2017, 28
(6)
,1337–1348
데이터마이닝 기법을 활용한 한국인의 고위험 음주 예측모형 개발 연구
ᄇ ᅡ
ᆨ일수
1
·한준태2
1위덕대학교 보건관리학과 ·2한국장학재단 장학정책연구소
ᄌ ᅥ
ᆸᄉ ᅮ 2017ᄂ ᅧ ᆫ 9ᄋ ᅯ ᆯ 20ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2017ᄂ ᅧ ᆫ 10ᄋ ᅯ ᆯ 20ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2017ᄂ ᅧ ᆫ 11ᄋ ᅯ ᆯ 2ᄋ ᅵ ᆯ
요 약
ᄇ
ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ ᄌ ᅵ ᆯᄇ ᅧ ᆼᄀ ᅪ ᆫ ᄅ ᅵᄇ ᅩ ᆫ ᄇ ᅮᄋ ᅦᄉ ᅥ ᄉ ᅵ ᆯᄉ ᅵᄒ ᅡ ᆫ ᄌ ᅥ ᆫᄀ ᅮ ᆨ ᄀ ᅲᄆ ᅩᄋ ᅴ ᄌ ᅡᄅ ᅭᄋ ᅵ ᆫ ᄌ ᅵᄋ ᅧ ᆨᄉ ᅡᄒ ᅬᄀ ᅥ ᆫᄀ ᅡ ᆼᄌ ᅩᄉ ᅡ 2014ᄂ ᅧ ᆫ ᄌ ᅡᄅ ᅭᄅ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᄋ
ᅧ ᄀ ᅩᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅳ ᆷ ᄌ ᅮᄌ ᅡᄃ ᅳ ᆯ ᄋ ᅴ ᄐ ᅳ ᆨᄉ ᅥ ᆼ ᄆ ᅵ ᆾ ᄋ ᅭᄋ ᅵ ᆫᄋ ᅳ ᆯ ᄑ ᅡᄋ ᅡ ᆨᄒ ᅡᄀ ᅩ ᄀ ᅩᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅳ ᆷ ᄌ ᅮ ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄀ ᅢᄇ ᅡ ᆯᄒ ᅢ ᆻᄃ ᅡ. ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄒ ᅧ ᆼ ᄀ ᅢᄇ ᅡ ᆯᄋ ᅳ ᆫ ᄃ
ᅦᄋ ᅵᄐ ᅥᄆ ᅡᄋ ᅵᄂ ᅵ ᆼ ᄇ ᅡ ᆼᄇ ᅥ ᆸ ᄌ ᅮ ᆼ ᄅ ᅩᄌ ᅵᄉ ᅳᄐ ᅵ ᆨ ᄒ ᅬᄀ ᅱᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄋ ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄂ ᅡᄆ ᅮ, ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨ 3ᄀ ᅡᄌ ᅵ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼᄒ ᅢ ᆻᄋ ᅳᄆ ᅧ, ᄅ ᅩᄌ ᅵ ᄉ
ᅳᄐ ᅵ ᆨ ᄒ ᅬᄀ ᅱᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅴ ᄌ ᅮᄋ ᅭ ᄀ ᅧ ᆯᄀ ᅪᄅ ᅩᄂ ᅳ ᆫ 40 ᄃ ᅢ ᄂ ᅡ ᆷᄌ ᅡᄋ ᅴ ᄋ ᅱᄒ ᅥ ᆷᄃ ᅩᄀ ᅡ ᄂ ᅩ ᇁ ᄋ ᅡ ᆻᄀ ᅩ, ᄉ ᅡᄆ ᅮᄌ ᅵ ᆨᄀ ᅪ ᄑ ᅡ ᆫᄆ ᅢᄉ ᅥᄇ ᅵᄉ ᅳᄌ ᅵ ᆨᄋ ᅴ ᄋ ᅱᄒ ᅥ ᆷᄃ ᅩᄀ ᅡ ᄂ ᅩ ᇁ ᄋ
ᅡ
ᆻᄃ ᅡ. ᄐ ᅳ ᆨ ᄒ ᅵ ᄒ ᅧ ᆫᄌ ᅢ ᄒ ᅳ ᆸᄋ ᅧ ᆫᄌ ᅡᄋ ᅵ ᆫ ᄀ ᅧ ᆼᄋ ᅮ ᄀ ᅩᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅳ ᆷ ᄌ ᅮ ᄋ ᅱᄒ ᅥ ᆷᄃ ᅩᄀ ᅡ ᄂ ᅩ ᇁ ᄋ ᅡ ᆻᄃ ᅡ. 3ᄀ ᅡᄌ ᅵ ᄇ ᅡ ᆼᄇ ᅥ ᆸ ᄌ ᅮ ᆼ AUROC (area under a receiver operation characteristic curve) ᄎ ᅳ ᆨᄆ ᅧ ᆫᄋ ᅦᄉ ᅥ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄀ ᅪ ᄅ ᅩᄌ ᅵᄉ ᅳᄐ ᅵ ᆨ ᄒ ᅬᄀ ᅱᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅵ ᄀ ᅡᄌ ᅡ ᆼ ᄂ ᅩ ᇁ ᄀ ᅦ ᄂ
ᅡᄐ ᅡᄂ ᅡ ᆻᄃ ᅡ. ᄄ ᅩᄒ ᅡ ᆫ ᄀ ᅩᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅳ ᆷ ᄌ ᅮ ᄋ ᅨᄇ ᅡ ᆼᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅡ ᆫ ᄋ ᅮᄉ ᅥ ᆫ ᄀ ᅪ ᆫ ᄅ ᅵ ᄃ ᅢᄉ ᅡ ᆼᄌ ᅡᄅ ᅳ ᆯ ᄉ ᅥ ᆫᄌ ᅥ ᆼᄒ ᅡ ᆷᄋ ᅦ ᄋ ᅵ ᆻᄋ ᅥ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄀ ᅪ ᄅ ᅩᄌ ᅵᄉ ᅳᄐ ᅵ ᆨ ᄒ
ᅬᄀ ᅱᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄀ ᅢᄇ ᅡ ᆯ ᄃ ᅬ ᆫ ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅴ ᄉ ᅡᄒ ᅮ ᄒ ᅪ ᆨᄅ ᅲ ᆯᄋ ᅳ ᆯ ᄀ ᅵᄎ ᅩᄅ ᅩ ᄃ ᅮ ᄀ ᅡᄌ ᅵ ᄆ ᅩᄒ ᅧ ᆼ ᄆ ᅩᄃ ᅮ ᄋ ᅨᄎ ᅳ ᆨᄇ ᅮ ᆫ ᄑ ᅩᄋ ᅴ ᄉ ᅡ ᆼᄋ ᅱ 10%ᄋ ᅵ ᆫ ᄌ ᅵ ᆸᄃ ᅡ ᆫ ᄋ
ᅦ ᄒ ᅢᄃ ᅡ ᆼᄃ ᅬᄂ ᅳ ᆫ ᄀ ᅧ ᆼᄋ ᅮᄅ ᅳ ᆯ ᄉ ᅥ ᆫᄌ ᅥ ᆼᄒ ᅡ ᆫ ᄀ ᅧ ᆯᄀ ᅪ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅵᄂ ᅡ ᄅ ᅩᄌ ᅵᄉ ᅳᄐ ᅵ ᆨ ᄒ ᅬᄀ ᅱᄆ ᅩᄒ ᅧ ᆼ 1ᄀ ᅡᄌ ᅵ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳᄅ ᅩ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅥ ᆺᄇ ᅩ ᄃ
