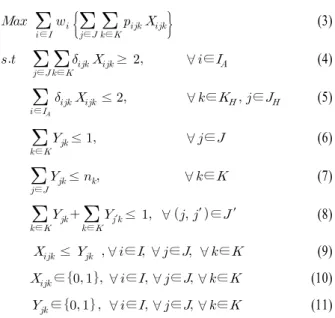Journal of the Korean Institute of Industrial Engineers http://dx.doi.org/10.7232/JKIIE.2015.41.4.396
Vol. 41, No. 4, pp. 396-407, August 2015. © 2015 KIIE
ISSN 1225-0988 | EISSN 2234-6457 <Application Research>
MGIS 및 유전자 알고리즘을 활용한 정보자산 최적배치에 관한 연구
김영화1․김수환2†
1육군정보학교 / 2국방대학교 운영분석학과
A Study on the Optimal Allocation for Intelligence Assets Using MGIS and Genetic Algorithm
Younghwa Kim1․Suhwan Kim2
1Army Intelligence School / 2Department of Operations Research, Korea National Defense University The literature about intelligence assets allocation focused on mainly single or partial assets such as TOD and GSR. Thus, it is limited in application to the actual environment of operating various assets. In addition, field units have generally vulnerabilities because of depending on qualitative analysis. Therefore, we need a methodology to ensure the validity and reliability of intelligence asset allocation. In this study, detection probability was generated using digital geospatial data in MGIS (Military Geographic Information System) and simulation logic of BCTP (Battle Commander Training Programs) in the R.O.K army. Then, the optimal allocation mathematical model applied concept of simultaneous integrated management, which was developed based on the partial set covering model. Also, the proposed GA (Genetic Algorithm) provided superior results compared to the mathematical model. Consequently, this study will support effectively decision making by the commander by offering the best alternatives for optimal allocation within a reasonable time.
†
Keywords: Genetic Algorithm(GA), Geographic Information System(GIS), Partial set covering problem
1. 서 론
1991년 걸프전 이후 세계 각지의 전투에서는 무인항공기(UAV, Unmanned Aerial Vehicle), 군사 위성 등과 같은 최첨단 정보자 산이 등장하고 있다. 이는 과거와 현재를 막론하고 전투에서 정보기능의 역할이 전투의 승패에 있어 무엇보다도 중요한 요 인으로 작용하기 때문이다. 전장에서 정보기능의 역할은 크게 정보(Intelligence)와 대정보(Counter Intelligence)로 분류할 수 있다. 특히, 정보 수집은 가용한 모든 출처 및 수집수단을 통해 적 및 작전환경에 관한 첩보를 획득하여 정보부서 및 기관에 보고하는 활동이다. 전투수행 전 단계에 걸쳐 적, 지형, 기상에 관한 정보를 지속적으로 제공하여 전장을 가시화함으로써 지
휘관의 상황인식 및 상황평가에 결정적으로 기여한다. 따라서 전투수행제대별 한정된 정보자산을 효과적으로 배치⋅운용 하여 전투에 결정적인 정보수집이 이루어져야 한다. 자산 배 치시 다양한 고려요소가 있겠지만 지형의 영향이 가장 크게 작용하기 때문에 정확한 지형분석을 통한 자산 배치는 필수 조건이다.
최근 들어, 감지기(Sensor) 및 광학장비, 인공위성 등을 활용 한 지형정보는 기존의 수준을 초월하여 다양성과 정확성을 두 루 겸비한 ‘질(質)’ 높은 지형정보 제공을 가능하게 하고 있다.
이러한 시대적 흐름에 발맞추어 우리 군에서도 ‘장차전 환경 에 적합한 지리공간정보 구축’을 목표로 2011년도에 국방지형 정보단(KDGA, Korea Defense Geospatial-Intelligence Agency)
제10회 석사논문경진대회 수상논문.
†연락저자:김수환 교수, 412-170 경기도 고양시 덕양구 제2자유로 33 국방대학교 운영분석학과, Tel : 02-300-2174, Fax : 02-309-8118, E-mail : [email protected]
2015년 2월 9일 접수; 2015년 5월 29일 수정본 접수; 2015년 6월 9일 게재 확정.
MGIS 및 유전자 알고리즘을 활용한 정보자산 최적배치에 관한 연구 397
을 창설하였다. 이와 더불어 MGIS 사업을 통해 사용자(부대) 요청에 따른 각종 지형분석 자료를 제공할 뿐만 아니라 공간상 에 분포하는 지리자료(Geographic Data) 및 속성자료(Attribute Data)를 통합 처리하고 압축하여 의사결정을 보조하는 군사지 리정보체계(MGIS, Military Geographic Information System)가 구축되었다. 이로써 신뢰성 높은 지형정보 제공이 가능하게 되 었다.
지금까지의 정보자산 최적배치에 대한 연구는 단일 자산 또 는 동일 유형의 자산만을 고려한 연구로 다양한 유형의 정보 자산을 보유하고 있는 실제 통합운용환경에 적용하기 제한된 다. 따라서 실제 운용환경의 다양한 유형의 정보자산을 포함 하며, 육군의 동시통합운용개념이 적용된 연구가 필요하다.
한편, 상급부대를 제외한 야전부대에서 정보자산의 배치⋅
운용은 등고선, 지형지물 등의 단순한 지형요소로 제작된 군 사종이지도를 활용하고 담당자의 경험과 능력에 의존하고 있 는 실정이다. 따라서 담당자의 수준에 의해서 발생하는 차이 는 객관성 및 타당성 측면에서 취약성을 내포하고 있다. 또한 군사종이지도의 지형요소를 활용한 정성적인 분석방법은 지 형의 다양한 특성과 정량적인 지형적 요소를 반영하기 제한되 기 때문에 정확성 측면에서 떨어질 수 있다. 이러한 이유로 효 과적인 전장 가시화를 위해서 정보자산의 동시통합운용 개념 을 고려하고 자산 배치⋅운용의 객관성과 신뢰성을 향상 시킬 수 있는 정보자산 배치방법이 필요하다.
따라서 본 연구의 목적은 정량화된 지형정보를 활용하고 가 용한 정보자산의 동시통합운용 개념을 고려한 최적배치 모형 개발을 통해 정보자산 배치⋅운용의 정확성과 타당성을 향상 시키고 합리적인 시간 내에 지휘관의 의사결정을 지원하는 것 이다. 이를 위해 MGIS의 디지털 지형공간 자료와 상용 소프트 웨어(Arc GIS 10.1)를 활용하여 정보자산별 탐지능력에 따라 가시선과 탐지거리를 분석하였다. 이어서 창조21(육군 전투지 휘훈련 모델)의 모의 논리를 적용하여 거리에 따른 탐지확률 을 산출하였으며, 이를 탐지지역의 은폐확률과 합성하여 최종 탐지확률을 생성하여 최적배치 수리모형의 입력 자료로 활용 하였다. 정보자산 최적배치 수리모형은 부분지역담당(Partial Set Covering) 모형을 기반으로 수립하였다. 또한 동시통합운 용 개념을 충족시키고 가용한 모든 정보자산의 종류와 가용수량, 중요감시지역(NAI, Named Area of Interest) 및 관심타격지역 (TAI, Target Area of Interest)의 중복탐지를 주요 제약조건으로 작전지역의 탐지확률 합을 최대화하도록 모형을 설계하였다.
