2021, 32
(1)
,123–134
재중동포 가족 찾기 서신 데이터베이스 구축 및 토픽 모델링과 로컬 대리 분석을 적용한 서신 내용 분석 †
기
ᆷ현희
1
·조진남2
12동덕여자대학교 정보통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2020ᄂ ᅧ ᆫ 12ᄋ ᅯ ᆯ 1ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2021ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 9ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2021ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 15ᄋ ᅵ ᆯ
요 약
ᄇ
ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ 1974ᄂ ᅧ ᆫᄋ ᅦᄉ ᅥ 2008ᄂ ᅧ ᆫᄁ ᅡᄌ ᅵ ᄌ ᅵ ᆫᄒ ᅢ ᆼᄃ ᅬ ᆫ KBS ᄒ ᅡ ᆫᄆ ᅵ ᆫᄌ ᅩ ᆨ ᄇ ᅡ ᆼᄉ ᅩ ᆼ ᄀ ᅡᄌ ᅩ ᆨ ᄎ ᅡ ᆽᄀ ᅵ ᄑ ᅳᄅ ᅩᄀ ᅳᄅ ᅢ ᆷᄋ ᅳᄅ ᅩ ᄇ ᅡ ᆯᄉ ᅩ ᆼᄃ ᅬ ᆫ ᄌ
ᅢᄌ ᅮ ᆼᄃ ᅩ ᆼ ᄑ ᅩ ᄉ ᅥᄉ ᅵ ᆫ 8ᄆ ᅡ ᆫ ᄋ ᅧᄐ ᅩ ᆼ ᄋ ᅦ ᄃ ᅢᄒ ᅡᄋ ᅧ ᄃ ᅦᄋ ᅵᄐ ᅥᄇ ᅦᄋ ᅵᄉ ᅳᄅ ᅳ ᆯ ᄀ ᅮᄎ ᅮ ᆨ ᄒ ᅡᄀ ᅩ ᄉ ᅥᄉ ᅵ ᆫᄋ ᅴ ᄂ ᅢᄋ ᅭ ᆼᄋ ᅳ ᆯ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄉ ᅥᄉ ᅵ ᆫᄋ ᅳ ᆯ ᄉ ᅳᄏ ᅢ ᆫ ᄒ
ᅡᄋ ᅧ ᄋ ᅵᄆ ᅵᄌ ᅵ ᄑ ᅡᄋ ᅵ ᆯᄅ ᅩ ᄉ ᅢ ᆼᄉ ᅥ ᆼᄒ ᅡ ᆫ ᄃ ᅡᄋ ᅳ ᆷ, ᄐ ᅢᄀ ᅳᄅ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄉ ᅥᄉ ᅵ ᆫ ᄂ ᅢᄋ ᅭ ᆼᄋ ᅳ ᆯ ᄋ ᅭᄋ ᅣ ᆨᄒ ᅡᄋ ᅧ ᄉ ᅥᄉ ᅵ ᆫ ᄋ ᅵᄆ ᅵᄌ ᅵᄅ ᅳ ᆯ ᄌ ᅥᄌ ᅡ ᆼᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ.
ᄐ
ᅢᄀ ᅳᄅ ᅳ ᆯ ᄀ ᅵᄇ ᅡ ᆫᄋ ᅳᄅ ᅩ ᄀ ᅥ ᆷᄉ ᅢ ᆨᄋ ᅵ ᄀ ᅡᄂ ᅳ ᆼ ᄒ ᅡᄆ ᅧ ᄀ ᅥ ᆷᄉ ᅢ ᆨᄃ ᅬ ᆫ ᄉ ᅥᄉ ᅵ ᆫᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄇ ᅡ ᆯᄉ ᅩ ᆼ ᄌ ᅵ, ᄇ ᅡ ᆯᄉ ᅩ ᆼ ᄌ ᅡ, ᄇ ᅡ ᆯᄉ ᅩ ᆼᄋ ᅵ ᆯ ᄌ ᅥ ᆼᄇ ᅩᄋ ᅪ ᄐ ᅢᄀ ᅳᄅ ᅳ ᆯ ᄌ ᅥᄌ ᅡ ᆼᄒ ᅡ ᄋ
ᅧ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅦ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄃ ᅩᄅ ᅩ ᆨ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄃ ᅦᄋ ᅵᄐ ᅥᄇ ᅦᄋ ᅵᄉ ᅳ ᄀ ᅮᄎ ᅮ ᆨ ᄉ ᅵ ᄉ ᅥᄉ ᅵ ᆫᄋ ᅴ ᄌ ᅮᄌ ᅦᄅ ᅳ ᆯ ᄇ ᅮ ᆫ ᄅ ᅲᄒ ᅡᄀ ᅵ ᄋ ᅱᄒ ᅢᄉ ᅥ ᄌ ᅥ ᆼᄎ ᅵ, ᄀ ᅧ ᆼ ᄌ
ᅦ, ᄆ ᅮ ᆫ ᄒ ᅪ, ᄉ ᅢ ᆼᄒ ᅪ ᆯ ᄃ ᅳ ᆼ ᄋ ᅴ ᄃ ᅢᄇ ᅮ ᆫ ᄅ ᅲᄅ ᅳ ᆯ ᄌ ᅥ ᆼᄋ ᅴᄒ ᅡᄋ ᅧ ᆻᄋ ᅳᄆ ᅧ, ᄀ ᅡ ᆨ ᄃ ᅢᄇ ᅮ ᆫ ᄅ ᅲ ᄂ ᅢᄋ ᅦᄉ ᅥ ᄀ ᅮᄎ ᅦᄌ ᅥ ᆨ ᄂ ᅢᄋ ᅭ ᆼᄋ ᅳ ᆯ ᄑ ᅡᄋ ᅡ ᆨᄒ ᅡᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄐ ᅩᄑ ᅵ ᆨ ᄆ ᅩ ᄃ
ᅦ ᆯᄅ ᅵ ᆼᄋ ᅳ ᆯ ᄉ ᅵ ᆯᄉ ᅵᄒ ᅡᄋ ᅧ ᆻᄀ ᅩ ᄒ ᅢᄃ ᅡ ᆼ ᄌ ᅮᄌ ᅦᄋ ᅦᄉ ᅥ ᄌ ᅮ ᆼ ᄋ ᅭᄒ ᅡ ᆫ ᄏ ᅵᄋ ᅯᄃ ᅳᄅ ᅳ ᆯ ᄎ ᅡ ᆽᄀ ᅵ ᄋ ᅱᄒ ᅢᄉ ᅥ ᄂ ᅡᄋ ᅵᄇ ᅳ ᄇ ᅦᄋ ᅵᄌ ᅳ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ ᄋ ᅳᄅ ᅩ ᄉ ᅥᄉ ᅵ ᆫ ᄇ ᅮ ᆫ ᄅ
