水 工 學
大 韓 土 木 學 會 論 文 集第28卷 第4B 號·2008年 7月 pp. 383 ~ 392
Bayesian Markov Chain Monte Carlo 기법을 통한 NWS-PC 강우-유출 모형 매개변수의 최적화 및 불확실성 분석
Parameter Optimization and Uncertainty Analysis of the NWS-PC Rainfall-Runoff Model Coupled with Bayesian Markov Chain Monte Carlo Inference Scheme
권현한*·문영일**·김병식***·윤석영****
Kwon, Hyun-Han
·
Moon, Young-Il·
Kim, Byung-Sik·
Yoon, Seok-Young···
Abstract
It is not always easy to estimate the parameters in hydrologic models due to insufficient hydrologic data when hydraulic structures are designed or water resources plan are established. Therefore, uncertainty analysis are inevitably needed to exam- ine reliability for the estimated results. With regard to this point, this study applies a Bayesian Markov Chain Monte Carlo scheme to the NWS-PC rainfall-runoff model that has been widely used, and a case study is performed in Soyang Dam water- shed in Korea. The NWS-PC model is calibrated against observed daily runoff, and thirteen parameters in the model are opti- mized as well as posterior distributions associated with each parameter are derived. The Bayesian Markov Chain Monte Carlo shows a improved result in terms of statistical performance measures and graphical examination. The patterns of runoff can be influenced by various factors and the Bayesian approaches are capable of translating the uncertainties into parameter uncer- tainties. One could provide against an unexpected runoff event by utilizing information driven by Bayesian methods. There- fore, the rainfall-runoff analysis coupled with the uncertainty analysis can give us an insight in evaluating flood risk and dam size in a reasonable way.
Keywords : rainfall-runoff model, bayesian model, optimization, uncertainty analysis
···
요 지
수공구조물을 설계하거나 수자원계획을 수립할 때 제한된 수문자료로 인해 수문모형의 매개변수를 추정하는데 어려움이 따 르며 추정된 결과에 신뢰성을 부여하기 위해서 필수적으로 불확실성 분석이 필요하다 하겠다. 이러한 관점에서 본 연구에서 는 국내외에서 주로 이용되고 있는 NWS-PC 강우-유출 모형을 대상으로 보다 진보된 매개변수 추정과 불확실성 분석이 가 능한 Bayesian Markov Chain Monte Carlo 기법과 결합하여 국내 소양강댐 유역 일유입량 모의에 적용하였다. 실측 일유 입량 자료를 대상으로 모형의 검정과정을 수행하였으며 NWS-PC 모형의 총 13개의 매개변수에 대한 사후분포를 추정하여 유출수문곡선의 불확실성 구간을 추정하였다. 검정 및 검증 모두에서 Bayesian Markov Chain Monte Carlo 기법이 모형의 적합성 측면에서 기존 방법론과 비교해보면 다소 우수하거나 비슷한 결과를 나타내었다. 실제로 유역에 발생하는 유출은 다 양한 요인에 따라 변화될 수 있으며 이러한 점에서 Bayesian 방법은 강우-유출 관계에서 발생하는 이러한 불확실성을 매개 변수의 불확실성으로 인지함으로서 우리가 예상치 못한 유출 사상에 대한 형태를 고려할 수 있는 장점이 있다. 따라서 댐 설계와 같은 대규모 수공 구조물 설계 시에 이러한 불확실성이 접목된 강우-유출 분석이 이루어진다면 보다 합리적인 방법 으로 홍수 위험도 분석이 가능하며 더욱이 댐 규모 결정에 있어서 신뢰성 있는 의사 결정 수단을 제공할 수 있을 것으로 사료된다.
핵심용어
:강우-유출모형, Bayesian Markov Chain Monte Carlo 모형, 최적화, 불확실성분석
···
1. 서 론
수문순환과정의 여러 성분과정 중 유출은 특히 수자원관리 입장에서 가장 중요한 변량으로서 유역의 강수로 인해 발생 하는 잠재유출량에서 증발산, 침투, 침루, 지하수 등 다양하
고 복잡한 과정을 거쳐 하천으로 유입되게 된다. 이러한 복 잡한 강우-유출과정을 모의하기 위해서 수학/물리학적 개념 에 근거하여 다양한 강우-유출 모형이 개발되어 왔다. 유출 모형의 기본 목적은, 유출현상을 예측하기 위한 것으로 치수 목적으로 시간 단위의 단기 홍수 사상 모형이, 이수 목적으
*정회원ㆍ한국건설기술연구원 수자원연구실 선임연구원ㆍ공학박사 (E-mail : [email protected])
**정회원ㆍ교신저자ㆍ서울시립대학교토목공학과교수ㆍ공학박사 (E-mail : [email protected])
***정회원ㆍ한국건설기술연구원 수자원연구실 선임연구원ㆍ공학박사
****정회원ㆍ한국건설기술연구원정책연구실실장ㆍ공학박사
로는 일 단위 이상의 장기 유출 모형으로 구분될 수 있다.
우리나라에서는 장기유출모의를 위하여 미국 국립기상국
(National Weather Service)의 NWS-PC 모형, 미국 공병단의
Streamflow Synthesis And Reservoir Regulation(SSARR), USGS의 Precipitation-Runoff Modeling System(PRMS), 영국의 Topmodel 모형, Tank 모형 등이 널리 이용되고 있 다. 각 모형은 다수의 매개변수들로 이루어져 있으며 유역의 관측된 강우, 증발산, 유출량 자료 및 유역특성자료를 이용 하여 추정하게 된다.
김운중 등(2002)은 Tank 모형을 유역의 물리적 특성이 반 영되는 장점을 유지하면서 미래에 도래할 강우에 적용하여 유출량을 예측할 수 있는 모형으로 개선하고 그 모형의 적 합성 여부를 섬진강 유역에 적용하여 검토하였다. 배덕효 등
(2002)
은 탱크 모형의 매개변수를 추정하는데 유역의 유출특
성을 모의할 수 있는 방안을 연구하였다. 서영제(1997)는 우 리나라 금강의 공주와 영산강의 나주 지점에서 탱크모형의 매개변수를 검정하고 설계 당시의 모형을 이용하여 홍수 수 문곡선을 유도하여 실측치와 비교하였다. 또한 이를 향후 홍 수예경보에 이용할 수 있도록 하였다. 신성철 등(2001)은 일 유출량 산정모형으로 Tank 모형의 매개변수 산정시 유전자 알고리즘과 Powell 방법을 이용하여 금강 수계 대청댐 지점 의 자료를 이용하여 일유출량을 모의하였다. 윤용남 등
(1998)
은 수치표고모형, 수치 토양도 및 인공위성영상 등을
분석한 토지이용도를 기본 자료로 GIS를 이용하여 소유역별 특성값을 추정하였다. 이를 바탕으로 NWS-PC모형의 매개변 수를 추정하고 모형의 보정과정을 통해 적절한 값을 선택하 는데 대한 연구를 수행하였다. 강경석과 서병하(1998)는
SAC-SMA
모형을 통하여 일단위유출량을 확충하고자하는
연구를 수행하였다. 이와 같이 강우-유출 모형에서 유출 자 료에 근거한 검정 및 보정은 필수적인 과정이며 많은 연구 가 수행되어 오고 있다.
