학 술 논 문
321
픽셀 단위 컨볼루션 네트워크를 이용한
복부 컴퓨터 단층촬영 영상 기반 골전이암 병변 검출 알고리즘 개발
김주영
1*·이시영
2*·김규리
3·조경원
1·유승민
1·소순원
6·박은경
4조백환
2,4·최동일
2·박훈기
5·김인영
11한양대학교 의생명공학전문대학원 생체의공학과, 2성균관대학교 삼성융합의과학원 의료기기산업학과
3건국대학교 의료생명대학 의학공학부, 4성균관대학교 의과대학 삼성서울병원 스마트헬스케어의료기기융합연구센터
5한양대학교병원 가정의학과, 6한양대학교 일반대학원 생체공학과
Development of Bone Metastasis Detection Algorithm on Abdominal Computed Tomography Image using Pixel Wise
Fully Convolutional Network
Jooyoung Kim
1*, Siyoung Lee
2*, Kyuri Kim
3, Kyeongwon Cho
1, Sungmin You
1, Soonwon So
6, Eunkyoung Park
4, Baek Hwan Cho
2,4, Dongil Choi
2,
Hoon Ki Park
5and In Young Kim
11,6
Department of Biomedical Engineering, Hanyang University
2
Department of Medical Device Management and Research, Sungkyunkwan University
3
Division of Biomedical Engineering, Konkuk University
4
Smart Healthcare & Device Research Center, Samsung Medical Center, Sungkyunkwan University School of Medicine
5
Department of Family Medicine, Hanyang University Medical Center
(Manuscript received 21 November 2017 ; revised 13 December 2017 ; accepted 19 December 2017)
Abstract: This paper presents a bone metastasis Detection algorithm on abdominal computed tomography images for early detection using fully convolutional neural networks. The images were taken from patients with various can- cers (such as lung cancer, breast cancer, colorectal cancer, etc), and thus the locations of those lesions were varied.
To overcome the lack of data, we augmented the data by adjusting the brightness of the images or flipping the images.
Before the augmentation, when 70% of the whole data were used in the pre-test, we could obtain the pixel-wise sen- sitivity of 18.75%, the specificity of 99.97% on the average of test dataset. With the augmentation, we could obtain the sensitivity of 30.65%, the specificity of 99.96%. The increase in sensitivity shows that the augmentation was effective. In the result obtained by using the whole data, the sensitivity of 38.62%, the specificity of 99.94% and the accuracy of 99.81% in the pixel-wise. lesion-wise sensitivity is 88.89% while the false alarm per case is 0.5. The results of this study did not reach the level that could substitute for the clinician. However, it may be helpful for radi- ologists when it can be used as a screening tool.
Key words: Bone metastasis, Deep learning, Cancer, Computed Tomography
I. 서 론
암이란 신체 조직이 과잉 성장하고 주변 조직 및 장기로 전이되어 기존의 구조를 파괴하거나 변형시켜 본래 기능을 하지 못하도록 하는 질병을 말한다. 골 전이 암(Bone
*Contributed equally to this work.
Corresponding Author : In Young Kim
Department of Biomedical Engineering, Hanyang University, Seoul 133-791, Korea
TEL: +82-2-2220-0690 / E-mail: [email protected]
이 연구는 국방과학연구소 생존성 기술 특화연구센터의 사업으로 지
원을 받아 수행하였음(No. UD150013ID).
322
metastasis) 이란 뼈가 아닌 다른 조직에서 발생한 원발암 (Primary cancer) 조직의 암세포가 혈관이나 림프관을 통 해 이동하여 골 조직으로 침투하여 전이되는 질병이고, 골 전이 암이 진행되면 골 조직이 손상되어 골절로 인한 극심 한 통증과 마비를 일으키게 된다. 뼈는 폐, 간에 이어 암 전 이가 흔히 일어나는 3대 장기 중 하나이며, 유방암과 전립 선암의 최호발 전이(70%) 장기이기도 하다[1]. 골 전이 암 은 대부분 원발암이 상당기간 진행된 환자에게서 발생하는 데, 최근 암의 치료 기술이 향상됨에 따라 환자의 생존기간 이 길어지게 되고, 암 발생률도 증가하면서 골 전이암의 발 생 빈도가 늘어나게 되었으며 이는 곧 골 전이 암의 진단 능력 역시 중요해짐을 의미한다.
