교통사고 데이터와 GIS를 이용한 보행자사고 개선구역 선정 : 서울시를 대상으로
A Selection of High Pedestrian Accident Zones Using Traffic Accident Data and GIS: A Case Study of Seoul
양종현1)· 김정옥2)· 유기윤3)
Yang, Jong Hyeon · Kim, Jung Ok · Yu, Kiyun
Abstract
To establish objective criteria for high pedestrian accident zones, we combined Getis-ord Gi* and Kernel Density Estimation to select high pedestrian accident zones for 54,208 pedestrian accidents in Seoul from 2009 to 2013. By applying Getis-ord Gi* and considering spatial patterns where pedestrian accident hot spots were clustered, this study identified high pedestrian accident zones. The research examined the microscopic distribution of accidents in high pedestrian accident zones, identified the critical hot spots through Kernel Density Estimation, and analyzed the inner distribution of hot spots by identifying the areas with high density levels.
Keywords: Pedestrian Accident, Hotspot, Getis-ord Gi*, Kernel Density Estimation
초 록
본 연구에서는 보행자사고 개선구역 선정을 위한 객관적 기준 마련을 위해 서울시의 2009년∼2013년 보행자사고
54,208건에 대해서 Getis-ord Gi*와 커널 밀도를 결합하여 보행자사고 개선구역을 선정하였다. Getis-ord Gi*를 통
해 보행자사고 발생 지점의 공간적 분포를 고려하여 보행자사고 핫스팟이 군집된 보행자사고 개선구역을 선정할 수
있었고 G
i*값을 통해 선정된 구역 간의 우선순위를 판별할 수 있었다. 그리고 보행자사고 개선구역 내부에 대해 커
널밀도추정을 시행함으로써 사고 발생 지점의 미시적인 분포를 파악하고 사고 발생에 중대한 영향을 미치는 핫스
팟을 식별할 수 있었다. 또한, 핫스팟에서 높은 밀도 레벨을 가지는 부분을 확인함으로써 핫스팟 내부를 분석할 수
있었다 .
핵심어 : 보행자사고, 핫스팟, Getis-ord Gi*, 커널밀도추정
Journal of the Korean Society of Surveying, Geodesy, Photogrammetry and Cartography Vol. 34, No. 3, 221-230, 2016
http://dx.doi.org/10.7848/ksgpc.2016.34.3.221
221 ISSN 1598-4850(Print) ISSN 2288-260X(Online) Original article
Received 2016. 01. 21, Revised 2016. 01. 26, Accepted 2016. 03. 25
1) Dept. of Civil & Environmental Engineering, Seoul National Univ. (E-mail: [email protected])
2) Corresponding Author, Member, Institute of Construction and Environmental Engineering, Seoul National Univ. (E-mail: [email protected]) 3) Member, Dept. of Civil & Environment Engineering, Seoul National Univ. (E-mail: [email protected])
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://
creativecommons.org/licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium,
provided the original work is properly cited.
222
1. 서 론
1970년대 이후 우리나라는 물리적 기반시설의 급속한 양적 팽창으로 교통사고가 급증하여 1979년에 교통안전법을 제정 하고 1980년대 이후부터 (구)국무조정실 주관으로 범정부적 인 교통안전종합대책을 수립하여 교통안전과 관련된 시책을 꾸준히 추진해오고 있다. 2008년부터는 교통사고 사상자 절 반 줄이기 프로젝트를 국정과제로 선정하여 교통안전정책을 본격적으로 추진해오고 있지만 여전히 도로 및 차량위주의 교통안전정책에 초점이 맞추어져 있다(Park and Han, 2014).
그러다보니 가장 기본적이면서도 중요한 보행은 교통안전정 책에서 밀려나있고, 보행자는 보행권을 누리지 못하고 있다.
도로교통공단에서 발간한 2013년판 「OECD 회원국 교통사 고 비교」에 따르면 2011년도 우리나라의 인구 10만 명 당 보 행 중 교통사고 사망자수는 4.1명으로 1위에 기록되어 있으며, OECD 평균 1.4명의 약 3배다. 또한 2010년 OECD통계에 따르 면 우리나라의 전체 교통사고 사망자수 대비 보행자 교통사고 사망자수가 36.6%로 OECD 회원국들의 평균치인 17.9%보다 2배 이상의 수치를 나타내고 있다(Jang et al., 2012).
