Kor. J. Hort. Sci. Technol. 28(4):627-637, 2010
토마토 품종 구분을 위한 SNP 분자표지 개발
배중환1ㆍ한 양2ㆍ정희진1ㆍ권진경1ㆍ채 영3ㆍ최학순3ㆍ강병철1*
1서울대학교 농업생명과학대학 식물생산과학부, 2요녕대학교 생명과학부, 3농촌진흥청 국립원예특작과학원
Development of a SNP Marker Set for Tomato Cultivar Identification
Joong-Hwan Bae
1, Yang Han
2, Hee-Jin Jeong
1, Jin-Kyung Kwon
1, Young Chae
3, Hak Soon Choi
3, and Byoung-Cheorl Kang
1*1
Department of Plant Science, and Plant Genomics and Breeding Institute, College of Agriculture and Life Sciences, Seoul National University, Seoul 151-921, Korea
2
School of Life science, Liaoning University, Liaoning 110-036, China
3
National Institute of Horticultural & Herbal Science, Suwon 440-310, Korea
Abstract. The consumption of tomato has greatly increased recently in Korea, and a large number of tomato cultivars are commercially available in the market. However, identification of tomato cultivars by morphological traits is extremely difficult because of the narrow genetic diversity of breeding lines. Therefore, it is necessary to develop molecular markers for cultivar identification in tomato. In this study, we surveyed single nucleotide polymorphism (SNP), and developed SNP marker sets for tomato cultivar identification. SNP markers were developed based on conserved ortholog set II (COSII) and intron-based markers derived from pepper EST sequences, and marker polymorphism was tested using high-resolution melting (HRM) analysis. A total of 628 primer sets was tested, and 417 primer sets amplifying single bands were selected. Of the 417 primer sets, 70 primer sets showing HRM polymorphism among 4 inbred lines were selected. Eleven markers were selected from the 70 primer sets and subjected to cultivar identification analysis. Thirty two commercial tomato cultivars were successfully identified using the marker set.
Additional key words: high resolution melting, single nucleotide polymorphism, Solanum lycopersicum
*Corresponding author: [email protected]
※ Received 29 January 2010; Accepted 6 April 2010. 본 연구는 농촌진흥청 농업과학기술개발 공동연구사업(과제번호: 200806A01081026)과 농림수산식품부 농림기술개발사업의 채소병리검정지원사업단(과제번호: 609002-5)의 지원에 의해 이루어졌으며 이에 감사 드립니다.
서 언
토마토(Solanum lycopersicum L.)는 전 세계적으로 가장 많이 재배되는 채소 작물로서, 2009년 현재 국내에는 총 522 종의 토마토 품종이 시판되고 있으며 매년 신품종이 계속해 서 개발 및 수입되고 있다. 이처럼 토마토 품종의 개발에도 불구하고, 육종 소재의 유전적 유사성이 매우 높아 토마토 품종간 표현형이 큰 차이를 보이지 않으며, 이로 인해 시판 토마토 품종의 식별이 매우 어렵다. 또한 우리나라는 1991 년 국제식물신품종보호동맹(UPOV) 가입과 1997년 종자산 업법의 발효에 따라 육종가의 지적 재산권을 보호하기 위한 제도적 장치가 마련되었고, 해외 농산물과 국산 농산물의 구분에 대한 필요성이 증대됨에 따라 분자표지를 이용한 품
종 구분 기술의 정립이 필요한 실정이다.
현재까지 토마토 품종 구분에 쓸 수 있는 분자표지로는 restriction fragment length polymorphism(RFLP)(Stevens 등, 1995; Van Ooijen 등, 1994), amplified fragment length polymorphism(AFLP)(Park 등, 2004), random amplified poly- morphic DNAs(RAPD)(Park 등, 2000; Qian 등, 2001; Stevens 등 , 1995), single sequence repeat(SSR)(Cooke 등, 2003; He 등, 2003; Kwon 등, 2006) 등이 개발되어 왔으나, 전기영동 이나 제한효소의 처리 등 PCR 이후에 과정 등이 복잡하고 많은 시간이 소모되는 단점이 있으며 일부 분자표지는 재현 성이 떨어지는 단점이 있다.
단일 염기서열 다형성(single nucleotide polymorphism:
SNP)이란 DNA 염기서열의 치환 혹은 1-2bp 소실에 따라
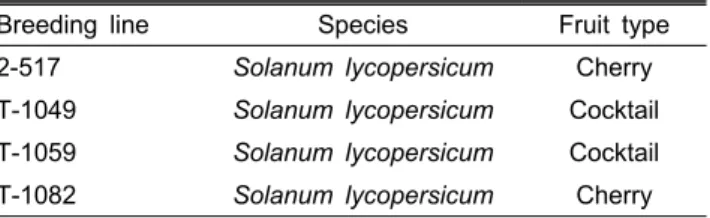
Table 1. Tomato breeding lines used for surveying DNA marker polymorphism.
Breeding line Species Fruit type
2-517 Solanum lycopersicum Cherry
T-1049 Solanum lycopersicum Cocktail T-1059 Solanum lycopersicum Cocktail T-1082 Solanum lycopersicum Cherry
두 개체간 염기서열이 서로 다르게 나타나는 현상이다. SNP 는 식물과 동물의 다양한 유전 연구와 응용에 가능하기 때 문에 최근 들어 많은 연구가 이루어지고 있다(Kim과 Misra, 2007). 인간은 평균 1000개 염기서열당 1개의 SNP가 1개씩 존재하는 것으로 알려져 있으며(Wang 등, 1998) 최근의 연 구 결과 토마토에서는 1,647개의 염기서열 당 1개의 SNP가 존재하는 것으로 보고 되었다(Van Deynze 등, 2007a). 이러 한 염기서열의 변화는 비암호화 영역(non-coding region)에 서 가장 높게 나타나며, 암호화 영역(coding region) 안에서 는 인트론 영역이 엑손 영역에 비해 서열 변화의 정도가 높 은 것으로 알려져 있다(Ching 등, 2002; Van Deynze 등, 2007b). 인트론의 서열은 서로 다른 종 간에도 동일한 형태 로 보존되어 있는 경우가 많기 때문에 SNP를 찾기 위하여 인트론이나 비암호화 영역으로부터 프라이머를 만드는 방 법이 이용된다(Fourmann 등, 2002). 이러한 염기서열의 차 이를 이용한다면 매우 가까운 품종 간에도 구분이 가능한 분자 분자표지를 개발할 수 있다.