일반적으로 지역담당문제(Set Covering Problem)는 NP-Com- plete 문제로 알려져 있기 때문에 최적해를 확인하기 위해서는 상당한 계산노력이 필요하다. 또한 문제의 규모가 증가할수록 계산시간은 급격히 증가한다. 특히, 현실 문제를 적용한 모형 은 더욱 복잡한 구조와 방대한 크기로 인해 계산시간의 급격 한 증가뿐만 아니라 경우에 따라 최적해 도출이 제한될 수 있 다(Gary et al., 2011). 따라서 합리적인 시간 내에 근사 최적해 (Approximate Optimal Solution)를 산출할 수 있도록 메타 휴리
스틱(Meta Heuristic) 기법인 유전자 알고리즘(GA, Genetic Algo- rithm)을 구현하여 수리모형의 최적해와 비교 실험하였다.
이번 연구에서 적용한 정보자산은 일반적인 보병사단에서 운용 가능한 인간정보(Human Intelligence)자산인 사단 수색부 대와 연대수색부대, 영상정보(Imagery Intelligence)자산인 열 상관측장비(TOD, Thermal Observation Device)와 지상감시레 이더(GSR, Ground Surveillance Radar), 신호정보(Signal Intelli- gence) 자산인 전자전지원 장비(ES, Electronic Warfare Support) 로 한정하였다.
본 연구는 제 2장에서 기존연구 고찰, 제 3장에서 탐지확률 생성, 제 4장에서 수리모형 구축, 제 5장에서 유전자 알고리즘 구현, 제 6장에서 실험 및 결과분석, 제 7장 결론 순으로 구성 하였다.
2. 기존연구 고찰
과거 최적 입지선정문제 및 설비배치문제는 주로 정성적인 방 법론을 적용하여 해결하였지만 최근에는 과학적이고 합리적 인 의사결정을 위해 정량적⋅수학적 방법론을 도입하여 연구 가 이루어지고 있다. 특히, 지역담당(Set Covering) 모형을 활 용한 연구가 활발하게 이루어져 왔는데 이는 현실적인 문제를 수학적으로 모형화하기 적합할 뿐만 아니라 다양한 해법들이 개발되어 다양한 유사 문제에서 활용도가 높기 때문이다.
지금까지 정보자산에 대한 최적배치 연구는 주로 자산의 일 부 또는 단일자산만을 고려하여 연구가 이루어져 왔다. Hong (1996)은 지상감시장비를 대상으로 각 후보 진지에서 감시장 비별 차폐면적을 구하여 감시지역의 탐지율을 최대화하기 위 해 선형계획모형을 개발하였으며, 수리모형을 수송 네트워크 로 변환하고 Out-of-Kilter 기법으로 최적해를 도출하였다. Seo (1997) 역시 지상감시장비를 대상으로 육군전술지형분석 프 로그램(ATTS, Army Tactical Terrain System)을 활용하여 후보 진지에서 장비별 탐지율을 구하였으며, 정수계획법(IP, Integer Programming)을 활용하여 감시지역의 탐지확률을 최대화하 는 배치모형을 개발하고 분지한계법(Branch & Bound)을 이용 하여 최적해를 구하였다. Lee et al.(2005)은 열상관측장비를 대상으로 GIS의 지형공간 정보와 TOD 실험자료를 활용하여 최대 탐지효과를 낼 수 있는 최적의 장비 수량 및 배치 수리 모 형을 제시하였으며, Lagrangian Relaxation 기법을 이용하여 근 사 최적해를 도출하였다.
지역담당 모형을 활용한 기존 연구로 Jeong(2005)은 기존 방 공무기체계와 연계된 패트리어트 최적배치문제를 0-1 IP를 활 용하여 수리모형을 구축하였으며, 분지한계법을 통해 최적 해를 도출하였다. Lee and Jeong(2006)은 미사일 방어를 위한 KDX-III 함정의 최적배치와 방어미사일을 할당하는 수리모형 을 부분지역담당 모형을 이용하여 구축하였으며, 분지한계법 으로 최적해를 도출하였다. Kwak(2007)은 항공기 및 탄도미사
398 Younghwa Kim․Suhwan Kim
일의 비행 특성을 고려한 지대공 유도무기 최적배치 모형을 개발하여 복합 휴리스틱기법을 활용, 근사 최적해를 도출하였다.
GIS를 활용한 연구로 Bang et al.(2006)은 GIS의 지형공간 정 보인 지형분석도(VITD), 수치고도 모형(DEM)과 TOD 탐지확 률 모델(Acquire Model, 미 야시장비연구소)을 이용하여 입력 자료를 구축하고 Dijkstra, A* 최적경로 알고리즘을 적용하여 최적침투경로를 분석하였다. 그 밖에도 Hwang and Cho(2002) 은 GIS를 기반으로 한 시간제약을 가진 주문배달 및 수거운송 계획모델을 제시하였으며, Kim et al.(2011)은 GIS를 이용하여 광 산폐기물 침출수에 대한 지표 이동경로 분석모델을 연구하였 다. 이처럼 활용도가 높은 GIS는 다양한 분야에 적용하여 활발 하게 연구되고 있다.
본 연구는 기존 정보자산 배치 연구와는 달리 실제 운용환 경에 적합하도록 육군의 정보자산 동시통합운용 개념을 바탕 으로 다양한 유형의 자산을 통합하는 최적모형을 개발하고 GA를 활용한 해법을 제시하였다. 또한 GIS 디지털 지형공간 자료를 활용한 지형분석과 탐지확률 생성을 통해 객관성 및 정확성 향상을 도모하였다.
3. 탐지확률 생성
정보자산별 탐지확률 생성을 위해 사용된 디지털 지형공간 자 료는 국방지형정보단에서 제공한 1:5만 축척의 군 표준 디지 털 지형정보 DB(FDB, Feature Data Base)와 래스터형 수치지 도(ADRG, Arc Digitized Raster Graphics), 지형분석도(VITD, Vector product Interim Terrain Data)이며, 모든 자료는 기준타 원체 WGS84, 투영좌표계 UTM 52 Zone을 적용하였다. 이러한 자료는 탐지확률 생성의 기초자료로 활용되는 가시선 분석과 배치 후보지에서 탐지가능지역까지의 거리 산출, 탐지지역의 은폐확률을 산출하기 위한 목적으로 활용하였다.