골 전이 암을 진단하기 위해서는 환자의 컴퓨터 단층 촬 영(Computed Tomography, CT) 영상을 확인하여야 하고, 복부 CT의 경우를 예로 한 환자의 CT 영상은 100여장이 넘는 경우가 많다. 임상의에게는 항상 정확하고 정밀한 판 단이 요구되는데, 2012년 한국 소비자원 발표에 따르면 매 년 암 진료에 대한 오진 중 31% 가량이 의사의 영상 판독 오류로 발생하며 그 예로 의사가 환자의 복부 CT 영상에서 다발성 골 전이 암을 판독하지 못해 환자가 사망하는 판독 오류 사례가 있었으며 2005년에는 반대로 흉추의 혈관종을 골 전이 암으로 오진하여 환자가 불필요한 치료를 받는 사 례도 발생하였다. 따라서 임상의가 판독을 진행하기 이전이 나 이후에 골 전이 암인 것으로 예상되는 부분을 확인 할 수 있도록 한다면 골 전이 암의 진단 효율은 물론 조기 검 출율과 검출 정확도 향상을 꾀할 수 있을 것이다.
골 전이 암을 판독하는 알고리즘의 개발은 크게 두 가지 방식을 고려할 수 있다. 첫번째는 기존 영상처리 알고리즘 을 응용하여 골 전이 암의 영상특성을 분석해 병변 부위를 검출해 내는 알고리즘을 직접 개발하는 것이고, 두번째는 본 연구에서 채택한 방식으로써 최근 영상 분석 분야에서 활발 하게 연구되고 효과적으로 이용되고 있는 기계학습 알고리 즘을 이용하는 것이다.
현재 다양한 영상 분석 분야에서 기계학습을 이용한 알고 리즘을 이용하고 있으며, 기계학습에는 방대한 입력 영상이 필요하기 때문에 주로 자연 영상 분석에 이용되었다[2]. 자 연 영상 분석에 이용되던 기계학습은 최근 컨볼루션 신경망 (Convolutional Neural Network, CNN) 의 구조를 수정 (Network surgery) 하여 완전 컨볼루션 신경망(Fully Con- volutional Network, FCN) 을 구현해 영상에서 원하는 대 상을 구분하는 유의미한 분할(Semantic segmentation) 알 고리즘을 이용한 연구로 발전하여 연구되고 있으며[3], 최근 기계학습의 성능이 사람의 판단과 유사하거나 이를 넘어서 는 성과를 보이면서[4] 기계학습을 객관적인 판단이 중요한 의료 분야에서 활용하는 것에 대한 연구가 다양하게 진행되
고 있다[5]. 이 중 뇌의 구조 분석[6]이나 폐, 유방과 같은 신체의 다양한 조직의 암 병변 검출[7,8]을 위한 연구가 대 표적이다.
의료영상의 경우 자연영상과 달리 자료의 확보가 어렵고 분석 과정에 의학적 진단이 필요하다. 따라서 자료의 부족 을 피하기 위해 구조적으로 단순하여 학습이 용이한 영상에 대한 연구가 주로 진행되고 있다. 특히 뇌와 폐, 유방 영상 은 촬영하는 대상과 그에 대한 방법의 기준이 정해져 있고 이에 따라 영상 전반에서 조직의 구조적 특징이 유사하게 나타난다. 또한 뇌 영상의 경우 3차원 데이터이지만 관상면 (Frontal plane) 에서의 구조가 각 면에서 유사하고, 좌우 대 칭적이어서 분석이 용이하다.
골 전이 암의 경우 원발암의 발생 위치에 따라 유방, 전 립선, 폐의 순으로 전이가 쉽게 일어나고, 이러한 장기들이 복부에 위치하였기 때문에 골 전이 암의 대부분이 복부에서 발생하여 복부 CT 영상에서 확인된다. 하지만 복부 CT는 촬영 영역에 대퇴골, 무명골, 미골, 천골, 요추, 흉추, 늑골 을 포함하여 단층영상이 구조적으로 복잡해 적은 양의 영상 자료로 기계학습에 적용하기 어려운 점이 있다. 기존의 연 구 중 기계학습을 이용하여 경화성 골 전이 암(Sclerotic spine metastases) 을 판별하는 연구[9]가 있지만, 척추에서 의 골 전이 암 영역만을 입력으로 넣은 것으로써 척추 CT 촬영이 복부 전반에 걸쳐 이루어지는 것을 감안할 때 전처 리과정을 거쳐 척추 영역만 추출하여 실제 임상에 이용하기 에는 어려움이 있을 수 있다.
따라서 본 연구에서는 임상의가 골 전이 암을 진단 할 때 스크리닝 도구로서 사용할 수 있도록 골 전이 암 환자의 복 부 CT 영상을 이용하여 학습한 완전 컨볼루션 신경망을 통 하여 골 전이 암의 병변 부위를 검출하는 알고리즘을 개발 하는 것을 목표로 하였다.
