한국정보통신학회논문지 Vol. 25, No. 7: 861~868, Jul. 2021
3D 시각화를 이용한 조선시대 시문 분석
민경주1·이병찬2*
The Analysis of Chosun Danasty Poetry Using 3D Data Visualization
Kyoung-Ju Min
1· Byoung-Chan Lee
2*1
CEO, Eureka Solution, Dongbu-ro 85beon-gil, Dong-gu, Daejeon, 34663 Korea
2*
Researcher, Department of General Education, Woosong university, Daejeon, 34606 Korea
요 약
빅데이터를 시각화하기 위한 기술이 발전하여 많은 데이터를 직관적으로 분석, 오류검출, 의미 도출 등의 작업이 활발히 진행되고 있다. 본 논문에서는 한국고전번역원의 한국고전종합DB에서 제공하는 한자로 된 문집데이터를 수집하여 데이터를 저장, 가공하여 3D 네트워크 다이어그램으로 문집 정보를 시각화하는 3D 분석의 설계와 구현에 대해 기술한다. 많은 양의 데이터를 2D로 표현했을 때의 문제를 해결하고, 직관적인 데이터 분석, 오류 검출, 특성이 나 유사도와 같은 유의미한 데이터 추출이 가능하고, 사용자 편의성을 제공할 수 있다. 본 논문은 선행연구에서 진행 한 2D 시각화로 한자로 된 조선시대 시문을 분석했을 때의 문제점을 개선하였다.
ABSTRACT
With the development of technology for visualizing big-data, tasks such as intuitively analyzing a lot of data, detecting errors, and deriving meaning are actively progressing. In this paper, we describe the design and implementation of a 3D analysis that collects and stores the writing data in Chinese characters provided by the Korean Classical Database of the Korean Classics Translation Institute, stores and progress the data, and visualizes the writing information in a 3D network diagram. It solves the problem when a large amount of data is expressed in 2D, intuitive that analysis, error detection, meaningful data extraction such as characteristics, similarity, differences, etc. and user convenience can be provided. In this paper, we improved the problems of analyzing Chosun dynasty poetry in Chinese characters using 2D visualization conducted in previous studies.
키워드
: 데이터 시각화, 조선시대 문집 분석, 3D 네트워크 다이어그램, 3D 텍스트 분석, 한자 분석
Keywords
: Data visualization, Analysis of chosun dynasty writings, 3D network diagram, 3D text analysis, Chinese character analysis
Received 13 May 2021, Revised 18 May 2021, Accepted 6 June 2021
* Corresponding Author Byoung-Chan Lee(E-mail:[email protected], Tel:+82-42-630-9148) Researcher, Department of General Education, Woosong University, Daejeon, 34606 Korea
Open Access
http://doi.org/10.6109/jkiice.2021.25.7.861
print ISSN: 2234-4772 online ISSN: 2288-4165This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License(http://creativecommons.org/li-censes/ by-nc/3.0/)
Ⅰ. 서 론
데이터의 양이 많아지면서 이를 효과적으로 분석하 기 위해 하둡, NoSQL 등 분석 인프라 기술과 통계처리, 데이터 마이닝, 그래프 마이닝 등 다양한 기술이 개발되 었다. 분석한 데이터는 각종 그래프, 워드 클라우드, 네 트워크 다이어그램, 생키 다이어그램 등 시각화 기법을 이용해 직관적인 이해가 가능하도록 표현한다. 한국고 전번역원에서는 조선왕조실록을 비롯하여 조선시대 문 집의 원문을 사진과 함께 디지털화하고, 텍스트 검색이 가능하도록 원문과 해설 등의 자료를 제공하고 있다. 한 국고전종합DB(이하 종합DB라 약칭)를 통해 검색 서비 스를 제공하여 인문학자 등에게 다양한 정보를 제공[1]
하고 있다. 하지만 데이터는 텍스트 기반의 검색 중심 서비스로 제공되어, 원문 데이터를 효과적으로 분석하 기엔 한계가 있다.
