제 2 절 구현 결과 ·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·27
제 3 절 측정 지표 및 제공 정보 ·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·29
제 4 장 머신러닝 기법을 통한 시스로그 분석 방안 제
언 ·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
34
제 1 절 필요성 ·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·34
제 2 절 제안 방법 ·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·36
1. 로그 수집 ···36 2. 전처리 ···37 3. 메시지 기반 군집화 ···37제 3 절 실험 결과 ·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·38
1. 실험 환경 ···38 2. 실험 결과 ···39참고문헌
···41표 차 례
표 1. Resource and URLs. Source: Intel Rack Scale Design PSME REST – API Sepcification. 2016-09 ···13표 2. Resources and URLs. Source: Intel Rack Scale Design POD Manager – API Sepcification. 2016-09 ···16
표 3. Syslog 출력 형식. ···35
그 림 차 례
그림 1. 블레이드 서버 ···7
그림 2. 마이크로 서버 ···8
그림 3. 하드웨어 기술 동향 (인텔 자료) source: Data Center & Connected Systems Group, “Intel Rack Scale Architecture Overview,” 2013-05-09. ···9
그림 4. 하드웨어 기술 동향 (인텔 자료) source: Data Center & Connected Systems Group, “Intel Rack Scale Architecture Overview,” 2013-05-09. ···9
그림 5. Pod Logical Hierarchy. Source: Intel Rack Scale Design. Architectural Requirements Specification. 2016-08. ···10
그림 6. Intel Rack Scale Design component location identification. Source: Intel Rack Scale Design. Architectural Requirements Specification. 2016-08. ···11
그림 7. PSME REST API hierarchy. Source: Intel Rack Scale Design PSME REST – API Sepcification. 2016-09 ···12
그림 8. POD Manager REST API hierarchy. Source: Intel Rack Scale Design POD Manager – API Sepcification. 2016-09 ···15
그림 9. ELK (Elasticsearch, Logstash, Kibana) framework. ···22
그림 10. ELK를 통한 로그 수집 및 분석 프레임워크. ···25
그림 11. 차세대 슈퍼컴퓨터 운영관리 시스템 아키텍쳐. ···26
그림 12. OCP 장비를 통한 Intel RSD 테스트베드 구축 설계도. ···27
그림 13. Intel RSD POD Manager API 연동. ···27
제 1 장 Intel RSD 기반 하드웨어 관리
제
1 절 Intel RSD
1. Intel RSD 소개
일반적으로 서버는 CPU, 메모리, 디스크, NIC 카드 등 다양한 디바이스로 구성 되며 제작된 형태에 따라 다음 종류로 구분해 볼 수 있다. □ Blade Server 그림 1. 블레이드 서버 블레이드 서버는 웹서비스와 같은 단일 작업 실행에 전념할 수 있도록, 하나 이 상의 CPU와 메모리를 담고 있는 얇고 모듈화된 전자 기판을 통해 제작된 서버이 다. 보통 하나의 캐리어에 다수의 블레이드 서버를 패키지함으로써 집적도를 높일 수 있다. □ Micro Server 그림 2. 마이크로 서버닝을 제공하며, 이를 통해 서비스 제공 속도를 높입니다.
⓶ 자원 활용과 상호 운용성을 개선하여 운영 효율성을 극대화합니다.
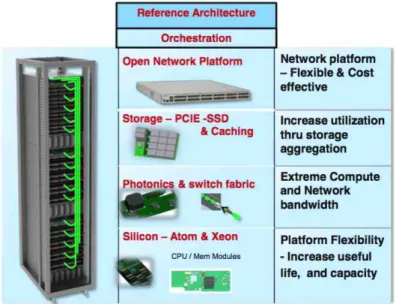
그림 3. 하드웨어 기술 동향 (인텔 자료) source: Data Center & Connected Systems Group, “Intel Rack Scale Architecture Overview,” 2013-05-09.
그림 4. 하드웨어 기술 동향 (인텔 자료) source: Data Center & Connected Systems Group, “Intel Rack Scale Architecture Overview,” 2013-05-09.
2. 아키텍쳐
인텔 RSD의 계층 구소는 아래의 그림과 같다. 관리 대상은 Blade, Module, Drawer, Rack, Pod로 구분하고 있으며 이를 BMC (Baseboard Management Controller), MMC (Module Management Controller), PSME(Pooled system management engine), RMM (Rack Management Module), PODM(POD Manager) 등 핵심 요소들이 연동되어 자원을 관리하고 있다.
