水 工 學
大 韓 土 木 學 會 論 文 集第30卷 第4B 號·2010年 7月 pp. 367 ~ 377
극한강우를 고려한 SIR알고리즘과 Bootstrap을 활용한 강우빈도해석
Rainfall Frequency Analysis Using SIR Algorithm and Bootstrap Methods
문기호*·경민수**·김형수***
Moon, Ki Ho · Kyoung, Min Soo · Kim Hung Soo
···
Abstract
In this study, we considered annual maximum rainfall data from 56 weather stations for rainfall frequency analysis using SIR(Sampling Important Resampling) algorithm and Bootstrap method. SIR algorithm is resampling method considering weight in extreme rainfall sample and Bootstrap method is resampling method without considering weight in rainfall sample.
Therefore we can consider the difference between SIR and Bootstrap method may be due to the climate change. After the fre- quency analysis, we compared the results. Then we derived the results which the frequency based rainfall obtained using the data from SIR algorithm has the values of -10%~60% of the rainfall obtained using the data from Bootstrap method.
Keywords :
bootstrap, sir algorithm, rainfall probability···
요 지
본 연구에서는 기상청 산한 56개 기상관측소의 연최대치계열 일 강우자료를 대상으로 Bootstrap기법과 SIR알고리즘을 이 용하여 표본을 재추출한 후, 빈도해석을 적용하여 결과를 비교검토 하였다. SIR알고리즘은 기존에 발생되었던 극한 사상에 가중치를 두어 표본을 재추출하는 방법으로 과거에 발생한 극한사상이 기후변화에 의해서 더욱 빈발하게될 것 이라는 가정 에 기초한다고 할 수 있다. 반면에 Bootstrap기법은 현재 발생한 사상에 동일한 가중치를 두어 표본을 재추출하는 방법이다.
따라서 두 방법의 차이를 계산하여 기후변화로 인한 극한강우의 빈도별 확률강우량의 변화를 산정할 수 있다. 비교결과 SIR 알고리즘에 의하여 재추출된 강우를 이용하여 산정된 확률강우량의 경우, Bootstrap기법에 의해서 재추출된 강우를 이용하여 산정한 확률강우량에 비해 지점에 따라 작게는 -10%정도의 감소와 크게는 60%정도의 차이를 보임을 확인하였다.
핵심용어 : Bootstrap, SIR 알고리즘, 확률강우량
···
1. 서 론
세계적으로 기후변화로 인한 강우의 양과 패턴의 변화로 인하여 다양한 형태의 재해가 발생하고 있으며 , 이러한 이유 로 인하여 변화하고 있는 강우량을 고려하여 빈도해석을 해 야 한다는 주장이 제기되고 있다 . 우리나라의 경우도 기후변 화로 인해 강우량이 증가하는 양상을 보이고 있으며 , 과거
관측 자료에서 볼 수 없는 집중호우와 홍수로 인하여 수공 구조물 설계시 가장 중요한 요소인 설계빈도를 초과 하는 강우가 발생하고 있다 . 이러한 새로운 강우사상을 분석하기 위해 국내외 많은 연구가 이루어지고 있다 . 김병식 등 (2008)
은 기후변화 시나리오를 이용한 미래 극한강우의 특성분석 과 IDF 분석을 실시하여 미래의 기후변화가 극한 강우에 어 떠한 영향을 미치는가를 평가한 바 있고 , 경민수 등 (2009) 은
기후변화로 인한 우리나라의 극한홍수의 예측과 평가를 위
해 GCM(Global Climate Model) 으로부터 지상 관측소지점
으로 축소된 월 총강수량을 기반으로 일강수를 모의할 수 있는 강수발생모형을 제시하였다 . 또한 강수발생모형으로부 터 재현된 연 최대치 시계열을 대상으로 빈도해석을 수행함 으로써 기후변화가 우리나라의 빈도별 일 강수량에 미치는
영향을 평가한 바 있다 . 외국의 사례를 보면 , Yue 등 (2003)
은 일본지역을 대상으로 강우 월 자료와 년 자료를 Mann- Kendall test 와 Bootstrap test 를 이용하여 경향성을 분석 평
가한 바있고 , Ekstrom 등 (2005) 은 영국의 미래 강우 시나리
오를 이용한 지역 빈도 해석 (Regional Frequency Analysis) 과
각각의 격자 분석 (Grid Box Analysis) 방법을 이용하여 극한
강우의 변화 양상에 대해 평가한 바 있다 . 또한 Samuels
등 (2009) 은 요르단강 지역을 대상으로 Hidden Markov 모
*
(
주)
이산수자원부(E-mail : [email protected])
**정회원·삼성화재해상보험
(
주)
삼성방재연구소선임연구원·공학박사(E-mail : [email protected])
***정회원·교신저자·인하대학교사회기반시스템공학부정교수·공학박사
(E-mail : [email protected])
델을 이용하여 극한강우의 영향으로 인해 변하는 홍수의 경 향성을 평가하였다 .
본 연구에서는 연최대 일 강우사상에 대하여 표본재추출 기 법인 Bootstrap 방법과 SIR(Sampling Importance Resampling)
알고리즘을 적용하여 다수의 연최대 강수사상을 각각 발생 시킨 후 , 빈도해석을 적용하여 결과를 비교검토 하였다 .
표본재추출기법은 통계학적인 방법으로 자료를 분석할 때 부족한 자료의 수를 충분한 수 만큼 만들어 내고자 할 때 일반적으로 사용된다 . 가장 대표적인 방법인 Boostrap 방법은 비교적 간단하기 때문에 많은 연구가 이루어지고 있다 . 김병 식 등 (2002) 은 AR(1) 모형 , PAR(1) 모형과 같은 추계학적 모
형의 잔차값에 Bootstrap 기법을 적용시켜 연 및 월 유출량
자료를 모의한 바 있고 권현한 등 (2004) 은 댐의 초기수위
결정을 위해 비매개변수적 핵밀도함수 방법과 Bootstrap 기법
을 적용하여 신뢰 구간을 추정한 바 있다 . 서영민 등 (2009)
은 Bootstrap 기법을 이용하여 불확실성을 고려한 강우빈도해
석모델 구축과 적용을 통해 홍수위험도 평가등의 불확실성 처리기법을 제시한 바 있다 . 또한 Zhao 등 (1997) 은 단위도
의 불확실성 분석을 위해 Bootstrap 기법을 적용하여 태풍시
기의 강우사상을 표본재추출한 바 있고 , Srinivas 등 (2005) 은 여러지역과 계절의 홍수량의 추계학적 모의를 위해 다중이 동블럭붓스트랩 (Hybrid moving block bootstrap) 기법을 이용
한 바 있다 . Beersma 등 (2007) 은 연 최대치 계열의 강우
자료를 이용하여 지역빈도해석와 시계열분석을 하여 네덜란 드 6 개 지역의 가뭄에 대한 평가를 하면서 시계열분석을 위 해 Bootstrap 기법을 적용한 바 있다 .