SNP를 탐색하기 위한 방법으로 염기서열 분석, DNA microarray(Rapley와 Harbron, 2004), temperature gradient gel electrophoresis(TGGE)(Balogh 등, 2004), single strand conformation polymorphism(SSCP)(Orita 등, 1989), denaturing high performance liquid chromatography(DHPLC)(Oefner 와 Underhill, 1995), HRM(Gundry 등, 2003) 분석 등이 개 발되어 왔으며, 이와 같은 SNP 탐색 도구 중 최근 들어 HRM 분석이 많이 이용되고 있다. HRM 분석은 PCR을 기반으로 하는 분석법으로 기존의 방법에 비해 SNP를 빠른 시간에 탐색해 낼 수 있는데, 이중 나선 DNA를 구성하고 있는 염 기 쌍의 조합(A=T, G=C), 길이, GC 비율 등에 따라 이중 나선이 단일가닥으로 변성되는 온도가 다른 점을 이용한 방 법이다(Montgomery 등, 2007). 즉, 일반적인 PCR 반응 과 정에 DNA 이중나선에 특이적으로 결합해 형광을 띠는 시 료를 첨가하고, PCR 반응이 끝난 후 온도를 서서히 높이면 PCR 산물은 단일가닥으로 변성되며 이와 함께 감소하는 형 광 값을 측정한다. 이때 비교하고자 하는 두 DNA 염기서열 상에 SNP가 존재할 경우 Tm 값이 달라지기 때문에 형광 값의 감소 양상이 다르게 나타나 SNP 유무를 탐색할 수 있 다. HRM 분석은 전기영동을 통해 DNA의 증폭 여부를 확 인하는 과정과 DNA 염기서열의 해독과정이 불필요하기 때 문에 기존의 방법과 비교해 매우 빠르고 비용이 저렴한 SNP 탐색법이다(Hoffmann 등, 2007). 본 연구는 국내에서 시판 중인 토마토 품종을 구분하기 위해 품종 구분이 가능한 SNP 분자표지를 개발하고 품종 구분 기술을 정립하는데 목적이 있다.
재료 및 방법
토마토 품종 및 DNA 추출
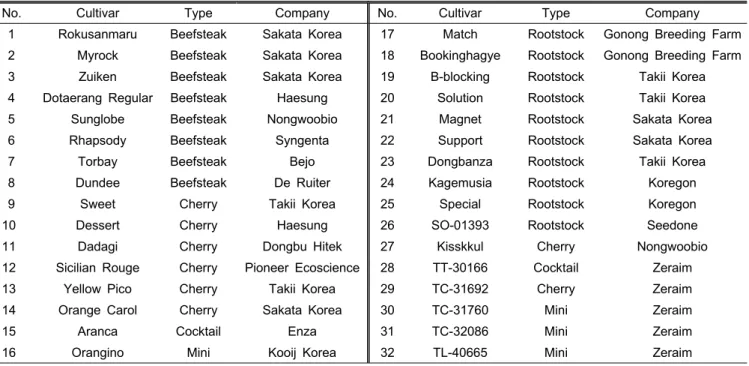
다형성 조사를 위하여 국립원예특작과학원에서 육성 모 본으로 사용하고 있는 4개의 계통(2-517, T-1049, T-1059, T-1082)을 이용하였고(Table 1), 품종 구분 SNP 분자표지 개발을 위하여 국내에서 시판중인 32개의 토마토 품종(Table 2)을 이용하였다. 본엽기의 3-4잎을 채취하여 튜브에 텅스 텐 구슬 2개를 넣고 Tissue Lyser(Qiagen, Germany)를 이용 하여 마쇄하였다. 마쇄한 토마토 잎으로부터 DNeasy
Ⓡ96 Plant Kit(Qiagen, USA)를 이용해 각 품종의 DNA를 추출하 였다(Prince 등, 1997). 추출한 DNA는 NanoDrop
ⓇND-1000 (Nanodrop Technologies, USA)를 이용하여 260nm에서 정 량하고 최종 농도가 20ng・µL
-1가 되도록 희석하였다.
프라이머 제작
토마토의 SNP 분자표지를 개발하기 위해서 코넬대학교 에서 운영하고 있는 Solanaceae Genome Network(SGN)과 National Center for Biotechnology Information(NCBI)를 이 용하여 COS II 분자표지를 선발하였다. The Arabidopsis Information Resource(TAIR)에서 얻은 애기장대의 염기서 열 정보와 고추의 EST를 비교 분석해 인트론 기반 분자표 지를 선발하였으며 SSR 분자표지와 비암호화 영역 분자표 지 또한 고추 EST로부터 선발하였다. COS II 분자표지 372 개, 인트론 기반 분자표지 115개, 비암호화 영역 분자표지 6개, SSR 분자표지 135개, 총 628개의 분자표지를 이용해 본 실험을 수행하였다.
PCR 분석
PCR을 위한 반응액의 총 부피는 25µL로 하였으며 유전
체 DNA 60ng, 1× PCR 완충용액(2.0mM MgCl
2, 70mM KCl,
100mM Tris-HCl), 2.5µM dNTPs, 15pmol primer(Bioneer,
Korea), Desai와 Pfaffle(1995)의 방법으로 추출한 0.2 unit
home-made Taq DNA polymerase를 첨가하였다. My Cycler
(Bio-Rad, USA)를 이용하여 PCR을 수행하였으며, PCR 조
건은 95℃에서 5분 동안 일차 변성하고, 95℃에서 30초, 5
Table 2. Tomato cultivars used in this study.