매개변수 추정방법은 크게 시행착오 방법과 최적화방법으 로 구분되며 Rosenbrock 알고리즘, Patten Search, 컴플렉 스(complex) 방법, Powell 방법 등이 최적화방법에 속한다.
최적화방법은 다시 지역최적화(local optimization) 방법 및 전역최적화(global optimization) 방법으로 대별된다. 전역 최 적화 방법은 가장 작은 목적함수를 갖는 매개변수들의 조합 을 찾아내는 방법론이라 할 수 있으며, 단지 국부최소치
(local minimum)
를 추정하는 것에 그치지 않고 매개변수들
의 조합의 관점에서 가장 작은 값을 가지는 국부 최소치를 찾아내는데 목적을 두고 있다.
국내에서는 지역최적화 방법이 일반적인 방법으로 주로 사용 되고 있으나, 최근에 Genetic 알고리즘, Shuffled Complex
Evolution-University of Arizona(SCE-UA) (Duan et al., 1992)방법 등과 같은 다양한 전역최적화 방법론이 도입되고 이용 되고 있다(강민구 등, 2002). 최근 강우-유출의 비선형성 관 계를 보다 정확하게 모의하기 위한 여러 방법론이 기존 강 우-유출 모형에 도입되고 있으며, 이러한 점에서 시행착오방 법으로 매개변수들을 최적화하는 것은 현실적으로 매우 어 려울 뿐만 아니라 비효율적이라 할 수 있다. 따라서 관측치 를 이용하여 매개변수들을 자동으로 전역최적화하고자 하는 연구가 이루어지고 있으며, 최근에 이와 함께 증가된 복잡성
에 따른 매개변수의 불확실성(uncertainty)까지 고려하고자 하는 것이 주된 연구 경향이 되고 있다. 이러한 불확실성을 실시함으로서 모형에 관련된 불확실성과 매개변수에 관련된 불확실성을 정량적으로 추정이 가능하므로 강우-유출 관계를 모의하는데 있어서의 문제점을 효율적으로 파악하는 것이 가 능하다.
그러나 이러한 매개변수를 추정하는데 있어서 불확실성을 고려하는 연구는 미약하며 특히 국내 강우-유출 관계의 검정 및 보정을 위한 충분한 자료를 가지고 있지 않다는 점에서 불확실성 분석은 더욱 필요하다 하겠다. 따라서 본 연구에서 는 국내에서 주로 사용되고 있는 NWS-PC 강우-유출 모형 에 대해서 기존 전역최적화 방법으로 수자원분야에서 널리 사용되고 있는 SCE-UA 기법및 Bayesian Markov Chain
Monte Carlo
기법을 결합한 강우-유출 모형을 국내 소양강
댐 유역에 적용하여 모형의 적합성과 타당성을 검증하고자 한다.
본 논문에서는 우선 Bayesian Markov Chain Monte
Carlo
기법과 NWS-PC 강우-유출 모형에 대한 이론적 배경
을 언급하고 대상 자료 및 유역에 대해서 설명하였다. 이들 모형을 소양강 유역에 검정 및 검증 기간으로 나눠 적용하 였으며 추정된 결론을 통계적 및 시각적 방법을 통하여 비 교 검토하였다.
2. SCE-UA 와 Bayesian Markov Chain Monte Carlo 모형
수리적으로 계산이 불가능하거나 복잡한 적분, 추정 등의 문제에 사용되는 Monte Carlo 기법은 최근에 수리 수문학 분야에서 위험도 및 불확실성을 평가하는 수단으로 널리 이 용되고 있다(Kwon and Moon, 2006). Monte Carlo기법은 관심이 있는 값을 확률변수의 기대값으로 표현하고 이것의 모의를 통하여 추출된 동일한 분포를 따르며 서로 독립
(Independent and identical Distributed: iid)인 표본들의 표 본평균을 이용하여 추정하는 방법이라고 할 수 있다.
이에 반해 Bayesian Markov Chain Monte Carlo 기법은 주어진 다변량 확률분포가 복잡하여 이를 따르는 iid 난수를 얻을 수 없는 경우에 사용가능한 기법으로서 iid 난수 대신
Markov Chain
난수를 추출하여 사용한다. Markov Chain을
통해 난수를 발생시킨다고 해서 정확하게 관심이 되는 확률 분포를 따르지 않지만 이를 일정 시간동안 반복 후에 얻어 지는 난수들은 추출을 원하는 분포에 수렴하게 된다. 따라서
Bayesian Markov Chain Monte Carlo기법은 복잡한 다변 량 확률분포 및 매개변수의 추정을 요하는 문제에서 주로 사용되며 또한 Bayesian 통계 기법에서 사후분포의 추론에 이용될 수 있다.
본 연구에서는 2가지 관점에서 Bayesian Markov Chain
Monte Carlo
기법을 이용하게 된다. 즉 강우-유출 모형의
여러 매개변수의 최적 해를 구할 뿐만 아니라 이에 따른 매 개변수의 사후분포를 추정하게 된다. 최근에 Bayesian
Markov Chain Monte Carlo
기법을 응용하여 빈도해석
(Kwon et al., 2008a),
여름 극치강수량 예측모형(권현한과
문영일, 2007; Kwon et al., 2008b) 및 계절 유출량 및 극
치 홍수량 예측 모형(Kwon et al., 2008c) 등 다양한 수리 수문학적 문제에 하나의 대안으로서 적용되고 있다.
Bayesian Markov Chain Monte Carlo
기법의 대표적인 방법 으로 메트로폴리스 해스팅스(Metropolis-Hastings Sampling) 방 법과 깁스표본법(Gibs Sampling)이 있다. 깁스표본법은 원하 는 다변량 확률분포에서 iid 표본을 추출하는 것이 복잡하거 나 난해한 경우 조건부 분포들에서 조건으로 주어지는 변수 들의 값은 정확하게 바로 직전의 단계에서 주어진 값들을 이용하여 계속 갱신하여 사후분포를 추정하는 것이다. 메트 로폴리스 해스팅스 방법은 직접적으로 표본을 얻기 어려운 확률 분포로부터 표본의 수열을 생성하는데 사용하는 기각 표본 추출 알고리즘이다. 이 수열은 주어진 분포에 근사하는
Bayesian Markov Chain Monte Carlo
를 모의실험하거나
예측치와 같은 적분을 계산하는데 사용될 수 있다. 이 방법 은 Metropolis et al.(1953)가 제안하였고 이것을 Hasting
(1970)
에 의해서 일반화 되었다. 깁스표본법은 메트로폴리스
해스팅스 방법의 특별한 경우이며, 일반적인 적용에는 제약 이 있지만 보통 더욱 빠르고 사용하기 쉽다. Bayesian
Markov Chain Monte Carlo
기법은 원하는 다변량 확률분
포에서 iid 표본을 추출하는 것이 복잡하거나 난해한 경우 이용 가능하며, 본 연구에서 메트로폴리스 해스팅스 기법을 이용하였다.