이렇듯 보행권이 위협받고 있다는 인식에 기초해 2012년 2 월에 『보행안전 및 편의증진에 관한 법률』이 제정·공포되었다.
그동안 행정자치부는 지역발전특별회계로 편성된 안전한 보 행환경 조성사업을 꾸준히 추진해왔으며, 2013년부터는 보 행법 시행으로 보행환경 개선지구로 사업의 명칭과 추진방식 을 변경하여 시범사업형태로 추진하고 있다(Park and Han, 2014). 이러한 사업을 진행할 때, 어떤 지점에 안전 대책을 우 선적으로 수립하여야 교통안전을 크게 개선할 수 있는지 파 악하는 것은 매우 중요하다(Khan et al., 2008).
이를 위해 많은 과학자들은 점 패턴 분석을 폭넓게 연구 하였고, 핫스팟을 찾아내는 다양한 방법들을 개발하였다.
점 패턴 분석은 크게 두 가지로 분류할 수 있다(O’Sullivan and Unwin, 2002). 첫째, 1차 효과를 조사하는 방법으로 KDE(Kernel Density Estimation) 등이 있다. 둘째, 2차 효과 를 조사하는 방법으로 공간적 자기상관성 기법이 있다. 공간 적 자기상관성 기법의 예로 Local Moran’s I와 Getis-ord Gi*
가 있다.
많은 연구들이 교통사고 핫스팟 선정에 KDE를 사용하였 으며(Anderson, 2009; Flahaut et al., 2003; Plug et al., 2011;
Prasannakumar et al., 2011; Truong and Somenahalli, 2011;
Vemulapalli, 2015), 일부 연구들은 KDE를 시행하여 보행자 사고 핫스팟을 선정하였다(Blazquez and Celis, 2013; Jang et al., 2013; Loo et al., 2011; Pulugurtha et al., 2007; Rankavat
and Tiwari, 2013). Blazquez and Celis(2013)는 산티아고에서 발생한 어린이가 관여된 보행자사고에 대해 KDE를 시행하여 핫스팟을 선정하고, 선정된 지역 내에서 Moran’s I를 시행함 으로써 어떠한 특성들이 군집되어 있는지 확인하였다. Jang et al.(2013)은 보행자사고가 모여 있는 지점을 확인하기 위해 KDE를 시행하였다. Loo et al.(2011)은 KDE를 시행하여 식 별한 보행자사고 핫스팟과 차량 간 사고 핫스팟을 비교함으 로써 보행자사고가 더 국부적으로 분포하며, 미시적인 분석 이 필요하다고 하였다. Pulugurtha et al.(2007)은 라스베이거 스의 보행자사고에 대해 KDE를 시행하여 보행자사고 핫스팟 을 선정하였고 핫스팟 간 순위를 선정하는 방법을 제시하였 다 . Rankavat and Tiwari(2013)는 보행자사고 밀도도를 그리 는데 KDE를 사용하였다.
이처럼 많은 연구들이 KDE를 사용하여 보행자사고 핫스 팟을 선정하였다. 하지만 보행자사고 핫스팟을 객관적인 방법 으로 선정하지 않고 연구자가 KDE의 결과인 밀도도를 통해 주관적으로 선정하였다. 또한, 보행자사고의 공간적인 분포를 고려하지 않아 단순히 사고가 많이 발생한 지점만 찾았으며 보행자사고 핫스팟이 군집된 구역을 찾지 못하였다.
일부 연구들은 Getis-ord Gi*를 시행하여 교통사고 핫스팟 을 선정하였다(Khan et al., 2008; Kingham et al., 2011; Kuo et al., 2011; Manepalli et al., 2011; Vemulapalli, 2015). 특히, Rankavat and Tiwari(2013)와 Truong and Somenahalli(2011) 는 Getis-ord Gi*를 사용하여 보행자사고 핫스팟을 선정 하였다 . Rankavat and Tiwari(2013)는 보행자사고에 대해 CSR(Conceptualization of Spatial Relationships)로 고정 거 리 밴드를 설정하여 Getis-ord Gi*를 시행하였다. Truong and Somenahalli(2011)는 보행자사고 지점의 심각도 지수에 대해 Getis-ord Gi*를 시행하였고 고정 거리 밴드에 비해 역거리와 역자승거리가 핫스팟을 더 정확하게 식별한다고 하였다.