II. 연구 방법
1. Dataset
골 전이는 정상 뼈 조직을 파괴하는 골 융해성 전이와 새 로운 뼈를 형성하는 골 형성 전이로 분류되는데, 대개 두 가 지 증상이 혼합되어 있으므로[10] 환자의 골 전이 종류에 따 른 분류 없이 복부 CT 영상을 수집하여 기계학습 알고리즘 개발을 진행하였다.
개발에는 2009년부터 2017년까지 촬영된 277명의 골 전
이 암 환자 CT영상을 사용하였으며, 이 중 전체 환자 수에
서 약 5%를 차지하는 12명의 환자는 인공관절(Artificial
joint) 이나 허리뼈 유합(Lumbar fusion) 수술 등을 받은 환
자로 CT 영상에서 극단적으로 밝은 영역을 생성하게 되어
기계학습에 영향을 줄 수 있으므로 아웃라이어(Outlier)로
323 정의하고 학습에서 제외하였다. 따라서 환자 277명 중 실제
사용한 환자의 수는 265명이다.
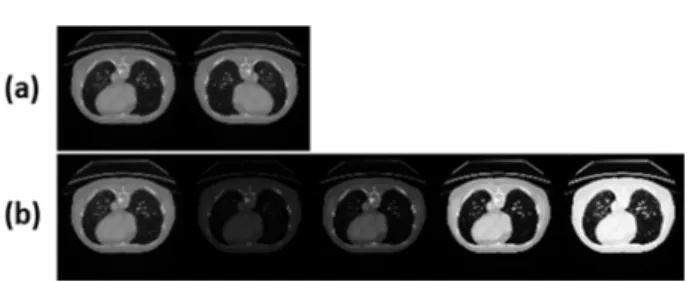
알고리즘 학습을 진행할 때에는 3차원 복부 CT 영상이 아닌 그림 1과 같이 골 전이 암이 존재하는 부위의 2차원 횡단면(Transeverse plane)영상과 의사가 직접 골 전이 암 부분을 표시한 정답 영상(Ground Truth, GT)을 개별 입 력으로 이용하여 265명의 환자로부터 촬영된 총 4838장의 2 차원 영상이 사용되었다. 따라서 환자 1명 당 약 18~19장
의 영상이 사용되었다.
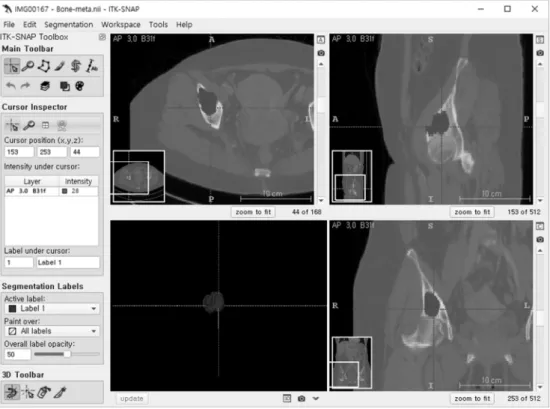
본 연구에서는 골 전이 환자의 3차원 복부 CT 영상 및 영상의학과 전문의가 병변 부위를 판독한 3차원 골 전이 실 측 영상을 이용하였으며, 이를 바탕으로 골 전이 암 검출 알 고리즘 개발을 진행하였다. 임상의가 복부 CT영상을 기반 으로 3차원 골 전이 암 판독 영상을 작성하는 데에는 그림 2 의 프리웨어로 제공되는 ITK-snap[11]을 이용하였다.
알고리즘의 학습과 정확도 확인을 위하여 전체 영상 데이 터에서 기계학습에 이용되는 데이터와 정확도 확인을 위한 데이터를 분리하여 학습하는 Hold out test를 적용하였고 이에 따라 전체 환자 데이터 중 약 10%는 테 학습에서 제 외시키고 나머지 환자의 영상을 학습에 이용하였다. 이 때 학습에 사용된 영상이 238명의 골 전이 암 환자에게서 촬 영된 4547장, 결과 확인에 사용된 테스트 데이터 영상이 27 명의 골 전이 암 환자에게서 촬영된 291장이다.
기계학습에서는 입력의 전처리 단계가 결과에 영향을 미 치기 때문에 원하는 결과를 얻기 위한 특징을 찾아낼 수 있 는 전처리 과정이 중요하게 작용한다. 전처리 과정은 일반 적으로 밝기, 기하학적 형태 등을 변화시켜 적용하게 되는 데 본 연구에서 밝기 조절에 관한 부분은 매우 신중하게 고 려하여 적용하였다. 이는 CT의 특성과 관련이 깊다. CT는 X 선이 특정 물질을 지날 때마다 방사선 밀도가 일정 수준 감쇄되는 성질을 이용하여 개발한 의학 영상 장비이다. 이
그림 1. 기계학습에 이용된 골 전이 암이 존재하는 부위의 횡단면 영상(a)과 골 전이 암이 표시된 정답 이미지(b).
