2018, 29
(4)
,975–985
한국인 암 발병 데이터를 이용한 공간검색통계량과 에셜론 분석의 핫스팟 지역 비교
ᄉ
ᅵᆫ영서
1
· 김동재2
12가톨릭대학교 의생명 · 건강과학과
ᄌ ᅥ
ᆸᄉ ᅮ 2018ᄂ ᅧ ᆫ 6ᄋ ᅯ ᆯ 11ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 7ᄋ ᅯ ᆯ 10ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 7ᄋ ᅯ ᆯ 12ᄋ ᅵ ᆯ
요 약
Kulldorff (1997)ᄀ ᅡ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡ ᆫ ᄀ ᅩ ᆼ ᄀ ᅡ ᆫᄀ ᅥ ᆷᄉ ᅢ ᆨᄐ ᅩ ᆼ ᄀ ᅨᄅ ᅣ ᆼᄋ ᅳ ᆫ ᄃ ᅦᄋ ᅵᄐ ᅥᄀ ᅡ ᄋ ᅥ ᆮᄋ ᅥᄌ ᅵ ᆫ ᄋ ᅧ ᆼᄋ ᅧ ᆨᄋ ᅴ ᄌ ᅮ ᆼᄉ ᅵ ᆷᄋ ᅳ ᆯ ᄋ ᅯ ᆫ ᄋ ᅴ ᄌ ᅮ ᆼᄉ ᅵ ᆷᄋ ᅳᄅ ᅩ ᄒ ᅢᄉ ᅥ ᄋ
ᅵ ᄋ ᅯ ᆫ ᄉ ᅡ ᆼᄋ ᅴ ᄋ ᅧ ᆼᄋ ᅧ ᆨᄋ ᅳ ᆯ ᄀ ᅥ ᆷᄉ ᅢ ᆨᄒ ᅢᄉ ᅥ ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺᄋ ᅳ ᆯ ᄇ ᅡ ᆯᄀ ᅧ ᆫᄒ ᅡᄂ ᅳ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺᄌ ᅵᄋ ᅧ ᆨᄋ ᅳ ᆯ ᄎ ᅡ ᆽᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄆ ᅡ ᆭᄋ ᅵ ᄊ ᅳᄋ ᅵᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ.
ᄒ
ᅡᄌ ᅵᄆ ᅡ ᆫ ᄋ ᅵ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆫ ᄋ ᅯ ᆫ ᄉ ᅡ ᆼᄋ ᅴ ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺᄇ ᅡ ᆩᄋ ᅦ ᄀ ᅥ ᆷᄎ ᅮ ᆯ ᄒ ᅡᄌ ᅵ ᄆ ᅩ ᆺ ᄒ ᅡ ᆫᄃ ᅡᄂ ᅳ ᆫ ᄃ ᅡ ᆫᄌ ᅥ ᆷᄋ ᅵ ᄋ ᅵ ᆻᄃ ᅡ. ᄄ ᅡᄅ ᅡᄉ ᅥ ᄋ ᅵᄅ ᅳ ᆯ ᄇ ᅩ ᄋ ᅪ ᆫ ᄒ ᅡᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄇ ᅩ ᆫ ᄂ
ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄋ ᅯ ᆫ ᄉ ᅡ ᆼᄋ ᅦ ᄀ ᅮ ᆨ ᄒ ᅡ ᆫᄃ ᅬᄌ ᅵ ᄋ ᅡ ᆭᄀ ᅩ ᄆ ᅩᄃ ᅳ ᆫ ᄋ ᅧ ᆼᄋ ᅧ ᆨᄋ ᅦᄉ ᅥᄋ ᅴ ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺ ᄀ ᅥ ᆷᄎ ᅮ ᆯ ᄋ ᅵ ᄀ ᅡᄂ ᅳ ᆼ ᄒ ᅡ ᆫ ᄋ ᅦᄉ ᅧ ᆯᄅ ᅩ ᆫ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄇ ᅥ ᆸᄀ ᅪ ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺᄌ ᅵ ᄋ
ᅧ
