Context-Gate를 이용한 이미지 캡션 생성
Image Caption Generation with Context-Gate
저자 (Authors)
배장성, 이창기
Jangseong Bae, Changki Lee
출처 (Source)
한국정보과학회 학술발표논문집, 2018.6, 589-591 (3 pages)
발행처 (Publisher)
한국정보과학회
KOREA INFORMATION SCIENCE SOCIETY
URL http://www.dbpia.co.kr/Article/NODE07503085
APA Style 배장성, 이창기 (2018). Context-Gate를 이용한 이미지 캡션 생성. 한국정보과학회 학술발표논문집, 589-591.
이용정보 (Accessed)
저작권 안내
DBpia에서 제공되는 모든 저작물의 저작권은 원저작자에게 있으며, 누리미디어는 각 저작물의 내용을 보증하거나 책임을 지지 않습니다. 그리고 DBpia에서 제공되는 저작물은 DBpia와 구독 계약을 체결한 기관소속 이용자 혹은 해당 저작물의 개별 구매자가 비영리적으로만 이용할 수 있습니다. 그러므로 이에 위반하여 DBpia에서 제공되는 저작물을 복제, 전송 등의 방법으로 무단 이용하는 경우 관련 법령에 따라 민, 형사상의 책임을 질 수 있습니다.
Copyright Information
Copyright of all literary works provided by DBpia belongs to the copyright holder(s)and Nurimedia does not guarantee contents of the literary work or assume responsibility for the same. In addition, the literary works provided by DBpia may only be used by the users affiliated to the institutions which executed a subscription agreement with DBpia or the individual purchasers of the literary work(s)for non-commercial purposes. Therefore, any person who illegally uses the literary works provided by DBpia by means of reproduction or transmission shall assume civil and criminal responsibility according to applicable laws and regulations.
강원대학교 114.70.235.***
2018/11/09 12:16 (KST)
Context-Gate를 이용한 이미지 캡션 생성
배장성O 이창기 강원대학교 컴퓨터과학과
[email protected] [email protected]
Image Caption Generation with Context-Gate
Jangseong BaeO Changki Lee Kangwon National University
요 약
이미지 캡션 생성은 이미지를 설명하는 캡션을 자동으로 생성하는 기술로 이미지 처리 기술과 자연어 처 리 기술이 합쳐진 어려운 기술이다. 이미지 캡션 생성은 Convolutional Neural Network를 이용하여 이미 지 정보를 인코딩하고, 기계 번역에 사용되는 인코더-디코더 모델의 디코더 부분을 이용하여 캡션을 생 성한다. 기존 기계 번역에 사용되는 인코더-디코더 모델은 디코딩 타임에 소스 정보와 타겟 정보를 동등 하게 다루고 있다. 그러나 문장 번역의 정확성은 소스 정보와 관련이 높고 문장 번역의 유창성은 타겟 부분과 연관이 높기 때문에 이를 적절히 분배할 필요가 있다. 본 논문에서는 소스와 타겟 정보를 적절히 분배할 수 있는 Context-Gate를 이미지 캡션 생성에 적용한다. 실험을 통해, 본 논문에서 제안한 모델이 Context-Gate를 적용하지 않은 연구보다 높은 성능을 보였다.
1. 서 론
이미지 캡션 생성은 주어진 이미지로부터 이미지의 내용을 묘사하는 문장을 자동으로 생성하는 기술을 말 한다. 이미지 캡션 생성은 이미지를 이해하기 위한 이미 지 처리 모델과 문장 생성을 위한 자연어 처리 모델이 합쳐진 응용으로 이미지 검색, 유아 교육, 청각 장애인 들을 위한 캡셔닝 서비스와 같은 응용에 사용될 수 있 다. 최근 딥러닝을 이미지 처리 및 자연어 처리 분야에 적용하여 높은 성능을 보이는 연구가 늘어났으며 이에 따라 이미지 캡션 생성 연구 또한 많은 발전이 있었다.
기존 연구들은 이미지 캡션 생성을 검색 문제로 풀고 자 하였으나 출력 결과로 학습 데이터에 없는 새로운 캡션을 생성할 수 없는 단점이 있었다[1,2]. 최근 연구 들은 Convolutional Neural Network(CNN)를 이용하여 이미지 정보를 인코딩하고 기계 번역에 사용되는 인코 더-디코더 모델의 디코더 부분을 이용하여 캡션을 생성 한다. 디코더를 이용한 이미지 캡션 생성은 이미지 캡션 생성을 검색 문제로 접근한 연구가 가지고 있는 새로운 캡션을 생성할 수 없는 문제점을 해결하였다[3,4,5].