탐지확률은 자산별 거리에 따른 탐지확률()과 감시 지역의 은폐확률()을 고려하여 생성하였다. 먼저 정보 자산별 탐지능력(최대 탐지거리)을 고려하여 배치 후보지에서 가시선 분석을 통해 지형 차폐여부에 의한 탐지가능 지역을 분석하고 탐지가능 지역에 대한 거리를 산출하여 거리에 따른 탐지확률을 생성하였다. 은폐확률은 VITD의 식생 분포를 활 용하여 탐지지역의 노출정도에 따른 은폐확률을 생성하였다.
거리에 따른 탐지확률과 탐지가능지역에 대한 은폐확률에 서 로 영향을 미치지 않으므로 서로 독립(Independent)이라고 가 정 하였다. 따라서 최종 탐지확률()은 식 (1)과 같이 계 산하였다.
× (1) 예를 들어, 인간정보자산이 임의 A지역에서 2km 이격된 B 지역까지의 탐지확률이 0.6이며, B지역의 은폐확률이 0.125일
경우 최종탐지확률은 0.525[= 0.6×(1-0.125)]가 된다. 여기에서 지역은 작전지역을 크기에 따라 구분한 격자(Cell)가 되며 거 리에 따른 탐지확률과 은폐확률은 Arc GIS를 통해 계산된다.
정보자산별 거리에 따른 탐지확률과 탐지지역의 은폐확률 생성방법에 대한 세부사항은 다음과 같다.
3.1 정보자산별 거리에 따른 탐지확률()
거리에 따른 탐지확률이란 후보지에서 탐지가능 지역까지 의 거리에 따른 탐지확률을 의미한다. 세부적인 확률 생성절 차는 다음과 같다.
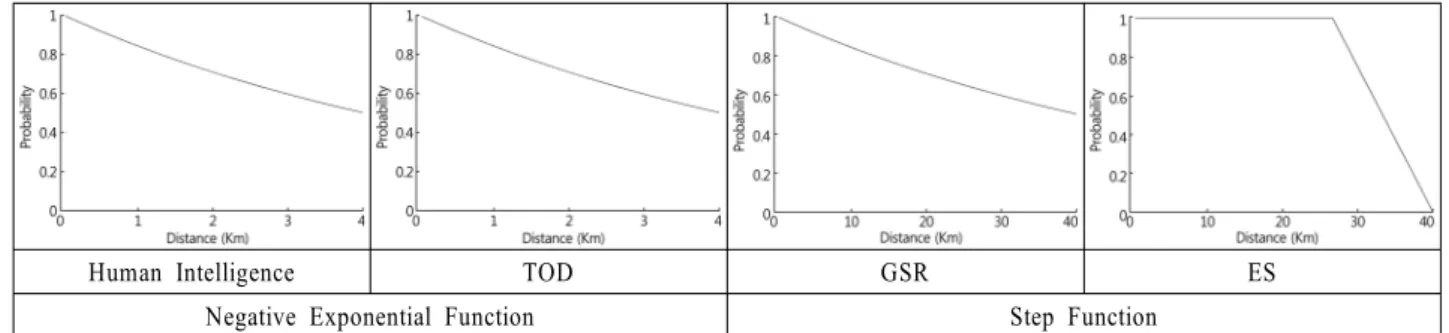
먼저 정보자산 배치 후보지에서 지형에 의한 차폐여부와 정 보자산별 최대 탐지거리를 고려한 가시선 분석을 통해 탐지 가능한 지역을 분석한다. 두 번째 단계는 가시선 분석을 통해 산출된 각각의 탐지가능 지역으로부터 후보지까지의 거리를 산출한다. 마지막으로 창조21 정보모델에서 사용되는 탐지확 률 함수에 산출된 거리를 대입하여 자산별 거리에 따른 탐지 확률을 생성한다. 창조21 정보모델에서 적용되는 정보자산별 최대 탐지거리 및 탐지확률 함수는 <Table 1>과 같다.
Table 1. The Maximum Detection Distance and Detection Probability Function
구 분 최대탐지거리
(km) 탐지확률 함수
인간정보 주 야 기동모델의
4 2 탐지논리 영상
정보
TOD 8 Negative Exponential Function
GSR 40
신호정보 ES 30 Step Function
창조21에서 인간정보 자산(수색, 특공, 정찰)의 탐지확률은 기동모델의 탐지논리인 시간(T)에 대한 함수로 식 (2)와 같으 며, 세부내용은 보안 목적상 생략한다(R.O.K Army BCTP Corps, 2013).
(2)
∆하지만 본 연구에서의 탐지확률은 탐지가능 지역까지의 거 리에 대한 함수에 적용해야하기 때문에 식 (2)의 적용이 제한 된다. 따라서 인간정보 자산의 탐지확률은 영상정보자산의 탐 지확률 함수인 Negative Exponential 함수에 인간정보 자산의 주간 최대탐지거리(4km)를 고려하여 생성하였다. <Figure 1>
은 이번 연구에서 활용한 창조21의 자산별 탐지확률 함수를 나타낸다.
A Study on the Optimal Allocation for Intelligence Assets Using MGIS and Genetic Algorithm 399
Human Intelligence TOD GSR ES
Negative Exponential Function Step Function Figure 1. The Functions of Intelligence Assets Detection Probability 3.2 은폐확률()
탐지지역의 은폐확률은 VITD의 식생 주제도를 활용하여 생성 한다. VITD의 식생 주제도는 총 3개의 레이어로 VEGAREA (Vegetation area), VGFAREA(Vegetation forested area), VGWAREA (Vegetation water area)로 구성되어 있다. VGFAREA 레이어에 포함된 DMT(Density Measure of Tree/Canopy Cover)의 속성값 을 이용하여 탐지지역의 노출정도를 은폐확률로 설정하였다.
DMT 속성값은 해당 지역의 수목에 의해 지면이 차폐되는 정보 를 확률로 표현한 것으로 <Table 2>에서 나타내는 것과 같이 25%, 50%, 75%를 기준으로 4개의 코드가 저장되어 있으며, 연구 에서는 각 구간의 중간값을 은폐확률로 설정하였다. VEGAREA 와 VGWAREA 레이어는 탐지지역의 지면 차폐정도가 지정되 어 있지 않지만 완전히 노출되어 있다고 판단하기 제한되므로 VGFAREA의 DMT 속성값의 가장 낮은 구간과 동일하게 은폐 확률을 설정하였다(Bang et al., 2006).
Table 2. Concealment Probability by VITD(Vegetation)
구 분 DMT 은폐확률
VEGAREA - 0.125
VGFAREA
0~25% 0.125
25~50% 0.375
50~75% 0.625
75~100% 0.875
VGWAREA - 0.125
4. 수리모형 구축
4.1 문제정의
먼저 작전지역을 격자(Cell) 단위로 구분하여 감시지역을 설 정하고 정보자산 종류, 가용수량, 후보지, NAI/TAI 지역 및 우 선순위를 구성한다. 구성된 요소를 바탕으로 정보자산별 가용 수량과 NAI/TAI 지역에 대한 중첩감시 제약, NAI/TAI 지역의 우선순위, 후보지간 거리제약 등을 고려하여 작전지역의 탐지 확률 합을 최대화시키는 후보지에 정보자산을 배치하는 것이다.
