Copyright
Ⓒ2016 KSAE / 141-01 pISSN 1225-6382 / eISSN 2234-0149 DOI http://dx.doi.org/10.7467/KSAE.2016.24.2.127 Transactions of KSAE, Vol. 24, No. 2, pp.127-136 (2016)
시각물체 추적 시스템을 위한 멀티코어 프로세서 기반 태스크 스케줄링 방법
이 민 채1)․장 철 훈2)․선 우 명 호*3)
만도 글로벌 R&D 센터1)․한양대학교 자동차공학과2)․한양대학교 미래자동차공학과3)
A Task Scheduling Strategy in a Multi-core Processor for Visual Object Tracking Systems
Minchae Lee1)․Chulhoon Jang2)․Myoungho Sunwoo*3)
1)
Global R&D Center, Mando, 21 Pangyo-ro, 255-gil, Bundang-gu, Seongnam-si, Gyeonggi 13486, Korea
2)
Department of Automotive Engineering, Hanyang University, Seoul 04763, Korea
3)
Department of Automotive Engineering, Hanyang University, Seoul 04763, Korea (Received 16 February 2015 / Revised 21 November 2015 / Accepted 12 December 2015)
Abstract : The camera based object detection systems should satisfy the recognition performance as well as real-time constraints. Particularly, in safety-critical systems such as Autonomous Emergency Braking (AEB), the real-time constraints significantly affects the system performance. Recently, multi-core processors and system-on-chip techno- logies are widely used to accelerate the object detection algorithm by distributing computational loads. However, due to the advanced hardware, the complexity of system architecture is increased even though additional hardwares improve the real-time performance. The increased complexity also cause difficulty in migration of existing algorithms and development of new algorithms. In this paper, to improve real-time performance and design complexity, a task scheduling strategy is proposed for visual object tracking systems. The real-time performance of the vision algorithm is increased by applying pipelining to task scheduling in a multi-core processor. Finally, the proposed task scheduling algorithm is applied to crosswalk detection and tracking system to prove the effectiveness of the proposed strategy.
Key words : Vision system(영상인식시스템), Object tracking(물체추적), Task scheduling(태스크 스케줄링), Multi-processor(다중연산장치)
1. 서 론
1)
지능형자동차의 핵심적인 시스템인 주행환경 인 식 시스템은 카메라, 레이더 등을 이용하여 차량, 차 선, 보행자 등의 주행환경을 인식하는 시스템이다.
이러한 주행환경 인식 시스템은 차량의 주행안전은 물론 편의성 향상을 위해 점차 많은 차량에 적용되 고 있다. 대표적으로 레이더를 이용하여 선행차량 을 인식하고 차간 거리를 제어하는 Adaptive Cruise
*
Corresponding author, E-mail: [email protected]
Control(ACC)과 카메라를 이용하여 차선을 인식하 고 차선이탈을 방지해 주는 Lane Keeping Assist System(LKAS) 등이 점차 확대 적용되고 있다.1) 또 한 유럽과 미국을 중심으로 사고율 감소를 위하여 충돌위험시 자동으로 제동하는 Autonomous Emer- gency Braking(AEB) 기능과 같은 주행안전 기능의 법제화 또한 추진되고 있다.2,3)
이러한 지능형자동차의 인식시스템은 차량의 주 행 안정성을 확보하기 위해 실시간으로 주행환경을 인식하여야 하기 때문에 소프트웨어 알고리즘의 실
이민채․장철훈․선우명호
시간성을 반드시 만족하여 한다. 하지만 카메라 기 반 인식시스템은 타 거리 기반의 인식 시스템과는 달리 영상 처리를 통해 물체를 인식하기 때문에 보 다 많은 신호처리 알고리즘과 연산시간을 필요로 한다. 또한 최근에는 근거리와 원거리에 위치하는 물체를 동시에 인식하기 위해 고해상도의 영상센서 가 요구됨에 따라, 프로세서가 처리해야 할 정보량 이 더욱 더 늘어나고 있다.4,5) 이에 따라 고해상도 영 상 데이터를 처리하기 위한 고성능의 하드웨어가 많이 개발되고 있으며, 최근에는 멀티 코어, GPU, FPGA 등을 이용한 병렬처리 기반 영상처리 시스템 에 대한 연구도 많이 이루어지고 있다.6)
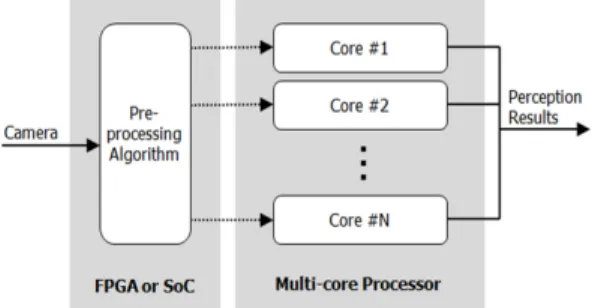
대표적인 영상처리 병렬화 방법으로는 FPGA 또 는 SoC를 이용한 하드웨어적 기능 분산 방법이 일 반적이다. Fig. 1은 이러한 하드웨어를 이용한 병렬 화 구조를 보여주고 있다. 이 방법에서는 연산량이 많거나 영상처리를 위한 공통적으로 수행하여야 하 는 부분을 기능적으로 분리하여 FPGA 또는 SoC로 구현한다. 또한 멀티코어 프로세서를 이용하여 상 위 어플리케이션을 병렬처리 함으로서 수행시간을 향상시킨다. 하지만 이러한 방법은 FPGA 또는 SoC 구현 후 알고리즘의 변경이 어려우며, FPGA와 프로 세서에 소프트웨어를 분산하는 방법에 따라 성능이 크게 차이가 나게 된다. 또한, FPGA에 알고리즘을 구현하고 성능을 검증하는 것은 매우 많은 시간과 노력을 필요로 하는 것으로, 알고리즘 개발단계의 경우 효율성이 떨어지게 된다.