그림 5. Pod Logical Hierarchy. Source: Intel Rack Scale Design. Architectural Requirements Specification. 2016-08.
그림 6. Intel Rack Scale Design component location identification. Source: Intel Rack Scale Design. Architectural Requirements Specification. 2016-08.
3. Intel RSD 구성 요소
인텔 RSD는 컴퓨팅, 패브릭, 스토리지 및 관리 모듈이 유기적으로 연동되어 광범위한 가상 시스템을 구축한다. 이는 다음과 같은 아래 4가지의 구성 요소를 토 대로 구축된다. □ Pod Manager : 멀티 랙을 관리합니다. 하드웨어 아랫단과 오케스트레이션 계층 위단 위치하며, 자원과 정책을 관리하고 표준 인터페이스를 통해 구현되는 펌웨 어이자 소프트웨어 API입니다.□ Pooled System : 컴퓨팅, 네트워크 및 스토리지 자원 풀(pool)을 워크로드 요구 사항에 따라 구성하는 시스템입니다.
□ Pod-wide storage : Pod 규모 스토리지(이더넷으로 연결된 스토리지 기반)에 멀티 랙 자원 또는 스토리지 하드웨어 및 컴퓨팅 노드(로컬 스토리지 포함)로 구축되며, 다양한 활용이 가능한 스토리지 알고리즘이 사용됩니다.
□ Configurable network fabric : 최신 TOR(Top-Of-Rack) 스위치 설계와 플랫 폼을 통한 분산 스위치 등 경제적인 네트워크 토폴로지를 다양하게 지원합니다.
4. Intel RSD 주요 API
□ PSME REST API
Resource URI
Service Root /rest/v1
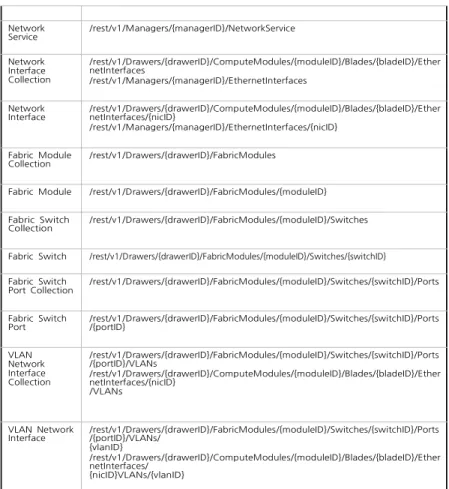
Drawer Collection /rest/v1/Drawers Drawer /rest/v1/Drawers/{drawerID} Comput e Module Collecti on /rest/v1/Drawers/{drawerID}/ComputeModules Compute Module /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID} Blade Collection /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades Blade /rest/v1/Drawers/{drawerID}//ComputeModules/{moduleID}/Blades/{bladeID} Processors Collection /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Proc essors Processor /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Proce ssors/{processorID} Memory Collection /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Mem ory Memory /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Mem ory/{memoryID} Storage Controllers Collection /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Stora geControllers Storage
Controller /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/StorageControllers/ {controllerID} Drives Collection /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Stora geControllers/ {controllerID}/Drives Drive /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Stora geControllers/ {controllerID}/Drives/{driveID} Manager collection /rest/v1/Managers Manager /rest/v1/Managers/{managerID} Network Service /rest/v1/Managers/{managerID}/NetworkService Network Interface Collection /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Ether netInterfaces /rest/v1/Managers/{managerID}/EthernetInterfaces Network Interface /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Ether netInterfaces/{nicID} /rest/v1/Managers/{managerID}/EthernetInterfaces/{nicID} Fabric Module Collection /rest/v1/Drawers/{drawerID}/FabricModules
Fabric Module /rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}
Fabric Switch Collection
/rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}/Switches
Fabric Switch /rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}/Switches/{switchID} Fabric Switch Port Collection /rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}/Switches/{switchID}/Ports Fabric Switch Port /rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}/Switches/{switchID}/Ports /{portID} VLAN Network Interface Collection /rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}/Switches/{switchID}/Ports /{portID}/VLANs /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Ether netInterfaces/{nicID} /VLANs VLAN Network Interface /rest/v1/Drawers/{drawerID}/FabricModules/{moduleID}/Switches/{switchID}/Ports /{portID}/VLANs/ {vlanID} /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bladeID}/Ether netInterfaces/ {nicID}VLANs/{vlanID}
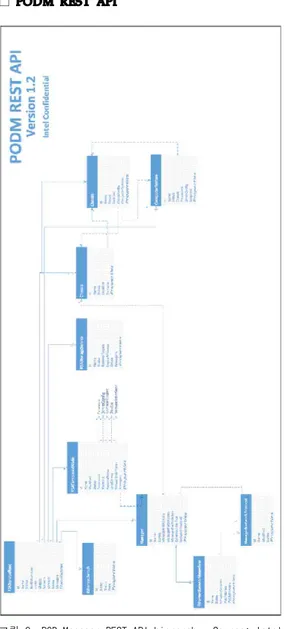
□ PODM REST API
그림 8. POD Manager REST API hierarchy. Source: Intel Rack Scale Design POD Manager – API Sepcification. 2016-09
Resource URI