문제 해결을 위한 가정사항은 다음과 같이 설정하였다.
① 각 배치 후보지에는 정보자산 종류에 관계없이 1대 자산만 배치 가능하다.
② 정보자산별 가용 수량, 후보지, NAI/TAI 지역에 대한 우선 순위(가중치)는 주어진다.
③ 인간정보자산의 감시능력을 고려하여 담당 가능한 NAI/
TAI 지역은 2개 지역으로 제한한다.
④ 기상은 주간 맑은 날씨로 탐지확률에 영향을 미치지 않 는다.
4.2 최적배치 수리모형
최적배치 수리모형은 기존 설비배치 문제와 본 연구의 문제 특성을 고려하여 부분지역담당 모형을 기반으로 수립하였다.
수리모형에 대한 세부내용은 다음과 같다.
인덱스(Index)
: 감시지역 i, ∈ {1, 2, 3, …, n}
: 정보자산이 배치될 후보지 j, ∈ {1, 2, 3, …, m}
: 정보자산 종류 k, ∈ {사단수색(= 1), 연대수색(= 2), TOD(= 3), GSR(= 4), ES(= 5)}
집합(Set)
: 모든 감시지역 i의 집합
: NAI/TAI로 선정된 감시지역 i의 집합
: 정보자산 배치 후보지 j의 집합
′ : 후보지 j 반경 1km 이내( ′ ) 인접한 후보지 j’의 집합
* ′ ′∈× ′∈ ≠ ′
′
: 인간정보자산 운용지역에 후보지 j 의 집합
: 정보자산 k의 집합
: 인간정보자산의 집합 상수(Parameter)
: 정보자산 k가 후보지 j에서 감시지역 I를 탐지할 확률
: 정보자산 k가 후보지 j에서 감시지역 I에 대한 담당 가능 여부(가능하면 1, 불가능시 0)
400 김영화․김수환
: 감시지역 i의 감시 우선순위(NAI/TAI 지역)에 대한 가중치
: 정보자산 k별 가용 수량 결정변수(Decision Variable)
: 자산 k가 후보지 j에 할당되어 감시지역 I를 감시하 면 1, 아니면 0
: 자산 k가 후보지 j에 할당되면 1, 아니면 0 목적함수 및 제약식(Objective Function and Constraints)
∈
∈
∈
(3)
∈
∈
≥ ∀∈ (4)
∈
≤ ∀∈ ∈ (5)
∈
≤ ∀∈ (6)
∈
≤ ∀∈ (7)
∈
∈
′≤ ∀ ′ ∈′ (8) ≤ ∀∈ ∀∈ ∀∈ (9) ∈ ∀∈ ∀∈ ∀∈ (10) ∈ ∀∈ ∀∈ ∀∈ (11) 목적함수 (3)은 감시지역 i의 우선순위를 고려하여 감시지 역에 대한 탐지확률의 합을 최대화하는 것이다. 제약식 (4)는 선정된 NAI/TAI 감시지역()은 최소 2개 이상의 정보자산으 로부터 담당되어야 함을 나타낸다. 제약식 (5)는 인간정보자 산의 능력을 고려하여 담당 가능한 NAI/TAI 지역은 최대 2개 소를 초과하여 담당할 수 없다는 제약조건이며, 제약식 (6)은 모든 배치 후보지에는 자산 종류에 관계없이 1대만 배치될 수 있음을 나타내고 제약식 (7)은 정보자산별 가용수량 제약조건 으로 정보자산 k별 가용한 자산수량()을 초과하여 배치할 수 없음을 의미한다. 또한 제약식 (8)은 정보자산이 배치된 후 보지 반경 1km 이내의 후보지에는 자산이 배치될 수 없음을 의미하며 제약식 (9)는 결정변수 와 의 관계식으로 후 보지 j에 자산 k가 배치되면 감시지역 i에 대해 감시 또는 감시 불가하며 배치되지 않으면 감시지역 i를 감시 할 수 없음을 나 타낸다. 제약식 (10)과 제약식 (11)은 결정변수와에 대한 이진정수 제약조건이다.
5. 유전자 알고리즘 구현
본 연구에서 제안하는 GA는 전통적인 GA 절차를 기반으로
구현하였다. 초기 설정 단계에서는 모집단의 개체 수, 반복세대 (종료 조건), 유전 파라미터를 설정한다. 이어서 초기 모집단 을 생성하여 개체별 제약조건 만족 여부에 따라 적합도를 평 가한 이후 유전 연산자(선택, 교차, 변이)를 통해 해의 개선을 유도하여 다음세대로 진화하는 과정으로 GA를 구현하였다.
<Figure 2>는 이번 연구에서 적용한 GA의 전반적인 순서도를 나타내며, GA 과정별 세부 내용은 다음과 같다.
Figure 2. GA Flow Chart
5.1 유전자형(Gene-type) 표현
GA를 구현하기 위해 주어진 문제의 해를 유전자(Gene)의 집합체인 염색체(Chromosome)로 표현해야한다. 따라서 염색 체는 해 공간에 대한 전역적인(Global) 탐색을 통해 근사 최적 해를 도출하기 위해 문제의 가능한 모든 해 공간과 문제의 특 성을 반영하여 표현해야 한다. 본 연구에서는 정보자산에 대 한 최적 배치결과가 해를 의미하기 때문에 가용한 자산의 수 량과 배치 후보지를 이용하여 정수 문자열(Integer String)로 구 성된 일차원 배열 형태로 <Table 3>과 같이 표현하였다.
Table 3. Gene-type Representation
자 산 사단수색 연대수색 TOD GSR ES
유전자좌 (Genetic Locus)
1 … 18 19 … 30 31 … 38 39 40 41 … 43
유전자
(후보지) 9 … 30 33 … 46 65 … 70 67 77 81 … 85
MGIS 및 유전자 알고리즘을 활용한 정보자산 최적배치에 관한 연구 401
예를 들어, <Table 3>에서 첫 번째 유전자는 사단수색 18개 자산 중 첫 번째 자산을 후보지 9번에 배치하며, 31번째 유전 자는 8대의 TOD 중 첫 번째 자산을 후보지 65번에 배치함을 의미한다.
5.2 초기 모집단 생성(Initial Population)
GA에서 모집단은 개체(염색체)들의 집합으로 구성되어 있 으며 이 개체들을 대상으로 하는 유전 연산자(Genetic Operator) 를 통해 해의 개선을 유도하게 된다. 따라서 초기 모집단이 생 성되어야 한다. 초기 모집단을 생성하는 방법에는 주어진 문 제의 특성을 반영한 발견적 생성 방법과 임의 생성 방법이 있 다. 본 연구에서는 생성된 해들이 지역적(Local) 근사해로 조 기 수렴하는 특성을 가진 발견적 생성 방법을 대신하여 전역 적인 해 공간 탐색이 가능한 임의생성 방법을 적용하였다. 정 보자산별 배치 가능한 후보지 집합에서 중복 배치가 발생하 지 않도록 임의 난수를 발생시켜 초기 모집단을 생성하였다.