ᆨᄋ ᅳ ᆯ ᄇ ᅵᄀ ᅭᄒ ᅢᄇ ᅩᄋ ᅡ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ 1999∼2013ᄂ ᅧ ᆫᄃ ᅩᄋ ᅴ 24ᄀ ᅢ ᄋ ᅡ ᆷ ᄇ ᅡ ᆯᄇ ᅧ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄉ ᅵ ᆯᄌ ᅦ ᄃ ᅦᄋ ᅵᄐ ᅥᄅ ᅳ ᆯ ᄀ ᅡᄌ ᅵᄀ ᅩ ᄇ ᅮ ᆫ ᄉ
ᅥ ᆨᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄋ ᅦᄉ ᅧ ᆯᄅ ᅩ ᆫ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄇ ᅡ ᆯᄇ ᅧ ᆼ ᄇ ᅵᄋ ᅲ ᆯ ᄀ ᅪ ᄋ ᅧ ᆫᄅ ᅧ ᆼᄑ ᅭᄌ ᅮ ᆫ ᄒ ᅪᄇ ᅡ ᆯᄉ ᅢ ᆼᄅ ᅲ ᆯᄋ ᅳ ᆯ ᄀ ᅵᄌ ᅮ ᆫ ᄋ ᅳᄅ ᅩ ᄂ ᅡᄋ ᅩ ᆫ ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺᄌ ᅵᄋ ᅧ ᆨ ᄀ ᅧ ᆯᄀ ᅪᄋ ᅪ ᄋ ᅯ ᆫ ᄒ ᅧ
ᆼ ᄀ ᅥ ᆷᄉ ᅢ ᆨ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄇ ᅵᄀ ᅭᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄀ ᅩ ᆼ ᄀ ᅡ ᆫᄀ ᅥ ᆷᄉ ᅢ ᆨᄐ ᅩ ᆼ ᄀ ᅨᄅ ᅣ ᆼ, ᄀ ᅩ ᆼ ᄀ ᅡ ᆫᄃ ᅦᄋ ᅵᄐ ᅥ, ᄋ ᅦᄉ ᅧ ᆯᄅ ᅩ ᆫ ᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄒ ᅡ ᆺᄉ ᅳᄑ ᅡ ᆺ.
1. 서론 ᄇ
ᅩᆫ연구에서는 통계청에서 제공하는암 등록통계 중지역별 24개 암종발생자 수, 조발생률, 연령표준 ᄒ
ᅪ발생률 (age standardization rate)에 대한 데이터를이용하였다. 지역은서울특별시를비롯해 각 시 ᄃ
ᅩ별 16개의 지역으로 나누었으며 암은 입술, 구강 및 인두, 식도, 위, 대장, 간, 담낭 및 기타 담도, 췌 ᄌ
ᅡᆼ, 후두, 폐, 유방, 자궁경부, 자궁체부, 난소, 전립선, 고환, 신장, 방광,뇌 및 중추신경계, 갑상선, 호 ᄋ
ᅳᆯ지킨 림프종, 비호지킨 림프종, 다발성 골수종, 백혈병, 기타 암을포함해 총 24개의 암을 통합한 결 ᄀ
ᅪ이다. 조발생률과 연령표준화발생률 (ASR)의 단위는명/10만명이며 1999∼2003년도, 2004∼2008년 ᄃ
ᅩ, 2009∼2013년도 세 기간으로 나누어진 통계자료이다.
ᄀ ᅩ
ᆼ간검색통계량은 질병 발생률과 같이 지역별로 얻어지는데이터에 있어서 통계적으로 유의하게 높거 ᄂ
ᅡ 낮은값을나타내는지역인 핫스팟을발견하기 위해 이용된다. 또한 공간데이터는변수나 특정 위치 ᄋ
ᅴ 값에 대한 정보를 제공하는데, 이 때 데이터는 특정 위치나 특정 지역에서 얻어지며 이들의 상대적 ᄋ
ᅵᆫ 위치가 기록된다. 이 공간 군의 존재에 관한 검정에 많은 방법이 제안되어왔다. 본연구에서는 한 ᄀ
ᅮ
ᆨ의 질병 발병 중 24개종암의 핫스팟지역을검출하기 위해서 원형검색방법과 에셜론 분석을이용하였 ᄃ
ᅡ. 본연구에서는전국에 있는각 시,도청을위치로 기록하였으며 유의하게 높은지역을핫스팟지역으 ᄅ
ᅩ 지정했다.
