The effect of linguistic exposure to the standard dialect in the perception of Korean stops
*Hyunjung Lee
(Incheon National University) Eun Jong Kong
**(Korea Aerospace University)
Lee, Hyunjung and Eun Jong Kong. 2021. The effect of linguistic exposure to the standard dialect in the perception of Korean stops. Studies in Phonetics, Phonology and Morphology 27.2. 275-291. The current study examined whether natural exposure to a different dialect affected listeners’ perceptual cue weighting, and whether listeners shifted their cue weightings similarly toward speakers of the dialect to which they were exposed. We examined perception of the three-way laryngeal contrast of Korean stops across the Seoul and Kyungsang dialects, which differ in the cue-weighting pattern for stop distinction; while Seoul speakers use f0 more than VOT, Kyungsang speakers rely more on VOT. We tested stop identification for 92 adult listeners grouped by dialect experiences: Seoul vs.
Kyungsang vs. Kyungsang-Seoul. The listeners in the Seoul and Kyungsang groups were college students pursuing higher education in their native dialect regions, whereas the Kyungsang-Seoul listeners were students who moved to the Seoul area for higher education. Mixed effects logistic regression analyses showed that Kyungsang-Seoul listeners accommodated their use of VOT and f0 cues similarly to Seoul listeners, but also diverged from Kyungsang listeners’ cue weighting patterns.
These results suggest that natural exposure to the standard Seoul dialect affected the perceptual accommodation of sub-phonemic acoustic cue weighting. (Incheon National University, Assistant Professor; Korea Aerospace University, Professor)
Keywords: Korean dialect, language exposure, perceptual accommodation, stops
1. Introduction
Considering the notion by Labov (1974) that “dialect differences are the result of isolation and the lack of communication (p. 234)”, it is reasonable to hypothesize that
* This work was supported by the National Research of Foundation of Korea (No. NRF- 2017S1A5A2A03068448).
** Corresponding author
interaction with different dialect talkers would increase phonetic similarities in their speech, resulting in phonetic accommodation. Trudgill (1986) also noted the importance of such interaction among talkers, and he theorized that frequent interaction among different dialect speakers would lead to permanent phonetic accommodation, which might eventually result in dialect acquisition.
Empirical studies have also found such phonetic accommodation in an experimental setting. Previous studies have confirmed that speech perception and production are indeed very plastic by showing the imitation of phonemic and sub- phonemic features under experimental settings (e.g., Munro, Derwing and Flege 1999, Nielsen 2006, 2011, Evans and Iverson 2007, Babel 2012). In speech production, for example, Nielsen (2006) revealed spontaneous phonetic imitation.
Nielsen (2006) indicated that speakers imitated longer VOTs after hearing a stop consonant with longer VOTs, suggesting that the phonetic imitation existed in the sub-phonemic level. Kim and Clayards (2019) also found imitation of the durational property for vowels, showing that the duration was imitated better than the vowel spectral qualities even though the durational property was the less important cue perceptually. In a shadowing task of Babel (2012), vowel spectra were also imitated, and low vowels were better imitated than high vowels. The different degree of vowel imitation interacted with attractiveness ratings toward talkers, and was also influenced by the speakers’ dialects. Overall, these previous studies have showed that talkers accommodated their speech similar toward their interlocutors even through a very short speech exposure of an experimental setting, and the speech modification was affected by linguistic and social factors.
These previous findings raise several questions regarding the effect of language
exposure on phonetic accommodation. Specifically, it is questioned if and how
speakers of a dialect modify their speech when they are naturally exposed to a
different dialect. The current study explored the question by examining the
perceptual accommodation of the three-way laryngeal contrast of Korean stops for
Kyungsang dialect speakers who moved to the Seoul dialect region for college
education. The Seoul dialect of Korean is a standard language, whereas the
Kyungsang dialect is a regional dialect spoken in the southern east part of Korea
peninsula. Given the phonetic imitation under the experimental setting, we might
expect that natural exposure to a target language or dialect for longer period of time
would also have a similar effect of phonetic accommodation. In addition, the
linguistic dominance of the Seoul standard language might also result in phonetic
accommodation for college students who need to interact with Seoul speakers.
Examining the perceptual accommodation for the stops in Seoul and Kyungsang Korean would help explore the sub-phonemic level imitation through natural auditory exposure as well as the effect of language ideology in phonetic accommodation.
Korean has the three-way laryngeal contrast of voiceless stops at three places of articulation, namely tense (p’, t’, k’), lax (p, t, k), and aspirated (p
h, t
h, k
h). While the Korean stops had been famous for their unusual three-way distinction in the voiceless region, they have recently drawn attention for their sound change. While VOT and f0 were the primary and secondary acoustic cues, respectively, to the stops for Seoul Korean speakers for older generations who were born around before 1960, the cue primacy has changed in that f0 has become a primary acoustic cue for younger generations, indicating a sound change of Korean stops (e.g., Silva 2006, Wright 2007, Kang and Guion 2008, Kang 2014, Lee, Kong and Holliday 2020).