이러한 Markov Chain을 만드는 방법에는 여러 가지가 있 는데 그 중 대표적인 메트로폴리스 해스팅스법 알고리즘은 다음과 같다. 우선 Markov Chain(X
0, X1,…, X
n)이라고 할 때 현재의 상태 X
t에 대해서 다음 상태 X
t+1는 조건부분 포 로부터 추출한 변수를 Y라 하자. 여기서 Y의 확 률은 다음 조건식을 통해 진화과정을 결정하게 된다. 여기서
π는 사전분포를 나타낸다.
(1)
메트로폴리스 해스팅스법의 방법론을 간략화 하여 나타내 면 다음과 같다.
[1]
초기치 X
0(t=0)를 초기화 한다.
[2]
조건부분포 로부터 Y를 추출한다.
[3]
균등분포로부터 확률변수 U를 추출한다.
[4]
추출된 확률변수 U가 다음 식 를 만족하 면 X
t+1=Y가되며 그렇지 않으면 X
t+1=Xt로 된다.
[5]
위의 과정을 충분히 반복한 후 초기의 일정부분 난수 를 제거한 이후의 난수들을 이용한다.
위의 알고리즘에서 보듯이 메트로폴리스 해스팅스법은 조 건부 분포들에서 조건으로 주어지는 변수들의 값은 정확하 게 바로 직전의 단계에서 주어진 값들이 사용되게 되며 따 라서 조건부 분포에서 추출된 난수들이 안정 상태에 도달하 는 것이 주어진 다변량 확률분포를 정확히 따르는 난수가 되는 척도가 되며 Bayesian Markov Chain Monte Carlo 모형을 구현하는데 가장 중요한 부분이 된다.
Duan et al.(1992)
에 의해서 개발된 SCE-UA 방법론의 주된 목적은 가능한 매개변수 공간(space)에서 하나의 최적 매개변수 조합을 찾아내는 것이다. 즉 SCE-UA 모형은 작은 확률을 가지는 매개변수의 공간으로 진행 가능한 개연성을 차단하면서 연속적으로 매개변수의 모집단을 최적의 공간으
로 진화시키면서 해를 찾아내게 된다. SCE-UA 방법이 매개 변수 공간 내에서 전역화 된 최소치를 신뢰성 있게 찾아내 는 방법론이지만, 매개변수 공간 내에서 “하나의 최적 매개 변수 Set”을 추정하는데 있어서 여전히 문제점을 내포하고 있다. 즉 가능한 매개변수 공간 내에서 매개변수 Set의 식별 성의 문제는 최종적으로 모형의 상당한 불확실성을 가져다 주게 된다. 본 연구에서는 전역 최적화된 공간을 찾을 뿐만 아니라 작은 확률공간으로의 전이를 방지하는데 있어서 효 율성을 증대시키기 위한 하나의 방법론으로서 Bayesian
Markov Chain Monte Carlo
기법을 도입하여 기존 SCE-
UA
방법론을 개선하였다. 이러한 기본 개념은 Vrugt et al
(2003)
에서 처음 도입 되었으며 여러 최적화 관련 문제에
적용되었다. 본 연구에서 사용된 알고리즘을 간략화하면 다 음과 같다.
[1]
사전분포(prior distribution)로 부터 n개의 표본 {q
1, q2,…, q
n}을 무작위로 추출한 후 다음 식 (2)를 이용하여 각 점의 사후분포(posterior distribution) {p(q
1|y), p(q2|y),…, p(q
n|y)}를 추정한다. 여기서 잔차(residuals)는 상호 독립 이고 일정한 분산
σ를 갖는 정규분포를 따른다는 가정 하 에 매개변수 집단의 우도(likelihood)는 관측치 y를 가지고 다음과 식 (2)와 같이 계산될 수 있다(Box and Tiao, 1973).
(2)
[2] n
개의 점들의 사후확률을 내림차순으로 정리하여
D[1: n, 1: nq+1]]
에 저장한다. 여기서 n
q는 매개변수들의 수 를 나타내며 따라서 D의 처음 열은 가장 큰 사후확률을 가 진 점들의 조합이 된다.
[3]
병렬적인 연속점 P
1, P2,…, P
q을 초기화 한다. 여기서
Pj는 D[k, 1: n
q+1], k=1,…, q이다.
[4] D
의 점들을 각 m개의 자료를 갖는 q개의 부분 C
1, C2,…, C
q로 나누어진다.
[5]
각 병렬적인 연속점들은 메트로폴리스 해스팅스법에 의 해서 연속적으로 진화해가면서 사후확률을 추정하게 된다.
[6] q
개의 부분 C
1, C2,…, C
q들은 다시 D공간으로 보내 져 사후확률에 따라 다시 내림차순으로 정리된다. 이를 다시 단계 4와 같이 Reshuffling 과정을 진행하게 된다.
이러한 다수의 초기 무작위 표본추출과정을 거치게 됨으로 서 상대적으로 매개변수들의 공간에 보다 폭넓은 탐색과정 이 가능해지며, 이는 결국은 전역 최적해의 공간을 찾을 수 있는 더 큰 기회를 부여하게 된다.
3. NWS-PC 강우 - 유출 모형
미국 국립기상국(National Weather Service)의 수문예측 사업 그룹은 강수, 눈의 축적과 융설, 토양 함수상태의 계산, 유출의 하도추적, 매개변수 최적화 등의 유출 예측체계를 컴퓨 터 프로그램화하여 NWSRFS(National Weather Service River
Forecast System)을 개발하였다. 이 NWSRFS의 축소 모형이
NWS-PC(TabiosIII et al, 1986)이며, NWS-PC는 NWSRFS 의 SAC-SMA(Sacramento Soil Moisture Accounting)과
HEC-1
의 운동파(kinematic wave) 추적 프로그램으로 구성
f
( • |X
t)
p X
(
t|Y) min 1 π ( )f X
Y(
t|Y) π ( )f Y|X
Xt(
t)
---⎝ , ⎠
⎛ ⎞
=
f
( • |X
t)
U p X
≤ (
t,
Y)
likelihood q
(
( )t y) exp 0.5
e q(
( )t)
i---
σ
⎝ ⎠
⎛ ⎞
2i=1 N
∑
–
=
되었으며 추적방법의 대안으로 단위도와 Muskingum 방법을 결합하여 적용할 수 있도록 개발되었다. NWS-PC에서
SAC-SMA
의 모형 보정은 수동 및 자동 보정을 조합하여
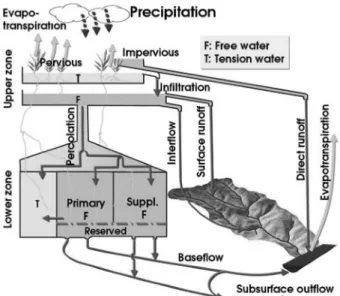
수행할 수 있으며 Rosenbrock 제약 최적화 기법을 사용한 다. SAC-SMA 모형은 유역을 상층부와 하층부로 구분하며, 상층부는 상부 토양층과 차단 저류지로 구성되고, 하층부는 토양수분과 지하수의 상태를 모의한다. 이와 관련하여 모형 에는 상층부에서의 지표면 유출, 하층부에서의 지표하 유출
2가지 주요 유출성분이 있다. 이러한 전반적인 개념도는 Fig.
