포인터 네트워크를 이용한 대명사 상호참조해결
박천음 이창기 강원대학교 컴퓨터과학과 {parkce, leeck} @ kangwon.ac.kr
Coreference Resolution for Pronouns with Pointer Networks
Cheoneum Park, Changki Lee
Kangwon National University Dept. of Computer Science
요 약
포인터 네트워크(Pointer Networks)는 어텐션 메커니즘(Attention mechanism)을 이용하여 입력 시퀀스에 대응 되는 위치들의 리스트를 출력하는 Recurrent Neural Network (RNN)의 확장된 모델이다. 문서 내에 등장한 대명사는 이와 대응되는 선행사와 참조관계에 있으며, 이때 대명사와 선행사는 하나의 엔티티로 정의된 다. 본 논문에서는 포인터 네트워크를 이용하여 대명사와 선행사의 참조관계를 밝히는 대명사 상호참조 해결 방법을 제안한다. 실험 결과, 본 논문에서 제안한 방법의 MUC F1 값이 약 77.76%로 기존 한국어 대 명사 상호참조해결(55.49%)보다 22.27% 우수한 성능을 보였다.
1. 서 론
대명사는 일반적으로 먼저 언급한 내용이나 단어(즉, 선행사) 를 다시 표현할 때 사용되며, 한정 명사구(즉, 한정사구)는 지 시 관형사와 일반 명사의 조합으로 선행사를 다시 표현할 때 사용된다. 대명사 상호참조해결(또는 대용어 해결)은 문서 내 에서 등장한 대명사나 한정사구가 어떤 선행사를 가리키고 있 는지를 밝히는 문제다. 담화나 문서 내에서 대명사나 한정사 구를 사용하면 특정 대상에 대한 정보를 일관성 있게 유지할 수 있으며, 현재 문맥에서 중심이 되는 내용을 더욱 잘 전달 할 수 있어 빈번히 사용된다. 이에 따라, 대명사 상호참조해결 은 문맥을 이해하는데 중요한 역할을 하며, 질의 응답, 문서 요약, 기계 번역 등에 응용될 수 있다.
상호참조해결 시스템은 크게 규칙기반과 통계기반으로 나눌 수 있다. 이 중 규칙 기반 시스템은 선행사들에 대하여 문법적 인 특성과 등장한 위치, 개체명, 성별, 인칭, 단복수 등의 의미에 대하여 일관성 있는 규칙을 정의해야 하므로 규칙을 정의한 사 람에게 매우 의존적이고, 유지보수도 어렵다. 통계 기반은 기계 학습 등을 이용하는 방법으로, 일반적으로 규칙 기반에 비해 보 다 좋은 성능을 보이지만, 자질 디자인이 잘 되어야 한다는 제 약이 있다. 일반적인 기계학습은 사람이 직접 자질을 추출하고 최적의 자질 조합을 찾아야 하는데, 이는 많은 시간과 노력을 필요로 한다.
최근 딥 러닝(Deep learning)의 등장으로 앞서 언급한 기계학습 의 어려움들을 극복할 수 있게 되었으며 자연어처리에서도 활 발히 연구되고 있다[1]. 본 논문에서는 딥 러닝 모델 중 하나인 포인터 네트워크(Pointer Networks)[2]를 이용한 대명사 상호참조 해결을 제안한다. 포인터 네트워크는 어텐션 메커니즘(Attention mechanism)[3]을 이용하여 입력 시퀀스에 대응되는 위치를 출력 하는 Recurrent Neural Network (RNN)의 확장된 모델이다.
본 논문의 구성은 다음과 같다. 2장에서 대명사 상호참조해결 에 대한 관련 연구를 설명하고, 3장에서 포인터네트워크에 대하
여 설명한다. 4장에서 본 논문에서 제안한 포인터 네트워크를 이 용한 대명사 상호참조해결에 대하여 설명하고, 5장에서 이에 대 한 실험 및 결과를 보인다.