ᅡ ᄇ ᅡ ᆫᄋ ᅳ ᆼᄅ ᅲ ᆯ ᄆ ᅵ ᆾ ᄒ ᅣ ᆼᄉ ᅡ ᆼᄃ ᅩᄀ ᅡ ᄃ ᅡᄉ ᅩ ᄀ ᅢᄉ ᅥ ᆫᄃ ᅬᄂ ᅳ ᆫ ᄀ ᅥ ᆺᄋ ᅳᄅ ᅩ ᄂ ᅡᄐ ᅡᄂ ᅡ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥ ᄀ ᅢᄇ ᅡ ᆯ ᄃ ᅬ ᆫ ᄀ ᅩᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅳ ᆷ ᄌ ᅮ ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄒ ᅧ ᆼᄀ ᅪ ᄋ
ᅮᄉ ᅥ ᆫ ᄀ ᅪ ᆫ ᄅ ᅵ ᄃ ᅢᄉ ᅡ ᆼᄌ ᅡ ᄉ ᅥ ᆫᄌ ᅥ ᆼ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆫ ᄆ ᅮ ᆫ ᄌ ᅦᄌ ᅥ ᆨ ᄋ ᅳ ᆷ ᄌ ᅮ ᄋ ᅨᄇ ᅡ ᆼ ᄆ ᅵ ᆾ ᄀ ᅢᄉ ᅥ ᆫ ᄀ ᅭᄋ ᅲ ᆨ, ᄌ ᅥ ᆯᄌ ᅮ ᄑ ᅳᄅ ᅩᄀ ᅳᄅ ᅢ ᆷ ᄀ ᅢᄇ ᅡ ᆯ ᄃ ᅳ ᆼ ᄋ ᅦ ᄇ ᅩᄃ ᅡ ᄉ ᅦᄇ ᅮ ᆫ ᄒ ᅪ ᄃ
ᅬᄀ ᅩ ᄒ ᅭᄀ ᅪᄌ ᅥ ᆨᄋ ᅵ ᆫ ᄀ ᅥ ᆫᄀ ᅡ ᆼ ᄀ ᅪ ᆫ ᄅ ᅵ ᄉ ᅥᄇ ᅵᄉ ᅳᄅ ᅳ ᆯ ᄌ ᅦᄀ ᅩ ᆼᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅡ ᆫ ᄀ ᅵᄎ ᅩᄌ ᅡᄅ ᅭᄀ ᅡ ᄃ ᅬ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅳ ᆯ ᄀ ᅥ ᆺᄋ ᅵᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄀ ᅩᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅳ ᆷ ᄌ ᅮ, ᄅ ᅩᄌ ᅵᄉ ᅳᄐ ᅵ ᆨ ᄒ ᅬᄀ ᅱᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄋ ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄂ ᅡᄆ ᅮ.
1. 서론 ᄋ
ᅳ
ᆷ주의 폐해의 중독성은 음주 유형에 따라큰차이를보인다. 즉,소량 혹은적절한 음주는허혈성 심 지
ᆯ환발생 위험 및 사망률을낮춰 주는것으로 알려져 있으며 (Chick, 1998; Maskarinec 등, 1998),스 ᄐ
ᅳ레스 및 긴장을완화시키고 사회적관계를형성하는데 도움을 준다 (Kim, 2012). 그러나 지나친 음주 ᄂ
ᅳᆫ간질환및 심뇌혈관질환과 같은 신체적인 건강문제, 우울과 같은부정적인 정서장애, 신체적 정신적 ᄋ
ᅴ존,상해 및 사망에 이를수 있으며 (Chavez 등, 2012; Lee와 Roh, 2011), 사회문제를유발하는 등사 ᄒ
ᅬ적 질서에 심각한 혼란을 초래하기도 한다. 또한 가정해체, 실업 및 직장 문제, 범죄, 재정문제 등을 ᄋ
ᅣ기하며, 막대한 사회적 비용손실을초래한다 (Casswell and Thamarangsi, 2009).
ᄉ
ᅥᆫ행연구에서 나타나듯, 모든 음주가 문제를발생시키는것은아니며, 일정 수준이상의 음주 시 많은 무
ᆫ제가 발생하게된다.
2016년 식품의약품안전처가 주류 소비·섭취를 만 15세 이상 남녀 2,000명을 대상으로 조사한 결과, ᄋ
ᅮ리국민의 1회 평균 음주량은맥주로 4.9잔을섭취하고 고위험 음주 (최근 6개월 동안 음주 경험자 중
1
(38004) ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄀ ᅧ ᆼᄌ ᅮᄉ ᅵ ᄀ ᅡ ᆼᄃ ᅩ ᆼᄆ ᅧ ᆫ ᄃ ᅩ ᆼ ᄒ ᅢᄃ ᅢᄅ ᅩ 261, ᄋ ᅱᄃ ᅥ ᆨᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄇ ᅩᄀ ᅥ ᆫᄀ ᅪ ᆫ ᄅ ᅵᄒ ᅡ ᆨᄀ ᅪ, ᄌ ᅩᄀ ᅭᄉ ᅮ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (41200) ᄃ ᅢᄀ ᅮ ᄀ ᅪ ᆼᄋ ᅧ ᆨᄉ ᅵ ᄃ ᅩ ᆼ ᄀ ᅮ ᄉ ᅵ ᆫᄋ ᅡ ᆷᄅ ᅩ 125, ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄌ ᅡ ᆼᄒ ᅡ ᆨᄌ ᅢᄃ ᅡ ᆫ ᄌ ᅡ ᆼᄒ ᅡ ᆨᄌ ᅥ ᆼᄎ ᅢ ᆨᄋ ᅧ ᆫᄀ ᅮᄉ ᅩ, ᄐ ᅵ ᆷᄌ ᅡ ᆼ.
E-mail: [email protected]
ᄒ
ᅡ루에 17도 소주 기준으로 남자는 8.8잔 이상, 여자는 5.9잔 이상 섭취)가 58.3%로 나타난 것으로 보 ᄀ
ᅩ되었다. 특히 20대의 고위험 음주와 폭탄주 경험이 각각 65.2%, 50.1%로 다른연령대보다 여전히 높 ᄋ
ᅡ 지속적인 인식개선이 시급한 것으로 나타났다.
ᄋ
ᅵ에 본연구에서는 문제적 음주인 고위험 음주 발생 원인을규명하고, 고위험 음주자들의 특성을파 ᄋ
ᅡ
ᆨ하고자 한다. 그러나 이와 유사한 주제, 즉 특정 건강위험 행위를하는자들의 특성을규명하기 위한 ᄉ
ᅥᆫ행연구는다양하게 존재한다.
