논문 2012-49-11-8
시공간 그룹특징을 사용한 동영상 복사물의 고속 검색
( Fast Detection of Video Copy Using Spatio-Temporal Group Feature )
정 재 협*, 이 준 우*, 강 종 욱*, 정 동 석***
( Jae Hyup Jeong, Jun Woo Lee, Jong Wook Kang, and Dong Seok Jeong )
요 약
본 논문에서는 동일한 동영상을 검출하기 위한 방법을 제안한다. 제안하는 방법은 시공간 그룹특징 핑거프린팅이다. 동영상 의 프레임은 고정된 비율 방법으로 추출되며, 수직그룹과 수평그룹으로 나눠진다. 서술자는 각 그룹특징을 이진화 핑거프린팅 으로 추출하여 만든다. 그 다음 원본 동영상의 서술자로 두 종류의 핑거프린팅 데이터베이스를 구축하여 질의 동영상과 정합 한다. 효율적이고 효과적인 동영상 복사 검색을 하기 위해 높은 강인성, 독립성, 정합 속도를 가져야 한다. 제안한 방법에선 그 룹특징으로 동영상의 다양한 변형에 높은 강인성과 독립성을 가지게 된다. 구축된 원본 핑거프린팅 데이터베이스는 질의 동영 상과의 고속 정합을 가능하게 해준다. 제안한 방법은 기존 방법들과 비교했을 때 다양한 변형에서 뛰어난 성능향상을 보였다.
특히, 속도 향상에 매우 뛰어난 성능을 가져온 것이 본 논문의 큰 장점이라 할 수 있다.
Abstract
In this paper, we propose a method to search for identical videos. The proposed method is spatio-temporal group feature fingerprinting. Frame of video is extracted from fixed rate method and is partitioned into vertical group and horizontal group. Descriptor is made of each group feature that is extracted from binary fingerprinting. Next, use descriptor of original video to build a two type of fingerprinting database and matching with query video. To efficient and effective video copy detection, method have high robustness, independence, matching speed. In proposed method, group feature have high robustness and independence in variable modification of video. Building a original fingerprinting database is able to fast matching with query video. The proposed method shows performance improvement in variable modifications in comparison to the existing methods. Especially, very singular performance in speed improvement is great advantage of this paper.
Keywords: video copy detection, fingerprinting, binary feature
Ⅰ. 서 론
현대인들은 디지털 기기와 인터넷 서비스의 발달로 수많은 양의 동영상 콘텐츠들이 업로드 되어 공유하는 세상에 살고 있다. 동영상 콘텐츠의 양이 많아짐에 따 라 종류도 매우 다양하며, 최근에는 UCC를 통한 업로
* 학생회원, ** 정회원, 인하대학교 전자공학과 (Dept. of Electronic Engineering, Inha University)
※ 본 연구는 문화체육관광부 및 한국콘텐츠진흥원의 2012년도 콘텐츠산업기술지원사업의 연구결과로 수 행되었음
접수일자: 2012년6월30일, 수정완료일: 2012년8월29일
드가 활발히 진행되고 있다.
하지만 엄청난 양의 동영상 콘텐츠의 증가로 인해 문 제가 발생하기도 한다. 그 중 하나가 바로 저작권 문제 이다. 동영상 콘텐츠의 공유가 다양한 디지털 매체를 통해 자유롭게 이루어지고 있다 보니, 원 제작자의 동 의 없이 불법적으로 공유되는 사례가 많이 발생하고 있 다. 저작권이 있는 동영상을 원본 그대로 배포하기도 하고, 원본 동영상의 밝기나 대비 값을 바꾼다든가 좀 더 흐리게 하거나 선명하게 하는 등 약간의 변형을 가 하여 배포하기도 하며, 최근에는 프레임 율 변화라든가 영상의 좌우반전을 통해 불법 동영상을 배포하는 경우
를 인터넷에서 흔히 볼 수 있다.
이러한 불법 동영상 콘텐츠의 남용 사례를 막기 위해 대두되는 기술이 원본 동영상으로 동영상 검색을 통해 불법 동영상을 가려내는 것이다. 동영상 검색은 동영상 의 제목으로 검색하는 텍스트 기반 검색과 동영상의 특 징을 추출하여 특징 정보로 검색하는 내용 기반 검색이 있다. 텍스트 기반 검색은 불법 배포자가 동영상 이름 을 바꾼 다음, 배포하는 경우가 많기 때문에 효과적으 로 검색하기 어렵다는 문제가 있다[1]. 반면에 내용 기반 검색은 동영상의 제목을 바꾸거나 변형을 가했어도 원 본 동영상과 변형 동영상간의 특징을 추출하여 비교하 기 때문에 보다 효과적인 검색 방법이라고 할 수 있다.
