Reliability estimation and ratio distribution in two independent Pareto-Pareto and power function †
Changsoo Lee 1 · Kyungsu Ahn 2
12 Department of Flight Operation, Kyungwoon University
Received 10 March 2020, revised 26 March 2020, accepted 3 April 2020
Abstract
We consider reliability estimations in two independent Pareto random variables hav- ing different scale parameter, and two independent Pareto and Power function random variables. And then we compare mean squared errors of two reliability estimators for each case. We consider the distribution for the ratio based on two independent Pareto random variables having different scale parameter, and two independent Pareto and Power function random variables respectively. And we observe the skewness for the ratio and study numerically trends for the skewness for the ratio based on two inde- pendent Pareto random variables having different scale parameter and two independent Pareto and Power function random variables.
Keywords: Hypergeometric function, Pareto distribution, Power function distribution, reliability, skewness.
1. Introdunction
An example of some beginning importance is the use of an exponential distribution with a threshold parameter to apply life times of lights and machines.
For independent random variables X and Y , and a real number c, the probability P (X <
c · Y ) is as given in Woo (2006): (i) it is reliability when c = 1, (ii) it is the distribution of the ratio X/(X + Y ) when c = t/(1 − t) for 0 < t < 1.
The reliability will increase the need for the industry to perform the systematic study for identifications and the reduction of causes of failures. These reliability studies must be performed by persons who (a) can identify and quantify the modes of failures, (b) know how to obtain and analyze the statistics of failure occurrences, and (c) can construct math- ematical models of the failure that depend on, for example, the parameters of the material strength or the design quality, the fatigue or the wear resistance, and the stochastic nature of the anticipated duty cycle in Saunders (2007). Ali and Woo (2005) studied the reliability in a power function distribution. Moon and Lee (2009) studied the reliability in the gamma
† This research is supported by 2020 Kyungwoon University Research Fund.
1
Corresponding Author : Associate professor, Department of Flight Operation, Kyungwoon University, Gumi 730-850, Korea. E-mail: [email protected]
2
Assistant professor, Department of Flight Operation, Kyungwoon University, Gumi 730-850, Korea.
case. Lee et al. (2010) studied reliability estimations and the density function of the ratio in right truncated Rayleigh distributions. Ali et al. (2010) studied estimations of the reliability P (Y < X) when X and Y belong to different distribution families, and Yoon and Lee (2012) studied reliability estimations and the distribution of the ratio in two independent variables with different distributions. Zaka and Akhter (2014) considered the modified moment, the maximum likelihood and percentile estimators for the parameters of the Power function distribution.
We consider reliability estimations in two independent Pareto random variables having dif- ferent scale parameters, and two independent Pareto and Power function random variables.
And then we compare mean squared errors of two reliability estimators for each case. We consider the distribution for the ratio based on two independent Pareto random variables having different scale parameter, and two independent Pareto and Power function random variables, respectively. And we observe the skewness for the ratio and study numerically trends for the skewness for the ratio based on two independent Pareto random variables having different scale parameter and two independent Pareto and Power function random variables
2. Pareto distribution
2.1. Estimating reliability
Let X and Y be two independent Pareto random variables each having the density function (2.1) with different scale parameters β 1 and β 2 and known parameter α, respectively:
f X (x) = αβ 1 α /x α+1 , x > β 1 > 0, α(> 0) and
f Y (y) = αβ 2 α /y α+1 , y > β 2 > 0, α(> 0). (2.1) In this section, we consider the case for the estimation of P (Y < X) when (X, Y ) is a pair of two independent Pareto random variables. As an application of this case, X and Y are representing two kinds of the income and the consumption in the economy.
Now, we consider the reliability R(ρ) = P (Y < X) as following:
Proposition 2.1 Let X and Y be independent Pareto random variables each having the density function (2.1) with different scale parameters β 1 and β 2 and known parameter α, respectively. Then
(a) The reliability R(ρ) =
( ρ α /2, if 0 < ρ < 1,
1 − ρ −α /2, if ρ ≥ 1 , where ρ = β 1 /β 2 .