Chung과 Joung (2012)의 연구에서는 2009년도 지역사회건강조사 자료를이용해 국내 성인 음주 유 혀
ᆼ을파악하고 개인의 인구사회학적 요인과 건강관련 요인을활용하여 음주 문제 및 알코올의존요인을 ᄑ
ᅡ악하고자 하였다. Kweon (2005)은 직접 설계한 설문지로 수집된자료를활용하여 사무직 직장인들 ᄋ
ᅳᆯ 중심으로 직무 스트레스와 직장 내 음주하위문화가 음주문제에 미치는영향을 통계적 모형으로 파악 ᄒ
ᅡ였다. Lee와 Roh (2011)는 2009년 국민건강영양조사의 자료를활용하여 음주특성이 우울여부 및 자 ᄉ
ᅡ
ᆯ생각 여부에 미치는영향을 분석하였으며, Kim 등 (2010)은 국민건강보험공단의 건강검진 수검자의 ᄌ
ᅡ료를활용하여, 음주량과 암 사망률과의관계를파악하기도 하였다. Lee와 Park (2016)는남자 대학 새
ᆼ을대상으로 음주 동기, 음주거절 효능감과 술의 효과에 대한 기대 또는 신념이 고위험 음주에 미치는 여
ᆼ향 요인을 분석하여 학년, 학과, 흡연상태, 고양 동기, 사회적 압력 상황에서의 음주거절 효능감이 고 ᄋ
ᅱ험 음주에 영향을주는것으로 파악하였다. Ryu 등 (2013)은다중로지스틱 회귀분석으로 음주 패턴 ᄋ
ᅳᆯ 분석하였는데 연령, 소득수준, 고용상태, 흡연, 비만, 건강의 주관적 평가 등이관련 요인으로 밝혀졌 ᄃ
ᅡ. 최근 Byeon (2015)은 2010년 서울시 복지패널에 참여한 20세 이상 성인 3,304명의 데이터와 데이 ᄐ
ᅥ마이닝 분석 중하나인 CART (classification and regression tree) 알고리즘을이용하여 고위험 음주 ᄋ
ᅨ측모형을구축하고, 유의미한 변수로 성별, 연령, 최종학력, 흡연 여부, 배우자 유무임을확인하였다.
ᄄ
ᅩ한 Lee (2014)는고위험 음주율에 영향을미치는지역의 사회환경 요인을파악하기 위해 시군구 단위 ᄅ
ᅩ 구성된지역사회 건강조사 자료를활용하여 지리적 가중회귀모형을적용하였다.
ᄋ
ᅵ와 같은선행연구들의 특징을살펴보면, 첫 번째, 분석에활용된자료의 규모이다. 분석자료로활용 되
ᆫ자료로는개인이 직접 설계하여 조사한 소규모 표본조사 자료에서부터 질병관리본부 등 국가단위에 ᄉ
ᅥ 수집된대규모 표본조사 자료 그리고 국민건강보험공단의 건강검진 자료 및 진료내역 자료 등으로 다 ᄋ
ᅣᆼ하였다. 두 번째는 음주와 가장 밀접한관계가 있거나, 문제적 음주에 가장 노출이 쉬운 집단 그리고 ᄋ
ᅳ
ᆷ주 문화 개선이 가장 필요한 집단 등관심을가지는연구집단이 다양하였다. 큰범위로는한국성인에 ᄉ
ᅥ부터 작게는대학생 또는 사무직근로자 등이었다. 마지막으로 음주발생 요인을 찾아내기 위한 방법 ᄋ
ᅳ로 대부분로지스틱 회귀분석을선호하였다. 그러나 다양한 방법을비교하거나 모형을평가하는 등의 ᄎ
ᅬ적화된모형을찾아내기 위한 부분은매우 소극적이었다.
ᄌ ᅩ
ᆼ합하면, 사회적 문제가 되는고위험 음주 발생의 원인을 찾아내어 그 결과를 일반화하기 위해서는 ᄋ
ᅮ리나라 전국민을대상으로 조사된대규모 자료를활용하는것이 효과적일 것이며 다양한 모형을적용 ᄒ
ᅡ고 비교하여 최적화된모형을결과로 원인을찾거나 음주관리 대상자 선정을효율화 할 필요가 있다.
ᄋ
ᅵ에 본연구에서는 질병관리본부에서 실시한 전국규모의 자료인 지역사회건강조사 자료를이용하고 ᄌ
ᅡ 하며, 경제적환경, 건강수준, 건강행위 등다양한 요인을고려한 고위험 음주 예측모형을개발하고 ᄀ
ᅢ발된예측모형을활용하여 고위험 음주 예방을위한 우선 관리 대상자를선정하고자 한다. 2장에서 느
ᆫ예측모형 개발을위한 자료의 설명과 분석 방법에 대해 소개하였다. 3절에서는 개발된고위험 음주 ᄋ
ᅨ측모형의 결과 및 평가를다루고 우선관리 대상자의 특성을파악하였다. 4절에서는결론 및 향후 연 ᄀ
ᅮ방향을제시하였다.
2. 연구 방법
2.1. 자료 수집 및 연구대상자 선정 ᄇ
ᅩᆫ연구에서활용된지역사회건강조사는 2008년부터 매년 전국시·군·구 단위로 전국 보건소에서 동 ᄉ
ᅵ에 실시하는대규모 표본조사로 표본가구에 대해 지역주민 건강행태, 만성질환이환및 의료이용 등을 ᄌ
ᅩ사하는체계적이고 신뢰성 있는 지역기반의 대표적인 전국조사 체계이다. 본연구에서는 2008년 이 ᄒ
ᅮ 지역사회건강조사 자료를활용함에 있어 건강행태관련 변수 중 매년 조사되지 않았던 항목이 일부 이
ᆻ기에 시계열 자료를 통한 분석보다는횡단면 자료로 가능한 많은변수를활용하고자 하였다.
ᄋ
ᅵ에 고위험 음주 특성 파악을위한 예측모형 개발에 사용된자료는지역사회건강조사 2014년 기준으 ᄅ
ᅩ 인구사회학적 특성, 가구소득, 건강행태 (현재 흡연 여부, 스트레스 인지 여부, 우울감 경험 여부, 주 과
ᆫ적 건강수준 인지 여부, 주관적 비만 인지 여부, 중등도 이상 신체활동 실천 여부 등)의 정보를이용하 ᄋ
ᅧᆻ다.
ᄋ
ᅧᆫ구대상자는 본연구에서활용한 변수 중에서 모름또는 응답거부인 경우는제외하고 총 149,592명 ᄋ
ᅳ로 분석하였다.
2.2. 변수 정의 ᄀ
ᅩ위험 음주에 영향을 주는요인은 관련 연구자료 및관련 자문가 자문 등을 통하여, 인구 사회학적 ᄐ
ᅳᆨ성 (성별, 연령, 결혼유무), 사회경제적 환경 (가구소득, 학력, 직업), 건강상태 (건강검진 여부, 우 우
ᆯ감 경험 여부, 건강수준,스트레스 여부, 비만 여부), 생활양식 (중등도 이상 신체활동여부, 아침식사 ᄋ
ᅧ부, 현재 흡연 여부)을설명변수로 포함하였으며, 직업의 경우 기타항목에는 학생, 주부, 군인, 무직 ᄃ
ᅳ
ᆼ이 포함되었다. 종속변수 (목표변수)는지역사회건강조사에서 정의하고 있는고위험 음주 기준을 적 ᄋ
ᅭ
ᆼ하여 2014년 조사 당시 최근 1년 동안 한 번의 술자리에서 남자 7잔/여자 5잔 이상을주 2회 이상 마 ᄉ
ᅵᆫ다고 응답한 사람을고위험 음주 (high-risk)로 정의 하고 그렇지 않은경우를정상 (normal)으로 정 ᄋ
ᅴ하였다. Table 2.1은 본연구에활용된 변수들의 설명이다.
