* 정회원 : 경남대학교 컴퓨터공학과 조교수 ([email protected]) 접수일자 : 2012. 05. 17
김봉현*
Development of Information Search Module by Integrating Regular Expression and Correlation Analysis Method
Bong-hyun Kim*
요 약
기존의 패턴 및 데이터베이스 검색, 페이지 단위 문자열 검색 기법은 단순 검색 방식으로 오탐율이 많아 검색 결 과에 대한 신뢰성이 떨어진다. 또한, 동일 조건을 다른 검색 기법에 추가로 시행함으로 인해 자원 낭비 및 시간 낭비 를 초래하고 있다. 따라서 본 논문에서는 정규식 구문과 상관분석 기법의 통합적 연계 방식을 적용시킨 정보 검색 모듈을 개발하였다. 이를 통해 기존의 문자열 검색기법의 문제로 지적되어 온 오탐율을 줄임으로써 경제적인 효과 및 신뢰성을 확보하는 보안형 정보 검색 기술을 연구하였다.
ABSTRACT
Existing patterns and database search, string search unit search results for a lot of false positives, a simple search technique unreliable. In addition, the same conditions in addition to other search methods implemented due to wasted of resources and enforcement have been causing a waste of time. Therefore, regular expression and correlation analysis method by applying an integrated linkage information search module is to develop in this paper. From this, existing string search technique that has been noted as a problem by reducing the economic impact false positive and reliability to develop method that will information search secure.
키워드
정규식 구문, 상관분석, 정보검색 모듈, 통합 모듈, 보안형
Key word
Regular Expression, Correlation Analysis, Information Search Module, Integration Module, Security
Ⅰ. 서 론
PC속 정보들을 DB화하고 설정의 변경에 따라 원하 는 정보를 추출하는 것은 정보 검색 분야에서 가장 기 본적이며 핵심적인 부분이다. 그러나 지금까지의 문자 열 검색기법에 대한 연구는 문서의 특성에 따라 재설계 하지 않고 기존의 알고리즘을 약간 수정하거나 수정없 이 결합하는 하이브리드 방식이 제안되고 있다. 그러 나 지식정보화로 인해 검색 대상이 되는 용량이 기하급 수적으로 증가하고 필요한 자료를 검색하는데 많은 시 간이 낭비되고 있다. 또한, 기존의 패턴 및 데이터베이 스 검색, 페이지 단위 문자열 검색기법은 단순 검색으 로 오탐율이 많아 검색 결과에 대한 신뢰성이 떨어지 고, 동일 조건을 다른 검색기법에 추가로 시행함으로 인해 자원 및 시간 낭비를 초래하고 있는 실정이다 [1][2].
최근에는 PC속 정보들의 검색에서 보안 기능이 추 가, 강화된 기술은 새로운 수익원으로 부상하고 있으 며 치열한 경쟁으로 성장기를 보이고 있는 기존의 PC 검색 시장에서 정보들을 효율적으로 관리, 검색하는 기술로 시장을 주도할 전망이다. 이와 같은 정보 검색 분야의 기술적 흐름속에서 IT 솔루션의 대부분 검색을 통해 추출하고자 하는 자료를 찾아내는 기술의 도입에 있어 정규식 구문(Regular expression)과 상관 분석 (Correlation analysis) 기법의 통합적 연계 개발 기술이 가져오는 파급효과는 상당히 많을 것으로 판단된다.
또한, 정규식 구문(Regular expression)과 상관 분석 (Correlation analysis) 기법의 활용방안은 페이지 또는 파일, 블록 단위 검색에 대한 정책화를 통하여 개발사 의존적인 검색 알고리즘을 사용자 중심으로 전환할 수 있을 것이다[3][4][5].
따라서, 본 논문에서는 정규식 구문(Regular expression)과 상관 분석(Correlation analysis) 기법의 통 합적 연계 방식을 적용시킨 정보 검색 모듈을 개발하 고자 한다. 또한, 이를 통해 기존의 문자열 검색 기법의 문제로 지적되어 온 오탐율을 줄임으로써 경제적인 효과 및 신뢰성을 확보하는 보안형 정보 검색 기술의 필요성을 충족시킬 수 있는 검색 모듈을 개발하고자 한다.