5.3 적합도 평가(Fitness Evaluation)
적합도 평가는 원 문제의 목적함수를 만족시키는 정도를 평 가하는 것이다. 수리모형의 목적함수는 각각의 정보자산 배치 결과에 따른 탐지확률의 합을 최대화시키는 것이므로 개체에 각각의 유전자들의 탐지확률 합(Total Probability)이 클수록 우수 한 해로 평가될 수 있다. 식 (12)는 GA에서 목적함수를 나타낸다.
(12) 하지만 임의생성 방법으로 생성된 개체는 실행 불가능해(In- feasible Solution)를 포함할 수 있다. 이에 따라 실행 불가능해일 경우 개체의 적합도를 낮게 평가하고 가능해(Feasible Solution) 를 보장하기 위해 벌금함수(Penalty Function)를 도입하였다.
(13)
식 (13)은 NAI/TAI 지역의 중첩감시 제약조건에 대한 벌금 함수를 나타낸다. 총 NAI/TAI 지역 수(Total NAI/TAI)와 해당 개체에서 중첩 감시된 NAI/TAI 지역 수(Overlaid NAI/TAI)의 차를 구하고 역수를 취한 형태로 표현된다. 모든 NAI/TAI 지 역이 중첩 감시되면 벌금함수 은 1이 된다.
(14)
식 (14)는 후보지간 거리제약(반경 1km 이내 배치)에 대한 벌금함수를 나타내며 제약조건을 위반한 총 후보지 쌍(Pair)의 수(Total Pair of Candidates(< 1km))를 구하고 역수를 취한 형태 이다. 위반한 후보지 쌍이 없을 경우 벌금함수 는 1이 된다.
따라서 본 연구의 적합도 평가함수는 목적함수()와 중첩 감시에 대한 벌금함수(), 후보지간 거리제약 벌금함수() 의 곱으로 식 (15)와 같다.
⋅⋅ (15)
5.4 선택(Selection)
선택은 다음 세대로 진화하기 위하여 진화법칙인 적자생존 과 자연도태의 원리를 바탕으로 적합도가 우수하게 평가된 개 체를 선택하는 과정이다. 선택 과정에서 단순하게 적합도가 우수한 개체만 선택하게 되면 지역해로의 수렴 가능성이 높다.
따라서 룰렛 휠 선택기법(Roulette Wheel Selection)을 적용하 여 적합도에 비례한 선택확률에 따라 개체를 선택하여 지역해 로의 수렴을 방지하고 해의 다양성을 보장하였다. 또한 엘리 트 보존전략(Elitist Preserving Selection)을 동시 적용하여 세대 별 가장 우수한 개체는 다음 세대에서도 생존할 수 있는 장치 를 마련하였다.
5.5 교차(Crossover)
교차는 선택연산을 통해 선택된 부모세대의 개체들을 대상 으로 새로운 개체를 생성하기 위한 과정이다. 교차를 통해 해 의 다양성을 확보하고 이전 세대에서 존재하지 않았던 보다 우수한 개체로 진화할 수 있다. 본 연구에서는 교차지점이 임 의 생성되는 일반적인 다점 교차(Multiple Points Crossover)와 는 달리 교차 이후 중복된 유전자 생성을 방지하기 위해 자산 의 종류가 구분되는 유전자좌(Genetic Locus)를 고정하는 3점 교차(Fixed 3-Points Crossover)를 적용하였으며 연산 방법은
<Figure 3>과 같다.
Figure 3. Fixed 3-Points Crossover
5.6 변이(Mutation)
선택과 교차는 부모개체들이 가지고 있는 유전 형질을 활용 하여 새로운 개체를 생성하는 반면, 변이는 부모세대에 존재 하지 않는 새로운 유전 형질을 도입하여 새로운 개체를 생성 하는 연산이다. 개체의 다양성이 유지되어 해의 탐색공간이 확장되기 때문에 열등한 집단에서 지역 최적해로의 수렴을 방 지한다. 본 연구에서는 모집단내에 가장 우수한 개체를 제외 하고 임의 변이(Random Mutation) 기법을 적용하였으며, 절차 는 다음과 같다(Haupt, 2004).
402 Younghwa Kim․Suhwan Kim
Step 1 : 일정한 변이율(Mutation Rate, )을 설정하고 모집단 의 개체수()와 개체의 유전자 수()를 곱하여 올림 (Ceiling)한 값을 변이횟수로 결정한다. 변이 횟수를 결 정하는 식은 다음과 같다.
⌈⋅⋅⌉ Step 2 : 변이 횟수만큼 임의의 난수를 발생시켜 변이 대상이
되는 개체와 유전자의 위치를 선정한다.
Step 3 : 변이 대상으로 선정된 유전자 위치의 형질을 해당 개 체에 다른 유전자 형질과 중복되지 않는 난수를 생성 하여 대체한다.
6. 실험 및 결과분석
6.1 실험 설계
본 연구에서 작전제대 및 작전형태는 보병사단의 방어 작전 으로 가정하였다. 연구지역은 정면 15km, 종심 20km의 지역으 로 방어 작전시 정규전 작전을 수행하는 전방사단의 일반적인 지형적 특성을 고려하여 산악지역과 종심 도로망이 발달된 지 역으로 선정하였다. 연구지역은 <Figure 4>와 같다.
Figure 4. Study Area
수리모형과 GA를 비교하기 위해 가용한 정보자산 종류, 자 산별 가용 수량 및 후보지, NAI/TAI 지역은 동일하게 적용하 였으며, 연구지역을 200×200m, 100×100m, 50×50m Cell 크기 별로 구분하여 실험을 구성하였다. 연구지역의 Cell 크기를 변 경하여 실험하는 이유는 연구에 활용된 디지털 지형정보 자료
는 래스터형(Raster Type)으로 변환되어 공간상의 지형요소에 대한 정보를 Cell 단위로 표현하기 때문에 동일 지역일 경우 Cell의 크기가 작을수록 세부적인 지역에 대한 지형정보를 표 현할 수 있기 때문이다. 따라서 탐지확률 생성시 분할된 Cell 크기의 지역은 동일한 확률값을 가지게 된다. 즉, Cell의 크기 가 증가할수록 해당 Cell 전체가 동일한 수치로 적용되기 때문 에 세밀한 지형의 특성을 반영한 탐지확률 생성이 제한된다.
따라서 탐지확률의 정확성을 향상시키기 위해서는 분할되는 Cell의 크기를 적합하게 줄여서 세부적인 지형에 대한 특성을 반영할 필요가 있다.
Table 4. Available Intelligence Assets and Candidates
구 분 수량 단위 운 용 후보지
인간정보 사단수색 18
분대 적지종심지역 30
연대수색 12 경계지역 26
영상정보 TOD 8
조 주 방어지역/
후방지역 29
GSR 2
신호정보 ES 3
총계 43 85
<Table 4>는 실험에서 적용한 정보자산 종류 및 수량, 자산 배 치 후보지를 나타낸다. 정보자산 종류 및 가용 수량은 일반적으 로 보병사단에서 운용 가능한 정보자산의 편제를 고려하였다.