ᅲ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄉ ᅢ ᆼᄉ ᅥ ᆼᄒ ᅡᄀ ᅩ ᄉ ᅥ ᆯᄆ ᅧ ᆼᄀ ᅡᄂ ᅳ ᆼ ᄋ ᅵ ᆫᄀ ᅩ ᆼ ᄌ ᅵᄂ ᅳ ᆼ ᄀ ᅵᄉ ᅮ ᆯ ᄋ ᅴ ᄒ ᅡᄂ ᅡᄋ ᅵ ᆫ ᄅ ᅩᄏ ᅥ ᆯ ᄃ ᅢᄅ ᅵ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄒ ᅢᄃ ᅡ ᆼ ᄇ ᅮ ᆫ ᄋ ᅣᄅ ᅩ ᄇ ᅮ ᆫ ᄅ ᅲᄒ ᅡ ᄀ
ᅦ ᄃ ᅬ ᆫ ᄒ ᅢ ᆨᄉ ᅵ ᆷ ᄏ ᅵᄋ ᅯᄃ ᅳᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄎ ᅮᄎ ᅮ ᆯ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄌ ᅥ ᆼᄎ ᅵ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅴ ᄉ ᅥᄉ ᅵ ᆫ ᄂ ᅢᄋ ᅭ ᆼ ᄋ ᅳᄅ ᅩᄂ ᅳ ᆫ ᄂ ᅡ ᆷᄇ ᅮ ᆨ ᄀ ᅪ ᆫ ᄀ ᅨ, ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄌ ᅥ ᆼᄇ ᅮᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄋ ᅭᄎ ᅥ ᆼ ᄃ
ᅳ
ᆼ ᄋ ᅴ ᄌ ᅮᄌ ᅦᄅ ᅳ ᆯ ᄎ ᅡ ᆽᄋ ᅡᄂ ᅢᄋ ᅥ ᆻᄀ ᅩ, ᄀ ᅧ ᆼᄌ ᅦ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅴ ᄉ ᅥᄉ ᅵ ᆫ ᄂ ᅢᄋ ᅭ ᆼ ᄋ ᅳᄅ ᅩᄂ ᅳ ᆫ ᄆ ᅮ ᆯᄑ ᅮ ᆷ ᄋ ᅭᄎ ᅥ ᆼ ᄆ ᅵ ᆾ ᄀ ᅮ ᆨ ᄋ ᅥᄉ ᅡᄌ ᅥ ᆫ, ᄋ ᅵ ᆯᄒ ᅡ ᆫᄉ ᅡᄌ ᅥ ᆫ ᄃ ᅳ ᆼ ᄀ ᅪ ᄀ ᅡ ᇀᄋ ᅳ ᆫ ᄀ ᅮ ᄎ
ᅦᄌ ᅥ ᆨᄋ ᅵ ᆫ ᄋ ᅭᄎ ᅥ ᆼ ᄑ ᅮ ᆷᄆ ᅩ ᆨᄋ ᅳ ᆯ ᄎ ᅡ ᆽᄋ ᅡᄂ ᅢᄋ ᅥ ᆻᄃ ᅡ. ᄆ ᅡ ᆭᄋ ᅳ ᆫ ᄇ ᅵ ᆨᄃ ᅦᄋ ᅵᄐ ᅥ ᄋ ᅧ ᆫᄀ ᅮᄀ ᅡ ᄃ ᅡᄋ ᅣ ᆼᄒ ᅡ ᆫ ᄒ ᅡ ᆨᄆ ᅮ ᆫ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅦᄉ ᅥ ᄋ ᅲ ᆼ ᄒ ᅡ ᆸ ᄋ ᅧ ᆫᄀ ᅮᄅ ᅩ ᄋ ᅵᄅ ᅮᄋ ᅥᄌ ᅵ ᄀ
ᅩ ᄋ ᅵ ᆻᄂ ᅳ ᆫ ᄇ ᅡ ᆫᄆ ᅧ ᆫ, ᄋ ᅵ ᆫᄆ ᅮ ᆫ ᄒ ᅡ ᆨ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅦᄉ ᅥ ᄌ ᅥ ᆨᄋ ᅭ ᆼᄃ ᅬ ᆫ ᄋ ᅨᄂ ᅳ ᆫ ᄃ ᅳᄆ ᅮ ᆯ ᄃ ᅡ. ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ ᄋ ᅵ ᆫᄆ ᅮ ᆫ ᄒ ᅡ ᆨ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄃ ᅩ ᄇ ᅵ ᆨᄃ ᅦᄋ ᅵᄐ ᅥ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅦᄉ ᅥ ᄒ ᅪ
ᆯᄋ ᅭ ᆼ ᄃ ᅬᄂ ᅳ ᆫ ᄃ ᅡᄋ ᅣ ᆼᄒ ᅡ ᆫ ᄇ ᅮ ᆫᄉ ᅥ ᆨ ᄀ ᅵᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄉ ᅥ ᆼᄀ ᅩ ᆼᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄀ ᅧ ᆯᄀ ᅪᄅ ᅳ ᆯ ᄃ ᅩᄎ ᅮ ᆯ ᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄃ ᅡᄂ ᅳ ᆫ ᄀ ᅥ ᆺᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧᄌ ᅮ ᆷ ᄋ ᅳᄅ ᅩᄊ ᅥ ᄋ ᅵ ᆫᄆ ᅮ ᆫ ᄒ
ᅡ ᆨ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅦᄉ ᅥᄋ ᅴ ᄇ ᅵ ᆨᄃ ᅦᄋ ᅵᄐ ᅥ ᄀ ᅵᄇ ᅡ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄀ ᅡ ᄋ ᅴᄆ ᅵᄀ ᅡ ᄋ ᅵ ᆻᄋ ᅳ ᆷᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧᄌ ᅮ ᆫ ᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄅ ᅩᄏ ᅥ ᆯ ᄃ ᅢᄅ ᅵ ᄇ ᅮ ᆫᄉ ᅥ ᆨ. ᄉ ᅥᄉ ᅵ ᆫ ᄃ ᅦᄋ ᅵᄐ ᅥᄇ ᅦᄋ ᅵᄉ ᅳ, ᄉ ᅥ ᆯᄆ ᅧ ᆼᄀ ᅡᄂ ᅳ ᆼ ᄋ ᅵ ᆫᄀ ᅩ ᆼ ᄌ ᅵᄂ ᅳ ᆼ, ᄐ ᅩᄑ ᅵ ᆨ ᄆ ᅩᄃ ᅦ ᆯᄅ ᅵ ᆼ.