이에 본 연구자들은 선행연구[2]를 통해 D3JS(Data Driven Document JavaScript) 기반의 네트워크 다이어 그램[3]을 이용하여 종합DB에 있는 문집정보를 시각화 하고, 이를 통해 인문학적 의미를 도출하는 연구를 수행 한 바 있다. 선행연구는 고전 문집 분석 시각화의 첫 단 계로, 의미 있는 결과를 도출하였지만 데이터 양이 방대 하여 평면에 많은 양의 텍스트를 표현하는 2D 기술이 갖는 한계와 성능 문제를 확인할 수 있었다[2]. 또 데이 터 시각화를 위해 노드와 엣지 정보를 각각 CSV(Comma Seperate Value) 파일로 관리하는 불편함이 있었다.
본 논문에서는 종합DB에서 API로 제공되는 문집자 료[1]를 자동 수집(Crawling)하여 데이터베이스에 저장 하고, 원문을 음절 단위로 분리해 데이터를 가공한다 [2]. D3JS 기반의 3D로 변환하는 3d-force-graph[4]를 이용해 3D 형태로 데이터를 시각화하여, 평면에 많은 글자나 데이터를 표현하기 어려운 2D 시각화의 한계[2]
를 넘어 문집에 수록된 모든 시문(詩文)의 특성을 파악 할 수 있도록 기술적인 설계와 결과를 보여준다. 이러한 3D 데이터 시각화를 이용하여, 한 문집에 수록된 모든 시문의 주요 어휘를 파악함은 물론이고, 두 문집의 시문 에 공통으로 사용되는 어휘, 특정 문집에만 출현하는 어 휘, 여러 문집에 공통으로 사용된 어휘 등을 직접 비교 할 수 있다. 이는 뉴스 기사의 토픽을 분석해 텍스트 기 반으로 한 시각화[5] 같은 기존 연구방식보다 진화된 형 태로, 인문학 데이터 분석에 최적화하였다. 또 인문학자
의 기억에 기반한 기존 연구방식을 벗어나 컴퓨터를 활 용해 시각화된 결과를 통해 저자의 어휘에 사용되는 패 턴을 찾을 수 있다.
이를 위한 본 논문의 구성은 다음과 같다.
2장에서는 문집 분석을 위한 설계에 대해 간단히 기 술하고, 3장에서는 문집 3D 시각화 결과와 인문학적 의 미에 대해 상세히 기술한다. 결론 및 향후 연구는 4장에 서 기술한다.
Ⅱ. 문집 분석을 위한 설계
2.1. 3D 시각화를 위한 문집 분석 절차
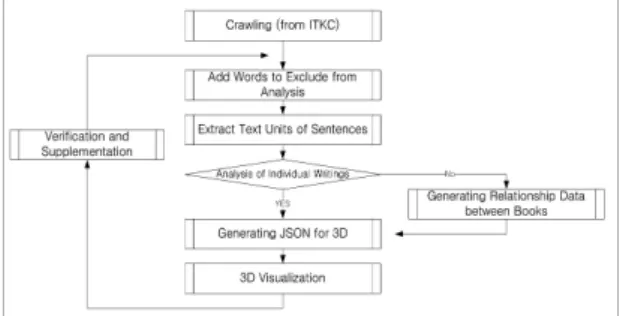
2D 또는 3D로 시각화하기 위해서는 데이터 가공이 필수적이다. 이를 위한 데이터 수집, 가공, 시각화 절차 가 그림 1에 나타나 있다.
Fig. 1 Flowchart of poetry analysis and 3D visualization procedure
표음문자인 한글과 달리 한자는 표의문자이다. 이는 음절마다 그 의미를 갖기 때문에 문장을 분석하는 방법 이 한글과 다르다. 이를 위해 크롤링한 데이터의 원문을 음절 단위로 추출한 후, 시각화를 위해 노드, 링크 구성 을 위한 JSON(JavaScript Object Notation) 형태로 변환 해 3D 네트워크 다이어그램[2][3]으로 시각화한다.