1
과 같다.
이러한 유출 과정을 모형으로 구성하기 위해서 16개의 주 요 매개변수를 가지고 있으며, 일반적으로 실측 강우-유출관 계를 이용하여 모형의 매개변수 추정을 필요로 한다. SAC-
SMA모형의 상태변수로는 상층부의 장력수량(UZTWM)과
자유수량(UZFWM), 하층부의 장력수량(LZTWM), 보조 자 유수량(LZFSM), 기저 자유수량(LZFPM) 및 강수로 인한 추가적인 불투수 지역의 저류고(ADIMC)이고, 이 모형에 포 함되어 있는 매개변수는 다음 Table 1과 같다. 본 연구에서 는 RIVA, SIDE, RSERV를 제외한 13개 매개변수에 대해 서 최적화 과정을 수행하였으며 각 최적화과정에서 존재하 는 각 매개변수의 사후분포를 추정하였다.
4. 모형 적용 및 비교
4.1
대상유역 및 자료
본 연구의 적합성을 평가하기 위해서는 모형의 검증을 위 한 최소한의 사상별 강우-유출 자료가 필요하다. 이번 연구 에서는 유출자료가 비교적 잘 갖추어져 있고 자연하천인 소 양강댐 유역에 대해 검토해 보았다. 소양강댐 유역은 1974 년부터 현재까지 양질의 수문자료가 축적되어져 있고, 과거 부터 많은 연구들이 이루어져, 본 연구의 대상유역으로 선정 하였다. 소양강은 총 유로연장 166 km로서 한강수계를 형성 하는 북한강의 최대지류이며, 유역의 대부분이 산악지역으로 둘러 쌓여 있다. 소양강댐 유역면적은 2,703 km
2이며, 유역 의 평균경사는 댐 지점으로부터 인제까지 약 1/800~1/1,000 이고 상류방향으로 1/400~1/800이다. 소양강댐 유역은 인북 천 유역, 내린천 유역 및 소양 호 유역 등 세 개로 이루어 져 있다. 소양댐 유역을 Fig. 2에 나타내었다.
일 단위 강우-유출 모형의 수행을 위해서 국가수자원관리 종합정보시스템(국토해양부 한강홍수통제소)에서 소양강댐 유 역 1974년부터 2006년까지의 일강수량 및 일유입량을 추출 하였다. 증발량은 기상청 산하 춘천기상대의 일증발량 자료 를 제공받아 이용하였다.
4.2
매개변수 검정
매개변수 검정을 위해서 1989년부터 1998년까지 총 10년 을 모형의 매개변수 추정 구간으로 이용하였으며 비교 차원 에서 기존 SCE-UA 방법에 대한 검정도 함께 이루어졌다.
매개변수를 추정하는데 있어서 초기치는 모형 자체가 가질 수 있는 매개변수의 범위를 초기 값으로 가정하여 수행하였
Fig. 1 Conceptual Description of SAC-SMA modelTable 1. SAC-SMA Model Parameters and Descriptions
Parameters Descriptions
PCTIM
RIVA
영구 불투수 지역의 면적비
수표면적 비율
PFREERSERV SIDE
침투수가 하층부 자유수대로 유입되는 비율 하층부 장력수중 증발산에 의해 소모되지 않는 비율 타 유역으로 배수되는 기저지하수의 비
ADIMP
임시 불투수 지역의 면적비
UZTWM UZFWM UZK LZTWM LZFSM LZFPM LZPK LZSK ZPERC REXP
상층부 장력수의 최대 저류용량 상층부 자유수의 최대 저류용량 상층부 자유수의 탈수계수 하층부 장력수의 최대 저류용량
하층부 자유수대 보조 지하수의 최대 저류용량 하층부 자유수대 기저 지하수의 최대 저류용량 하층부 기저 지하수의 탈수계수
하층부 보조 지하수의 탈수계수
포화상에서 건조상으로 변할 때 증가되는 침투량의 계수 하층부 수분부족량 변화에 따른 침투곡선 곡률
UZTWCUZFWC LZTWC LZFSC LZFPC ADIMC
상층부 장력수의 초기 수분 상태 변수 상층부 자유수의 조기 수분 상태 변수 하층부 장력수의 초기 수분 상태 변수 하층부 보조자유수의 초기 수분 상태 변수 하층부 기저자유수의 초기 수분 상태 변수 임시 불투수 지역의 현재 저류영역
PXADJPEADJ
강우 보정계수
증발산 보정계수
Fig. 2 Map showing Soyang Dam watershed and its drainage basin다. Bayesian Markov Chain Monte Carlo법은 조건으로 주어지는 변수들의 값은 바로 직전의 단계에서 주어진 값들 이 사용되게 되며 따라서 조건부 분포에서 추출된 난수들이 안정 상태에 도달하는 것이 주어진 다변량 확률분포를 정확 히 따르는 난수가 되는 척도가 된다. 조건부로 추출된 변수 들이 안정 상태에 도달하면 변수들의 퍼짐정도(분산)가 상대 적으로 수축(shrink)되게 되며 이를 정량적으로 평가하기 위 해서 Gelman-Rubin 통계치(Gelman과 Rubin, 1992)를 이 용하였다. 이러한 관점에서, 총 10,000번 Bayesian Markov
Chain Monte Carlo
모의를 수행하여 그중 수렴이 이루어진
5,000
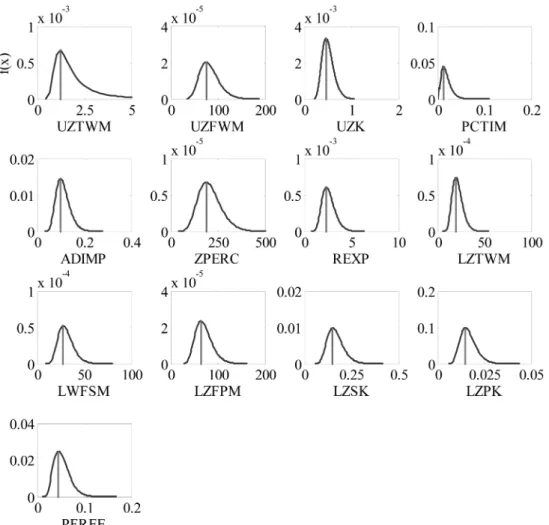
번 이후의 표본을 이용하여 13개 매개변수의 사후분포
를 추정하였으며 각 매개변수의 사후분포를 핵밀도함수를 이 용하여 Fig. 3에 나타내었다.