Fig. 1. Bone metastasis site transverse plane image (a) and ground truth (b) from abdominal CT used for machine learning.
그림 2. ITK snap을 이용한 골 전이 암 판독.
Fig. 2. Bone metastasis annotation using ITK snap.
324
방사선 밀도가 감쇄되는 정도는 통과하는 물질에 따라 다른 특징을 보이는데, CT 영상은 증류수의 감쇄도를 0으로, 공 기의 감쇄도를 −1000으로 하여 물질에 따른 감쇄도를 다음
식 (1)과 같은 Hounsfield unit으로 표현한다.
HU
Hounsfield unit= 식 (1)
이 값을 다양한 신체 구성 물질에 대하여 정리한 Houns- field scale 값은 표 1와 같다. 이러한 CT의 특성을 고려하 여 본 연구에서 밝기 조절에 대한 부분을 설계하였다.
2. 뉴럴 네트워크 구조
본 연구에서 개발한 기계학습 알고리즘은 컨볼루션 신경 망(Convolutional Neural Network)을 토대로 개발하였다.
컨볼루션 신경망은 여러 개의 컨볼루션 층과 인공 신경망 층으로 이루어져 입력이 2차원 데이터일 때 적합하며 컨볼 루션과 풀링(Pooling)의 반복으로 구성된다. 컨볼루션 신경망 중 잘 알려진 것들로 AlexNet[12], VGG(Visual Geometry Group)[13], GoogLeNet[14] 등이 있는데, 이 중 16개의 컨볼루션 층과 3개의 완전 연결 층으로 이루어진 컨볼루션 신경망인 VGG19를 이용하였다. 이는 기존에 자연 사진의 분류 연구에 사용되었으며, 완전 컨볼루션 신경망(Fully
1000 µ µ –
waterµ
water– µ
air---
×
표 1. 하운스필드 스케일.Table 1. Hounsfield Scale.
Substance Hounsfield Unit
Air −1000
Lung −500
Fat −100 to −50
Water 0
CSF 15
Kidney 30
Blood 30 to 45
Muscle 10 to 40
Grey matter 37 to 45
White matter 20 to 30
Liver 40 to 60
Soft Tissue, Contrast 100 to 300 Bone 700 (cancellous bone) to
3000 (dense bone)
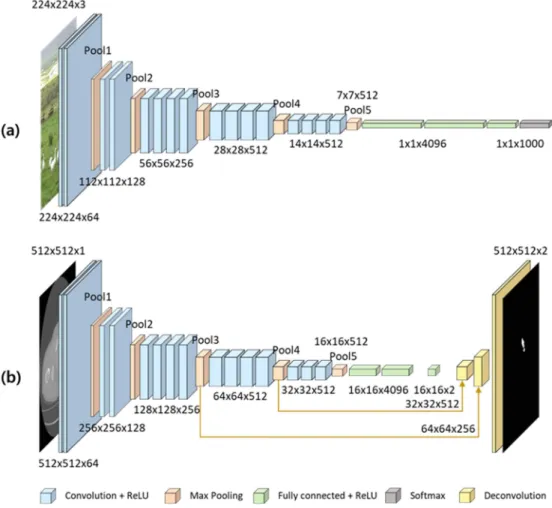
그림 3. VGG19 신경망 모델의 구조(a)와 이를 수정하여 개발한 신경망 모델(b).
Fig. 3. VGG19 Network (a) and modified semantic segmentation network (b).
325 Convolutional Network) 를 구성하여 픽셀단위의 분류 연
구도 이루어지고 있다[6].
본 연구에서는 완전 컨볼루션 신경망을 이용하여 환자의 CT 영상에서 골 전이 암 위치를 분할하여 검출 할 수 있도 록 하였다. 또한 그림 3의 (a)와 같은 VGG19 신경망 모델 의 network surgery를 통해 그림 3의 (b)와 같이 기존 입 력 영상 크기가 224 × 224 × 3인 것을 512 × 512 × 1로 변 경하였고, 15번째 컨볼루션 층까지의 기본 구조를 사용하고 이후로 3개의 컨볼루션 층을 추가하여 학습하였다. 최종단 에는 3층의 디컨볼루션 학습 층을 추가하여 영상의 업샘플 링(Up-sampling)이 이루어지게 하였고 이에 따라 입력 영 상(512 × 512)과 동일한 크기의 확률 분포 출력을 얻었다.