SIR 알고리즘은 Bootstrap 에서 파생된 기법으로 우도함수를 고
려하여 표본을 재추출 할 수 있는 장점을 가지고 있다 . 이명우 등 (2005) 은 Boostrap 기법과 SIR 알고리즘을 이용하여 확률강우 량의 비교와 위험도 분석을 수행한 사례가 있으며 , 문기호 등
(2008) 은 SIR 알고리즘을 이용하여 홍수량에 대한 비도해석을
수행한 바 있다 . 또한 Moradkhani 등 (2005) 은 SIS(Sequential Importance Sampling), SIR 을 이용한 PF(Particle Filter) 방법으 로 산정된 상태변수와 모델 매개변수 평가를 위해 새로운 연 속수문자료동화 보정기법을 연구한 사례가 있으며 , Li(2007) 는
저수지의 용량을 정하기 위해 SIR 알고리즘을 적용한 바 있다 .
본 연구에서는 Bootstrap 방법과 SIR 알고리즘을 이용하여 표본을 재추출 한 후 재추출된 표본을 이용하여 확률강우량 산정 및 우리나라의 강우사상의 경향성을 분석 하고자 한다 .
실제로 이명우 등 (2005) 에서도 SIR 알고리즘을 이용하여 확
률강우량을 산정하였으며 , 이때 SIR 알고리즘에서 중요한부분 인 우도 함수의 선정 방법을 연속된 강우사상의 표준편차를 이용하여 선정한 바 있다 . 하지만 수문사상에 있어서는 자료 의 평균과 표준편차의 개념보다는 극한사상을 고려하는 것 이 더 효과적일 것이라 생각된다 . 따라서 본 연구에서는 극 한사상을 고려한 우도함수를 선정하여 표본을 재추출 하였 고 재추출된 표본을 이용하여 빈도해석을 수행하였다 . 또한 표본재추출 과정에서 발생하는 불확실성을 정량화 함으로써 기존의 연구와 차별화 하였다 .
SIR 알고리즘과 Bootstrap 방법에 의해서 재추출된 강우의
차이를 통해서 산정된 확률강우량은 향후 변화하는 강우의 양을 고려한 수공구조물을 설계하는데 유용한 정보로 제공
할 될 수 있을 것이라 생각된다 . 또한 기후변화로 인하여 크게 대두되고 있는 강우량의 변화에 대해서 , 기후모형으로 부터 산정된 데이타와의 비교 자료로도 충분히 활용될 수 있을 것이라 생각된다 .
2. 이론적 배경
2.1 Bootstrap
다양한 분야에서 사용되고 있는 대부분의 통계이론은 계산
능력이 미미했던 1930 년대부터 이루어 졌으며 , 분석 대상이
되는 자료는 대부분 정규성을 가정으로 하여 계산되어 졌다 .
그러나 컴퓨터의 발전에 따른 계산능력의 향상으로 인해
1980 년대 이르러는 컴퓨터를 이용한 통계방법의 필요성을 느 끼게 되었고 확정론적 접근방법이나 추계학적 접근방법 등 에 대한관심이 증가하기 시작하였다 . 또한 컴퓨터의 계산속
도의 발전에 힘입어 Monte Carlo 방법의 활용성이 증가하
게 되어 과거 처리하기 복잡한 통계문제도 효과적으로 처리 할 수 있게 되었다 (Eforn and Diaconis, 1983).
Eform(1979) 에 의해 제안된 Bootstrap 방법은 주어진 표본
을 토대로 표본 재추출을 하여 분석 대상이 되는 통계량의 성질을 파악하는 기법으로 , 복잡한 문제들을 포함한 많은 통 계문제에 여러 가지 이론적 이점들이 밝혀져 왔으며 , 더욱이 컴퓨터의 발전으로 인하여 그 효용서이 더욱 높아지고 있다
( 전명식 , 1996).
Bootstrap 방법은 어떠한 표본 자료에서 알려져 있지 않은
확률분포 g ( θ ) 로부터 크기가 n인 무작위 표본 X =( θ
1, θ
2, … ,
θ
n) 를 얻었다고 할 때 , 관찰값 X로부터 경험적 분포 h ( θ ) 를
만든 뒤 무작위 추출표본 를 h ( θ ) 로부터
얻는 것을 말하며 , 이를 Bootstrap 표본 이라고 통칭한다 . 여
기서 근본적인 개념은 표본 에서 얻어진 추측통계량과 Bootstrap 표본 에 의해 얻
어진 추측통계량의 조건부확률분포는 서로 적절한 조건하에
서 유사할 것이라는 점이다 ( 전명식 , 1990). 본 연구에서는
관측자료로부터 Bootstrap 표본 을 추출하기 위하여 Monte- carlo 방법을 이용하였다 . 다음 Fig. 1 은 전명식 등 (1997) 에
서 제시한 Bootstrap 과정을 나타낸 것이다 .
2.2 SIR 알고리즘
SIR 알고리즘은 Monte Carlo 베이지안 기법의 한 종류로
서 Weighter Bootstrap Sampling 이라고도 불리어진다 . 이 기법은 기존의 고전적인 분석 방법에 비해 유용한 사전정보 의 사용을 가능하게 하고 크기가 작은 표본일 때에 상대적
으로 더 신뢰성 있는 분석을 할 수 있는 방법이다 . SIR 알고
리즘의 주된 목적은 관심 있는 모수의 사후밀도함수를 사전 X
*=( x
1*, , , x
2*… x
n*)
X
=( θ
1, , , θ
2… θ
n) X
*=( x
1*, , x
2*… x ,
n*)
Fig. 1 Bootstrap process
밀도 함수와 우도 함수로부터 구하는 것이다 . 본 연구 에서 는 우도함수를 연최대치 일 강우사상을 이용하였다 .