Specifically, the VOT duration patterned in the order of ‘tense < lax < aspirated,’
and VOT between the lax and aspirated stops was well separated for older
generations. However, recent studies reported significant overlap of VOT between
the two stops, and instead of VOT the low f0 value has primarily distinguished the
lax from the aspirated stop. That is, the relative importance of VOT and f0 in the lax
and aspirated stops has changed over decades. Such shift of the cue weighting has
been observed not only in Seoul Korean but also in regional dialects of Korean such
as North and South Kyungsang dialects (e.g., Lee and Jongman 2012, Lee, Politzer-
Ahelez and Jongman 2013, Lee 2020, Lee, Kong and Holliday 2020). Previous
literature reported that Kyungsang dialect speakers relied on the VOT cue more than
Seoul speakers did, using f0 as a secondary cue, and attributed different tonal
systems between Seoul and Kyungsang Korean to the dialect difference (e.g., Lee
and Jongman 2012). However, recent generational comparisons have shown that the
importance of f0 has also increased for younger Kyungsang generations, whereas that
of VOT has reduced for the three-way laryngeal stop distinction (e.g., Lee and
Jongman 2019, Lee 2020). The increased influence of Seoul Korean might result in
this tendency of the generational change. To sum up, the previous studies suggested
that although the change of acoustic cue weighting for stops is in more advanced
stage in Seoul Korean than that in Kyungsang dialects of Korean, the cue weighting
of the Kyungsang Korean stops has also changed in the same direction as Seoul
Korean stops.
Our recent study, Kong, Holliday and Lee (under revision) also indicated that adult Kyungsang listeners used the VOT and f0 cues similar to Seoul listeners in the perception of the three-way laryngeal contrast of stops. Kong et al. (under revision) examined the perception of Korean stops for 164 listeners differing in dialects (Seoul vs. Kyungsang) and education levels (elementary, high school, university), and found that the Kyungsang listeners’ perceptual accommodation was modulated by education levels. Specifically, high school students in each dialect group exhibited stronger dialect-specific cue weighting patterns; Seoul high school students used f0 more than VOT, whereas Kyungsang high school students relied more on VOT than f0. But the cue-weighting of university students in both Seoul and Kyungsang regions was less dialect-specific than their respective high school counterparts, using the secondary acoustic cues more than high school students. In other words, when high school students entered a college located in Kyungsang areas, their local characteristics of using acoustic cues were weaker in perception, and Kong et al.
(under revision) suggested that when language users broadened their social network for a college education, language users accommodate their perception by being more tolerant toward phonetic variants by adjusting secondary cues. The findings in Kong et al. (under revision) confirmed previous studies regarding the effect of social factors in phonetic accommodation, showing that such phonetic accommodation is related to listeners’ need for better interaction and conversation under inter-dialectal linguistic settings (e.g., Babel 2009, 2012, Abrego-Collier, Grove, Sonderegger and Yu 2011, Kim, Horton and Bradlow 2011, Black 2012, Pardo, Gibbons, Suppes and Krauss 2012, Babel, McGuire, Walters and Nicholls 2014).
Given the dialect differences in the cue weighting of Korean stops and the effect of education levels in phonetic accommodation, the current study aims to explore the effect of natural exposure to a standard variety in the speech perception, and examine how such linguistic exposure affects listeners’ utilization of multiple acoustic cues.
For this purpose, this study compared the identification of the three-way laryngeal
contrast of Korean stops across three different listener groups varying the linguistic
experiences with regard to regional dialects. Specifically, we compared the stop
perception across three groups, Kyungsang-Seoul listeners (i.e., regional dialect users
who moved to the Seoul standard language area), Seoul listeners (i.e., standard
variety users), and Kyungsang listeners (i.e., regional dialect users). The listeners of
the Kyungsang-Seoul group were those who moved to the Seoul area for a higher
education, and they had stayed in Seoul less than one year. The data for the latter two groups were adopted from Kong et al. (under revision).
As described above, Kyungsang speakers differ from Seoul speakers in that they lag behind in using the f0 cue compared to Seoul speakers. However, taking into account the effect of language exposure and the higher education, Kyungsang-Seoul listeners would show perceptual patterns similar to the Seoul listeners, using f0 more than Kyungsang listeners do. More importantly, the Kyungsang-Seoul listeners broaden their social network through a higher education, providing both linguistic (i.e., exposure) and social (i.e., higher education) motivation to speech accommodation, and therefore we might expect that the use of multiple acoustic cues for the stop perception of Kyungsang-Seoul listeners would shift more toward that of Seoul listeners compared to Kyungsang listeners.