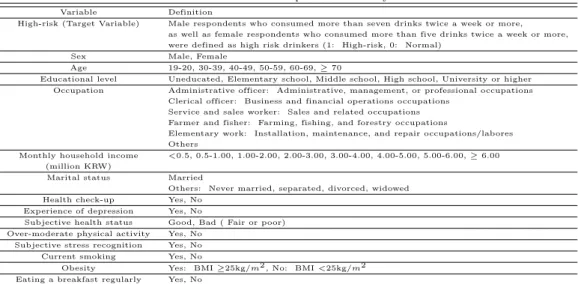
Table 2.1 Data description in the analysis
Variable Definition
High-risk (Target Variable) Male respondents who consumed more than seven drinks twice a week or more, as well as female respondents who consumed more than five drinks twice a week or more, were defined as high risk drinkers (1: High-risk, 0: Normal)
Sex Male, Female
Age 19-20, 30-39, 40-49, 50-59, 60-69, ≥ 70
Educational level Uneducated, Elementary school, Middle school, High school, University or higher Occupation Administrative officer: Administrative, management, or professional occupations
Clerical officer: Business and financial operations occupations Service and sales worker: Sales and related occupations Farmer and fisher: Farming, fishing, and forestry occupations
Elementary work: Installation, maintenance, and repair occupations/labores Others
Monthly household income <0.5, 0.5-1.00, 1.00-2.00, 2.00-3.00, 3.00-4.00, 4.00-5.00, 5.00-6.00, ≥ 6.00 (million KRW)
Marital status Married
Others: Never married, separated, divorced, widowed
Health check-up Yes, No
Experience of depression Yes, No
Subjective health status Good, Bad ( Fair or poor) Over-moderate physical activity Yes, No
Subjective stress recognition Yes, No
Current smoking Yes, No
Obesity Yes: BMI ≥25kg/m2 , No: BMI <25kg/m2
Eating a breakfast regularly Yes, No
2.3. 분석 방법 ᄋ
ᅳ
ᆷ주 고위험 (high-risk)과 정상 (normal)과의 일반적 현황은교차분석을 실시하였으며, 본연구에서 ᄀ
ᅢ발하고자 하는고위험 음주 예측모형은지역사회건강조사에서 고위험 음주로 정의된사람을예측하는 ᄆ
ᅩ형이며, 모형을구축하기 위하여 로지스틱 회귀분석, 의사결정나무, 신경망 분석을적용하였다.
ᄅ
ᅩ지스틱 회귀분석의 경우 목표변수가 이항형일 때 사용되는 가장 보편화된방법이며, 의사결정나무 ᄋ
ᅴ 분류나무는 의사결정규칙을 나무 구조의 형태로 도표화하여 목표변수의 범주를 분류하는기법으로 ᄂ
ᅡ무 구조로 표현이 되기 때문에 분류 결과의 해석이 용이하며 주요한 예측변수에관한 정보를얻을수 이
ᆻ는장점이 있다. 신경망 분석 기법은매우 유연한 비선형 모형으로 입력변수들을결합하여 각 은닉마 ᄃ
ᅵ (hidden units)에 전달하고 은닉마디들의 결합을 출력마디에 전달함으로서 목표변수의 범주를예측 ᄒ
ᅡ는것으로 가장 널리 사용되는모형은 MLP (multilayer perceptron) 신경망으로 입력층, 은닉마디로 ᄀ
ᅮ성된 은닉층,그리고 출력층으로 구성된다 (Kang 등, 2014).
ᄇ
ᅩᆫ 연구에서 사용한 의사결정나무 분석의 경우 interactive method을 이용하여 모형을 개발하였으 ᄆ
ᅧ, 분석의 분리기준 (split criterion)에서 nominal 타겟 기준은 Pearson의 통계량, ordinal 타겟 기 주
ᆫ은 엔트로피 (entropy) 지수로 설정하였으며, 신경망 분석의 경우에서는 은닉마디 수를 2∼5개를 비 ᄀ
ᅭ한 결과 오분류율 및 RASE (root average squared error) 측면에서 5개 (RASE: 0.3622, 오분류 ᄋ
ᅲᆯ: 0.18572)로 할 경우가 가장 좋았으나, 은닉층과 은닉마디가 많으면 많을수록 신경망은 복잡해지며 ᄀ
ᅨ수의 수가 급격히 증가하기 때문에 최적화가 어려울 수 있는점을 고려하여 은닉마디가 3개인 경우 (RASE: 0.3622,오분류율: 0.18584)와 거의 차이가 없어 마디 수를최소화한 3개로 설정하고 은닉층의 화
ᆯ성함수는디폴트인 쌍곡탄젠트 함수, 타겟층의활성함수는로지스틱 함수로 설정하였다.
ᄄ
ᅩ한 개발된예측모형의 성능에 대한 평가는 ROC (receiver operation characteristic) 곡선의 아래 ᄆ
ᅧᆫ적을나타내는 AUROC (area under a ROC curve), 오분류율, KS (Kolmogorov-Smirnov) 통계량 으
ᆯ이용였으며, 분석 패키지는 SAS 9.4 및 SAS Enterprise Miner 13.2를사용하였다.
3. 연구 결과
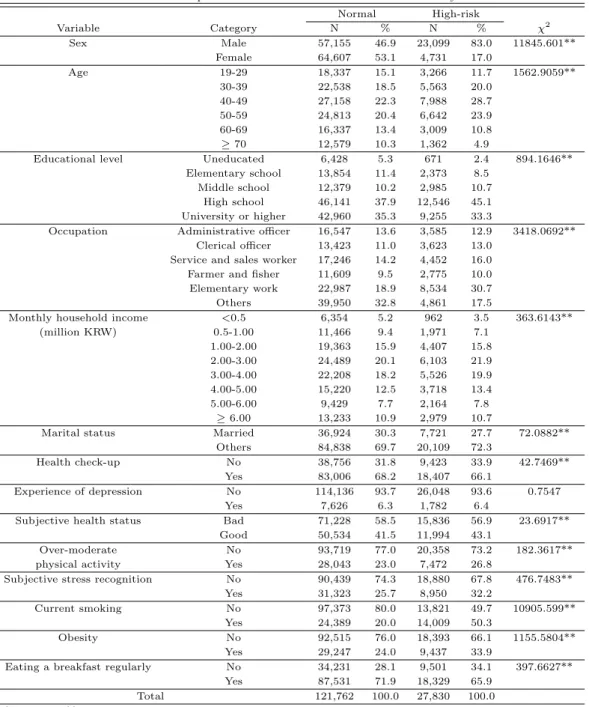
3.1. 주요 요인의 일반적 현황 ᄀ
ᅩ위험 음주 여부에 따른 연구 대상자의 일반적 현황은 Table 3.1에 제시하였다. 연구 대상자 전체 149,592명 중에서 음주 고위험 (high-risk)은 27,830명으로 18.6%였으며, 정상 (normal)은 121,762명 ᄋ
ᅳ로 81.4%였다.