멀티코어 및 모바일 GPU를 이용한 실시간 영상 처리 또한 인식 성능과 개발 효율성을 만족시킬 수 있는 방법으로 활발한 연구가 진행되고 있다. 모바 일 GPU는 일반 PC에 적용되어 있는 GPU보다 병렬
Fig. 1 Multi-processor based parallel processing structure
처리 유닛의 수는 적지만, 하드웨어 및 소프트웨어 개선을 통하여 실시간 영상처리가 가능하도록 발전 하고 있다. 이러한 GPU는 SW의 변경이 용이하기 때문에, 기존의 FPGA 또는 SoC보다 알고리즘의 성 능을 검증하고 재설계하기 용이하다. 하지만 시스 템 단가가 상승하고 순차적인 알고리즘에는 적용하 기 어려운 단점이 있다.7)
실시간 시스템 분야에서도 스케줄링 및 알고리즘 구조를 변경하여 영상처리 효율성을 향상시키는 연 구가 진행되고 있다. 멀티코어에서 실행되는 각 스 레드에 알고리즘을 분산하여 처리하는 방법으로 적 절한 스케줄링을 통하여 전체 처리속도를 향상시키 는 방법이다.8,9) 이러한 스케줄링 방법의 경우 일반 적으로 특정 알고리즘에 국한되어 적용되고 있으 며, 해당 알고리즘 및 하드웨어 시스템에 맞게 최적 화되어 적용된다. 하지만 알고리즘에 따라 적용되 기 힘든 구조이거나, 하드웨어에 따라 별도의 최적 화 과정을 거쳐야 하는 경우도 있다.
이 연구에서는 기존의 선행연구가 하드웨어를 추 가 적용함에 따라 발생하는 개발 효율성 저하 및 구 현 문제를 해결하기 위하여, 일반적으로 쉽게 접근 가능한 멀티코어를 이용하여 기존에 구현된 알고리 즘의 실시간 성능을 향상시키기 위한 방법을 제안 하였다. 이 연구에서 적용된 방법은 CPU에서 명령 어들이 파이프라이닝을 통하여 처리되는 것과 같 이, 태스크를 파이프라이닝하여 단위시간당 처리되 는 태스크 수를 증가시켜 실시간 성능 및 추적성능 을 향상시킨다. 이 방법은 기존에 개발된 알고리즘 의 변경을 최소화하며, 전체적인 실시간 성능을 향 상시키는 것이 목적이다. 이를 위하여 이 연구에서 는 기존의 알고리즘을 몇 개의 모듈로 분해하고, 이 를 태스크 기반으로 스케줄링 하여 성능을 향상시 켰다.
2. 병렬처리 시스템
이 연구에서는 병렬처리 이용하여 기존 알고리즘 의 실시간 성능을 향상시켰다. 하지만 병렬처리 방 법은 기존의 모든 알고리즘에 바로 적용이 가능하 지 않다. 이 장에서는 이를 설명하기 위한 기본적인 병렬처리 접근방법과 한계를 다루고 있다.
시각물체 추적 시스템을 위한 멀티코어 프로세서 기반 태스크 스케줄링 방법
2.1 병렬처리 구조
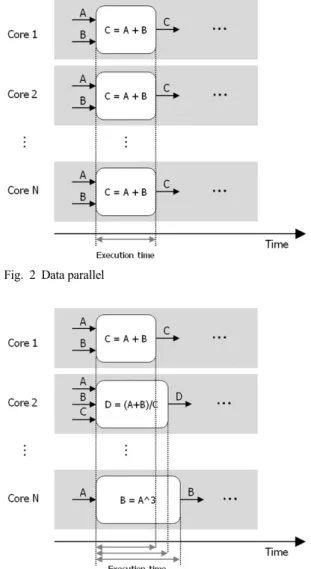
병렬처리 시스템의 구조는 크게 두 가지로 나눌 수 있다. 영상처리와 같이 데이터 집약적인 기능을 동시에 처리하기 위한 데이터 병렬(data parallel)과 다양한 기능을 동시에 수행하기 위한 태스크 병렬 (task parallel)이다. Fig. 2는 데이터 병렬을 나타내고 있으며, Fig. 3은 태스크 병렬을 나타내고 있다. 다음 은 이에 대한 각각의 장단점을 설명한다.