No. Cultivar Type Company No. Cultivar Type Company
1 Rokusanmaru Beefsteak Sakata Korea 17 Match Rootstock Gonong Breeding Farm 2 Myrock Beefsteak Sakata Korea 18 Bookinghagye Rootstock Gonong Breeding Farm
3 Zuiken Beefsteak Sakata Korea 19 B-blocking Rootstock Takii Korea
4 Dotaerang Regular Beefsteak Haesung 20 Solution Rootstock Takii Korea
5 Sunglobe Beefsteak Nongwoobio 21 Magnet Rootstock Sakata Korea
6 Rhapsody Beefsteak Syngenta 22 Support Rootstock Sakata Korea
7 Torbay Beefsteak Bejo 23 Dongbanza Rootstock Takii Korea
8 Dundee Beefsteak De Ruiter 24 Kagemusia Rootstock Koregon
9 Sweet Cherry Takii Korea 25 Special Rootstock Koregon
10 Dessert Cherry Haesung 26 SO-01393 Rootstock Seedone
11 Dadagi Cherry Dongbu Hitek 27 Kisskkul Cherry Nongwoobio
12 Sicilian Rouge Cherry Pioneer Ecoscience 28 TT-30166 Cocktail Zeraim
13 Yellow Pico Cherry Takii Korea 29 TC-31692 Cherry Zeraim
14 Orange Carol Cherry Sakata Korea 30 TC-31760 Mini Zeraim
15 Aranca Cocktail Enza 31 TC-32086 Mini Zeraim
16 Orangino Mini Kooij Korea 32 TL-40665 Mini Zeraim
5℃에서 30초, 72℃에서 60초의 변성, 결합, 신장 3단계를 35번 반복한 후, 최종 신장 단계로 72℃에서 10분 간 반응 하였다. 증폭된 DNA 산물은 1% agarose 젤에서 전기영동 한 후 밴드를 확인하였다.
HRM 분석
HRM 분석은 Park 등(2009)의 방법에 따라 진행하였다.
HRM 분석을 위한 반응액의 총 부피는 20µL로 하였으며 유 전체 DNA 주형은 100ng, 1× PCR 완충용액(2.0mM MgCl
2, 70mM KCl, 100mM Tris-HCl), 2.5μM dNTPs, 1.25mM dsDNA inter-calating dye SYTO
Ⓡ9(Invitrogen, USA), 10pmol primer(Bioneer, Korea), Desai와 Pfaffle(1995)의 방법으로 추출한 0.2 unit home-made Taq DNA polymerase를 첨가하 였다. PCR 조건은 95℃에서 4분 동안 일차 변성시키고, 95℃
에서 15초, 55℃에서 15초, 72℃에서 30초의 변성, 결합, 신 장 3단계를 50번 반복하였다. PCR이 수행된 이후 90℃에서 1분, 40℃에서 1분간 유지한 후 70℃에서 95℃까지 초당 0.1℃씩 온도를 올려가면서 HRM 분석을 실시하였다. HRM 분석을 위한 real time PCR 기기로 Corbett Rotor-Gene 6000 real-time rotary analyzer(Corbett Research, Australia)를 이용 하였으며 melting curve 등 HRM 분석은 Corbett Rotor-Gene 6000 Application Software version 1.7(Corbett Research, Australia)을 사용하여 실시하였다.
품종간 유사성 분석
HRM 분석을 통해 얻은 normalized graph와 difference
graph를 비교 분석하여 품종간의 유사성을 분석하였다. 각 분자표지 유형별로 품종간의 그래프 confidence 값이 90%
이상인 유형을 보이는 품종들을 짝지어 그룹화하였다. 각 분자표지 유형별로 가장 많은 품종이 나타내는 그래프의 유 형에 1을 부여하고 같은 유형을 보이는 품종의 개수가 감소 함에 따라 순차적으로 9까지의 숫자 값을 부여하였다. 별도 의 염기 서열 해독 작업을 거치지 않고 품종간의 계통도 분 석을 하기 위해 그래프 유형별로 부여된 숫자 값에 임의적 으로 두 자리의 염기 서열(1=AA, 2=AT, 3=AG, 4=AC, 5=TA, 6=TT, 7=TG, 8=TC, 9=GA)을 대입하였다. 각 품종 별로 분자표지의 5’ 3’방향의 프라이머 서열과 그래프 유형에 따른 두 자리의 염기서열을 나열하였다. 총 11개 분자표지 와 임의의 서열을 나열해서 얻은 염기서열 정보를 바탕으로 MEGA version 4(Tamura 등, 2007)를 이용해 품종간의 계 통 분석을 수행하여 계통도를 나타내었다.
결과 및 고찰
토마토 품종 구분을 위한 SNP 분자표지 개발
HRM 분석을 통한 SNP 탐색을 할 때, 효율적인 HRM 분석 결과를 얻기 위해서는 다양한 조건이 고려되어야 한다 . 단일 밴드로 증폭이 되며 , PCR 산물이 500bp 이하일 때 SNP 를 구별하기가 가장 용이하며(Reed와 Wittwer, 2004), PCR 산물내의 SNP의 숫자가 하나일 때 HRM 분석을 통한 SNP 의 분석이 가장 용이한 것으로 증명되었다(Park 등, 2009).
PCR의 산물의 크기와 단일 밴드의 증폭 여부를 확인하기
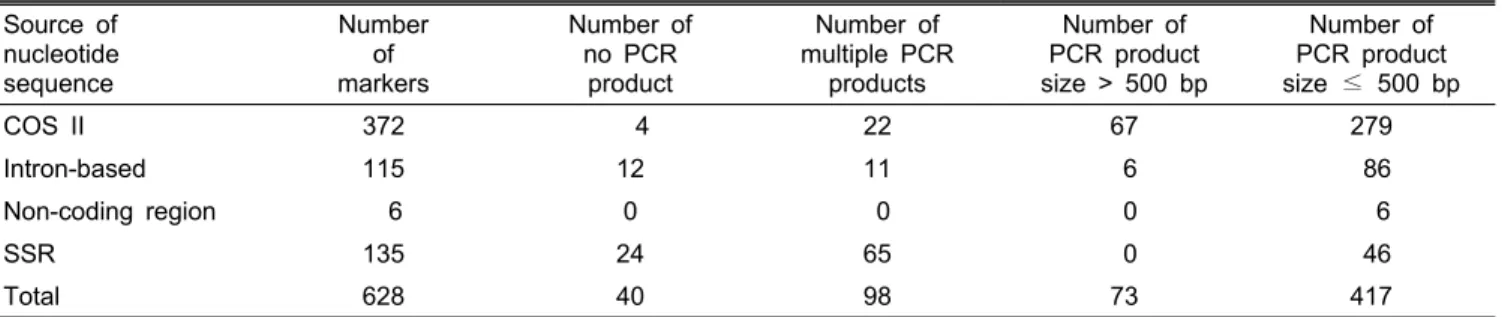
Table 3. Source of nucleotide sequence, number of PCR product, and PCR product size.