2. 관련 연구
대명사 상호참조해결의 규칙기반 방법은 다단계시브(Multi-pass sieve) 모델[4] 등이 있으며, 통계기반 방법은 멘션 페어 (Mention pair) 모델[5] 등이 있다. 스탠포드(Stanford)의 다단계 시브 모델에서는 대명사와 엔티티의 속성, 개체명 정보 등을 이용하여 상호참조를 해결한다. 멘션 페어 모델은 현재 등장 한 멘션과 임의의 선행사를 하나의 쌍으로 만들고 기계학습을 이용하여 서로 참조관계인지 아닌지를 판별하는 방법이다.
[6]에서는 규칙기반과 통계기반을 결합한 모델을 제안하고 이 를 적용하여 한국어 상호참조해결을 수행하였다. 규칙기반 방법 으로 다단계시브 모델을 한국어에 적합하게 수정하였고, 중심화 이론(Centering theory)[7]과 Resolution of Anaphora Procedure (RAP)[8] 알고리즘을 대명사 상호참조해결 시브에 적용하였다.
통계기반 방법으로는 딥 러닝 기반의 멘션페어 모델을 적용하 였다. [6]의 규칙기반 모델은 모든 데이터에 대하여 일관성 있는 규칙을 정의하는데 어려움이 있고, 엔티티의 속성정보가 부족하 거나 모호한 경우에도 어려움을 보였다. [6]의 멘션페어 모델은 하나의 쌍으로 입력된 단어들(현재 명사, 선행사)과 그 주변 문 맥만을 사용하기 때문에 선행사와 대명사가 멀리 떨어져 있는 경우에 오류가 많이 발생하였다. 본 논문에서는 선행사와 대명 사가 멀리 떨어져 있는 경우에도 문맥정보를 이용하도록 RNN 의 확장된 모델인 포인터 네트워크를 이용한다.
3. 포인터 네트워크
포인터 네트워크는 어텐션 메커니즘을 이용하는 RNN의 확장 모델이다. 일반적인 RNN은 입력과 출력이 1:1로 대응되는 순 차 데이터(sequence data)를 모델링 할 수 있으나, 입출력이
699
2016년 한국컴퓨터종합학술대회 논문집
𝑁: 𝑀 인 문제에 바로 적용하기 어렵다. RNN encoder-decoder[9]
모델은 두 개의 RNN 구조(encoder, decoder)로 구성되며, 인코 더(encoder RNN)에서 주어진 입력 열을 문맥 벡터(context vector) 𝑐 로 인코딩(encoding)한 후, 이를 이용하여 디코더 (decoder RNN)에서 결과 열을 생성하기 때문에 입출력이 𝑁: 𝑀 인 문제를 모델링 할 수 있다. 그러나 RNN encoder-decoder 모 델은 고정된 출력 사전 길이(output vocabulary size)를 갖기 때문 에 각 출력에 대한 타겟 클래스의 개수가 가변적인 문제(예를 들어, 입력 열 길이에 따라 변하는 문제)를 해결할 수 없다.
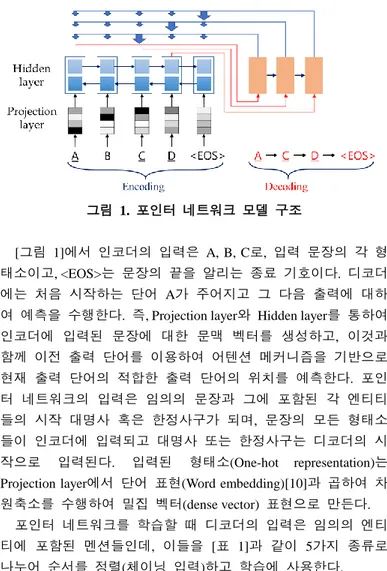
포인터 네트워크는 출력 클래스의 개수가 가변적인 (즉, 입력 열 길이에 따라 변하는) 문제를 처리할 수 있는 모델이다. 어텐 션 메커니즘은 인코더의 hidden state를 이용하여 생성된 문맥 벡 터와 현재까지 생성한 디코더의 hidden state를 입력으로 하여 입 력 중 어느 위치를 주의해서 봐야 할지(attention weight)를 결정 한다. 포인터 네트워크는 [그림 1]과 같이 attention weight(즉, 입 력열의 위치 별 확률)를 디코더의 출력으로 가지며, 현재 디코 더 단위(decoder unit)의 출력이 다음 디코더 단위의 입력이 된다.