2.2 데이터 병렬과 태스크 병렬
데이터 병렬은 최근 많은 연구에 활용되고 있는 GPU와 같이 데이터 처리에 특화된 하드웨어를 이 용하여, 다량의 데이터를 동시에 처리하는 방법이 다. Fig. 2와 같이 같은 연산을 여러 하드웨어를 통하 여 분산 수행하는 것이 핵심이며, 가용한 하드웨어 의 수가 많을수록 처리 속도가 향상되고 쉽게 확장 이 가능한 장점이 있다. 즉, 하드웨어 성능이 향상된 다면 알고리즘의 큰 수정 없이 성능을 향상시킬 수 있다. 반면, 가장 큰 단점으로는 알고리즘이 데이터 병렬에 적합한 형태이어야 한다. 각각의 연산유닛 에서 처리하는 연산이 동일하여야 하며, 연산부하 및 연산속도가 일정하여야 분산처리가 가능하다.
병렬처리 하고자 하는 알고리즘이 순차적으로 처리 되어야 하는 방법으로 구성되어 있다면, 데이터 병 렬을 적용할 수 없다.
Fig. 3과 같이 태스크 병렬은 일반적인 PC와 같이 여러 개의 성격이 다른 어플리케이션을 동시에 처 리하는 방법이다. 이는 GPU보다는 좀 더 다양한 연 산이 수행 가능한 CPU에 적합한 작업이다. 데이터 병렬과는 다르게 알고리즘이 순차적으로 수행되어 야 하고, 다양한 연산이 이루어져야 한다면 태스크 병렬 방법이 유리하다. 하지만 태스크 병렬방법은 각각의 CPU에서 수행되는 알고리즘의 수행시간이 서로 다르기 때문에 이로 인한 CPU 유휴시간이 발 생할 수 있다. 또한 이러한 방법은 제한적인 연산만 수행이 가능한 GPU에 적용되기 힘들어, CPU와 같 이 보다 일반적인 프로세서를 필요로 하게 된다.
2.3 알고리즘의 병렬화 방법과 한계
태스크 병렬과 데이터 병렬은 위에서 설명한 것
Fig. 2 Data parallel
Fig. 3 Task parallel
과 같이 이상적인 경우 프로세서의 수가 늘어나는 만큼 연산시간을 줄일 수 있다. 하지만 실제 많은 어 플리케이션은 프로그램 구조상 병렬화가 가능한 부 분이 제한적이다. 이러한 병렬화를 통한 성능향상 은 암달의 법칙(Amdahl’s Law)을 통해 예측이 가능 하다. 암달의 법칙은 프로그램 수행시간을 병렬화 가 가능한 부분과 병렬화가 가능하지 않은 부분을 나누어서 전체 시간을 나타낸다. 다음은 이를 수식 으로 나타낸 것이다.
(1)
은 1개의 프로세서로 전체 프로그램 수행Minchae Lee․Chulhoon Jang․Myoungho Sunwoo
시간 나타낸다. 이때 프로그램 수행시간은 병렬화 가능하지 않은 부분을 나타내는 시간()과 병렬화 가능한 부분의 시간()으로 나타낼 수 있다. 만약, 병렬화 가능한 프로세서가 개로 늘어날 경우 이는 다음과 같이 표현할 수 있다.
(2)
여기에서 은 프로세서 수이며, 병렬화 가능한 부분의 시간()이 배 줄어들기 때문에
로 나타낼 수 있다. 최종적으로 병렬화를 통한 속도 향 상은 다음과 같이 나타낼 수 있다.
(3)여기에서
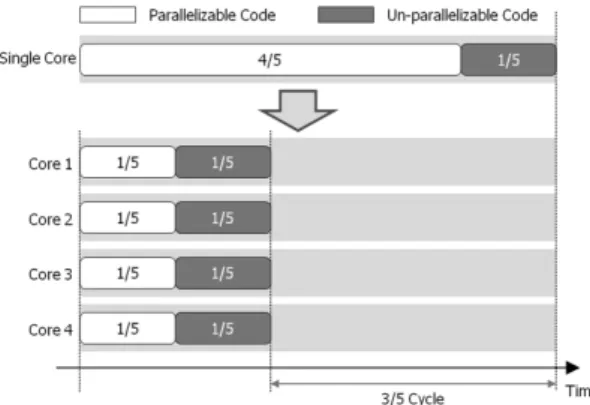
은 병렬화 가능하지 않은 부분의 비율 이며, 는 병렬화를 통한 속도향상 비율이다.Fig. 4 1/5 un-parallelizable code
Fig. 5 4/5 un-parallelizable code
이러한 암달의 법칙은 Fig. 4와 Fig. 5에서 쉽게 확 인 할 수 있다. Fig. 4는 병렬화가 가능한 부분이 전 체 수행시간의 4/5를 차지하며 나머지 1/5만이 병렬 화가 가능하지 않다. 이에 따라 병렬화시 줄어드는 수행시간은 기존대비 3/5 만큼이 된다. 하지만 Fig. 5 의 경우 병렬화가 가능한 부분이 1/5이며, 병렬화로 얻는 시간 이득은 3/20으로 크게 제한된다. 이와 같 이 실제 소프트웨어의 병렬화 가능 부분의 비율에 따라 성능향상 폭이 크게 달라지게 된다.
