지 않 는 경우로, FN은 영역이 균열 판단 확률이 높지 않았으나 영 역의 중심을 중심선이 지나는 경우로 하였다. 높은 확률로 균 열로 판단된 경우의 기준은 각 영역에서 균열 예측 확률이 0.9 이상인 경우로 하였다.
본 글에서 소개된 과정은 다음과 같이 요약할 수 있다. 웹 스크레이핑 프로그램에 특정 키워드를 이용하여 입력자료를 수집하면, 그 자료를 4가지의 단순한 이미지 가공을 거쳐 균
(a) T1 (b) T2
(c) T3 (d) T4
Fig. 3 Examination data for crack visualization
열 인식의 학습 자료로 사용하고 이미지 가공 방법 별 한 개씩 의 학습된 모델을 얻는다. 최적 모델을 선정하기 위해 얻은 모델의 예측 결과를 정답과 비교하고, 선정된 모델의 이미지 가공 방법을 균열 시각화 과정에 사용한다. 균열 시각화에서 는 앞서 사용했던 입력자료를 30px, 50px, 100px 단위로 나누 고, 균열인 분류와 균열이 아닌 분류에 각각 50개, 100개, 200 개, 400개를 입력자료로 사용하여 총 12개의 학습된 모델을 얻는다. 각 모델에 의한 시각화 결과를 비교하고, 우수한 모델 을 선정한다. Fig. 4는 이 과정을 묘사한 것이다.
Ⅲ. 결과 및 고찰
1. 균열 인식
가공하지 않은 원본 입력자료와 원본 입력자료를 각각 다 르게 가공한 세 종류의 입력자료를 사용하여 총 네 가지 입력 자료에 의한 균열 인식 결과를 비교하였다. Table 1의 검정 자료를 활용하여 네 가지 모델에 대해 학습한 결과는 Table 3과 같다. Table 3의 Accuracy 항목 값은 예측의 정확도를 나 타낸다. 아래의 C1, C2, C3, C4, N1, N2, N3는 Table 1의 자료 를 이용한 것이다.
그레이스케일을 활용한 모델은 원본 입력자료 모델과 비교 했을 때 두 가지 검정 자료에 대해 더 낮은 정확도를 보였으나 그 외의 검정 자료에 대해 예측의 정확도가 더 높았다. 원본 자료에 가로, 세로를 224px로 크기 조정만 한 모델은 원본
keywords
Image Scraping
Original Input data
-Original -224px -Gray-scale -224px&gray-scale
Transfer Learning
Output
Model Examination
Examination data
Prediction
Visualization 224px&gray-scale
Divided by -30px -50px -100px
Input data per category -50
-100 -200 -400
recognition
visualization
Error
Examination
입력자료 모델보다 전반적인 정확도는 높아졌으나 그 차이가 크지 않았으며, 균열이 아닌 세 자료 중 두 자료는 원본 자료 를 활용했을 때보다 더 낮은 정확도를 보였다. 가로, 세로를 모두 224px로 조정하고 그레이스케일을 적용해 색을 제거한 모델은 전반적으로 정확도의 개선 효과가 있었다. 이 모델은 N2 자료에서 그레이스케일만 적용한 입력자료에 비해 정확 도가 낮아졌으나, 평균 0.961의 가장 높은 평균 정확도를 나타 냈으므로 최적 모델로 선정하였다.
2. 균열 시각화
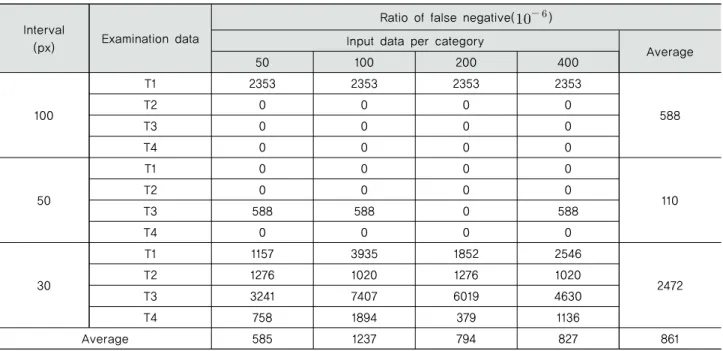
100px, 50px, 30px간격으로 입력자료를 분할 및 검정 자료 를 조사한 시각화 결과가 Table 4, 5, 6으로 나타났다. 전체 조사 횟수에 대한 FP와 FN의 발생 횟수 비율이 Table 7, 8으로 나타났다.