1. 서론 ᄎ
ᅬ근 빅데이터로부터 통찰력과 지식을얻고자 기계 학습, 딥러닝 등의 기술을 적용하여 원천 지식을 회
ᆨ득하는 빅데이터 연구가활발히 이루어지고 있다. Shickel 등 (2018)은대표적인 의료 빅데이터에 기 ᄀ
ᅨ 학습 및 딥러닝을적용하여 의학적 가치를도출하는연구들을소개하였으며, Lim 등 (2020)은소셜 ᄆ
ᅵ디어를크롤링하여 건강 보조제 등의 상품을사용한 후 사용자들의 상품에 대한 리뷰 등을바탕으로 ᄉ
ᅡᆼ품의 효과를 분석하는연구를제시하였으며, Kim 등 (2017)은 식약처에서관리하는약물부작용보고 ᄃ
ᅦ이터베이스를 분석하여 가장 많이 겪는부작용과 심각한 부작용 등을찾아냈다. 이처럼 많은 빅데이 ᄐ
ᅥ 연구들이 학제 간 융합 연구를 바탕으로 하고 있다. 인문학 연구에 있어서도 다양한 문헌들이 연구
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ 2017ᄂ ᅧ ᆫ ᄃ ᅢᄒ ᅡ ᆨᄆ ᅵ ᆫᄀ ᅮ ᆨ ᄀ ᅭᄋ ᅲ ᆨ ᄇ ᅮᄋ ᅪ ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄒ ᅡ ᆨᄌ ᅮ ᆼ ᄋ ᅡ ᆼᄋ ᅧ ᆫᄀ ᅮᄋ ᅯ ᆫ (ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄒ ᅡ ᆨᄌ ᅵ ᆫᄒ ᅳ ᆼ ᄉ ᅡᄋ ᅥ ᆸᄃ ᅡ ᆫ)ᄋ ᅴ ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄒ ᅡ ᆨ ᄇ ᅮ ᆫ ᄋ ᅣ ᄐ
ᅩᄃ ᅢᄋ ᅧ ᆫᄀ ᅮᄌ ᅵᄋ ᅯ ᆫ ᄉ ᅡᄋ ᅥ ᆸᄋ ᅴ ᄌ ᅵᄋ ᅯ ᆫᄋ ᅳ ᆯ ᄇ ᅡ ᆮᄋ ᅡ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅵ ᆷ (ASK-2017-KFR-1230011).
1
(02748) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥ ᆼᄇ ᅮ ᆨ ᄀ ᅮ ᄒ ᅪᄅ ᅡ ᆼᄅ ᅩ13ᄀ ᅵ ᆯ 60, ᄃ ᅩ ᆼᄃ ᅥ ᆨᄋ ᅧᄌ ᅡᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅮᄀ ᅭᄉ ᅮ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (02748) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥ ᆼᄇ ᅮ ᆨ ᄀ ᅮ ᄒ ᅪᄅ ᅡ ᆼᄅ ᅩ13ᄀ ᅵ ᆯ 60, ᄃ ᅩ ᆼᄃ ᅥ ᆨᄋ ᅧᄌ ᅡᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄆ ᅧ ᆼᄋ ᅨᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄋ
ᅴ근간이 되므로 텍스트 분석을활용한 연구 방법을적용하는것이 가능하지만, 아직까지 인문학 문야 ᄋ
ᅪ 빅데이터 융합 연구는매우 드문 실정이다. 이는 인문학 분야에서는대량의 데이터를 분석하여 연구 ᄅ
ᅳᆯ 진행하기에 데이터베이스화 되어 축적된데이터의 양이 다른 분야의 빅데이터 연구에 비해 적고 연구 무
ᆫ헌들이 데이터베이스로 구축되어관리되고 있지 않은경우가 많은데서 기인한다.
보
ᆫ 논문에서는 인문학 연구를위해 필요한 서신 데이터베이스를구축하고 그 내용을 분석하는데 토픽 ᄆ
ᅩ델링과 설명가능 인공지능기술을적용하여 방대한 양의 서신 속에 숨어있는주제를파악하여 인문학 ᄌ
ᅥᆨ 의미를 고찰하고자 한다. 본연구에서 사용된인문학 데이터는 1974년도에서 2008년도까지 진행된 KBS한민족방송이산가족찾기 서신 약 24만 여 통 중에서 한중수교 이전인 1992년도까지 약 8만 통 ᄋ
ᅵ다. 이시기는앞서 언급한 바와 같이 한중수교 이전이므로 재중 동포의 생활상이 공식적 문서로는알 ᄅ
ᅧ진 바가 없고, 개별 인터뷰나 직접 방문 등을 통해 재중동포 연구가 이루어지고 있다. 따라서 8만여 ᄐ
ᅩ
ᆼ의 서신을 분석하여 그간 알려지지 않은재중 동포의 정치적, 경제적, 사회적, 그리고 문화적관점을 ᄉ
ᅡ
ᆯ펴보고자 한다.
ᄋ
ᅧᆫ구서신은주로 길림성 연변자치주를 중심으로 요녕성과 흑룡강성 등 동북 3성에 거주하는재중동포 8만 여명이 KBS 라디오 방송국으로 발송한 서신으로 주 내용은한국에 있는가족을 찾는것이나 재중 ᄃ
ᅩ
ᆼ포의 삶과 일상을포함하고 있다. 시기적으로 한중수교 이전의 서신들이기 때문에 재중 동포들의 생 화
ᆯ상에관한 연구가 이루어지기 어려운시기의 서신 자료들이므로 그 의미가큰자료라고 할 수 있다.
ᄇ
ᅩᆫ연구에서는 종이 문서인 서신을이미지 파일로 스캔하여 수동으로 데이터베이스에 업로드하여 데 ᄋ
ᅵ터베이스를구축하였다. 서신의 내용을 분석하기 위해 데이터베이스 입력자가 이미지로 저장된서신 ᄋ
ᅴ 내용을 읽고 태그 형식으로 내용 중의 핵심 키워드를 입력하였다. 서신의 전문을 입력하면 보다 정확 ᄒ
ᅡ고 풍부한 내용이 분석가능하겠으나 한자가 섞인 서신 이미지를 입력자가 읽고서 전문을 입력하는데 ᄋ
ᅥ려움이 있었다. 따라서 서신의 의미를살릴 수 있으면서도 효율적 텍스트 분석을위하여 최대한 본문 ᄋ
ᅴ 내용을 동일한 가이드라인에 따라 태그 형식으로 요약하여 입력하도록하였다. 또한 서신을업로드 ᄒ
ᅡᆯ 때 내용에 따른 1차적 주제 분류를위해서 정치, 경제, 생활, 문학 등편지가 포함하고 있는주제를 ᄃ
ᅡ중선택하여 입력할 수 있도록하였으며, 이를바탕으로 서신 속에서 언급된고향의 분포 및 발송지에 ᄃ
ᅢ한 통계 분석을 실시하였다.