Ⅱ. 기존 알고리즘 및 제안 모듈 설계
기존 정보 검색 알고리즘은 정형 데이터 검색으로서 Brute Force(BF), Knuth Morris Pratt(KMP), Boyer Moore Family (BM), Shift Or, Karp Rabin, 접미사 오토마타 (Backward DAWG Matching) 등이 있다. 이들 정형 데이 터 검색 알고리즘은 검색하고자 하는 문자열의 블록과 검색 속도에 관한 알고리즘이다[6][7][8].
알고리즘 특징
Brute Force (Naive) 알고리즘
- 패턴의 첫 글자가 매칭되는 것을 차례대로 검색하고, 첫 글자가 매칭이 되었으면, 그 상 태에서 다음 글자 매칭, 중간에 글자 매칭이 실패했다면 다시 차례대로 패턴 첫 글자부 터 검색을 시작한다.
Knuth- Morris-Pratt
알고리즘 (or KMP algorithm)
- 초기는 BF와 유사하나 일치하지 않는 문자 발생시 이미 일치 되었던 위치는 건너뛰고 그 다음부터 검색 수행
- 보통 BF 보다 많이 빠르지는 않지만, 최악의 경우 길이n의 텍스트 문자열에 대해 단지 n 번의 비교가 수행
- 이미 수행 했던 텍스트와 패턴의 비교들을 기억할 수 있는 수단을 제공하고 그 정보를 이용하여 비교 횟수를 줄임
Boyer-Moore 알고리즘
- 비교 과정이 검색 패턴 끝에서 시작하여 역 방향으로 처리
- 입력 텍스트내의 문자가 검색 패턴에 존재하 지 않을 때, 다음 문자로 큰 폭 이동 가능
Shift-Or 알고리즘
- 비트 병렬성을 기반으로, 머신의 처리 단위 (워드) 내부에서 비트연산 이용
- 머신의 처리 단위보다 패턴의 길이가 짧다면 효과적임
Karp-Rabin 알고리즘
- fingerprint 후 hash function 적용 h(k) = k mod q ( q>m, q=prime)
- 텍스트의 각 윈도우와 패턴에 대하여, 문자 열을 십진수(또는 d진수)로 바꾸고 이를 해 쉬값으로 변환하여 사용
접미사오토 마타(BDM)
- 접미사 오토마타를 기반으로 하며 패턴 P상 에서의 접미사 오토마타는 P의 모든 접미사 들을 인식하는 오토마타
표 1. 정형 데이터 검색 알고리즘
Table. 1 Structure Data Search Algorithm
본 논문에서는 정규식 구문과 상관 분석 기법을 통 합한 보안형 정보 검색 모듈을 개발하기 위해 정규식 구문 검색 기법 및 정책 기반의 상관분석 기법을 통합, 적용하여 보안 이벤트를 통한 수집, 검색, 상관분석 동 작의 동시 적용 환경을 구축하고 형식의 정규화 및 정 보보호 설비의 신속한 수용이 가능한 검색 모듈을 설계 하였다.
그림 1. 기존의 검색 방법 Fig. 1 Existing Search Method
이를 위해 정규식 구문과 상관 분석 기법의 통합을 통 해 보안형 정보 검색 모듈을 개발, 적용하여 기존의 검색 기법에서 문제점으로 지적되어 온 오탐율을 줄이고 이 를 통해 경제적인 효과 및 신뢰성을 확보하는 검색 모듈 을 개발하기 위한 시스템 모듈을 설계하였다. 또한, 아래 의 5가지 기법을 통합적으로 적용한 보안형 정보 검색 모듈을 개발하기 위한 시스템 모듈을 설계하였다.
2.1. 정규식 기반의 (Regular Expression) 검색 알고리즘 정규식 기반의 검색 알고리즘은 문자열에 있는 패턴 을 테스트는 데이터 유효성을 수행하고 정규식을 사용 하여 특정 텍스트를 식별하고 이를 제거하거나 다른 텍 스트로 전환하는 기술이다.
따라서, 대다수의 IT 기반 보안 운영 장비중에 데이터 의 검색을 요하는 시스템에는 대부분 정규식 기반의 검 색 알고리즘이 적용되어 운영되고 있다.
2.2. 상관분석 기반의 (Correlation Analysis) 검색 알고 리즘
상관분석 기반의 검색 알고리즘은 상관분석 연산자
를 검색기능에 적용하여 다수의 검색조건을 만족하는
결과를 검색할 수 있는 기술이다. 따라서, 사용자 정의의 상관분석 규칙을 지원하며 분석결과 이벤트의 종류에 따라 다양하게 활용되고 있다.