이러한 동영상의 고유한 특징 정보를 추출한 것을 내용 기반 핑거프린팅이라고 한다.
내용 기반 핑거프린팅을 이용한 검색 방법은 동영상 으로부터 추출한 특징 정보를 이용한 핑거프린팅 데이 터베이스를 구축하기 때문에 보다 정확하고 간결한 동 영상 검색을 할 수 있다[2]. 핑거프린팅은 높은 강인성, 독립성, 정합 속도의 성능을 만족해야 효과적인 동영상 검색이 이루어진다[3]. 강인성은 다양한 변형이 가해진 동영상의 원본 동영상을 정확하게 구분할 수 있는 성능 을 말한다. 강인성이 높아지기 위해서는 같은 동영상끼 리는 유사한 핑거프린팅을 가지고 있어야 한다. 독립성 은 서로 다른 동영상을 구별할 수 있는 성능을 말한다.
독립성이 높아지기 위해서는 서로 다른 동영상은 다른 핑거프린팅을 가지고 있어야 한다. 정합 속도는 동영상 끼리의 비교를 통해 검색하는데 걸리는 시간이다. 고속 정합은 고유의 데이터베이스를 구축하는 핑거프린팅의 큰 특징이라고 할 수 있는데, 특징 정보가 간결해야만 고속 정합이 된다.
본 논문에서는 동영상 프레임의 그룹화한 특징을 이 용하여 새로운 핑거프린팅 방법을 제시하여 원본 동영 상과 다양한 변형이 가해진 질의 동영상의 비교를 통해 고속으로 정확한 동영상 복사 검색을 하는 것을 목적으 로 한다. 논문은 총 Ⅴ장으로 구성되며, Ⅰ장은 서론, Ⅱ 장에서는 핑거프린팅 종류에 따른 특징을 설명하고 Ⅲ 장에서는 제안한 핑거프린팅 방법을 설명, Ⅳ장에서는 실험 및 결과를 수행하고 실험 결과를 도시한다. 마지 막으로 Ⅴ장에서는 결론에 대해 기술한다.
Ⅱ. 핑거프린팅 종류에 따른 특징
핑거프린팅을 이용한 동영상 검색 방법은 특징 정보 의 종류에 따라 성능에서 큰 차이가 난다. 특징 정보의 종류는 동영상의 칼라 특징, 시간 특징, 공간 특징, 시공 간 특징으로 나눌 수 있다.
칼라 특징을 이용한 핑거프린팅 방법은 시간 또는 공 간적으로 동영상의 칼라 정보를 가지고 히스토그램으로 구성하는 방법이다. 이 방법은 아주 정확한 정지 영상 의 정보를 가지므로 이미지간의 비교에는 많이 쓰이는 방법이나, 동영상의 경우에는 특징을 추출하는데 시간 이 오래 걸리고, 동영상 포맷별로 칼라 특징에 차이가 있기 때문에 좋은 방법이라고는 할 수 없다[4].
시간 특징을 이용한 핑거프린팅 방법은 동영상의 고 유한 시간 특징을 이용한 방법이다[5]. 많은 정지 영상의 집합인 동영상으로부터 시간 특징만을 추출하여 비교하 기 때문에 정합 속도가 빠르다는 장점이 있다. 그러나 짧은 동영상의 경우 특징 정보가 부족하므로 상대적으 로 강인성과 독립성이 낮다는 단점이 있다.
공간 특징을 이용한 핑거프린팅 방법은 동영상의 공 간 특징인 정지 영상의 특징을 각각 추출하는 방법이 다. 특히 이미지 핑거프린팅에서 많이 쓰이는 방법이며, 대표적인 방법으로 크기, 회전에 불변한 SIFT(Scale Invariant Feature Transform)[6]와 SIFT에서 속도를 크 게 향상한 SURF(Speed Up Robust Feature)[7]가 있다.
이 방법은 다양한 변형에도 강인하다는 장점이 있으나, 칼라 특징과 마찬가지로 특징을 추출하는데 시간이 오 래 걸린다는 단점이 있다.
마지막으로 시공간 특징을 이용한 핑거프린팅 방법 은 시간 특징과 공간 특징의 장점을 모두 지닌 방법이 다. 시간 특징 방법과 공간 특징 방법은 서로 반대의 장 단점을 갖고 있는데, 시공간 특징 방법은 시간과 공간 특징의 장점들을 유지하고 단점들은 최소화 시키는데 주력한 방법이므로, 효과적인 동영상 검색을 위한 특징 정보에 가장 알맞은 방법이다. 본 논문에서도 시공간 특징을 이용한 핑거프린팅 방법을 사용하였다.