3. 영상처리 시스템 병렬화 방법 3.1 기능분리를 통한 병렬화
지능형 자동차를 위한 영상처리 시스템은 인식성 능과 실시간성을 모두 만족하여야 한다. 하지만 일 반적으로 인식 성능을 높이기 위해서는 보다 많은 연산시간을 필요로 하게 된다. 소프트웨어 측면에 서 이를 해결하기 위한 방법은 영상처리 알고리즘의 처리속도를 향상시키는 것이다. 하지만 인식성능을 유지하면서 처리속도를 향상시키는 것은 쉽지 않으 며, 하드웨어를 추가하고 기능을 분리하여 병렬처 리함으로써 기존 알고리즘의 수행시간을 향상시킬 수 있다. 예를 들어 HOG와 같은 공통적이며 선행처 리가 필요한 부분은 고속의 SoC나 FPGA를 이용하 고, 이를 이용한 어플리케이션은 병렬의 프로세서 에서 처리하여 전체 처리속도를 향상 시킬 수 있다.
이러한 병렬처리 방법은 일반적으로 구현하기 용 이하며, 각각 개발된 어플리케이션을 쉽게 통합할 수 있는 장점이 있다. 하지만, 이러한 병렬화 방법은 SoC에서 수행하는 영상처리 결과에 모든 어플리케 이션이 의존하게 되므로, 각 프로세서에 할당된 어 플리케이션을 수행한 후, 동기화를 위한 유휴시간 이 발생하게 된다. Fig. 6은 이러한 동기화된 어플리 케이션의 수행시간과 유휴시간을 보여주고 있다.
각각의 어플리케이션은 할당된 기능을 수행한 후, 다음 사이클을 시작하기 위하여 일정 유휴시간을 가지게 된다. Fig. 7은 어플리케이션을 비동기화하 여 처리하였을 때, 처리과정을 보여주고 있다. Fig. 6 과는 달리 유휴시간이 발생하지 않지만 각각의 실 행주기가 달라진다. 이와 같이 공통부분을 별도의 하드웨어에서 수행하는 경우 이러한 비동기 어플리
A Task Scheduling Strategy in a Multi-core Processor for Visual Object Tracking Systems
Fig. 6 Synchronous task scheduling
Fig. 7 Asynchronous task scheduling
케이션 실행은 적용할 수 없을 뿐만 아니라 각각의 어플리케이션 수행속도 역시 개선될 수 없다.
3.2 태스크 파이프라이닝을 통한 병렬화 이 연구에서 제안된 방법은 기존의 프로세서가 명령을 수행 시 파이프라이닝 방법을 이용하여 성 능(throughput)을 향상시키는 것과 유사한 방법으로, 태스크 병렬의 방법 중 하나이다. 파이프라이닝의 장점은 기존 알고리즘을 나누어 여러 프로세서에서 수행할 경우, 총 연산시간은 변함이 없지만 성능이 증가한다는 장점이 있다. 따라서 영상처리의 경우 획득한 영상을 처리하는 시간은 동일하지만, 출력 이 업데이트 되는 주기는 빨라지게 된다. 즉, 획득된 이미지가 최종 결과로 나오는 시간차는 존재하지 만, 처리결과의 주기는 빨라지게 된다. 이는 실시간 위치 추정 등이 필요한 제어 알고리즘에는 중요한 역할을 한다. 시간지연은 일정하고 예측이 가능하 지만, 센서 데이터의 신뢰성 확보 및 안정적인 물체 추적을 위해서는 빠른 주기가 필수적이다.
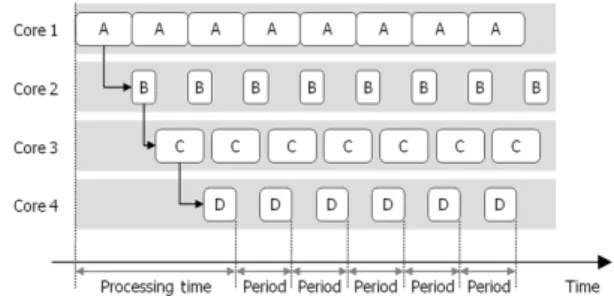
Fig. 8과 Fig. 9는 태스크 할당 정책에 따른 두가지 파이프라이닝 방법을 보여주고 있다. Fig. 8의 경우 하나의 코어에서 한가지의 태스크만을 수행하는 구
Fig. 8 Pipelining with homogeneous task allocation
Fig. 9 Pipelining with heterogeneous task allocation
조(homogeneous)이며, Fig. 9의 경우에는 하나의 코 어에서 모든 연산을 수행하고 이를 여러 코어가 일 정한 주기를 가지고 동시에 처리하는 구조(hetero- geneous)이다. 각각 구현되는 방법은 차이가 있으 나, 실질적인 최종 출력주기는 같음을 확인할 수 있다.
일반적으로 Fig. 8과 같은 구조는 최초에 알고리 즘을 설계하고 구현할 때 개발하기 용이한 구조이 며, Fig. 9와 같은 구조는 기존에 개발되어 있는 알고 리즘을 병렬화하기 쉬운 구조이다. 따라서 이 연구 에서는 기존 구현되어 있는 알고리즘의 성능을 개 선하기 위해서 Fig. 9와 같은 구조의 태스크 할당과 스케줄링 방법을 이용하여 시스템을 구성하였다.
4. 스케줄러 디자인
이 연구에서 제안된 태스크 스케줄러는 멀티코어 프로세서 환경에서 어플리케이션을 병렬화 함으로 써 물체인식 및 추적 성능을 향상시키기 위하여 개 발되었다. 이 연구에서 제안하는 태스크 스케줄러 는 스케줄러, 스케줄 테이블, 스레드, 태스크로 크게 4가지 요소로 구성된다. 각각은 이벤트를 통하여 동 기화 된다.