인간정보자산은 사단 수색대대와 연대 수색중대를, 영상정보 와 신호정보자산은 각각 정보중대의 TOD, GSR, ES로 한정하 였다. 실험을 위해 자산 배치 후보지는 자산별 운용지역을 고려 하여 총 85개소를 선정하였다. 세부 현황은 <Table 4>와 같다.
Table 5. NAI/TAI Area and Priority
구 분 우선순위 구 분 우선순위
접근로 1
N#1 1
접근로 2
N#7 2
T#8 4
T#2 5
T#9 7
N#3 8
N#10 9
T#4 11
T#11 12
N#5 14
T#12 15
T#6 16
N#13 17
접근로 3
N#14 3
※ 총계 : 18개소 (NAI 8, TAI 10)
T#15 6
N#16 10
T#17 13
T#18 18
<Table 5>는 실험을 위해 선정된 NAI/TAI 현황 및 우선순위 를 나타내며 NAI 지역 8개소, TAI 지역 10개소로 총 18개소를 선정하였다. NAI/TAI 지역 선정은 작전 준비간 전장정보분석 (IPB, Intelligence Preparation of Battlefield) 4단계 적 방책분석 에서 선정하게 된다. <Figure 5>는 선정된 배치 후보지와 NAI/
TAI 지역을 나타낸다.
A Study on the Optimal Allocation for Intelligence Assets Using MGIS and Genetic Algorithm 403
Figure 5. Total NAI/TAI Area and Candidates
GA를 적용한 실험은 수리모형과 동일한 조건으로 수행하 였으며 알고리즘의 적합성과 성능을 평가하기 위해 수리모형 의 실험결과와 비교하였다. 각 실험별 30회 반복하여 최대⋅
최소⋅평균 적합도와 연산시간을 측정하였다. GA는 유전 파 라미터(Genetic Parameters)에 의해 결과 및 성능이 좌우된다.
따라서 우수한 성능(근사 최적해, 연산시간)의 알고리즘을 구 현하기 위해 파라미터 변화에 따라 성능에 미치는 영향을 비 교하는 실험을 수행하였다. 파라미터 성능비교 실험은 실험 1 의 조건을 기준으로 실험 수치별 30회 반복하여 최대적합도 및 평균 연산시간을 측정하였으며, 성능 비교 결과는 <Figure 6>과 같다. 성능비교 실험 결과에 의해 가장 효과적인 수치를
<Table 6>과 같이 적용하였다.
Table 6. Genetic Parameters
구 분 모집단
크기
교차율 ()
변이율
() 반복세대
수치 40 0.5 0.015 500
실험은 군에서 일반적으로 사용하고 있는 Intel i5-3470 CPU와 4GB RAM의 PC 사양에서 수행하였다. 또한 수리모형의 최적 해 계산을 위해 GAMS 23.5(Solver : CPLEX)를 사용하였으며,
GA는 MATLAB R 2012를 활용하여 구현하였다. Figure 6. Result for Genetic Parameters
404 김영화․김수환
Table 7. Total Results
구 분 GA GAMS(수리모형)
공통
작전지역 크기 15×20km
배치 후보지 85개소
정보자산 종류
(자산별 수량) 5종류
(사단수색 18, 연대수색 12, TOD 8, GSR 2, ES 3)
실험 1
격자 크기(분할) 200×200m(7,500개 지역)
연산시간(s) 3.43(평균) 38.46
최적해(최소/평균/최대) 18,679.7042/19,046.4953/19,239.8805 19,239.8805
배치결과(후보지)
사단수색 4, 5, 6, 8, 9, 10, 13, 15, 16,
18, 20, 21, 23, 24, 26, 27, 29, 31 4, 5, 6, 8, 9, 10, 13, 15, 16, 18, 20, 21, 23, 24, 26, 27, 29, 31 연대수색 32, 37, 39, 40, 43, 45,
47, 48, 49, 50, 53, 54 32, 37, 39, 40, 43, 45, 47, 48, 49, 50, 53, 54 TOD 57, 59, 63, 67, 71, 74, 76, 77 57, 59, 63, 67, 71, 74, 76, 77
GSR 62, 72 62, 72
ES 81, 83, 85 81, 83, 85
실험 2
격자 크기(분할) 100×100m(30,000개 지역)
연산시간(s) 3.45(평균)
“Out of memory”
최적해(최소/평균/최대) 57,977.7166/59,665.6935/60,362.8553
배치결과 (후보지)
사단수색 4, 5, 6, 8, 9, 11, 12, 13, 19, 20, 23, 24, 25, 26, 27, 28, 29, 30 연대수색 32, 34, 35, 37, 38, 40,
44, 46, 49, 50, 53, 54 TOD 57, 60, 63, 66, 69, 71, 75, 76
GSR 70, 72
ES 82, 83, 84
실험 3
격자 크기(분할) 50×50m(120,000개 지역)
연산시간(s) 3.46(평균)
“Out of memory”
최적해(최소/평균/최대) 222,316.7674/229,520.9352/231,170.1916
배치결과(후보지)
사단수색 4, 5, 6, 9, 12, 13, 14, 15, 19 21, 23, 24, 25, 26, 27, 28, 29, 31 연대수색 32, 33, 34, 35, 37, 40,
44, 45, 49, 50, 53, 54 TOD 57, 63, 64, 65, 70, 71, 74, 75
GSR 62, 72
ES 82, 83, 85
Table 8. Result of Overlaid NAI/TAI Area(Experiment 1)
구 분 N#1 T#2 N#3 T#4 N#5 T#6 N#7 T#8 T#9 N#10 T#11 T#12 N#13 N#14 T#15 N#16 T#17 T#18 중첩
감시수량
GA 6 8 2 2 2 2 2 7 8 6 5 5 3 6 2 2 2 2
수리모형 6 8 2 2 2 2 2 7 8 6 5 5 3 6 2 2 2 2
6.2 결과 및 분석
<Table 7>은 실험 구성별 GA와 수리모형의 실험결과를 나타내 는데 GA 결과는 30회 실험 중 가장 우수한 적합도를 산출한 결과 이다. <Table 7>과 같이 수리모형의 경우 실험 1을 제외하고 최적 해를 도출할 수 없었다. 이는 Cell의 크기가 감소할수록 감시지역 의 수가 증가하여 가능한 해의 조합 역시 급격하게 증가하기 때문 이다. 이에 따라 일반적인 PC 사양으로는 최적해 계산이 제한된 다. 하지만 실험 1의 결과를 통해 본 연구에서 제안하는 수리모형 에 대한 타당성을 검증할 수 있다. <Table 7>의 자산 배치결과에서
보는 바와 같이 정보자산별 가용한 수량과 운용지역을 충족하는 후보지에 자산이 배치되었다. 뿐만 아니라 선정된 NAI/TAI 지역 에 대한 중첩감시 제약조건 역시 <Table 8>과 같이 만족하였다.