ᄋ
ᅮ울감 경험 유무를제외한 대부분의 설명변수에서 통계적으로 유의한 차이를보였다. 고위험에서는 ᄂ
ᅡ
ᆷ자 (83.0%)의 비율이 높았으나 정상에서는여성 (53.1%)의 비율이 높았다. 연령에서는고위험이 40- 49세 (28.7%), 50-59세 (23.9%)가 높게 나타났다. 또한 기능단순노무직의 고위험 비율이 30.7%로 상 ᄃ
ᅢ적으로 높게 나타난 반면 정상에서는기타 (군인, 학생, 주부, 무직)의 비율이 32.8%로 가장 높았다.
주
ᆼ등도 이상의 신체활동여부, 스트레스 여부, 배우자 유무, 건강검진 여부, 흡연 여부, 비만 여부, 아침 시
ᆨ사 여부의 변수에서 두 집단간 통계적인 차이를보였다. 특히, 현재 흡연 여부의 경우 현재 흡연자가 ᄀ
ᅩ위험에서의 비율이 50.3%인 반면, 정상에서는 20.0%로 나타나큰차이를보였다 (Table 3.1 참조).
3.2. 고위험 음주 예측모형 개발 및 평가 ᄇ
ᅮᆫ석데이터는크게 분석용 (train data)과 평가용 (validation data)으로 구분하였고, 분석용과 평가 ᄋ
ᅭ
ᆼ데이터는 6:4의 비율로 분할하여 생성하였다. 본연구에서는데이터마이닝에서의 주요 기법에 해당 ᄒ
ᅡ는로지스틱 회귀분석, 의사결정나무, 신경망 분석 기법을적용하였다.
Table 3.1 Descriptive characteristics for the variables in the analysis
Normal High-risk
Variable Category N % N % χ
2Sex Male 57,155 46.9 23,099 83.0 11845.601**
Female 64,607 53.1 4,731 17.0
Age 19-29 18,337 15.1 3,266 11.7 1562.9059**
30-39 22,538 18.5 5,563 20.0
40-49 27,158 22.3 7,988 28.7
50-59 24,813 20.4 6,642 23.9
60-69 16,337 13.4 3,009 10.8
≥ 70 12,579 10.3 1,362 4.9
Educational level Uneducated 6,428 5.3 671 2.4 894.1646**
Elementary school 13,854 11.4 2,373 8.5 Middle school 12,379 10.2 2,985 10.7
High school 46,141 37.9 12,546 45.1 University or higher 42,960 35.3 9,255 33.3
Occupation Administrative officer 16,547 13.6 3,585 12.9 3418.0692**
Clerical officer 13,423 11.0 3,623 13.0 Service and sales worker 17,246 14.2 4,452 16.0 Farmer and fisher 11,609 9.5 2,775 10.0 Elementary work 22,987 18.9 8,534 30.7
Others 39,950 32.8 4,861 17.5
Monthly household income <0.5 6,354 5.2 962 3.5 363.6143**
(million KRW) 0.5-1.00 11,466 9.4 1,971 7.1
1.00-2.00 19,363 15.9 4,407 15.8
2.00-3.00 24,489 20.1 6,103 21.9
3.00-4.00 22,208 18.2 5,526 19.9
4.00-5.00 15,220 12.5 3,718 13.4
5.00-6.00 9,429 7.7 2,164 7.8
≥ 6.00 13,233 10.9 2,979 10.7
Marital status Married 36,924 30.3 7,721 27.7 72.0882**
Others 84,838 69.7 20,109 72.3
Health check-up No 38,756 31.8 9,423 33.9 42.7469**
Yes 83,006 68.2 18,407 66.1
Experience of depression No 114,136 93.7 26,048 93.6 0.7547
Yes 7,626 6.3 1,782 6.4
Subjective health status Bad 71,228 58.5 15,836 56.9 23.6917**
Good 50,534 41.5 11,994 43.1
Over-moderate No 93,719 77.0 20,358 73.2 182.3617**
physical activity Yes 28,043 23.0 7,472 26.8
Subjective stress recognition No 90,439 74.3 18,880 67.8 476.7483**
Yes 31,323 25.7 8,950 32.2
Current smoking No 97,373 80.0 13,821 49.7 10905.599**
Yes 24,389 20.0 14,009 50.3
Obesity No 92,515 76.0 18,393 66.1 1155.5804**
Yes 29,247 24.0 9,437 33.9
Eating a breakfast regularly No 34,231 28.1 9,501 34.1 397.6627**
Yes 87,531 71.9 18,329 65.9
Total 121,762 100.0 27,830 100.0
*: p<0.05, **: p<0.01
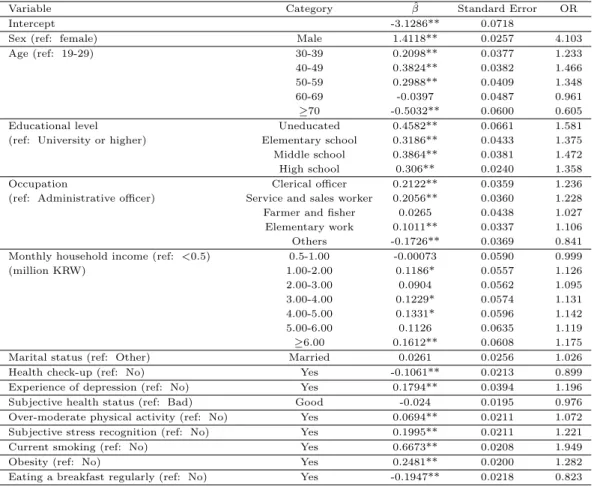
ᄅ
ᅩ지스틱 회귀분석의 경우 본 연구에서 정의된 종속변수와 독립변수를 반영한 결과 Table 3.2와 같 ᄋ
ᅵ 각 변수의 회귀계수 및 오즈비 (Odds Ratio)를산출하였다. 남자가 여자보다 고위험 음주의 오즈비 ᄀ
ᅡ 약 4.1이었으며, 19-29보다 연령대가 높을수록 고위험 음주의 오즈비가 높아지지만, 60세 이후부터
Table 3.2 Result of logistic regression analysis
Variable Category β ˆ Standard Error OR
Intercept -3.1286** 0.0718
Sex (ref: female) Male 1.4118** 0.0257 4.103
Age (ref: 19-29) 30-39 0.2098** 0.0377 1.233
40-49 0.3824** 0.0382 1.466
50-59 0.2988** 0.0409 1.348
60-69 -0.0397 0.0487 0.961
≥70 -0.5032** 0.0600 0.605
Educational level Uneducated 0.4582** 0.0661 1.581
(ref: University or higher) Elementary school 0.3186** 0.0433 1.375
Middle school 0.3864** 0.0381 1.472
High school 0.306** 0.0240 1.358
Occupation Clerical officer 0.2122** 0.0359 1.236
(ref: Administrative officer) Service and sales worker 0.2056** 0.0360 1.228
Farmer and fisher 0.0265 0.0438 1.027
Elementary work 0.1011** 0.0337 1.106
Others -0.1726** 0.0369 0.841
Monthly household income (ref: <0.5) 0.5-1.00 -0.00073 0.0590 0.999