(b) The reliability R(ρ) is a monotone increasing function of ρ.
Proof
(a) For β 1 < β 2 , R(ρ) = P (Y < X) = R ∞
β
2P (Y < x)f X (x)dx = 1 2 (β 1 /β 2 ) α . And also, for β 1 > β 2 , R(ρ) = R ∞
β
1P (Y < x)f X (x)dx = 1 − 1 2 (β 2 /β 1 ) α .
(b) Since dρ d R(ρ) > 0, R(ρ) is a monotone increasing function of ρ.
Since the reliability R(ρ) is a monotone function of ρ, the inference on R(ρ) is equivalent to the inference on ρ (McCool, 1991). Therefore, it is sufficient for us to consider the estimation of ρ instead of estimating R(ρ).
Assume X 1 , · · · , X n and Y 1 , · · · , Y m be independent random samples from the density function (2.1) each having different scale β 1 and β 2 , respectively. Then well-known estimators of β 1 and β 2 are given in Johnson et al. (1974) as follows:
β ˆ 1 = X (1;n) = X (1) and ˆ β 2 = Y (1;m) = Y (1) . (2.2) From (2.2), the MLE of ρ is
ˆ
ρ = X (1) /Y (1) . (2.3)
The following density functions are well-known in Rohatgi (1976) as:
f X
(1)(x) = nαβ 1 nα x −nα−1 , x > β 1
and
f Y
(1)(y) = mαβ mα 2 y −mα−1 , y > β 2 . (2.4) From the results (2.4), and formula 3.381(3) in Gradshteyn and Ryzhik (1965), we can obtain the expectation and the variance for the MLE ˆ ρ of ρ = β 1 /β 2 ;
E( ˆ ρ) = nmα 2
(nα − 1)(mα + 1) · ρ and
V ar( ˆ ρ) = [ nmα 2
(nα − 2)(mα + 2) − n 2 m 2 α 4
(nα − 1) 2 (mα + 1) 2 ]ρ 2 , nα > 2. (2.5) From the expectation in (2.5), an unbiased estimator ˜ ρ of ρ is given as:
˜
ρ = (nα − 1)(mα + 1) nmα 2 · X (1)
Y (1) ,
which it has the variance as follows:
V ar( ˜ ρ) = [ (nα − 1) 2 (mα + 1) 2
nmα 2 (nα − 2)(mα + 2) − 1]ρ 2 , nα > 2. (2.6) From the results (2.5) and (2.6), we can obtain mean squared errors(MSE‘s) of the MLE ˆ
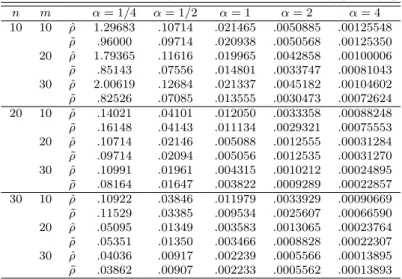
ρ and an unbiased estimator ˜ ρ for ρ ≡ β 1 /β 2 as given in Table 2.1.
