요약_이 연구는 한일 동의어 중 발음을 기준으로 일본어와 유사한 음과 유사하지 않은 음으로 분류하고, 유사성의 정도에 따라 한국어 초급 한자어의 난이도를 위계화하여 제 시하는 것을 목적으로 한다. 이는 음운적인 정보도 어휘 습득의 요소로서 교육적으로 가 치가 있다는 근거를 제시하기 위함이다. 한국어와 일본어에서 한자어라는 공통 요소를 가지고 있어 일본인 학습자는 한국어 어휘 습득에 용이하다는 것이 일반적인 견해이다.
그러나 한국어 한자어와 일본어 한자어는 음운적 차이로 인해 목표어와 학습자의 모어 와의 매개체 생성이 어렵다고 할 수 있다. 이에 본 연구에서는 한일 동음동의 한자어를 음절구조, 음절, 음절별 음소의 음운적 차이에 따라 분류하여 일본인 학습자들이 일본어 와의 유사성을 바탕으로 한국어 한자어의 의미를 유추할 수 있도록 1단계부터 4단계까 지 위계화하였다. 난이도 위계에 따른 분석 결과, 1음절과 2음절 모두에서 유사도가 높 은 어휘는 7%, 1음절과 2음절 중 한 개만 유사도가 높은 어휘는 31%, 1음절과 2음절 모 두 유사도가 낮은 어휘는 62%로 나타났다. 이는 1음절과 2음절 모두 유사성에 따라 그 의미를 유추할 수 있는 어휘가 10개 중 1개가 채 되지 않고, 둘 중 하나를 유추할 수 있 는 어휘가 10개 중 3개 정도에 그치며, 나머지 6, 7개는 유사성이 전혀 없다는 의미이다.
본 연구는 기존에 한국어에서 일본어와 동음동의로 분류된 한자어를 대상으로 양 언어 의 발음을 대조하여 유사성의 정도에 따라 위계화하여 일본인 학습자들이 한국어의 어 휘를 쉽게 학습할 수 있는 자료를 제시했다는 데 의의가 있다.
주요어_ 한국어, 일본어, 한자어, 어휘, 어휘 습득, 동의어, 동음어, 음절, 음소, 위계
* 계명대, 외국어로서의 한국어교육학, jungatess@daum.net
** 계명대, 언어학, kimsj@kmu.ac.kr
한국어교육을 위한 한자어 난이도 위계 설정 - 일본인 학습자를 중심으로
김은정*·김선정**
1. 서론
이 연구의 목적은 한국어를 학습하는 일본인 학습자를 위해 한일 동의(同意) 한자어를 발음의 유사성을 기준으로 분류하여 한국어 교육을 위한 한자어의 난 이도 위계를 제시하는 데에 있다.
일본은 한국과 같은 한자 문화권에 속한다. 따라서 일본인 학습자는 비한자 문 화권의 학습자와는 달리 한자라는 공통적인 요소가 존재하여 한국어 어휘 학습 에서 유리하다고 볼 수 있다. 한국어의 기초 한자 1,800자 중에서 일본 상용한자 에도 포함되는 한자의 수는 1,604자로 기초 한자 중 약 90%에 해당하는 한자가 한국과 일본에서 공통적으로 사용되고 있다고 할 수 있다. 또한 국립국어연구원 (2003)에서 선정한 한국어 학습용 어휘 6,000개 중에서 절반 이상이 한자어로 나 타나 한국어와 일본어의 문장 구조 및 어순의 유사성과 더불어 한자어는 일본인 학습자의 한국어 학습에 용이한 요소가 된다고 할 수 있다. 한자어의 경우 뜻이 거의 일치하고 발음 또한 일치하거나 유사하여 일찍이 기존의 한자어 연구에서 는 한일 한자어의 의미, 형태, 통사, 음운 등의 비교·대조 연구를 통해 한자어 교 육 방안의 일환으로 제시하고 있다. 이미 한자를 알고 사용할 줄 안다는 점에서 한자어는 일본인 학습자에게 한국어 학습 시 자신감으로 작용한다고 할 수 있다.