이민채․장철훈․선우명호
4.1 태스크 및 스레드
스레드는 CPU에 각각 하나씩 할당되어 태스크를 실행하는 역할을 한다. 스레드는 스케줄 테이블에 의해 정해진 시간 또는 이벤트에 의해 동작되게 된 다. 태스크는 이때 스레드에 의해 수행되는 사용자 어플리케이션이다. 따라서 태스크 디자인은 각 태 스크의 역할 및 수행시간을 고려하여 결정되어 한 다. 이 연구에서는 기존에 수행되던 알고리즘을 여 러 스레드에서 동시에 수행하기 때문에 하나의 태 스크에 시간차를 두어 실행하고, 알고리즘이 동시 에 실행될 때 데이터를 보호하는 방법이 중요하다.
알고리즘의 구조 측면에서, 기존 하나의 CPU에 서 실행되는 어플리케이션에 비하여 가장 크게 차 이가 발생하는 부분이 데이터 공유이다. 여러 CPU 에서 자원을 공유할 경우 이를 보호하고 통제할 수 있는 방법이 필요하다. 일반적으로 세마포어, 뮤텍 스 등과 같은 방법을 이용하며, 이 연구에서도 뮤텍 스를 이용하였다. 즉, 하나의 CPU에서 데이터에 접 근할 경우에는, 다른 CPU의 접근을 일시적으로 차 단하고 대기하도록 하여 데이터를 보호하였다.
4.2 태스크 스케줄러 및 스케줄 테이블 스케줄 테이블은 시간에 따른 항목과 이벤트에 따른 항목으로 구분되며, 스케줄러에 의해서 해석 된다. 스케줄러는 스케줄 테이블을 해석하여 이벤 트와 스레드를 생성하고 이를 태스크와 연결하는 역할을 한다. 스케줄러는 초기화 과정 시스템에서 가용한 수만큼의 스레드를 생성하고 이를 각각 CPU에 할당한다. 생성된 스레드는 태스크를 수행 하는 역할을 하게 되며, 이를 위하여 이벤트를 기다 리게 된다. 따라서 스케줄러는 스레드가 기다릴 이 벤트를 생성하고, 해당 이벤트가 어떤 태스크를 수 행하여야 하는지 설정하게 된다. Table 1은 이때 사 용되는 스케줄 테이블의 예를 보여주고 있다. 각각 의 태스크는 정해진 CPU에 할당되어 연산을 수행 하게 된다. 이때 주어진 offset 만큼 연산을 시작하는 시간이 지연되게 되며, 이에 따라 각 CPU는 서로 다 른 실행 분포를 보이게 된다. 이는 Fig. 8 및 Fig. 9에 서 보는 것처럼, 각 프로세서마다 시작 시간이 다른 것과 같다.
Table 1 Schedule table
CPU ID Task ID Offset [ms] Period [ms]
Task 1 1 0 0 30
Task 2 3 1 30 30
5. 소프트웨어 구현
이 연구에서 사용된 소프트웨어는 다양한 소프트 웨어 구조 구현의 용이성 및 소프트웨어 분석을 위하 여 윈도우 기반의 소프트웨어 개발환경에서 구현되 었다. 하지만 제안된 방법은 최근 자동차용으로 개발 되고 있는 Dual-core, Quad-core 등의 Multi-core 기반 의 임베디드 시스템에 바로 적용하여 활용 가능하다.
사용된 운영체제는 Windows이며, Microsoft사의 Visual Studio환경에서 C++언어를 사용하여 구현되 었다. 스레드는 윈도우 API에서 제공하는 posix-thread 를 이용하였으며, 스레드에 전달되는 이벤트는 윈 도우에서 제공하는 시스템 Event를 이용하였다. 하 드웨어는 4개의 Core를 가진 64bit PC를 이용하였 다. 실제 윈도우에는 구현된 소프트웨어 환경 외에 기타 서비스 어플리케이션이 동작하기 때문에, 정 밀한 이벤트 전달 및 정확한 시간을 측정하기에는 제약사항이 있으나, 이 연구의 결과를 검증하기에 는 충분하였다.
6. 사례연구 : 횡단보도 인식 및 추적 이 연구에서 적용한 사례연구는 횡단보도 인식 및 추적 알고리즘이다. 횡단보도 인식은 횡방향으 로 반복되는 패턴을 인식하여 거리를 추정하는 것 이 목표이며, 차량 제어기는 추정된 거리를 이용하 여 차량을 제어하게 된다. 따라서 거리의 정확도 뿐 아니라 실시간성 또한 중요하며, 이 연구에서는 횡 단보도 인식과 추적 부분을 분리하여, 각각을 Task 로 구성하였다. 그 결과 횡단보도 추적 알고리즘의 인식 주기가 증가함은 물론 추적 성능도 개선되었 음을 확인하였다.