그림에서 보는 바와 같이 강우-유출 관계를 모사하기 위한 각 매개변수에 내재되 있는 불확실성 정도를 정량적으로 표 현할 수 있다. 예를 들어 기존에 매개변수 추정법에서
UZFWM
에 경우 단일 값인 66을 제시하고 있으나 Bayesian
분석을 통해 추정된 UZFWM은 대략적으로 중앙값은 80이 고 2.5%와 97.5%의 Quantile 값으로 각각 77과 87을 경 계로 하는 하나의 분포형으로 매개변수를 표현해 주고 있다.
이렇게 추정된 매개변수들의 불확실성은 결국 유출량의 불 확실성으로 전이되어 표현된다.
기존 방법론과의 비교를 위하여 SCE-UA를 통해서 매개변 수를 추정하였으며 이를 Bayesian 방법으로 추정된 결과와
함께 Table 2에 나타내었다. Table 2에서 2.5%, 50%, 97.5%
는 각 매개변수의 확률분포에서 추정된 Quantile값 즉, 불확 실성 구간을 나타낸다. SCE-UA를 이용한 매개변수 추정시 목적함수로 일반적으로 사용되는 RMSE 목적함수를 통하여
Fig. 3 Posterior distributions of parameters of SAC-SMA model derived from Bayesian Markov Chain Monte Carlo simulation.Kernel density function are employed to estimate probability density
Table 2. SAC-SMA Model Parameters and credible uncertainty bound using Bayesian Markov Chain Monte Carlo simulation and SCE-UA
Parameter SCE-UA
Bayesian Markov Chain Monte Carlo simulation
2.50% 50% 97.50%
UZTWM 138.192 1.055 1.619 5.403
UZFWM 66.557 76.870 80.257 86.643
UZK 0.419 0.477 0.496 0.500
PCTIM 0.034 0.003 0.016 0.042
ADIMP 0.176 0.090 0.108 0.124
ZPERC 19.965 131.764 209.696 248.441
REXP 2.503 2.025 2.563 3.007
LZTWM 1.001 15.977 20.948 24.122
LZFSM 50.406 24.332 30.014 35.898
LZFPM 52.348 61.549 68.866 74.128
LZSK 0.225 0.143 0.162 0.183
LZPK 0.017 0.014 0.016 0.019
PFREE 0.029 0.035 0.053 0.072
매개변수를 추정하였다. 두 가지 방법론에서 가장 큰 차이를 보이는 매개변수는 상층부의 최대저류량(UZTWM)으로 기존 방법론은 138 mm를 제시하고 있는 반면 본 연구에서 제시 한 방법론은 상대적으로 작은 1 mm에서 6 mm의 범위를 나타내고 있다. 이는 단일단계 자동추정법으로 하나의 최적 매개변수들의 공간을 추정함으로서 오는 오류로 판단되며, 또한 최대저류량은 물리적으로 유출이 발생하기 시작하는 강 우량으로서 소양강댐 유역이 산지유역임을 감안할 때 물리 적으로 타당한 것으로 사료된다. 또한 최대침루량(maximum
percolation) ZPERC
의 경우 UZTWM과 마찬가지로 단면적
으로 하나의 매개변수 공간내에서 매개변수를 추정함으로서 발생하는 오류로 사료되며, 또한 대상유역이 산지지역임을 감 안하면 19.97은 물리적으로 타당하지 않는 것으로 판단된다.
일반적으로 강우-유출 모형의 정확성을 평가하기 위한 많 은 통계적 적합도 기준이 제안되었으나, 적합도 기준보다는 모의 발생된 값과 측정된 값 사이의 불일치에 더 중점을 두 고 있다. 즉 관측치와 예측치 사이의 차이인 잔차 분석이 계통적으로 과소 또는 과대 추정되는 것을 파악하여 모형 수행능력을 평가하는데 사용되고 있다. 본 논문에서는 통계 적 평가 수단으로 상관계수(correlation coefficient, CC), 편 의(bias), 평균제곱오차(root mean square error, RMSE),
Nash-Sutcliffe계수(N-S), 일치계수(Index of agreement,
IoA)를 사용하여 모형의 적합성을 평가하였다.
Nash-Sutcliffe
계수는 Nash and Sutcliffe(1970)가 제안한 통계적 기준으로 편의를 줄일 수 있는 무차원계수인다. 모의 된 수문곡선이 실측 수문곡선과 잘 일치할수록 1에 가까워 지는 성질이 있다. 이 기준은 무차원양으로서 자료의 개수에 관계없이 절대적 평가기준이 될 수 있다.
(3)
(4)
(5)
여기서, q
0는 실측유량을 q
s는 모의 유량을 나타낸다. 통계적 으로 F
2는 총제곱오차를 나타내며 는 총제곱편차를 의미 한다. 즉 전체변동에 대한 오차의 정도로 해석될 수 있다.
편의와 평균제곱오차는 다음 식 (6)과 식 (7)으로 정의될 수 있다. 평균제곱오차는 비선형 유출모형의 수행능력을 평 가하기 위함이며 모형 수행결과 평균적으로 어느 정도의 유 량만큼 오차가 발생하는지를 나타내는 지표로 일종의 평균 치라고 할 수 있다.
(6)
(7)
상관계수는 모형의 효율성을 나타내는 무차원 기준으로 1
에 근접할수록 모형의 모의능력이 우수함을 뜻한다.
(8)
Willmott(1981)
은 평균과 분산사이의 차이를 추정할 때 상 관계수의 근거한 통계치의 민감성을 보완하고자 일치계수를 개발하였다. 일치계수는 식 (9)와 같다. 일치계수는 0부터 1 의 범위를 가지며 1에 가까울수록 모형의 예측능력이 우수 함을 뜻한다.
(9)
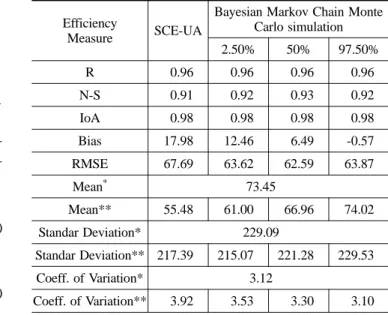
전체적인 검정결과를 통계적으로 분석하여 비교하면 Table
3과 같다. 전체적으로 상관계수, N-S 계수, IoA는 두 방법 모두 유사하거나 Bayesian 방법이 다소 우수한 반면 모형의 편의 및 자료자체의 기본 특성치를 모의하는데 있어서는 상 대적으로 Bayesian 방법이 향상된 결과를 보이고 있다. 무 엇보다도 Bayesian 방법론의 가장 큰 장점은 매개변수의 불 확실성을 정량화 할 수 있다는 것이다. 따라서 이를 이용하 여 다수의 유출량 곡선을 추정할 수 있으며 이들 결과 또한 관측치와 비교하여 Table 3에 나타내었다.