JSON으로 데이터를 관리하면 CSV로 처리할 때보다 노 드와 링크 정보를 하나의 파일로 관리할 수 있어 효과적 이다. 또 JSON으로 데이터를 송수신하는 AJAX (Asynchronous Javascript And XML)로 처리할 때 효과 적이다. 또한 강력한 WebGL 기술[6]을 이용해 웹 기반 으로 구현한다.
모든 설계와 구현은 인문학자들이 쉽게 사용할 수 있
는 환경을 고려하여 표준 HTML5 웹을 기준으로 하고,
모바일에서도 동일하게 표현된다.
2.2. 문집 단어 추출
음절 단위로 문장을 구분해 데이터베이스에 저장하 고, 각 음절마다 출현 빈도를 함께 저장한다. 모든 문장 이 음절 단위로 구분되기 때문에 문장에서 발생 가능한 모든 음절 조합을 데이터베이스에 저장한다. 예를 들어
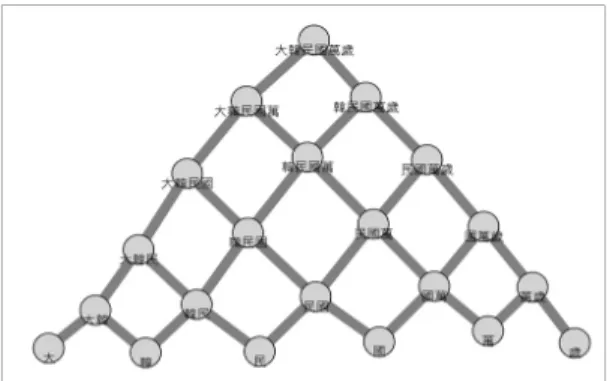
“大韓民國萬歲”라는 문장은 “大”, “韓”, “民”, “國”, “大 韓”, “韓民”, “民國”, “國萬”, “萬歲”, “大韓民”, …, “大 韓民國萬歲”와 같이 총 21개의 발생 가능한 모든 경우 에 대해 세분화하여 데이터베이스에 저장한다.
한자는 사전(dictionary) 데이터와 비교하지 않기 때 문에, 저장된 모든 음절 단위 단어가 의미 있는 데이터 인지 확인하지 않고 단어들의 관계만을 고려하여 시각 화를 수행한다. 예를 들어, 위에서 생성된 21개의 단어 중 “民”이라는 단어는 “韓民”, “民國”으로 확장된다. 이 와 같이 음절 단위 정보를 시각화하면 그림 2와 같은 시 각화를 예상할 수 있다.
Fig. 2 Visualization prediction of “DaeHanMinGook ManSe (大韓民國萬歲)”
즉, 그물망 구조(완전이진트리)의 Root 노드인 “大韓 民國萬歲”와 같은 긴 문장을 자주 사용하면 그림 2와 같 은 형태를 시각적으로 확인할 수 있다. 데이터의 출현 빈도에 따라 노드, 링크의 크기를 상대적 크기로 달리 표현하면서 문집 안에서의 출현 빈도를 직관적으로 이 해할 수 있다. 또 원근법에 기반하여 3D로 표현하기 때 문에 화면에 많은 데이터를 표현할 때 한계가 있는 2D 의 문제점을 개선할 수 있다.
한자의 단어 단위 문집 분석을 위해서는 단어별 노드, 링크 정보를 JSON으로 변환해야 한다. 그림 3은 단어별
노드, 링크를 생성하는 알고리즘을 슈도 코드로 나타내 고 있다.
Fig. 3 JSON generating algorithm for nodes and links by word
고전 문집의 문장 종류는 문장이 상대적으로 짧은 시 (詩)에서 매우 긴 상소문(上疏文)까지 다양하지만, 음절 단위로 세분화하면 상소문의 경우 데이터의 양이 기하 급수적으로 증가하므로, 데이터 분석이 용이하도록 연 구의 대상을 시로 제한하였다.
Ⅲ. 문집의 시문 3D 시각화 결과
3.1. 단일 문집의 시문 시각화
단일 문집의 시각화는 단일 문집에 출현하는 모든 단 어 분포를 3D로 시각화하여, 특정 문집을 저술한 저자 가 자주 사용한 어휘발견을 목적으로 한다.
