2018, 29
(1)
,229–240
평균 대조괴리도 알고리즘 기반 분류용 제한볼츠만기계
†
시
ᆷ주용
1
· 신원용2
·황창하3
1인제대학교 통계학과 ·2단국대학교 모바일시스템공학과 · 5단국대학교 응용통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2017ᄂ ᅧ ᆫ 9ᄋ ᅯ ᆯ 11ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2017ᄂ ᅧ ᆫ 9ᄋ ᅯ ᆯ 28ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2017ᄂ ᅧ ᆫ 10ᄋ ᅯ ᆯ 11ᄋ ᅵ ᆯ
요 약
ᄌ
ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄂ ᅳ ᆫ ᄋ ᅵ ᆸᄅ ᅧ ᆨᄇ ᅦ ᆨᄐ ᅥᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄒ ᅪ ᆨᄅ ᅲ ᆯᄇ ᅮ ᆫ ᄑ ᅩᄅ ᅳ ᆯ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄂ ᅳ ᆫ ᄉ ᅢ ᆼᄉ ᅥ ᆼᄆ ᅩᄒ ᅧ ᆼᄋ ᅳᄅ ᅩᄉ ᅥ ᄌ ᅮᄅ ᅩ ᄃ ᅡᄅ ᅳ ᆫ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄋ
ᅡ
ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅢ ᄐ ᅳ ᆨᄌ ᅵ ᆼᄇ ᅧ ᆫᄉ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄎ ᅮᄎ ᅮ ᆯ ᄒ ᅡᄀ ᅥᄂ ᅡ ᄉ ᅵ ᆷᄎ ᅳ ᆼ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅴ ᄀ ᅡᄌ ᅮ ᆼ ᄎ ᅵᄃ ᅳ ᆯ ᄋ ᅴ ᄎ ᅩᄀ ᅵᄀ ᅡ ᆹᄋ ᅳ ᆯ ᄋ ᅥ ᆮᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄉ ᅡᄋ ᅭ ᆼ ᄃ ᅬᄋ ᅥ ᄋ
ᅪ
ᆻ ᄃ ᅡ. ᄀ ᅳᄅ ᅥᄂ ᅡ ᄎ ᅬ ᄀ ᅳ ᆫ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄋ ᅦ ᄅ ᅡᄇ ᅦ ᆯᄎ ᅳ ᆼᄋ ᅳ ᆯ ᄎ ᅮᄀ ᅡᄒ ᅡᄋ ᅧ ᄇ ᅮ ᆫ ᄅ ᅲᄅ ᅳ ᆯ ᄋ ᅱᄒ ᅡ ᆫ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄀ ᅡ ᄀ ᅩᄋ ᅡ ᆫᄃ ᅬᄋ ᅥ ᆻᄃ ᅡ.
ᄇ
ᅮ ᆫ ᄅ ᅲᄋ ᅭ ᆼ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄋ ᅴ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ ᄋ ᅳᄅ ᅩ ᄌ ᅮᄅ ᅩ ᄃ ᅢᄌ ᅩᄀ ᅬᄅ ᅵᄃ ᅩ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ ᄋ ᅵ ᄉ ᅡᄋ ᅭ ᆼ ᄃ ᅬᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦ ᄉ
ᅥᄂ ᅳ ᆫ ᄇ ᅮ ᆫ ᄅ ᅲᄋ ᅭ ᆼ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄅ ᅳ ᆯ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄒ ᅡᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄉ ᅢᄅ ᅩᄋ ᅮ ᆫ ᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄃ ᅢᄌ ᅩᄀ ᅬᄅ ᅵᄃ ᅩ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆯ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡᄀ ᅩ ᄇ ᅮ ᆫ ᄅ ᅲᄉ ᅥ ᆼᄂ ᅳ ᆼ ᄋ