상관분석(Correlation Analysis)은 확률론과 통계학에 서 두 변수간에 어떤 선형적 관계를 갖고 있는 지를 분석 하는 방법이다. 두 변수는 서로 독립적인 관계로부터 서 로 상관된 관계일 수 있으며 이때 두 변수간의 관계의 강 도를 상관계수라 한다. 상관관계의 정도를 파악하는 상 관계수는 두 변수간의 연관된 정도를 나타낼 뿐 인과관 계를 설명하는 것은 아니다. 그러나 본 논문에서는 두 변 수가 되는 조건은 정규식에 의한 검색결과로서 원인과 결과의 인과관계가 아닌 결과의 관계만을 활용하는 설 계이다.
2.3. 정책 기반의 정규식 구문(Regular expression)과 상관분석 기법(Correlation analysis method) 개발 기존 또는[OR] 조건만을 이용한 구문검색을 상관성 을 적용하기위해 정책기반의 검색문법을 적용하여 검 색의 효율성을 극대화하여 반복적인 검색과 중복 검색 을 하지 않고 단일 검색을 수행하듯 표현하여 사용자 정의 정책 기반의 검색 모듈을 적용한 모듈 구조 설계 이다.
2.4. 개인정보(개인정보보호법 범위) 상관 검색 기술 개발
최근 개인정보의 오남용에 따른 다양한 보안 사고(금 전적인 피해가 매우 심함)가 발생하여 이에 대한 보호 조 치를 강조하는 개인정보보호법이 2011년 9월 30일부로 발효되어 현재 개인정보를 처리하는 모든 공공기관, 영 리목적의 사업자, 협회ㆍ동창회 등 비영리기관ㆍ단체, 개인 등을 대상으로 개인정보의 중요성을 강조하고 그 에 대한 보호 조치를 하도록 하고 있는 실태이다. 이에 사용자 컴퓨터에 본인의 의도에 의한 또는 의도하지 않 아도 존재하는 개인정보는 개인정보보호법에 저촉 받 을 수 있게 되었다. 따라서 사용자 컴퓨터에 존재하는 개 인정보를 찾아서 사용자에게 삭제, 이동, 암호 등의 조치 를 취하게 유도하는 검색 모듈을 개발하였다.
2.5. 문법적 상관성, 비형식화 상관성 및 단일 페이지 상관성 검색 기술 개발
정규식 기반의 사용자 정의 규칙을 기반으로 상관분
석을 적용하여 상용 보안 솔루션에서 보편화 되어 있는 정책 규칙 기반을 적용하였으며, 페이지 기반의 검색 규 칙을 개발하였다. 이는 단일 정규식을 이용하여 검색이 가능할 뿐만 아니라 단일 정규식을 상관분석을 적용하 여 복합적으로 적용하도록 개발 하였다.
그림 3. 정규식 정책화 및 상관분석 설계 Fig. 3 Design of Regular Policy and Strategy &
Correlation Analysis
Ⅲ. 보안형 정보 검색 모듈 개발
본 논문에서는 다양한 검색조건을 결합하여 기존 시장에 유통되고 있는 단순 검색 솔루션이 가지고 있 는 빠른 처리에 비해 오탐율이 높다는 문제점을 보완 하기 위해 정규식 구문(Regular expression)과 상관분석 (Correlation analysis) 검색 기법을 통합한 정보 검색 모듈 을 개발하였다. 이를 위해 다음의 3가지 보완 사항을 적 용하였다. 첫째는 올바른 판단을 할 수 있는 문법적인 근 거가 필요하다는 것이며 둘째는 페이지 단위 검색을 통 하여 페이지 내에 존재하는 근거를 찾아야 한다는 것이 다. 마지막으로 찾은 파일에 대한 확인(해당 페이지 뷰 어) 근거를 적용해야 한다는 것이다. 이에 본 논문에서 개발한 검색 모듈은 정규식 구문, 상관분석 기법, 페이지 단위 검사 및 결과에 대한 페이지 뷰어를 제공하여 사용 자에게 오탐에 따른 심리적, 정신적 문제를 해결하여 신 뢰성과 안정성을 목표로 개발하였다[9].