Bang (2019)과 그의 동료들은 텍스트 마이닝을 통해서 텍스트로부터 주제를추출하는방법을제시하 ᄋ
ᅧᆻ다. 본연구에서는 각 대분류 내에서 구체적 편지 주제를파악하기 위해 텍스트 마이닝 기법 중에서 ᄃ
ᅩ Blei 등 (2003)이 제시한 토픽 모델링 알고리즘인 잠재 디리클래 할당 (latent dirichlet allocation;
LDA)을 실시하여 대분류에 속하는세부 주제를정의하였다. 또한 각 주제를 레이블링하여 나이브 베 ᄋ
ᅵ즈 (Naive Bayes)로 분류 학습을시킨 뒤, Ribeiro 등 (2016)이 제안한 로컬 대리 분석 (local inter- pretable model-agnostic explanations; LIME)을적용하여 해당 주제로 분류하기 위한 핵심 키워드를 ᄎ
ᅮ출하였다. 대부분의 서신은 가족찾기가 서신의 목적이므로관련 키워드인 가족호칭, 인명, 한국지 며
ᆼ, 중국지명 등이 주를이룬다. Son (2020)의 연구에 따르면 불균형한 텍스트 분석을위한 새로운 분 ᄉ
ᅥᆨ 방법이 필요하다. 본연구에서는자주 등장하지 않지만, 재중 동포의 삶을유추해볼수 있는키워드 ᄅ
ᅳᆯ찾는것이 중요한 연구 목적이다. 이러한 키워드를희소 키워드라고 칭한다. 희소 키워드는 빈도수 ᄀ
ᅡ 적기 때문에 기존의확률 분포를활용한 모델은적절하지 않다. 로컬 대리 분석은서신들과 해당 주 ᄌ
ᅦ를 분류하는기계 학습모델에 적용하여 기계가 분류를하는데큰영향을키워드를 찾아주므로 희소 ᄏ
ᅵ워드의 경우에도 해당 서신에서 중요도를가지면 찾아낼 수 있다.
ᄇ
ᅮᆫ석을 통해 얻은의미 있는서신 주제로는정치 분야에서 남북관계 및 한국정부에 대한 요청 및 서 우
ᆫ함에 대한 내용을 들수 있다. 특히 재중 동포들의 처우에 대한 유감을표하는서신과 고국방문요청 ᄋ
ᅵ 다수를이루었다. 경제 대 분류에 속하는서신들의 주 내용은 물품요청이 주를이루었으며, 학습을 ᄋ
ᅱ한 국어사전, 영어사전, 일어사전 등의 요청이 다수 있었으며 녹음테이프 달력 등도 물품요청 주제
ᄋ
ᅦ서 자주언급된 물품으로 알려졌다. 생활및 문화 대분류의 경우 해당하는서신의 숫자도 적고 구체적 ᄉ
ᅡ생활을언급하지 않는경향이 있어 세부 주제를도출하기 어려웠다.
ᄇ
ᅩᆫ연구의 공헌은 인문학 연구와 빅데이터 분석 기술을성공적으로 융합할 수 있다는연구 방법을제 ᄉ
ᅵ한 것이다. 데이터베이스 구축의관점에서는소실 위기에 있는 종이 서신들을데이터베이스로 구축하 ᄋ
ᅧ 영구 보존이 가능해졌으며, 사용자들이 검색을 통하여 8만여 통의 서신을자유롭게 검색하고 분석을 ᄋ
ᅱ해 저장할 수 있도록하여 원하는정보를담고 있는서신의 분석 또한 가능하게 하였다. 서신의 표면 ᄌ
ᅥᆨ 주제는서신의 목적인 가족찾기였지만, 그리운고국에 발송하는서신이었으므로 그 외에 다양한 내 ᄋ
ᅭ
ᆼ들을 포함하고 있다. 그러나 이러한 내용이나 키워드들이 일반 주제였던 가족찾기를 위한 키워드에 더
ᇁ여 찾기가 어렵다는제약점이 있었다. 따라서 희소 키워드 중에서 중요한 키워드를찾기 위해 서신을 ᄐ
ᅳᆨ정 주제로 학습하고 로컬 대리 분석을적용하여 성공적으로 핵심 키워드를찾아낼 수 있음을보여주었 ᄃ
ᅡ.
보
ᆫ 논문은다음과 같이 구성된다. 2절에서 서신 빅데이터 설계 및 구현에 대해 구체적으로 살펴보고 3절에서 서신을 통해 나타난 거주지 및 출신지에 대한 분포를알아본다. 4절에서 토픽 모델링과 로컬 대 ᄅ
ᅵ 분석을적용한 서신 주제 분석에 대해 서술하고 마지막으로 5절에서 결론 및 향후 연구를제시한다.
2. 서신 데이터베이스 구축
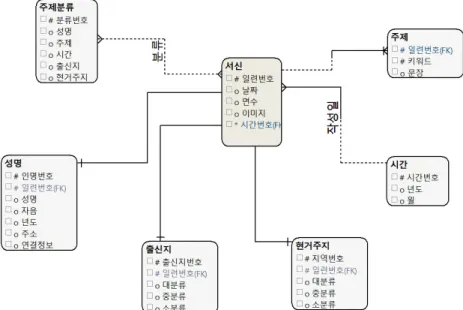
Figure 2.1 Entity-relationship diagram for the correspondence database
Figure 2.1은서신 데이터베이스 구축을위한 개체관계도를나타낸다. 각 서신마다 일련번호를부여 ᄒ
ᅡ였으며 한 서신은여러면으로 구성된다. 각 서신의 면에 해당 이미지를업로드하도록 하였다. 서신 ᄋ
ᅵ미지를업로드할 때 해당 서신의 내용을요약할 수 있는태그를 입력하도록하였다. 이는한글과 한자 ᄀ
ᅡ 섞여 있는편지의 전체 내용을데이터베이스에 입력하기에 어려움이 있기 때문에 최대한 원본서신의 ᄂ
ᅢ용을살릴 수 있도록형용사 그리고 명사 위주로 서신 내용을요약하여 입력하였다. 재중 동포 연구에 ᄉ
ᅥ 현거주지 및 한국에서의 거주지는이주에관련된유용한 의미가 있으므로 출신지와 현 거주지 정보를
과
ᆫ리하며, 서신의 주제 대분류는가족찾기 이외의 주제를찾아내는데 도움이 되도록서신 입력자가 정 ᄎ
ᅵ, 경제, 사회, 문화 등미리 정의된주제에 해당하는내용이 있다고 판단되면 지정하도록하였다. 한 ᄉ
ᅥ신이 여러 측면의 내용을 포함할 경우 다중지정이 가능하다. 마지막으로 발송인의 정보를관리하되 ᄀ
ᅢ인 정보는암호화하여 입력하도록하였다.