기계학습과정에서 1배치(Batch) 당 2개의 영상을 사용하 였고, 경사하강법(Stochastic gradient descent)에 사용된 최적화 방법으로는 Adam optimizer를 사용하였다[15]. 학 습율은 1e-4로 1e5회 학습 후 1e-5로 변경하여 1e5회를 추 가로 학습해 결과가 최대한 수렴할 수 있도록 하였다.
3. 데이터 불균형 문제 해결 방법 제안 및 적용
본 연구에서 기계학습에 사용된 환자 데이터는 복부 CT 영상이며 이 때 기계학습 알고리즘을 이용하여 구분해야 하 는 골 전이 암의 병변이 전체 복부 CT 영상에서 차지하는 비율은 한 장의 영상 당 평균 약 0.21%로 기계학습 시 모 든 영역을 골 전이 암이 아닌 것으로 판별하게 되는 데이터 의 불균형 문제(Imbalance problem)가 존재한다. 이러한 문제를 해결하기 위하여 본 연구에서는 비용함수(Cost function) 의 변형을 통한 클래스 별 가중치를 적용한 손실 (Loss) 의 연산과 학습에 사용되는 영상의 augmentation 기 법을 사용하였다.
비용함수(Cost function)은 예측한 값과 실제 값의 거리 (Distance) 를 계산하는 함수이며 기계학습에 이용하고자 하 는 입력의 유효한 입력이 n개일 때 학습에 이용되는 정답이 L, 기계학습을 이용하여 예측한 정답을 라고 할 때 거리 D 는 다음의 식 (2)와 같다.
식 (2)
기계학습은 위의 식 (2)의 값(Entropy)이 감소하는 방향 으로 이루어지는데, 이 때 데이터의 불균형 문제를 해결하 기 위하여 각 영상에서 골 전이 암 병변이 차지하는 넓이 (Foreground) 또는 각 영상에서 골 전이 암 병변이 존재하 지 않는 넓이(Background)의 비를 계산하여 비용함수에 곱 해 가중치 손실 함수(Weighted loss function)을 구현하였 다[16].
영상의 augmentation은 영상을 이용한 기계학습에서 효
과를 보이는 방식으로 영상의 상하좌우 반전(Flip), 밝기조 절, 대비조절, 잘라내기(Crop), 픽셀단위 이동(Shift) 등의 방식을 이용하여 총 데이터 개수를 증가시켜 학습하게 한다 [17]. 의학영상의 경우 구조적인 특징이 명확하기 때문에 반 전 등의 사용을 고려할 때 신중하여야 하고, CT 영상의 경 우 위에서 언급한 Hounsfield Scale을 따르기 때문에 밝기 조절에 있어서도 신중하여야 한다. 본 연구에서의 목적은 골 전이 암의 병변부위를 기계학습 알고리즘을 이용하여 찾아 내는 것이고 골격은 좌우 대칭적인(Symmetric)한 특성을 가지기 때문에 기타 장기의 비대칭적인(Asymmetric)한 성 질을 학습에서 고려하지 않아도 된다고 판단되어 기계학습 진행 시 그림 4의 (a)와 같이 임의로 좌우 반전된 영상을 이 용하여 모델을 학습하였다. 또한 밝기를 이용한 augmen- tation 도 진행하였는데, 이 경우 표 1의 Hounsfield scale 을 고려하였다. Hounsfield scale 중 bone은 최소 700으 로 가장 높은 값을 가지고 있고, bone보다 작은 값을 가지 면서 가장 큰 값은 최대 300의 값을 가지는 soft tissue이 므로 밝기를 조절 할 때 두 영역의 값이 같아지지 않도록 ( −200 200)내의 범위에서 밝기를 조절하였고, 본 결과에서 는 그림 4의 (b)와 같이 겹치지 않는 범위의 [−100 −50 0 50 100] 에서 임의로 선택하여 밝기를 조절하여 사용하였다.
위 두가지 augmentation 기법을 이용하여 학습에 사용 된 영상은 총 4547장에서 10배 증가한 45470장과 같게 되 었다.
III. 연구 결과 및 고찰
전체 골 전이 암 환자 265명 중 테스트를 위해 27명의 영 상을 제외하고 학습에 사용한 골 전이 암 환자 238명 중 약 70% 에 해당하는 171명의 골 전이 병변 영상을 이용하여 제 안한 알고리즘의 성능을 분석한 결과 데이터의 augmen- tation 이 이루어지지 않았을 때 픽셀 단위에서 18.75%의 민 감도와 99.97%의 특이도, 99.80%의 정확도를 보였다(표 2). 여기에 좌우 반전과 밝기 조절을 통한 10배의 데이터 augmentation 을 이용한 경우 30.65%의 민감도와 99.95%
의 특이도, 99.81%의 정확도를 보여주었다(표 3). 또한 환 yˆ
D yˆ L ( , ) = – Σ
iL
ilog ( ) yˆ
i그림 4. 좌우반전 이미지(a)와 밝기조절 이미지(b).