ᄀ ᅩ
ᆼ간 검색 통계량은데이터가 얻어진 영역의 중심을 원의 중심으로 해서 원상의 영역을검색해 핫스팟 ᄋ
ᅳᆯ발견하는방법이며 이 방법은검정될모든 원을포함하는파라미터 공간을가진 최대 우도비 검정이
1
(137-701) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄎ ᅩᄀ ᅮ ᄇ ᅡ ᆫᄑ ᅩᄃ ᅢᄅ ᅩ 222, ᄀ ᅡᄐ ᅩ ᆯᄅ ᅵ ᆨᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅴᄉ ᅢ ᆼᄆ ᅧ ᆼ · ᄀ ᅥ ᆫᄀ ᅡ ᆼᄀ ᅪᄒ ᅡ ᆨᄀ ᅪ, ᄃ ᅢᄒ ᅡ ᆨᄋ ᅯ ᆫᄉ ᅢ ᆼ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (137-701) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄎ ᅩᄀ ᅮ ᄇ ᅡ ᆫᄑ ᅩᄃ ᅢᄅ ᅩ 222, ᄀ ᅡᄐ ᅩ ᆯᄅ ᅵ ᆨᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅴᄉ ᅢ ᆼᄆ ᅧ ᆼ · ᄀ ᅥ ᆫᄀ ᅡ ᆼᄀ ᅪᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄃ
ᅡ. Kulldorff (1997)에 의한 원형검색방법은 SaTScan을이용해 분석하였으며 여기에는베르누이모형 ᄀ
ᅪ 포아송모형이 있다. 베르누이모형은사건 발생확률이 상대적으로큰현상에 대하여 공간적 군집경 ᄒ
ᅣᆼ이 가장 우세한 지점과 공간적 범위를탐색하는데 주로 이용한다. 포아송모형은 공간상에서 상대적 ᄋ
ᅳ로 희귀하게 발생하여 그 발생 가능성이 매우 낮은사건에 적용되는모형으로 예를 들어, 상대적 발생 ᄇ
ᅵᆫ도가 낮은희귀성 질병의 발생 등의 공간적 군집지역을찾아내기 위하여활용한다.
ᄒ
ᅡ지만 원형 검색 방법으로는 원상의 핫스팟 밖에 검출할 수 없기 때문에 다른검색방법인 에셜론 분 ᄉ
ᅥᆨ과 결과를비교해보고자 한다. 에셜론 분석은 원격탐사에 의해 얻은각종 공간 데이터 해석을위해 개 ᄇ
ᅡᆯ된 것으로, 공간 데이터의 위상적 구조를계통적이고 객관적으로 발견하기 위한 분석이다. 데이터의 ᄀ
ᅩ저를바탕으로 한 위상적 구조로 이루어지는상위 에셜론 순으로 영역을검색함으로써 원상에만 국한 ᄃ
ᅬ지 않은모든영역에서의 핫스팟 검출이 가능하다. 따라서 본연구에서는세 기간으로 나누어진 데이 ᄐ
ᅥ에 대해 원형검색방법과 에셜론 분석으로 핫스팟지역을비교해보고자 한다.
2. 분석 방법
2.1. 공간검색통계량 ᄀ
ᅩ
ᆼ간 통계학에서의 일반적인관심사항은 일련의 점들이 랜덤하게 분포되어 있는지에 대한 여부나 일 저
ᆼ한 군집성을지니고 있는지의 여부에관한 것이다. 이러한 군집을찾기 위해 공간검색통계량을사용 ᄒ
ᅡ게된다.
ᄌ
ᅥᆫ체지역을 G라 하고 그 중하나의 지역을 Z라 하자. 이 때 Z지역 안에서 일련의 점들이 포함될 확 류
ᆯ을 p라 하고, Z지역 밖의 점들이 포함될 확률을 q라 한다. 이 때 각각의 점들이 서로 독립일 때 가설 ᄋ
ᅳ
ᆫ다음과 같다.
H0: p = q vs H1: p ̸= q.
n(G)는 G에서의 모집단 수, n(Z)는 Z지역 내부의 모집단 수, c(G)는전체지역 G에서 속성을지닌 ᄀ
ᅢ체 수, c(Z)는 Z지역 내부에서 속성을지닌 개체 수로 한다.
ᄋ
ᅧ기서는포아송 분포에 기인한 모델을고려하며, 전체 지역 G에서 속성을지닌 개체 수가 c(G)로될 화
ᆨ률은다음과 같다.
exp[−pn(Z) − q(n(G) − n(Z))][pn(Z) + q(n(G) − n(Z))]c(G)
c(G)! .
ᄌ
ᅥᆫ체 지역 안에서의 지점 x에서의 밀도는
pn(x)
pn(Z)+q(n(G)−n(Z)) , x ∈ Z
qn(x)
pn(Z)+q(n(G)−n(Z)) , x /∈ Z ᄀ
ᅡ 되며, 이 때 포아송모델에 대한 우도함수는다음과 같이 주어진다.
L(Z, p, q) = exp[−pn(Z) − q(n(G) − n(Z))]
c(G)! pc(Z)qc(G)−c(z)Y
Xi
n(Xi).
ᄋ
ᅵ 우도함수를최대화하는 Z를구함으로써 군집이될가능성이큰지역을찾을수 있으므로 지역 Z가 ᄌ
ᅮ어졌을때의 최대우도 함수를계산한다.
ᄋ
ᅵ때 최우추정량은 ˆp=c(Z)/n(Z), ˆq=(c(G) − c(Z))/(n(G) − n(Z))을대입하여 구한다.