따라서 일본인 한국어 학습자가 자신의 모어인 일본어의 배경지식을 통해 한국 어의 한자어와 연계할 수 있는 매개체를 생성할 수 있다면 한국어 한자어 학습에 쉽게 접근할 수 있을 뿐만 아니라 단시간의 어휘력 신장을 기대할 수도 있을 것 이다. Nation(2001)에서는 단어를 안다는 것은 의미, 형태, 연상, 화용 등의 관계 도 포함하여 인지하는 것이라는 견해를 밝히고 있는데, 이는 곧 L2의 단어를 L1 을 토대로 자연 습득할 수 있다면 어휘력 향상에 긍정적인 전이를 미친다 할 수 있으며, 어휘력의 향상은 곧 원활한 의사소통 능력1의 지름길이라 할 수 있다. 그 러나 한국어와 일본어는 공통된 한자어를 사용하며, 어순 및 문장 구조가 유사
1 조현용(2000)의 한국어 학습자 대상의 조사 결과에 따르면 어휘는 고급 과정의 학습자일수록 의사소 통에서 장애를 유발하는 요인뿐만 아니라 한국어 능력 중 가장 중요한 요인으로 꼽고 있다. 즉, 한국어 수준이 고급으로 갈수록 어휘의 중요성을 인식하고 있다는 것이다. 또한 발음 역시 문법과 마찬가지로
하다는 공통점이 있지만 음운적인 면에서는 매우 다른 양상을 보이고 있다고 할 수 있다. 두 언어에서 사용되는 자음과 모음이 다르고, 음절구조와 나타나는 음 운현상이 다르다. 허용·김선정(2013)에서는 True Friends와 False Friends를 분 류하는 것은 어휘 학습에 도움이 되며, True Friends는 L2 학습에 긍정적 전이로 False Friends는 L2 학습에 부정적 전이로 나타날 수 있다고 하였다. 본 연구에서 는 한국어와 일본어의 한자어 중 음운적 유사성 정도가 높을수록 True Friends 로 유사성 정도가 낮을수록 False Friends로 보고 유사성 기준을 제시하고자 한 다. 지금까지 제시된 한일 동음동의어를 살펴보면, ‘동음’의 경계가 음운적인 면 에서 매우 모호하게 나타난다고 할 수 있다. 예를 들면, ‘家具’는 한국어로 [가구], 일본어로 /かぐ/[kagu]로 의미와 발음 면에서도 거의 완벽하게 일치하는 것을 알 수 있다. 그러나 ‘家族’은 한국어로 [가족], 일본어로 /かぞく/[kazoku]로 한국어 는 2음절, 일본어는 3음절로 의미는 일치하나, 발음 면에서는 음절수가 다름을 알 수 있다. 기존의 연구에서는 의미, 형태, 음운 등의 대조를 통해 /가족/ 역시 / 가구/와 같은 동음동의어로 제시되어 있으나, 음절수가 달라 일본인 한국어 학습 자가 동음어로 인식하지 않을 수도 있다. 이러한 이유로 본 연구에서는 /가구/와 /かぐ/[kagu]는 True Friends로 /가족/과 /かぞく/[kazoku]는 False Friends로 분류한다.
이에 본 연구에서는 의미가 같은 한자어 중 동음으로 분류 시 ‘음절’을 첫 번 째 기준으로 삼아 음절 구조, 음절 수, 음절별 음소를 기준으로 분류하여 한국어 와 가장 유사한 음과 한국어와 가장 유사하지 않은 음으로 4단계로 분류하여 일 본인 학습자를 위한 한자어 난이도 위계를 제시하고자 한다. 이렇게 제시된 한자 어의 난이도 위계는 일본인 학습자의 어휘력 신장에 기여할 수 있는 한국어 교육 자료로 활용될 수 있을 것이다.
의사소통 시 장애를 일으키는 요인이라 할 수 있을 것이다.