Service Root /rest/v1 PodCollection /rest/v1/Pods
POD /rest/v1/Pods/{podID}
Rack Collection /rest/v1/ Pods/{podID}/Racks Rack /rest/v1/Pods/{podID}/Racks/{rackID} Drawer Collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers Drawer /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID} Compute Module
Collection
/rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es
Compute Module /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}
Blade Collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades
Blade /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}
Processor Collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}/Processors
Processor /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}/Processors/{processorID}
Memory collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}/Memory
Memory /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}/Memory/{memoryID}
Storage controller
collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModules/{moduleID}/ Blades/{bladeID}/ StorageControllers Storage controller /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul
es/{moduleID}/ Blades/{bladeID}/StorageControllers/{controllerID} Drive collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul
es/{moduleID}/ Blades/{bladeID}/ StorageControllers/{controllerID}/Drives
Drive /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/
Blades/{bladeID}/StorageControllers/{controllerID}/Drives/{driveID} Manager Collection /rest/v1/Managers
Manager /rest/v1/Managers/{managerID}
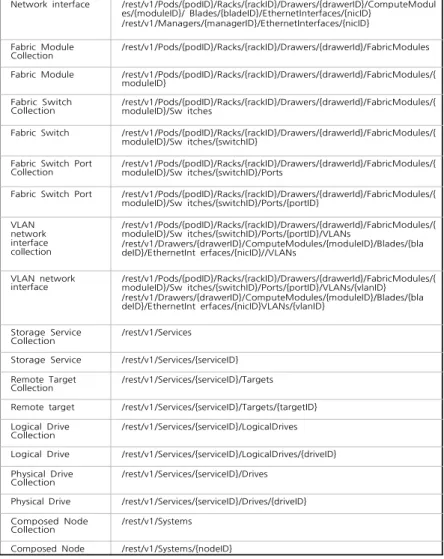
Network service /rest/v1/Managers/{managerID}/NetworkService Network interface
collection
/rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}/EthernetInterfaces
Network interface /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerID}/ComputeModul es/{moduleID}/ Blades/{bladeID}/EthernetInterfaces/{nicID}
/rest/v1/Managers/{managerID}/EthernetInterfaces/{nicID} Fabric Module
Collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules Fabric Module /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{
moduleID} Fabric Switch
Collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{moduleID}/Sw itches Fabric Switch /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{
moduleID}/Sw itches/{switchID} Fabric Switch Port
Collection
/rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{ moduleID}/Sw itches/{switchID}/Ports
Fabric Switch Port /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{ moduleID}/Sw itches/{switchID}/Ports/{portID} VLAN network interface collection /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{ moduleID}/Sw itches/{switchID}/Ports/{portID}/VLANs /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bla deID}/EthernetInt erfaces/{nicID}//VLANs VLAN network interface /rest/v1/Pods/{podID}/Racks/{rackID}/Drawers/{drawerId}/FabricModules/{ moduleID}/Sw itches/{switchID}/Ports/{portID}/VLANs/{vlanID} /rest/v1/Drawers/{drawerID}/ComputeModules/{moduleID}/Blades/{bla deID}/EthernetInt erfaces/{nicID}VLANs/{vlanID} Storage Service Collection /rest/v1/Services
Storage Service /rest/v1/Services/{serviceID} Remote Target
Collection /rest/v1/Services/{serviceID}/Targets Remote target /rest/v1/Services/{serviceID}/Targets/{targetID} Logical Drive
Collection /rest/v1/Services/{serviceID}/LogicalDrives Logical Drive /rest/v1/Services/{serviceID}/LogicalDrives/{driveID} Physical Drive
Collection /rest/v1/Services/{serviceID}/Drives Physical Drive /rest/v1/Services/{serviceID}/Drives/{driveID} Composed Node
Collection
/rest/v1/Systems
Composed Node /rest/v1/Systems/{nodeID}
수 있다. 일반적으로 송신 시스템에서는 에러 발생 여부를 감지하는 데이터 무 결성을 검사하기 위해 CRC (Cyclic Redundancy Check) 비트를 추가하여 전송 하고 수신 시스템에서는 CRC 비트를 이용하여 에러를 감지한다.