본 논문에서는 인코더를 위해 bidirectional Gated Recurrent Unit(bi-GRU)[3]을 사용하며, 다음과 같이 정의한다.
ℎ⃗ 𝑠= 𝑓𝐺𝑅𝑈(𝐸(𝑥𝑠), ℎ⃗ 𝑠−1) ℎ⃖⃗𝑠= 𝑓𝐺𝑅𝑈(𝐸(𝑥𝑠), ℎ⃖⃗𝑠+1)
ℎ⃡𝑠= [ℎ⃗ 𝑠, ℎ⃖⃗𝑠]
여기서 ℎ⃗ 𝑠와 ℎ⃖⃗𝑠는 입력 열에 대한 Forward, Backward Network 이며, 𝐸(𝑥𝑠)는 단어표현(word embedding)을 적용하는 함수이다.
ℎ⃡𝑠는 ℎ⃗ 𝑠와 ℎ⃖⃗𝑠를 합(concatenate)한 것으로 입력 순서 정보와 역 순의 정보를 모두 본다. 입력 열 위치에 따른 조건부확률을 학습하는 디코더는 다음과 같이 정의된다.
ℎ𝑡= 𝑓𝐺𝑅𝑈(ℎ⃡𝑦
𝑡−1, ℎ𝑡−1)
𝑎𝑡(𝑠) = exp (𝑠𝑐𝑜𝑟𝑒(ℎ𝑡, ℎ⃡𝑠))
∑ exp (𝑠𝑐𝑜𝑟𝑒(ℎ𝑠 𝑡, ℎ⃡𝑠)) 𝑠𝑐𝑜𝑟𝑒𝑐𝑜𝑛𝑐𝑎𝑡(ht, ℎ⃡𝑠) = 𝑣𝑡𝑇tanh(𝑊𝑎[ℎ𝑡; ℎ⃡𝑠])
𝑦𝑡= argmax(𝑎𝑡(𝑠′))
ℎ𝑡는 디코더의 hidden state이며, 인코더와 디코더의 이전 시간 hidden state를 입력으로 받는다. 𝑎𝑡는 𝑠𝑐𝑜𝑟𝑒𝑐𝑜𝑛𝑐𝑎𝑡함수의 결과 벡 터에 𝑠𝑜𝑓𝑡𝑚𝑎𝑥를 이용하여 정규화한 값(즉, attention weight)이며, 입력 열의 위치를 가리킨다. 𝑠𝑐𝑜𝑟𝑒𝑐𝑜𝑛𝑐𝑎𝑡 함수는 ℎ𝑡와 ℎ⃡𝑠를 합 (concatenate)하여 alignment score를 계산한다. 본 논문에서는 beam search를 이용하여 최적의 출력 열을 선택한다.
4. 포인터 네트워크를 이용한 대명사 상호참조해결
대명사 상호참조해결은 대명사나 한정사구와 의미가 같은 선 행사들을 연결하는 문제이다. 포인터 네트워크는 입력 열에 대응되는 위치를 출력 열로 생성한다. 이에 따라 본 논문에서 는 대명사 상호참조해결에 포인터 네트워크를 이용할 것을 제 안한다. 포인터 네트워크에 대한 모델 구조는 [그림 1]과 같다.
그림 1. 포인터 네트워크 모델 구조
[그림 1]에서 인코더의 입력은 A, B, C로, 입력 문장의 각 형 태소이고, <EOS>는 문장의 끝을 알리는 종료 기호이다. 디코더 에는 처음 시작하는 단어 A가 주어지고 그 다음 출력에 대하 여 예측을 수행한다. 즉, Projection layer와 Hidden layer를 통하여 인코더에 입력된 문장에 대한 문맥 벡터를 생성하고, 이것과 함께 이전 출력 단어를 이용하여 어텐션 메커니즘을 기반으로 현재 출력 단어의 적합한 출력 단어의 위치를 예측한다. 포인 터 네트워크의 입력은 임의의 문장과 그에 포함된 각 엔티티 들의 시작 대명사 혹은 한정사구가 되며, 문장의 모든 형태소 들이 인코더에 입력되고 대명사 또는 한정사구는 디코더의 시 작으로 입력된다. 입력된 형태소(One-hot representation)는 Projection layer에서 단어 표현(Word embedding)[10]과 곱하여 차 원축소를 수행하여 밀집 벡터(dense vector) 표현으로 만든다.