ᅳ ᆯ ᄒ ᅣ ᆼᄉ ᅡ ᆼᄉ ᅵᄏ ᅵ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅳ ᆷᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅵ ᆫᄃ ᅡ. ᄌ ᅦᄋ ᅡ ᆫ ᄃ ᅬ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄇ ᅮ ᆫ ᄅ ᅲᄋ ᅭ ᆼ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄂ ᅳ ᆫ ᄇ ᅦ ᆫᄎ ᅵᄆ ᅡᄏ ᅵ ᆼ ᄌ ᅡᄅ ᅭᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄋ
ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄉ ᅮᄎ ᅵᄌ ᅥ ᆨ ᄋ ᅧ ᆫᄀ ᅮᄅ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅡᄋ ᅧ ᄀ ᅵᄌ ᅩ ᆫ ᄋ ᅴ ᄃ ᅢᄌ ᅩᄀ ᅬᄅ ᅵᄃ ᅩ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄇ ᅮ ᆫ ᄅ ᅲᄋ ᅭ ᆼ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨᄇ ᅩᄃ ᅡ ᄃ ᅥ ᄌ
ᅩ ᇂᄋ ᅳ ᆫ ᄉ ᅥ ᆼᄂ ᅳ ᆼᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧᄌ ᅮᄂ ᅳ ᆫ ᄀ ᅥ ᆺᄋ ᅳ ᆯ ᄒ ᅪ ᆨ ᄋ ᅵ ᆫᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅢᄌ ᅩᄀ ᅬᄅ ᅵᄃ ᅩ, ᄇ ᅮ ᆫ ᄅ ᅲᄋ ᅭ ᆼ ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨ, ᄋ ᅧ ᆨᄌ ᅥ ᆫᄑ ᅡ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ, ᄌ ᅦᄒ ᅡ ᆫᄇ ᅩ ᆯ ᄎ ᅳᄆ ᅡ ᆫᄀ ᅵᄀ ᅨ, ᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄃ ᅢᄌ ᅩᄀ ᅬᄅ ᅵᄃ ᅩ.
1. 서론
RBM (restricted Boltzmann machine,제한볼츠만기계)은 원래 1986년 Smolensky에 의해 Harmo- nium이라는 이름으로 제안되었다 (Rumelhart와 McLelland, 1986). 그러나 Hinton 등 (2006)이 RBM의 학습 알고리즘으로 CD (contrastive divergence, 대조괴리도) 알고리즘을 제안한 이후로 RBM이 유명해졌다. RBM은 입력벡터에 대한 확률분포를 학습할 수 있는 생성모형으로서 원래 다 ᄅ
ᅳ
ᆫ 학습 알고리즘을 위해 특징변수들을 추출하거나 심층 신경망의 가중치들의 초기값을 얻기 위해 제 ᄋ
ᅡᆫ되었다. 그러나 최근 변형된 RBM들이 제안되어 분류, 시계열분석 및 협업필터링 (collaborative filtering) 등을위해 사용되고 있다.
이
ᆯ반적 신경망과 심층 신경망의 전통적인 학습방법인 역전파 알고리즘은 오차제곱합을 최소화하기 ᄋ
ᅱ해 기울기하강법 (gradient descent method)을사용하기 때문에 비교적 쉽게 최적에 가까운가중치 르
ᆯ구하는 경향이 있어 심층 신경망을 학습하기 위해 많이활용되어왔다 (Hinton, 2009; Lee와 Chun, 2016). 그러나 역전파 알고리즘은몇 가지 중요한 문제점을 가지고 있다. 즉, 과적합 (overfitting) 문 ᄌ
ᅦ, 가중치의 초기값에 민감한 문제 및 지역극소 (local minima) 문제를가지고 있다. 역전파 알고리즘
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ 2016ᄂ ᅧ ᆫᄃ ᅩ ᄌ ᅥ ᆼᄇ ᅮ (ᄀ ᅭᄋ ᅲ ᆨ ᄀ ᅪᄒ ᅡ ᆨᄀ ᅵᄉ ᅮ ᆯ ᄇ ᅮ)ᄋ ᅴ ᄌ ᅢᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅧ ᆫᄀ ᅮᄌ ᅢᄃ ᅡ ᆫᄋ ᅴ ᄀ ᅵᄎ ᅩᄋ ᅧ ᆫᄀ ᅮᄉ ᅡᄋ ᅥ ᆸ ᄌ ᅵᄋ ᅯ ᆫᄋ ᅳ ᆯ ᄇ ᅡ ᆮᄋ ᅡ ᄉ