Rubin(1987) 이 제시한 SIR 알고리즘의 방법은 g ( θ ) 라는 확 률분포로부터 표본 값을 직접 모의하기 어려울 때 g ( θ ) 와 유사하고 모의가 비교적 쉬운 h ( θ ) 를 결정하여 이를 산정 된 사전확률분포에 적용하는 방법이다 . 즉 , 사전확률 분포 h ( θ ) 를 결정하고 , 결정된 사전확률분포 h ( θ ) 로부터 크기가 n
인 표본 을 설정한 후 표본 X의 가중치 w ( θ
i) 를 계산한다 . 여기서 표본 X로부터 θ
i가 선택될 확률이 w ( θ
i) 에 비례한다고 가정하고 를 생성하는 과정이 SIR 알고리즘 이다 .
w ( θ
i) 는 다음과 같은 방법으로 구할 수 있다 . 즉 , θ는 우리 가 알고자 하는 매개변수이고 , 이 θ는 사후밀도함수 로부터 구해진다 . 여기서 π ( θ ) 는 우도 함 수 , k는 비례상수이며 , 사전밀도함수로부터 표본을 위하는 것이 가능하다는 전제하에서 계산된다 . 위의 SIR 알고리즘에서 h ( θ )= π ( θ ) 이고 , g ( θ )=p( θ | data ) 이면 가중 함수는 식 (1) 과 같다 .
(1)
여기서 , 를 사전밀도함수 π ( θ ) 로부터의 표본
이라 하면 , 이로부터 사전밀도함수의 표본 를
특정한 가중확률 를 갖고 대체
하는 사후밀도함수의 대략적인 표본 를 얻을 수 있다 . 자료를 관측하기 이전에 각 θ
i는 모두 1/ n만 큼의 가중치를 갖고 있으며 , 이러한 가중치는 우도함수와의
곱을 통해 배가된다 ( 이명우 등 , 2005).
3. 확률강우량 산정
3.1 대상지점
본 연구에서는 우리나라 기상청 산하에 있는 기상관측소
76 개 중 비교적 관측 자료의 수가 많은 56 개 지점을 대상
으로 하였고 , 56 개 지점에 대하여 크게 우리나라를 4 등분하 여 각 부분에서 1 개의 지점식 4 개지점 ( 서울 , 울산 , 광주 , 인 제 ) 을 대표 지점으로 선정하여 시계열도 및 통계값을 제시하 였다 . 다음의 Table 1 과 Fig. 2 는 전국 56 개 대상지점을 나 타낸 것이다 .
3.2 자료의 이용
본 연구에서는 각 지점별 기상관측소의 과거 관측 시작년 X
=( θ
1, , , θ
2… θ
n)
X
*=( θ
1*, , , θ
2*… θ
n*)
π θ|data ( ) k π θ
=⋅ ( ) L θ ⋅ ( )
w θ ( ) g θ ( ) h θ ⁄ ( ) π θ (
|data) π θ ( )
---
k L θ ⋅ ( )
= = =
X θ (
1, , , θ
2… θ
n)
X θ (
1, , , θ
2… θ
n) L θ ( )
i =( L θ ( ) L θ
i, ( ) … L θ
2, , ( )
n)
X
*=( θ
1*, , , θ
2*… θ
n*)
Table 1. The sample size of 56 observations
No. Observation duration No. Observation duration
1 Gangneung 1961~2006 29 Yangpyong 1972~2006
2 Ganghwa 1972~2006 30 Yeosu 1961~2006
3 Geoje 1972~2006 31 Yeongju 1972~2006
4 Gochang 1972~2006 32 Yongcheon 1972~2006
5 Goheung 1972~2006 33 Wando 1972~2006
6 Gwangju 1961~2006 34 Ulleungdo 1961~2006
7 Gumi 1972~2006 35 Ulsan 1961~2006
8 Gunsan 1967~2006 36 Uljin 1971~2006
9 Namwon 1972~2006 37 Uiseong 1972~2006
10 Namhae 1972~2006 38 Icheon 1972~2006
11 Daegwallyong 1971~2006 39 Inje 1972~2006
12 Daegu 1961~2006 40 InCheon 1961~2006
13 Daejeon 1968~2006 41 Imsil 1972~2006
14 Mokpo 1961~2006 42 Jangheung 1972~2006
15 Mungyeong 1972~2006 43 Jeonju 1961~2006
16 Boryeong 1972~2006 44 Jeongeup 1972~2006
17 Boeun 1972~2006 45 Jeju 1961~2006
18 Pusan 1961~2006 46 Jecheon 1972~2006
19 Buan 1972~2006 47 Jinju 1969~2006
20 Buyeo 1972~2006 48 Cheonan 1972~2006