Ⅲ. 시공간 그룹특징 핑거프린팅 알고리즘 동영상은 정지 영상의 집합이므로 10초짜리 30fps 동 영상이라고 해도 300개의 정지 영상을 가진다. 즉, 모든
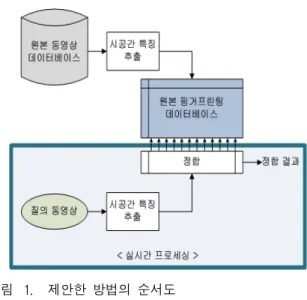
그림 1. 제안한 방법의 순서도
Fig. 1. Flowchart of the proposed method.
정지 영상에서 특징을 추출하는 것은 시간도 오래 걸리 고 중복된 특징 정보를 가지게 되는 단점이 있다. 그래 서 본 논문에서는 시공간 특징을 추출하기 전에 동영상 의 정지 영상인 프레임을 초당 F 프레임만 사용하는 고 정된 비율(fixed rate) 방법을 사용 하였다. 키 프레임을 추출하는 것도 좋은 방법이라 할 수 있으나, 그 과정에 서 추출 속도가 느려지는 단점이 있다. 본 논문에서는 추출 시간당 성능비를 고려하여 F를 3으로 하였다.
그림 1은 제안한 알고리즘의 순서도이다. 원본 동영 상으로 특징 정보 추출 후에 데이터베이스를 구축하고, 변형이 가해진 질의 동영상으로 특징 정보를 추출한 다 음 원본 핑거프린팅 데이터베이스와 비교를 통해 원본 동영상을 찾는 과정이다. 원본 핑거프린팅 데이터베이 스는 먼저 구축되어 있으며, 질의 동영상의 경우 실시 간 프로세싱을 통해 정합 결과를 얻게 된다.
1. 서술자 추출
서술자로 추출된 정보는 시공간 특징이며, 그룹특징 방법을 사용하여 추출하였다[8]. 그룹특징 방법이란 정지 영상에서 그림 2와 같이 수직그룹(Vertical Group)과 수 평그룹(Horizontal Group)으로 나누어 특징을 각각 저 장하는 방법이다.
이 방법은 영상 전체를 블록으로 나누어 사용하지 않 고, 수직과 수평에 해당하는 블록의 특징만을 추출하는 방법으로 장면전환 검출의 효과적인 방법인 연속된 영 상에서 수평, 수직 중심 영역의 정보만을 취하는 방법 을 참고하였다[9].
그림 2. 프레임의 수직그룹과 수평그룹
Fig. 2. Vertical group and Horizontal group in frame.
블록을 나누기 전에 선행 작업으로 동영상에서 추출 한 각 프레임들은 Gray Level에 해당하는 Y성분만 사 용하였다. 그 다음 그림 2와 같이 블록으로 나눠 각 블 록의 평균 화소값을 계산한다. 각 블록은 수직, 수평으 로 7개씩 그룹을 형성하게 되고 각 그룹 내에서의 평균 화소값을 구한다. 마지막으로, 그룹별로 그룹 평균 화소 값과 블록 평균 화소값의 비교를 통해 식 (1)과 식 (2) 와 같이 이진화 값을 할당한다.
≥ ≤ ≤ (1)
≥ ≤ ≤ (2)
식 (1)은 수직그룹에 관한 식이고, 식 (2)는 수평그룹 에 관한 식이다. VG는 수직 그룹 평균 화소값이고, VBi
는 수직 그룹의 각 그룹 평균 화소값이다. VBi의 평균 으로부터 VG를 구하고, VBi와 VG간의 비교를 통해 이 진화 값(bvi)을 할당한다. 수평 그룹의 경우도 같은 방 식으로 이진화 값(bhi)을 할당한다.
식 (1)과 (2)와 같이 블록 평균 화소값이 그룹 평균 화소값보다 크거나 같을 경우에는 1, 작을 경우에는 0 을 할당한다. 그림 3은 수평그룹 각 블록의 평균 화소 값이 그룹 평균 화소값과의 비교를 통해 이진화로 할당
그림 3. 이진화 값을 구하는 예 Fig. 3. Example of getting binary value.
되는 예이다.
한 프레임 당 수직그룹과 수평그룹으로 이진화 값이 할당되므로, 최종적으로 동영상의 특징 정보는 식 (3)과 같이 수직그룹과 수평그룹으로 각각 이루어진 이진화 핑거프린팅으로 추출하여 서술자를 구성한다. 식 (3)에 서 bvk, bhk는 한 프레임에서 추출한 각 수직그룹과 수 평그룹의 이진화 값이고, Bv, Bh는 한 동영상에서 추출 한 수직그룹과 수평그룹의 이진화 값이다. 여기서 R은 동영상에서 고정된 비율로 뽑힌 프레임의 총 개수이다.