ᅮᄒ ᅢ ᆼᄃ ᅬ ᆫ ᄀ ᅥ ᆺᄋ ᅵ ᆷ (NRF-2016R1D1A1B03931617). ᄋ ᅵ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ 2017ᄒ ᅡ ᆨᄂ ᅧ ᆫᄃ ᅩ ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄃ ᅢᄒ ᅡ ᆨᄋ ᅧ ᆫᄀ ᅮᄇ ᅵ ᄌ ᅵᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄋ
ᅧ ᆫᄀ ᅮᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ. ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ 2017ᄂ ᅧ ᆫᄃ ᅩ ᄉ ᅡ ᆫᄋ ᅥ ᆸᄐ ᅩ ᆼ ᄉ ᅡ ᆼᄌ ᅡᄋ ᅯ ᆫ ᄇ ᅮᄋ ᅴ ᄌ ᅢᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄋ ᅦᄂ ᅥᄌ ᅵᄀ ᅵᄉ ᅮ ᆯᄑ ᅧ ᆼᄀ ᅡᄋ ᅯ ᆫ (KETEP) ᄋ ᅴ ᄋ
ᅦᄂ ᅥᄌ ᅵᄋ ᅵ ᆫᄅ ᅧ ᆨᄋ ᅣ ᆼᄉ ᅥ ᆼᄉ ᅡᄋ ᅥ ᆸᄋ ᅳᄅ ᅩ ᄌ ᅵᄋ ᅯ ᆫ ᄇ ᅡ ᆮᄋ ᅡ ᄉ ᅮᄒ ᅢ ᆼᄒ ᅡ ᆫ ᄋ ᅵ ᆫᄅ ᅧ ᆨᄋ ᅣ ᆼᄉ ᅥ ᆼ ᄉ ᅥ ᆼᄀ ᅪᄋ ᅵ ᆸᄂ ᅵᄃ ᅡ. (No. 20174030201740).
1
(50834) ᄀ ᅧ ᆼᄂ ᅡ ᆷ ᄀ ᅵ ᆷᄒ ᅢᄉ ᅵ ᄋ ᅥᄇ ᅡ ᆼᄃ ᅩ ᆼ, ᄋ ᅵ ᆫᄌ ᅦᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅧ ᆷᄋ ᅵ ᆷᄀ ᅭᄉ ᅮ.
2
(16890) ᄀ ᅧ ᆼᄀ ᅵᄃ ᅩ ᄋ ᅭ ᆼᄋ ᅵ ᆫᄉ ᅵ ᄉ ᅮᄌ ᅵᄀ ᅮ ᄌ ᅮ ᆨᄌ ᅥ ᆫᄃ ᅩ ᆼ 126ᄇ ᅥ ᆫᄌ ᅵ, ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄆ ᅩᄇ ᅡᄋ ᅵ ᆯᄉ ᅵᄉ ᅳᄐ ᅦ ᆷᄀ ᅩ ᆼ ᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅮᄀ ᅭᄉ ᅮ.
3
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (16890) ᄀ ᅧ ᆼᄀ ᅵᄃ ᅩ ᄋ ᅭ ᆼᄋ ᅵ ᆫᄉ ᅵ ᄉ ᅮᄌ ᅵᄀ ᅮ ᄌ ᅮ ᆨᄌ ᅥ ᆫᄃ ᅩ ᆼ 126ᄇ ᅥ ᆫᄌ ᅵ, ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅳ ᆼᄋ ᅭ ᆼᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄋ
ᅴ 이런 문제점들을극복할 수 있게 제안된모형이 심층 신뢰망 (deep belief network)인데 심층 신뢰망 ᄋ
ᅳᆫ 입력자료만을가지고 필요한 수만큼 RBM을쌓아 올려가며 학습하는비지도학습모형이다. 따라서 RBM은 심층 신뢰망을학습하는데 사용되는대표적인 모형이다.
RBM은한 개의 입력층과 한 개의 은닉층으로 구성되어있는비지도학습모형이다. 입력노드들은 입 ᄅ
ᅧᆨ값으로 이진자료, 범주형자료, 계수형자료, 이산형자료 또는연속형자료를 취할 수 있지만 은닉노드 ᄃ
ᅳ
ᆯ은모두 이진값만을다루는 RBM을사용한다. 왜냐하면 은닉노드들이 이진값 이외의 경우를다루는 RBM은 불안정하기 때문이다. 그런데 은닉노드들의 값은학습과정에서 생성된다. Larochelle와 Ben- gio (2008)는 RBM에 라벨층을 추가하여 분류용 RBM (discriminative RBM)을 개발하였다. 본 논 무
ᆫ에서는 은닉노드들이 이진값만을 다루는 분류용 RBM을 사용하고자 한다. 일반적 RBM과 분류용 RBM은학습을위해 로그가능도함수를최대화하거나 또는 음로그가능도함수를최소화한다. 그러나 최 ᄃ
ᅢ화하는 문제보다 최소화하는 문제가 더 자연스럽기 때문에 음로그가능도함수를 최소화하고자 한다.