21 Sancheong 1972~2006 49 Chongju 1966~2006
22 Seogwipo 1961~2006 50 Chupungryong 1961~2006
23 Seosan 1967~2006 51 Chuncheon 1965~2006
24 Seoul 1961~2006 52 Tongyeong 1967~2006
25 Sungsanpo 1972~2006 53 Pohang 1961~2006
26 Sokcho 1967~2006 54 Hapcheon 1972~2006
27 Suwon 1963~2006 55 Haenam 1972~2006
28 Suncheon 1972~2006 56 Hongcheon 1972~2006
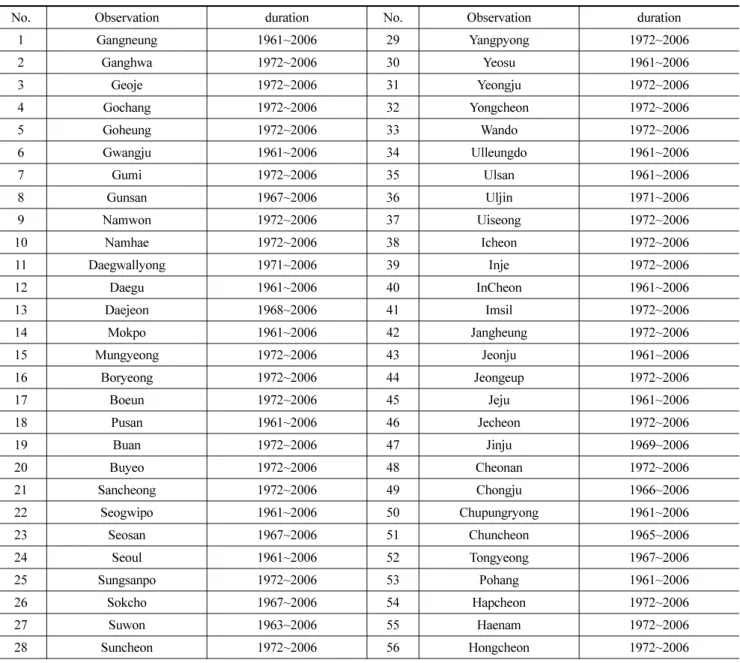
부터 2006 년 까지의 연최대치 계열의 일 강우사상을 이용하 였다 . Fig. 3 은 서울 , 울산 , 광주 , 인제 지점의 연 최대치계 열의 시계열도이며 , Fig. 4 는 56 개 지점에대하여 각 지점 연최대치 일 강우자료를 과거 ( 관측시작 년 ~ 총 년수 /2) 와 현
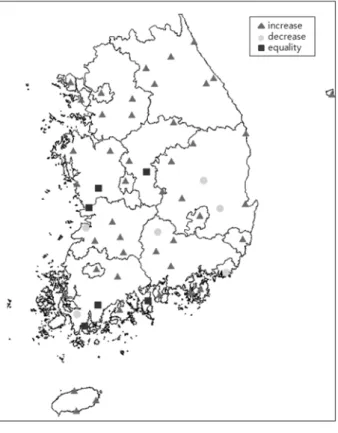
재 ( 총 년수 /2~ 마지막 년 ) 두 구간으로 나눈 후 각 지점의 연최대치 일 강우 자료 중 상위 10% 의 강우량 값을 기준 으로 과거와 현재 두 구간에서의 기준값 이상의 발생 회수 를 각각 파악하여 과거 구간에서 기준값 이상의 발생 회수 가 현재 구간에서의 발생회수보다 많으면 감소하는 경향을 나타내는 것이며 , 현재 구간에서 기준값 이상의 발생 회수가 과거 구간에서의 발생회수 보다 많으면 증가하는 경향을 나 타내는 것이다 . Table 2 는 서울 , 울산 , 광주 , 인제 4 개의 대 표지 점에 대하여 기준값을 기준으로 과거와 현재에 발생한 회수를 나타낸 것이다 .
그림을 통해 알 수 있듯이 증가하는 경향을 나타내는 지 점들이 대다수인 것을 볼 수 있다 . 이러한 증가 양상을 보 임에 따라 본 연구에서는 표본재추출기법인 Bootstrap 방법과 우도함수를 고려한 SIR 알고리즘을 이용하여 강우의 경향성 분석 및 확률강우량 산정하여 하고자한다 .
다음의 Table 3 는 4 개의 대표지점의 강우자료에 대한 기
본적인 통계특성을 보여주고 있다 .
3.3 Bootstrap을 이용한 확률 강우량 산정
3.3.1 Bootstrap 방법을 이용한 표본 재추출
본 연구에서는 각 지점의 연최대치 일 강우자료를 이용하
여 Bootstrap 방법에 적용하였으며 , 재추출할 자료수는 1000
개로하였고 300 번 모의 하였다 . 모의 수 선정에 있어서
1000 개의 자료를 500 번 모의 하였을 때 각각의 분산을 이
용하여 수렴하는 구간을 찾았으며 , 300 번 이상의 모의 에서
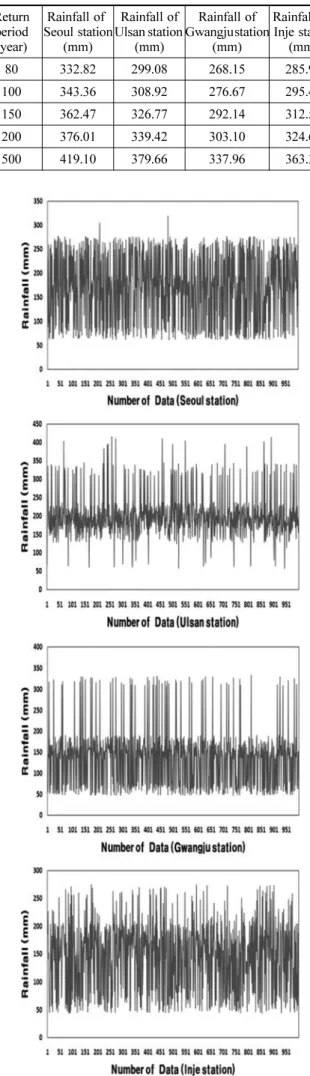
수렴하는 구간을 나타냈기에 모의 수를 300 회로 하였다 . 다 음 FIg. 5 는 4 개 지점을 300 번 모의한 표본자료 중 무작위로
선정한 자료이며 , Table 4 는 기본통계특성을 나타낸 것이다 .
Bootstrap 방법을 이용하여 표본 재추출을 하였을때의 기본
통계 특성을 살펴보면 관측된 자료와 비슷한 통계치를 나타
내고 있다는 것을 알 수 있다 . 이는 Boostrap 방법이 관측된
강우사상의 특성 및 분포형을 그대로 유지 하면서 생성된 자료이기 때문이다 .
3.3.2 Bootstrap 을 이용한 빈도해석 Fig. 2 The location of observations
Fig. 3 Annual maximum rainfall
Bootstrap 방법으로 얻어진 재추출된 표본자료를 이용한 빈 도해석을 수행하기 위해 우선 재추출된 표본자료의 분포형 선정하였다 . 분포형 선정을 위해 Chi-square 검정과 Kolmogrov-
Smirnov 검정을 이용하였다 . 본 연구에서는 2 가지 검정을 통
과한 Gumbel 분포를 선정하였으며 , 선정된 분포형을 이용하
여 빈도해석을 수행하였다 . 다음 Fig. 6 는 Bootstrap 방법으로
재추출된 1000 개의 자료를 300 번 모의 했을 때의 4 개 지점
에 대한 불확실성을 나타낸 것이며 , Table 5 는 각 빈도별 평균 확률강우량값을 나타낸 것이다 .
Fig. 6 을 보면 재현기간이 커짐에 따라 불확실성도 커지는
것을 알 수 있으며 , 빈도별 평균 확률강우량값은 서울지점이 가장 크게 나타났다 . 이에 따라 본 연구에서는 재현기간에 따른 평균 확률강우량을 이용하여 강우사상의 경향성에 대 한 비교 분석을 수행 하고자 한다 .