ᄀ
ᅮ축된 데이터베이스는 데이터베이스 관리자, 서신 입력자 및 일반 사용자로 권한을 나누어 개발 ᄒ
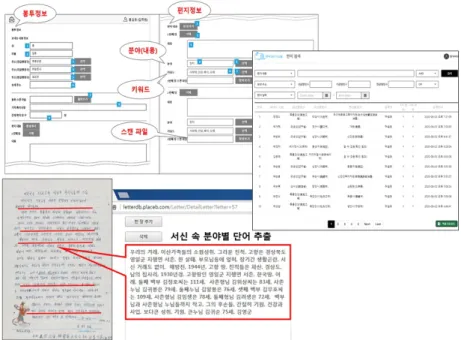
ᅡ였다. Figure 2.2는 서신 데이터베이스 구축 인터페이스를 나타낸다. 구현된 서신 데이터베이스는 https://letter.dongduk.ac.kr에서 운영중이다.
Figure 2.2 User interface for the correspondence database
Figure 2.2의 왼쪽 위의 그림은 서신 입력자가 서신을 데이터베이스에 입력하는 사용자 인터페이스 르
ᆯ보여준다. 모든서신은 봉투가 포함되어 있고, 봉투에는 발송지 정보가 기재되어 있으므로 봉투 이 ᄆ
ᅵ지도 데이터베이스에 업로드하였으며, 이때 서신 발송지를함께 입력하였다. 각 서신은한 장에서 최 ᄃ
ᅢ 10장까지로 구성되어 있으므로 새로운장을생성하여 서신 당 여러 장으로 구성된 편지들을 입력하 ᄃ
ᅩ록하였다. 한 장의 서신을 입력할 때 서신 내용을요약할 수 있도록태그 형태로 입력하도록하였는 ᄃ
ᅦ Figure 2.2의 아래 그림에서 볼수 있다. 마지막으로 오른쪽그림은 일반 사용자가 검색을한 후 검 새
ᆨ 내용을 분석을위해 파일로 저장할 수 있는 일반 사용자 인터페이스이다. 검색은태그 기반 검색, 주 ᄌ
ᅦ 기반 검색, 발송자 기반 검색, 발송지 기반 검색, 발송일 기준검색이 가능하다.
3. 서신 발송지 분포 및 출신지 분석 보
ᆫ장에서는서신의 내용을 분석하기에 앞서, 서신이 발송된 중국지역 분포를조사하고 서신에서 출 ᄉ
ᅵᆫ지로 언급된지역에 대한 분석 결과를시각화하여 제시한다.
3.1. 서신 발송지 분포 ᄉ
ᅥ신 발송지 분포는각 서신의 봉투에 기재되어 있는 주소를기반으로 하였으며, 총 81,827 통의 서 ᄉ
ᅵᆫ 중 1.39%에 해당하는 1,137통은발송지를 “알수없음”으로 분류하였는데 이는 중국의 행정구역이 변 ᄒ
ᅪ함에 따라 데이터베이스에 정의된행정구역에서 찾을수 없는경우를 뜻한다. 서신 발송지 분포는다 ᄋ
ᅳ
ᆷ과 같다. 대부분의 서신은재중 동포의 주요 이주 지역으로 알려진 동북 3성으로부터 발송되었으며 ᄀ
ᅵᆯ림성이 31,700통 (38.7%)으로 가장 많았고, 흑룡강성 29,950통 (36.6%),그리고 요녕성이 14,945통 (18.3%) 순으로 그 비율이 전체의 93.6%에 달하였다. 그 이외의 지역은내몽골자치구 1,067통 (1.3%), ᄇ
ᅦ이징시 847통 (1.0%) 등이었다.
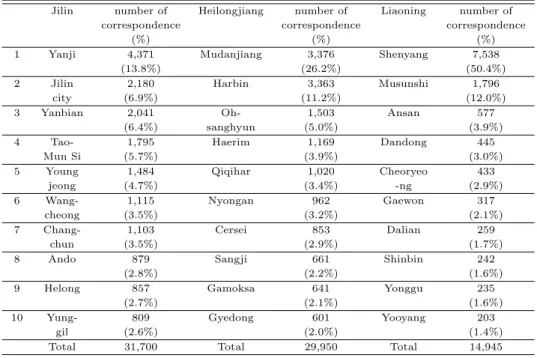
Table 3.1 Regional distribution
Jilin number of Heilongjiang number of Liaoning number of
correspondence correspondence correspondence
(%) (%) (%)
1 Yanji 4,371 Mudanjiang 3,376 Shenyang 7,538
(13.8%) (26.2%) (50.4%)
2 Jilin 2,180 Harbin 3,363 Musunshi 1,796
city (6.9%) (11.2%) (12.0%)
3 Yanbian 2,041 Oh- 1,503 Ansan 577
(6.4%) sanghyun (5.0%) (3.9%)
4 Tao- 1,795 Haerim 1,169 Dandong 445
Mun Si (5.7%) (3.9%) (3.0%)
5 Young 1,484 Qiqihar 1,020 Cheoryeo 433
jeong (4.7%) (3.4%) -ng (2.9%)
6 Wang- 1,115 Nyongan 962 Gaewon 317
cheong (3.5%) (3.2%) (2.1%)
7 Chang- 1,103 Cersei 853 Dalian 259
chun (3.5%) (2.9%) (1.7%)
8 Ando 879 Sangji 661 Shinbin 242
(2.8%) (2.2%) (1.6%)
9 Helong 857 Gamoksa 641 Yonggu 235
(2.7%) (2.1%) (1.6%)
10 Yung- 809 Gyedong 601 Yooyang 203
gil (2.6%) (2.0%) (1.4%)
Total 31,700 Total 29,950 Total 14,945
Table 3.1은 동북 3성의 하위 행정구역별 발송지 분포 중에서 상위 10개 지역을나타낸다. 길림성의 겨
ᆼ우는연길시, 길림시, 연변 조선족자치구, 도문시, 그리고 용정시의 순으로 서신이 발송되었으며, 흑 ᄅ
ᅭ
ᆼ강 성의 경우는 목단강시, 하얼빈시, 오상현, 해림현, 치치하얼시의 순으로 서신이 발송되었다. 마지 ᄆ
ᅡ
ᆨ으로 요녕성의 경우는 심양시, 무순시, 안산시, 단동시, 그리고 철령시 순으로 서신이 발송되었다.