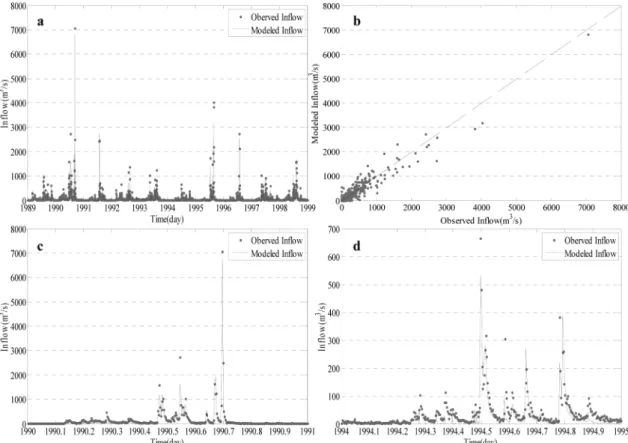
검정에서 나타낸 결과를 시각적으로 비교하기 위해서
SCE-UA
방법과 Bayesian Markov Chain Monte Carlo
모의방법을 각각 Fig. 4와 Fig. 5에 나타내었다. 각 그림에 서 1989년에서 1998년까지의 수문곡선과 산점도를 나타내었 으며 특히, 검정 기간 중에 고수위가 발생한 해(1990년)와 저수위가 발생한 해(1994년)를 그림에 나타내었다. Fig. 4에 서 보듯이 SCE-UA 방법론의 경우 실측 유입량과 매우 좋 은 일치 결과를 보여주고 있으나 상대적으로 1994년 갈수년
NS F02–F2F02 ---
=
F2
[
q0( ) q
t – s( )
t]
i2i=1
∑
n=
F02
[
q0( ) q
t – 0]
i2i=1
∑
n=
F02
Bias 1
n---
(
q0( ) q
t – s( )
t)
t=1
∑
n=
RMSE 1
n---
(
q0( ) q
t – s( )
t)
2t 1= n
⎝ ∑ ⎠
⎜ ⎟
⎜ ⎟
⎛ ⎞
0.5=
CC
qo
( ) q
t – 0( ) q (
s( ) q
t – s)
t 1=
∑
nn 1–
( )
---
=
IoA 1
q0
( ) q
t – s( )
t( )
2t 1= n
∑
qs
( ) q
t – 0+qo( ) q
t – o( )
2t 1=
∑
n--- –
=
Table 3. Model performance measures in calibration phase for SCE-UA and Bayesian Markov Chain Monte Carlo simulation
Efficiency
Measure SCE-UA
Bayesian Markov Chain Monte Carlo simulation
2.50% 50% 97.50%
R 0.96 0.96 0.96 0.96
N-S 0.91 0.92 0.93 0.92
IoA 0.98 0.98 0.98 0.98
Bias 17.98 12.46 6.49 -0.57
RMSE 67.69 63.62 62.59 63.87
Mean* 73.45
Mean** 55.48 61.00 66.96 74.02
Standar Deviation* 229.09
Standar Deviation** 217.39 215.07 221.28 229.53
Coeff. of Variation* 3.12
Coeff. of Variation** 3.92 3.53 3.30 3.10
* : the values estimated from the observed flow
** : the values estimated from the modeled flow
에 상대적으로 정도가 떨어지는 결과를 보여주고 있다.
Fig. 5
는 Bayesian 방법론을 이용하였을 때의 결과를 나타
내며 SCE-UA 방법과 마찬가지로 산점도(Fig. 5b)에서 보면 전체적으로 매우 우수한 모의능력을 보여주고 있다. 이와 더
Fig. 4 Model calibration results using SCE-UA from 1989 to 1999. a) Comparison between observed flow and modeled flow, b) scatter plot, c) high flow year 1990 and d) low flow year 1994. Red dotted dots indicates the observed flow and blue solid line corresponds to the modeled flowFig. 5 Model calibration results using Bayesian Markov Chain Monte Carlo simulation from 1989 to 1999. a) Comparison between observed flow and modeled flow, b) scatter plot, c) high flow year 1990 and d) low flow year 1994. The Red dots indicates observed flow and blue solid line corresponds to the modeled flow. Light shading is the uncertainty associated with model structure while dark shading is the uncertainty derived from posterior distribution on parameters
불어 SCE-UA와는 다르게 고수위가 발생한 해 뿐만 아니라 갈수년에도 SCE-UA에 비해 보다 정도가 높은 결과를 보여 주고 있음을 시각적으로 확인할 수 있다. 앞서 언급했듯이
Bayesian
방법은 각 매개변수의 사후분포 추정이 가능하므로
이를 이용하여 유출량의 불확실성구간을 Fig. 5c와 Fig. 5d 처럼 추정이 가능하다.
강우-유출 관계를 규명하고자 할 때 우리는 크게 두 가지 오차를 생각할 수 있으며, 첫 번째로 모형의 매개변수에서 발생하는 불확실성과 두 번째로 모형 구조 자체에서 발생하 는 불확실성으로 구분할 수 있다. Bayesian 방법은 매개변 수의 관련된 불확실성이 추정이 가능하므로 한편으로는 모형 구조 자체에서 발생하는 불확실성 또한 추정이 가능하다. 다 시 말해서, 수만 번 매개변수를 표본 추출하여 매개변수 자 체의 불확실성을 추정했음에도 불구하고 추정된 불확실성구 간이 실측치를 포함하지 못한다면, 모형의 구조 자체가 이를 모의하기에 한계가 있다고 판단할 수 있다. 이는 Bayesian 방법에서 추정된 유량과 실측유량과의 잔차를 추정함으로서 가능하다. 이 두 가지 불확실성을 구분하여 추정하여 그림에 나타내었다. 여기서 진한 색으로 나타낸 불확실성 구간이 매 개변수로부터 유도된 불확실성 구간이고, 밝은 색으로 나타 낸 구간은 모형으로부터 유도된 오차 즉, 실측유출량과
Bayesian
방법으로 추정된 최적의 매개변수 조합으로부터 추
정된 유출수문곡선과의 차이로 정의된다. 그림에서 확인되듯 이 매개변수로 인해 추정된 불확실성은 상대적으로 모형 자 체에서 발생한 오차보다 상대적으로 매우 작음을 알 수 있 으며, 이는 결과적으로 개선된 강우-유출 모형이 필요함을
내포한다고 할 수 있다.