Getis-ord Gi*를 사용한 기존 연구들은 Getis-ord Gi*로 도출한 통계적으로 유의미한 핫스팟의 주변 지역을 고려하 지 않아 보행자사고 핫스팟이 군집된 구역을 찾지 못하였다.
또한 Getis-ord Gi*를 시행하기 위해 사건을 집합화했지만, 집합화된 구역 내부 보행자사고의 미시적인 분포를 고려하 지 않았다.
본 논문은 KDE와 Getis-ord Gi*를 결합하여 보행자사고
개선이 필요한 구역(이하 보행자사고 개선구역)을 선정하는
방법론을 제시한다. 구체적 연구목적은 다음과 같다. 첫째, 보
행자사고 발생 지점의 공간적 분포를 고려하여 보행자사고 핫
스팟이 군집된 보행자사고 개선구역을 선정하며, 선정된 구역
간의 우선순위를 판별한다. 둘째, 지정된 보행자사고 개선구
A Selection of High Pedestrian Accident Zones Using Traffic Accident Data and GIS: A Case Study of Seoul
223 역 내부에 속한 사고의 미시적인 분포를 분석함으로써 사고
발생에 중대한 영향을 미치는 지점을 판단한다.
2. 자료구축 및 분석방법
이 연구는 보행자사고 개선구역을 선정하고 개선구역 내 사 고의 미시적인 공간 분포를 분석하는 것을 목적으로 한다. 연 구흐름은 Fig. 1과 같으며, ArcGIS 10.3을 사용하여 연구를 진행하였다 .
1단계는 분석을 위한 데이터 구축 단계로 우선 엑셀로 저장된 서울시 보행자사고 데이터의 개별 사고를 포인트로 변환한다. 본 연구에서는 교통사고분석시스템
1)과 공공데 이터포털
2)에서 취득한 2009∼2013년도 서울시 보행사고 데이터(54,208건)를 이용한다. 데이터는 사고발생지점, 사 고일, 사고요일, 사고시군구, 사고구분, 사망, 중상, 경상, 부상, 사고유형 등으로 이루어져 있다. 다음으로 서울시 수치지도를 일정 크기의 격자로 나눈 후 앞서 작성한 포인 트 데이터 셋과 공간결합(spatial join)을 통해 개별 격자 에 보행자사고를 포함하고 보행자사고 발생수가 0인 격자
들은 제거한다.
2단계는 존(zone) 설정을 위해 Getis-ord Gi*와 KDE를 적 용한다 . 먼저 격자에 대해 Getis-ord Gi*를 시행한 후 우선순 위 판별을 위해 Getis-ord Gi*의 결과 값인 G
i*값을 내림차순 으로 정렬한다. 이때 G
i*값이 큰 순서대로 보행자사고 개선구 역을 설정해 나가며, G
i*값이 큰 격자와 그 격자를 기준으로 위 , 아래, 오른쪽, 왼쪽에 인접한 격자 하나씩을 포함하여 보 행자사고 개선구역으로 설정한다. 또한 인접한 격자가 95%
이상의 신뢰도를 가진다면 다시 그 격자를 기준으로 위, 아 래 , 오른쪽, 왼쪽에 인접한 격자를 포함하여 보행자사고 개선 구역을 설정한다. 마지막으로 선정된 보행자사고 개선구역에 KDE를 시행하여 개선구역 내 사고의 미시적인 분포를 확인 하며 세부 존으로 나눈다.
3. 보행자사고 개선구역 선정 분석
3.1 공간적 자기상관성 분석 (Getis-ord Gi*)
공간적 자기상관성은 Tobler(1970)의 ‘모든 것들은 관련되 어 있지만 가까울수록 먼 것에 비해 더 크게 관련되어 있다.’
는 지리학 제 1법칙에 근거한다. Getis-ord Gi*는 공간적 자기 상관성 기법 중 하나로써 공간적 자기상관성의 정도를 통계적 으로 측정하며, 관심 지역이 우연적인 분포를 제외한 다른 공 간적 패턴을 보이지 않는다는 귀무가설을 검정한다. 이를 위 해 각각의 피처마다 G
i*값을 계산하며 G
i*값을 통해 핫스팟의 통계적 유의성을 파악할 수 있다.