Source of nucleotide sequence
Number of markers
Number of no PCR
product
Number of multiple PCR
products
Number of PCR product size > 500 bp
Number of PCR product size ≤ 500 bp
COS II 372 4 22 67 279
Intron-based 115 12 11 6 86
Non-coding region 6 0 0 0 6
SSR 135 24 65 0 46
Total 628 40 98 73 417
Table 4. Summary of markers showing polymorphism using HRM analysis.
Marker type Number of markers Number of markers
showing polymorphism
Percentage of polymorphism (%)
COS II marker 279 42 15.05
Intron-based marker 86 18 20.93
Non-coding region marker 6 2 33.33
SSR marker 46 8 17.39
total 417 70 16.78
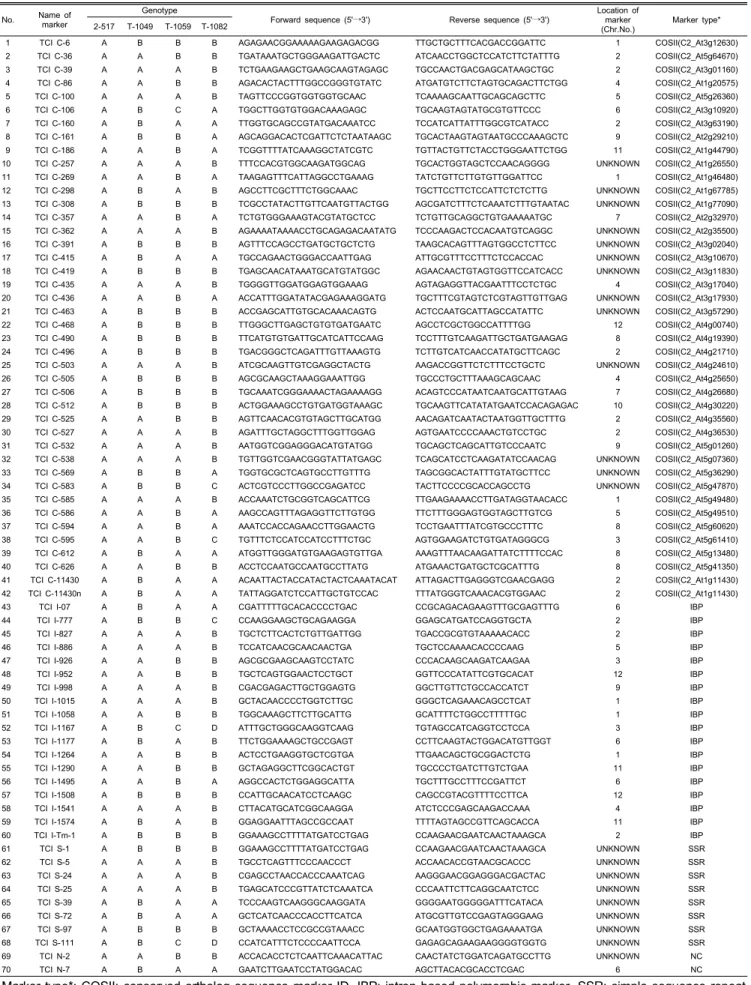
위해 COS II 분자표지 372개, 인트론 기반 분자표지 115개, 비암호화 영역 분자표지 6개, SSR 분자표지 135개로부터 고안된 총 628개의 프라이머 조합을 이용하여 4 종류의 토 마토 계통(2-517, T-1049, T-1059, T-1082)에 대해 PCR을 수행하였다. 토마토 4 계통은 과종의 형태에서 차이를 보이 는데 2-517과 T-1082는 체리형, T-1049와 T-1059는 칵테일 형의 과실을 맺는다. PCR 결과 전체 628개의 분자표지 중 40개 분자표지에서 PCR 산물이 증폭되지 않았으며, 73개의 분자표지에서 500bp 이상의 PCR 산물이 증폭되었고, 98개 분자표지에서 다중 밴드가 증폭되었으며, 나머지 417개의 분자표지에서 PCR 산물의 크기가 500bp 이하인 단일 밴드 가 증폭되었다. 417개의 분자표지는 COS II 분자표지 279 개, 인트론 기반 분자표지 84개, 비암호화 영역 분자표지 6 개, SSR 분자표지 46개로 확인되었다(Table 3). SNP를 탐 색하기 위해 417개의 분자표지를 이용하여 토마토 4개의 계 통을 이용해 HRM 분석을 실시하였다. 그 결과 4개의 계통 을 두 가지 이상의 유형으로 구분이 가능한 분자표지는 총 70개이며, 분자표지 별로는 COS II 분자표지 42개, 인트론 기반 분자표지 18개, 비암호화 영역 분자표지 2개, SSR 분 자표지 8개로 확인되었다(Table 4). 이들 분자표지는 토마 토 염색체 내의 1번 염색체에 6개, 2번 염색체에 11개, 3번 염색체에 3개, 4번 염색체에 4개, 5번 염색체에 3개, 6번 염 색체에 5개, 7번 염색체에 2개, 8번 염색체에 4개, 9번 염색 체에 3개, 10번 염색체에 1개, 11번 염색체에 3개, 12번 염 색체에 3개씩 분포하고 있으며 22개의 분자표지는 어느 염 색체에 위치하는지에 대한 정보가 아직까지 없는 상황이다
(Table 5).
본 실험에서 비암호화 영역 분자표지의 경우 SNP가 가장 높은 빈도 수(33.33%)로 나타났으며 인트론 기반 분자표지 (20.93%), SSR 분자표지(17.39%), COS II 분자표지(15.05%) 순으로 SNP의 빈도가 확인되었다. 그러나 HRM 분석에 이 용된 비암호화 영역 분자표지의 수가 6개에 불과해 다른 분 자표지들과의 정확한 비교는 어려웠다. Labate 등(2009)이 32개의 토마토 품종을 이용하여 EST, COS II와 비암호화 영 역 분자표지 등을 통해 분석한 결과에 따르면 SNP나 InDel (insert-delete)을 포함하는 다형성은 토마토 내에서 125개의 염기서열 당 1개 꼴로 발견되었다. 이 중에서 엑손, 인트론, 비암호화 지역이 모두 포함된 EST에서 93개의 염기서열 당 1개 꼴로 가장 많은 다형성이 발견되었으며 비암호화 영역 분자표지, COS II 분자표지 순으로 발견되었다. 비암호화 영역 분자표지는 141개의 염기서열 당 1개의 다형성이, COS II 분자표지의 경우에 있어서는 166개의 염기서열당 1개의 꼴로 다형성이 발견되었다. 하지만 이 실험에서는 상업용 품종보다는 야생종 토마토의 분석이 이루어졌으며, 야생종 토마토를 제외한 Solanum lycopericum 내의 품종들만의 분 석에서는 SNP의 빈도가 현격히 낮아짐을 확인할 수 있었다.