조선 후기, 청음 김상헌이 저술한 청음집에 수록된 자 료 중 시(詩)만 별도로 추출해 2음절 이상의 단어, 출현 빈도 2회 이상인 데이터를 3D 시각화한 결과가 그림 4 이고, 네트워크의 복잡성을 시각화하면 이미지를 생성 할 수 있다[7].
데이터를 나타내는 노드, 노드 사이의 관계를 나타내
는 링크를 이용해 전하량을 계산해 노드 사이의 최적 거
리를 표현하는 D3JS 기반의 네트워크 다이어그램을 이
용하면 원인-결과, 근원지-목적지 등의 표현이 효과적
이다. 마우스의 스크롤과 회전으로 시각화 결과화면에
서 눈에 띄는 부분으로 접근해 구체적인 데이터 분포를
확인할 수 있다.
Fig. 4 Visualization result of CheongEumJip (2 syllables, 2 or more times)
그림 4는 노드 11,159개와 링크 4,856개를 시각화하 고 있다. 2D로 수천 개 이상의 노드와 링크(엣지) 표현 시 화면이 복잡해지는 한계를 3D로 간단히 해결할 수 있다. 그림 4를 확대해 의미 있는 데이터를 찾으면 된다.
Fig. 5 Expanded result of the singularity of CheongEumJip
그림 5는 청음집 중 이중그물망 구조를 보이는 영역 을 확대한 모습으로 “萬城風雪過重陽(만성풍설과중양)”
문장을 그림 2의 원리로 표현한 모습이다. 그림 5의 흰 색 원으로 표시한 영역으로 3D 그래프를 이동해 보면 그림 6과 같다.
그림 6은 “萬城風雨近重陽(만성풍우근중양)”의 문장 을 그림 2의 원리로 표시한 영역으로 그림 5와 그림 6은 영어의 숙어처럼 활용되는 “萬城風 ○○重陽”와 같은 어휘 패턴을 확인할 수 있다. 이는 인문학 연구자에게 엄청난 시간이 요구되는 작자 글쓰기에 드러나는 어휘 활용과 특성 파악을 시각화 결과만으로 찾을 수 있음을 보인 대표적인 예이다.
Fig. 6 Opposite side of CheongEumJip singularity
3.2. 문집-문집 시각화
문집-문집 시각화는 두 문집에 출현하는 단어 중 두 문 집에 공통으로 출현하는 단어, 하나의 문집에만 출현하 는 단어 등을 시각적으로 표현하는 방법이다[2]. 즉 비교 하는 두 문집에 출현하는 단어의 합집합을 시각적으로 표현한다. 이 방법은 두 문집 사이 유사성과 차이를 시각 화 결과로 확인할 수 있다. 또 할아버지나 아버지로부터 어린 시절 교육을 받는 조선시대 관습을 고려하면, 아버 지나 할아버지가 그들만이 사용하는 어휘가 아들이나 손 자에게 자연스럽게 전수되는 영향 관계가 형성되며, 이 런 어휘를 찾을 때 유용하다. 노드나 링크에 마우스를 올 리면 해당 어휘의 출현 빈도를 확인할 수 있다.
하지만 이 방법은 데이터가 많은 두 문집에 출현하는 단어의 합집합을 표현하기 때문에, 데이터의 양이 매우 많아진다. 이런 점을 고려하여 1음절어가 1회 출현된 단 어 등 중요도가 낮은 단어 등을 시각화에서 제외함으로 써 시스템의 성능저하를 선택적으로 예방할 수 있다.
그림 7은 청음집(3회 이상 출현)과 퇴우당집(2회)을 동시에 비교하여 노드 5,282개와 링크 1,542개에 대한 두 문집 사이의 관계를 3D로 나타내고 있다.
Fig. 7 Visualization result of between CheongEumJip and ToiWooDangJip
두 문집 사이의 관계는 링크에 움직이는 점의 색으로 구분하였고, 링크의 두께는 출현 빈도의 절대량을 의미 한다. 노드 크기는 3D 특성상, 원근법에 의해 크기가 변 하기 때문에 동일한 크기로 설정하였다.