2. Methods
2.1 Participants
The current study examined the stop identification for 92 participants which consisted of three adult groups of native Korean speakers: Seoul speakers, Kyungsang speakers in the Kyungsang region and Kyungsang speakers who had moved to the Seoul capital city. Combining with the existing data in Kong et al.
(under revision) for Seoul [39 adults (19 female), mean age of 23.3 years (SD = 2.6)]
and Kyungsang Korean speakers [33 adults (18 female), mean age of 22.7 years (SD
= 2.6)] who have lived in the Kyungsang region, we newly collected the perception data from South Kyungsang Korean-speaking adults [20 adults (9 female), mean age of 19.55 years (SD = 0.88)] who had just moved to the Seoul region for their college education. The average length of residential time that Kyungsang-Seoul participants have lived in the Seoul metropolitan city was 10.5 months (SD = 8.2). All participants were born and educated in the target dialect region until they pursued the higher education. The Seoul Korean-speaking and Kyungsang Korean-speaking participants who moved to Seoul were recruited in Korea University located in the Seoul city, and Kyungsang Korean-speaking participants were recruited in Kyungnam University in the Changwon city where South Kyungsang Korean is used.
None of the participants reported language or hearing problems, and all of them
provided informed consent.
2.2 Stimuli
The current study used the same auditory stimuli in Kong, Beckman and Edwards (2011) for the identification task. A total of thirty stimuli were created based on /ta/
and /t
ha/ 280 monosyllables produced by a 30-year-old male Seoul Korean speaker in Praat (Boersma and Weenink 2020). One CV base token with the lenis stop /ta/
was chosen, and we created synthetic stimuli systematically varying the two acoustic dimensions of VOT and f0. We first created a VOT continuum by adding and cutting the VOT portion in six different log-scale steps (9, 13, 19, 28, 40, and 58 ms), and aspirated portion was adapted from the /t
ha/ token. At each VOT step, a five-step f0 continuum was then created by lowering and raising f0 from 98Hz to 130Hz in 8Hz steps. Overall, a total of 30 auditory stimuli were created (6 steps for VOT × 5 steps for f0).
2.3 Tasks and procedure
The three groups of participants completed the three-alternative forced-choice (3AFC) task presented in E-Prime 3.0 (Psychology Software Tools, Inc 2016). In the 3AFC task, each listener responded to a total of 90 trials (30 auditory stimuli × three repetitions); each of the three experiment blocks had the 30 auditory stimuli and within one block the 30 trials were presented in a randomized order. The listeners were asked to identify what they heard immediately after the auditory stimuli were presented, and they clicked one of the visual response options written in Korean orthography <ㄷ>, <ㄸ>, and <ㅌ>, representing /t/, /t’/, and /t
h/, respectively. The three response options on the computer screen formed an equilateral triangle. In order to prevent listeners from any potential response bias the mouse pointer was always re-set to the center of the triangle for each trial. The current study conducted the perception experiment in quiet locations such as a classroom of a university.
2.4 Statistical analysis
The mixed effects logistic regression models analyzed the categorical responses from
the 3AFC task (three alternative forced choice), and the analyses were implemented
in R (R Core Team 2020) using lme4 package (Bates, Mächler, Bolker and Walker
2015). As a dependent variable, the regression model estimated listeners’ responses
to the stop identification. Given that there were three response options, three regression models were constructed for the three pairs of the Korean stops: (1) /t/-/t
h/ (lax-aspirated), (2) /t’/-/t/ (tense-lax), and (3) /t’/-/t
h/ (tense-aspirated). Each of the three regression models had two fixed effects of VOT and f0 values interacting with the speaker group (i.e., Seoul, Kyungsang, and Kyungsang-Seoul). In each model the Kyungsang-Seoul group was set as the reference level for the group factor, and therefore, the regression model evaluated if and how the Kyungsang-Seoul speaker group differed from the other two groups in using the two acoustic dimensions of VOT and f0 for the stop identification. For random effects, individual listeners were set as a random factor where intercepts and slopes of VOT and f0 were varied by the individual variability.
3. Results
Table 1 & 2 presents the results of the mixed effects regression analyses where the three pairs of stop categories are predicted by acoustic variables of VOT and f0. The estimated coefficients of VOT and f0 were summarized in Table 1 by the listener group and contrast pair of the stops. Across the three groups, VOT and f0 were significant acoustic variables in perceiving /t/-/t
h/ and /t’/-/t/, and VOT was a significant variable in identifying /t’/-/t
h/. In terms of the magnitude of coefficients, there were listener group differences in utilizing VOT and f0. It was consistently Seoul listeners that showed greater coefficients of f0 in perception ( = 2.737), while it was consistently Kyungsang listeners that had smaller coefficients of f0 ( = 2.019).