의사소통의 어려운 요인 한국어 능력 요인의 중요도
어휘 발음 문법 어휘 발음 문법
초급 28% 28% 44% 46% 27% 27%
중급 47% 30% 19% 44% 28% 28%
고급 64% 18% 18% 72% 11% 17%
2. 선행연구 검토
일본어와 더불어 중국어, 베트남어는 한자라는 매개체를 사용하는 한자 문화 권을 형성한다. 이러한 공통점으로 인하여 한국어 한자어에 관한 비교·대조 연 구는 지금껏 비교적 활발히 연구되어 왔다. 한일한자어에 관한 연구로는 이동은 (2002), 사노 데루아키(2004), 이이다 사오리(2005), 카이모리 토키코(2005) 등 이 있으며, 한중한자어에 관한 연구로는 한여빈(2009), 한베한자어에 관한 연구 로는 윤혜숙(2003)을 들 수 있다. 먼저 이동은(2002)에서는 한국 한자음을 기준 으로 일본 한자음을 비교한 결과를 가나다순으로 제시2하고 있다. 이이다 사오리 (2005)에서는 2자 한자를 중심으로 한일 동형이의 한자어를 선별하여 의미를 대 조하고 그 차이점을 정리3하였다. 한여빈(2009)에서는 한중 대조를 바탕으로 동 형동의 한자어를 발음의 유사성에 따라 분류하여 한국어 발음 정보를 중국어 병 음을 활용하여 제시하였고, 윤혜숙(2003)에서는 한국어와 베트남어의 형태적, 의미적, 음운적 대조를 통해 True Friends와 False Friends의 목록을 제시하여 모어의 영향으로 인한 긍정적 전이와 부정적 전이 현상에 대하여 논하였다.
본 장에서는 한일 동음동의 한자어 분류 시 동음의 기준을 제시한 사노 데루아 키(2004)와 카이모리 토키코(2005)의 분류 기준을 구체적으로 살펴보고자 한다.
사노 데루아키(2004)에서는 의미, 형태, 음운으로 나누어 대조 분석을 실시하 였다. 의미면에서는 의미가 같거나 거의 비슷한 한자어, 약간의 의미 차이가 있 는 한자어, 한일 공통 영역과 그렇지 않은 영역도 있는 한자어, 의미 차이가 큰 한
2 기초한자와 상용한자에 모두 포함되어 있는 한자, 기초한자에만 있고 상용한자에는 없는 한자, 상용한 자에서 약자로 표기하는 한자, 상용한자에서 훈독만 있는 한자, 기초한자에서 둘 이상의 음을 가지는 한자로 분류하고 일본 한자음에서 실현되는 한자음의 한자를 분류하여 그 수를 명시하고 있다.
3 남북한 언어 비교 사전의 12,000단어 중 선별한 동형 한자어는 4,941단어, 표준국어대사전과 일본어 사전 広辞苑을 토대로 검토한 결과는 동형동의어가 4,274어(86.50%)로 나타났고, 동형이의어는 667 어(13.50%)로 나타났다. 동형이의어를 다시 분류하여 한일 한자어에서 일본어의 의미가 더 큰 것(374, 56.07%), 한국어의 의미가 더 큰 것(141어, 21.14%), 공통 의미가 있고 다른 의미도 있는 것(84어, 12.59%), 공통 의미가 없는 것(68어, 10.20%)의 순으로 분류하였다. 일본 한자어의 음독과 훈독의 확 인 작업을 하였으나 기준이 제시되어 있지 않아, 의미를 큰 기준으로 보고 동형동의어와 동형이의어를 분류하였다고 볼 수 있다.