성능을 위해 필터링 기능을 추가하여 불필요한 데이 터를 제거하면 단일 문집 분석과 비교했을 때보다 효과 적인 결과를 산출할 수 있다.
Fig. 8 The double-net network of two books comparison visualization (CheongEumJip and ToiWooDangJip)
그림 8은, 그림 5와 그림 6에서 찾을 수 있었던 이중 그물망 구조가 단순화되어 표현된 예이다. 이는 필터링 을 통해 화면에 표현되는 데이터양이 줄어든 영향이 크 다. “萬城風雪過重陽(만성풍설과중양)”과 “萬城風雨近 重陽(만성풍우근중양)”를 더 쉽게 확인할 수 있다.
3.3. 다중 문집 시각화
다중 문집 시각화는 여러 문집에 공통으로 등장하는 어휘를 찾기 위한 기능으로, 할아버지-아버지-아들과 같은 형태로 교육이 전달되는 과정에서 영향 관계를 시 각적으로 확인하기 위한 방법이다[2]. 문집-문집의 비교 는 두 문집의 합집합을 구해 두 문집을 상세 비교하는 반면 다중 문집 시각화는 여러 문집을 동시에 비교하기 때문에 연산과 화면에 표현되는 데이터양을 고려해야 만 한다. 이를 위해 문집에 공통으로 출현하는 단어 즉, 교집합이 사용되었다.
그림 9는 청음 김상헌 가계의 주요 문집인 청음집, 곡 운집, 문곡집, 퇴우당집, 노가재집, 포음집 6개 문집을 다중 비교해 청음집을 기준으로 표현한 화면이다. 6개
문집을 순차적으로 비교해야 해 링크의 색상과 두께로 데이터를 구분하였다. 전술한 것처럼 노드 크기는 원근 법으로 표현하는 3D의 특성상 데이터 크기를 효과적으 로 표현하지 못한다. 출현 빈도를 링크 두께로 구분하 고, 링크 색으로 표현된 흰색이 청음집을 나타낸다.
Fig. 9 Compare multiple books (based on CheongEumJip)
그림 10은 같은 방법으로 6개 문집 중, 문곡집을 기준 으로 시각화한 화면이다. 청음집과 비교하여 어휘별 출현 빈도가 달라 링크의 두께가 청음집과 비교해 차이가 있다.
또 문곡집을 구분하는 링크 색상으로 녹색이 사용되어 각 문집마다 출현 빈도를 직관적으로 이해할 수 있다.
Fig. 10 Compare multiple books (based on ToiWooDangJip)
3.4. 간찰 데이터 시각화
간찰(簡札)은 편지를 의미하는 데이터로 보낸 사람과 받는 사람이 표시되어 있어 문집에 기록된다. 그래서 간 찰 데이터의 제목을 단순 텍스트 분석 후 시각화만으로 인물 관계를 정확하게 확인할 수 있다. 정확한 이해를 위해 조선시대 문집이 편찬되는 과정을 잠시 살펴볼 필 요가 있다. 옛 문인들은 사후 자신의 기록이 문집으로 출판되는 것을 고려하여 편지를 보낼 때 대부분 사본을 만들어 놓고, 수신할 때도 모두 기록으로 남겼다. 이를 토대로 보낸 편지와 받은 편지 제목의 대부분에서 보낸 사람과 받은 사람에 대한 기록을 확인할 수 있다. 이렇 게 보존된 간찰의 송수신자 정보는 인물의 인맥관계를 파악할 때 중요한 자료로 활용할 수 있어, 한 인물에 대 한 인맥 네트워크를 시각화할 수 있다. 그뿐만 아니라, 간찰을 주고받은 횟수에 따라 이름에 대한 출현 빈도가 달라져 해당 인물과의 중요도까지 확인할 수 있다. 원칙 적으로 보낸 사람과 받은 사람에 대한 정보를 얻기 위해 디지털화 된 XML 정보를 확인하는 것이 바람직하지만, 종합DB의 경우 XML 태깅 작업이 완전하지 못해 텍스 트 분석을 통해 인물 네트워크를 확인할 수 있다.