Fig. 4. Flipped input (a) and brightness adjusted image (b).
326
자의 수를 늘려 238명의 골 전이 병변 영상을 모두 이용하 였을 때에는 픽셀단위에서 38.62%의 민감도와 99.94%의 특이도, 99.81의 정확도를 보여주었고(표 4), 이 때 학습의 반복(Epoch)에 따른 손실함수의 값과 민감도는 그림 5와 같 이 나타났다. 그림 5의 (b)에서 초기 민감도가 0.5인 것은 학습이 시작될 때 예측 모델의 초기값을 무작위로 생성하기 때문이다. 이후 점차 감소하다가 학습이 진행됨에 따라 다시 상승하는 것을 확인할 수 있다. 기계학습을 이용하여 얻은 골 전이 암 예측 결과는 그림 6과 같다. 얻은 예측 결과 중 픽셀단위로 골 전이 암을 가장 잘 예측한 경우는 99.33%
의 민감도를 보였다.
개발된 알고리즘을 골 전이 암 진단을 위한 스크리닝 도 구로 사용하기 위해 그림 7과 같은 2차원 결과 이미지를 환 자에 따라 3차원 예측 영상과 정답 영상으로 구분하여 식 (3) 과 같이 IoU(Intersection over Union)값을 구하여 비 교하였다.
식 (3)
A
G은 그림 7에서 적색으로 표시된 영역과 황색으로 표시 된 영역의 합으로써 골 전이 암이 존재하는 것으로 임상의 가 진단한 영역(Ground truth)이다. A
P는 그림 7에서 녹 색으로 표시된 영역과 황색으로 표시된 영역의 합으로써 개 발된 기계학습 알고리즘이 골 전이 암이 존재하는 것으로 예측한 영역(Prediction)이며, A
I는 그림 7에서 황색으로 표 시된 영역으로 A
G와 A
P영역이 교차되는 영역(Intersection) 이다. 이 때 골 전이 암 병변 별 IoU 값에 따른 민감도는 그림 8과 같이 나타났으며 이때 IoU가 0 이상일 때 최대
IoU Area of Overlap Area of Union
--- A
IA
G+ A
P– A
I---
= =
표 2. Augmentation을 사용하지 않은 학습의 confusion matrix.
Table 2. Nonaugmented training confusion matrix.
Nonaugmented Training Confusion Matrix
Predicted Class Positive Negative Actual
Class
Positive 35478 153777
Negative 22309 88917396
Sensitivity 18.7461%
Accuracy 99.8024%
Specificity 99.9749%
표 3. Augmentation을 사용한 confusion matrix.
Table 3. Augmented training confusion matrix.
Augmented Training Confusion Matrix
Predicted Class Positive Negative Actual
Class
Positive 58014 37566
Negative 131241 88902139
Sensitivity 30.6539%
Accuracy 99.8106%
Specificity 99.9578%
표 4. 전체 데이터에 Augmentation을 사용한 confusion matrix.
Table 4. Augmented training confusion matrix with whole data.
Augmented Training Confusion Matrix
Predicted Class Positive Negative Actual
Class
Positive 59034 145348
Negative 20242 87855760
Sensitivity 38.6232%
Accuracy 99.8123%
Specificity 99.9449%
그림 6. 테스트용 영상(b)을 학습된 모델에 입력하였을 때의 출력 영 상(c)과 정답 영상(a).
Fig. 6. The prediction image (c) and the Ground truth (a) when the (b) is original test set image.
그림 5. 학습 횟수(Epoch)에 따른 손실함수값(a)과 픽셀단위에서의 민감도 그래프(b).
Fig. 5. The graph of train loss (a) and pixel-wise sensitivity of the test image for each epoch.
327
민감도는 88.89%로 나타났으며, 병변이 아닌 영역을 병변 으로 판별한 사례는 전체 병변 수의 50%였다.
본 연구에서 개발된 기계학습 알고리즘 학습에 사용한 골 전이 암 영상은 총 238명의 환자로부터 수집된 복부 CT 영 상에서 골 전이 암이 존재하는 영상 4547장이다. 이는 복 부 CT 한 장이 약 149장이고 이 범위에 포함되는 골격이 대퇴골, 무명골, 미골, 천골, 요추, 흉추, 늑골에 이르는 것 을 고려할 때 결코 충분하지 않은 데이터이다. 또한 전체 영 상에서 검출하고자 하는 병변 부위가 차지하는 비율이 픽셀 단위에서 0.21%로 만일 민감도가 0%로 수렴하여 영상의 모 든 부분이 병변이 아니라고 판별하더라도 99.79%의 정확도
를 도출 할 수 있음에도 픽셀 단위 민감도가 38.62%로 학 습된 데에는 비용함수에 비율에 따른 가중치를 적용한 것이 유효하였던 것으로 분석하였다.