L(Z) =
e−n(G)
c(G)! (n(Z)c(Z))c(Z)(n(G)−n(Z)c(G)−c(Z))c(G)−c(Z)Q
Xin(Xi), n(Z)c(Z) >n(G)−n(Z)c(G)−c(Z)
e−n(G)
c(G)! (n(G)c(G))c(G)Q
Xin(Xi) = L0, 그외에.
ᄄ
ᅩ한 우도비 람다는핫스팟을발견하기 위해 전체지역의 부분집합인 지역 Z에서 최대인것으로 한다.
ᄋ
ᅧ기서 L0는귀무가설이 참일 때의 우도함수 값이며 검정통계량 람다는다음과 같이 나타낼 수 있다.
λ =
M axzL(Z) L0 =(
c(Z)
n(Z))c(Z)(n(G)−n(Z)c(G)−c(Z))c(G)−c(Z) (n(G)c(G))c(G)
, n(Z)c(Z) >n(G)−n(Z)c(G)−c(Z)
1, 그외에
2.2. 에셜론분석 ᄋ
ᅦ셜론 분석 (Myers 등,1997)은 공간상에 분류된지도상의 1변량 데이터에 대해 공간적 위치를표면 ᄉ
ᅡᆼ의 데이터를바탕으로 분할, 공간 데이터의 위상적 구조를계통적이고 객관적으로 발견하기 위해서 개 ᄇ
ᅡᆯ된 해석법이다. 이러한 데이터의 계층적 구조나 원형데이터의 위상적 표면의 변화를 나타내기 위해 ᄋ
ᅦ셜론 덴드로그램 (Echelon dendrogram)을이용한다. 핫스팟으로 간주할 수 있는여러 개의 지역들 ᄋ
ᅳ
ᆫ에셜론 덴드로그램상에서 피크로 표현한다.
ᄋ
ᅵᆫ공위성 등을 통해 얻어진 원격탐사 (remote sensing) 데이터와 같이 데이터의 고저가 n × m 배열 ᄉ
ᅡᆼ의 Dij= {(x, y) | xi−1< x < xi, yi−1 < y < yi}, i=1,2,· · ·,n, j=1,2,· · ·,m의 계수값 h로 주어지 느
ᆫ 공간 데이터인 경우, 즉데이터 고저가 2차원 공간의 배열 상에 주어진 경우 데이터는 (i, j, h)로 나타 ᄂ
ᅢᆫ다. 이와 같은 공간 데이터의 경우 이들세 변수의관계를나타내는함수 h = f(i, j)는이산적이며 복 ᄌ
ᅡ
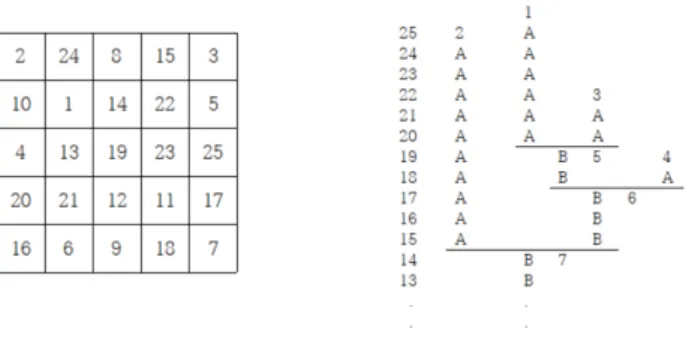
ᆸ한 함수가 되어 구조도 복잡하게된다. 아래와 같은 5×5 배열상의 데이터가 주어질 때, 데이터의 구 ᄌ
ᅩ는 Figure 2.1과 같이 에셜론 덴드로그램으로 재 표현할 수 있다.
Figure 2.1 Echelon dendrogram
3. Korean cancer outbreak data 분석 및 결과 보
ᆫ연구에서 사용하는데이터에서는암 유병률이 지역별로 1%대를맴도는것으로 보아 포아송모형을 ᄉ
ᅡ용하는것이 적절하다고 판단하여 SaTScan을이용한 원형검색방법에서는포아송모델로 분석해보고 ᄌ
ᅡ 한다. 에셜론 분석에 있어서 기준을 인구수로 할 경우 상대적으로 인구수가 많은서울특별시, 경기도 ᄌ
ᅵ역이 유병률과는무관하게 높게 나올것이라 추측해 기준을발병비율과 연령표준화발생률로 한다. 조 ᄇ
ᅡᆯ생률은 100,000명당 발생하는암환자수를의미하고 연령표준화는지역별로 편차가큰연령분포를 동 이
ᆯ하게 조정하거나, 연령구조 (분포)에 영향을받는 특정 현상에 대해 연령구조효과를제거해 재분석한 거
ᆺ이다. 또한 에셜론방법을이용한 연구에서는한국의 전체 영역이 16개로 적은관계로 검색하는핫스 ᄑ
ᅡᆺ 수를최대 4개까지로 제한을했다. 제한하지 않을경우에는 9개 영역까지 핫스팟으로 검출되어 한국 ᄋ
ᅴ 거의 모든영역이 핫스팟으로 표현되는경우도 있기 때문이다. 따라서 본연구에서는세 기간으로 나 ᄂ
ᅮ어진 데이터에 대해 포아송모델을이용한 원형검생방법과 발병비율과 연령표준화발생률을기준으로 ᄒ
ᅡᆫ 에셜론 분석 방법의 핫스팟 지역을비교해본다.