ᄄ
ᅡ라서 음로그가능도함수를모수에 대해 미분하여 기울기하강법을사용하는것이 필요하다. 기울기하 ᄀ
ᅡᆼ법 기반 학습 알고리즘을 유도하는 것은 어렵기 때문에 Hinton 등 (2006)은 로그가능도의 기울기 (gradient)에 대한근사값을사용하여 일반적 RBM의 학습알고리즘인 CD 알고리즘을유도하였다. 현 ᄌ
ᅢ 가장 널리 사용되고 있는 일반적 RBM과 분류용 RBM의 학습알고리즘은 CD알고리즘이다 (Hin- ton 등, 2006; Bengio 등, 2007; Feng 등, 2015). CD 알고리즘은마코프 연쇄 전이의 회수를설정하 ᄂ
ᅳᆫ것이 필요하다. 전이회수가 k인 k-단계 CD-k 알고리즘이 RBM을학습하는데 일반적으로 많이 사 ᄋ
ᅭ
ᆼ된다. 로그가능도의 기울기에 대해 상당히 편향된 근사값을제공하지만 빠르고 분산이 작아 실제로는 CD-1알고리즘이 가장 많이 사용되고 있다. Ma와 Wang (2016)은 일반적 RBM의 학습을위해 평균 (average) CD알고리즘을제안하고 제안한 알고리즘이 기존의 CD 알고리즘보다 로그가능도의 기울기 ᄋ
ᅦ 대해 더 좋은근사값을제공한다는사실을 증명하였다.
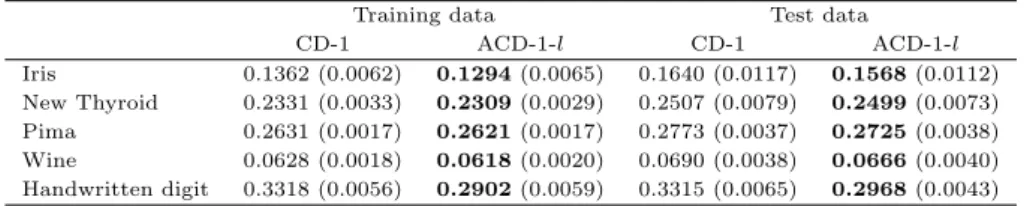
보
ᆫ 논문에서는 분류용 RBM을 학습하기 위한 평균 CD 알고리즘을 제안하고 평균 CD알고리즘이 ᄀ
ᅵ존의 CD 알고리즘보다 더 좋은 분류성능을 제공한다는 사실을 밝히고자 한다. 2절에서는 분류용 RBM을 소개하고, 3절에서는 평균 CD가 기존의 CD보다 로그가능도의 기울기에 대해 더 좋은 근사 ᄀ
ᅡ
ᆹ을 제공한다는사실을 보인다. 그리고 4절에서는 평균 CD알고리즘을 이용한 분류용 RBM의 학습 ᄇ
ᅡᆼ법을제안하고, 5절에서는제안된 평균 CD알고리즘을 실제자료에 적용하여 기존의 CD 알고리즘과 ᄋ
ᅩ분류율 및 AUC (area under receiver operating characteristic curve) 관점에서 분류성능을비교한 ᄃ
ᅡ.