알고리즘 성능 평가 단계에서 사람이 3차원 영상을 트레 이싱 하며 골 전이 암 병변 부위를 판독하였기 때문에 발생 하는 문제점과 특이사항을 확인하였다. 먼저 그림 9와 같이 잘못 판별된 정답 영상들을 확인할 수 있었는데, 이는 골 전
그림 8. 골 전이 암 병변 별 IoU 값에 따른 민감도.Fig. 8. Bone metastases legion-wise sensitivity according to IoU value.
그림 7. 개발된 알고리즘 테스트에 사용된 영상(a)과 그 영상으로부 터 예측된 결과와 정답 비교(b).
Fig. 7. Image used in the developed algorithm test (a) and the comparison between the predicted result and the ground truth (b).
그림 11. 입력 영상 (a), 판별 영상과 정답 간 비교 영상 (b), 재 판별 한 골 전이암의 위치(c).
Fig. 11. The input image (a), comparison image of prediction and ground truth (b) and re-identified bone metastasis legion.
그림 10. 골전이암으로 판별된 정답 영상 (a), 입력 영상 (b), 학습된 모델의 예측 영상 (c).
Fig. 10. Ground tru.th (a), input image (b) and predicted output (c).
그림 9. 골 전이 암 판별 중 잘못 판별된 영상(a), 잘못 판별된 부분 을 확대한 영상(b).
Fig. 9. Incorrectly identified image of bone metastasis (a) and magnified image of misidentified part (b).
328
이 암 영상을 사람이 판별하여 정답 영상을 작성하는 과정 에서 발생한 오류로 학습 영상 자료와 성능 평가 영상 자료 에서 이러한 정답 영상의 오류를 확인하여 보완하는 것이 전체 알고리즘의 성능 향상에 도움이 될 것으로 보인다.
또한 기계학습 시 3차원 영상을 트레이싱 하며 판별한 정 답 영상을 이용하여 학습하였는데, 이러한 경우 사람이 3차 원 영상을 확인할 때에는 그림 10의 (a)와 같이 정답 영상 을 판독할 수 있지만 그림 10의 (b) 2차원 영상만이 주어 졌을 때에는 그림 10의 (c)의 예측 영상과 같이 골 전이 암 을 판별하더라도 구분할 수 없는 현실적인 문제가 발생한다.
따라서 후속 연구에서는 한 환자의 3차원 CT 영상을 한꺼 번에 입력으로 사용하는 기계학습 알고리즘을 개발하여 병 변 부위의 검출 민감도를 향상하는 것이 필요할 것이다.
또한 정밀도가 평균 이하인 판별 영상 중 그림 11과 같 은 영상도 확인할 수 있었는데, 그림 11의 (b)에서 알고리 즘을 이용하여 골 전이 암으로 검출되었지만 정답 영상에 판별되어 있지 않았던 초록색 영역이 검출된 영역이 육안으 로 볼 때 골 전이 암 영역으로 판별되어 임상의의 재 판독 결과 그림 11의 (c) 영역에 골 전이 암이 존재하는 것으로 확인하였고, 초기 판독에서 누락된 골 전이 암 병변 부위인 것으로 결론지었다. 이는 개발한 알고리즘의 성능을 보여 줄 수 있는 좋은 사례이다.
IV. 결 론
본 논문에서는 다양한 원발암에서 뼈로 전이된 경우의 환 자 265명의 컴퓨터단층촬영 영상을 이용하여 전이된 암의 병변 부위를 픽셀 단위로 찾아내는 연구를 진행하였다. 2차 원 완전 컨볼루션 신경망(Fully Convolutional Network) 에 환자의 CT 영상과 영상의학과 전문의가 병변부위로 판 독한 실측 영상을 입력으로 사용하였으며, 데이터의 부족을 극복하기 위하여 영상의 밝기를 조절하고 좌우를 뒤집어 학 습하였다. 전체 데이터의 10%를 평가 데이터로 구분하여 90% 의 데이터를 기계학습에 이용하였고, augmentation 기 법을 통해 실질적으로 학습에 사용된 데이터의 총 수를 10 배 증가시켰다. 평가 데이터로 개발한 알고리즘을 테스트 한 결과는 픽셀 단위에서 평균 38.62%의 민감도와 99.94%의 특이도, 99.81%의 정확도를 보여주었다.