CNN과 디코더를 이용한 기존 이미지 캡션 생성 연구 들은 기존 기계 번역 모델과 같이 디코딩 타임에 소스 정보와 타겟 정보를 동등하게 다루고 있다. 그러나 생성 되는 문장의 정확성과 유창성이 소스와 타겟의 비율에 의해 결정되는 만큼 소스와 타겟의 비율을 적절히 분배 할 필요가 있다[6]. 본 연구에서는 입력되는 이미지 정 보를 소스로 보고 Context-Gate[6]를 이미지 캡션 생 성에 적용하고자 한다. 또한 실험을 통해 Context-Gate 를 적용한 모델이 Context-Gate를 적용하지 않은 모델 보다 우수함을 보인다.
2. 관련 연구
이미지 캡션 생성 연구는 캡션 생성을 검색 문제로 풀고자 하는 방법과, 이미지 정보를 CNN으로 인코딩하 고 기계 번역 모델의 디코더 부분을 이용하여 캡션을 생성 하는 방식의 연구가 진행 되었다.
[1,2]의 연구는 이미지와 이미지를 설명하는 캡션을 하나의 쌍으로 두고, 동일한 벡터 공간에 위치하게끔 학 습한 후, 새로운 입력 이미지와 가장 가까운 벡터 공간 에 위치한 캡션을 정답으로 출력하도록 하였다. 그러나 이와 같은 방법은 학습데이터에 없는 새로운 캡션을 생 성할 수 없는 단점이 있다.
[5]에서는 CNN으로 인코딩된 이미지를 Recurrent Neural Network(RNN)의 처음 단계에만 사용하였고, RNN의 그레디언트 소멸 문제를 해결한 Long Short- Term Memory(LSTM) RNN[7]을 이용한 이미지 캡션 생 성 모델을 제안하였다.
[3,4]에서는 캡션의 각 단어를 생성할 때 마다 CNN 으로 인코딩된 이미지 정보를 RNN의 입력으로 받는 이 미지 캡션 생성 모델을 제안하였다. [3]은 기본적인 RNN을 사용하였고 [4]는 LSTM RNN의 변형인 Gated Recurrent Unit(GRU)[8] 을 사용하였다.
[9]에서는 이미지를 위한 R-CNN(Regions with CNN feature)과 캡션을 위한 RNN을 이용하여 이미지의 오브 젝트와 그에 따른 캡션의 단어를 동일한 벡터 공간 (multimodal embedding)에 위치하도록 학습하는 모델을 제안하였다.
이미지 캡션 생성을 위한 데이터로는 Flickr 8K[1], Flickr30K[10] 등이 있다. Flickr 8K 데이터 셋은 Flickr 웹에서 추출한 8,000개의 이미지로 구성되어 있으며,
589
2018년 한국컴퓨터종합학술대회 논문집
강원대학교 | IP: 114.70.235.*** | Accessed 2018/11/09 12:16(KST)
한 개의 이미지마다 그 이미지를 묘사하는 5개의 캡션 을 포함하고 있다. [11]데이터 셋은 Flickr8K 데이터셋 을 한국어로 번역한 것이다.
[6]은 기계 번역 모델의 디코딩 타임에 소스 정보와 타겟 정보 비율을 적절히 분배하는 Context-Gate를 적 용하여 번역 문장의 정확성 및 유창성을 조절하고, 기계 변역에 성능을 향상시킨 모델이다.
3. 이미지 캡션 생성 모델 3.1 인코더-디코더
그림 1은 두개의 RNN으로 구성된 RNN 인코더-디코 더 모델이다. 첫번째 RNN은 입력 문장을 일정한 크기 의 벡터 c로 압축하고, 두번째 RNN은 압축된 벡터 c로 부터 P(y|x)를 최대화 하는 출력 언어를 생성한다.
그림 1. RNN 인코더-디코더
본 연구에서는 입력 정보가 문장이 아닌 이미지 정보이 다. 따라서 기계 번역에서 일반적으로 사용하는 RNN 인코더를 사용하지 않고 이미지 처리에 좋은 성능을 보 이고 있는 CNN을 인코더로 사용한다.
3.2 Context-Gate를 이용한 이미지 캡션 생성
Context-Gate는 디코더로 생성되는 문장의 정확성과 유창성을 조절하기 위한 기술이다. 기존 디코더에 소스 와 타겟의 비율을 조절하기 위해 하나의 게이트를 새로 추가한다. 그림 2는 Context-Gate를 나타내며, 기존 디 코더의 수식 및 변경된 디코더의 수식은 아래와 같다.