포인터 네트워크를 학습할 때 디코더의 입력은 임의의 엔티 티에 포함된 멘션들인데, 이들을 [표 1]과 같이 5가지 종류로 나누어 순서를 정렬(체이닝 입력)하고 학습에 사용한다.
표 1. 엔티티에 포함된 단어들 간의 연결 순서 Chaining order Chain explanation
Coref0
엔티티의 처음 위치의 대명사가 시작 입력이 되며, 그 다음으로 등장하는 멘션 순서로 정렬한다.
{이곳45이곳56어디61(순국한) 곳33}
Coref1
엔티티의 마지막 위치의 대명사가 시작 입력이 되 며, 첫 번째 멘션부터 순서대로 정렬한다. 후방 조응 사(즉, 대명사가 선행사보다 먼저 등장한 경우)가 존 재하면, 후방 조응사를 시작 입력으로 한다.
{어디61(순국한) 곳33이곳45이곳56} 후방 조응사: {이것0원자19번38이것39무엇44}
Coref2 순서는 Coref1과 같으며, 후방 조응사를 고려하지 않 는다.
Coref3
엔티티의 마지막 위치의 대명사가 시작 입력이 되 며, 포함된 멘션들을 역순으로 정렬한다. 후방 조응 사가 존재하면, 후방 조응사를 시작 입력으로 한다.
{어디61이곳56이곳45(순국한) 곳33} 후방 조응사: {이것0무엇44이것39원자19번38}
Coref4 순서는 Coref3과 같으며, 후방 조응사를 고려하지 않 는다.
700
2016년 한국컴퓨터종합학술대회 논문집
5. 실험
본 논문에서는 포인터 네트워크를 이용한 대명사 상호참조해 결의 실험 데이터로 ETRI 퀴즈 도메인 상호참조해결 데이터 셋을 이용하였다. 이 데이터 셋은 퀴즈 도메인(장학퀴즈와 wiseQA)의 840개 질문으로 구성되어 있으며, 학습 데이터를 656 문서, 개발(development) 데이터를 73 문서, 평가 데이터를 111 문서로 구성하였다. 포인터 네트워크에 대한 평가 지표는 MUC F1 값을 이용하였다[11].
인코더와 디코더의 활성함수는 tanh를 사용하였고, attention layer의 활성함수는 relu를 사용하였다. Drop-out은 0.5의 확률 값으로 적용하였으며, 학습율은 0.1을 시작으로 성능 개선이 없으면 5 에포크(epoch)마다 50%씩 감소하도록 정의하였다.
Beam search에서의 beam 크기는 5로 정의하였고, 히든 레이어 유닛 수는 개발셋(development set)을 이용하여 결정하였다([표 3] 참고). 각 실험은 개발셋으로 모델을 학습하고, 평가셋(test) 으로 성능을 측정하는 cross-validation을 수행하였다.
[표 2]는 히든 레이어 유닛 수를 [100, 50] (즉, [ℎ⃖⃗⃗ , ℎ𝑠 𝑡] )으로 정의하고 연결 순서에 따른 대명사 상호참조해결 실험을 개발 셋에서 수행한 결과이다. coref3이 86.56%로 참조해결 순서 중 에서 가장 좋은 성능을 보였으며, coref2가 85.08%로 다음으로 좋은 성능을 보였다.
[표 3]은 [표 2]에서 가장 좋은 성능을 보인 coref3에 대한 파라미터 최적화를 수행한 것이다. 개발셋에 대하여 히든 레 이어 유닛 수가 [100, 50]일 경우, 86.56%로 가장 좋은 성능을 보였고, 이때 평가셋에서는 77.76%의 성능을 보였다.
