Development of the Unified Database Design Methodology for Big Data Applications - based on MongoDB -
1)
전체 글
1)
수치
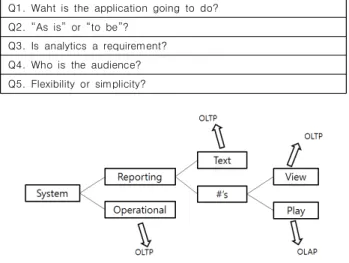
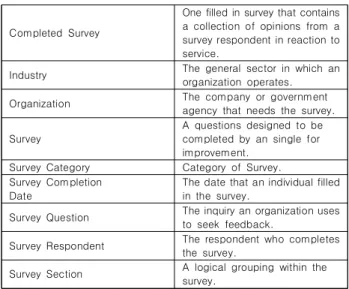
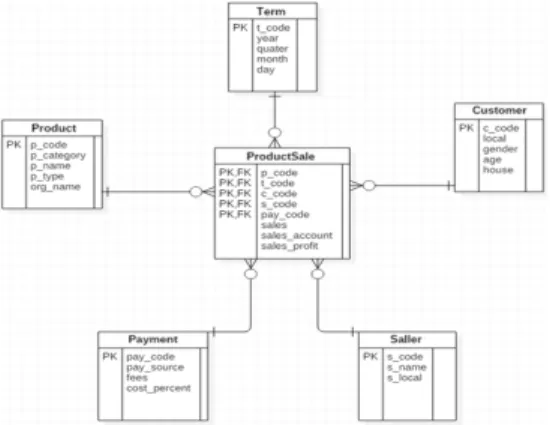
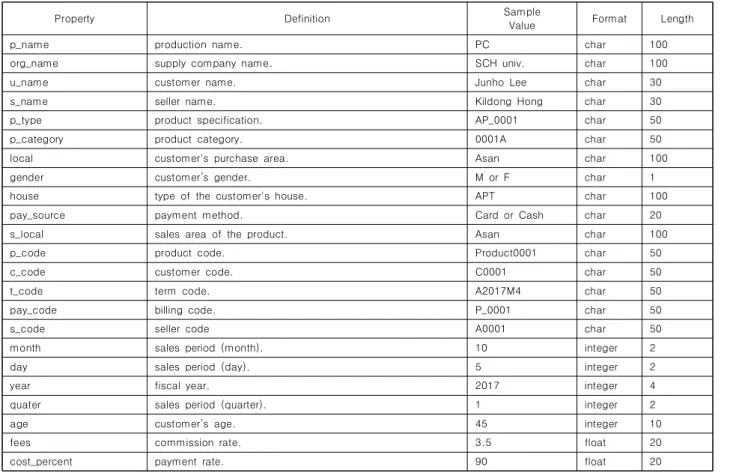
관련 문서
CREATE TABLE puzzle_info ( pid INTEGER PRIMARY KEY, totalcellnum INTEGER NOT NULL, colcellnum INTEGER NOT NULL, quizn INTEGER NOT NULL,. quiznum INTEGER REFERENCE
이 논문에서는 서명 수열-양방향 종속 시스템 방식 기반의 선내 전파전달특성 측정을 위한 시스템을 설계 하고, 구현을 통하여 실측한 데이터를 분석하였다. 향후