본 실험에서 사용된 4개의 계통은 유전적으로 연관 관계가 높은 계통이었기 때문에 발견되는 SNP의 빈도수가 더욱 낮 아졌을 것으로 생각된다.
토마토 품종 구별 및 유사성 분석
70개의 분자표지 가운데 nomalized graph와 difference
Table 5. List and information of SNP markers developed in this study.
No. Name of marker
Genotype
Forward sequence (5'→3') Reverse sequence (5'→3') Location of marker (Chr.No.)
Marker type*
2-517 T-1049 T-1059 T-1082
1 TCI C-6 A B B B AGAGAACGGAAAAAGAAGAGACGG TTGCTGCTTTCACGACCGGATTC 1 COSII(C2_At3g12630)
2 TCI C-36 A A B B TGATAAATGCTGGGAAGATTGACTC ATCAACCTGGCTCCATCTTCTATTTG 2 COSII(C2_At5g64670) 3 TCI C-39 A A A B TCTGAAGAAGCTGAAGCAAGTAGAGC TGCCAACTGACGAGCATAAGCTGC 2 COSII(C2_At3g01160) 4 TCI C-86 A A B B AGACACTACTTTGGCCGGGTGTATC ATGATGTCTTCTAGTGCAGACTTCTGG 4 COSII(C2_At1g20575)
5 TCI C-100 A A A B TAGTTCCCGGTGGTGGTGCAAC TCAAAAGCAATTGCAGCAGCTTC 5 COSII(C2_At5g26360)
6 TCI C-106 A B C A TGGCTTGGTGTGGACAAAGAGC TGCAAGTAGTATGCGTGTTCCC 6 COSII(C2_At3g10920)
7 TCI C-160 A B A A TTGGTGCAGCCGTATGACAAATCC TCCATCATTATTTGGCGTCATACC 2 COSII(C2_At3g63190) 8 TCI C-161 A B B A AGCAGGACACTCGATTCTCTAATAAGC TGCACTAAGTAGTAATGCCCAAAGCTC 9 COSII(C2_At2g29210) 9 TCI C-186 A A B A TCGGTTTTATCAAAGGCTATCGTC TGTTACTGTTCTACCTGGGAATTCTGG 11 COSII(C2_At1g44790) 10 TCI C-257 A A A B TTTCCACGTGGCAAGATGGCAG TGCACTGGTAGCTCCAACAGGGG UNKNOWN COSII(C2_At1g26550) 11 TCI C-269 A A B A TAAGAGTTTCATTAGGCCTGAAAG TATCTGTTCTTGTGTTGGATTCC 1 COSII(C2_At1g46480) 12 TCI C-298 A B A B AGCCTTCGCTTTCTGGCAAAC TGCTTCCTTCTCCATTCTCTCTTG UNKNOWN COSII(C2_At1g67785) 13 TCI C-308 A B B B TCGCCTATACTTGTTCAATGTTACTGG AGCGATCTTTCTCAAATCTTTGTAATAC UNKNOWN COSII(C2_At1g77090) 14 TCI C-357 A A B A TCTGTGGGAAAGTACGTATGCTCC TCTGTTGCAGGCTGTGAAAAATGC 7 COSII(C2_At2g32970) 15 TCI C-362 A A A B AGAAAATAAAACCTGCAGAGACAATATG TCCCAAGACTCCACAATGTCAGGC UNKNOWN COSII(C2_At2g35500) 16 TCI C-391 A B B B AGTTTCCAGCCTGATGCTGCTCTG TAAGCACAGTTTAGTGGCCTCTTCC UNKNOWN COSII(C2_At3g02040) 17 TCI C-415 A B A A TGCCAGAACTGGGACCAATTGAG ATTGCGTTTCCTTTCTCCACCAC UNKNOWN COSII(C2_At3g10670) 18 TCI C-419 A B B B TGAGCAACATAAATGCATGTATGGC AGAACAACTGTAGTGGTTCCATCACC UNKNOWN COSII(C2_At3g11830) 19 TCI C-435 A A A B TGGGGTTGGATGGAGTGGAAAG AGTAGAGGTTACGAATTTCCTCTGC 4 COSII(C2_At3g17040) 20 TCI C-436 A A B A ACCATTTGGATATACGAGAAAGGATG TGCTTTCGTAGTCTCGTAGTTGTTGAG UNKNOWN COSII(C2_At3g17930) 21 TCI C-463 A B B B ACCGAGCATTGTGCACAAACAGTG ACTCCAATGCATTAGCCATATTC UNKNOWN COSII(C2_At3g57290)
22 TCI C-468 A B B B TTGGGCTTGAGCTGTGTGATGAATC AGCCTCGCTGGCCATTTTGG 12 COSII(C2_At4g00740)
23 TCI C-490 A B B B TTCATGTGTGATTGCATCATTCCAAG TCCTTTGTCAAGATTGCTGATGAAGAG 8 COSII(C2_At4g19390) 24 TCI C-496 A B B B TGACGGGCTCAGATTTGTTAAAGTG TCTTGTCATCAACCATATGCTTCAGC 2 COSII(C2_At4g21710) 25 TCI C-503 A A A B ATCGCAAGTTGTCGAGGCTACTG AAGACCGGTTCTCTTTCCTGCTC UNKNOWN COSII(C2_At4g24610)
26 TCI C-505 A B B B AGCGCAAGCTAAAGGAAATTGG TGCCCTGCTTTAAAGCAGCAAC 4 COSII(C2_At4g25650)
27 TCI C-506 A B B B TGCAAATCGGGAAAACTAGAAAAGG ACAGTCCCATAATCAATGCATTGTAAG 7 COSII(C2_At4g26680) 28 TCI C-512 A B B B ACTGGAAAGCCTGTGATGGTAAAGC TGCAAGTTCATATATGAATCCACAGAGAC 10 COSII(C2_At4g30220) 29 TCI C-525 A A B B AGTTCAACACGTGTAGCTTGCATGG AACAGATCAATACTAATGGTTGCTTTG 2 COSII(C2_At4g35560) 30 TCI C-527 A A A B AGATTTGCTAGGCTTTGGTTGGAG AGTGAATCCCCAAACTGTCCTGC 2 COSII(C2_At4g36530)