ᄉ
ᅥ신 발송지의 분포가 재중 동포의 주거지 분포와 일치하지는않을지라도 재중 동포의 주거지 분포를 ᄋ
ᅲ추해볼수 있는기초 자료로활용해 볼수 있다. 시사주간에서 발표한 2012년도 기준 재중동포 주거 ᄌ
ᅵ 분포에 따르면 길림성 104만명, 요녕성 32만 8천명, 그리고 흑룡강성이 24만명인데 비해서 서신 발 ᄉ
ᅩ
ᆼ지는 혹룡강성에서 발송된서신이 요녕성에서 발송된서신보다 많았다. 또한 가장 많은서신이 발송 되
ᆫ 길림성의 연길시, 길림시, 연변조선족자치구, 그리고 도문시 등이 평지에 주로 분포하고 있는것으로
ᄇ
ᅩ아 재중동포들이 주로 벼농사에 종사하고 있음을확인할 수 있었다. 현재에도 재중 동포들은계속적 ᄋ
ᅳ로 이주하고 있으며, 특히 한중수교이후 한국으로의 재이주가활발히 이루어지고 있어 연변조선족자 ᄎ
ᅵ구의 경우 점차 조선족 집거촌이 사라지고 있는현실이다.
3.2. 재중 동포의 출신지 분석 ᄌ
ᅢ중 동포의 중국으로의 이주는다양한 경로를거치므로 서신 속에서 출신지로 언급된지명을 분석하 느
ᆫ것은재중 동포의 이주사에 있어서도 중요한 자료가될수 있다. 대부분의 서신이 가족찾기를 목적 ᄋ
ᅳ로 발송되었고, 가족을언급하기 위해서는 본인이 살았던 고향을언급한 경우가 대부분이다. 따라서 ᄃ
ᅦ이터베이스로 구축할 때 제 2장에서 설명한 바와 같이 출신지 항목을만들고, 서신을 입력할 때, 서신 ᄋ
ᅴ 내용 중에서 고향을명확히 언급한 경우에 직접 입력하도록하였다. 고향에 대한 언급이 명확한 서신 ᄎ
ᅩᆼ 29,077통 중에서 언급된지명을기준으로 대한민국과 북한으로 나누었으며, 대한민국과 북한 내에서 ᄃ
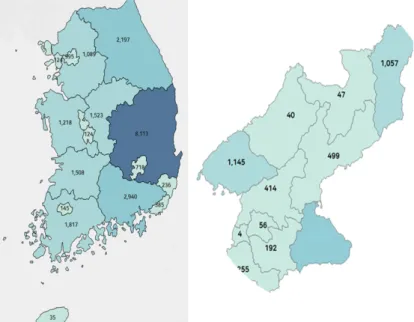
ᅩ 단위로 분석을 실시하였다.
Figure 3.1은 대한민국과 북한의 도 단위 분석을 시각화 한 결과이다. 서신에서 현재의 행정구역이 ᄋ
ᅡ닌 출신지명에 대해 언급한 경우, 데이터베이스 입력자가 현재의 해당 출신지로 변경하여 입력하도록 ᄒ
ᅡ였다. 출신지가 대한민국인 서신은 총 23,171통으로 79.7%를차지하였고, 북한인 서신은 총 5,906통 ᄋ
ᅳ로 20.3%를 차지하였다. 대한민국이 출신지인 경우 경상북도가 월등하게 높았고 다음이 경상남도, ᄀ
ᅡᆼ원도, 그리고 전라남도 순이었다. 출신지가 경상도가 많은이유는 일제 강점기에 일본에서 가장 가까 ᄋ
ᅯᆻ기 때문인 것으로 보인다. 북한의 경우 평안북도, 함경북도 그리고 함경남도의 순으로 나타났다. 강 ᄋ
ᅯ
ᆫ도는대한민국과 북한 모두에 속할 수 있으나 북한쪽의 강원도는 소수였으므로 대한민국으로 분류하 ᄋ
ᅧᆻ다.
Figure 3.1 Visualization of hometown distribution
4. 태그를 활용한 서신 내용 분석 보
ᆫ장에서는데이터베이스 구축시 생성된태그를활용하여 토픽 모델링을적용하여 대분류 내의 세부 ᄌ
ᅮ제를찾아내는과정을서술한다. 또한 정치와 경제 분야의 서신을나이브 베이즈를적용하여 서신을 ᄌ
ᅮ제별로 자동 분류한 다음,로컬 대리분석을적용하여 서신별 핵심 키워드를추출한 과정에 대하여 자 ᄉ
ᅦ히 설명한다.
4.1. 토픽 모델링을 적용한 세부 주제 추출 ᄐ
ᅩ픽 모델링은 문서 속에 잠재되어 있는주제를단어의 통계적확률 분포에 의해 찾아내는비지도학습 ᄋ
ᅴ 일종으로 일반적으로 텍스트에 적용되어왔으나, 유전자정보, 네트워크 구조 등을 분석하는데도 널리 화
ᆯ용되고 있다. 본연구에서는 데이터베이스 구축과정에서 서신의 내용을파악하기 위해 입력자가 정 ᄎ
ᅵ, 경제, 사회, 문화 등미리 지정해 둔범주로 분류하도록한 다음,대분류 내에서 세부 주제를추출하 느
ᆫ데 토픽 모델링을적용하였다.
ᄌ
ᅢ중 동포의 한중수교 이전의 생활상을파악하기 위해서 사회, 문화 대분류를정의하였으나, 두 주제 ᄀ
ᅡᆫ의 큰차이가 나타나지 않았고, 가족찾기 내용과 많은부분겹쳐진 토픽이 나타난 세부 주제를도출 ᄒ
ᅡ기 어려웠다. 경제 분야의 서신 내용의 대부분은 물품요청이 주를이루었으며, 도출된단어들은사전 ᄅ
ᅲ, 학습서 등자기 개발을위한 서적과 잡지, 달력, 녹음테이프 등고국의 소식을 들을수 있거나 연관 되
ᆫ 물품들이 주를이루었다. 가장 의미 있는세부 주제를도출할 수 있었던 대분류는정치 분야였으며, ᄐ
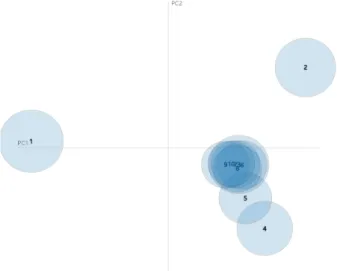
ᅩ픽모델링을적용한 시각화 결과는 Figure 4.1과 같다.