The f0 coefficient differences between Seoul and Kyungsang groups were statistically significant (/t/-/t
h/:
f0:K-S= .717, SE = .250, p < .005; /t’/-/t/:
f0:K-S= - .765, SE = .214, p < .001). By contrast, VOT coefficients for Seoul listeners were the smallest among the three groups for the pairs of /t/-/t
h/ ( = 2.646) and /t’/-/t/ ( = 2.192). In the model of /t/-/t
h/ pair, a VOT coefficient difference between Seoul and Kyungsang was significantly different (
VOT:K-S= .298, SE = .298, p <.05).
Reflecting the group differences in VOT and f0 sensitivity, Seoul listeners weighted f0 over VOT, and Kyungsang listener weighted VOT over f0 when both acoustic cues were important information for the stop contrast.
Looking into the group difference between Kyungsang-Seoul and the other two
groups (i.e., Seoul and Kyungsang), Table 2 provides the results of the models that
defined Kyungsang-Seoul listener group as a reference level of the group factor. To
read the result table, VOT and f0 coefficients in the three models indicate Kyungsang-Seoul group listeners’ sensitivity to the two acoustic variables, and the interaction terms show coefficient differences of VOT and f0 between KS group and Seoul and Kyungsang groups.
The results show that Kyungsang-Seoul group were sensitive to VOT and f0 in identifying /t
h/ from /t/, as the coefficients were statistically significant. In terms of the magnitude of f0 coefficients, there was a significant group difference between Kyungsang-Seoul and Kyungsang groups where the f0 coefficient of the former was greater than that of the latter group (
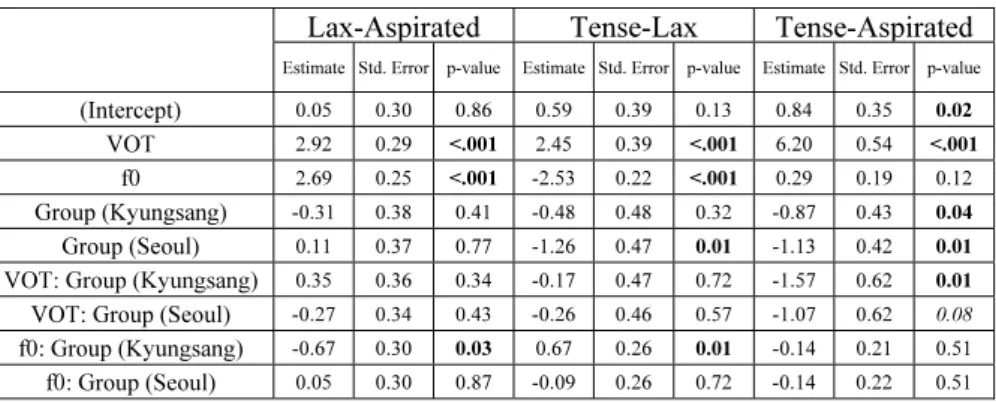
f0:K= -.667, SE = .298, p < .05). Kyungsang- Seoul listeners’ f0 coefficient was not statistically different from that of the Seoul listener group. Figure 1 visualizes the patterns by displaying logistic curves of estimated probability of response categories as a function of VOT and f0. The f0 coefficient for the Kyungsang-Seoul listener group was greater than that for the Kyungsang listener group in Table 1.
Similarly, Kyungsang-Seoul listener groups were sensitive to VOT and f0 in identifying /t/ from /t’/, as the estimated coefficients from the tense-lax model were statistically significant: Listeners were likely to identify /t/ from /t’/ as VOTs were longer and f0s were lower. Also similar to the lax-aspirated model, their VOT coefficient was not significantly different from those of the other two listener groups, while the f0 coefficient for Kyungsang-Seoul listeners was greater than that of Kyungsang listeners (
f0:K= .671, SE = .258, p < .01). The bottom center panel in Figure 1 shows that the f0 curve for Kyungsang-Seoul group is relatively steeper than that for Kyungsang listener group. Finally, Kyungsang-Seoul listeners did not use f0 but VOT only in identifying /t
h/ from /t’/. The VOT coefficient for Kyungsang-Seoul group was significantly or marginally greater than those for Kyungsang (
VOT:K= - 1.569, SE = .618, p < .05) and Seoul listeners. (
VOT:S= -1.065, SE = .615, p = .08).
Overall, the results of the regression analyses suggest that Kyungsang-Seoul listener group patterned differently from Kyungsang listener group in terms of utilizations of acoustic cues. Specifically, it was the f0 cue that Kyungsang-Seoul group differed from Kyungsang group when the cue was meaningfully used for a category distinction.