×
min ln
(1)
×
min ln
(2a)
×
min ln
× × ×
(2b) where G
i*: z score,
×
min ln
× × ×
: the spatial weight between feature i and j,
×
min ln
× × ×
: the attribute value for feature j, and
×
min ln
× × ×
: the total number of features.
Eq.(1)의
×
min ln
× × ×
와 S는 각각 Eq.(2a)와 Eq.(2b)로 계산한다. 양수 Fig. 1. Work flow
1) 교통사고분석시스템(TAAS Traffic Accident Analysis System) http://taas.koroad.or.kr
2) 공공데이터 포털 http://www.data.go.kr
Journal of the Korean Society of Surveying, Geodesy, Photogrammetry and Cartography, Vol. 34, No. 3, 221-230, 2016
224
인 G
i*값은 큰 값들이 군집되어 있는 구역을 말해주며 음수인 G
i*값은 작은 값들이 군집되어 있는 구역을 말해준다. G
i*의 절 댓값이 클수록 결과가 통계적으로 더욱 더 유의미함을 의미한 다(Khan et al., 2008). 본 논문에서는 보행자사고 개선구역을 선 정하기 위해 큰 G
i*값을 가지는 구역들에 관심을 가진다.
Getis-ord Gi*를 적용하기 위해 보행자사고를 집합화한다.
격자망 생성을 통해
×
min ln
× × ×
의 정사각형 격자망을 생 성하고, 공간 결합을 통해 격자망 내에 발생한 보행자사고의 데이터를 입력하였다. 그리고 사고 발생 수가 0인 격자들을 제거하였다 .
본 연구에서는 보행자사고 발생 지점의 공간적 분포를 고 려하기 위해 Getis-ord Gi*를 시행하였다. G
i*값이 크다는 것 은 해당하는 피처 i의 속성 값이 클 뿐만 아니라, 주변 피처들 의 속성 값도 크다는 것을 의미하므로(Rankavat and Tiwari, 2013) 일정한 기준에 따라 G
i*값이 큰 피처뿐만 아니라, 그 주 변의 피처들도 관심 지역에 포함하였다. 또한 Getis-ord Gi*는 CSR을 통해 두 사고 간의 공간적 가중치를 부여한다. CSR에 는 고정 거리 밴드와 역거리 등이 있다. 고정 거리 밴드는 고정 거리 내에 있는 피처의
×
min ln
× × ×
에 1의 값을 부여하며, 밖에 있는 피처에는 0의 값을 부여한다. 이것은 Tobler(1970)의 지리학 제 1법칙을 제대로 반영하지 못하며, 고정 거리 내에 있는 모 든 피처가 같은 영향을 준다고 가정하므로 비현실적이다. 따 라서 거리가 증가함에 따라 인접한 보행자사고가 미치는 영향 이 감소한다고 가정하여 CSR로 역거리를 이용하였다.
보행자사고 데이터에서 Getis-ord Gi*를 통해 사고가 많 이 발생한 격자들이 군집되어 있는 구역을 파악할 수 있다.
하지만, 이 경우 사고의 심각도를 고려하지 않게 된다. 연구 자의 의도에 따라 교통안전공단에서 개발한 사고별 인명피 해 심각도의 합과 같은 다른 분석 필드에 대해 Getis-ord Gi*
를 시행할 수 있다. 본 연구에서는 보행자사고 개선구역 내 미시적인 사고 분포를 확인하기 위해 설정된 존에 KDE를 적용하였다.
3.2 밀도 추정 (Kernel Density)
밀도추정이란 해당 변수에서 관측된 데이터로부터 변수가 가질 수 있는 모든 값들에 대한 밀도(확률)를 추정하는 것이 다. KDE는 사고 핫스팟을 식별하는 대중적인 위치 선정 방법 으로, 이해하기 쉬운 방법이며 시행하기 쉽기 때문에 핫스팟 을 식별할 때 많이 사용된다(Bailey and Gatrell, 1995; Kuo et al., 2011; Silverman, 1986). 하지만, KDE는 비모수적 방법 으로써 공간적인 분포를 고려하지 않는다(Kuo et al., 2011).