최종적으로 한 동영상에서 Fp라는 이진화 핑거프린팅 을 추출하게 되고 Bv와 Bh를 각각 갖는다. 예를 들어, Bv={11011...110}, Bh={11011...001}으로 각각 길이가 L=7xR인 이진화 핑거프린팅을 갖게 되는 것이다.
(3)
2. 원본 핑거프린팅 데이터베이스 구축
원본 동영상의 특징 정보를 이용하여 원본 핑거프린 팅 데이터베이스를 구축하는 것은 정합 속도가 빨라지 는 큰 장점이 있다. 본 논문에서는 원본 핑거프린팅 데 이터베이스를 2가지 방법으로 각각 구축하여 성능 결과 를 알아보았다. 첫 번째는 역파일 테이블(Inverted-File Table) 구축이고, 두 번째는 클러스터 헤드 테이블 (Cluster-head Table) 구축이다[10].
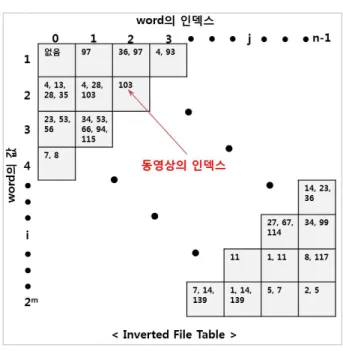
가. 역파일 테이블
역파일 테이블은 이진화 핑거프린팅을 워드(word)로 나눠, 동영상의 인덱스 테이블을 구축하는 방법이다. 워 드의 길이를 m, 이진화 핑거프린팅의 길이를 L이라고
그림 4. 이진화 핑거프린팅을 워드로 나눈 예
Fig. 4. Example of binary fingerprinting divided by word.
그림 5. 역파일 테이블의 예
Fig. 5. Example of Inverted file table.
했을 때, 워드의 개수는 n이 된다(n = ⌊L/m⌋). 그림 4는 전체 길이가 L인 이진화 핑거프린팅을 m=7 길이의 워드로 나눈 예이다.
여기서 각 워드의 이진화 핑거프린팅 10진수 값을 세 로축, 워드의 인덱스를 가로축으로 하는 역파일 테이블 을 구성하게 되는데 총 크기는 2m x n이다. 그림 5는 구축된 역파일 테이블의 예이다.
역파일 테이블의 각 테이블 블록에는 동영상의 인덱 스가 들어가게 된다. 예를 들어, 4번째 동영상의 1번째 워드의 값이 ‘2’이면 2행 1열에 ‘4’라는 동영상의 인덱스 가 할당되는 것이다. 서술자의 이진화 핑거프린팅은 수 직그룹과 수평그룹이 각각 존재하므로 역파일 테이블도 식 (4)와 같이 각각 구성하게 된다.
(4) 이렇게 해서 모든 원본 동영상에 대해 원본 핑거프린 팅 데이터베이스를 역파일 테이블로 구성한다.
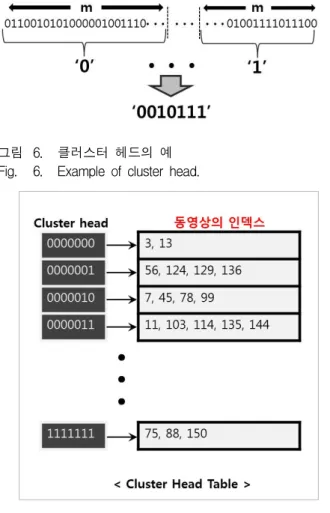
나. 클러스터 헤드 테이블
클러스터 헤드 테이블은 역파일 테이블과 마찬가지 로 이진화 핑거프린팅을 워드로 나눠 동영상 인덱스를 구축하는 방법이다. 클러스터에서도 워드의 길이를 m, 이진화 핑거프린팅의 길이를 L이라고 했을 때, 워드의 개수는 n이 된다(n = ⌊L/m⌋). 단, 구축하는 방식에서 역파일과 차이가 있다. 클러스터에서는 역파일과 다르 게 2차원 테이블을 구성하는 것이 아니라, 1차원 테이 블을 구성한다. 즉, 세로축만을 가지게 되고 세로축은 이진화 핑거프린팅의 각 워드에서 0과1의 중 개수가 많 은 쪽으로 ‘0’ 또는 ‘1’을 할당하여 구성한다. 단, 같은 개수가 나오지 않게 m은 홀수 길이를 가져 구성하는데 이렇게 구성한 워드의 대푯값들이 모여 클러스터 헤드 (Cluster head)가 만들어진다.
예를 들어, m=89이고 L=630인 이진화 핑거프린팅의 경우 그림 6과 같이 7자리의 클러스터 헤드로 구성된 다. 구성된 클러스터 헤드는 그림 7과 같이 해당 클러
그림 6. 클러스터 헤드의 예 Fig. 6. Example of cluster head.
그림 7. 클러스터 헤드 테이블의 예 Fig. 7. Example of cluster head table.