31 TCI C-532 A A A B AATGGTCGGAGGGACATGTATGG TGCAGCTCAGCATTGTCCCAATC 9 COSII(C2_At5g01260)
32 TCI C-538 A A A B TGTTGGTCGAACGGGTATTATGAGC TCAGCATCCTCAAGATATCCAACAG UNKNOWN COSII(C2_At5g07360) 33 TCI C-569 A B B A TGGTGCGCTCAGTGCCTTGTTTG TAGCGGCACTATTTGTATGCTTCC UNKNOWN COSII(C2_At5g36290) 34 TCI C-583 A B B C ACTCGTCCCTTGGCCGAGATCC TACTTCCCCGCACCAGCCTG UNKNOWN COSII(C2_At5g47870) 35 TCI C-585 A A A B ACCAAATCTGCGGTCAGCATTCG TTGAAGAAAACCTTGATAGGTAACACC 1 COSII(C2_At5g49480) 36 TCI C-586 A A B A AAGCCAGTTTAGAGGTTCTTGTGG TTCTTTGGGAGTGGTAGCTTGTCG 5 COSII(C2_At5g49510) 37 TCI C-594 A A B A AAATCCACCAGAACCTTGGAACTG TCCTGAATTTATCGTGCCCTTTC 8 COSII(C2_At5g60620) 38 TCI C-595 A A B C TGTTTCTCCATCCATCCTTTCTGC AGTGGAAGATCTGTGATAGGGCG 3 COSII(C2_At5g61410) 39 TCI C-612 A B A A ATGGTTGGGATGTGAAGAGTGTTGA AAAGTTTAACAAGATTATCTTTTCCAC 8 COSII(C2_At5g13480)
40 TCI C-626 A A B B ACCTCCAATGCCAATGCCTTATG ATGAAACTGATGCTCGCATTTG 8 COSII(C2_At5g41350)
41 TCI C-11430 A B A A ACAATTACTACCATACTACTCAAATACAT ATTAGACTTGAGGGTCGAACGAGG 2 COSII(C2_At1g11430) 42 TCI C-11430n A B A A TATTAGGATCTCCATTGCTGTCCAC TTTATGGGTCAAACACGTGGAAC 2 COSII(C2_At1g11430)
43 TCI I-07 A B A A CGATTTTTGCACACCCCTGAC CCGCAGACAGAAGTTTGCGAGTTTG 6 IBP
44 TCI I-777 A B B C CCAAGGAAGCTGCAGAAGGA GGAGCATGATCCAGGTGCTA 2 IBP
45 TCI I-827 A A A B TGCTCTTCACTCTGTTGATTGG TGACCGCGTGTAAAAACACC 2 IBP
46 TCI I-886 A A A B TCCATCAACGCAACAACTGA TGCTCCAAAACACCCCAAG 5 IBP
47 TCI I-926 A A B B AGCGCGAAGCAAGTCCTATC CCCACAAGCAAGATCAAGAA 3 IBP
48 TCI I-952 A A B B TGCTCAGTGGAACTCCTGCT GGTTCCCATATTCGTGCACAT 12 IBP
49 TCI I-998 A A A B CGACGAGACTTGCTGGAGTG GGCTTGTTCTGCCACCATCT 9 IBP
50 TCI I-1015 A A A B GCTACAACCCCTGGTCTTGC GGGCTCAGAAACAGCCTCAT 1 IBP
51 TCI I-1058 A A B B TGGCAAAGCTTCTTGCATTG GCATTTTCTGGCCTTTTTGC 1 IBP
52 TCI I-1167 A B C D ATTTGCTGGGCAAGGTCAAG TGTAGCCATCAGGTCCTCCA 3 IBP
53 TCI I-1177 A B A B TTCTGGAAAAGCTGCCGAGT CCTTCAAGTACTGGACATGTTGGT 6 IBP
54 TCI I-1264 A A B B ACTCCTGAAGGTGCTCGTGA TTGAACAGCTGCGGACTCTG 1 IBP
55 TCI I-1290 A A B B GCTAGAGGCTTCGGCACTGT TGCCCCTGATCTTGTCTGAA 11 IBP
56 TCI I-1495 A A B A AGGCCACTCTGGAGGCATTA TGCTTTGCCTTTCCGATTCT 6 IBP
57 TCI I-1508 A B B B CCATTGCAACATCCTCAAGC CAGCCGTACGTTTTCCTTCA 12 IBP
58 TCI I-1541 A A A B CTTACATGCATCGGCAAGGA ATCTCCCGAGCAAGACCAAA 4 IBP
59 TCI I-1574 A B A B GGAGGAATTTAGCCGCCAAT TTTTAGTAGCCGTTCAGCACCA 11 IBP
60 TCI I-Tm-1 A B B B GGAAAGCCTTTTATGATCCTGAG CCAAGAACGAATCAACTAAAGCA 2 IBP
61 TCI S-1 A B B B GGAAAGCCTTTTATGATCCTGAG CCAAGAACGAATCAACTAAAGCA UNKNOWN SSR
62 TCI S-5 A A A B TGCCTCAGTTTCCCAACCCT ACCAACACCGTAACGCACCC UNKNOWN SSR
63 TCI S-24 A A A B CGAGCCTAACCACCCAAATCAG AAGGGAACGGAGGGACGACTAC UNKNOWN SSR
64 TCI S-25 A A A B TGAGCATCCCGTTATCTCAAATCA CCCAATTCTTCAGGCAATCTCC UNKNOWN SSR
65 TCI S-39 A B A A TCCCAAGTCAAGGGCAAGGATA GGGGAATGGGGGATTTCATACA UNKNOWN SSR
66 TCI S-72 A B A A GCTCATCAACCCACCTTCATCA ATGCGTTGTCCGAGTAGGGAAG UNKNOWN SSR
67 TCI S-97 A B B B GCTAAAACCTCCGCCGTAAACC GCAATGGTGGCTGAGAAAATGA UNKNOWN SSR
68 TCI S-111 A B C D CCATCATTTCTCCCCAATTCCA GAGAGCAGAAGAAGGGGTGGTG UNKNOWN SSR
