1. INTRODUCTION
Since omni-directional cameras can provide a very wide field of view (up to 360° horizontally, 180° vertically) about scenes, they are popularly deployed in application areas like visual surveil- lance, where human detection is usefully demanded.
Human detection has a wide range of applications such as pedestrian detection for car driving safety, people counting for commercial marketing, human interaction in robotics, and so on in addition to hu- man intrusion detection in visual surveillance.
Thus, during the last two decades, huge intensive
research efforts have been poured into image- based human detection.
As opposed to researches on human detection under perspective cameras, where remarkable ach- ievements [1-9] have been accomplished during the last decade, those under omni-directional (fisheye) cameras [10-11] is far from satisfaction.
Exquisite human model like deformable part model [2] and deformation dictionaries [7] as well as most of effective hand-crafted feature vectors for human detection under perspective images like HoG [1, 8, 9] and Integral channel [3] cannot be directly applied to omni-images since they are se-
Real-time Human Detection under Omni-directional Camera based on CNN with Unified Detection
and AGMM for Visual Surveillance
Thanh Binh Nguyen
†, Van Tuan Nguyen
†, Sun-Tae Chung
††, Seongwon Cho
†††ABSTRACT
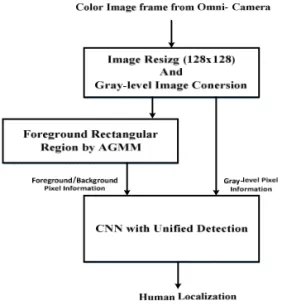
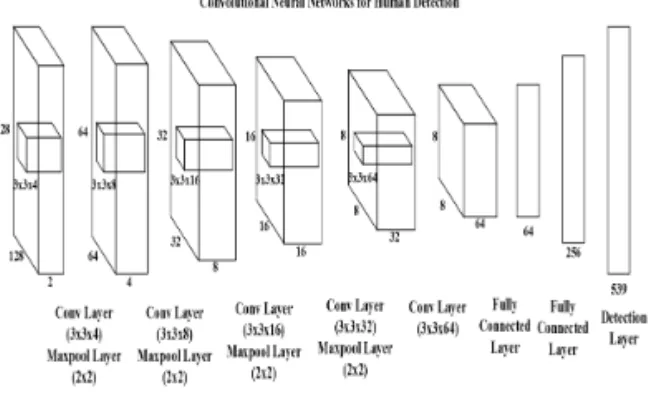
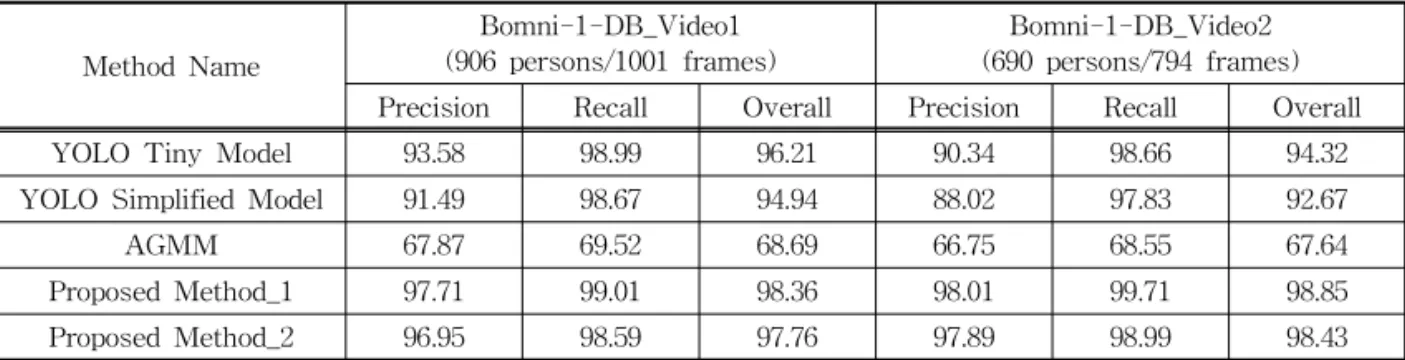
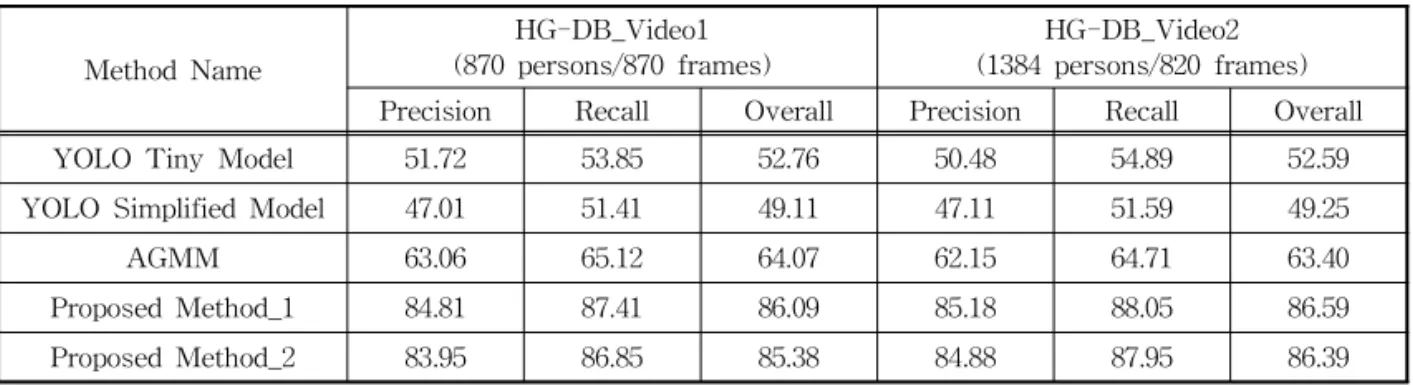
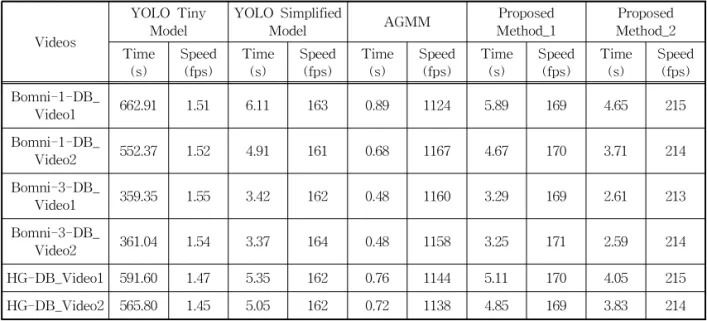