위 알고리즘을 이용해 각 환자에서 골 전이 암 병변 영역 을 검출해 내는 최대 민감도를 IoU 값에 따라 확인했을 때 최대 88.89%로 나타났다. 이때 병변이 아닌 영역을 병변으로 판별한 건당 오검출 사례(False alarm per case)는 0.5건 이 었다.
본 연구의 결과는 픽셀 단위에서 38.62%의 민감도를 가 지고 있지만 실제 병변 별 검출 민감도는 88.89%로 나타
났다. 하지만 임상의의 진단을 대신 하기 위해서는 오검출 사례가 존재하더라도 민감도가 100%에 도달해야 하기 때 문에 여전히 진단의를 대신 할 수 있는 수준에 이르지 못한 것으로 분석된다. 결과에서 나타난 진단 민감도와 임상의의 진단에서 누락된 병변을 찾아낸 사례를 바탕으로 볼 때, 임 상의의 진단 전후에 스크리닝 도구로 활용하여 환자 진단에 도움이 될 것으로 보인다.
참고문헌
[1] R. E. Coleman, “Clinical features of metastatic bone disease and risk of skeletal morbidity,” Clin. Cancer Res., vol. 12, no. 20, pp. 6243-6249, 2006.
[2] A. Krizhevsky, I. Sutskever and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Adv.
Neural Inf. Process. Syst., pp. 1097-1105, 2012.
[3] J. Long, E. Shelhamer, and T. Darrell. “Fully convolutional networks for semantic segmentation,” in Proc. the IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2015, pp. 3431-3440.
[4] F. Schroff, D. Kalenichenko, & J. Philbin, “Facenet: A uni- fied embedding for face recognition and clustering,” in Proc.
the IEEE conference on computer vision and pattern recog- nition, Jun. 2015, pp. 815-823.
[5] G. Litjens, T. Kooi, B.E. Bejnordi, A.A.A. Setio, F. Ciompi, M. Ghafoorian, ... & C. I. Sánchez, “A survey on deep learn- ing in medical image analysis,” arXiv preprint arXiv 1702.05747, 2017.
[6] P. Moeskops, M.A. Viergever, A.M. Mendrik, L.S. de Vries, M.J.Benders, & I. Išgum, “Automatic segmentation of MR brain images with a convolutional neural network,” IEEE Trans Med Imaging, vol. 35, no. 5, pp. 1252-1261, 2016.
[5] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Angue- lov, ... and A. Rabinovich, “Going deeper with convolu- tions,” in Proc. the IEEE conference on computer vision and pattern recognition, Jun. 2015, pp. 1-9.
[6] J. Long, E. Shelhamer, and T. Darrell. “Fully convolutional networks for semantic segmentation,” in Proc. the IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2015, pp. 3431-3440.
[7] J. Kuruvilla, & K. Gunavathi, “Lung cancer classification using neural networks for CT images,” Comput Methods Programs Biomed., vol. 113, no. 1, pp. 202-209, 2014.
[8] P. Teare, M. Fishman, O. Benzaquen, E. Toledano, & E.
Elnekave, “Malignancy Detection on Mammography Using Dual Deep Convolutional Neural Networks and Genetically Discovered False Color Input Enhancement,” J Digit Imag- ing., vol. 30, no. 4, pp. 499-505, 2017.
[9] H. R. Roth, J. Yao, L. Lu, J. Stieger, J. E. Burns, & R. M.
Summers, “Detection of sclerotic spine metastases via ran- dom aggregation of deep convolutional neural network clas- sifications,” arXiv preprint arXiv 1407.5976, 2014.
[10] L. J. Suva, C. Washam, R. W. Nicholas and R. J. Griffin.
“Bone metastasis: mechanisms and therapeutic opportuni- ties,” Nat Rev. Endocrinol., vol. 7, no. 4, pp. 208-218, 2011.
[11] http://www.itksnap.org , accessed on Nov. 13, 2017.
[12] A. Krizhevsky, I. Sutskever and G. E. Hinton, “Imagenet
329
classification with deep convolutional neural networks,” Adv.Neural Inf. Process. Syst., pp. 1097-1105, 2012.
[13] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv 1409.1556, 2014.
[14] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Angue- lov, ... and A. Rabinovich, “Going deeper with convolu- tions,” in Proc. the IEEE conference on computer vision and pattern recognition, Jun. 2015, pp. 1-9.
[15] D. Kingma, & J. Ba, “Adam: A method for stochastic opti-
mization,” arXiv preprint arXiv 1412.6980, 2014.
[16] D. Eigen, R. Fergus, Eigen, D. and R. Fergus, “Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture,” in Proc. the IEEE International Conference on Computer Vision, Dec. 2015, pp. 2650-2658.
[17] Howard, A. G. (2013). “Some improvements on deep convo- lutional neural network based image classification,” arXiv preprint arXiv 1312.5402, 2013.