(million KRW) 1.00-2.00 0.1186* 0.0557 1.126
2.00-3.00 0.0904 0.0562 1.095
3.00-4.00 0.1229* 0.0574 1.131
4.00-5.00 0.1331* 0.0596 1.142
5.00-6.00 0.1126 0.0635 1.119
≥6.00 0.1612** 0.0608 1.175
Marital status (ref: Other) Married 0.0261 0.0256 1.026
Health check-up (ref: No) Yes -0.1061** 0.0213 0.899
Experience of depression (ref: No) Yes 0.1794** 0.0394 1.196
Subjective health status (ref: Bad) Good -0.024 0.0195 0.976
Over-moderate physical activity (ref: No) Yes 0.0694** 0.0211 1.072
Subjective stress recognition (ref: No) Yes 0.1995** 0.0211 1.221
Current smoking (ref: No) Yes 0.6673** 0.0208 1.949
Obesity (ref: No) Yes 0.2481** 0.0200 1.282
Eating a breakfast regularly (ref: No) Yes -0.1947** 0.0218 0.823
*: p<0.05, **: p<0.01, ref: reference, OR: Odds Ratio
ᄂ
ᅳᆫ감소하는경향을보인다. 최종학력 수준에서는대학교 이상보다 학력이 낮은경우가 고위험 음주의 ᄋ
ᅩ즈비가 높았으며, 직업에서는사무직에서의 고위험 음주 오즈비가 약 1.24, 판매서비스직 약 1.23, 기 ᄂ
ᅳ
ᆼ단순노무직이 약 1.1로 나타났다. 월평균가구소득이 600만 원이상에서의 오즈비가 약 1.18, 우울감 ᄋ
ᅵ 있거나 스트레스가 있는경우 고위험 음주의 오즈비가 각각 1.20, 1.22였으며, 비만인 경우에도 오즈 ᄇ
ᅵ가 1.28로 높게 나타났다. 반면, 건강검진을받은경우와 아침식사 (주5일 이상)를할 경우 고위험 음 ᄌ
ᅮ 오즈비가 낮아짐을알 수 있다. 특히 현재 흡연자인 경우 고위험 음주 오즈비가 약 1.95로 높았다.
Figure 3.1은의사결정나무 방법으로 고위험 음주 예측모형을도식화한 것으로 유형별 규칙을파악할 ᄉ
ᅮ 있다. 로지스틱 분석과 마찬가지로 인구 사회학적 특성 (성별, 연령, 결혼 유무), 사회경제적 환경 (가구소득,학력, 직업), 건강상태 (건강검진 여부, 우울감 경험 여부, 건강수준,스트레스 여부, 비만 여 ᄇ
ᅮ), 생활양식 (중등도 이상 신체활동여부, 아침식사 여부, 현재 흡연 여부)을설명변수로 고려한 결과 13개 그룹으로 분류되었다.
Figure 3.1에서 살펴보면 성별이 의사결정 나무에서 가장 먼저 분리되며, 현재 흡연 여부, 연령, 주관 ᄌ
ᅥ
ᆨ 건강상태, 비만, 직업 등의 순으로 분리되었으며, 총 13개의 그룹 중에서 남자이면서, 현재 흡연 중이
H-R: 18.6%
(High-risk) N: 89,755
H-R: 28.8%
N: 48,123
Sex
H-R: 6.9%
N: 41,632
H-R: 36.9%
N: 21,479
Current smoking
H-R: 22.2%
N: 26,644
H-R: 40.4%
N: 15,382 H-R: 28.1%
N: 6,097 Age
H-R: 38.5%
N: 6,620 H-R: 41.8%
N: 8,762 Subjective health
status
Male Female
H-R: 25.7%
N: 19,015 H-R: 13.4%
N: 7,629
30~59 19~29, ≥60 30~69 19~29, ≥70
Age
H-R: 31.6%
N: 6,947 H-R: 22.3%
N: 12,068
Occupation*
H-R: 30.2%
N: 1,535
H-R: 34.3%
N: 1,281 H-R: 9.8%
N: 254
19~59 ≥60
Age
H-R: 6.00%
N: 40,097 Current smoking
Yes No Yes No
H-R: 7.7%
N: 23,980 H-R: 3.5%
N: 16,117
19~49 ≥50
Age
H-R: 9.7%
N: 10,100 H-R: 6.2%
N: 13,880 H-R: 8.3%
N: 1,976 H-R: 2.8%
N: 14,141
H-R: 8.7%
N: 6,924 H-R: 12.0%
N: 3,176 Subjective stress recognition
Good Bad
Obesity
Yes No 2, 3, 5 1, 4, 6
Eating a breakfast regularly
Yes No
* Occupation: 1. Administrative officer, 2. Clerical officer 3. Service and sales worker, 4. Farmer and fisher 5. Elementary work, 6. Others
No Yes Group 1
Group 2 Group 4 Group 6
Group 3
Group 5 Group 7 Group 9
Group 8 Group 10
Group 12 Group 11 Group 13
Figure 3.1 Result of decision tree
ᄀ
ᅩ, 연령이 30-59세이고 주관적 건강상태가 나쁘다고 판단한 경우가 약 41.8%의 고위험 음주 예측률을 ᄇ
ᅩ여 가장 높게 나타났다.
Table 3.3 Misclassification rate, AUROC and KS statistics for the predictive models
Logistic regression Decision tree Neural network
Misclassification Rate Train data (60%) 0.187 0.186 0.186
Validation data (40%) 0.187 0.186 0.186
AUROC Train data (60%) 0.753 0.752 0.765
Validation data (40%) 0.754 0.750 0.763
Kolmogorov-Smirnov Train data (60%) 0.391 0.403 0.413
statistics Validation data (40%) 0.395 0.405 0.412
서
ᆼ별이 여자인 경우에서도 현재 흡연자이고 연령이 19-59세인 경우에 고위험 음주 예측률 34.3%로 노
ᇁ게 나타남을알 수 있다. 앞서 로지스틱 회귀모형에서도확인된 것처럼 의사결정나무 모형에서도 흡 ᄋ
ᅧᆫ은고위험 음주에 주요한 요인으로확인 되었으며, 총 13개의 그룹 중에서 3번 그룹을제외한 예측률 ᄋ
ᅵ 높은 1∼7번 그룹이 남성임을알 수 있었다 (Figure 3.1 참조).
ᄄ
ᅩ한 개발된예측모형의 성능에 대한 평가는 AUROC, 오분류율, KS 통계량을이용하였는데, Table 3.1과 Figure 3.2에서와 같이 오분류율은 약 0.186-0.187이었으며, Roc 곡선의 아래 면적을나타내는 AUROC는약 0.753-0.765, KS 통계량은 약 0.391-0.413의 값을나타내 모형의 설명력과 타당성을 확 ᄇ
ᅩ하였다. 3가지 방법의 성능에 대한 차이는 크지 않았으나, AUROC 및 KS 통계량 측면에서는 신경 ᄆ
ᅡᆼ 분석이 다소 좋았으며, AUROC 측면에서는로지스틱 회귀분석이 다소 좋게 나타났다 (Table 3.3과 Figure 3.2참조).