스터 헤드에 동영상의 인덱스가 할당된다.
그림 7에서처럼 45번째 동영상의 클러스터 헤드가
‘0000010’이면, 3행에 ‘45’라는 동영상의 인덱스가 할당 되는 것이다. 역파일과 마찬가지로 서술자의 이진화 핑 거프린팅은 수직그룹과 수평그룹이 각각 존재하므로 클러스터 헤드 테이블도 식 (5)와 같이 각각 구성하게 된다.
(5)이렇게 해서 모든 원본 동영상에 대해 원본 핑거프린 팅 데이터베이스를 클러스터 헤드 테이블로 구성한다.
3. 정합 단계
마지막 단계는 정합으로, 질의 동영상을 구축된 원본 핑거프린팅 데이터베이스에 정합시켜 원본을 검색하는 과정이다. 질의 동영상의 서술자 추출은 원본 동영상과 동일하게 시공간 그룹특징 핑거프린팅 방식으로 이진 화 핑거프린팅을 수직그룹과 수평그룹으로 추출한다.
이 과정은 그림 1과 같이 실시간 프로세싱으로 질의 동 영상의 서술자 추출한 다음 원본 핑거프린팅 데이터베 이스와의 정합이 이루어진다. 원본 핑거프린팅 데이터 베이스는 앞서 설명했듯이, 본 논문은 두 종류로 두어 각각의 성능을 실험하였다. 다음은 각 데이터베이스에 따른 정합 과정이다.
먼저, 역파일 테이블의 경우이다. 질의 동영상도 이진 화 핑거프린팅을 m길이의 워드로 나눠 각 워드의 값을 구한다. 그 다음 첫 번째 워드 값에 해당하는 테이블 블 록을 역파일 테이블에서 찾고, 원본 동영상의 인덱스를 확인한다. 해당 블록의 원본 동영상과 질의 동영상과의 해밍 디스턴스(Hamming distance)를 식 (6)과 같이 계 산한다. 여기서 X는 원본 동영상, Y는 질의 동영상의 이진화 핑거프린팅이다.
(6)
그 다음 주어진 임계치(ThI)보다 작거나 같을 경우 매치(match) 되었다고 판단한다. 임계치보다 클 경우에 는 해당 테이블 블록의 다음 인덱스에 해당하는 원본 동영상과 같은 방식으로 비교해본다. 만약 해당 테이블 블록의 모든 원본 동영상들과 매치가 되지 않는다면,
그림 8. 정확한 매치의 정의 Fig. 8. Definition of correct match.
두 번째 워드 값에 해당하는 테이블 블록을 찾은 다음, 위와 같은 과정을 반복한다. 즉, 매치가 될 때까지 세 번째 워드, 네 번째 워드,...,마지막 워드까지 비교해보는 것이다. 마지막 워드에서도 매치가 되지 않는다면 해당 질의 동영상의 원본은 구축한 원본 데이터베이스에 없 다는 결과가 나온다.
다음으로 클러스터 헤드 테이블의 경우이다. 마찬가 지로 질의 동영상의 이진화 핑거프린팅을 m길이의 워 드로 나눠 클러스터 헤드를 구한다. 그 다음 질의 동영 상과 같은 클러스터 헤드를 테이블에서 찾고, 원본 동 영상의 인덱스를 확인한다. 역파일과 마찬가지로 식 (6) 과 같이 질의 동영상과 원본 동영상의 해밍 디스턴스를 계산한 다음 주어진 임계치(ThC)보다 작거나 같을 경우 에만 매치 되었다고 판단한다. 해당 클러스터 헤드의 모든 원본 동영상과 매치되지 않는다면, 질의 동영상의 클러스터 헤드와 가장 유사한 클러스터 헤드를 찾은 다 음 같은 방식으로 비교하게 된다. 예를 들어, 질의 동영 상의 클러스터 헤드가 7자리인 ‘0000010’일 경우 한 자 릿수만 틀린 ‘0000011’, ‘0000110’, ‘0001010’ 등과 같은 클러스터 헤드를 찾아 비교해보고, 그래도 매치 되는 결과가 없으면 두 자릿수가 틀린 클러스터 헤드와 비교 하는 순으로 진행된다. 마지막 클러스터 헤드에서도 매 치가 되지 않는다면 해당 질의 동영상의 원본은 구축한 원본 데이터베이스에 없다는 결과가 나온다.
두 종류의 정합 모두 해당 인덱스 원본 동영상과의 비교를 수직그룹과 수평그룹에서 각각 이루어지며, 한 쪽만 매치되어도 매치되었다는 결과가 나온다.
Ⅳ. 실험 및 결과
1. 실험 목적
본 논문의 목적은 질의 동영상을 가지고 원본 동영상
을 검색하는 것이며[10], 더 나아가 그림 8과 같이 원본 동영상에서의 정확한 시간적 위치를 찾는 것이다.