Table 7, 8의 결과로 각 모델에서 단일 조사 범위에 대한 FP, FN의 발생 비율을 확인할 수 있다. 각 오류의 발생은 Table 4, 5, 6의 사진에서 육안으로도 확인할 수 있다. 100px과 50px에서는 일부 경우를 제외하고 오류가 발생하지 않았으며 30px에서는 대부분의 결과에서 오류가 나타나, 조사 간격이 좁아질수록 오류가 많아지는 경향이 나타났다. 이는 조사 간 격이 커질수록 균열이 범위 내에서 차지하는 면적이 작아지 는 것으로 설명할 수 있다. 넓은 조사 범위에서 균열은 명확한 형태와 상대적으로 작은 점유면적으로 인해 특징을 추출하기 가 수월해진다. 대조적으로 좁은 조사 범위에서는 균열이 뚜 렷한 형태를 나타내기 어려울 수 있거나 점유면적이 클 수 있고 점유면적이 커지면 균열인 부분을 균열로 판단하지 않 을 가능성이 커진다. 이는 30px 간격을 사용한 모델에서 다른 모델에 비해 FN이 많은 것으로 검증된다.
Model
Accuracy
Cracked Non-cracked
Average
C1 C2 C3 C4 N1 N2 N3
Original 0.911 0.991 0.881 0.969 0.860 0.730 0.970 0.902
Gray-scale 0.934 0.994 0.976 0.938 0.976 0.787 0.973 0.940
224px 0.923 0.972 0.976 0.976 0.980 0.793 0.968 0.941
224px&
Gray-scale 0.968 0.995 0.996 0.992 0.995 0.797 0.982 0.961
Table 3 Accuracy of each model for each examination data
Examination data
Input data per category
50 100 200 400
T1
T2
T3
T4
Table 4 Result of crack visualization of 100px interval
분류별 입력자료 개수에 따른 영향은 크지 않았다. FP의 경우 400개에서 평균적으로 가장 높은 정확도를, 200개에서 가장 낮은 정확도를 보였다. FN의 경우 50개에서 가장 높은 정확도가 나타났으며, 100개에서 가장 낮은 정확도가 나타 났다.
Ⅳ. 결 론
본 연구에서는 합성곱 모델인 Inception-v3 모델의 전이학 습을 이용한 균열 사진에 대한 예측 및 시각화를 했으며, 균열 예측은 이미지 처리 방법에 따라, 균열 시각화는 훈련 자료 개수 및 조사 간격에 따라 결과를 나타내었다. 균열 예측 및 시각화를 위한 입력자료는 웹 스크레이핑을 통해 수집한 사 진을 이용하였다. 균열 인식 및 시각화에 여러 모델을 활용하
Examination
data
Input data per category
50 100 200 400
T1
T2
T3
T4
Table 5 Result of crack visualization of 50px interval
Examination data
Input data per category
50 100 200 400
T1
T2
T3
T4
Table 6 Result of crack visualization of 30px interval
였으며 균열 인식 및 균열 시각화 결과의 정량적인 평가를 이용하여 최적 모델을 선정하였다.
균열 인식의 경우 입력자료의 이미지 처리 방식에 따라 총 네 가지 모델을 이용하였으며, 실험을 통해 크기를 조정하고 그레이스케일도 적용하여 색을 제거한 모델이 균열인 경우와 균열이 아닌 경우의 예측 정확도를 각각 0.968 이상, 0.797 이상으로 판단하여 가장 정확도가 높은 것으로 나타났다.
균열 시각화의 경우 조사 간격에 따라 입력자료를 다르게 활용하고 조사 간격과 입력자료의 크기를 같게 하여 진행하 였다. 이때 이용한 조사 간격은 각각 30px, 50px, 100px이며, 세 경우에서 모두 분류별 입력자료를 50개, 100개, 200개, 400 개로 다르게 적용한 모델을 이용하여 균열 시각화를 진행하 였다. 시각화 결과 자료에 대해 false positive, false negative 오류를 검정하였다. 시각화 결과 50px 및 100px에서는 일부
Interval
(px) Examination data
Ratio of false positive(
)
Input data per category
Average
50 100 200 400
100
T1 0 0 0 0
T2 0 0 0 0 0
T3 0 0 0 0
T4 0 0 0 0
50
T1 588 0 0 0
T2 0 0 0 0 37
T3 0 0 0 0
T4 0 0 0 0
30
T1 231 231 926 231
T2 0 255 0 0 161
T3 231 0 231 231
T4 0 0 0 0
Average 88 41 96 39 66
Table 7 Ratio of occurrence of false positive (FP) per estimation for interval, examination data and input data per category
Interval
(px) Examination data
Ratio of false negative(
)
Input data per category
Average
50 100 200 400
100
T1 2353 2353 2353 2353
T2 0 0 0 0 588
T3 0 0 0 0
T4 0 0 0 0
50
T1 0 0 0 0
T2 0 0 0 0 110
T3 588 588 0 588
T4 0 0 0 0
30
T1 1157 3935 1852 2546
2472
T2 1276 1020 1276 1020
T3 3241 7407 6019 4630
T4 758 1894 379 1136
Average 585 1237 794 827 861
Table 8 Ratio of occurrence of false negative (FN) per estimation for interval, examination data and input data per category
경우를 제외하고 오류가 나타나지 않았으며, 조사 간격이 좁 아질수록 FP 및 FN이 모두 증가하는 것을 확인할 수 있었다.