Table 2.1 MSE‘s of the MLE ˆ ρ and an unbiased estimator ˜ ρ (units: ρ
2)
n m α = 1/4 α = 1/2 α = 1 α = 2 α = 4
10 10 ρ ˆ 1.29683 .10714 .021465 .0050885 .00125548
˜
ρ .96000 .09714 .020938 .0050568 .00125350 20 ρ ˆ 1.79365 .11616 .019965 .0042858 .00100006
˜
ρ .85143 .07556 .014801 .0033747 .00081043 30 ρ ˆ 2.00619 .12684 .021337 .0045182 .00104602
˜
ρ .82526 .07085 .013555 .0030473 .00072624 20 10 ρ ˆ .14021 .04101 .012050 .0033358 .00088248
˜
ρ .16148 .04143 .011134 .0029321 .00075553 20 ρ ˆ .10714 .02146 .005088 .0012555 .00031284
˜
ρ .09714 .02094 .005056 .0012535 .00031270 30 ρ ˆ .10991 .01961 .004315 .0010212 .00024895
˜
ρ .08164 .01647 .003822 .0009289 .00022857 30 10 ρ ˆ .10922 .03846 .011979 .0033929 .00090669
˜
ρ .11529 .03385 .009534 .0025607 .00066590 20 ρ ˆ .05095 .01349 .003583 .0013065 .00023764
˜
ρ .05351 .01350 .003466 .0008828 .00022307 30 ρ ˆ .04036 .00917 .002239 .0005566 .00013895
˜
ρ .03862 .00907 .002233 .0005562 .00013893
As Table 2.1 is observed, because the inference on R(ρ) is equivalent to the inference on ρ in McCool (1991), we obtain the following:
Fact 2.1 Assume X 1 , ·, X n and Y 1 , · · · , Y m be independent random samples from the density function (2.1) each having different scales β 1 and β 2 and known parameter α, re- spectively. Then for ρ ≡ β 1 /β 2 ,
(a) when α = 1, 2 and 4, an estimator R( ˜ ρ) of the reliability R(ρ) = P (Y < X) performs better than the MLE R( ˆ ρ) in the sense of MSE.
(b) when α = 1/2 and 1/4, two estimators can not dominate each other in the sense of MSE.
From the result (b) in Fact 2.1, because the MLE and an unbiased estimator for ρ can not dominate each other in the sense of MSE, a bias estimator ¯ ρ having minimum MSE‘s among {s · X (1) /Y (1) |s > 0} is recommended as the following:
If there exists satisfying min s>0 E[(s · X Y
(1)(1)
− ρ) 2 ] = E[(s 0 · X Y
(1)(1)
− ρ) 2 ], then from the expectation and the variance of ˆ ρ in (2.5),
s 0 = (nα − 2)(mα + 2)
(nα − 1)(mα + 1) if nα > 2.
Therefore, ¯ ρ = (nα−2)(mα+2) (nα−1)(mα+1) · X Y
(1)(1)
has the minimum MSE among a family n s · X Y
(1)(1)
|s > 0 o . And then, because the inference on R(ρ) is equivalent to the inference on ρ in McCool (1991), we can obtain the following:
Corollary 2.1 Under the same conditions of Fact 2.1, the reliability estimator R( ¯ ρ) performs better than other two estimators R( ˆ ρ) and R( ˜ ρ) in the sense of MSE regardless of α−values.
Now, we consider an interval estimation of ρ = β 1 /β 2 .
From the quotient density in Rohatgi (1976), the density function of a pivot quantity P ≡ ρ · Y (1) /X (1) is derived as:
f P (x) = ( mnα
(m+n) x nα−1 , 0 < x < 1,
mnα
(m+n) x −mα−1 , x ≥ 1.
And then for given p i ≥ 0 (i = 1, 2) with 0 < 1 − p 1 − p 2 < 1,
([p 1 (1 + n/m)] 1/(nα) · X (1) /Y (1) , [p 2 (1 + m/n)] −1/(mα) · X (1) /Y (1) ) is an (1 − p 1 − p 2 )100% conservative confidence interval for ρ = β 1 /β 2 .
2.2. Distribution of the ratio
In this section, we consider the ratio R X = X/(X + Y ), when X and Y are independent Pareto random variables each having density function (2.1) with different parameters β 1 and β 2 anf known parameter α, respectively. First, from the quotient density in Rohatgi (1976) and the integration, we can derive the quotient density Q = Y /X as follows: For ρ = β 1 /β 2 ,
f Q (x) = ( α
2 ρ −α x −α−1 , if x ≥ ρ −1 ,
α
2 ρ α x α−1 , if 0 < x < ρ −1 . (2.7) From the quotient density function (2.7), we can derive the density function of the ratio R X = X/(X + Y ) as follows:
f R
X(r) = ( α
2 ρ −α r α−1 /(1 − r) α+1 , if 0 < r ≤ ρ/(1 + ρ),
α
2 ρ α (1 − r) α−1 /r α+1 , if ρ/(1 + ρ) < r < 1. (2.8) From the result (2.8) and formula 3.194 (1) in Gradshteyn and Ryzhik (1965), we can obtain k−th moments of the ratio R X as follows:
For k = 1, 2, · · · ,
E(R k X ) = 1
2 2 F 1 (k, α; α + 1; ‘ − 1/ρ) + α
2(k + α) ρ k 2 F 1 (k, k + α; k + α + 1; −ρ), (2.9)
where 2 F 1 (a, b; c; x) is the hypergeometric function.