□ 대역폭 (Bandwidth): 네트워크에서 처리 가능한 비트수로 처리율(Throughput) 또는 전송율 (transfer rate)라고도 부른다. 대역폭은 Capacity, Available bandwidth로 구분할 수 있다. Capacity는 네트워크의 최대 처리량을 의미한다. 가용 대역폭은 현재 사용할 수 있는 대역폭으로 Capacity에서 현재 사용량을 제 외한 값이다.
2. 능동 모니터링 기법
□ 능동 모니터링 방식은 측정을 위해서 별도의 측정 패킷 (Probe Packet)을 이용 하는 방식이다. 주로 가용 대역폭 (available bandwidth), 병목(bottleneck) 지점 검출, 그리고 특정경로상의 지연, 지터, 손실률등을 측정하는데 주로 이용된다. 대표적인 능동 모니터링 방식으로는 ICMP 패킷을 활용하는 Ping과 TraceRoute 가 있다. 능동 모니터링 방식은 측정 패킷의 크기가 작고 분석해야 할 패킷의 양이 적기 때문에 측정 패킷을 받아서 분석하는 시스템의 부하가 크지 않다. 반 면, 실제 사용자 트래픽을 측정하는 것이 아닌 경로의 상태를 측정하기 때문에 사용자가 체감하는 네트워크 상태와 차이가 있을 수 있다. 또한 네트워크가 용 대역폭이 낮은 경우에는 측정 데이터가 사용자 데이터와 경쟁하기 때문에 네트 워크 상태를 더욱 악화시키는 문제점이 있다.
3. 수동 모니터링 기법
□ 수동 모니터링 방식은 별도의 측정 패킷을 만들지 않고 사용자 트래픽을 이용하 여 네트워크 상태를 모니터링 하는 방식으로 사용자 트래픽의 전송율이나 데이 터 플로우의 지연, 지터, 손실률과 같은 전송 상태를 측정하는데 적합하다. 대표 적인 수동 모니터링 방식으로는 탭(Tap)이나 미러링(Mirroring)을 이용하여 사 용자 트래픽을 모니터링 하는 방법이 있다. 수동 모니터링 방식은 별도의 측정 패킷을 전송하기 않기 때문에 네트워크의 부하 증가 없이 사용자의 데이터 플로 우를 측정할 수 있다는 장점이 있지만 측정해야 할 패킷의 크기가 크고 패킷의 수가 많기 때문에 분석하는 시스템의 부하가 커질 수 있다. 또한 사용자 트래픽 이 송수신 되는 동안에만 측정이 가능하기 때문에 경로의 상태를 측정하기에는 부적합하다.4. 혼성 모니터링 기법
□ 최근 들어 측정 성능을 증대시키기 위해서 능동 모니터링 방식과 수동 모니터링 방식을 혼용하여 사용하려는 노력이 확대되고 있다[2][3]. [2]에서는 그리드 상 에서 확장성 있는 측정을 위해서 그리드 응용 프로그램이 실행되고 있는 동안에 는 응용 프 로그램의 패킷을 활용한 수동 모니터링 방식을 사 용하고, 응용 프 로그램이 실행되지 않는 동안에만 능동 모니터링 방식을 이용하는 방법을 제안 하였다. [3]에서는 종단간 성능 향상을 위해서 능동 모니터 링 방식과 수동 모 니터링 방식을 통해 측정된 결과 를 비교, 분석하여 성능 저하의 원인을 판단하 고 제 거함으로써 종단간 성능 향상시키기 위한 혼성 모니터링 방식을 연구하였 다.제
2 절 컴퓨팅 모니터링 기법
1. 측정 지표