예를 들어, 3분 원본 동영상의 2분~2분30초 구간이 30초 질의 동영상의 정확한 구간일 때, 이 정확한 구간 을 정합을 통해 찾는다. 오차 범위는 앞뒤로 1초를 두 었으며, 오차 범위 안으로 매치되어야 원본을 정확히 검출했다는 결과가 나온다. 다르게 말하면, 질의 동영상 으로 해당 원본 동영상을 찾았다고 해도 오차 범위가 1 초인 정확한 구간을 찾지 못하면 원본을 잘못 검출했다 는 결과가 나온다.
본 논문에서 제시한 두 종류의 원본 핑거프린팅 데이 터베이스 구축은 질의 동영상과 원본 동영상의 길이가 같아야 하기 때문에, 길이가 더 긴 원본 동영상을 질의 동영상 길이와 같게 1초 단위로 분할하여 구축하는 방 식을 사용하였다. 즉, 질의 동영상이 10초일 경우 1분짜 리 원본 동영상을 1초 단위로 분할하면 시작 위치가 0 초~50초이므로, 총 51개로 분할된다. 이러한 방식을 사 용하기 위해, 데이터베이스가 구축된 원본 동영상 인덱 스에는 시작 위치 정보도 포함된다.
2. 실험 환경
본 논문에서 제시한 동영상 검색 방법의 성능을 확인 하기 위해 다양한 동영상 데이터베이스 환경을 구축하 였고, 올바른 실험 평가 기준을 사용하였다[8]. 동영상의
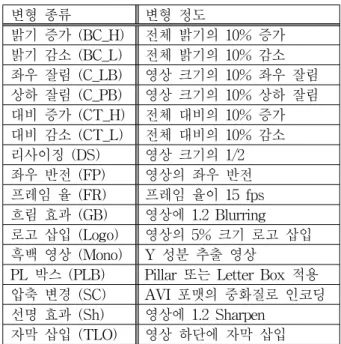
변형 종류 변형 정도
밝기 증가 (BC_H) 전체 밝기의 10% 증가 밝기 감소 (BC_L) 전체 밝기의 10% 감소 좌우 잘림 (C_LB) 영상 크기의 10% 좌우 잘림 상하 잘림 (C_PB) 영상 크기의 10% 상하 잘림 대비 증가 (CT_H) 전체 대비의 10% 증가 대비 감소 (CT_L) 전체 대비의 10% 감소 리사이징 (DS) 영상 크기의 1/2 좌우 반전 (FP) 영상의 좌우 반전 프레임 율 (FR) 프레임 율이 15 fps 흐림 효과 (GB) 영상에 1.2 Blurring 로고 삽입 (Logo) 영상의 5% 크기 로고 삽입 흑백 영상 (Mono) Y 성분 추출 영상
PL 박스 (PLB) Pillar 또는 Letter Box 적용 압축 변경 (SC) AVI 포맷의 중화질로 인코딩 선명 효과 (Sh) 영상에 1.2 Sharpen
자막 삽입 (TLO) 영상 하단에 자막 삽입 표 1. 변형 종류와 변형 정도
Table 1. Modification type and degree.
종류는 총 7종류로 애니메이션, 다큐멘터리, 드라마, 영 화, 뉴스, 쇼 프로그램, 스포츠이며 장르마다 약 20개씩 총 153개로 구성하였다. 원본 동영상 포맷은 MPEG4이 고, 크기는 704x396, 640x352, 704x400, 720x480 등이며, fps는 24~30 범위로 하였다. 원본 동영상의 시간은 10 분이며, 질의 동영상의 시간은 30초로 두었다. 변형의 종류와 정도는 표 1과 같이 구성하였다.
본 논문에서 실험 평가 기준은 식 (7)과 (8), (9)에서 정의한 강인성에 해당하는 재현율(Recall)과 독립성에 해당하는 정확도(Precision), 정합 속도에 해당하는 MTV를 사용하였다.
× (7)
× (8)
× (9)
Dtrue는 원본을 정확히 검출한 횟수, Dmiss는 원본을 검출하지 못한 횟수, Dfalse는 원본을 잘못 검출한 횟수 를 나타낸다. 재현율과 정확도가 100에 가까워질수록 우수한 강인성과 독립성을 가진 동영상 검색 방법이라 할 수 있다. 정합 속도를 평가하기 위한 정합 시간 값인 MTV (Matching Time Value)는 전체 실험에서 가장 오래 걸린 정합 시간으로 해당 정합 시간을 나눈 값이 다. 즉, MTV값이 0에 가까울수록 정합 시간이 적게 걸 리므로 정합 속도가 빠르다는 뜻이다. 본 논문에서 가 장 오래 걸린 정합 시간은 비교 기존 방법 GFOM[8]의 정합 시간인 1708.669초이다.