이처럼 본 연구에서 제안하는 정보자산 최적배치 모형은 한 정된 정보자산을 효과적으로 활용하여 감시공백을 최소화하 고 다양한 정보자산운용 하 동시통합운용개념을 적용해야하 는 실제 환경에 적합한 것으로 판단된다. 특히, 동시통합운용 측면에서 다양한 유형의 자산에 대한 통합운용과 NAI/TAI 지 역에 대한 혼합 및 중첩감시가 가능한 모형으로 실제 자산 운 용환경에 적합하다고 할 수 있다.
MGIS 및 유전자 알고리즘을 활용한 정보자산 최적배치에 관한 연구 405
Experiment 1 Experiment 2 Experiment 3
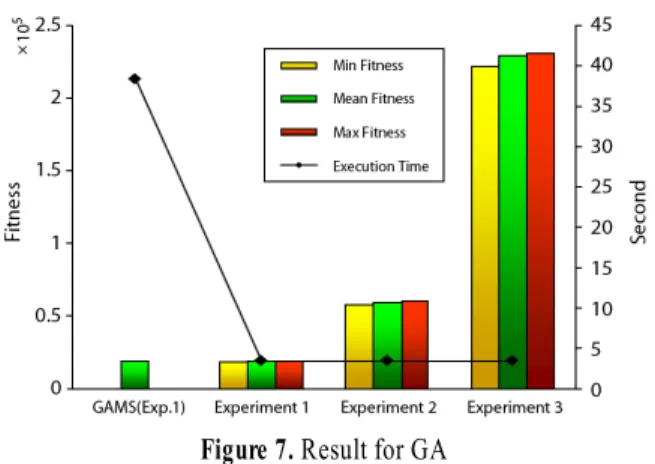
Figure 8. The Best Solution(GA) Figure 7. Result for GA
<Figure 7>은 각 실험별 GA 결과로 최적해가 도출된 실험 1 의 수리모형 결과와 GA의 최대⋅최소⋅평균 적합도 및 연산 시간을 나타낸다. 실험 1의 조건에서 GA는 30회 실험 중 8회의 실험결과가 수리모형과 동일한 최적해와 배치결과를 제공하 였으며, NAI/TAI 지역에 대한 중첩감시 제약 또한 <Table 8>과 같이 수리모형과 동일한 결과를 도출하였다. 최소 적합도는 18679.7042로 수리모형의 최적해와 비교하여 약 3% 차이가 발 생하였고 평균 적합도는 19046.4953을 나타내었다. 특히, 연산 시간은 평균 3.43초로 수리모형 대비(38.46초) 35.03초(91.1%) 가 단축되었다. 또한 GAMS로 계산이 제한되었던 실험 2와 실 험 3에 대한 GA 실험 결과, 최대 적합도는 각각 60362.8553, 231170.1916이며 평균 적합도는 각각 59665.6935, 229520.9352 를, 최소 적합도는 각각 57977.7166, 222316.7674, 평균 연산시 간은 3.45초, 3.46초를 나타내었다.
실험 결과를 통해 본 연구에서 제안하는 GA는 최적해와 근사 한 3% 이내의 결과를 제공하였으며, 연산시간은 실험별 3.43~
3.46초로 Cell 크기에 영향을 받지 않고 유사한 계산시간이 소 요됨으로써 합리적인 시간 내에 근사 최적해를 도출할 수 있는 우수한 알고리즘이라고 할 수 있다.
<Figure 8>은 각 GA 실험별 적합도가 가장 우수한 실험결 과로 세대에 따른 최우수 개체의 적합도와 모집단의 평균 적 합도를 그래프로 나타낸다. 실선은 세대별 최우수 개체의 적 합도를, 점선은 세대별 모집단의 평균 적합도를 의미한다. 100
세대까지는 적합도의 수치가 급격하게 증가하며 이후 300세 대까지는 낮은 증가율을 보인다. 이후 최우수 개체의 적합도 는 일정한 값(근사 최적해)으로 수렴하여 종료세대까지 안정 상태로 지속된다. 평균 적합도 역시 세대가 진화할수록 증가 하고 일정 범위로 유지되는데 이는 생존 환경에 적합한 우성 형질을 갖는 개체의 자손은 세대가 거듭할수록 집단에서 번성 하기 때문이다.
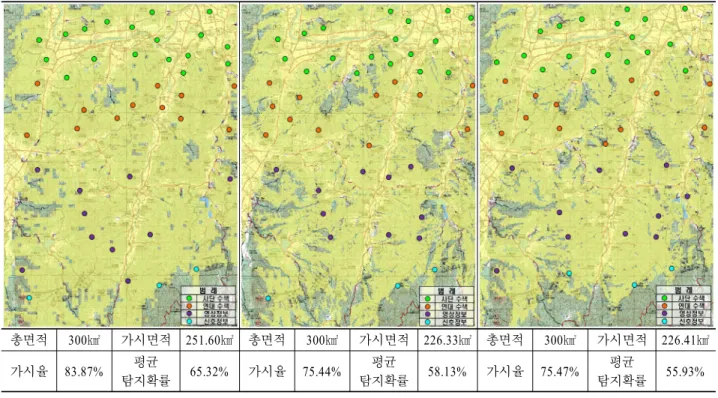
<Figure 9>는 실험별 가장 우수한 적합도를 제공한 GA 실험 의 자산배치 결과와 총면적(300㎢)에 대한 가시율, Cell별 평균 탐지확률을 나타낸다. 각 그림에서 지점(Point)은 자산의 배치 결과를 의미하며, 노란 음영으로 표현된 부분은 자산 배치결과 에 의해 탐지가 가능한 지역을 나타낸다. 이에 따라 실험별 가 시율은 각각 83.87%(251.60㎢), 75.44%(226.33㎢), 75.47%(226.41
㎢)이며 평균 탐지확률은 각각 65.32%, 58.13%, 55.93%를 나타 내었다. 가시율과 탐지확률 모두 실험 1이 가장 높은 결과를 나 타내었는데 이는 실험 1의 Cell 크기가 500×500m로 실험 중 가장 넓어 세부적인 지형적 영향이 크게 작용하지 않았기 때문이다.
동일 조건에서 실험별 자산 배치결과는 일부 상이한 결과를 보였다. 이는 Cell 크기에 따라 가시선 분석에 영향을 미쳐 같 은 후보지라도 탐지가능 지역의 변화가 발생했기 때문이다.
평균 탐지확률은 Cell 크기가 작아질수록 감소하는 결과를 얻 었는데, 이는 Cell 크기가 작아질수록 지역을 구성하는 Cell의 수가 급격하게 증가함이 원인으로 해석할 수 있다.
다시 말해 동일한 크기의 지역이라도 Cell 크기에 따라 지형 정보가 다르게 반영되기 때문에 가시선 분석에 영향을 미치게 되고 지역의 구성하게 되는 Cell의 수가 증감하여 평균 탐지확 률에 변화를 일으키게 된다.