□ 온도/팬속도: 일반적으로 시스템의 온도는 시스템의 수명 및 성능에 많은 영향을 미치므로 매우 중요한 측정 지표이다. 그러므로 서버 보드에는 온도를 감지하고 제어할 수 있도록 센서가 부착되어 있으며 팬 속도를 제어함으로써 온도를 조절 할 수 있다. 이를 위한 온도 및 팬 속도 측정 및 제어는 BMC (Baseboard Management Controller)를 통해 데이터 접근 및 설정이 가능하다. □ 소비 전력: 최근 저전력에 대한 요구사항이 증가함에 따라 소비되는 전력량을 줄이고 성능을 향상시키기 위한 연구가 많이 진행되고 있다. 이를 위해서는 메 인 보드에서 소비되는 전력을 정확히 측정해야 한다. □ CPU 및 메모리 사용량: 시스템 자원의 이용 상태를 확인할 수 있는 가장 기본 적인 정보로 리눅스의 경우 Top 명령어를 통해 확인이 가능하다. □ 디스크 사용량: 시스템을 구성하는 스토리지의 사용량을 나타내는 지표로 전체 디스크 용량, 현재 사용량, 가용 디스크 용량등을 확인할 수 있다.□ 작업 현황: 사용자의 작업의 상태를 나타내는 지표로 스케줄러에서 출력된 로그 파일을 분석하여 측정할 수 있다. 대부분의 스케줄러 로그에는 작업의 제출 시 간, 작업별 자원 할당량, 대기 시간, 및 작업 종료 시간등이 포함되어 있어 작업 통계를 구할 수 있다. 스케줄에 따라 로그를 출력하는 항목, 방식이 서로 다르기 때문에 [5]에서는 표준화된 워크로드 형식으로 아래의 항목을 정의하고 있다. ü Job Number: 정수로 표기된 작업 번호. 로그파일에 기록된 첫 번째 작업을 1로하여 순차적으로 부여함. ü Submit Time: 초 단위로 기록된 작업 제출 시각. 로그파일에 기록된 1번 작업의 제출 시간을 0으로 하여 제출된 시간의 차이를 기록. ü Wait Time: 초 단위로 기록된 큐 대기 시간. 작업 제출 시각과 실제 작업이 실행한 시각의 차이로 기록. ü Run Time: 초 단위로 기록된 작업 실행 시간. 작업이 시작된 시각과 종료 된 시각의 차이로 기록됨.
ü Number of Allocated Processors: 작업에 할당한 프로세서의 수. ü Average CPU Time Used: 초 단위로 기록된 CPU 사용 시간. ü Used Memory: KB 단위로 기록된 메모리 사용량.
ü Requested Number of Processors: 사용자에 의해 요청된 프로세스 수. ü Requested Time: 초 단위로 기록된 사용자가 예측한 작업 실행 시간. ü Requested Memory: KB 단위로 기록된 사용자에 의해 요청된 메모리 용 량. ü Status: 정수로 기록된 작업 상태 코드 (0~5 값으로 표기). ü User ID: 사용자 아이디. ü Group ID: 그룹 아이디.
ü Executable (Application) Number: 동일한 워크 로드에 있는 다수의 응용 프로그램을 구분하기 위해 기록된 값.
ü Queue Number: 하나의 시스템에 다수의 큐가 존재 할 경우 이를 구분하기 위해 기록된 값.
ü Partition Number: 하나의 시스템에 다수의 파티션(partition)이 존재 할 경우 이를 구분하기 위해 기록된 값.
ü Preceding Job Number: 본 작업이 시작하기 전에 종료 되어야하는 이전 작업.
ü Think Time from Preceding Job: 초 단위로 기록된 값으로 이전 작업이 종료 되고 제출된 작업이 시작 할 때까지의 시간.
2. ELK
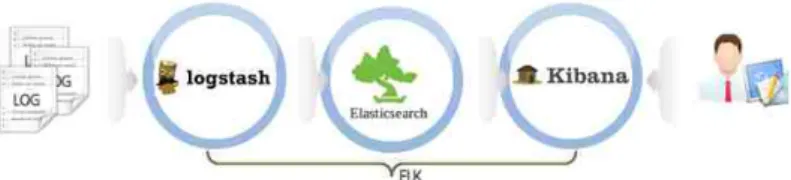
□ 기술의 정의
ELK Stack은 Elasticsearch, Logstash, Kibana의 약자로서 Elasticsearch는 Apache의 Lucene을 바탕으로 개발한 실시간 분산 검색 엔진이며, Logstash는 각종 로그를 가져와 JSON 형태로 만들어 Elasticsearch로 전송하고 Kibana는 Elasticsearch에 저장된 Data를 사용자에게 Dashboard 형태로 보여주는 Solution이 다.
