Defect Severity-based Defect Prediction Model using CL
1)
전체 글
1)
수치

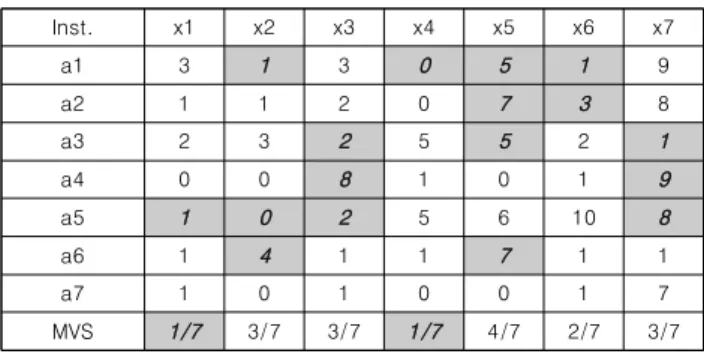
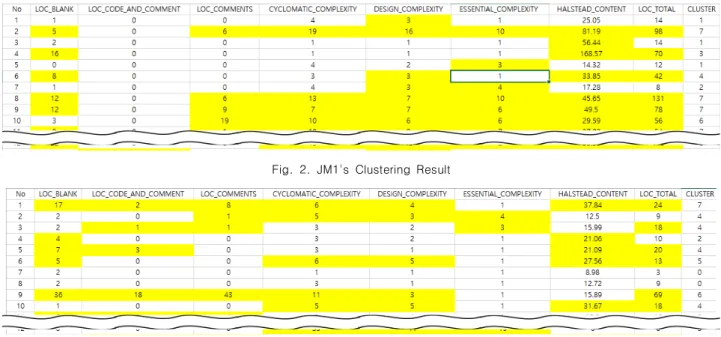
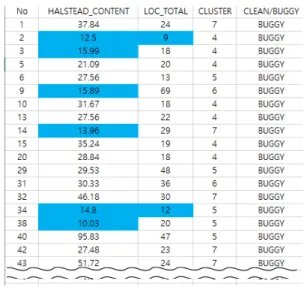
관련 문서
Messerschmitt, "Simulation of Multipath Impulse Response for Indoor Wireless Optical Channels, IEEE Journal on Selected Areas in Communications, Vol. Kahn, "Angle
"Brazilian test: stress field and tensile strength of anisotropic rocks using an analytical solution." International Journal of Rock Mechanics and Mining
W., "The Temperature Dependence of the Diffusion Bonding Between Tungsten Carbides for Micro WC-PCD Tool Fabrication" Journal of the Korean Society
“Evaluation of R&D investments in wind power in Korea using real option.” Renewable and Sustainable Energy Reviews. "Real Option Valuation of a Wind Power Project Based
Owens, "The structural coloration of textile materials using self-assembled silica nanoparticles," Journal of Nanoparticles Research, vol.. Yang,
Kikuchi, "Solutions to shape and topology eigenvalue optimization problems using a homogenization method", International Journal for Numerical Methods in
Pitas, "Minimum Class Variance Extreme Learning Machine for Human Action Recognition,"IEEE Transactions on Circuits and Systems for Video Technology,
The lateral size of the defect obtained from the deformation amount and the defect detection test using the shearing interferometer, width and depth of