KDE는 데이터를 각각 커널함수에 입력하여 합치 형태를 통
해 밀도추정을 하며, 각각의 포인트에서 가장 높은 값을 가지 고 , 포인트에서 멀어질수록 감소하다가 대역폭(bandwidth)에 서 0의 값을 가진다(Silverman, 1986).
×
min ln
× × ×
(3) where
×
min ln
× × ×
: density estimate at the location
×
min ln
× × ×
, n : number of observations, h : bandwidth, K : Kernel function, and d
i: distance between the location
×
min ln
× × ×
and the location of the
×
min ln
× × ×
observation.
커널 함수는 다양한 형태가 있지만 커널 함수 형태 선택 은 결과에 큰 영향을 미치지 않는다(Silverman, 1986). 본 연 구에서는 가장 광범위하게 쓰이는 형태 중 하나인 사차함수 (quartic function)를 사용하였다(Schabenberger and Gotway, 2005). KDE에서 거리는 유클리디언 거리 또는 네트워크 거 리로 계산할 수 있다. 네트워크 거리는 도로를 1D로 가정하 며 , 유클리디언 거리는 도로를 2D로 가정한다(Xie and Yan, 2008). 도로를 선으로 가정할 수 있을 정도로 거시적으로 분 석할 때에는 네트워크 거리가 적합하다. 하지만, 본 연구에서 는 개선구역 내부에 속한 사고의 미시적인 분포를 확인하기 위해 유클리디언 거리로 설정하였다. 마지막으로 대역폭 h는 Eq. (4)로 구하였으며, 이 대역폭은 밀도분석에서 매우 적합한 대역폭이며 , 수치를 구하기 쉽다(Silverman, 1986).
×
min ln
× × ×
(4)
where SD : (weighted)Standard Distance,
: (weighted) mean center, and n : the number of points if no population field is used, or if a population field is supplied, it is the sum of the population field values.
본 연구에서는 모든 보행자 사고에 1을 부여한 경우와 Jo et al.(2014)의 사고마다 인명피해 심각도를 가중치로 부여한 2가 지 경우에 대해 KDE를 시행하고 그 결과를 비교하였다. 모든 보행자 사고에 1을 부여한 경우 사고별 인적피해수준의 심각 도를 고려하지 않게 되며, 인명피해 심각도를 통해 이를 고려 할 수 있다. 인명피해 심각도는 교통사고시 발생하는 인적피 해인 사망, 중상, 경상, 부상을 비교하기 쉽도록 부상기준으로 환산한 값이며 다음과 같이 구한다.
×
min ln
× × × (5)
A Selection of High Pedestrian Accident Zones Using Traffic Accident Data and GIS: A Case Study of Seoul
225 where
: Equivalent Casualty Loss Only,
: number of minor injuries,
: number of moderate injuries,
: number of severe injuries, and
: number of fatalities.
본 연구에서는 Getis-ord Gi*를 통해 설정한 보행자사고 개 선구역에 대해 KDE를 시행하여 존을 세부적으로 분류하였 다 . 또한 KDE를 통해 얻은 밀도 값을 Jenks Natural Breaks를 시행하여 9개의 계급으로 나누었다. Jenks Natural Breaks는 교통사고 데이터를 서로 다른 계급으로 분류하는 적합한 방 법으로써 계급 내의 요소들 간의 분산을 최소화하고 계급 간 의 분산을 최대화하여 데이터 값들의 실제적인 군집을 보존 한다 (Manepalli et al., 2011).
4. 분석결과
4.1 존 설정
Getis-ord Gi*를 실행한 결과 값인 G
i*의 크기순으로 Grid 1, 2, 3, 4, 5를 정하였다(Table 1). 이를 통해 통계적으로 유의 미한 보행자사고 개선구역을 선정하였으며 G
i*값을 통해 보행
자사고 개선구역 간 우선순위를 판별하였다. 또한, 핫스팟이 군집되어 있는 보행자사고 개선구역을 선정하기 위해 Grid 1, 2, 3, 4, 5뿐만 아니라 주변 격자들까지 포함하여 Zone 1, 2, 3, 4, 5를 선정하였다. Fig. 2의 왼쪽 그림은 Getis-ord Gi*를 실행 한 결과이며, 오른쪽 그림은 그 결과를 통해 주변지역까지 포 함하여 선정한 보행자사고 개선구역을 나타낸다. Zone 1은 영 등포역 부근이며, Zone 2는 신논현역 3번 출구 북쪽부근이다.