69 TCI N-2 A A B B ACCACACCTCTCAATTCAAACATTAC CAACTATCTGGATCAGATGCCTTG UNKNOWN NC
70 TCI N-7 A B A A GAATCTTGAATCCTATGGACAC AGCTTACACGCACCTCGAC 6 NC
Marker type*: COSII; conserved ortholog sequence marker ID, IBP; intron based polymorphic marker, SSR; simple sequence repeat
marker, and NC; non-coding region marker
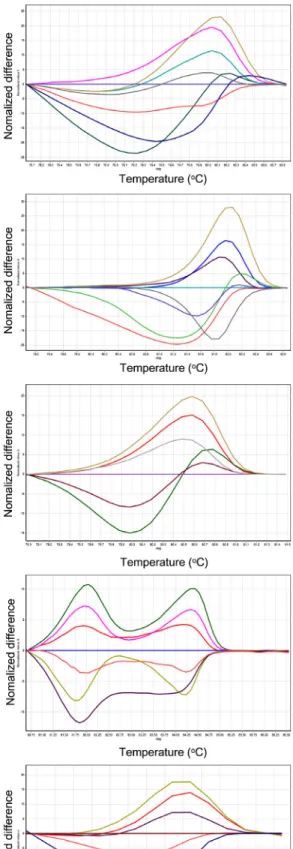
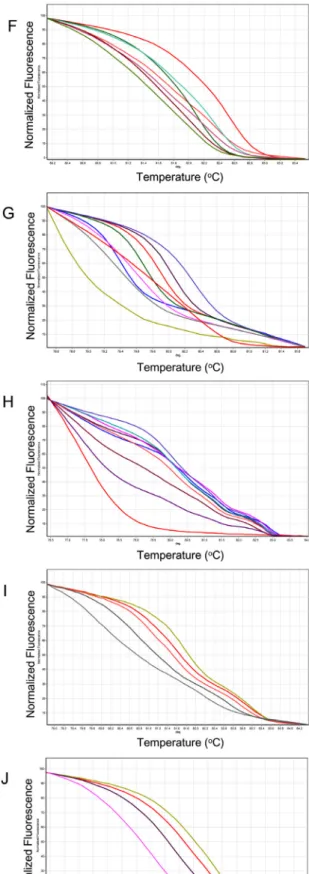
Fig. 1. Normalized graphs and difference graphs of 11 markers used for cultivar identification. Markers showed 4 to 9 melting
curve patterns depending on marker. A, TCI C-100 showing 8 curve patterns; B, TCI C-419 showing 8 curve patterns; C, TCI
C-436 showing 6 graph patterns; D, TCI C-505 showing 7 curve patterns; E, TCI C-506 showing 6 curve patterns; F, TCI
C-583 showing 7 curve patterns; G, TCI C-595 showing 9 curve patterns; H, TCI I-777 showing 9 curve patterns; I, TCI I-1015
showing 5 curve patterns; J, TCI I-1058 showing 4 curve patterns; K, TCI I-1167 showing 7 curve patterns.
Fig. 1. Normalized graphs and difference graphs of 11 markers used for cultivar identification. Markers showed 4 to 9 melting
curve patterns depending on marker. A, TCI C-100 showing 8 curve patterns; B, TCI C-419 showing 8 curve patterns; C, TCI
C-436 showing 6 graph patterns; D, TCI C-505 showing 7 curve patterns; E, TCI C-506 showing 6 curve patterns; F, TCI
C-583 showing 7 curve patterns; G, TCI C-595 showing 9 curve patterns; H, TCI I-777 showing 9 curve patterns; I, TCI I-1015
showing 5 curve patterns; J, TCI I-1058 showing 4 curve patterns; K, TCI I-1167 showing 7 curve patterns. (Continued)
Fig. 1. Normalized graphs and difference graphs of 11 markers used for cultivar identification. Markers showed 4 to 9 melting curve patterns depending on marker. A, TCI C-100 showing 8 curve patterns; B, TCI C-419 showing 8 curve patterns; C, TCI C-436 showing 6 graph patterns; D, TCI C-505 showing 7 curve patterns; E, TCI C-506 showing 6 curve patterns; F, TCI C-583 showing 7 curve patterns; G, TCI C-595 showing 9 curve patterns; H, TCI I-777 showing 9 curve patterns; I, TCI I-1015 showing 5 curve patterns; J, TCI I-1058 showing 4 curve patterns; K, TCI I-1167 showing 7 curve patterns. (Continued)
Fig. 2. Dendrogram of 32 tomato cultivars based on HRM analysis using 11 SNP markers. Numeric value was given according to the number of normalized curve patterns in sequential order, scored from 1 to 9. Color and number in the left panel denotes melting curve patterns of each marker.
graph를 비교 분석하여 가장 뚜렷한 다형성을 보인 프라이머 조합 11개를 선발하였다. COS II 분자표지 7개(TCI C-100, TCI C-419, TCI C-436, TCI C-505, TCI C-506, TCI C-583, TCI C-595), 인트론 기반 분자표지 4개(TCI I-777, TCI I-1015, TCI I-1058, TCI I-1167)를 이용해 국내에서 시판되
는 토마토 32개 품종을 대상으로 HRM 분석을 실시하였다.
HRM분석 결과 각 분자표지 별로 4개에서 9개까지의 서로
다른 곡선 유형이 확인되었으며(Fig. 1), 그래프 유형별로
그룹화 한 결과를 이용하여 토마토 품종 간의 유사성을 분
석하고 32개 품종들의 계통도를 작성하였다(Fig. 2).
TCI I-1167 분자표지를 제외한 10개의 분자표지에서 특 정 품종을 구별해 낼 수 있는 품종 특이적인 그래프가 1개에 서 3개까지 확인되었다. 전체 32개의 토마토 품종 중 18개 품종(56.25%)이 특정 분자표지에 대해 품종 특이적인 그래 프 유형이 확인되었기 때문에 이들 18개 토마토 품종에 대 해서는 빠른 품종 구분이 가능하다. 또한 토마토의 과종 형 태에 따라 HRM 분석 결과의 유사성이 있음을 확인하였다.