3. 실험 결과
실험 결과에서는 본 논문에서 제시한 두 종류의 원본 핑거프린팅 데이터베이스가 워드의 길이에 따라 성능이 어떻게 변하는지 그리고 정합 단계에서 임계치에 따라 성능이 어떻게 성능이 변하는지 알아보고, 마지막으로 기존 방법과의 비교 성능 결과를 알아보았다.
가. 워드의 길이에 따른 역파일과 클러스터
역파일과 클러스터를 통한 핑거프린팅 데이터베이스
그림 9. 워드의 길이에 따른 MTV와 재현율 그래프 (a) 역파일 방법 (b) 클러스터 방법 Fig. 9. MTV & Recall graph according to word length.
(a) Inverted-file method (b) Cluster method
의 구축은 워드의 길이에 따라 속도와 성능이 좌우된 다. 그림 9는 각각 워드의 길이에 따른 MTV와 재현율 그래프이다.
그림 9에서 세로축은 재현율과 MTV의 값을 나타내 며, 식 (7)과 (9)에서 설명하였다. 가로축은 (a)가 m이 고, (b)가 n이므로 서로 상반된다. 그 이유는 이진화 핑 거프린팅의 길이가 L일 때, n = ⌊L/m⌋이고 m은 워 드의 길이, n은 워드의 개수를 나타내므로, m만 놓고 봤을 때 (a)는 값이 커질수록 속도가 빨라지나 (b)는 반 대로 느려지기 때문이다. 워드의 길이에 따라 재현율은 큰 차이가 없으므로, 각각 최적의 값을 (a)는 m=7, (b) 는 n=7로 두었다.
나. 임계치에 따른 역파일과 클러스터
다음은 그림 10은 각 임계치에 따른 역파일과 클러스 터의 결과이다. 임계치는 원본과 질의 동영상의 이진화
그림 10. 임계치에 따른 MTV와 재현율 그래프 (a) 역파일 방법 (b) 클러스터 방법 Fig. 10. MTV & Recall graph according to Threshold.
(a) Inverted-file method (b) Cluster method
핑거프린팅의 해밍 디스턴스를 구한 다음 매치 여부를 비교하는 것으로써, 각각 ThI와 ThC를 가진다. 그림 10 을 보면 (a)와 (b) 모두 최적의 정합 시간과 재현율을 고려했을 때, 임계치가 50일 때 최적의 결과가 나왔다.
다. 기존 방법과 비교 결과
본 논문에서 제안한 방법은 그룹특징을 이용한 역파 일 방법(GF-Inv,)과 클러스터 방법(GF-Clu.)이다. 비교 할 기존 방법은 Hua[11]와 GFOM[8]의 13V13H으로 순차 정보를 이용한 방법들이다.
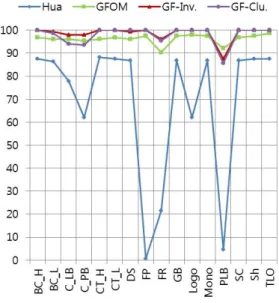
그림 11은 변형에 따른 재현율 그래프이다. 제안한 방법들은 모든 변형에서 Hua보다 뛰어난 강인성을 보 였고, 평균적으로 GFOM 보다 높은 강인성을 보였다.
제안한 방법은 PLB 변형에서 기존의 GFOM보다 낮은 강인성을 보였으나, 큰 차이는 없다.
표 2에서 평균 재현율과 정확도, MTV 값을 모두 비 교해 보았다. 제안한 방법은 기존 방법들보다 강인성에 해당하는 재현율에서 모두 뛰어난 성능을 보였고, 독립
그림 11. 변형에 따른 재현율 그래프
Fig. 11. Recall graph according to Modification.
Recall Precision MTV
Hua 68.84 100 20.55
GFOM 96.16 100 100
GF-Inv. 98.64 99.01 1.02 GF-Clu. 97.96 99.27 0.55 표 2. 제안된 방법과 기존 방법의 비교
Table 2. Compare with proposed & other methods.
성에 해당하는 정확도에서는 조금씩 낮은 성능을 보였 으나 큰 차이는 없다. 큰 성능 차이를 보인 부분이 바로 MTV인데, 제안한 방법이 기존 방법들보다 훨씬 뛰어 난 성능을 보인다. 그 이유는 제안한 방법은 원본 핑거 프린팅 데이터베이스를 구축하여 원본 동영상을 찾는 시간을 줄이며, 이진화 핑거프린팅을 사용하여 비교 시 연산속도를 단축시키기 때문이다.