- 기존 디코더 수식
P(𝑦𝑖|𝑦<𝑖, x) = 𝑔(𝑦𝑖−1, ℎ𝑖, 𝑠𝑖) ℎ𝑖= 𝑓(𝑦𝑖−1, ℎ𝑖−1, 𝑠𝑖)
𝑓(𝑊𝑒(𝑦𝑖−1) + 𝑈ℎ𝑖−1+ 𝐶𝑠𝑖)
- Context-Gate가 적용된 디코더 수식 𝑧𝑖= 𝜎(𝑊𝑧𝑒(𝑦𝑖−1) + 𝑈𝑧ℎ𝑖−1+ 𝐶𝑧𝑠𝑖)
ℎ𝑖= 𝑓((1 − 𝑧𝑖)⨂(𝑊𝑒(𝑦𝑖−1) + 𝑈𝑧ℎ𝑖−1) + 𝑧𝑖⨂𝐶𝑧𝑠𝑖)
위 식에서 𝑔 는 softmax 함수이고 𝑦𝑖−1은 이전 단계의 디코더에서 생성한 단어이며, ℎ𝑖는 현재 디코더의 히든 레이어, 𝑠𝑖는 현재 입력 이미지 정보를 나타낸다. 𝜎 는 시그모이드 함수이며 𝑊 , 𝑈 , 𝐶 는 각각 가중치 행렬을 의미하고, ⨂는 element-wise multiplication을 의미한다.
새로운 디코더는 Context-Gate 𝑧𝑖를 통해 디코더의 히 든레이어 ℎ𝑖를 조절한다.
그림 2. Context-Gate
입력된 이미지로부터 이미지 캡션을 생성하기위한 모 델의 구조는 그림 3과 같다.
그림 3. GRU-Context-Gate
GRU-Context-Gate 모델은 입력된 이미지를 4,096 차원으로 인코딩하는 CNN과 단어를 순차적으로 생성하 는 RNN으로 구성되어 있다. CNN은 이미지 인식에서 좋 은 성능을 보인 VggNet[12]을 이용하였고, VggNet의 마지막 두번째 히든 레이어의 값을 이미지 정보로 사용 하였다. RNN은 LSTM RNN의 변형인 GRU를 사용하였으 며, 기존 디코더 수식이 아닌 Context-Gate가 적용된 디코더 수식을 사용하였다. 모델의 처음 입력은 문장의 시작 기호이고, 이로부터 다음 단어가 생성될 확률을 구 한다. 빔 서치를 이용하여 다음 단어를 선택하고 이를 다시 모델의 입력으로 보내며, 다음 단어에 문장의 끝 기호가 나올 때까지 반복한다.
4. 실험 및 결과
본 논문에서 제안한 모델을 평가하기 위해, [1,10]의 영어 이미지 캡션 데이터 및 [11]에서 구축한 한국어 이미지 캡션 데이터를 사용하였으며, [4,5]의 연구와 같 이 6,000개의 이미지를 학습에 사용하고 1,000개의 이 미지를 검증에 사용하였으며, 나머지 1,000개의 이미지 를 평가에 사용하였다. 평가 지표는 기존 이미지 캡션 생성 연구에서 주로 사용한 BLEU[13] 스코어를 사용하 였다. GRU-Context-Gate 모델은 Theano[14]를 이용 하여 구현하였으며, 학습시에는 CNN 모델의 가중치는 고정하고 RNN 부분만 RMSprop를 이용하여 학습하였다.
590
2018년 한국컴퓨터종합학술대회 논문집
강원대학교 | IP: 114.70.235.*** | Accessed 2018/11/09 12:16(KST)
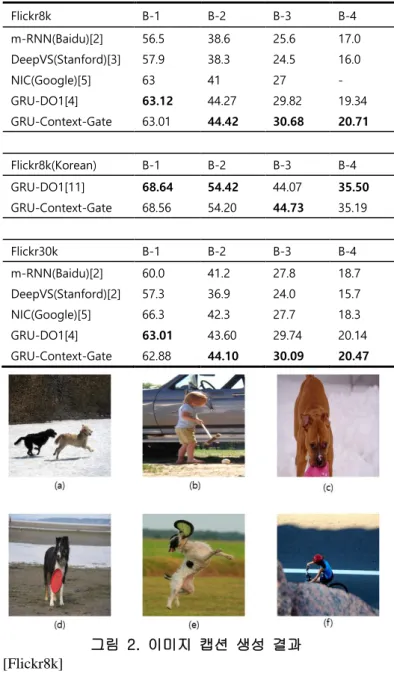
표 1은 이미지 캡션 생성 실험 결과이다. 실험결과 본 논문에서 제안한 모델이 여러 데이터셋에서 좋은 성능 을 보였다.