Figure 4.1 Visualization of topic modeling
Figure 4.1은세부 주제를 10개로 지정했을경우, 나타나는토픽들의 독립성을 보여준다. 토픽 1과 ᄐ
ᅩ픽 2는다른토픽들과 매우 뚜렷한 독립성을갖는토픽으로 정치 분야에 속한 서신 내에서 구체적 세 ᄇ
ᅮ 토픽으로 볼수 있다. 토픽 3에서 토픽 10까지는그림에서 보듯이 토픽간의 겹침 현상이 심하고 이 르
ᆯ바탕으로 볼때 대부분의 서신에 포함된가족찾기관련 내용임을알 수 있다. 서신의 목적이 가족찾 ᄀ
ᅵ였으므로 거의 대부분의 서신이 가족을찾기 위한 내용이 포함되어 있다는 특징이 있으며, 이들 중에 ᄉ
ᅥ 그 밖의 다른주제를언급한 경우 토픽 1과 토픽 2와 같이 매우 분리된토픽으로 시각화된다. 키워드
ᄎ
ᅮ출을 위해서는정보 검색에서 많이 사용되는 Manning 등 (2008)이 제시한 term frequency-inverse document frequency (TF-IDF)가중치 값을모두 적용하였다. Kim 등 (2016) TF-IDF를적용하면 보 ᄃ
ᅡ 효율적으로 키워드를추출할 수 있다는것을보여주었다.
Table 4.1에서 토픽 1과 토픽 2을 구성하는상위 30개의 키워드 중에서 다른주제와 겹치지 않는핵 시
ᆷ 키워드 10개를보여준다. 먼저, 토픽 1을구성하는핵심 키워드는 북한, 요구, 남북,자본주의, 암투, ᄇ
ᅡᆼ조, 발전, 통일, 비극,그리고 건설로 남북한관계를주제로 언급하였음을보여준다. 특히, 당시의 대 ᄇ
ᅮᆨ정책이나 남북 통일의 염원등을언급한 서신이 다수 있음을알 수 있다. 토픽 2는한국정부에 대한 ᄋ
ᅭ청이라는주제가 포함되어 있음을알 수 있다. 서신을 통해 재중 동포들은고국방문을요청하였고 가 ᄌ
ᅩ
ᆨ찾기 프로그램의 성과로서 재중 동포들의 한국방문이 이루어졌다. 또한 정부에 재중 동포에 대한 대 ᄋ
ᅮ를요청하는내용도 다수 포함되어 있다.
Table 4.1 Selected 10 keywords
Topic Subject Keywords
1 Relationship between North Korea, request, South Korea South Korea and and North Korea, capitalism, veiled North Korea enmity, connivance, development,
unification, tragedy, establishment 2 Requests to Korean government, regret, commings and government goings, visit, eagerness, cooperation,
homeland, opportunity, request, effort
4.2. 로컬 대리 분석을 적용한 핵심 키워드 추출
4.1절에서 살펴본토픽 모델링은 Kim 등 (2016)의 연구에 따르면 단어의 빈도수나 TF-IDF 가중치 ᄀ
ᅡ
ᆹ을 사용하므로 희소하지만 중요한 의미가 있는키워드를찾아내기 어렵다. 재중 동포 서신 데이터베 ᄋ
ᅵ스 특성상, 자주 사용되는단어들은한국지명, 중국지명, 호칭 등으로 고국에 있는가족을찾는데 필 ᄋ
ᅭ한 단어들이 대부분이다. 따라서 서신으로부터 인문학적 의미를지닐 수 있는키워드를찾고자 한다 ᄆ
ᅧᆫ 단어의확률 분포가 아닌 다른방법을적용하는것이 적절하다. 특히 서신 한 장 속에서 중요한 의미 ᄅ
ᅳᆯ갖는키워드를 추출한다면, 데이터베이스화 되어있는서신으로부터 의미를찾는데 큰기여를할 수 이
ᆻ다.
ᄋ
ᅵ를위해 로컬 대리 분석 기법을서신에 적용하였다. 로컬 대리 분석이란 데이터 한 개에 대해 기계
℡℡학습을 통해 분류된 결과를해석할 수 있는 분석 기법이다. 학습기법과관계없이 모델을설명할 수 이
ᆻ으며, 개별 데이터에 대하여 해석을해내는것이 로컬 대리 분석의 특징이다. 본연구에 로컬 대리 분 ᄉ
ᅥ
ᆨ을 적용하기 위해서 서신들의 주제 분류를 위해 나이브 베이즈 알고리즘을 사용하였다. Kowsari 등 (2019)이 제시한 바와 같이 텍스트를이진 분류하거나 다중 분류하는데는다양한 기계 학습알고리즘을 ᄀ
ᅩ려해 볼수 있다. 특히 요즈음엔 딥러닝의 순환신경망이 언어의 의미를파악하는데 효율적인 것으로 ᄋ
ᅡ
ᆯ려졌으나 본연구에서 사용된텍스트는이미지로 정의된서신을요약하기 위한 태그였기 때문에 문맥 ᄋ
ᅴ 파악보다는단어의확률 분포를활용하는나이브 베이즈를선택하였다. Kim 등 (2017)의 연구에 따 ᄅ
ᅳ면 나이브 베이즈 알고리즘이 다양한 도메인의 텍스트 분류에 효율적임이 알려졌다.
Figure 4.2는나이브 베이즈로 정치 분야 서신과 경제 분야의 이진 분류 모델을생성한 다음, 정치 분 ᄋ
ᅣ라고 예측한 서신에 로컬 대리 분석을적용하여 시각화한 것이다. 왼쪽그림에서 0은경제 분야를나 ᄐ
ᅡ내고 푸른색으로, 1은정치 분야를나타내며 각 분야에서 중요한 변수가 순차적으로 등장한다. 0에 해 ᄃ
ᅡᆼ하는경제 분야관련 키워드가 없는것은해당 서신이 100% 정치 분야 서신이기 때문이다. 이 서신을 저
ᆼ치로 분류하는데 기여한 중요 키워드는핵문제, 유엔, 이중성, 륙자 회담, 모순, 공개화, 베이커장관,
ᄋ
ᅱ험성, 핵사찰, 그리고 선언이라는키워드였다. 오른쪽그림에서는보다 중요한 단어가 진한 주홍색으 ᄅ
ᅩ 시각화되어 나타난다. 로컬 대리 분석의 특징은데이터마다 적용이 가능하다는 것으로 텍스트의 경 ᄋ
ᅮ 문서마다 적용이 가능하다.