ElasticSearch는 Apache Lucene을 기반으로 하는 분산 검색엔진이지만, 그 자체 로 파일를 저장하는 NoSQL 형식의 데이터베이스이다. 따라서 대규모 시스템의 로 그와 같이 분산된 시스템의 로그를 수집하여 인덱스를 생성/관리하는데 매우 유용 하다.
그림 9. ELK (Elasticsearch, Logstash, Kibana) framework.
○ ElasticSearch : Apache의 Lucene을 바탕으로 개발한 실시간 분산 검색 엔진
○ Logstash : Logstash는 각종 로그를 가져와 JSON형태로 만들어 ElasticSearch로 전송
보여주는 Solution □ 기술의 특징 ELK는 설치와 확장이 용이한 오픈소스 기반의 소프트웨어 스택이다. ELK는 다 음과 같은 특징을 가지고 있다. ○ 루씬 기반: Elasticsearch는 다국어 검색 지원, 자동 완성 지원, 미리보기 지원등 다양한 기능을 지원하는 루씬을 기반으로 만들어져 유연하고 편 리한 인텍싱을 지원한다. ○ 분산 시스템 지원: 유연한 분산 시스템을 지원한다. 특히 시스템의 손쉽 게 시스템을 확장함으로써 대용량 데이터 분석에 용이하다. 또한 데이터 는 분산 자장되고 복사본을 유지하여 노드 데이터를 안전하게 보호할 수 있다. 또한 Discovery 기능이 내장되어 별도의 분산 시스템 관리자가 필 요하지 않다. ○ Multi-tenacy 지원: 하나의 데이터를 여러 개의 분리된 인덱스들의 그룹 으로 저장할 수 있다. 즉, 데이터의 속성에 따라 인덱스를 다르게 할당하 여 유연한 검색이 가능하다. ○ 문서 (JSON) 포맷 구조 사용: JSON 구조로 인하여 모든 레벨의 필드에 쉽고 빠 르게 접근이 가능하며 사전 매핑 없이 JSON 문서 형식으로 데이터를 바로 입력 하여 색인 작업을 수행할 수 있다. 또한 REST API 지원을 통해 HTTP Method 행태로 사용이 가능하다. ○ 실시간 분석 지원: 저장된 데이터는 검색을 위해 별도의 갱신을 필요로 하지 않 는다. 즉, 색인 작업이 완료됨과 동시에 바로 검색이 가능하다.
3. 구현 방안
클러스터 운영하는데 있어 다수의 시스템에서 발생하는 다양한 이벤트 로그 또 는 상태 정보를 일관된 형태로 관리하는 기법은 매우 중요하다. 이를 위해 ELK 소 프트웨어 스택을 이용하여 물리적인 장비에 장착된 센서로부터 측정한 정보(온도, 팬 속도, 소비전력), 시스템 자원 활용 현황 (CPU, 메모리, 디스크 사용량), 작업 수행 및 큐 현황 (작업 시작 시간, 작업 종료 시간, 사용된 자원량, 큐 상태)를 동 일한 형태로 일원화 하여 관리하도록 한다. ○ 노드들에서 쏟아져나오는 로그(대표적으로 Syslog)는 Filebeat를 통해 수집/전 송○ 소위 ELK (ElasticSearch / Logstash / Kibana)를 통해 로그를 수집/가공/저장/ 검색 및 시각화
ü 각 노드에서의 로그 수집 (Ship Logs) - Filebeat / Topbeat: ELK에서는 packetbeat, filebeat, topbeat, winlogbeat등 다양한 Beat를 통해 실시간으 로 데이터를 수집한다. 본 보고서에서는 이중 filebeat와 topbeat에 대해서 알아본다. Filebeat는 syslog와 같이 /var/log에 쌓이는 로그 파일을 수집하 여 전송한다. Topbeat는 이름에서 확인할 수 있듯이 리눅스 명령어의 Top 과 유사하게 아래의 시스템 정보를 실시간으로 수집하여 elasticsearch로 전송한다.