본 논문에서 제시한 프로그램의 핵심은 False Positive
와 False Negative (False Positive 와 False Negative) 라는
개념이 있다. 간단히 설명하면, 앞에 것은 "병에 걸리지
않았는데 병에 걸렸다고 진단하는 오류"를 가리키며, 후
자는 "병에 걸렸는데 병에 걸리지 않았다고 진단하는 오
류"를 가리킨다. 바이러스 검사 프로그램 같은 경우, 바
이러스가 있음에도 바이러스가 없다고 보고하면 False
Negative가 되는 것이다. 보듯이 False Negative가 더 위 험한 경우가 많다.) 에 대한 오류를 최대한 줄여 사용자 에게 신뢰성, 안정성을 부여하기 위한 방안으로 개발하 였다. 이는 사용자로 하여금 다양한 판단의 근거를 만들 어 줄 수 있다. 아래 그림 4는 텍스트 파일에 관하여 정규 식 구문과 상관분석 기법을 통한 분석에 대한 소스 일부 를 나타낸 것이다.
그림 4. 텍스트 파일 분석 소스 Fig. 4 Text File Analysis Source
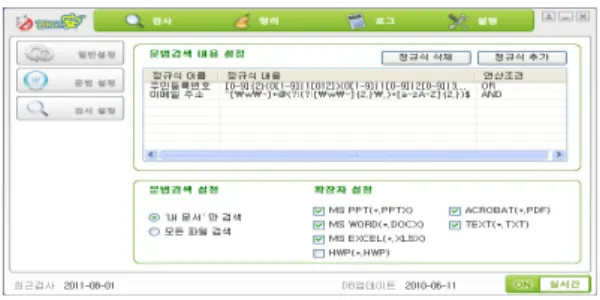
또한, 아래 그림 5는 문법 검색을 나타낸 화면이며 그 림 6은 문법 설정을 나타낸 화면이다. 그림 7은 문법 설 정 과정에서 정규식 추가 부분을 나타낸 화면이며 그림 8은 문법 설정 과정에서 정규식 프리셋 부분을 나타낸 화면이다.
그림 6. 문법 설정 화면 Fig. 6 Grammar Setting Screen
그림 7. 정규식 추가 화면 Fig. 7 Regular Addition Screen
그림 8. 정규식 프리셋 화면 Fig. 8 Regular Free-set Screen
Ⅳ. 시뮬레이션 분석
본 논문에서 개발한 정규식 구문(Regular expression)
과 상관분석(Correlation analysis) 검색 기법의 통합적 연
계 방식을 적용한 보안형 정보 검색 모듈의 성능을 평가
하기 위한 시뮬레이션 분석 실험을 수행하였다. 성능 평
가 실험에서는 100 페이지로 되어 있는 문서에 페이지
단위로 5가지 정보가 중복 또는 단일로 들어 있는 경우
를 기반으로 시뮬레이션을 수행하였다.
페 이 지
정보량 주민
번호 메일 주소
신용
카드 이름 기타
정보 합계
1 1 1 2
2 1 1
3 1 1 1 3
4 1 1 2
5 1 1 1 1 4
6 1 1
7 1 1 1 1 4
8 1 1
9 1 1 1 1 4
10 1 1
11 1 1 1 1 4
12 0
13 1 1 1 1 4
14 0
15 1 1 1 1 1 5
16 1 1
17 1 1 1 1 4
18 1 1
19 1 1 1 1 4
20 1 1
21 1 1 1 1 4
22 1 1
23 1 1 1 3
24 1 1
25 1 1 1 3
26 1 1 2
27 1 1 1 1 4
28 1 1
29 1 1 1 1 4
30 1 1
31 1 1 1 1 4
32 1 1
33 1 1 1 1 4
34 0
35 1 1 1 1 4
36 0
37 1 1 1 1 1 5
38 1 1
39 1 1 1 1 4
40 1 1
41 1 1 1 1 4
42 1 1
43 1 1 1 1 4
44 1 1
45 1 1 1 3
46 1 1
47 1 1 1 3
48 1 1 2
49 1 1 1 1 4
50 1 1
표 2. 시뮬레이션 데이터 파일 Table. 2 Simulation Data File
51 1 1 1 1 4
52 1 1
53 1 1 1 1 4
54 1 1
55 1 1 1 1 4
56 0
57 1 1 1 1 4
58 0
59 1 1 1 1 1 5
60 1 1
61 1 1 1 1 4
62 1 1
63 1 1 1 1 4
64 1 1
65 1 1 1 1 4
66 1 1
67 1 1 1 3
68 1 1
69 1 1 1 3
70 1 1 2
71 1 1 1 1 4
72 1 1
73 1 1 1 1 4
74 1 1
75 1 1 1 1 4
76 1 1
77 1 1 1 1 4
78 0
79 1 1 1 1 4
80 0
81 1 1 1 1 1 5
82 1 1
83 1 1 1 1 4
84 1 1
85 1 1 1 1 4
86 1 1
87 1 1 1 1 4
88 1 1
89 1 1 1 3
90 1 1
91 1 1 1 3
92 1 1 2
93 1 1 1 1 4
94 1 1
95 1 1 1 1 4
96 1 1
97 1 1 1 1 4
98 1 1
99 1 1 1 1 4
100 0
합계 50 45 49 45 50 239
시뮬레이션 결과 다섯 가지 항목에 대하여 단일 검색
시에는 5회의 반복 수행으로 239가지의 검색 결과 자료
가 나오는 반면, 상관분석을 수행하면 그 결과치가 아래
표 3과 같이 도출되었다.