대과종 품종인 ‘마이로꾸’와 ‘서건’은 7개의 분자표지에서 그래프 유형이 같은 것으로 확인되었다. ‘도태랑 레귤러’와
‘Torbay’는 9개 분자표지, ‘썬글로브’와 ‘랩소디’ 또한 9개에 서 같은 유형을 보여 대과종 품종 사이의 높은 유사성이 확인 되었다. 방울형 품종 중에는 ‘스위트’와 ‘다다기’가 9개 분자 표지에서 서로 같은 그래프 유형을 보였으며, 방울형 품종은 소과종 품종과도 유사성이 높음이 확인되었다. 방울형 품종 인 ‘다다기’는 소과종인 ‘TC-32086’과 6개 분자표지에 대해 같은 그래프 유형을 나타내며, 방울형 품종 ‘TC-30166’은 소과종 품종 ‘TL-40665’와 8개 분자표지에 대해 그래프 유형 이 일치하였다. 대목용 품종에서는 ‘Match’와 ‘S0-01393’은 6개 분자표지에 대해 그래프 유형이 일치하며, ‘써포트’는
‘부킹하계’, ‘B-블로킹’과 각각 7개, 6개 분자표지에 대해 그 래프 유형이 일치하고 ‘부킹하계’와 ‘B-블로킹’간에도 5개 분자표지의 그래프 유형이 일치해 세 품종간의 유사성이 높 음이 확인되었다. 또한 ‘카게무샤’는 ‘동반자’, ‘스페셜’과 각 각 7개의 분자표지에 대해 그래프 유형이 일치하며 ‘동반자’
와 ‘스폐셜’ 또한 5개 분자표지의 유형이 일치해 품종 간에 높은 유사성을 가진 것으로 확인되었다. 이와 같이 토마토 과종 형태에 따라 품종 간의 유사성이 높은 것을 알 수 있는 데, Fig. 2에서 나타난 바와 같이 대목용 품종과 대과종 품종 들 사이에서 상대적으로 높은 유사성을 지니고 있으며, 방울 형과 소과종 품종들 간의 유사성이 높음을 확인할 수 있다.
현재 국내외에서 판매되는 토마토의 경우에는 유전적인 유사성이 매우 높기 때문에 품종을 구별하기 위한 분자표지 를 개발할 때 SNP를 이용하는 것이 유용하다. Van Deynze 등(2007a)은 COS II 분자표지를 이용하여 미국 내에서 판매 되고 있는 열 개의 토마토 품종을 이용하였을 때 1,647개의 염기서열당 1개의 꼴로 SNP가 존재함을 확인하였다. 이러 한 COS II 분자표지는 단순히 토마토의 염기서열만을 기초 로 작성한 분자표지에 비해서 유전적으로 유사한 품종들 간 의 구별이 더욱 용이하며, 이를 통해서 유전적인 유연관계 나 다양성 등의 조사도 가능한 장점을 가지고 있다. 또한 인 트론은 mRNA로 전사가 되지 않기 때문에 식물체가 진화를 거쳐 오면서 다양한 염기서열의 변화가 축적되고 보존되어 왔으며 종 간에는 많이 차이를 보인다. 이러한 이유로 인해
인트론에서의 SNP 빈도는 엑손에 비해 많은 것으로 알려져 있으며 특히 쌀에서의 SNP 빈도는 인트론이 엑손에 비해 3-6배 많다고 보고 되었다(Feltus 등, 2006; The Arabidopsis Genome Initiative 2001).
본 실험을 통해 HRM 분석법으로 32개의 토마토 품종을 구별하고 과종에 따른 품종의 유사성을 분석하였다. 토마토 내의 염기서열을 이용한 RFLP(Miller와 Tanksley, 1990)와 SNP(Nesbitt와 Tanksley, 2002) 분석으로 토마토 재배종 품 종의 유전적인 다양성이 야생종에 비해 낮은 것이 확인되었 으며, HRM 분석을 이용한 구별 방법이 다른 분자표지를 이 용하는 방법에 비해서 효율이 더 높다고 판단되었다. 최근 에는 HRM 분석을 이용한 SNP 탐색을 통해 고밀도 유전자 지도 작성(Park 등, 2009), 유전자 탐색(Lehmensiek 등, 2008), 품종 구별(Mackay 등, 2008; Wu 등, 2008) 등이 이루어지 고 있다. HRM 분석은 식물 내의 SNP를 탐색하는 데 있어 서 가장 효과적인 방법으로 제시되고 있으며, 특히 PCR 과 정을 추가적으로 수행하지 않아도 되며 증폭 산물 DNA의 염기서열 해독이 필요 없기 때문에 시간과 비용을 크게 절 약할 수 있어(Hoffmann 등, 2007) HRM 분석법을 이용한 품종 구분 기술이 널리 이용될 것이다.
초 록
최근 들어 우리나라에서 토마토 소비가 급증하고 있으며 많은 토마토 품종이 시장에서 거래되고 있다. 그러나 토마토 품종 육성에 이용되는 부모 계통의 유전적 다양성이 낮아 형태적 인 특성에 의한 토마토 품종의 구분은 매우 어려운 현실이다.
이에 따라 토마토의 품종을 구별해 낼 수 있는 분자표지의 개 발이 필요한 실정이다 . 본 연구에서는 SNP를 탐색하고 토마 토 품종 구분을 위한 SNP 마커를 개발하였다. SNP분자표지 는 고추 유전체 서열로부터 파생된 COS II 분자표지와 인트 론 기반 분자표지를 기반으로 선발되었으며, HRM분석을 통 해 다형성을 테스트 하였다. 전체 628개의 프라이머 조합 가 운데 PCR을 통해 크기가 500bp 이하의 단일 밴드가 증폭된 417개의 프라이머 조합을 선발하였다. 417개의 프라이머 조합 을 이용해 4개의 토마토 계통을 대상으로 HRM 분석을 실시 하였으며, 다형성을 보인 70개의 프라이머 조합을 선발하였 다. 70개의 프라이머 조합을 이용하여 32개의 토마토 품종을 대상으로 HRM 분석을 실시하였다. HRM분석을 통해 총 11 개의 SNP 분자표지가 선발되었으며, 이 분자표지를 이용해 시판중인 32개의 토마토 품종을 모두 구분할 수 있었다.
추가 주요어 : HRM, 단일 염기 다형성, Solanum lycopersicum
인용문헌