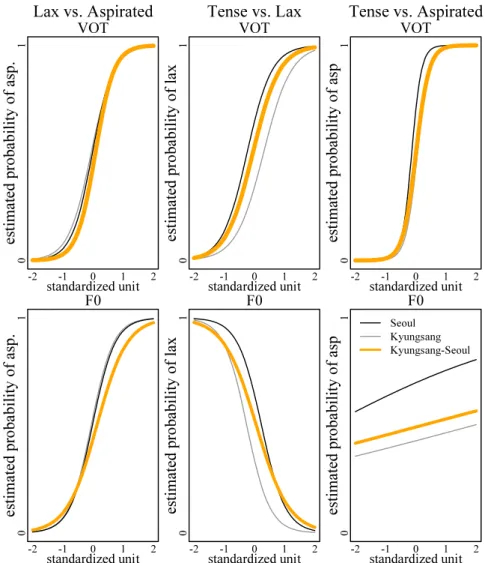
Figure 2 plots individual listeners’ VOT and f0 coefficients, which were calculated
by adding by-subject random coefficients to fixed effect coefficients. The top left
(Lax vs. Aspirated) and right (Tense vs. Lax) panels in Figure 2 confirm that
individual Kyungsang-Seoul listeners’ f0 coefficients were overall greater than those
of Kyungsang listeners and more or less similar to those of Seoul listeners by showing widespread individual coefficients more than bottom left (Tense vs.
Aspirated).
Table 1. VOT and f0 coefficients of each listener group (Seoul, Kyungsang, and Kyungsang-Seoul) from three logistic mixed-effects regression models (/t/-/t
h/:
Lax-Asp., /t’/-/t/: Tense-Lax and /t’/-/t
h/: Tense-Asp.) All coefficients were statistically significant except f0 coefficients in /t’/-/t
h/. Italic indicates p>.05
Lax-Aspirated Tense-Lax Tense-Aspirated
VOT f0 VOT f0 VOT f0
Seoul 2.646 2.737 2.192 -2.625 5.136 0.150
Kyungsang 3.265 2.019 2.281 -1.860 4.632 0.151 Kyungsang-Seoul 2.918 2.687 2.449 -2.531 6.201 0.291 Table 2. Results of three logistic mixed-effects regression models where
perception of a pair of stops was predicted by VOT, f0 and listener groups (Seoul, Kyungsang, and Kyungsang-Seoul). The reference level of Group variable was Kyungsang-Seoul. Bold indicates p<.05
Lax-Aspirated Tense-Lax Tense-Aspirated
Estimate Std. Error p-value Estimate Std. Error p-value Estimate Std. Error p-value (Intercept) 0.05 0.30 0.86 0.59 0.39 0.13 0.84 0.35 0.02
VOT 2.92 0.29 <.001 2.45 0.39 <.001 6.20 0.54 <.001
f0 2.69 0.25 <.001 -2.53 0.22 <.001 0.29 0.19 0.12
Group (Kyungsang) -0.31 0.38 0.41 -0.48 0.48 0.32 -0.87 0.43 0.04 Group (Seoul) 0.11 0.37 0.77 -1.26 0.47 0.01 -1.13 0.42 0.01 VOT: Group (Kyungsang) 0.35 0.36 0.34 -0.17 0.47 0.72 -1.57 0.62 0.01 VOT: Group (Seoul) -0.27 0.34 0.43 -0.26 0.46 0.57 -1.07 0.62 0.08 f0: Group (Kyungsang) -0.67 0.30 0.03 0.67 0.26 0.01 -0.14 0.21 0.51 f0: Group (Seoul) 0.05 0.30 0.87 -0.09 0.26 0.72 -0.14 0.22 0.51
Figure 1. Logistic curves estimated in the mixed effects models. Panels were separated by the stop comparison pairs and fixed effect variables (VOT and f0)
01
-2 -1 0 1 2
VOT
est im ate d p robab ili ty o f asp .
standardized unit
Lax vs. Aspirated
01
-2 -1 0 1 2
F0
es tima te d pr ob ab ili ty o f a sp .