그림 11은 남당집의 간찰 중, 교류 관계를 확인할 수 있는 제목만을 전술한 방법으로 음절 단위로 구분하여 시각화한 예이다.
그림 1의 순서도에 분석 제외할 단어 처리하는 과정이 포함되어 있다. 일반적으로 문집의 경우 장 (Chapter, 원 문에는 其㊀, 其二 등)을 나타내는 순번 정보가 포함되어 있고, 간찰의 경우에는 제목에 “答洪吉童(답홍길동)”과 같이 답장을 의미하는 단어가 출현한다. 그뿐만 아니라 간찰을 송수신한 날짜를 나타내는 육십갑자 연월일 표기 가 많다. 이와 같은 인물정보를 파악할 때는 불필요한 정 보이므로 제외 후 처리해야 정확한 결과를 얻을 수 있다.
Fig. 11 Visualization of letter title of NamDangJip
그림 12는 불필요한 날짜, 답(答) 정보 등을 필터링한 후의 시각화 된 결과로, 그림 11보다 정확한 결과화면을 보인다.
Fig. 12 Visualization of letter title of NamDangJip (After filtering)
3.5. 데이터 검색
2D나 3D로 데이터를 시각화하기 위해서는 많은 양 의 데이터에서 원하는 데이터를 찾기 어려운 문제가 있 다. 이는 아무리 잘 만들어진 시각화 결과라도 수천, 수 만 이상의 데이터에서 원하는 데이터를 찾지 못하면 활 용이 쉽지 않기 때문에 중요한 문제이다.
Fig. 13 3D visualization search results
그림 13은 JSON 데이터를 이용해 AJAX로 검색 결과 목록을 가져온 후, 사용자가 선택 시 원하는 데이터를 3D 화면의 맨 앞으로 가져오는 검색 결과를 보인 예이다.
3.6. 인문학적 의미
문집 연구는 결국 모든 자료의 상호 관계와 그 의미를
파악하는 작업으로 관계의 확인은 네트워크 다이어그 램으로의 시각화가 필연적이다. 시각화는 복잡한 데이 터 중에서 가장 중요한 정보를 확인하는 유용한 방법이 다. 문집 연구의 핵심은 저자가 지닌 특성 즉 타인과의 차별성을 파악하고, 그 가치를 판단하는 것이다. 그 차 별성은 결국 어휘로 표출되며 동일 어휘의 공유는 문집 사이의 상관성을 보여준다. 아울러 자신만의 특별한 어 휘 사용은 그 문집의 특성이 될 수 있다. 선행연구에서 이런 실상을 직관적으로 확인할 수 있는 2D 시각화로 획기적인 인문학 연구 방법론 변화와 결과를 도출하였 으나 한정된 화면과 평면이라는 한계도 드러났다.
자료의 복잡성으로 2D 시각화는 인문학 연구자가 원 하는 정보를 효율적으로 확인하기 어려웠다. 결국 대안 은 3D 시각화이다. 어휘 정보 사이의 관계를 입체적으 로 보여주며 다양한 표출에 효율적이다. 그리고 인물 관 계망에도 유용하게 활용할 수 있다. 이러한 많은 양의 복잡한 관계를 표현하는 방법은 현재로는 3D 시각화가 유일한 대안으로 보인다. 본 연구는 이러한 측면에서 인 문학 연구의 진보를 가져오는 좋은 방법론이다.