Figure 4.2 Visualization of local surrogate for the politics subject
서
ᆯ명가능 인공지능기술의 일종인 로컬 대리 분석은기계 학습모델에서 모델의 예측을설명하기 위해 ᄉ
ᅡ용되고 있다. 본연구에서는 서신 데이터베이스를활용하는데 있어 원하는 서신을찾고 이미지로 저 ᄌ
ᅡᆼ된서신을모두 읽지 않고도 해당 주제에 대한 핵심 키워드를찾는데활용하기 위해 적용하였다. 예를 ᄃ
ᅳ
ᆯ어 정치 분야의 서신을 분석하고자 한다면, 먼저 높은확률 순서로 기계가 예측한 정치 분야의 서신을 ᄉ
ᅥᆫ정한 해당 서신들에 로컬 대리 분석을적용하여 중요 키워드를 찾아내는것이다. 총 8만통에 달하는 ᄉ
ᅥ신을모두 읽고 서신의 내용 중정치 분야에서 언급된주제 및 핵심 키워드들을사람이 찾는다는것은 ᄀ
ᅥ의 불가능한 일일 것이다. 로컬 대리 분석은단순히 기계의 예측결과를설명하는데서 벗어나 각 데 ᄋ
ᅵ터에서 중요한 역할을하는희소 키워드를도출해 냄으로써 기존의 단어확률 분포로는찾아낼 수 없 느
ᆫ 중요한 키워드를찾아낼 수 있다.
5. 결론 및 향후 연구 보
ᆫ연구에서는 KBS한민족방송가족찾기 프로그램으로 발송된재중 동포 서신 8만여 통에 대하여 ᄃ
ᅦ이터베이스를구축하고 검색 기능을 통해 원하는서신을검색 및 저장한 다음토픽 모델링과 로컬 대 ᄅ
ᅵ 분석을적용하여 가족찾기 이외의 서신 내용을요약할 수 있는핵심 키워드를도출하는방법을제시 ᄒ
ᅡ였다. 이미 발송된지 짧게는 30년에서 45년 가까이된서신들이고 시기적으로 한중수교 이전의 재 주
ᆼ 동포들로부터 발송된서신들이므로 그 학술적 가치가 높아 데이터베이스로 구축하는작업 자체가 무 ᄎ
ᅥᆨ 가치 있는작업이다. 또한 아직까지 인문학 연구에 빅데이터를활용하는방법론이 적용된 연구가 드 ᄆ
ᅮ
ᆯ다는것을감안하면, 재중동포의 생활상을파악하기 위해 빅데이터 분석 기술을적용하여 인문학과 분 ᄉ
ᅥᆨ 기술의 융합을도모한 측면에서 커다란 의미가 있다.
ᄉ
ᅥ신 데이터베이스로부터 찾아내고자 한 주제나 핵심 키워드는서신의 본 목적인 가족찾기를제외한
ᄂ
ᅢ용에서 나타난다. 이를위해 서신을 입력하는단계에서 서신 입력자가 서신의 내용을요약할 수 있는 ᄐ
ᅢ그를 입력하도록하였으며, 서신의 내용이 분류될수 있는대분류를정치, 경제, 사회, 문화 등으로 나 ᄂ
ᅮ어 다중선택할 수 있도록하였다. 검색 과정에서 이렇게 입력한 태그 기반 검색 및 주제 기반 검색이 ᄀ
ᅡ능하고, 검색 결과를따로 저장하여 분석 작업에활용하도록하였다.
ᄃ
ᅢ분류 내의 세부 주제를찾기 위해 토픽 모델링을 실시하였다. 정치, 경제, 사회, 문화의 모든대분 ᄅ
ᅲ에 대해 토픽 모델링을적용한 결과 독립적인 주제를도출할 수 있는 분야는정치 분야였다. 정치 분 ᄋ
ᅣ에 토픽 모델링을적용해 시각화 한 결과 2개의 독립적 세부 주제를도출하였으며 이는남북관계에 ᄃ
ᅢ한 내용과 한국정부에게 요청하는내용이었다. 남북관계에 대한 주제에는대북 문제, 통일 기원,남 ᄒ
ᅡᆫ의 발전 등이 키워드로 등장하였으며, 한국정부에게 요청한 내용은 고국 방문요청, 정부에 대한 서 ᄋ
ᅮᆫ함 등이 키워드로 등장하였다. 실제로 이 서신들의 결과로 재중 동포의 고국방문이 이루어지기도 하 ᄋ
ᅧᆻ다.
ᄐ
ᅩ픽 모델링을 통해 도출된키워드들은 TF-IDF값을갖는단어들의확률 분포를기반으로 하기 때문 ᄋ
ᅦ 정치 분야에서 의미 있는서신들을찾는데 어려움이 있다. 따라서 정치 분야의 서신과 그 외 분야의 ᄉ
ᅥ신을 나이브 베이즈로 학습하여 정치 분야의 서신 중 확률이 높은 서신을 찾아내고, 그 서신에 로컬 ᄃ
ᅢ리 분석을적용하여 정치 분야로 분류하는데큰영향을미친 키워드를선정하였다. 이 방법은 본연구 ᄋ
ᅦ 사용된서신들의 많은단어들이 가족호칭, 중국지명, 한국지명 등가족을찾기 위한 단어들의 비중 ᄋ
ᅵ 크기 때문에 드러나지 못했던 희소 키워드들을찾아내는데큰역할을할 수 있다. 100%확률로 정 ᄎ
ᅵ 서신으로 분류된서신의 핵심 키워드는핵문제, 유엔, 핵사찰, 위험성, 륙자회담, 베이커 장관,모순, ᄉ
ᅥᆫ언 등으로 토픽 모델링에서 찾을수 없는 중요한 키워드들을찾아낼 수 있었다.
보
ᆫ 연구의 한계점은 다음과 같다. 한중 수교 이전의 재중 동포의 삶과 문화에 대해 연구하기 위해서 ᄂ
ᅳᆫ사회 및 문화로 분류된서신들로부터 의미 있는결과를도출할 것으로 기대했으나, 이 두 분야는 실 지
ᆯ적으로 가족찾기 주제와 겹쳐지는주제들로 구성된키워드만 도출할 수 있었다. 고향의 가족을찾기 ᄋ
ᅱ해 편지를쓰다 보니 그 내용안에 현재의 삶이 포함되어 있는서신들도 다수였고, 당시의 상황 상 개 ᄋ
ᅵᆫ적 사실을많이 언급하지 않아 특징이 있는키워드를도출하는것이 어려웠다. 현재 정치 분야에 대해 ᄉ
ᅥ만 토픽 모델링 및 로컬 대리 분석으로 의미 있는결과를도출하였으나, 서신으로부터 가족찾기 연관 ᄂ
ᅢ용들을자동적으로 학습시켜 이 서신들을제거하고 남은서신들을다시 학습하도록한다면, 경제, 사 ᄒ
ᅬ, 문화 측면에서도 새롭게 도출할 수 있을것으로 기대된다.
References