6.1 횡단보도 인식 시스템 구조
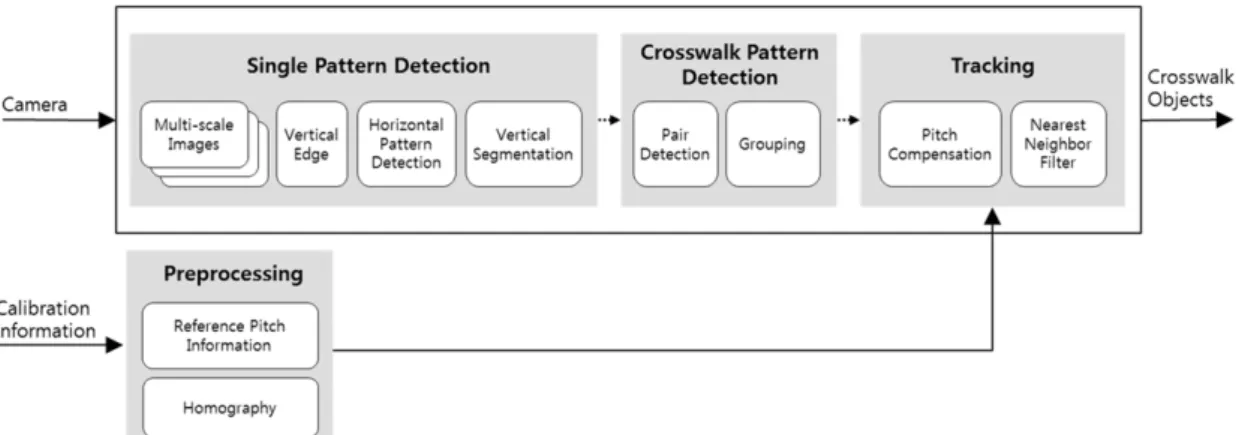
Fig. 10은 횡단보도 인식 시스템의 소프트웨어 구 조를 설명하고 보여주고 있다. 횡단보도 인식 시스 템은 그림과 같이 여러 단계의 알고리즘으로 구성
시각물체 추적 시스템을 위한 멀티코어 프로세서 기반 태스크 스케줄링 방법
Fig. 10 The structure of crosswalk detection algorithm
Fig. 11 The multi-scaled images for crosswalk detection
되어 있다. 횡단보도의 반복되는 패턴을 인식하기 위하여 단일 패턴을 인식하고 이를 이용하여 반복 되는 패턴을 그룹화 한다. 마지막으로는 종방향 거 리를 계산하고 이를 기반으로 칼만 필터를 이용한 다중물체 추적을 수행한다.
횡단보도 패턴은 지표면에 위치하여 거리에 따라 그 크기 및 길이가 변하게 된다. 또한 차선과 같이 소실점을 향하여 평행한 직선이 원근(perspective)변 형이 되어 영상으로 나타나게 되며, 이를 거리에 관 계없이 인식하기 위해서는 다중 스케일의 영상이 필수적이다. Fig. 11은 이러한 다중 스케일 영상을 보여주고 있다. 이는 물체인식, 차량인식 등의 인식 방법에 일반적으로 적용되는 방법이며, 이를 이용 하여 원거리와 근거리의 물체 인식에 동일한 알고 리즘을 적용할 수 있게 된다.
6.2 패턴 기반 횡단보도 인식
단일 패턴 인식은 다중 스케일 영상을 기반으로 각각의 이미지에서 종방향 직선을 찾는 과정이다.
단일 패턴은 횡단보도의 사각형 형태에서 종방향 직선을 지칭하는 것으로, 이러한 직선은 횡방향으 로 반복적으로 검출되게 된다. 종방향 직선은 다중 스케일 영상을 기반으로 각각의 이미지에서 픽셀 형태로 검출되게 되며, 검출된 픽셀들은 세그멘테 이션 과정을 거쳐 하나의 직선으로 표현되게 된다.
즉, 이러한 단일 패턴 인식과정은 2차원 배열 형태 의 픽셀 이미지가 직선 단위 오브젝트로 변환되는 과정으로 볼 수 있다. 따라서 이후 과정은 영상의 픽 셀단위 처리가 아닌 직선 오브젝트 단위의 처리가 이루어지게 된다.
횡단보도는 종방향 직선이 연속되고 반복되는 형 태를 가지고 있다. 즉, 단일 패턴 인식과정을 통해 검출된 직선 오브젝트가 반복되는 것을 의미하며, 횡단 보도 인식은 이러한 반복된 패턴 찾는 과정이 다. 하지만, 주행환경에서 이러한 횡방향으로 반복 되는 패턴은 횡단보도 외에도 많이 검출이 될 수 있 으며, 이는 오인식률을 높이게 된다. 따라서 횡단보 도의 사각형을 우선적으로 인식하기 위해 상승과 하강 두 가지의 종류의 직선 오브젝트를 찾아 짝을 이루게 된다. 짝을 이룬 직선 오브젝트는 하나의 사 각형이 되며, 최종적으로 이러한 사각형이 반복되 는 것을 횡단보도로 인식하게 된다. 단, 횡단보도는 일정한 크기와 길이 그리고 차선, 차량과의 기하학 적 제약사항이 있으므로 이러한 정보를 이용하여 오인식을 줄이는 과정을 거치게 된다. Fig. 12는 각 각의 직선이 짝을 이루어 반복되는 패턴을 찾은 영 상을 보여주고 있다.