Zone 3은 신천역 4번 출구 서쪽부근이며, Zone 4는 수유역 부 근이고 , Zone 5는 방이동 먹자골목이다.
단순히 Getis-ord Gi*만 시행하여 얻은 결과인 Fig. 2의 왼 쪽과 주변지역을 포함한 Fig. 2의 오른쪽으로는 보행자사고 개선구역 내부의 미시적인 분포를 파악하기 어려우며, 어느 지점이 사고 발생에 중대한 영향을 미치는 핫스팟인지 판별 하기 어렵다. 이러한 점을 개선하기 위해 KDE를 시행하였다.
# Grid G
i*# Grid G
i*Grid 1 18.63 Grid 4 14.37 Grid 2 15.34 Grid 5 14.23 Grid 3 15.04
Table 1. Values of G
i*226
4.2 세부 존 분류
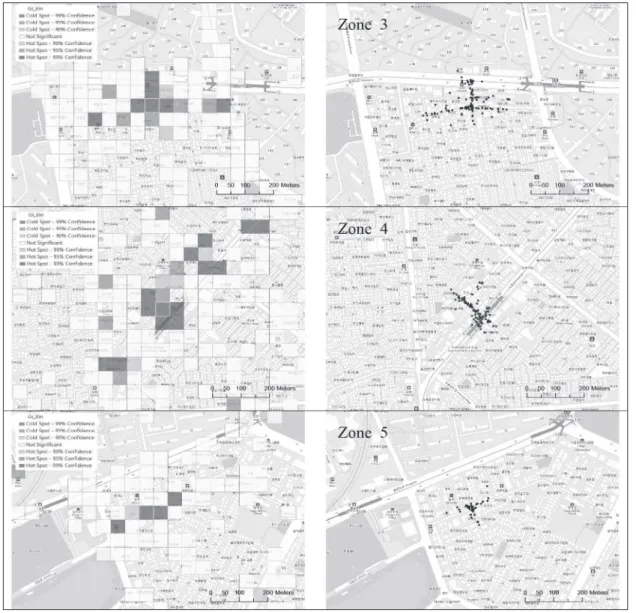
Getis-ord Gi*를 통해 선정한 Zone 1, 2, 3, 4, 5(Fig. 2)에 대 하여 KDE를 시행하였다. Jenks Natural Breaks를 이용하여 결과를 9개의 계급으로 나누었으며, 레벨이 높을수록 큰 밀도 를 가진다. Fig. 3의 왼쪽은 모든 보행자사고에 1의 값을 부여 한 경우이며, Fig. 3의 오른쪽은 사고마다 인명피해 심각도를 가중치로 부여한 경우다.
Fig. 3의 왼쪽을 보면 KDE를 통해 Zone 1, 2, 3, 4, 5 내부의 미시적인 분포를 분석함으로써 사고 발생에 중대한 영향을 미 치는 핫스팟들을 식별할 수 있음을 알 수 있다. 각각의 존 내
부에 여러 개의 핫스팟이 군집되어 있는 것은 G
i*값이 큰 격자 만 관심구역으로 선정하지 않고, 그 주변 격자까지 관심구역 으로 선정했기 때문이다. 즉, Getis-ord Gi*를 시행한 결과를 분석할 때 단순히 G
i*값이 큰 지점만 고려하면 안 되며 그 지 점의 주변까지 고려하여야 함을 알 수 있다.
Fig. 3의 왼쪽의 Zone 1, 2, 3, 4, 5에 있는 핫스팟들을 세부
존으로 나누었다. Zone 1은 Zone 1-1, 1-2, 1-3, 1-4의 세부 존
으로 나누었으며, 세부 존들은 모두 대로이다. Zone 2는 Zone
2-1, 2-2, 2-3의 세부 존으로 나누었다. Zone 2-1, 2-2는 대로이
며 , Zone 2-3은 이면도로의 교차로다. Zone 3은 Zone 3-1, 3-2,
Fig. 2. Getis-ord Gi* of pedestrian accident(left) and selected zones(right)
A Selection of High Pedestrian Accident Zones Using Traffic Accident Data and GIS: A Case Study of Seoul
227 3-3으로 나누었다. Zone 3-1은 대로이며, Zone 3-2, 3-3은 이면
도로의 교차로다. Zone 4는 Zone 4-1, 4-2, 4-3으로 나누었다.