이와 대조적으로 입력자료 개수에 따른 변화는 추세가 뚜렷 하지 않게 나타났다. FP의 경우 분류별 입력자료 400개에서, FN의 경우 50개에서 오류 비율이 가장 낮게 나타났다.
감사의 글
이 연구는 서울대학교 교내지원사업 (과제번호 : 500- 20180208)의 지원을 받아 수행되었음.
REFERENCES
1
. Boeing, G., and P. Waddell, 2016. New insights into rental housing markets across the United States: web scraping and analyzing craiglist rental listings. Journal of Planning Educationand Research 1-20. doi:10.1177/0739456X16664789.
2. Byun, G. J., H. W. Song, W. Choi, and S. M. Wu, 2000.
Crack evaluation technique and crack repair of concrete structures. Magazine of the Korea Concrete Institute 12(6):
97-108 (in Korean).
3. Chen, G., H. Mu, D. Pommerenke, and J. L. Drewniak, 2004. Damage detection of reinforced concrete beams with novel distributed crack/strain sensors. Structural Health
Monitoring 3(3): 225-243. doi:10.1177/1475921704045625.
4. Chilamkurthy, S., 2019. Transfer learning tutorial, https://pytorch.org/tutorials/beginner/transfer_learning_tut orial.html. Accessed 14 Apr. 2019.
5. Devikar, P., 2016. Transfer learning for image classification of various dog breeds. International Journal of Adavanced
Research in Computer Engineering & Technology 5(12):
2707-2715.
6. Hassan, S. I., D. L. Minh, S. H. Im, G. B. Min, J. Y. Nam, and H. J. Moon, 2018. Damage detection and classification system for swer inspection using convolutional neural networks based on deep learning. Journal of the Korea
Institute of Information and Communication Engineering 22(3):
451-457 (in Korean). doi:10.6109/JKIICE.2018.22.3.451.
7. Kang, H. K., and S. G. Hong, 2008. Causes and mitigation of concrete cracking. Magazine of the Korea Concrete
Institute 20(5): 61-68 (in Korean).
8. Kim, W., 1995. Major causes for deterioration in concrete structures. Magazine of the Korea Conrete Institute 7(6):
14-22 (in Korean).
9. Krizhevsky, A., I. Sutskever, and G. E. Hinton, 2012.
ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing
Systems 1097-1105. doi:10.1145/3065386.
10. LeCun, Y., Y. Bengio, and G. Hinton, 2015. Deep learning.
Nature 521(7553): 436-444. doi:10.1038/nature14539.
11. Lee, B. Y., S. T. Yi, and J. K. Kim, 2007. Surface crack evaluation method in concrete structures. Journal of the
Korean Society for Nondestructive Testing 27(2): 173-182
(in Korean).12. Lee, Y. I., B. H. Kim, and S. J. Cho, 2018. Image-based spalling detection of concrete structures using deep learning. Journal of the Korea Concrete Institue 30(1):
91-99 (in Korean). doi:10.4334/JKCI.2018.30.1.091.
13. Pan, S. J., and Q. Yang, 2010. A Survey on transfer learning. IEEE Transactions on knowledge and data
engineering 22(10): 1345-1359. doi:10.1109/TKDE.2009.191.
14. Pour-Ghaz, M., A. M. Asce, T. Barret, T. Ley, N. Materer, A. Apblett, and J. Weiss, 2014. Wireless crack detection in concrete elements using conductive surface sensors and radio frequency identification technology. Journal of
Materials in Civil Engineering 26(5): 923-929. doi:
10.1061/(ASCE)MT.1943-5533.0000891.
15. Simard, P. Y., D. Steinkraus, and J. C. Platt, 2003. Best practices for convolutional neural networks applied to visual document analytsis. In Proceedings of the Seventh
International Conference on Document Analysis and Recognition 2: 958-962. doi:10.1109/ICDAR.2003.1227801.
16. Song, G., H. Gu, Y. L. Mo, T. T. C. Hsu, and H. Dhonde, 2007. Concrete structural health monitoring using embedded piezoceramic transducers. Smart Materials and Structures 16: 959-968. doi:10.1109/ICDAR.2003.1227801.
17. Suaris W., and V. Fernando, 1987. Detection of crack growth in concrete from ultrasonic intensity measurements.
Materials and Structures 20: 214-220. doi:10.1007/BF02472738.
18. Szegedy, C., V. Vanhoucke, S. Ioffe, J. Shlens, and Z.
Wojna, 2016. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference
on computer vision and pattern recognition 2818-2826.
doi:10.1109/CVPR.2016.308.
19. Szegedy, C., W. Liu, Y. Jia, P. Sermanet, S. Reed, D.
Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, 2015. Going deeper with convolutions. The IEEE
Conference on Computer Vision and Pattern Recognition
1-9. doi:10.1109/CVPR.2015.7298594.
20. Xia, X., C. Xu, and B. Nan, 2017. Inception-v3 for flower classification. Image, Vision and Computing, 2017 2nd
International Conference on IEEE 783-787. doi:10.1109/
ICIVC.2017.7984661.
21. Yoon, W. H., 1991. About crack of concrete structure. Magazine