3.4 SIR알고리즘을 이용한 확률 강우량 산정
3.4.1 SIR 알고리즘을 이용한 표본 재추출
SIR 알고즘을 이용하여 표본을 재추출에서 중요한 부분은
우도함수의 선정이다 . 본 연구에서는 우도 함수의 선정에 있 어 연최대치 일 강우사상 중 상위 90% 이상의 극한강우 사 상을 이용하였고 , Bootstrap 방법과 동일하게 1000 개 자료를 재추출하여 300 번 모의 하였다 . 다음 Fig. 7 은 SIR 알고리즘 Fig. 4 Increase and decrease of Rainfall
Table 2. The trend of rainfall frequency at selected sites
Observation Referencevalue Frequency count
in past Frequency count in present
Seoul 261.6 1 5
Ulsan 208.3 2 4
Gwangju 176 2 4
Inje 200 1 4
Table 3. Statistical characteristics of Observation data
Statistics Rainfallof Seoul station(mm)
Rainfall of Ulsan station(mm)
Rainfall of Gwangju station(mm)
Rainfall of Inje station(mm)
Mean 155.91 135.24 127.68 126.37
Standard
deviation 65.13 72.67 58.48 53.75
Variance 4149.70 5166.75 3345.88 2804.63
Max 332.80 417.80 335.6 275.80
FIg. 5 The resampling results of Bootstrap
Table 4. Statistical characteristics of Bootstrap data
Statistics Rainfallof Seoul station(mm)
Rainfall of Ulsan station(mm)
Rainfall of Gwangju station(mm)
Rainfall of Inje station(mm)
Mean 154.72 135.91 123.24 127.62
Standard
deviation 62.17 72.18 55.18 52.41
Variance 3861.99 5204.38 3042.77 2744.33
Max 329.98 416.60 333.75 274.91
Fig. 6 The uncertainty of rainfall quantile using Bootstrap FIg. 7 The resampling results of SIR algorithm Table 5. The mean values of rainfall quantiles for given return
periods usign Bootstrap
Returnperiod (year)
Rainfall of Seoul station
(mm)
Rainfall of Ulsan station
(mm)
Rainfall of Gwangju station
(mm)
Rainfall of Inje station
(mm)
80 332.82 299.08 268.15 285.96
100 343.36 308.92 276.67 295.40
150 362.47 326.77 292.14 312.54
200 376.01 339.42 303.10 324.69
500 419.10 379.66 337.96 363.32
을 이용하여 4 개의 지점을 300 번 모의한 표 자료 중 무작
위로 선정한 자료이며 , Table 6 는 기본통계특성을 나타낸 것
이다 .
관측자료와 Bootstrap 방법을 이용하여 산정된 표본자료의 기본 통계특성을 SIR 알고리즘을 이용하여 재추출된 표본의 기본 통계특성과 비교해보면 평균 및 표준편차 그리고 분산 값이 크게 산정되어지는 것을 볼 수 있다 . 그러나 극치값은 관측자료나 Bootstrap 방법에 의해 재추출된 표본자료보다 작 거나 비슷한 값이 산정되었다 . 이를 통해 우도함수의 선정을 극한강우사상으로 하였을 경우 Fig. 6 에서 알 수 있듯이 관 측된 강우자료의 극치값 이상의 값이 추출 되는 것이 아니 라 우도함수로 선정한 극한사상의 값들이 많이 추출된다는 것을 알 수 있다 .
3.4.2 SIR 알고리즘을 이용한 빈도해석
SIR 알고리즘을 이용하여 얻어진 재추출 표본자료를 이용한 빈도해석을 수행하기 위해서 Bootstrap 방법을 이용하여 빈도 해석을 수행하였을 때와 같은 검정방법으로 분포형을 선정 하여 빈도해석을 수행하였으며 , 검정을 통해 선정된 분포형 은 Gumbel 분포이다 . 다음 Fig. 8 은 SIR 알고리즘으로 1000 개
의 자료를 300 번 모의했을 때의 4 개 지점에 대한 불확실성
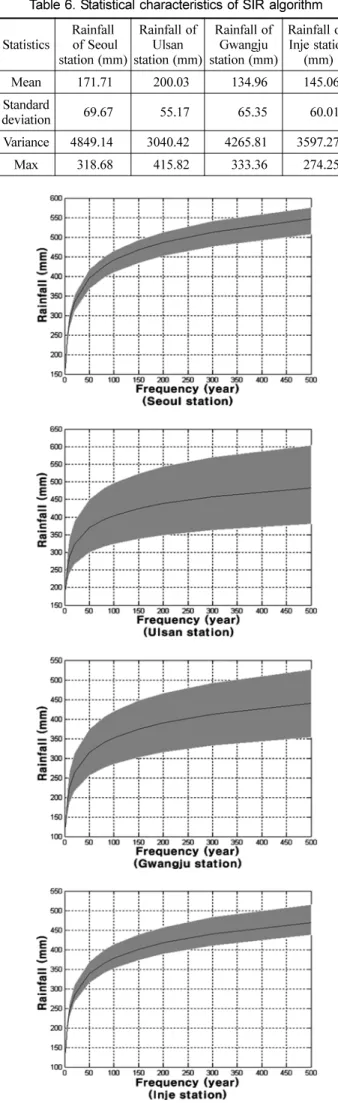
을 나 낸 것이며 , Table 7 는 각 빈도별 평균 확률강우량값
을 나타낸 것 이다 .
Fig. 8 또한 Fig. 6 와 같이 재현기간이 커짐에 따라 확률
강우량에 대한 불확실 성이 커지는 것을 알 수 있었다 . 특 히 광주지점과 울산지점은 Fig. 6 의 같은 지점에 비해 확률 강우량의 불확실성범위가 확연히 크다는 것을 알 수 있다 . 이 처럼 광주와 울산지점의 불확실성 범위가 크다는 것은 SIR
알고리즘을 이용하여 재추출된 표본 강우자료의 최소 최대 값의 편차가 다른 지점의 재추출된 표본강우 자료의 편차에 비해 크다는 것 이며 , 또한 이는 연최대치의 관측자료에서 우도함수로 선정한 상위 90% 의 값과 최대값의 편차가 서울
과 인제지점에 비하해 크기 때문이다 .