4.3
매개변수 검증
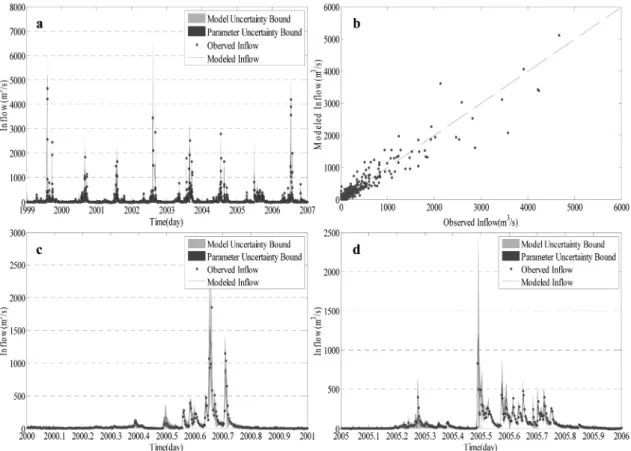
매개변수 검증을 위해서 1999년부터 2006년까지 총 8년의 일강수량, 일유입량 및 일증발량 자료를 이용하여 모형을 검 증하는데 이용하였으며 비교 차원에서 기존 SCE-UA 방법을 매개변수 검증도 함께 이루어졌다. Fig. 6은 앞서 검정단계 에서 추정된 매개변수의 사후분포를 이용하여 1999년부터
2006년까지 일유입량 결과를 나타낸다. Fig. 6b는 모형과 관 측유량과의 산점도를 나타내며 고유량 및 저유량 모두에서 비교적 좋은 결과를 나타내어 주고 있다. 또한 Fig. 6c와
6d에서는 검증기간 중 2개년을 선택하여 예측유량, 실측유량 과 불확실성 구간을 도시하여 나타내었다. 모의유량이 실측 유량의 거동을 잘 모사하고 있음을 확인할 수 있으며 수문 곡선의 감수부 또한 비교적 정확하게 모의되고 있다. 자세한 통계학적 비교는 Table 4와 Fig. 7에 나타내었다.
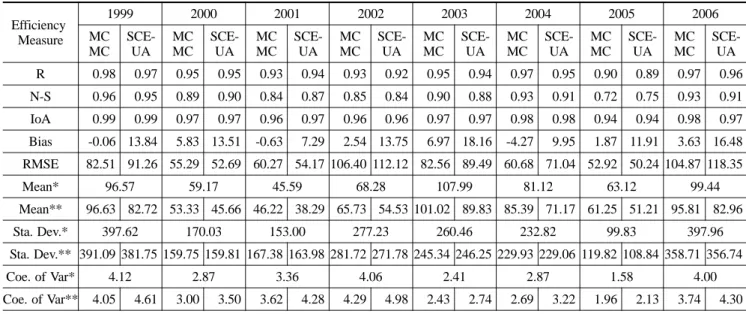
검정과정과 마찬가지로 상관계수, 편의, 평균제곱오차, N-
S계수, 일치계수를 사용하여 검증과정에서 모형의 적합성을 시간에 따라 평가하였다. 대체적으로 높은 정도의 결과를 얻 을 수 있었으며 Bayesian 방법이 기존 SCE-UA 방법보다 우수하거나 비슷한 결과를 보여주고 있다. 특히 편의 및 기 존 자료의 통계 특성치를 재생산하는데 Bayesian 방법이 더 욱 우수함을 다시 한번 확인 할 수 있었으며 이를 도시적으 로 Fig. 7에 나타내었다. 검정과정과 마찬가지로 전체적으로 상관계수는 비슷한 값으로 보이고 있으나 편의, RMSE, 일반 통계치에서 기존방법에 비해 우수한 결과를 보여주고 있다.
Fig. 6 Model verification results using Bayesian Markov Chain Monte Carlo simulation from 1999 to 2006. a) Comparison between observed flow and modeled flow, b) scatter plot, c) high flow year 2000 and d) low flow year 2005. The Red dots indicates observed flow and blue solid line corresponds to the modeled flow. Light shading is the uncertainty associated with model structure while dark shading is the uncertainty derived from posterior distribution on parameters
5. 결론 및 토의
수공구조물을 설계하거나 수자원계획을 수립할 때 제한된 수문자료로 인해 수문모형의 매개변수를 추정하는데 어려움 이 따르며 이러한 관점에서 추정된 결과에 신뢰성을 부여하 기 위해서 필수적으로 불확실성 분석에 필요하다 하겠다.
이러한 관점에서 본 연구에서는 국내외에서 주로 이용되고 있는 NWS-PC 강우-유출 모형을 대상으로 보다 진보된 매 개변수 추정과 불확실성 분석이 가능한 Bayesian Markov
Chain Monte Carlo
기법과 결합하여 국내 소양강댐 유역
일유입량 모의에 적용하였으며 기존 SCE-UA 방법론과 비교
하였다. 1989년부터 1998년까지 총 10년의 일유입량 자료를 대상으로 모형의 검정과정을 수행하였으며 NWS-PC 모형의 총 13개의 매개변수에 대한 사후분포를 추정하였다. 추정된 매개변수의 사후분포를 이용하여 다수의 유출 수문곡선을 유 도하였으며 이를 토대로 유출수문곡선의 불확실성 구간을 추 정하였다. 1999년부터 2006년까지 총 8년의 자료를 대상으 로 모형의 검증 또한 실시되었다. 본 연구에서 도출된 결론 은 다음과 같다.
1.
검정 및 검증 모두에서 Bayesian Markov Chain Monte
Carlo
기법이 모형의 적합성 측면에서 기존 방법론과 비
교해보면 다소 우수하거나 비슷한 결과를 나타내었다.
Table 4. Model performance measures in verification phase for SCE-UA and Bayesian Markov Chain Monte Carlo simulation
Efficiency Measure
1999 2000 2001 2002 2003 2004 2005 2006
MC MC
SCE- UA
MC MC
SCE- UA
MC MC
SCE- UA
MC MC
SCE- UA
MC MC
SCE- UA
MC MC
SCE- UA
MC MC
SCE- UA
MC MC
SCE- UA R 0.98 0.97 0.95 0.95 0.93 0.94 0.93 0.92 0.95 0.94 0.97 0.95 0.90 0.89 0.97 0.96 N-S 0.96 0.95 0.89 0.90 0.84 0.87 0.85 0.84 0.90 0.88 0.93 0.91 0.72 0.75 0.93 0.91 IoA 0.99 0.99 0.97 0.97 0.96 0.97 0.96 0.96 0.97 0.97 0.98 0.98 0.94 0.94 0.98 0.97 Bias -0.06 13.84 5.83 13.51 -0.63 7.29 2.54 13.75 6.97 18.16 -4.27 9.95 1.87 11.91 3.63 16.48 RMSE 82.51 91.26 55.29 52.69 60.27 54.17 106.40 112.12 82.56 89.49 60.68 71.04 52.92 50.24 104.87 118.35
Mean* 96.57 59.17 45.59 68.28 107.99 81.12 63.12 99.44
Mean** 96.63 82.72 53.33 45.66 46.22 38.29 65.73 54.53 101.02 89.83 85.39 71.17 61.25 51.21 95.81 82.96
Sta. Dev.* 397.62 170.03 153.00 277.23 260.46 232.82 99.83 397.96
Sta. Dev.** 391.09 381.75 159.75 159.81 167.38 163.98 281.72 271.78 245.34 246.25 229.93 229.06 119.82 108.84 358.71 356.74
Coe. of Var* 4.12 2.87 3.36 4.06 2.41 2.87 1.58 4.00
Coe. of Var** 4.05 4.61 3.00 3.50 3.62 4.28 4.29 4.98 2.43 2.74 2.69 3.22 1.96 2.13 3.74 4.30
* : the values estimated from the observed flow
** : the values estimated from the modeled flow
Fig. 7 Comparison of model performances on SCE-UA and Bayesian Markov Chain Monte Carlo simulation with eight different statistics over time (1999-2006)
2.