Ⅳ. 결론 및 향후 연구
인문학에서는 데이터를 시각화하는 것이 상대적으로 뒤떨어져 있다. 한국고전종합DB에는 수많은 연구자가 활용하는 우리나라 고전 인문학 연구의 중요한 보고[2]
인데, 이 데이터를 크롤링 후 가공하여 D3JS 기반으로 만들어진 3d-force-graph[4]를 이용해 3D로 문집 데이터 를 시각화하였다. D3JS 기반의 네트워크 다이어그램은 노드와 엣지의 색, 크기, 굵기 등을 다양화해 표현을 자 유롭게 할 수 있다[8]. 하나의 문집을 상세히 분석한 문 집 시각화는 물론이고, 두 문집 사이의 관계나 유사도 확인을 위한 문집-문집, 다중 문집 3D 시각화는 선행연 구에서 진행한 모든 내용을 3D로 시각화하는 것이 가능 하며, 기존의 2D로 표현했을 때 생기는 평면의 한계에 서 생기는 문제를 해결하고, 많은 양의 데이터 시각화에 직관성과 사용자 편의성, 확장성을 제공한다. 또 시각화 된 결과에서 검색 기능을 이용해 방대한 데이터를 가진 문집 데이터에서도 효과적으로 사용할 수 있다. 그뿐만 아니라 별도의 추가 작업 없이 간찰 데이터의 제목만을 추출하여 시각화하면서 문집에 수록된 인물 관계를 시
각화할 수 있다. 이 방법은 표준 HTML을 준수하기 때 문에 웹브라우저만으로 동작하고, 모든 노드는 클릭하 면 원문을 바로 확인할 수 있다. 이런 방법은 주 사용자 가 인문학자임을 고려하였다.
본 연구에서 제시된 방법을 통해 많은 양의 인문학 데 이터에서 문집 전체 또는 시문의 특성이나, 문집 사이 유사도 확인에 도움이 되고, 인문학 외에도 다양한 분야 에서 관계 분석에 활용할 수 있을 것으로 기대한다.
향후 연구로는 데이터양에 따라 컴퓨터의 성능에 영 향을 미치기 때문에 데이터에 필터를 사용하였는데, 성 능의 한계치 등에 관한 연구가 필요하다. 또 인문학 연 구자들과 협업을 통해 인문학적으로 의미 있는 기능의 보완 작업이 필요하다.
References
[ 1 ] S. P. Son, “An Idea on Compilation of Biographies for The Comprehensive Publication of Korean Classics in Premodern Times,” Journal of Korean Classics, vol 55, pp. 7-43, Jun.
2020.
[ 2 ] B. C. Lee and K. J. Min, “A Study on Visualization of the Analysis between the Collections of Korean Literature in Korea Classic DB,” Journal of Korean Classics, vol. 57, pp.
5-32, Mar. 2021.
[ 3 ] Meeks, Elijah, D3.Js in Action: Data Visualization with JavaScript, 2nd ed. Pennsylvania, PA: Manning Publications, 2017.
[ 4 ] GitHub – vasturiano, 3d-force-graph [Internet]. Available:
https://github.com/vasturiano/3d-force-graph.
[ 5 ] S. A. Kim, “Exploring the Trends and Challenges of Artifical Intelligence Education through the Analysis of Newspapers in Korea, 1991-2020: A topic-modeling approach,” Journal of Information and Communication Convergence Engineering, vol. 18, no. 4, pp. 216-221, Dec.
2020.
[ 6 ] G. Zhou and J. Xia. (2018, December). Using OmicsNe for Network Integrationt and 3D Visualization. Current protocols in Bioinformatics [Online]. Available: https://currentprotocols.
onlinelibrary.wiley.com/doi/abs/10.1002/cpbi.69.
[ 7 ] K. Daghan, “A Study on Data Visualization Utilizing Tree Structure in 3D Space,” Design D. dissertation, Seoul National University, Korea, 2019.
[ 8 ] J. J. Pokorny, A. Norman, A. P. Zanesco, S. Bauer-Wu, B.
K. Sahdra, and C. D. Saron. (2018, January). Network analysis for the visualization and analysis of qualitative data, Psychological Methods [Online]. Avalable:
https://doi.org/10.1037/met0000129.
민경주(Kyoung-Ju Min)
2006년 충남대학교 컴퓨터공학과 박사과정 수료 2008년~현재 : 유레카솔루션 대표
※관심분야 : 초고속네트워크, 네트워크보안, 데이터분석, 데이터시각화
이병찬(Byoung-Chan Lee)
2001년 단국대학교 한문학과 문학박사 2015년~현재 : 우송대학교 교양대학 연구원
※관심분야 : 텍스트마이닝, 데이터분석