Figure 3.2 Roc curve for the predictive models
3.3. 고위험 음주 예방을 위한 우선 관리 대상자 선정 보
ᆫ연구에서의 고위험 음주 예방을위한 우선관리 대상자 선정은앞서 적용한 3가지 분석 방법 (로지 ᄉ
ᅳ틱 회귀분석, 의사결정나무, 신경망 분석) 중에 AUROC 측면에서 가장 높은 2가지 방법, 그 결과 신 겨
ᆼ망과 로지스틱 회귀모형으로 개발된예측모형의 사후확률을기초로 두 가지 모형 모두 예측분포의 상 ᄋ
ᅱ 10%인 집단에 해당되는경우로 선정하였다. 즉 신경망과 로지스틱 회귀모형으로 개발된예측모형의 ᄉ
ᅡ후확률을기초로 두 가지 모형 모두 예측분포의 상위 10%인 집단에 해당되는반응률 (%response)은 44.4%로 나타나 신경망 모형 또는로지스틱 회귀모형의 반응률보다 높게 나타났다. 또한 전체 자료에 ᄉ
ᅥ의 반응율 즉, 기준선 반응률 (base line %response, 18.6%)에 비해 각 등급에서의 반응률이 얼마나 노
ᇁ은지를나타내는향상도 (lift)에서도 두 가지 모형 모두 예측분포의 상위 10%인 집단으로 설정할 경 ᄋ
ᅮ 향상도가 개선되었다 (Table 3.4 참조).
Table 3.4 Result of response and lift table for the top 10% of the predicted probability distribution Train data (60%) Validation data (40%)
Model N High-risk Res(%) Lift N High-risk Res(%) Lift
Neural network 8,970 3,928 43.8 2.35 5,983 2,639 44.1 2.37
Logistic regression 8,974 3,885 43.3 2.33 5,984 2,624 43.9 2.36 Neural network
& Logistic regression 7,295 3,238 44.4 2.39 4,893 2,195 44.9 2.41 Res: Response
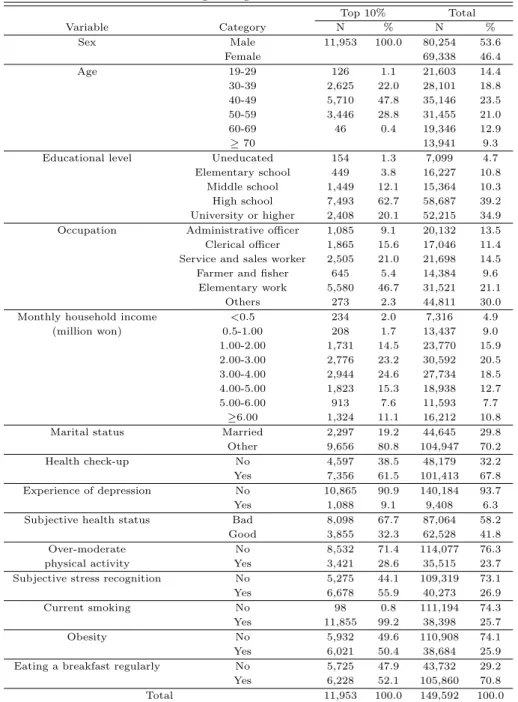
Table 3.5는 신경망과 로지스틱 회귀모형으로 개발된 예측모형의 사후확률을 기초로 두 가지 모형 ᄆ
ᅩ두 예측분포의 상위 10%인 집단을 우선 관리 대상자로 선정한 것으로, 특성을 살펴보면 40대 남 서
ᆼ의 비율이 높았으며, 최종학력의 경우 고등학교 졸업이 62.7%로 가장 높았는데 이는 전체 집단에 ᄉ
ᅥ의 39.2%보다 크게 증가함을 확인 할 수 있으며,직업의 경우 기능단순노무직과 판매서비스직이 각 ᄀ
ᅡ
ᆨ 46.7%, 12.0%로 높게 나타나 전체 집단에서의 기능단순노무직 (21.1%)과 판매서비스직 (14.5%)의 ᄇ
ᅵ율 보다 높게 나타났다. 건강검진을 받지 않은 경우 우선관리 대상자의 비율이 38.5%로 전체 집단 ᄋ
ᅦ서의 32.2%보다 증가했으며, 건강상태가 나쁘다고 인지하는 경우에서도 67.7%로 전체 집단에서의 58.2%보다 증가했다. 특히 전체 집단에서의 스트레스를경험한 비율이 26.9%인 반면, 우선관리 대상에
ᄉ
ᅥ는 55.9%로 매우 높아졌으며, 현재 흡연 여부의 경우에서도 우선관리 대상자에서는거의 100%에 가 ᄁ
ᅡ
ᆸ게 나타났다.
Table 3.5 Characteristics for the top 10% of the predicted probability distribution using neural network and logistic regression model
Top 10% Total
Variable Category N % N %
Sex Male 11,953 100.0 80,254 53.6
Female 69,338 46.4
Age 19-29 126 1.1 21,603 14.4
30-39 2,625 22.0 28,101 18.8
40-49 5,710 47.8 35,146 23.5
50-59 3,446 28.8 31,455 21.0
60-69 46 0.4 19,346 12.9
≥ 70 13,941 9.3
Educational level Uneducated 154 1.3 7,099 4.7
Elementary school 449 3.8 16,227 10.8 Middle school 1,449 12.1 15,364 10.3
High school 7,493 62.7 58,687 39.2
University or higher 2,408 20.1 52,215 34.9 Occupation Administrative officer 1,085 9.1 20,132 13.5 Clerical officer 1,865 15.6 17,046 11.4 Service and sales worker 2,505 21.0 21,698 14.5 Farmer and fisher 645 5.4 14,384 9.6
Elementary work 5,580 46.7 31,521 21.1
Others 273 2.3 44,811 30.0
Monthly household income <0.5 234 2.0 7,316 4.9
(million won) 0.5-1.00 208 1.7 13,437 9.0
1.00-2.00 1,731 14.5 23,770 15.9
2.00-3.00 2,776 23.2 30,592 20.5
3.00-4.00 2,944 24.6 27,734 18.5
4.00-5.00 1,823 15.3 18,938 12.7
5.00-6.00 913 7.6 11,593 7.7
≥6.00 1,324 11.1 16,212 10.8
Marital status Married 2,297 19.2 44,645 29.8
Other 9,656 80.8 104,947 70.2
Health check-up No 4,597 38.5 48,179 32.2
Yes 7,356 61.5 101,413 67.8
Experience of depression No 10,865 90.9 140,184 93.7
Yes 1,088 9.1 9,408 6.3
Subjective health status Bad 8,098 67.7 87,064 58.2
Good 3,855 32.3 62,528 41.8
Over-moderate No 8,532 71.4 114,077 76.3
physical activity Yes 3,421 28.6 35,515 23.7
Subjective stress recognition No 5,275 44.1 109,319 73.1
Yes 6,678 55.9 40,273 26.9
Current smoking No 98 0.8 111,194 74.3
Yes 11,855 99.2 38,398 25.7
Obesity No 5,932 49.6 110,908 74.1
Yes 6,021 50.4 38,684 25.9
Eating a breakfast regularly No 5,725 47.9 43,732 29.2
Yes 6,228 52.1 105,860 70.8
Total 11,953 100.0 149,592 100.0
4. 결론 및 제언 보
ᆫ연구에서는전국규모의 대규모 조사자료인 지역사회건강조사의 자료를바탕으로 고위험 음주자들 ᄋ
ᅴ 특성 및 고위험 음주 요인을 파악할 수 있는고위험 음주 예측모형을개발하고 개발된모형을활용 ᄒ
ᅡ여 고위험 음주 예방을위한 우선관리 대상자를선정하였다.