ᄌ
ᅵ역별 인접정보와 같이 유의한 인접정보에 의한 데이터 간의 비교가 가능하다면 공간적인 계층구조 르
ᆯ구할 수 있다. 이들시도별 암 발병 비율에 대한 구조는 에셜론 덴드로그램에 의해 나타낼 수 있으 ᄆ
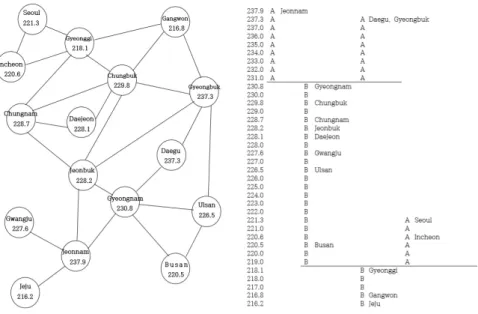
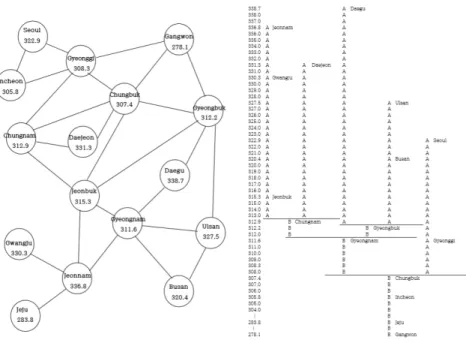
ᅧ 1999∼2003년도의 24개 암 발병 비율에 대한 지역별 인접정보와 에셜론 덴드로그램은 Figure 3.1과 ᄀ
ᅡ
ᇀ다. 이 그림으로부터 우리는 4개의 피크가 존재하고 제 1피크는 전라남도, 제 2피크는경상북도, 제 3피크는 충청남도, 제 4피크는서울특별시, 인천광역시로 구성됨을 알 수 있다. 또한 덴드로그램의 상 ᄋ
ᅱ 에셜론 순으로 공간 검색 통계량을 구한 후, 이 통계량이 최대가 되는영역까지를핫스팟으로 한다.
ᄋ
ᅵ 때 지역 Z가될수 있는데이터 내의 지역은 같은 지역 Z로될 수 있는 다른 지역에 반드시 인접하 ᄃ
ᅩ록취한다. 이 때 Log λ 값이 가장큰값은 4802.68로 전라남도, 경상북도, 충청남도, 전라북도가 핫 ᄉ
ᅳ팟 지역임을알 수 있다. 이번에는이들시도별 암 발병률을연령표준화발생률을기준으로 비교해 보 ᄀ
ᅩ자 한다. Figure 3.2는 연령표준화발생률에 대한 지역별 인접정보와 에셜론 덴드로그램을나타내고 이
ᆻ다. 이를 통해 우리는 3개의 피크가 존재하며 제 1피크는 전라남도, 제 2피크는대구광역시, 경상북 ᄃ
ᅩ, 제 3피크는서울특별시, 인천광역시로 구성됨을 알 수 있다. 또한 덴드로그램의 상위 에셜론 순으 ᄅ
ᅩ 공간 검색 통계량을구하고서 이 통계량이 최대가 되는영역까지를 핫스팟으로 하기 때문에 Log λ ᄀ
ᅡ
ᆹ이 가장큰 전라남도, 대구광역시, 경상북도, 경상남도가 핫스팟 지역임을알 수 있다. 같은데이터 르
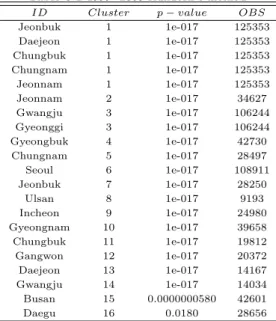
ᆯ가지고 Kulldorff의 원형검색방법을이용한 결과는 Table 3.1과 같다. cluster 1의 로그우도비 값은 2753.18로 cluster 중가장큰값을가지고 있으며 이 때의 p-value는 0.01보다 작고 해당 지역은전라북 ᄃ
ᅩ, 대전광역시, 충청북도, 충청남도, 전라남도이다. 따라서 이 다섯 지역이 핫스팟임을알 수 있다.