4. 확률강우량 산정 결과 비교4.1 빈도해석을 통한 Bootstrap방법과 SIR알고리즘의 결 과 비교
본 연구에서는 Bootstrap 방법과 SIR 알고리즘을 이용한 빈도해석의 결과 비교를 위해 Bootstrap 방법을 이용하여 빈 도해석을 수행 하였을 경우와 SIR 알고리즘을 이용하여 빈도
Table 6. Statistical characteristics of SIR algorithm
Statistics Rainfallof Seoul station (mm)
Rainfall of Ulsan station (mm)
Rainfall of Gwangju station (mm)
Rainfall of Inje station
(mm)
Mean 171.71 200.03 134.96 145.06
Standard
deviation 69.67 55.17 65.35 60.01
Variance 4849.14 3040.42 4265.81 3597.27
Max 318.68 415.82 333.36 274.25
Fig. 8 The uncertainty of rainfall quantile using SIR algorithm
Table 7. The mean values of rainfall quantiles for given return periods using SIR algorithm
Return period (year)
Rainfall of Seoul station
(mm)
Rainfall of Ulsan station
(mm)
Rainfall of Gwangju station (mm)
Rainfall of Inje station
(mm)
80 425.99 394.63 342.84 364.88
100 440.63 405.78 355.04 377.61
150 467.17 426.02 377.17 400.71
200 485.99 440.36 392.85 417.08
500 545.83 485.99 442.74 469.15
해석을 수행 하였을 경우의 확률강우량을 이용하였다 . 다음
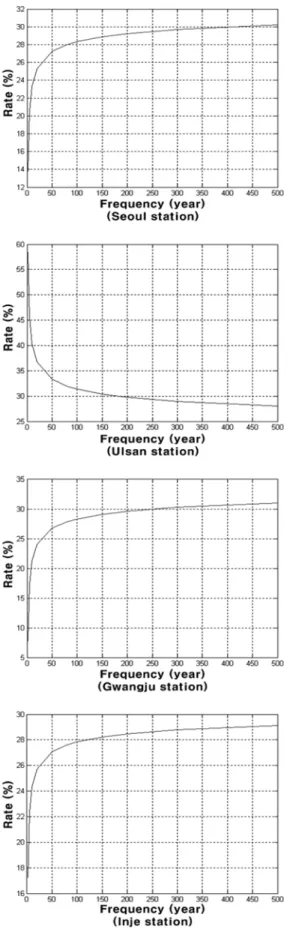
Fig. 9 는 두 결과를 이용하여 증가 감소율을 나타낸 것이며 ,
증가율과 감소율의 기준이 되는 값은 Bootstrap 을 이용하여
산정한 확률강우량으로 하였다 .
두 방법으로 산정된 결과의 비교를 위해 비교의 기준 값
은 Bootstrap 방법을 이용하여 계산되어진 확룰강우량으로 하
였다 . Bootstrap 방법은 원자료의 분포형과 특성을 그대로 반
영하기 때문에 비교 기준이 되기에 적합하다 평가되었다 . Fig. 9 에서 알 수 있듯이 서울 , 광주 , 울산 , 인제 4 지점 모
두 200 년 빈도에서 Bootstrap 방법을 이용하여 확률강우량을
산정 한 경우보다 . SIR 알고리즘을 이용하여 확률 강우량을
산정하였을 때 확률강우량이 증가 한다는 것을 확인 할 수 있으며 , 평균적으로 약 29% 정도 증가하였다 . 그러나 서울 ,
광주 , 인제 지점은 빈도가 커질수록 확률강우량이 점점 증가 하는 경향을 보이고 있으나 울산의 경우는 빈도가 커짐에 따라 확률강우량이 감소하는 경향을 나타내고 있다 . 다음
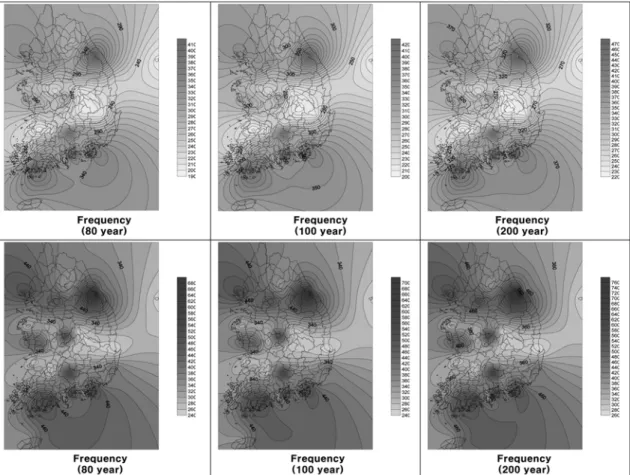
Fig. 10 는 Bootstrap 방법과 SIR 알고리즘을 으로 재추출된 자 료를 이용하여 우리나라의 기상청 산하 56 개 지점에 대한
80 년 , 100 년 , 200 년 빈도의 확률강우량을 나타낸 것이며 위
부분의 그림이 Bootstrap 방법을 통해 얻어진 자료를 사용하
여 산정한 것이고 아래 부분의 그림이 SIR 알고리즘을 통해
얻어진 자료를 사용하여 산정한 것이다 . 또한 Fig. 11 은 80
년 , 100 년 , 200 년 빈도일 때의 증감률을 나타낸 것이다 .
Fig. 10 을 보면 Bootstrap 방법으로 재추출한 표본을 이용
하여 빈도해석을 수행하였을 때보다 SIR 알고리즘을 이용하
여 재추출된 표본으로 빈도해석을 수행하였을 때 빈도별 확 률강우량이 더 크게 산정되었다는 것을 알 수 있다 . 이는
SIR 알고리즘을 이용하여 표본을 재추출 할 때 우도함수를 고려였기에 재추출된 표본에서 극한강우사상이 Bootstrap 방 법에의해 생성된 자료보다 많이 생성되었기 때문이다 . 다음
Fig. 12 는 56 개 지점에 대한 증가 감소지점 (Fig. 4) 과 극치
사상을 고려한 SIR 알고리즘을 통해 재추출된 자료를 이용
하여 빈도해석한 각 지점결과의 증가율 (Fig. 11 에서의 200 년
빈도 증가율 ) 을 비교한 것이다 .
Fig. 12 를 보면 증가율이 높은 지점과 증가경향을 나타내
는 지점이 대부분 일치하는 것을 볼 수 있다 . 이는 극한사 상을 우도로 고려하였을 때 최근의 증가 추세를 어느 정도 반영할 수 있다는 것이라 생각할 수 있다 .
