Hand Language Translation Using Kinect
7
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
수치
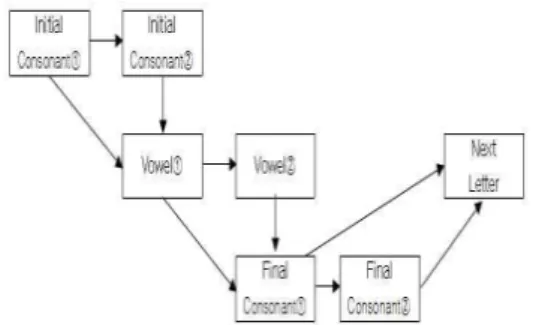
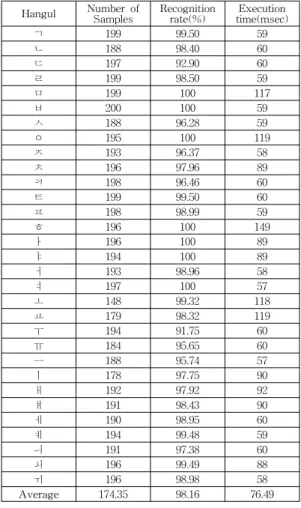
관련 문서
According to the results of this study, the biggest visual effect that can be achieved by introducing a fusion collage technique using various media into
In order to simulate a thermo-mechanical behavior in the vicinity of the deposited region by a LENS process, a finite element (FE) model with a moving heat flux is developed
Using this leap motion, a surgeon can perform the virtual shoulder arthroscopic surgery skillfully and reduce mistakes in surgery.. The simulation using leap motion shows
In this paper, we propose a method to guarantee the system life as passive elements by using high efficiency operation and analog devices by tracking
In this paper, photosensitivity measurement interferometer using a Electronic Speckle Pattern Interferometry theory develope and verify through a comparative
ventilation unit at the top and a hydrogen charging station with a ventilation unit at the bottom by using it, the flame and temperature generated inside the
Thus, in this regard, this study aims to explore specific ways in which teachers can achieve the right social development of learners by using pictorial
In addition to the problem of this bias, the problem caused by using the time variable with a weighted wage rate may be a multicollinearity between time value (=time x