ᄀ
ᅩ위험 음주 예측모형을개발에는데이터마이닝의 주요 분류 기법인 로지스틱 회귀분석, 의사결정나 ᄆ
ᅮ, 신경망 분석 3가지 방법을적용하였으며, 그 결과 AUROC와 KS 통계량 측면에서는 신경망 모형이 ᄀ
ᅡ장 좋게 나타났다. 가장 보편적인 방법인 로지스틱 회귀분석의 주요 결과로는 40대 남자의 위험도가 노
ᇁ았고, 사무직과 판매서비스직의 위험도가 높았다. 또한 우울감이 있거나 스트레스가 있는경우와 비 ᄆ
ᅡᆫ인 경우에도 높게 나타났다. 특히 현재 흡연자인 경우 고위험 음주 위험도가 높아지는것을확인할 수 이
ᆻ었으며, 의사결정나무 방법에서도 성별과 현재 흡연 유무가 고위험 음주 위험에 가장 주요한 요인으로 화
ᆨ인 할 수 있었다.
ᄋ
ᅡ울러 고위험 음주의 우선관리 대상자 선정은 AUROC 측면에서 가장 높게 나타난 신경망과 로지 ᄉ
ᅳ틱 회귀모형으로 개발된예측모형의 사후확률을기초로 두 가지 모형 모두 예측분포의 상위 10%인 집 ᄃ
ᅡᆫ에 해당되는경우로 선정한 결과, 신경망이나 로지스틱 회귀모형 1가지 모형으로 적용하는것보다 반 ᄋ
ᅳ
ᆼ률 및 향상도가 다소 개선되는것으로 나타났다.
보
ᆫ 연구에서 개발된 고위험 음주 예측모형과 우선 관리 대상자 선정 방법을 실제 의료서비스 제공기 과
ᆫ에서활용할 경우, 문제적 음주에 노출될가능성이큰 집단 또는고위험 음주관리대상자 선정 그리고 ᄀ
ᅳ들에 대한 문제적 음주 예방 및 개선 교육, 절주 프로그램 개발 등에 보다 세분화되고 효과적인 건강 과
ᆫ리 서비스를제공할 수 있을것으로 판단된다. 또한 나아가서 음주로 발생될수 있는다양한 질병 및 ᄉ
ᅡ회적 문제를예방함으로서 의료비 및 사회적 문제로 인해 불필요하게 지출되는비용 등도 절감될 것이 ᄃ
ᅡ.
ᄆ
ᅡ지막으로, 추후 본연구에활용된 분석자료 이외 음주에관련된지역사회환경 및 지리적 요인 등을 ᄎ
ᅮ가적으로 반영하여 모형을정교화 할 경우, 고위험 음주 문제를해결하고 예방할 수 있는다양한 대책 ᄉ
ᅮ립이 가능할 것으로 판단된다.
References
Byeon, H. (2015). Prediction modeling of high risk drinking in Korea using CRT method. Asia-pacific Journal of Multimedia Services Convergent with Art, Humanities, and Sociology , 5, 99-108.
Casswall, S. and Thamarangsi, T. (2009). Reducing the harm from alcohol: Call to action. Lancet, 373, 2247-2257.
Chavez, L. J., Williams, E. C., Lapham, G. and Bradley, K. A. (2012). Association between alcohol screening scores and alcohol related risk among female veterans affairs patients. Journal of Studies on Alcohol and Drugs, 73, 391-400.
Chick, J. (1998). Alcohol health and the heart: implications for clinicians. Alcohol & Alcoholism, 33, 576-591.
Chung, S. S. and Joung, K. H. (2012). Factors associated with the patterns of alcohol use in Korean adults.
Korean Journal of Adult Nursing, 24, 441-453.
Lee, J. K. (2014). Socio-demographic and geospatial factors influencing drinking. Mental Health and Social Work, 42, 143-173.
Lee, E. K. and Park, J. H. (2016). The effects of drinking motives, refusal self-efficacy, and outcome expectancy on high risk drinking. Journal of the Korean Data and Information Science Society, 27, 1047-1057.
Lee, H. K. and Roh, S. W. (2011). The relations of alcohol drinking behavior, depressive mood, and suicidal
ideation among Korean adult. Journal of Korean Alcohol Science, 12, 155-168.
Ryu, S. Y., Crespi, C. M. and Maxwell, A. E. (2013). Drinking patterns among Korean adults: Results of the 2009 Korean Community Health Survey. Journal of Preventive Mdicine and Public Health, 46, 183-191.
Kang, H. C., Han, S. T., Choi, J. H., Lee, S. G., Kim, E. S. and Um, I. H. (2014). Methodology of data mining for big data analysis: A case study on SAS Enterprise Miner, Free Academy, Seoul.
Kim, M. K. (2012). A study on parents’ alcohol use, university students’ alcohol expectancy, and alcohol use disorder: Mediating effects on self-esteem and depression. Asian journal of Child Welfare and Development, 10, 61-80.
Kim, M. K., Ko, M. J. and Han, J. T. (2010). Alcohol consumption and mortality from all-cause and cancers among 1.34 million Koreans: the results from the Korea national health insurance corporation’s health examinee cohort in 2000. Cancer Causes Control, 21, 2295-2302.
Kweon, G. Y. (2005). Factors influencing drinking of employees: focus on the white collar employees.
Korean Journal of Social Welfare, 57, 93-118.
Maskarinec, G., Meng, L. and Kolonel, L. N. (1998). Alcohol intake, body weight, and mortality in a
multiethnic prospective cohort. Epidemiology, 9, 654-661.
2017, 28
(6)
,1337–1348
Developing the high-risk drinking predictive model in Korea using the data mining technique
Il-Su Park
1
· Jun-Tae Han2
1Department of Health Management, Uiduk University
2Department of Student Aid Policy Research, Korea Student Aid Foundation
Received 20 September 2017, revised 20 October 2017, accepted 2 November 2017
Abstract
In this paper, we develop the high-risk drinking predictive model in Korea using the cross-sectional data from Korea Community Health Survey (2014). We perform the logistic regression analysis, the decision tree analysis, and the neural network analysis using the data mining technique. The results of logistic regression analysis showed that men in their forties had a high risk and the risk of office workers and sales workers were high. Especially, current smokers had higher risk of high-risk drinking. Neural network analysis and logistic regression were the most significant in terms of AUROC (area under a receiver operation characteristic curve) among the three models. The high-risk drinking predictive model developed in this study and the selection method of the high-risk intensive drinking group can be the basis for providing more effective health care services such as hazardous drinking prevention education, and improvement of drinking program.
Keywords: Decision tree, high-risk drinking, logistic regression, neural network.
1
Assistant professor, Department of Health Management, Uiduk University, 261 Donghaedaero, Gang- dong, Gyeongju, Gyeongbuk, 38004, Korea.
2