[표 4]는 본 논문에서 제안한 포인터 네트워크를 이용한 대 명사 상호참조해결과 규칙기반인 다단계시브를 이용한 대명사 상호참조해결에 대한 성능을 비교한 것이다. 본 논문에서 제 안한 방법의 성능이 기존 규칙기반의 방법에 비하여 22.27%
우수한 성능을 보였다.
표 2. 연결 순서에 따른 대명사 상호참조해결 성능
Chaining order F1 (dev)
Coref0 83.38
Coref1 82.58
Coref2 85.08
Coref3 86.56
Coref4 81.61
표 3. Coref3에 대한 포인터 네트워크 파라미터 최적화 Attention
scoring method
Dimension of
[𝒉⃖⃗⃗⃗ , 𝒉𝒔 𝒕] F1 (dev) F1 (test)
concat
[100, 50] 86.56 77.76
[200, 100] 85.79 -
[400, 200] 84.78 -
[800, 400] 85.18 -
[1600, 800] 83.15 -
표 4. 포인터 네트워크와 규칙기반 성능 비교
Model F1 (dev) F1 (test)
Pointer Networks 86.56 77.76
Multi-pass sieve 62.77 55.49
6. 결론
본 논문에서는 포인터 네트워크를 이용하여 대명사 상호참조해 결을 수행하였고, 포인터 네트워크의 연결 순서에 대하여 5가지 종류로 정의하였다. 그 결과, 본 논문에서 제안한 방법이 77.76%로 기존 규칙기반 방법에 비하여 22.27% 우수한 성능을 보였다. 향후 연구로는 대명사 상호참조해결을 위해 더 많은 데 이터를 구축하여 품질을 향상시킬 것이며, 현재 상대적으로 짧 은 문서인 질문 문서에만 적용하고 있는 포인터 네트워크를 일 반적인 문서에도 적용할 예정이다. 또한 포인터 네트워크에 GRU 대신 Long short-term memory를 적용해볼 것이며, 다양한 자 연어처리 문제(즉, 구문분석, SRL 등)에도 적용할 예정이다.
감사의 글
이 논문은 2016년도 정부(미래창조과학부)의 재원으로 정보통신 기술진흥센터의 지원을 받아 수행된 연구임. (No.R0101-16-0062, (엑소브레인-1세부) 휴먼 지식증강 서비스를 위한 지능진화형 WiseQA 플랫폼 기술 개발)
참고문헌
[1] R. Collobert, et al. Natural language processing (almost) from scratch. The Journal of Machine Learning Research, 12, 2011..
[2] O. Vinyals, et al. Pointer Networks. Advances in Neural Information Processing Systems, pp. 2674-2682, 2015
[3] D. Bahdanau, et al. Neural machine translation by jointly learning to align and translate. Proceedings of ICLR’ 15, arXiv:1409.0473, 2015.
[4] H. Lee, et al. Deterministic coreference resolution based on entity-centric, precision-ranked rules. Computational Linguistics 39.4: pp. 885-916, 2013.
[5] A. Rahman, and V. Ng. Supervised models for coreference resolution.
In: Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 2-Volume 2. Association for Computational Linguistics, pp. 968-977. 2009.
[6] 박천음, 최경호, 이창기. 딥 러닝을 이용한 가이드 멘션페어 한국 어 상호참조해결, 한국정보과학회 2015 한국컴퓨터종합학술대회, pp. 693-695, 2015.
[7] Barbara J. Grosz, Scott Weinstein & Aravind K. Joshi. "Centering: A framework for modeling the local coherence of discourse." Computational linguistics 21.2, pp. 203-225, 1995.
[8] Lappin Shalom and Herbert J. Leass. "An algorithm for pronominal anaphora resolution." Computational linguistics 20.4 pp. 535-561, 1994.
[9] K. Cho, et al. Learning phrase representation using RNN encoder-decoder for statistical machine translation. Proceedings of EMNLP’ 14, 2014.
[10] 이창기, 김준석, 김정희. 딥 러닝을 이용한 한국어 의존 구문 분석.
제26회 한글 및 한국어 정보처리 학술대회, pp. 87-91, 2014.
[11] M. Vilain, et al. “A model-theoretic coreference scoring scheme,”
In:Proceedings of the 6th conference on Message understanding. Association for Computational Linguistics, pp. 45-52, 1995.
701