Minchae Lee․Chulhoon Jang․Myoungho Sunwoo
Fig. 12 The pairs of edge segments
Fig. 13 The multi-target tracking results
6.3 좌표변환 및 횡단보도 추적
인식된 횡단보도는 영상 이미지에서 픽셀단위의 위치와 크기로 나타나게 된다. 이러한 픽셀단위의 정보를 차량제어에 사용하기 위해서는 카메라 보정 및 역원근(inverse perspective) 변환을 통하여 차량 과의 상대좌표가 결정되어야 한다. 또한 차량의 종 방향 가감속에 의한 pitch 모션은 역원근 변환을 통 한 상대좌표 결정에 큰 영향을 미치며, 이를 보상하 여야 정확한 거리를 획득할 수 있다. 인식된 횡단보 도의 위치는 최종적으로 NNF(Nearest Neighbor Filter)를 통하여 추적 되게 된다. NNF는 track manage- ment와 칼만 필터가 결합된 형태로, 다중 물체를 추 적하는 가장 일반적인 방법이다. Fig. 13은 NNF를 이용하여 다수의 횡단보도를 추적하는 결과를 보여 주고 있다.
6.4 수행시간 및 추적성능
이 사례연구에서 수행한 병렬화 방법은 제안된 파이프라이닝을 이용하여 알고리즘을 동시에 수행 하는 것이다. 따라서 동일한 알고리즘을 동시에 시 간차를 두어 수행하였고, 최종적으로 NNF는 각 태 스크에 공통적으로 적용되어 실행 주기를 높였다.
이러한 스케줄링 테이블은 Table 2와 같이 구성되 며, 그 결과 Fig. 14와 같이 수행시간이 배치되게 된 다. Task 1과 2, 3은 같은 연산을 수행하는 태스크로, 파이프라이닝이 적용되었고 각각은 5 ms 간격으로 실행이 되며, 주기는 15 ms가 된다. NNF의 경우 Task 에서 수행한 인식 결과를 기반으로 5 ms 마다 횡단 보도를 추적하여 결과를 출력하게 된다.
Table 2 The schedule table for crosswalk detection systems CPU ID Task ID Offset (ms) Period (ms)
Task 1 1 0 0 15
Task 2 2 1 5 15
Task 3 3 2 10 15
NNF Task 4 3 0 5
Fig. 14 The scheduling strategy of crosswalk tasks
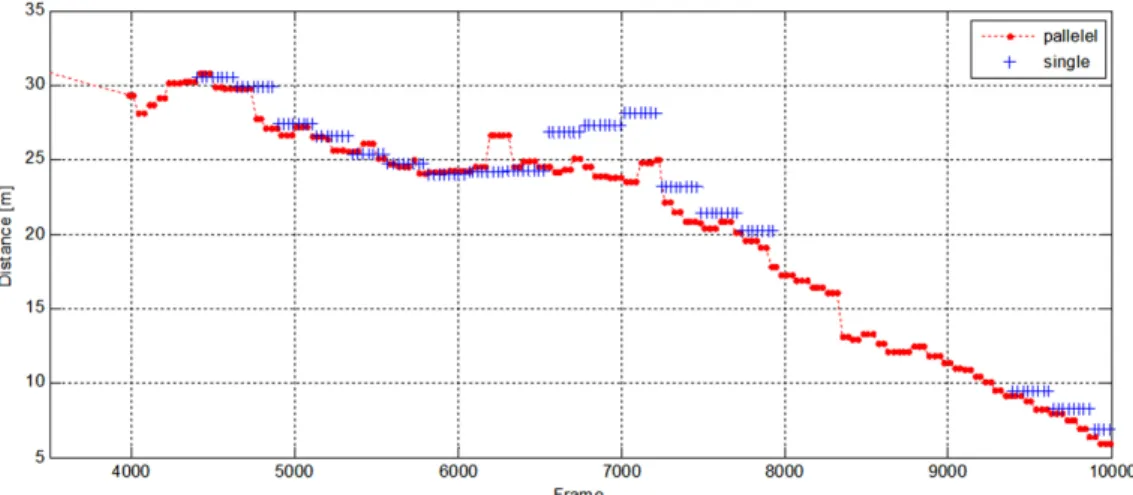
위와 같은 설정을 사례연구에 적용하여 병렬화를 수행한 결과, 하나의 테스크를 수행하는 시간은 동 일하지만 NNF를 이용한 추적성능은 향상되는 것을 확인하였다. Fig. 15와 Fig. 16은 제안된 알고리즘을 적용하여 횡단보도를 인식하고 거리를 추정한 결과 를 보여주고 있다. Fig. 15와 Fig. 16은 각각 서로 다 른 영상에 대해 추적을 한 것으로, 기존 단일코어 기 반의 알고리즘에 비하여 멀티코어를 이용하여 병렬 화된 알고리즘의 출력 주기가 빠르고, 횡단보도 추 적성이 향상된 것을 확인할 수 있다. Fig. 15에서 보 이는 것과 같이 단일 코어에서 연산을 수행한 경우
A Task Scheduling Strategy in a Multi-core Processor for Visual Object Tracking Systems
Fig. 15 The comparison of single-core and multi-core based crosswalk detection algorithms (I)
Fig. 16 The comparison of single-core and multi-core based crosswalk detection algorithms (II)
횡단보도의 위치가 업데이트 되는 간격이 넓으며, 일부 구간에서 추적을 실패하는 경우가 발생한다.