자어, 어느 한쪽에도 없는 한자어의 다섯 가지로 분류하였다. 형태면에서는 일본 의 경우 간략한 한자의 형태인 속자4를 사용하고 있어 한국어에서 사용되고 있는 한자 형태를 사용하게 되면 일본인 한국어 학습자에게 혼란을 야기할 수 있으므 로 일본의 속자를 같이 표기할 필요가 있다고 주장하며 현재 일본에서 사용되고 있는 속자 211자를 제시하였다. 음운적 대조로는 한국어 기초 한자 1800자와 일 본어 상용한자 1945자의 독음(讀音)을 비교하여 한국어 한자5와 일본어 한자의 유사점과 차이점을 밝혀 교육 방안에 활용하고자 하였다. 한국어의 한자 독음은 대부분이 음독이지만 일본어의 한자는 음독, 훈독으로 나뉜다고 할 수 있다. 사 노 데루아키(2004)에서는 한국어를 기준으로 한국어의 초성, 종성, 중성에 일본 어를 대응시켜 분석하였다. 초성의 경우 일정한 대응은 대응표로 제시되어 있으 나 그에 따른 구체적인 기준이 제시되어 있지 않아 경우에 따른 대응에 대한 설 명이 미흡하다고 볼 수 있다. 종성에서는 한국어의 종성이 음절의 일치를 이루지 는 않으나 대응이 규칙적이라고 밝히고 있다. 한국 한자어의 종성으로 사용되는 /ㄱ, ㄴ, ㅁ, ㄹ, ㅂ, ㅇ/는 대응규칙에 따르면 /ㄱ/은 /く/[ku], /き/[ki]로 /ㄴ/과 / ㅁ/은 /ん/[N]으로, /ㄹ/은 /つ/[tsu], /ち/[chi]로, /ㅂ/은 /う/[u] 장음화로, /ㅇ/
은 /う/[u], /い/[i]음 장음화로 규칙적인 대응을 이룬다고 하였으나, 규칙이 나타 나는 환경이나 구체적인 기준이 제시되어 있지 않아 일대 다수로 대응되는 경우 대응 규칙을 활용하기에는 어려운 점이 있다고 할 수 있다. 마지막으로 중성의 경우, 초성과 종성은 비교하였으나 한국어의 모든 중성과의 대응 관계를 다루지 않았다는 점과, /ㅓ, ㅕ, ㅝ/의 경우 일본어에는 없는 음으로 가장 가까운 소리로 바뀐다고 언급하였으나, 이에 대한 예시로 4단어를 언급하는 것에 그쳐 가장 가
4 속자(俗字) 혹은 약자(略字)는 현재 일본에서는 신자체(新字体)로 불리며 한국어에서는 나라를 의미 하는 [국]의 한자어는 ‘國’으로 표기하고 있으나 일본의 경우 나라라는 의미는 같으나 [くに(kuni)]는
‘国’로 표기하고 있어 형태적인 면에서 차이가 나타난다. 이러한 현상은 일본에서 1950년대 이후 전면 적으로 신자체를 공표하고 공식문서나, 신문, 서적 등에서 교체하기 시작하면서 한국과 동일한 구자체 (旧字体) ‘國’의 형태가 변화하게 되었다고 볼 수 있어, 노년층에서는 한국과 동일한 ‘國’의 형태를 알 수도 있으나 젊은 층에서는 구자체를 알 수 있을지에 대한 염려가 있기 때문이라 볼 수 있다.
5 사노 데루아키(2004)에서는 한국어 한자의 특징으로 원칙적으로 1자(字) 1음(音)이고, 한자를 훈독하 는 습관이 없고, 동일한 의미를 가진 한자음 하나에 복수의 한자가 대응하는 경우가 있고, 놓이는 위치 가 큰 제약을 받는 경우가 있다고 정의하고 있다.
까운 음에 대한 예가 부족하다고 할 수 있다.