F system: 시스템 자원 상태 수집. (system load, cpu useage, memory useage, swap useage)
F process: 프로세스별 분석데이터 수집. (process name, parent pid, state, pid, cpu useage, memory useage)
F filesystem: 파일시스템 분석데이터 수집. (마운트된 디스크의 총량, 사 용량, 각 디스크의 이름, 마운트위치 등)
F cpu_per_core: core별 cpu 사용량 수집
ü 로그의 처리와 인덱싱 (Process & Filtering) - Logstash: Filebeat, Topbeat를 비롯하여 다양한 로그 데이터를 가공하여 출력한다. 이를 위해 Input, Filter, Output으로 구성된 pipeline 구조로 구성된다.
F Input: 수집할 데이터를 정의한다. 기본적으로 약 40종 이상을 제공하 며 Apache accesslog나 log4j에서 발생하는 로그를 수집하기 위해서는 일반적으로 file이나 tcp를 이용하여 데이터를 수집한다.
F Filter: input으로 정의된 로그에 대해서 parsing을 지원하기 위한 설정 이다. filter에서 사용되는 RegExp 패턴들은 logstash 폴더 내 patterns 폴더 하위에 적재되어 있는데 필요한 경우 이 pattern들을 활용하여 데 이터를 좀 더 쉽게 가공할 수 있다.
ü 로그의 저장(Store & indexing) - ElasticSearch: 수집된 로그를 저장하고 검색을 지원하기 위해 인텍스를 생성하여 관리한다. elasticsearch는 기본 적으로 검색엔진이지만 NoSQL처럼 비정형 데이터베이스로 사용이 가능하 다. 데이터 모델을 JSON으로 사용하고 있어서, 요청과 응답을 모두 JSON 으로 주고 받고 소스 저장도 JSON 형태로 저장한다.
제
2 절 구현 결과
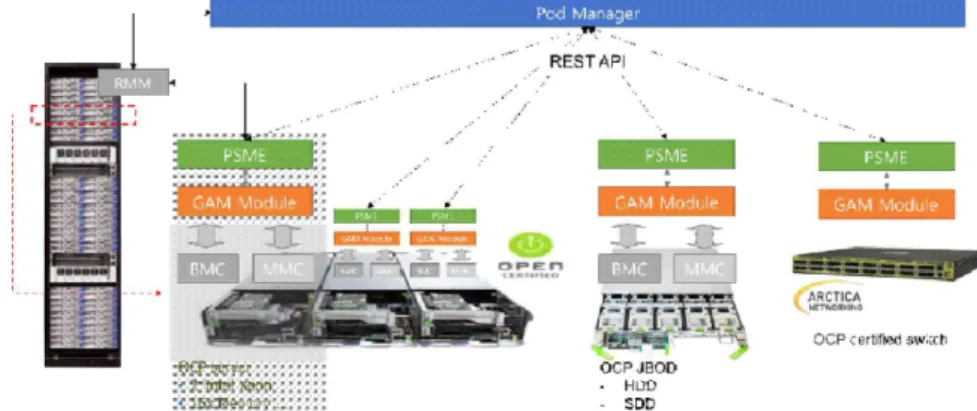
그림 12. OCP 장비를 통한 Intel RSD 테스트베드 구축 설계도.
<그림 12>는 OCP 장비를 이용하여 Intel RSD 테스트 베드를 구축한 설계도이 다. 본 그림에서 확인할 수 있듯이 OCP 서버에 PSME 모듈을 설치하여 PoD Manager를 통해 서버 정보를 수집하고 수집된 결과를 구현된 대시보드를 통해 사 용자에게 보여준다.
그림 13. Intel RSD POD Manager API 연동.
□ Intel RSD PODM API 가 제공하는 노드 정의 명령 ("/redfish/v1/Nodes/Actions/Allocate")을 이용하여 노드를 정의하고 노드 생성 명령("/redfish/v1/Nodes/1/Actions/ComposedNode.Assemble")을 호출하면, Logical Node가 생성됨.
그림 18. 스위치 포트별 상세 정보 구현 화면.
○ 인프라 자원 관리 모듈
Field Descript
ID Event log message ID
Received Time The received time of the syslog event in server.
Device Reported Time The reported time of the syslog event in device.
Facility The facility code to specify the type of program that is logging the message.
Severity Level The severity code to indicate relative importance.
Fromhost The machine that originally sent the syslog event.