Figure 3.3은 2004∼2008년도의 24개 암 발병 비율에 대한 지역별 인접정보와 에셜론 덴드로그램을 ᄂ
ᅡ타내고 있으며 이로부터 우리는 4개의 피크가 존재하는것을알 수 있다. 또한 제 1피크는 전라남도, ᄌ
ᅦ 2피크는경상북도, 제 3피크는 충청남도, 제 4피크는서울특별시로 구성됨을 알 수 있다. Log λ 값 ᄋ
ᅵ 가장 큰값을 가진 지역이 핫스팟이며 Log λ 값은 4739.01로 전라남도, 경상북도, 충청남도, 전라 ᄇ
ᅮ
ᆨ도 지역이 핫스팟임을알 수 있다. Figure 3.4는 2004∼2008년도의 24개 암 연령표준화발생률에 대 ᄒ
ᅡᆫ 지역별 인접정보와 에셜론 덴드로그램을나타내고 있으며 4개의 피크가 존재하고 제 1피크는전라남 ᄃ
ᅩ, 광주광역시, 제 2피크는대전광역시, 충청남도, 제 3피크는대구광역시, 울산광역시, 경상북도, 제 4피크는 서울특별시, 경기도로 구성됨을알 수 있다. Log λ 값이 가장큰 값을가진 지역이 핫스팟이 ᄆ
ᅧ Log λ 값은 1754.63으로 서울특별시, 경기도 지역이 핫스팟임을알 수 있다. 같은데이터를가지고 Kulldorff의 원형검색방법을이용한 결과는 Table 3.2와 같다. cluster 1의 로그우도비 값은 3093.24로 cluster 중가장큰값을가지고 있으며 이 때의 p-value는 0.01보다 작고 해당 지역은전라남도, 전라북 ᄃ
ᅩ이다. 따라서 이 두 지역이 핫스팟임을알 수 있다.
Figure 3.1 1999∼2003 adjacent information & Echelon dendrogram
Figure 3.2 1999∼2003 ASR’s adjacent information & Echelon dendrogram
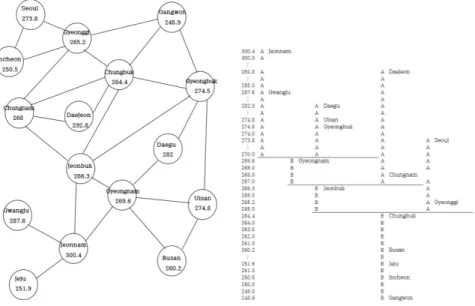
Figure 3.5는 2009∼2013년도의 24개 암 발병 비율에 대한 지역별 인접정보와 에셜론 덴드로그램 ᄋ
ᅳᆯ 나타내고 있으며 이 그림으로부터 우리는 4개의 피크가 존재하고 제 1피크는 전라남도, 제 2피크 느
ᆫ경상북도, 제 3피크는 부산광역시, 제 4피크는 서울특별시, 인천광역시로 구성됨을알 수 있다. 이
Figure 3.3 2004∼2008 adjacent information & Echelon dendrogram
Figure 3.4 2004∼2008 ASR’s adjacent information & Echelon dendrogram
Table 3.1 1999∼2003 Kulldorff’s method
ID Cluster p − value OBS
Jeonbuk 1 1e-017 125353
Daejeon 1 1e-017 125353
Chungbuk 1 1e-017 125353
Chungnam 1 1e-017 125353
Jeonnam 1 1e-017 125353
Jeonnam 2 1e-017 34627
Gwangju 3 1e-017 106244
Gyeonggi 3 1e-017 106244
Gyeongbuk 4 1e-017 42730
Chungnam 5 1e-017 28497
Seoul 6 1e-017 108911
Jeonbuk 7 1e-017 28250
Ulsan 8 1e-017 9193
Incheon 9 1e-017 24980
Gyeongnam 10 1e-017 39658
Chungbuk 11 1e-017 19812
Gangwon 12 1e-017 20372
Daejeon 13 1e-017 14167
Gwangju 14 1e-017 14034
Busan 15 0.0000000580 42601
Daegu 16 0.0180 28656
Table 3.2 2004∼2008 Kulldorff’s method
ID Cluster p − value OBS