특히 편의 및 자료의 통계적 특성에 대해서 보다 합리적 인 결과를 얻을 수 있었다. 검정 및 검증 과정에서 상관 계수, N-S 계수, IoA 계수가 0.9 이상의 높은 정확성을 갖는 모의가 가능하였다.
3. Bayesian
방법의 특성상 각 매개변수가 확률분포형으로
추정이 가능하므로 각 매개변수에 내재해 있는 불확실성 을 정량적으로 파악이 가능할 뿐만 아니라 한편으로는 모 형 자체가 갖는 불확실성 또한 파악이 가능하였다.
4.
본 연구에서는 결과적으로 보면 매개변수의 불확실성 보 다 모형 자체가 갖는 불확실성이 상대적으로 크게 나타났 으며, 이는 강우-유출 모형의 개선이 더욱 필요함을 의미 한다고 추론할 수 있다.
5.
일반적으로 강우-유출 모형에서 각 매개변수의 단일 값을 사용한다는 것은 결국 동일한 강우가 발생한 경우 동일한 유출량을 갖는 것으로 가정한다는 의미를 나타낸다. 그러 나 실제로 유역에 발생하는 유출은 그 이전 강우강도, 강 우사상에 연속성, 기상학적 상이성 등 다양한 요인에 따라 변화될 수 있으며 이러한 점에서 Bayesian 방법은 강우- 유출 관계에서 발생하는 이러한 불확실성을 매개변수의 불 확실성으로 인지함으로서 우리가 예상치 못한 유출 사상 에 대한 형태를 고려할 수 있는 장점이 있다.
따라서, 댐 설계와 같은 대규모 수공 구조물 설계 시에 이러한 불확실성이 접목된 강우-유출 분석이 이루어진다면 보다 합리적인 방법으로 홍수 위험도 분석이 가능하며 더욱 이 댐 규모 결정에 있어서 신뢰성 있는 의사 결정 수단을 제공할 수 있을 것으로 사료된다.
감사의 글
본 연구는 건설교통부 한국건설교통기술평가원의 이상기후 대비시설기준강화 연구단에 의해 수행되는 2005 건설기술기 반구축사업(05-기반구축-D03-01)에 의해 지원되었습니다.
참고문헌
국가수자원관리 종합정보시스템, 국토해양부 한강홍수통제소,
http://www.wamis.go.kr/.강경석, 서병하(1998) SAC-SMA 모형을 이용한 일 유출량 산 정, 한국수자원학회 학술발표회 논문집, 한국수자원학회, pp.
146-152.
강민구, 박승우, 임상준, 김현준(2002) 전역최적화 기법을 이용한 강우-유출모형의 매개변수 자동보정. 한국수자원학회논문집, 한국수자원학회, 제35권, 제5호, pp. 541-552.
권현한, 문영일(2007) 기상정보 및 태풍특성을 고려한 계절 강수 량의 확률론적 모형 구축, 대한토목학회논문집, 대한토목학회, 제27권, 제1-B호, pp. 45-52.
김운중, 김민환, 전일권(2002) 감수곡선을 이용한 탱크 모형과 매개변수 자동보정에 의한 유출 예측, 대한토목학회논문집,
대한토목학회, 제22권, 제6-B호, pp. 777-784.
배덕효, 정일원, 강태호(2002) 유역 유출특성을 고려한 매개변수 추정에 관한 연구”, 대한토목학회 학술발표회 논문집, 대한토 목학회, pp. 38-41.
서영제(1997) 탱크모형의 매개변수 검정에 관한 연구, 한국수자원 학회논문집, 한국수자원학회 제30권, pp. 327-334.
신성철, 강경석, 서병하(2001) Tank Model의 매개변수 최적화에 관한 연구, 한국수자원학회 학술발표회 논문집, 한국수자원학 회, pp. 158-163.
윤용남, 유철상, 안재현, 양인태, 고덕구(1998) 댐건설전후 유역의 장기유출특성변화의 분석 1. GIS를 이용한 NWS-PC 모형 의 매개변수추정, 대한토목학회논문집, 대한토목학회, 제18권, 제II-5호, pp. 449-459.
Box, G.E.P. and Tiao, G.C. (1973) Bayesian Inference in Statistical Analysis, Addison-Wesley-Longman, Reading, MA.
Duan, Q., Gupta, V.K., and Sorooshian, S. (1992) Effective and efficient global optimization for conceptual rainfall-runoff models, Water Resour. Res. Vol. 28, No. 4, pp. 1015-1031.
Gelman, A. and Rubin, D.B. (1992). Inference from iterative simu- lations using multiple sequences (with discussion). Statistical Science 7, pp. 457-472.
Hastings, W.K. (1970) Monte carlo sampling methods using markov chains and their applications, Biometrika, Vol. 57, pp.
97-109.
Kwon, H.-H. and Moon, Y.-I. (2006)
Improvement of overtopping
risk evaluations using probabilistic concepts for existing dams, Stochastic Environmental Research and Risk Assessment, Vol.20, No. 4, pp. 223-237.
Kwon, H.-H., Casey, B., and Lall, U. (2008a) Climate informed flood frequency analysis and prediction in montana using hier- archical bayesian modeling, Geophys. Res. Lett., Vol. 35, L05404, doi:10.1029/2007GL032220
Kwon, H.-H., Khalil, A.F., and Siegfried, T. (2008b) Prediction of extreme rainfall events using teleconnections and typhoon characteristics, Journal of the American Water Resources Asso- ciation(JAWRA), Vol. 44, No. 2, pp. 436-448.
Kwon, H-H, Casey, B., Xu, K., and Lall, U. (2008c) Seasonal and annual maximum streamflow forecasting using climate infor- mation: application to the three gorges dam in the yangtze river basin, Hydrological Sciences Journal, in press.
Metropolis, N., Rosenbluth, A.W., Rosenbluth, M.N., Teller, A.H., and Teller, E. (1953) Equations of state calculations by fast computing machines, J. Chem. Phys., Vol. 21, pp. 1087-1091 Nash, J.E. and Sutcliffe, J.V. (1970) River flow forecasting concep-
tual models Part I - A discussion of principles, J. Hydrol., Vol.
10, pp. 282-290.
Tabios III, G., Obeysekera, J.T., and Salas, J.D. (1986) National weather service model -PC version. Colorado State Univ., Ft.
Collins, Colorado.
Vrugt, J.A., Gupta, H.V., Bouten, W., and Sorooshian, S. (2003) A shuffled complex evolution metropolis algorithm for optimization and uncertainty assessment of hydrologic model parameters, Water Resour. Res., Vol. 39, No. 8, doi:10.1029/2002WR001642.
Willmott, C.J. (1981) On the validation of models. Phys. Geog., 2, pp. 184-194.
(