Message A free-form message that provides information about the event. 표 3. Syslog 출력 형식. 터 포맷과 일치한다. 즉, 대부분의 경우 시스로그 이벤트 메시지에 있는 데이터 필드를 발생 시간에 따라 나열하고 키워드를 통한 필터링 기능을 제공하는 경우가 대부분이다. 그러나 이 경우 다음과 같은 문제가 있다. 첫째, 중복된 로그 메시지가 많다. 대부분의 에러 메시지의 경우 문제가 해결되 지 않은 동안 일정한 주기로 반복되어 로그 메시지가 출력된다. 예를 들어 NTP (Network Time Protocol) 서버에 연결상 문제가 발생한 경우 주기적으로 에러 메 시지가 출력된다. 이 경우 운영자 입장에서는 시스템 전체 운영에 있어 치명적인 문제가 아니기 때문에 대부분 수정하지 않은 경우가 많아 동일한 메시지가 주기적 으로 출력된다. 둘째, 에러의 원인 파악은 어렵다. 시스로그 메시지를 통해 원인을 파악하기 위해서는 대부분 관리자가 메시지 내용을 분석해야 한다. 그러나 <표3> 과 같은 형식으로 메시지가 출력될 경우 관리자는 에러의 원인을 규명하기 위해서 모든 메시지 내용을 확인해야 한다. 셋째, 에러 메시지간의 연관성을 파악하기 어렵 다. 일반적으로 하나의 근본적인 원인 (Root Cause)으로 인해 많은 형태의 에러 메 시지가 발생할 수 있다. 예를 들어 Network Interface Card 드라이버 문제가 발생 한 경우 NTP 서버, 스케줄러 서버등 네트워크를 통한 모든 연결상의 에러 메시지 가 동시에 출력된다. 그러므로 이를 분석하기 위해서는 동일한 행태의 메시지를 그 룹화하고 발생 연관성을 파악해야 근본적인 원인을 유추해 볼 수 있다. $ModLoad immark $ModeLoad imtcp $InputTCPServerRun portNum $ModLoad ommysql *.* :ommysql:database-server,database-name,database-userid,database-password use_syslog=True syslog_log_facility=LOG_LOCAL0
제
2 절 제안 방법
본 절에서는 시스템에서 발생한 근본적인 결함을 검출하고 운영자로 하여금 에 러 메시지의 가독성을 향상시키기 위해 메시지 내용을 기반으로 한 클러스터링 기 법을 제시한다. 또한 최근 많이 사용하는 오픈소스 기반의 클라우드 관리 플랫폼 오픈 스택 시스템을 대상으로 로그 메시지를 수집하고 수집된 제시된 클러스터링 기법을 적용한 예를 살펴본다.1. 로그 수집
참고 문헌
(1) 권원옥, et. al. “마이크로서버 기술 동향,” Electronics and Telecommunications Trends, vol. 29, no. 4 2014. pp. 49-58.
(2) B.B. Lowekamp. "Combining active and passive network measurements to build scalable monitoring systems on the grid." Performance Evaluation Review, 30(4): 19-26, 2003.
(3) J.-W. Park and J.Kim, "Quality monitoring for real- time IP media transport over multi-point delivery environment," IEEE Transaction on Consumer Electronics, 54(4):2060-2067, Nov. 2008.
(4) R. Gerhards. The syslog protocol. RFC 5424. 2009.
(5) A. B. Downey and D. G. Feitelson, “The elusive goal of workload characterization,”ACM SIGMETRICS Performance Evaluation Review, vol. 26, pp. 14-29, 1999.
(6) Reips, Ulf-Dietrich, and Stefan Stieger. "Scientific LogAnalyzer: A Web-based tool for analyses of server log files in psychological research." Behavior Research Methods, Instruments, & Computers 36.2 (2004): 304-311.
(7) Gerhards, R., The syslog protocol, RFC 5424, 2009.
(8) Pitakrat, T., Grunert, J., Kabierschke, O., Keller, F., and Hoorn, A., “A framework for system event classification and prediction by means of machine learning,” in Proc. of the 8th International Conference on Performance Evaluation Methodologies and Tools. ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), 2014, pp. 173-180.
(9) R development core team, R : A language and environ- ment for statistical computing, [Online], Available : http://www.r-project.org.
※ 저자 정보
이름 소속/연락처
박주원 슈퍼컴퓨터시스템개발실/[email protected]
조혜영 슈퍼컴퓨터시스템개발실/[email protected]