지점마다 차이를 살펴보면 제주 , 서산 , 대전 지점의 경우
빈도별 증가량이 1~7% 정도로 낮은 증가율을 보이는 것을
알 수 있으며 , 특히 포항의 경우는 빈도별 증가율이 -10~
-19% 정도로 오히려 낮아 지는 경향이 나타났다 . 이는 우도
선정에 있어 선정된 값이 작기 때문이다 . 반면 대관령 , 보은 ,
정읍 , 부여 , 양평 , 고흥 , 울진 , 강화 , 장흥 , 보령 , 해남 , 목포 ,
이천지점은 40~65% 정도의 높은 증가율을 나타내는 것을 알
수 있었으며 , 나머지 38 개 지점들의 경우 7~40% 정도의 증
가율을 보이는 것으로 나왔다 .
5. 결 론본 연구에서는 강우량 빈도해석에 필요한 충분한 자료를
확보하기 위하여 Bootstrap 과 SIR 알고리즘을 각각 적용하
여 자료를 재 추출한 후 , 빈도해석 결과를 비교 하였고 극 한강우사상을 이용하여 향후 강우의 경향성에 대해 검토하 였다 . 이를 통해서 얻은 결론을 정리하면 다음과 같다 .
SIR 알고리즘을 이용해서 재추출한 강우량을 가지고 빈도해
석을 하는 경우 , Bootstrap 을 이용해서 재추출한 결과를 이
용해서 빈도해석을 한 경우에 비해서 큰 값을 가지는 것을
Fig. 9 The rate of rainfall quantiles using SIR algorithm and
Bootstrap
Fig. 10 The diagram of rainfall quantiles for given return periods (unit: mm)
Fig. 11 The diagram of rainfall quantile rates of SIR algorithm and Bootstrap (unit: %)
Fig. 12 Collation of Weather station
알 수 있으며 , 이는 극한강우사상을 이용한 우도함수를 고려 했기 때문인 것으로 판단된다 . 하지만 본 연구에서는 연 최 대치 계열 중 90% 에 해당하는 값을 선정했지만 우도함수선 정에 있어 주관적인 성향이 내포되는 문제점 있다 . 따라서 우도함수선정에 있어 명확한 방법론을 제시가 필요하다 생 각된다 .
SIR 알고리즘은 과거의 관측자료로부터 사전밀도함수를 찾 아 우도함수를 고려하여 새로운 사후밀도함수를 찾아내는 표 본 재추출 방법이다 . 따라서 우도함수를 고려할 때 SIR 알고 리즘이 이용되는 상황을 잘 이해하여 선정해야한다고 생각 된다 . 본 연구에서는 수문학적요소인 강우사상을 이용하여 표본 재추출을 하였고 , 우도의 선정에 있어서 수문학적요인 중에서 중요한 요소인 극한강우사상을 고려하였다 . 본 연구 에서 중요한 부분인 우도함수를 극한강우사상으로 고려한 이 유는 기후변화로 인하여 예상치 못한 극한강우사상들이 빈 번하게 발생하고 있기에 이러한 강우사상의 경향성을 파악 하고자 하였다 . 본 연구에서의 결과를 이용하여 기후모델을 이용한 경향성과 비교 한다면 , 동역학적방법과 확률론적인 방법을 모두 고려하여 신뢰도 높은 경향성을 나타 낼 수 있 을 것이라 생각 된다 . 차후 현재까지의 변화하는 양상을 고 려해서 미래의 우도함수를 예측한 후 , 자료를 재추출 하여 빈도해석을 한다면 , 미래의 변화하는 강우사상 고려한 수공 구조물을 설계하는데 참고자료로 활용할 수 있을 것으로 생 각된다 . 또한 많은 기후모형들과의 비교 자료로 사용될 수 있을 것이라 생각된다 .
감사의 글
이 연구는 소방방재청 자연재해저감기술개발사업 [NEMA-
09-NH-02] 연구비 지원으로 수행되었으며 이에 감사드립니다 .
참고문헌
강승호
,박태성
(1996)몬테칼로 베이지안 분석과 응용사례
,한국
통계확회논문집
,한국통계학회
,제
3권
,제
1호
, pp. 169-177.경민수
,김형수
,김병식
(2009)기후변화가 한반도 일 강수량의 빈도에 미치는 영향
,한국수자원학회 2009년도 학술발표회 초록집
,한국수자원학회
, pp. 129-133.권현한
,김병식
,김보경
,윤석영
(2009)기후변화에 따른 극치강수 량의 시공간적 특성 변화 분석
,한국수자원학회 2009년도 학술발표회 초록집
,한국수자원학회
, pp. 1152-1155.권현한
,문영일
(2004)댐 수위 추정 방법의 개선을 통한 수리수
문학적 위험도 분석
,한국수자원학회 2004년도 학술발표회 초록집
,한국수자원학회
, pp. 863-869.김병식
,김보경
,경민수
,김형수
(2008)기후변화가 극한강우와
I- D-F분석에 미치는 영향 평가
,한국수자원학회논문집
,한국수
자원학회
, Vol. 41, No. 4, pp. 379-394.김병식
,김형수
,서병하
(2002) Bootstrap방법에 의한 하천유출량 모의와 왜곡도
,한국수자원학회논문집
,한국수자원학회
, Vol.35, No. 3, pp. 275-284.
문기호
,경민수
,김덕길
,곽재원
,김형수
(2008) SIR알고리즘을
이용한 홍수량 빈도해석에 관한 연구
,한국습지학회지
,한국 습지학회
,제
10권 제
3호
, pp. 125-132.서영민
,지홍기
,이순탁
(2009) Bootstrap을 이용한 강우빈도해석 에서의 매개변수 추정에 대한 불확실성 해석
,한국수자원학회
2009년도 학술발표회 초록집
,한국수자원학회
, pp. 1406-1411.