Zone 4-1은 이면도로의 교차로, Zone 4-2, 4-3은 이면도로이 며 Zone 4-4는 대로이다. Zone 5는 Zone 5-1, 5-2, 5-3, 5-4로 나누었으며 세부 존들은 모두 이면도로의 교차로다.
Zone 1~5 중 대부분의 존은 보행자사고에 1의 가중치를 부여했을 때와 인명피해 심각도를 가중치로 부여했을 때 밀 도 패턴이 크게 변하지 않았다. 하지만, Zone 4의 경우 Fig.
3의 왼쪽에 비해 Fig. 3의 오른쪽에서 이면도로인 Zone 4-1, 4-2, 4-3의 밀도 계급이 낮아졌고, 대로인 Zone 4-4는 밀도
계급이 높아졌다. 즉, Zone 4-1, 4-2, 4-3을 Zone 4-4와 비교 했을 때, 사고 발생 빈도에 비해 인명피해가 심각하지 않음 을 알 수 있다.
KDE를 통해 핫스팟 식별뿐만 아니라, 핫스팟 내부 또한 분
석할 수 있다. Fig. 3 의 오른쪽을 보면 Zone 1-2와 Zone 4-4
에서 도로 중심 부근에서 밀도가 가장 높은 것을 확인할 수
있다 . 이 지점에는 중앙차로 버스정류장이 있다. KDE를 통해
Zone 1-2와 Zone 4-4에 대한 개선대책을 세울 때 도로 중심
부근에 위치한 중앙차로 버스정류장을 중요하게 고려해야함
을 알 수 있다.
228
5. 결 론
본 연구는 KDE와 Getis-ord Gi*를 결합함으로써 다음의 두 가지를 만족하는 보행자사고 개선구역을 선정하는 방법론 을 제시하였다. 첫째, Getis-ord Gi*를 통해 보행자사고 발생 지 점의 공간적 분포를 고려하여 보행자사고 핫스팟이 군집된 보 행자사고 개선구역을 선정하였다. 단순히 G
i*값이 큰 격자만 관심구역에 포함시키지 않고 그 주변 격자까지 관심구역에 포 함시킴으로써 높은 값을 가진 피처가 군집되어 있는 구역, 이 른바 핫스팟이 군집되어 있는 구역을 찾는다는 Getis-ord Gi*
의 목적과 부합하게 개선구역을 선정하였다. 또한 G
i*값을 통 해 선정된 구역 간의 우선순위를 판별할 수 있었다. 둘째, KDE 를 통해 지정된 보행자사고 개선구역 내부의 사고 발생 지점 의 미시적인 분포를 파악하여 사고 발생에 중대한 영향을 미 치는 핫스팟들을 식별할 수 있었다. 또한, 핫스팟에서 높은 밀 도 레벨을 가지는 부분을 확인함으로써 핫스팟 내부를 분석 할 수 있었다.
본 연구에서는 사고 수에 대해 Getis-ord Gi*를 시행하였으 나 연구자의 의도에 따라 사고 수가 아닌 사고별 인명피해 심
각도의 합이나 심각도 지수 또는, 사망자 수 등 여러 가지 필드 에 대해 본 연구에서 제시한 방법론을 시행할 수 있으므로 응 용가능성이 클 것으로 기대된다.
이번 연구에서는 사고의 공간적인 분포 외에 여러 가지 사 회경제적 변수들을 고려하지 않았다. 향후 연구에서 보행자사 고 개선구역을 선정할 때 다른 사회경제적 변수들을 고려하 여 더욱 현실의 상황을 반영한 개선구역 선정 방안을 제시할 필요가 있을 것이다.
감사의 글
본 연구는 "국토교통부 국토공간정보연구사업 국토공 간정보의 빅데이터 관리, 분석 및 서비스 플랫폼 기술개발 (16NSIP-B081011-03)과제"의 연구비 지원에 의해 연구되었음
References