상관갯수 검색수 비 고
2 6 두 가지 정규식에 대한
상관 검색 결과
3 9 세 가지 정규식에 대한
상관 검색 결과
4 36 네 가지 정규식에 대한
상관 검색 결과
5 4 다섯 가지 정규식에 대한
상관 검색 결과
표 3. 검색 시뮬레이션 결과 Table. 3 Search Simulation Result
Ⅴ. 결 론
지식정보화로 인해 검색 대상이 되는 용량이 기하급 수적으로 증가하고 필요한 자료를 검색하는데 많은 시 간이 낭비되고 있다. 또한, 전체 페이지에 대한 순차적 단순 검색으로 검색 후 수집된 데이터가 많아 검색 결과 에 대한 2차 분석이 필요로 한다. 이는 검색 결과에 대한 신뢰성이 떨어지고, 동일 조건을 다른 검색기법에 추가 로 시행함으로 인해 자원 낭비 및 시간 낭비를 초래하고 있다.
따라서, 본 논문에서는 정규식 구문(Regular expression) 과 상관분석(Correlation analysis) 검색 기법의 통합적 연 계 방식을 적용시켜 보안형 검색 모듈을 개발함으로써 기존의 문자열 검색 기법의 문제로 지적되어 온 오탐율 을 줄임으로써 경제적인 효과 및 신뢰성을 확보하는 보 안형 검색기술의 필요성을 충족시킬 수 있는 검색 모듈 을 개발하였다.
이러한 정규식 구문과 상관분석 검색 기법을 통합한 모듈의 적용을 통해 기존 검색기법과는 차별화된 계산 량 감소, 정확도 향상 및 보안성 강화 등의 기능을 기반 으로 문서 분류, 추출 및 검색 사업화 분야의 발전방향을 제시하여 다양한 활용 분야에 적용될 것이며 이로 인해 사용자 PC의 성능 및 사용자 유휴시간에 맞추어 검색을 할 수 있어 다양한 방식으로 활용할 수 있을 것으로 생각 된다.
참고문헌
[1] 박정아 외1, “정보검색에서의 사용자 중심 적합성 판 단 모형,” 한국감성과학회, 2009.
[2] 이수상, 정보검색의 세계, 한국도서관협회, 2011.
[3] 허승표 외5, “효율적인 정규식 표현을 이용한 XSS 공 격 특징점 추출 연구,” 한국정보처리학회, 2009.
[4] 김숙경, “상관분석과 연관규칙을 이용한 학생들의 컴퓨터 사용패턴과 학업 성취도 관계 분석,” 전남대 학교대학원석사학위논문, 2008.
[5] 맹성현, “정보검색 기술의 현황과 발전방향,” 한국정 보과학회, 2004.
[6] 김은상, “다중바이트 문자집합 텍스트에서의 문자열 검색 알고리즘,” 정보과학회논문지, Vol16, No10, 2010.
[7] 북연인, 정보검색 알고리즘, 미래컴, 2003.
[8] 노형기 외3, “내용기반 영상정보 검색 기술의 현황,”
대한전자공학회, 1998.
[9] 이재윤, “임의의 2차원 변조 시스템에 대한 일반화된 오류 확률 분석,” 한양대학교대학원박사학위논문, 2008.
저자소개