성기원
(2003)유역의 수문학적 상사성을 이용한
Nash모형의 불 확실성 평가
,한국수자원학회논문집
,한국수자원학회
, Vol. 36, No. 3, pp. 399-411.오제승
,김치영
,김원
(2007)강우 자료의 변동 특성 분석
,한국
수자원학회 2007년도 학술발표회 논문집
,한국수자원학회
, pp. 1602-1607.오태석
,문영일
,권현한
,전시영
(2009)일강우자료를 이용한 서울 지점의 강우 사상 특성 분석
,한국수자원학회 2009년도 학 술발표회 초록집
,한국수자원학회
, pp. 1389-1392.이명우
,이충성
,김형수
,심명필
(2005) Bootstrap방법과
SIR알고 리즘을 이용한 확률강우량 결정과 위험도 분석
,대한토목학회
논문집
,대한토목학회
,제
25권 제
5B호
, pp. 365-373.이상복
,김경덕
,허준행
(2004)강수자료에 대한 변동성 및 경향 성 해석
,한국수자원학회 2004년도 학술발표회
,한국수자원학 회
, pp. 696-700.이창환
,안재현
,김태웅
(2004)강우의 증가경향성을 고려한 확률 강우량 산정법의 적용성 분석
,한국수자원학회 2004년도 학 술발표회
,한국수자원학회
, pp. 696-700.전명식
(1990)통계적 테이타분석방법을 위한 컴퓨터 활용
I:붓스 트랩 이론과 응용
.응용통계연구
,한국통계학회지
,한국통계학 회
,제
3권
,제
1호
, pp. 121-141.전명식
(1996)붓스트랩방법의 실제적활용
-군집표본추출법에 근거 한 분할표분석을 중심으로
,한국통계학회논문집
,한국통계학회
,제
3권
,제
1호
, pp. 179-188.정창삼
,심재현
,허준행
,여운광
(2008)통계적 기법을 이용한 기
후 변화 분석
(강우량 중심
),한국수자원학회 2008년도 학술 발표회 논문집
,한국수자원학회
pp. 1001-1006.황석환
,김중훈
,유철상
,정성원
,유도근
(2009) Bootstrap기법을 이용한 서울지점 강우자료의 정량적 동질성 분석
,한국수자원
학회 2009년도 학술발표회초록집
,한국수자원학회
, pp.1157-1161.
Albert, J.H. (1993) Teaching bayesian statistics using sampling methods and MINITAB, The American statistician Associa- tion, Vol. 47, No. 3, pp. 182-191,
Beersma, J.J. and Buishand, T.A. (2007) Drought in the Nether- lands – Regional frequency analysis versus time series simula- tion, Journal of Hydrology, Vol. 347, Issues 3-4, pp.332-346.
Eform, B. (1979) Bootstrap Method: Another Look at the Jack-nife, The annual of statistics, Institute of Mathmatical Statistics, Vol.
7, No. 1, pp. 1-26.
Ekström, M., Fowler, H.J., Kilsby, C.G., and Jones, P.D. (2005) New estimates of future changes in extreme rainfall across the UK using regional climate model integrations. 2. Future esti- mates and use in impact studies, Journal of Hydrology, Vol.
300, Issues 1-4, pp. 234-251.
Fowler, H.J., Ekström, M., Kilsby, C.G., and Jones, P.D. (2005) New estimates of future changes in extreme rainfall across the UK using regional climate model integrations. 1. Assessment of control climate, Journal of Hydrology, Vol. 300, Issues 1-4, pp. 212-233.
Hamed, K.H. (2008) Trend detection in hydrologic data: The Mann–Kendall trend test under the scaling hypothesis, Journal of Hydrology, Vol. 349, Issues 3-4, pp. 350-363.
Jia, Y. and Culver, T.V. (2006) Bootstrapped artificial neural net- works for synthetic flow generation with a small data sample, Journal of Hydrology, Vol. 331, Issues 3-4, pp. 580-590.
Klein Tank, A.M.G., and Konneb, G.P. (2003) Trends in Indices of Daily Temperature and Precipitation Extremes in Europe, 1946-1999, Journal of Climate, Vol. 16, pp. 3665-3680.
Li, K.-H. (2007) Pool size selection for the sampling/importance resampling algorithm, Statistica Sinica, Vol. 17, No. 3, pp. 895- 907.
Lisi, F. and Vigilio, V. (1997) Statistical considerations on the ran- domness of annual maximum daily rainfall, Journal of the Ameri-
can Water Resources Association, Vol. 33, Issue 2, pp.431-441.
Moradkhani, H., Hsu, K.L., Gupta, Hoshin., and Sorooshian, S.
(2005) Uncertainty assessment of hydrologic model states and parameters: Sequential data assimilation using the particle filte, Water Resources Research, Vol. 41, No. 5, pp. W05012.1- W05012.17.
Osborn, T.J. and Hulme, M. (2002) Evidence for trends in heavy rainfall events over the UK, Philosophical Transactions: Math- ematical, Physical and Engineering Sciences, Flood Risk in a Changing Climate, Vol. 360, No. 1796, pp. 1313-1325.
Overeem, A., Buishand, A., and Holleman, I. (2008) Rainfall depth duration frequency curves and their uncertainties, Journal of Hydrology, Vol. 348, Issues 1-2, pp. 124-134.
Prudhomme, C., Jakob, D., and Svensson, C. (2003) Uncertainty and climate change impact on the ood regime of small UK catchments. Journal of Hydrology, Vol. 277, Issues 1-2, pp. 1- Ramesh, N.I. and Davison, A.C. (2002) Local model for explor-23.
atory analysis of hydrological extremes, Journal of Hydrology, Vol. 256, Issues 1-2, pp. 106-119.
Rubin D.B. (1987) A Noniterative sampling/importance resampling alternative to the data augementation algorithm for creating a few imputation are modest:The SIR algorithm, Journal of the american statistical addiciation, American statistical associa- tion, Vol. 82, pp. 543-546.
Samuels, R., Rimmer, A., and Alpert, P. (2009) Effect of Extreme Rainfall Events on the Water Resources of the Jordan River, Journal of Hydrology, In Press, Accepted Manuscript, Avail- able online.
Sharma, S.K. and Tiwari, K.N. (2009) Bootstrap based artificial neural network (BANN) analysis for hierarchical prediction of monthly runoff in Upper Damodar Valley Catchment, Journal of Hydrology, In Press, Corrected Proof, Available online.
Srinivas, V.V. and Srinivasan, K. (2005) Hybrid moving block boot- strap for stochastic simulation of multi-site multi-season streamows, Journal of Hydrology, Vol. 302, Issues 1-4, pp. 307-330.
Stow, C.A., Reckhow, K.H., Qian, S.S., Lamon, E.C., Arhonditsis, G.B., Borsuk, M.E., and Seo, D.G. (2007) Approaches to eval- uate water quality model parameter uncertainty for adaptive TMDL implementation, Journal of the American Water Resources Association, Vol. 43, No. 6, pp. 1499-1507.
Yue, S. and Hashino, M. (2003) Long term trends of annual and monthly precipitation in japan, Journal of the American Water Resources Association, Vol. 39, Issue 3, pp. 587-596.
Zhao, B., Tung, Y.K., Yeh, K.C., and Yang, J.C. (1997) Storm resa- mpling for uncertainty analysis of a multiple-storm unit hydrograph, Journal of Hydrology, Vol. 194, Issues 1-4, pp.
366-384.
(