In this paper, we propose a new real-time human detection under omni-directional cameras for visual surveillance purpose, based on CNN with unified detection and AGMM. Compared to CNN-based state-of-the-art object detection methods. YOLO model-based object detection method boasts of very fast object detection, but with less accuracy. The proposed method adapts the unified detecting CNN of YOLO model so as to be intensified by the additional foreground contextual information obtained from pre-stage AGMM. Increased computational time incurred by additional AGMM processing is compensated by speed-up gain obtained from utilizing 2-D input data consisting of grey-level image data and foreground context information instead of 3-D color input data. Through various experiments, it is shown that the proposed method performs better with respect to accuracy and more robust to environment changes than YOLO model-based human detection method, but with the similar processing speeds to that of YOLO model-based one. Thus, it can be successfully employed for embedded surveillance application.
Key words: Human Detection; Omni-Directional Camera; CNN (Convolutional Neural Networks);
AGMM (Adaptive Gaussian Mixture Model); Visual Surveillance
※ Corresponding Author : Sun-Tae Chung, Address:
(06978) Dept. of Smart Systems Software, Soongsil Univ., 369, Sangdo-Ro, Dongjak-Gu, Seoul, Korea, TEL : +82- 2-820-0638, FAX : +82-2-821-7653, E-mail : cst@ssu.
ac.kr
Receipt date : May 9, 2016, Approval date : Aug. 9, 2016
†††
Dept. of Information and Telecommunication Engin- eering, Soongsil University
(E-mail : [email protected])
†††
Dept. of Smart Systems Software, Soongsil Uniersity
†††