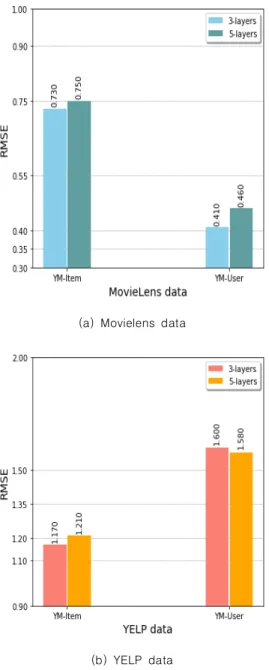
Recommendation system using Deep Autoencoder for Tensor data
1)
전체 글
1)
수치
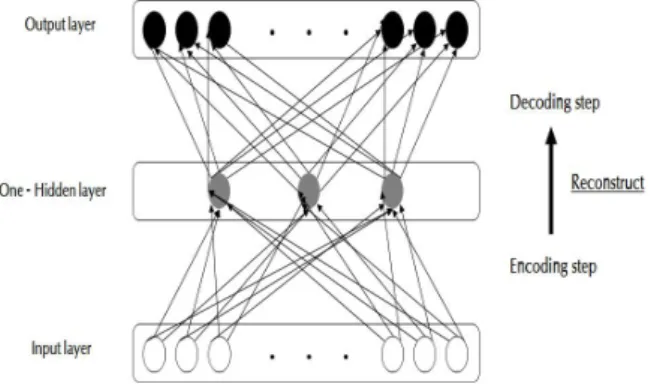
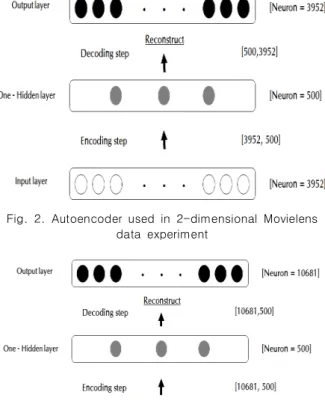


관련 문서
For students majoring in Computer Science have shown positive relationships with personal attitude and subjective norms, differing from those majoring in
In this study, using concept mapping of a variety of learning techniques in the area of science, especially biology, has a positive effect on learning
Taylor Series
School of Computer Science & Engineering Seoul
Motivation – Learning noisy labeled data with deep neural network.
• i) The very high uncertainties associated with modern engineering seismology should be and can be absorbed through the engineering means like the capacity design principle. •
If we wish to develop a learning process based on
The head of the related administrative body of the central government may annul the accreditation if; first, the administrator of the private qualification acquired