standardized unit
01
-2 -1 0 1 2
VOT
es tima ted pr ob abi lity of la x
standardized unit
Tense vs. Lax
01
-2 -1 0 1 2
F0
es tim at ed p rob ab ilit y of la x
standardized unit
01
-2 -1 0 1 2
VOT
es tim ated p ro ba bi lity o f a sp
standardized unit
Tense vs. Aspirated
01
-2 -1 0 1 2
F0
es tim at ed prob abil ity of a sp
standardized unit Seoul Kyungsang Kyungsang-Seoul
1 2 3 4
1234
VOT coefficients
f0 c oe ffi ci en ts
Lax vs. Aspirated
VOT coefficients
f0 c oe ffi ci en ts
Lax vs. Aspirated
VOT coefficients
f0 c oe ffi ci en ts
Lax vs. Aspirated
0 1 2 3 4 5
-3-2-1
VOT coefficients
f0 c oe ffi ci en ts
Tense vs. Lax
VOT coefficients
f0 c oe ffi ci en ts
Tense vs. Lax
VOT coefficients
f0 c oe ffi ci en ts
Tense vs. Lax
2 3 4 5 6 7
0
VOT coefficients
f0 c oe ff ic ient s
Tense vs. Aspirated
VOT coefficients
f0 c oe ff ic ient s
Tense vs. Aspirated
VOT coefficients
f0 c oe ff ic ient s
Tense vs. Aspirated
Seoul Kyungsang Kyungsang-Seoul
Figure 2. Scatterplots of individuals’ f0 coefficients against VOT coefficients
4. Discussion
The present study aimed to examine if a natural exposure to a different dialect
affected the use of multiple acoustic cues and if listeners shifted their perceptual cue
weightings similar toward speakers of the exposed dialect. For this purpose, we
tested the identification of the three-way laryngeal contrast of stops across three
listener groups differing in dialect experiences (i.e., Seoul vs. Kyungsang vs.
Kyungsang-Seoul). Given the reported dialect difference in the acoustic cue weighting for the Korean stops, we expected group differences in using the multiple acoustic cues. The results indicated that the Kyungsang-Seoul listener group shifted their use of VOT and f0 cues similar toward Seoul listeners. Specifically, the Kyungsang-Seoul listeners who moved to the Seoul region for a college education used f0 more than Kyungsang listeners did, similar to Seoul listeners. In addition, this perceptual shift showed a systematic pattern especially for the lax-aspirated pair, indicating that the magnitude of the coefficients (i.e., the degree of the reliance on an acoustic cue) for f0 and VOT in the order of ‘Kyungsang < Kyungsang-Seoul <
Seoul’ and ‘Seoul < Kyungsang-Seoul < Kyungsang’, respectively. Such patterns were generally true for the other pairs, although they were less systematic compared to the lax-aspirated pair. Therefore, it can be summarized that the use of the multiple acoustic cues for Kyungsang-Seoul listeners became similar to those for Seoul listeners, whereas it became different from those for Kyungsang listeners. In other words, the Kyungsang-Seoul listener group was not identical to either the native Kyungsang or the standard Seoul dialect group regarding the use of VOT and f0 to the stop identification, forming three separate groups. The results suggested that the natural exposure to the standard Seoul dialect had affected the perceptual accommodation.
In the present study, the effect of the language exposure was observed for the perceptual accommodation in the sub-phonemic level even through several months of the linguistic exposure. In addition, given the group difference between Kyungsang- Seoul and Kyungsang listeners, the present findings can be separated from the effect of the higher education (Kong et al. under revision). Our earlier work (Kong et al.
under revision) showed that Kyungsang listeners changed their use of VOT and f0
after entering a university located at their dialect region. Compared to this group of
Kyungsang college listeners, the degree of the perceptual shift to the standard variety
was even greater for the Kyungsang-Seoul listeners. This result may indicate that
listeners who moved to a different dialect region for a higher education more
effectively accommodated their use of acoustic cues compared to those who pursued
a college education in the native dialect region. In addition, consistent findings across
male and female participants of the present study indicate that such accommodation
is robust enough to affect male listeners who are known to lag behind females in the
process of linguistic change.
The present findings may have several implications regarding the perceptual accommodation under natural linguistic settings. First, listeners flexibly accommodate their perception, and the sociolinguistic factors such as relocating to a standard dialect region or higher education facilitate the perceptual accommodation.
MacLeod (2012) noted that speech is converged or accommodated when speakers want to decrease social distance from their interlocutors. That is, language users imitate the acoustic characteristics of their interlocutors for a social intimacy as well as for a better communication. In the present study, Kyungsang-Seoul listeners who just entered a college located in the Seoul capital area and thus had verbal communication in person would be willing to increase social intimacy with their Seoul Korean speaking peers
1, and therefore they might have stronger motivation for the phonetic accommodation compared to Kyungsang listeners staying in the native dialect region.
Second, we might consider the language ideology of Korean for the effect of phonetic accommodation. Korean language ideology emphasized homogeneity toward standard Seoul Korean (Silva 2011). Speakers of regional dialects of Korean tend to be favorable to standard Seoul Korean, and even some younger regional dialect speakers, especially females, showed negative attitude toward their native dialects (Min 1997). Under such dominant language ideology, relocating to the Seoul standard variety region might provide Kyungsang-Seoul listeners strong motivation for phonetic accommodation making the most of the increased opportunities to interact with Seoul Korean-speaking interlocutors. Based on such sociolinguistic settings, Kyungsang-Seoul college students could be even more ready and in more ideal position for the perceptual accommodation.