2. 분류용 RBM 및 CD-k 알고리즘 부
ᆫ류용 RBM은 한 개의 입력층과 한 개의 은닉층으로 구성되어있는 비지도학습 모형인 일반적 RBM에 라벨층이 추가된모형이다. 분류용 RBM의 입력노드는 입력값으로 이진자료, 범주형자료, 계 ᄉ
ᅮ형자료, 이산형자료 또는연속형자료를취할 수 있지만 본 논문에서는지면관계상 일반적인 경우라고 새
ᆼ각되는연속형자료를 입력값으로 취하는 분류용 RBM에 대해서만 설명하겠다. 따라서 다른유형의 이
ᆸ력값을취하는 분류용 RBM에 대해서는설명을생략한다. 그림 2.1은 분류용 RBM의 구조를설명한 ᄃ
ᅡ. 입력층은 은닉층과 연결되고 라벨층은 은닉층과 연결되지만 같은 층에 있는노드들끼리는 서로 연 겨
ᆯ되지 않는다고 가정한다. 한편관련 가중치행렬을각각 WWW와 UUU로 나타내며 입력벡터, 은닉노드관련 ᄇ
ᅧᆫ수들의 벡터 및 라벨벡터를각각 xxx, hhh, yyy로 나타낸다. 지금부터 편의상 hhh를 은닉벡터라고 부르겠다.
Figure 2.1 Discriminative RBM
ᄋ
ᅵ제 (xxx, yyy의 결합확률분포 p(xxx, yyy)를정의하고자 한다. 결합확률분포는 일반적 RBM처럼 에너지 함 ᄉ
ᅮ를사용하여 다음과 같이 정의한다.
p(xxx, yyy) = 1 Z(θθθ)
X
h h h
e−E(xxx,yyy,hhh;θθθ),
ᄋ
ᅧ기서 θθθ는 WWW , UUU , aaa, bbb, ccc의 원소들로 이루어진 모수벡터이고 Z(θθθ) =P
xx
x,yyy,hhhe−E(xxx,yyy,hhh;θθθ)는정규화 상수 ᄋ
ᅵ며 E(xxx, yyy, hhh; θθθ)는에너지 함수이다. 따라서 분류용 RBM의 학습과정은 훈련자료에 대해서 로그가능 ᄃ
ᅩ함수를최대화하거나 또는 음로그가능도함수를최소화하는 θθθ를 찾는 것이다. 입력벡터 xxx, 은닉벡터 hhh,라벨벡터 yyy를각각 xxx = (x1, · · · , xd)t와 hhh = (h1, · · · , hm)t, yyy = (y1, · · · , yg)t로 나타낸다. 그러면 부
ᆫ류용 RBM의 에너지 함수는다음과 같이 정의된다.
E(xxx, yyy, hhh; θθθ) =
d
X
i=1
(xi− ai)2 2σi2 −
m
X
j=1
bjhj−
d
X
i=1 m
X
j=1
Wij
xi
σi2hj−
g
X
k=1
ckyk−
m
X
j=1 g
X
k=1
Ujkhjyk,
ᄋ
ᅧ기서 ai와 bj는계수이고, Wij는 입력노드 i와 은닉노드 j를연결하는가중치이다. 그리고 Ujk는 은 니
ᆨ노드 j와 출력노드 k를연결하는가중치이며, σi는각 입력변수 xi의 표준편차이다. 한편 g는그룹의 ᄀ
ᅢ수를 나타내는데 xxx가 그룹 k에 속한다면 라벨벡터는사실 yyy = eeek가된다. 이때 eeek는 k번째 원소만 1이고 나머지 원소들은 0인 g × 1 벡터이다.
ᄒ
ᅡᆫ편 hhh가 주어졌을때 xxx의 조건부확률분포는다음과 같이 표현된다.
p(xxx|hhh; θθθ) = p(xxx, hhh; θθθ)/
Z
p(xxx, hhh; θθθ)dxxx =
d
Y
i=1
N (xi;
m
X
j=1
Wijhj+ ai, σi2),
ᄋ
ᅧ기서 N(xi; µ, σ2)은 평균이 µ이고 분산이 σ2인 정규분포의 확률밀도함수를 나타낸다. 따라서 hhh가 ᄌ
ᅮ어졌을때 xi들은서로 독립이된다. 한편 조건부분포는다음과 같이 표현된다.
p(xi|hhh; θθθ) = N (xi;
m
X
j=1
Wijhj+ ai, σi2), p(yk= 1|hhh; θθθ) = eck+Pmj=1Ujkhj P
lecl+
Pm j=1Ujlhj. ᄀ
ᅳ리고 xxx와 yk= 1이 주어졌을때 또는 xxx가 주어졌을때 조건부확률을구할 수 있는데 그 결과는다 ᄋ
ᅳ ᆷ과 같다.