V. 결 론
본 논문에서는 내용기반 동영상 복사 고속 검색에 적 합한 방법을 제안하였다. 강인성과 독립성을 높이기 위 해 서술자로 고정된 비율의 프레임마다 그룹특징을 추 출하여 그룹별로 이진화 핑거프린팅을 만드는 시공간 그룹특징 핑거프린팅 방법을 사용하였다. 고속 정합을 위해 이진화 핑거프린팅으로 원본 핑거프린팅 데이터베 이스를 구축하였으며, 구축 방법으로 역파일 테이블과 클러스터 헤드 테이블을 각각 제안하였다. 제안한 방법 모두 기존 방법들보다 우수한 성능을 보였으며, 특히 정합 속도에서 기존의 Hua보다 20배 이상 빠른 속도를 보였다. 정합 속도가 빨라야 실시간 프로세싱이 이루어 져서 인터넷에서 남용하는 불법 동영상 콘텐츠를 찾는 데 수월해지므로, 본 논문에서 제안한 방법은 우수한 성능을 가진 동영상 복사 검색 방법이라 할 수 있다.
참 고 문 헌
[1] C. Jacob, A. Frinkelstein, and D. Salesin “Fast multiresolution image query,” Technical Report 95-01-06, University of Washington, 1995.
[2] J. Oostveen, T. Kalker, and J. Haitsma, “Feature extraction and a database strategy for video fingerprinting,” Proc. Int. Conf. Recent Advances in Visual Information Systems (VISUAL), London, U.K., 2002, pp. 117-128.
[3] S. C. Cheung and Avideh Zakhor, “Effecient video similarity measurement with video signature,” IEEE Trans. Circuits and Systems for Video Technology, Vol. 13, No. 1, pp. 59-74, Jan. 2003.
[4] A. Hampapur and R. M. Bolle, Videogrep : Video copy detection using inverted file indices IBM Research Division Tomas. J. Watson Research Center, Tech. Rep., 2001.
[5] L. Chen and F. W. M. Stentiford, “Video sequence matching based on temporal ordinal measurement,” Pattern Recogn. Lett., Vol. 29, No. 13, pp. 1824-1831, 2008.
[6] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Int'l. J. Computer Vision, Vol. 60, No. 2, pp. 91-110, 2004.
[7] H. Bay, T. Tuytelaars, and L. V. Gool,
“Surf:Speed up robust features,” European Conference on Computer Vision, Vol. 3951. pp.
404-417, 2006.
[8] 정재협, 김태왕, 양훈준, 진주경, 정동석 “시공간 순차 정보를 이용한 내용기반 복사 동영상 검출,”
전자공학회논문지, 제49권, SP편, 제2호, pp.
240-248, 2012.
[9] C. W. Ngo, T. C. Pong, and R. T. “Video partitioning by temporal slice coherency.” IEEE Trans. on Circuits and Systems for Video Technology, Vol. 11, No. 8, Aug 2001.
[10] M. M. Esmaeili, M. Fatourechi, and R. K. Ward,
“A Robust and Fast Video Copy Detection System Using Content-Based Fingerprinting,”
IEEE Trans. on Information Forensics and Security, Vol. 6, No. 1, March 2011
[11] X. S. Hua, X. Chen, and H, J, Zhang, “Robust video signature based on ordinal measure,”
International Conference on Image Processing, 2004.
저 자 소 개 정 재 협(학생회원)
2009년 인하대학교 전자공학과 학사 졸업
2011년 인하대학교 전자공학과 석사 졸업
2011년~현재 인하대학교 박사 과정
<주관심분야: 영상신호처리, 패턴인식, 내용 기반 검색, 컴퓨터 비젼>
정 동 석(정회원)
1977년 서울대학교 전기공학과 학사 졸업
1985년 Virginia Tech
전자공학과 공학 석사 1988년 Virginia Tech
전자공학과 공학 박사 1988년~현재 인하대학교 전자공학부 교수 1990년~1994년 전자공학회 논문지 편집위원 1990년~1994년 통신학회 논문지 편집위원 2000년~2004년 정보전자공동연구소 소장 2010년~2012년 인하대학교 IT공대학장 2012년~현재 인하공업전문대학교 총장
<주관심분야 : 영상처리, 컴퓨터 비젼, 패턴인식, 내용기반 멀티미디어검색>
이 준 우(학생회원)
2006년 인하대학교 전자공학과 학사 졸업
2008년 인하대학교 전자공학과 석사 졸업
2008년~현재 인하대학교 박사 과정
<주관심분야: 영상신호처리, 내용 기반 검색, 비 디오압축, 컴퓨터 비젼>
강 종 욱(학생회원)
2010년 인하대학교 전자공학과 학사 졸업
2012년 인하대학교 전자공학과 석사 졸업
2012년~현재 인하대학교 박사 과정
<주관심분야: 패턴인식, 영상처리, SLAM>