Jeonnam 1 1e-017 81313
Jeonbuk 1 1e-017 81313
Gwangju 2 1e-017 170168
Gyeonggi 2 1e-017 170168
Gyeongbuk 3 1e-017 54019
Incheon 4 1e-017 34702
Chungnam 5 1e-017 37790
Ulsan 6 1e-017 14355
Seoul 7 1e-017 157328
Gangwon 8 1e-017 26485
Gyeongnam 9 1e-017 53627
Log λ값이 가장 큰 값은 3457.79로 전라남도, 경상북도, 전라북도, 충청남도가 핫스팟임을알 수 있 ᄃ
ᅡ. Figure 3.6은 2009∼2013년도의 24개 암 연령표준화발생률에 대한 지역별 인접정보와 에셜론 덴드 ᄅ
ᅩ그램을나타내고 있으며 이를 통해 5개의 피크가 존재하고 제 1피크는 대구광역시, 제 2피크는전라 ᄂ
ᅡ
ᆷ도, 광주광역시, 전라북도, 제 3피크는대전광역시, 제 4피크는 울산광역시, 부산광역시, 제 5피크는 ᄉ
ᅥ울특별시, 경기도로 구성됨을알 수 있다. 이때 가장큰값인 Log λ 값은 1769.66으로 서울특별시, 경 ᄀ
ᅵ도 지역이 핫스팟임을알 수 있다. 같은데이터를가지고 Kulldorff의 원형검색방법을이용한 결과는 Table 3.3과 같다. cluster 1의 로그우도비 값은 2856.49로 cluster 중가장큰값을가지고 있으며 이 때 ᄋ
ᅴ p-value는 0.01보다 작다. 따라서 경기도가 핫스팟임을알 수 있다.
Figure 3.5 2009∼2013 adjacent information & Echelon dendrogram
Figure 3.6 2009∼2013 ASR’s adjacent information & Echelon dendrogram
Table 3.3 2009∼2013 Kulldorff’s method
ID Cluster p − value OBS
Gyeonggi 1 1e-017 219061
Jeonnam 2 1e-017 100721
Jeonbuk 2 1e-017 100721
Gyeongbuk 3 1e-017 67834
Incheon 4 1e-017 52447
Busan 5 1e-017 82559
Chungnam 6 1e-017 48976
Gwangju 7 1e-017 28826
Gangwon 8 0.0000000000000118 34047
Seoul 9 0.0000000000188 213957
4. 결론 및 고찰
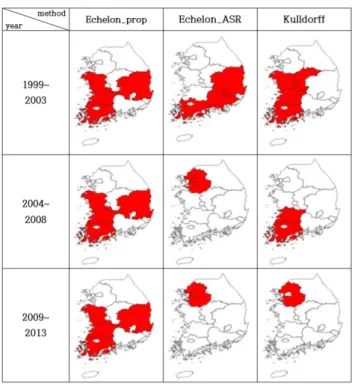
Figure 4.1 Hotspot region comparison
Figure 4.1은 분석기준과 방법에 따라 연도별로 24개 암종발생 데이터에 적용해서 탐색한 핫스팟 지 ᄋ
ᅧ
ᆨ을 나타낸다. 결과를 해석해보면 에셜론분석을 이용한 방법에서는 1999∼2003년도, 2004∼2008년 ᄃ
ᅩ, 2009∼2013년도 모두 24개종 암 발병 비율이 높은 지역은 전라남도, 경상북도, 충청남도, 전 ᄅ
ᅡ북도로 변함이 없음을 알 수 있다. 하지만 연령표준화발생률을 기준으로 한 에셜론 분석의 결과 ᄋ
ᅦ서는 1999∼2003년도에는 전라남도, 경상북도, 대구광역시, 경상남도 지역이, 2004∼2008년도와 2009∼2013년도에는서울특별시, 경기도 지역이 핫스팟임을알 수 있다. 또한 Kulldorff의 원형검색방
버
ᆸ으로 세 기간에 나눈데이터를비교해보면 1999∼2003년도에는전라남도, 충청남도, 전라북도, 대전 과
ᆼ역시, 충청북도로 넓은지역에 퍼져있다가 2004∼2008년도에는전라남도, 전라북도 두 지역으로 축소 ᄃ
ᅬ며 2009∼2013년도에는경기도로 핫스팟 지역이 옮겨졌음을알 수 있다.