Finally, it is worthwhile to note the systematic group difference of the magnitude of f0 and VOT coefficients for the lax-aspirated pair, which might confirm the previous findings regarding the sound change of Korean stops. Previous studies showed that the enhancement of f0 for the Seoul Korean stops was more robust in the lax-aspirated pair than the other pairs (e.g., Silva 2006, Wright 2007, Kang and Guion 2008, Kang 2014, Lee, Holliday and Kong 2020), indicating that the change of the acoustic cue primacy was initiated by the lax-aspirated pair followed by the other pairs in Seoul Korean. In the present study, we observed the similar pattern. The Kyungsang-Seoul listeners were in between Seoul and Kyungsang groups regarding
1 Standard Seoul Korean has the largest population in South Korea.
the degree of f0 and VOT reliance for the lax-aspirated pair. On the other hand, the group difference in the VOT and f0 reliance was less clear for the tense-lax and the tense-aspirated pairs, following the innovative cue weighting pattern in the process of the sound change. Since the change of using the VOT and f0 cues has been completed for the lax-aspirated pair earlier than the other pairs in Seoul Korean, the pair is expected to have more robust cue weighting pattern with less individual variations. Such robustness seems to be realized as the systematic group difference in the present study, where Kyungsang-Seoul listeners accommodated perceptual cue weightings toward the Seoul Korean most clearly for the lax-aspirated stop contrast with less individual variations. Therefore, we might speculate that the ongoing sound change in the Korean stops can be reflected in the perceptual accommodation as a systematic inter-dialectal group difference.
In conclusion, the current study examined if language exposure under natural linguistic setting affects listeners perceptual cue weighting. We compared three adult listener groups differing in dialect experiences (Seoul vs. Kyungsang vs. Kyungsang- Seoul) for the perception of the three-way laryngeal contrast of Korean stops. All the participants were college students, and Kyungsang-Seoul listeners were students who moved to the Seoul area for higher education. Since we already observed the shift of cue weighting due to transition from high school to college (Kong et al. under revision), the present observation was in an ideal position to see the effect of natural exposure to a different dialect. We found that Kyungsang-Seoul listeners accommodated their use of VOT and f0 cues similar toward Seoul listeners, but also diverged from Kyungsang listeners’ cue weighting pattern. These results suggested that the natural exposure to the standard Seoul dialect had affected the perceptual accommodation.
R
EFERENCESA
BREGO-C
OLLIER, C
ARISSA, J
ULIANG
ROVE, M
ORGANS
ONDEREGGER, and A
LANC.
L. Y
U. 2011. Effects of speaker evaluation on phonetic convergence. In ICPhS 2011, 192-195.
B
ABEL, M
OLLYE
LIZABETH. 2009. Phonetic and Social Selectivity in Speech
Accommodation. PhD Dissertation. University of California, Berkeley.
________________________. 2012. Evidence for phonetic and social selectivity in spontaneous phonetic imitation. Journal of Phonetics 40.1, 177-189.
B
ABEL, M
OLLY, G
RANTM
CG
UIRE, S
OPHIAW
ALTERS, and A
LICEN
ICHOLLS. 2014.
Novelty and social preference in phonetic accommodation. Laboratory Phonology 5.1, 123-150.
B
ATES, D
OUGLAS, M
ARTINM
ÄCHLER, B
ENB
OLKER, and S
TEVEW
ALKER. 2015.
Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67.1, 1-48.
B
LACK, A
LEXIS. 2012. Acoustic and social parameters on phonetic imitation: gender, emotion, and feature saliency. University of British Columbia Working Papers in Linguistics 33, 16-33.
B
OERSMA, P
AULand D
AVIDW
EENINK. 2020. Praat: Doing phonetics by computer (Version 6.1.37). [Computer program].
E
VANS, B
RONWENG. and P
AULI
VERSON. 2007. Plasticity in vowel perception and production: A study of accent change in young adults. The Journal of the Acoustical Society of America 121.6, 3814-3826.
K
ANG, K
YOUNG-H
Oand S
USANG. G
UION. 2008. Clear speech production of Korean stops: Changing phonetic targets and enhancement strategies. The Journal of the Acoustical Society of America 124.6, 3909-3917.
K
ANG, Y
OONJUNG. 2014. Voice Onset Time merger and development of tonal contrast in Seoul Korean stops: A corpus study. Journal of Phonetics 45, 76- 90.
K
IM, D
ONGHYUNand M
EGHANC
LAYARDS. 2019. Individual differences in the link between perception and production and the mechanisms of phonetic imitation.