따라서 Cell 크기가 작아질수록 작전지역을 작은 단위로 구 분할 수 있어 현실 세계와 근접한 세부적인 지형정보를 활용 하여 정확한 지형분석이 가능하게 할 수 있다. 하지만, 단순하 게 Cell 크기를 축소하게 되면 이를 처리하기 위한 불필요한 자원 소모를 초래하게 되며 고사양(CPU, RAM, 저장장치 등) 이 요구될 수 있다. 따라서 사용되는 디지털 지형자료가 표현 할 수 있는 최대 해상도(Cell 크기)를 고려하여 적합한 Cell 크 기를 설정해야 한다.
406 Younghwa Kim․Suhwan Kim
총면적 300㎢ 가시면적 251.60㎢ 총면적 300㎢ 가시면적 226.33㎢ 총면적 300㎢ 가시면적 226.41㎢
가시율 83.87% 평균
탐지확률 65.32% 가시율 75.44% 평균
탐지확률 58.13% 가시율 75.47% 평균
탐지확률 55.93%
(a) Experiment 1 (b) Experiment 2 (c) Experiment 3
Figure 9. Allocation Result and Visible Area and Visible Rate and Mean Detection Probability
7. 결 론
본 연구의 목적은 정보자산 배치문제에 있어 기존의 단일 수 집자산을 고려한 연구와 정성적인 접근방법에서 탈피하여 정 량적인 분석기법을 적용하고 정보자산 동시통합운용 개념에 부합되는 최적배치 모형을 개발하는 것이다. 이를 통해 정보 자산 배치⋅운용계획의 정확성과 타당성을 향상시켜 최종적 으로 노력의 낭비를 방지하고 분석시간 단축을 통해 합리적인 시간 내에 지휘관의 신속한 의사결정을 지원하는 것이다. 이 를 위해, 군 GIS의 디지털 지형공간 자료와 육군 전투지휘훈 련 모델인 창조21의 모의논리를 활용하여 입력 자료를 구축 하였으며, 이를 적용하여 작전지역에 대한 탐지확률의 합을 최대화하는 수리모형을 제시하였다. 또한 수리모형을 한계를 극복하기 위해 메타 휴리스틱 기법인 GA를 적용한 해법을 제 시하였다.
모형실험을 통해 가용 정보자산 통합 배치, 자산별 가용 수량, NAI/TAI 지역 중첩감시에 대한 제약조건을 충족시킴으로써 수리모형의 타당성과 정보자산 동시통합운용 개념에 대한 적 합성을 입증하였다. 뿐만 아니라 적용된 GA는 수리모형의 한 계를 극복하고 수리모형보다 우수한 연산시간을 제공하였다.
따라서 본 연구에서 제안하는 정보자산 최적배치 모형은 기 존에 분석자의 능력과 경험에 의존한 것과는 달리 지형에 대 한 수치자료와 과학적 모의 논리를 적용하여 분석결과에 대한 신뢰성과 정확성을 향상시킬 수 있을 것으로 판단된다. 또한 급박한 전장 환경에서 합리적인 시간에 근사 최적해를 제공하
므로 지휘관의 신속한 의사결정 지원이 가능하다.
향후 연구방향은 본 연구에서 정보자산별 탐지확률은 주간 맑은 날씨로 가정하여 생성하였으며, 다른 요소는 고려하지 않았다. 따라서 탐지확률의 정확성을 향상시키기 위해 기상요 소와 자산별 특성 등 다양한 요소를 고려하여 자산별 탐지확 률에 대한 추가적인 연구와 디지털 지형공간 자료의 지속적인 최신화가 필요하다. 끝으로, 정보자산에 대한 제대별 동시통 합운용을 위해 동적인(Dynamic) 수집자산인 정찰대, UAV 등 을 포함하는 모형에 대한 연구가 지속되어야 한다.
참고문헌
Alcaraz, J. and Maroto, C. (2001), A robust genetic algorithm for re- source allocation in project scheduling, Annals of Operation Re- search, 102(1-4), 83-109.
Army R. O. K., BCTP Corps (2013), 2013 Creation 21 Logic Simulation, Eduction Reference, 4-65-4-115.
Bang et al. (2006), Analysis of Information Route using Optimal Path Finding Method and Geospatial Information, Korean Society of Civil Engineers, 26(1), 195-202.
Beasley, J. E. and Chu, P. C. (1996), A genetic algorithm for the set cove- ring problem, European Journal of Operation Research, 94, 392- 404.
Garey, M. R. and Johnson, D. S. (1979), Computers and Intractability : A Guide to the Theory of NP-Complete, W. H. Freeman, San Fran- cisco, USA.
Haupt, R. L. and Haupt, S. E. (2004), Practical Genetic Algorithm,
A Study on the Optimal Allocation for Intelligence Assets Using MGIS and Genetic Algorithm 407
Wiley, New Jersey, USA.
Holland, J. (1973), Genetic algorithm and the optimal allocation of trials, SIAM Journal on Computer, 2(2), 88-105.
Holland, J. (1975), Adaptation in natural and artifitial systems, Univer- sity of Michigan Press.
Hong, K. M. and Kim, C. Y. (1996), The Ground Surveillance Equip- ment Optimal Arrangement Using Out of Kilter Algorithm, Military Operations Research Society of Korea, 22(1), 129-141.
Houck, C. R., Joines, J. A., and Kay, M. G. (1996), Comparison of ge- netic algorithms, restart and two-opt switching for solving large lo- cation-allocation problems, Computer and Operations Research, 23(6), 587-596.
Hwang, H. S. and Cho, K. S. (2002), Pickup and Delivery Scheduling with Time Constraint Using GeoDatabase, KIIE Spring Conference 185-192.
Jeong, C. Y. (2005), A Study on Optimal Allocation for PATRIOT by Using Integer Programming, Master Diss., Korea National Defense University.
Kim et al. (2011), Analysis of Mine Leachate Transport Pathway on the Surface Using GIS, The Korean Society of Mineral and Energy Resources Engineers, 48(5), 560-572.
Kwak, K. H. (2007), Optimal Allocation Model for SAM Using Multi- Heuristic Algorithm, Master Diss., Korea National Defense Uni- versity.
Lee et al. (2006), Experimental Research on the Optimal Surveillance Equipment Allocation Using Geo-Spatial Information, The Korea Institute of Military Science and Technology, 9(1), 72-79.
Lee, S. H. and Jeong, I. C. (2006), Optimal Allocation Model of KDX for Missile Defense, The Korea Society for Simulation, 15(4), 69-77.
Osman, M. S., Abo-Sinna, M. A., and Mousa, A. A. (2005), An effec- tive genetic algorithm approach to multiobjective resource alloca- tion problems(MORAPs), Applied Mathematics and Computation, 163(2), 755-768.
Seo, S. C. and Jung, K. R. (1997), An Optimal Surveillance Units Assign- ment Model Using Integer Programming, Military Operations Re- search Society of Korea, 23(1), 14-24.