ᄋ
ᅵ 세 가지 방법의 결과를비교해보면, 다소 차이가 있음을알 수 있다. 검색하는방법과 분석하는기 주
ᆫ이 서로 다르기 때문에 나타난 당연한 결과라 볼수도 있겠지만, 우도비가 최대가 되는지역을검색하 ᄂ
ᅳᆫ것이므로 이 데이터의 경우에 세 방법의 효율성을비교, 검토하기에 실질적으로 다소 어려운형편이 ᄃ
ᅡ. 1999∼2003년도에 세 검색방법에서 같은기간에 같은핫스팟 지역의 결과를보이는것은전라남도 ᄀ
ᅡ 있다. 이 때 에셜론두가지 방법의 분석결과 같은핫스팟을보인 지역은경상북도이며, ASR을기준 ᄋ
ᅳ로 한 에셜론 분석과 Kulldorff분석 결과 충청남도, 전라북도 지역이 같은핫스팟 지역으로 나타나는 거
ᆺ을 볼수 있다. 2004∼2008과 2009∼2013에는두 검색방법에서 같은기간에 같은핫스팟 지역의 결 과를보이고 있다. 2004∼2008년도에는 인구수를기준으로 한 에셜론방법과 Kulldorff방법이 동일하게 ᄌ
ᅥᆫ라남도와 전라북도를핫스팟지역으로 가지고 있다. 그리고 2009∼2013년도에는 ASR을기준으로 한 ᄋ
ᅦ셜론방법과 Kulldorff 방법이 동일하게 경기도를핫스팟 지역으로 가지고 있음을알 수 있다. 세 가 ᄌ
ᅵ 방법을모두 비교하기에는같은결과가 없는것으로 보일 수 있지만 기간에 따라 최소 두 검색방법에 ᄉ
ᅥ는같은지역이 나오며 전체적으로 보았을경우 전라남도에서 전라북도, 경기도 순으로 핫스팟 지역이 ᄋ
ᅵ동되었음을알 수 있다.
ᄋ
ᅦ셜론 분석의 특징으로는데이터가 지닌 계층구조의 피크를바탕으로 검색을해 나가기 때문에 효율 서
ᆼ 있게 핫스팟의 검색이 가능하며 대용량의 데이터에도 적용이 가능하다. 또한 공간정보에 인접정보만 ᄋ
ᅵ용하므로 다양한 형상의 핫스팟 검출이 가능하다는장점이 있다. 또한 기준을유병률과 연령표준화발 새
ᆼ률에 따라서도 상이한 결과를나타낼 수 있으므로 적용하는데이터에 따라 구별해서 사용할 필요가 있 ᄃ
ᅡ고 판단된다. 본연구에서와 같이 영역 수가 적은수의 데이터인 경우에는이처럼 다양한 검색 방법을 ᄌ
ᅥ
ᆨ용하여 볼 필요가 있을것이다.
References
Hong, H. (2003). Detection of hotspot areas using spatial clustering methods and echelon analysis. National Statistical Office [Statistical Research] , 8, 131-153.
Kulldorff, M. (1997). A spatial scan statistic. Communications in Statistics - Theory and Methods, 26, 1481-1496.
Moon, S. (2003). Echelon analysis. Journal of the Korean Data Analysis Society, 5, 273-282.
Moon, S. (2011). Study of Korean mortality by means of spatial statistics. Journal of the Korean Data Analysis Society, 13, 221-232.
Moon, S. and Kim, J. (2006). Detection of hotspots for geospatial lattice data. Journal of theKorean Data
& Information Science Society, 17, 131-139
Myers, W. L. and Patil, G. P. (2002). Echelon analysis. Encyclopedia of Environmetrics, 2, 583-586.
Myers, W. L., Patil, G. P. and Joly, K. (1997). Echelon approach to areas of concern in synoptic regional
monitoring. Environment and Ecological Statistics, 4, 131-152.
2018, 29
(4)
,975–985
A comparative study on the hotspot area in the Echelon analysis and spatial scan statistic using Korean
cancer outbreak data
Youngseo Shin
1
· Dongjae Kim2
12Department of Biomedicine · Health Science, The Catholic University of Korea
Received 11 June 2018, revised 10 July 2018, accepted 12 July 2018
Abstract
The Spatial Scan Statistic proposed by Kulldorff (1997) is a method of finding hotspots by searching for this original area with the center of the circle around which the data is acquired. This method is often used to find hot spots. However, this method has disadvantages in detecting only the circular hotspot. Echelon Analysis is not limited to circular type and can detect hotspots in all areas. Therefore, the paper compared the Echelon analysis and Kulldorff’s method. we analyzed the actual data on 24 cancers outbreaks from 1999 to 2013. The Echelon analysis analyzed hotspot areas based on incidence rate and Age Standardization Rate.
Keywords: Echelon analysis, hotspot, spatial data, spatial scan statistic.
1
Researcher, Department of Biomedicine · Health Science, The Catholic University of Korea, 222, Banpo- daero, Seocho-gu, Seoul 137-701, Korea.
2