표 1. 이미지 캡션 생성 실험 결과
그림 2. 이미지 캡션 생성 결과 [Flickr8k]
(a) two dogs play in the snow
(b) a little girl is playing with a toy car (c) a brown dog is running in the snow
(d) a black and white dog is running on a beach (e) a dog catching a frisbee
(f) a person wearing a red helmet is riding a bike down a hill
[Flickr8k Korean]
(a) 두 개들이 눈 속에서 논다
(b) 한 작은 소녀가 트럭 옆에서 크로켓을 하고 있다
(c) 눈 속에 있는 한 개가 그것의 입 안에 어떤 물체를 들고 있는 중 이다
(d) 한 갈색 개가 해변 위에서 달리는 중이다
(e) 한 프리스비를 잡기 위해 공중으로 도약하는 한 개
(f) 빨간 셔츠와 헬멧을 착용한 한 남자가 거리에서 자전거를 타는 중 이다
5. 결론
본 논문에서는 기계 번역 모델에 사용되는 Context- Gate를 이미지 캡션 생성에 적용하였다. 실험을 통해 Context-Gate를 적용한 모델이 Context-Gate를 적용 하지 않은 연구들 보다 높은 성능을 나타냄을 보였다.
향후 연구로는 이미지 정보를 기계 번역에 사용하는 연 구를 진행할 예정이다.
감사의 글
이 논문은 2016년도 정부(미래창조과학부)의 재원으로 한국연 구재단의 지원을 받아 수행된 기초연구사업임 (No. NRF- 2016R1C1B1014124)
참고문헌
[1] Hodosh, Micah, Peter Young, and Julia Hockenmaier.
Framing image description as a ranking task: Data, models and evaluation metrics. Journal of Artificial Intelligence Research. 47:853-899. 2013.
[2] Farhadi, Ali, et al. Every picture tells a story: Generating sentences from images. European Conference on Computer Vision. pp.15-29. 2010.
[3] Mao, Junhua, et al. Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv:1412.6632. 2014.
[4] 이창기. Recurreunt Neural Network를 이용한 이미지 캡션생성. KCC. pp.540-542. 2015.
[5] Vinyals, Oriol, et al. Show and tell: A neural image caption generator. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
[6] TU, Zhaopeng, et al. Context gates for neural machine translation. arXiv preprint arXiv:1608.06043, 2016.
[7] YAO, Kaisheng, et al. Spoken language understanding using long short-term memory neural networks. In: Spoken Language Technology Workshop(SLT), IEEE. 189-194. 2014.
[8] Kyunghyun Cho, et al. On the properties of neural machine translation: Encoder-decoder approaches. Eighth Workshop on Syntax. Semantics and Structure in Statistical Tranlation.
pp. 103-111. 2014.
[9] Karpathy, Andrej, and Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
[10] Young, Peter, Lai, Alice, Hodosh, Micah, and Hockenmaier, Julia. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. TACL, 2:67–78, 2014.
[11] 배장성, 이창기. 딥러닝을 이용한 한국어 이미지 캡션 생성. KCC. pp.488-490. 2016.
[12] Simonyan, et al. Very deep convolutional networks for large-scale image recognition. arXiv:1409-1556. 2014.
[13] Papineni, Kishore, et al. BLEU: a method for automatic evaluation of machine translation. Proceedings of the 40th annual meeting on association for computational linguistics.
Association for Computational Linguistics. 2002.
[14] Bastien, Frédéric, et al. Theano: new features and speed improvements. arXiv:1211-5590. 2012.
Flickr8k B-1 B-2 B-3 B-4
m-RNN(Baidu)[2]
DeepVS(Stanford)[3]
NIC(Google)[5]
GRU-DO1[4]
GRU-Context-Gate
56.5 57.9 63 63.12 63.01
38.6 38.3 41 44.27 44.42
25.6 24.5 27 29.82 30.68
17.0 16.0 - 19.34 20.71
Flickr8k(Korean) B-1 B-2 B-3 B-4 GRU-DO1[11]
GRU-Context-Gate
68.64 68.56
54.42 54.20
44.07 44.73
35.50 35.19
Flickr30k B-1 B-2 B-3 B-4
m-RNN(Baidu)[2]
DeepVS(Stanford)[2]
NIC(Google)[5]
GRU-DO1[4]
GRU-Context-Gate
60.0 57.3 66.3 63.01 62.88
41.2 36.9 42.3 43.60 44.10
27.8 24.0 27.7 29.74 30.09
18.7 15.7 18.3 20.14 20.47
591
2018년 한국컴퓨터종합학술대회 논문집
강원대학교 | IP: 114.70.235.*** | Accessed 2018/11/09 12:16(KST)