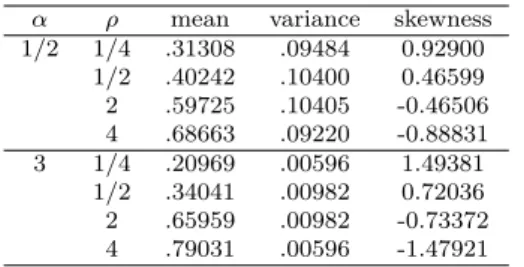
Based on k−th moments of the ratio R X , and by recursion formulas 15.2.13 and 15.2.25 of the hypergeometric function and formula 15.1.8 in Abramowitz and Stegun (1970), we can obtain means, variances and coefficients of the skewness as given in Table 2.2.
Table 2.2 Mean, variance and coefficient of skewness for the density (2.8) α ρ mean variance skewness
1/2 1/4 .31308 .09484 0.92900 1/2 .40242 .10400 0.46599 2 .59725 .10405 -0.46506 4 .68663 .09220 -0.88831 3 1/4 .20969 .00596 1.49381 1/2 .34041 .00982 0.72036 2 .65959 .00982 -0.73372 4 .79031 .00596 -1.47921
From Table 2.2, we can observe the following trends:
Fact 2.2 When X and Y are independent Pareto random variables each having density function (2.1) with different parameters β 1 and β 2 and known parameter α, respectively.
For α = 1/2 and 3, the density function of the ratio R X = X/(X + Y ) is right skewed when ρ = β 1 /β 2 = 1/4 and 1/2, but it is left skewed when ρ = 2 and 4.
3. Pareto and power function distributions
3.1. Estimating reliability
Assume X and Y be two independent Pareto random variable having density function (2.1) with unknown parameter β and known parameter α and a Power function random variable having density function (3.1) with θ(> β) and known δ(6= α) > 0, respectively.
f Y (y) = (δ/θ δ )y δ−1 , 0 < y < θ, δ > 0, (3.1) As the consideration of Ali et al. (2010), we consider the case for estimations of the reliability P (Y < X) when (X, Y ) is a pair of Pareto and Power function random variables, respectively. As an application of this case Y , representing time to sustain a proper level of the radioactivity, is a Power function random variable and X, representing keeping up the time of a white rat from its beginning time which is exposed to the radioactivity, is a Pareto random variable in Saunders (2007).
Now, we consider the reliability R(η) = P (Y < X) as following:
Proposition 3.1 Assume X and Y be two independent Pareto random variable having density function (2.1) with β > 0 and known α > 0 and a Power function random variable having density function (3.1) with θ(> β) and known δ(6= α) > 0, respectively. Then
(a) the reliability R(η) = δ−α δ η α − δ−α α η δ , η ≡ β/θ < 1, α 6= δ.
(b) the reliability R(η) is a monotone decreasing function of η.
Proof
(a) R(η) = P (Y < X) = Z ∞
β
P (Y < x)f X (x)dx
= Z θ
β
P (Y < X)f X (x)dx + Z ∞
θ
f X (x)dx = α
δ − α [(β/θ) α − (β/θ) δ ] + (β/θ) α . (b) Since dη d R(η) = δ−α δα (η α−1 − η δ−1 ) < 0 for 0 < η < 1, and hence we have done.
Since the reliability R(η) is a monotone function of η, the inference on R(η) is equivalent to the inference on η (McCool, 1991). Therefore, it is sufficient for us to consider estimations of η instead of estimating R(η).