하지만 병렬화를 적용한 경우, 이를 개선하여 연속 적인 결과를 출력하고 있다. 이는 상황에 따라 변동 할 수 있으나, 실험을 진행한 상황의 경우 추적된 데 이터의 이용률이 최대 39 % 가량 상승하였다.
특히, 제어기 측면에서 추적성능의 경우 데이터 가 연속적으로 출력되는 것은 입력의 연속성 이상 의 큰 의미가 있다. 위와 같이 횡단보도와의 거리를 기반으로 제동제어를 수행하는 경우에는 성능측면 에서 큰 차이를 보이게 된다. 제동제어 도중 거리에 대한 정보가 가용하지 않을 경우 목표거리에 제동 을 실패할 수 있으며, 최악의 경우 제어를 해제하는
경우도 발생할 수 있기 때문이다.
특이사항으로는 Fig. 16의 경우 2500 frame ~ 3000 frame에서 차량에 pitch가 발생하여 횡단보도의 위 치에 급격한 변화가 발생하였다. 이때 단일 코어의 경우에는 이를 추적하지 못하고 있으나, 병렬처리 는 이러한 급격한 움직임 또한 추적하는 결과를 보 여주고 있다. pitch의 영향으로 인하여 잘못된 거리 를 출력하고는 있으나, 거리 추적이 연속적으로 이 루어지고 있기 때문에, 이는 pitch 보상을 통해 해결 이 가능하게 된다. 단일 코어의 경우 데이터가 가용 하지 않아 pitch 보상을 적용할 데이터가 존재하지 않는 상황이다. 이는 제안된 방법의 추적성이 우수 함을 보여주는 결과이다.
이민채․장철훈․선우명호
7. 결 론
지능형자동차의 인식시스템은 차량의 주행 안정 성을 확보하기 위해 인식성능 뿐만 아니라 실시간 성을 반드시 만족하여 한다. 이 연구에서는 기존의 SoC, FPGA, GPU 등을 적용한 연구가 공통적으로 가지는 알고리즘 병렬화 한계 및 디자인 복잡도 문 제를 해결하기 위하여 태스크 스케줄링 방법을 제 안하였다. 제안된 스케줄링 방법은 시각물체 추적 시스템의 성능을 향상시켰으며, 사례연구를 위하여 횡단보도 인식 및 추적시스템에 적용되어 실시간 성능 및 추적성능이 향상되었음을 확인하였다.
후 기
이 연구는 교육부의 BK21플러스사업(22A201300 00045), 지식경제부 에너지자원기술개발사업(2006 ETR11P091C), 산업통상자원부 산업원천기술개발 사업(No. 10039673, No. 10042633), 2011년도 정부 (미래창조과학부)의 재원으로 한국연구재단의 지 원을 받아 수행(No. 2011-0017495) 되었습니다.
References
1) J. S. Gu, S. Yi and K. Yi, “Human-centered Design of a Stop-and-go Vehicle Cruise Con- trol,” Int. J. Automotive Technology, Vol.7, No.5, pp.619-624, 2006.
2) S. J. Kwon, T. Fujioka, M. Omae, K. Y. Cho and M. W. Suh, “A Study on the Model-matching Control in the Longitudinal Autonomous Driving System,” Int. J. Automotive Technology, Vol.5, No.2, pp.135-144, 2004.
3) K. Y. Chu, J. H. Han, M. C. Lee, D. C. Kim, K.
C. Jo, D. E. Oh, E. N. Yoon, M. G. Gwak, K. J.
Han, D. H. Lee, B. D. Choe, Y. S. Kim, K. Y.
Lee, K. S. Huh and M. Sunwoo, “Development of an Autonomous Vehicle: A1,” Transactions of KSAE, Vol.19, No.4, pp.146-154, 2011.
4) J. H. Ryu, C. S. Kim, S. H. Lee and M. H. Lee,
“H∞ Lateral Control of an Autonomous Vehicle Using the RTK-DGPS,” Int. J. Automotive Technology, Vol.8, No.5, pp.583-591, 2007.
5) J. J. Hwang, S. G. Cho, J. S. Lee and S. H. Park,
“Maritime Object Segmentation and Tracking by Using Radar and Visual Camera Integration,”
Journal of Information and Communication Convergence Engineering, Vol.8, No.4, pp.466- 471, 2010.
6) J. H. Hong, W. J. Kim and K. S. Chung, “Inte- grated Parallelization of Video Decoding on Multi-core Systems,” Journal of The Institute of Electronics Engineers of Korea, Vol.49-SD, No.7, pp.39-49, 2012.
7) J. H. Lee, S. H. Kang, M. H. Lee, S. Li, H. I.
Kim and I. K. Park, “Real-time Parallel Image Processing Library Using Mobile GPU,” Jour- nal of KIISE : Computing Practices and Letters, Vol.20, No.2, pp.96-100, 2014.
8) W. Y. Lee, “Power-efficient Scheduling of Periodic Real-time Tasks on Lightly Loaded Multicore Processors,” Journal of The Korea Society of Computer and Information, Vol.17, No.8, pp.11-19, 2012.
9) J. Y. Kim, K. K. Kwon, S. I. Lee and K. S. Ahn,
“Implementation of IDE for OSEK/VDX OS Extended Real-time Processing and Protection Functions,” Journal of Korean Institute of Infor- mation Technology, Vol.11, No.2, pp.119-126, 2013.