Language, Cognition and Neuroscience 34.6, 769-786.
K
IM, M
IDAM, W
ILLIAMSS. H
ORTON, and A
NNR. B
RADLOW. 2011. Phonetic convergence in spontaneous conversations as a function of interlocutor language distance. Laboratory Phonology 2.1, 125-156.
K
ONG, E
UNJ
ONG, M
ARYE. B
ECKMAN, and J
ANE
DWARDS. 2011. Why are Korean tense stops acquired so early?: The role of acoustic properties. Journal of Phonetics 39.2, 196-211.
K
ONG, E
UNJ
ONG, J
EFFREYJ. H
OLLIDAY, and H
YUNJUNGL
EE. under revision. Post- adolescent changes in the perception of regional sub-phonemic variation.
Journal of Phonetics.
L
ABOV, W
ILLIAM. 1974. Linguistic change as a form of communication. Human Communication: Theoretical Explorations (1974), 221-256.
L
EE, H
YUNJUNG. 2020. Cross-generational acoustic comparisons of tonal Kyungsang Korean stops. The Journal of the Acoustical Society of America 148, EL172- EL178.
L
EE, H
YUNJUNG, J
EFFREYJ. H
OLLIDAY, and E
UNJ
ONGK
ONG. 2020. Diachronic change and synchronic variation in the Korean stop laryngeal contrast.
Language and Linguistics Compass 14.7, e12374.
L
EE, H
YUNJUNGand A
LLARDJ
ONGMAN. 2012. Effects of tone on the three-way laryngeal distinction in Korean: An acoustic and aerodynamic comparison of the Seoul and South Kyungsang dialects. Journal of the International Phonetic Association 42.2, 145-169.
__________________________________. 2019. Effects of sound change on the weighting of acoustic cues to the three-way laryngeal stop contrast in Korean:
Diachronic and dialectal comparisons. Language and Speech 62.3, 509-530.
L
EE, H
YUNJUNG, S
TEPHENP
OLITZER-A
HELEZ, and A
LLARDJ
ONGMAN. 2013.
Speakers of tonal and non-tonal Korean dialects use different cue weightings in the perception of the three-way laryngeal stop contrast. Journal of Phonetics 41.2, 117-132.
M
ACL
EOD, B
ETHANY. 2012. The Effect of Perceptual Salience on Phonetic Accommodation in Cross-Dialectal Conversation in Spanish. PhD Dissertation. University of Toronto.
M
IN, H
YUN-
SIK. 1997. A study on the sociolinguistic features of Men’s and Women’s language in Korean. The Sociolinguistic Journal of Korea 5.2, 529-587. The Sociolinguistic Society of Korea.
M
UNRO, M
URRAYJ, T
RACEYM. E
RWING, and J
AMESE. F
LEGE. 1999. Canadians in Alabama: A perceptual study of dialect acquisition in adults. Journal of Phonetics 27.4, 385-403.
N
IELSEN, K
UNIKOY. 2006. Specificity and generalizability of spontaneous phonetic imitation. In Ninth International Conference on Spoken Language Processing.
713-716.
_________________. 2011. Specificity and abstractness of VOT imitation. Journal
of Phonetics 39.2, 132-142.
P
ARDO, J
ENNIFERS., R
ACHELG
IBBONS, A
LEXANDRAS
UPPES, and R
OBERTM.
K
RAUSS. 2012, Phonetic convergence in college roommates. Journal of Phonetics 40.1, 190-197.
P
SYCHOLOGYS
OFTWARET
OOLS, I
NC. 2016. E-Prime 3.0. [Computer program].
R C
ORET
EAM. 2020. R: A Language and environment for statistical computing (Version 3.6.3) [Computer program]. https://www.R-project.org.
S
ILVA, D
AVID. J. 2006. Acoustic evidence for the emergence of tonal contrast in contemporary Korean. Phonology 23.2, 287-308.
______________. 2011. Out of one, many: The emergence of world Korean (s).
Inquiries into Korean Linguistics IV, 9-37.
T
RUDGILL, P
ETER. 1986. Dialect in Contact. Blackwell: Oxford.
W
RIGHT, J
ONATHAND. 2007. The Phonetic Contrast of Korean Obstruents. PhD Dissertation. University of Pennsylvania, Philadelphia.
Hyunjung Lee (Assistant Professor) Department of English Education Incheon National University
12 Gaebeol-ro, Songdo-dong, Yeonsu-gu Incheon 21999, Republic of Korea e-mail: [email protected] Eun Jong Kong (Professor) Department of English Korea Aerospace University
76 Hanggongdaehangro Deogyang-gu Goyang-si Gyeonggi-do 10540, Republic of Korea e-mail: [email protected]
received: July 30, 2021 revised: August 19, 2021 accepted: August 23, 2021