Assume X 1 , · · · , X n and Y 1 , · · · , Y m be independent random samples from the density function (2.1) with β > 0 and known α > 0 and a Power function random variable having density function (3.1) with θ(> β) and known δ(6= α) > 0, respectively.
Then for known α and δ, the following well-known estimators of β and θ are given in Johnson et al. (1974) as:
β = X ˆ (1;n) = X (1) and ˆ θ = Y (m;m) = Y (m) . (3.2) From the result (3.2), a MLE ˆ η of η is given by:
ˆ
η = ˆ β/ˆ θ = X (1) /Y (m) . (3.3)
From the density function of X (1) in (2.4) and the density function of Y (m) as the following
f Y
(m)(x) = (mδ/θ mδ )x mδ−1 , 0 < x < θ, we can obtain the expectation and variance the a MLE ˆ η of η as follows:
E(ˆ η) = nmαδ
(nα − 1)(mδ − 1) · η and
V ar(ˆ η) = [ nmαδ
(nα − 2)(mδ − 2) − n 2 m 2 α 2 δ 2
(nα − 1) 2 (mδ − 1) 2 ]η 2 , mδ > 2, nα > 2. (3.4) From the expectation in (3.4), an unbiased estimator ˜ η of η is given as:
˜
η = (nα − 1)(mδ − 1)
nmαδ · X (1) /Y (m) ,
which it has the variance as follows:
V ar(˜ η) = [ (nα − 1) 2 (mδ − 1) 2
nmαδ(nα − 2)(mδ − 2) − 1]η 2 , mδ > 2, nα > 2. (3.5)
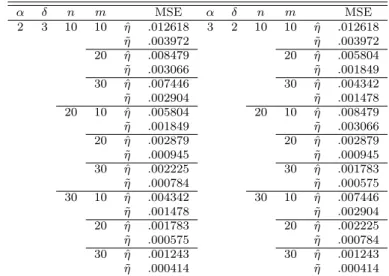
Table 3.1 MSE‘s of a MLE ˆ η and an unbiased estimator ˜ η (units: η
2)
α δ n m MSE α δ n m MSE
2 3 10 10 η ˆ .012618 3 2 10 10 η ˆ .012618
˜
η .003972 η ˜ .003972
20 η ˆ .008479 20 η ˆ .005804
˜
η .003066 η ˜ .001849
30 η ˆ .007446 30 η ˆ .004342
˜
η .002904 η ˜ .001478
20 10 η ˆ .005804 20 10 η ˆ .008479
˜
η .001849 η ˜ .003066
20 η ˆ .002879 20 η ˆ .002879
˜
η .000945 η ˜ .000945
30 η ˆ .002225 30 η ˆ .001783
˜
η .000784 η ˜ .000575
30 10 η ˆ .004342 30 10 η ˆ .007446
˜
η .001478 η ˜ .002904
20 η ˆ .001783 20 η ˆ .002225
˜
η .000575 η ˜ .000784
30 η ˆ .001243 30 η ˆ .001243
˜
η .000414 η ˜ .000414
From the results (3.4) and (3.5), we can obtain mean squared errors (MSE‘s) of the ML estimator and an unbiased estimator ˜ η of η as given in Table 3.1.
As Table 3.1 is observed, because inference on R(η) is equivalent to inference on η in McCool (1991), we obtain the following:
Fact 3.1 Assume X 1 , · · · , X n and Y 1 , · · · , Y m be independent random samples from the density function (2.1) with β > 0 and known α > 0 and a Power function random variable having density function (3.1) with θ(> β) and known δ(6= α) > 0, respectively.
Then for η = β/θ < 1, an estimator R(˜ η) of the reliability R(η) = P (Y < X) performs better than a MLE R(ˆ η) in the sense of MSE only when (α, δ) = (2, 3) and (3, 2).
By similar manner as like Corollary 2.1 in Section 2, we can obtain the following bias estimator ¯ η of η = β/θ: For nα > 2 and mδ > 2,
¯
η = (nα − 2)(mδ − 2) (nα − 1)(mδ − 1) · X (1)
Y (m) has a minimum MSE among a family {s · X Y
(1)(m)