카이모리 토키코(2005)에서도 한일 한자어의 형태, 한자음, 의미로 대조하였 으며, 국립국어연구원(2003)의 한국어 교육 기본 어휘 중 한자어가 차지하는 비 율을 조사하여 학습용 어휘에서는 약 55%가 한자어이며, 초급 어휘가 약 37%를 차지한다고 하며 한자어의 비중에 대해 언급하였다. 형태적 분석에서는 현재 일 본에서 사용되고 있는 신자체6(新字体)와 한국 한자의 차이를 정리하여 한국 한 자와 일본 한자를 같이 표기하여 제시하였다. 의미적 분석은 품사별로 동형동의 어와 이형어로 분류하고 동형동의어는 의미와 용법이 일치하는 단어, 의미와 용 법이 차이가 나는 단어, 일본에서 사용 빈도가 낮은 단어로 재분류하였고, 이형 어는 형태는 다르나 의미가 대응되는 단어와 의미 범위나 용법에 차이가 나는 단 어로 분류하였다. 한자음 대조로는 海野·大原(1993), 이동은(2002), 菅野(2004) 의 선행연구를 바탕으로 한국어 교육용 기초한자 1800자를 분석하여 381가지의 동형동의어가 나타난다고 언급하였으며 이를 초성, 중성, 종성으로 분류하고, 초 성과 중성의 조합, 중성과 종성의 조합으로 나누어 일본어와 대응되는 목록을 제 시하였다. 사노 데루아키(2004)에서 연구개음 /ㅇ/을 두 가지로 분류하고 있는 것과 한국어의 모든 중성을 다루지 않은 것과는 달리 카이모리 토키코(2005)에 서는 /ㅇ/을 초성으로만 분류하고 있으며, 한국어의 중성을 구체적으로 일본어 와 대응시키고 있고 예외적인 부분에 대한 예시도 구체적이며 다양하게 제시되 어 있다. 그러나 일본어에 대한 지식이 있는 한국어 교사에게는 도움이 될 수 있 으나 일본어에 대한 지식이 없는 한국어 교사에게 도움이 될 수 있을지 의문이 든다. 일본인 한국어 학습자를 고려해 보더라도 카이모리 토키코(2005)에서 제 시한 대응 규칙은 고급 학습자의 한일 대조 학습 자료로는 활용 가치가 있을 것 이나 초급과 중급 학습자에게 제시하기에는 학습자에게 오히려 너무 많은 양의 정보를 제공하여 학습에 혼란을 가중시킬 수 있을 것으로 보인다. 따라서 본 연 구에서는 한일 동음동의 한자어를 일본어와의 음운상의 유사도에 따라 한국 한 자어의 난이도를 위계화하여 제시하고자 한다.
6 사노 데루아키(2004)에서는 속자(俗字)로 카이모리 토키코(2005)에서는 약자(略字)로 부르고 있으나 본 연구에서는 현재 일본에서 신자체(新字体)로 통용되고 있으므로 신자체(新字体)로 부르도록 한다.
3. 한일 한자음의 대조적 특징
신용태(1999)에서는 중국에서 유입된 한자7가 한국어와 일본어 음운체계의 차 이8로 인해 고유한 음운체계에 맞게 발음이 변하여 의미는 동일한 동의어이나 한 자음에 차이가 발생하게 되었으며, 한국어와는 달리 일본어에 종성의 형태가 없 는 것도 한자음을 받아들이는 변수로 작용한 주요한 요인이라고 보고 있다. 한국 어의 종성은 [ㄱ, ㄴ, ㄷ, ㄹ, ㅁ, ㅂ, ㅇ]의 7개로, 일본어에서는 발음(発音) /N/의 형태로만 존재하고 후행음절이 없는 음절 말에서는 [n]으로 발음되나 후행음절 이 있을 경우 변이음 [ㄴ, ㅁ, ㅇ]으로 나타나게 된다. 또한 촉음(促音) /Q/의 경 우 후행음절이 없는 경우에는 나타나지 않고 후행음절이 있을 경우에만 나타나 며 변이음 [ㄱ, ㄷ, ㅂ]로 나타난다. 이러한 종성의 형태가 음절구조의 차이로 이 어지게 되며, 개음절과 폐음절을 모두 가지는 구조인 한국어에 비해 일본어는 폐 음절이 없는 개음절의 구조로 한국 한자음에서 종성이 있는 폐음절의 발음이 일 본어에서는 개음절의 구조로 나타나려면 모음이 삽입되어야 함으로 모음이 삽 입되어 음절이 늘어나게 되는 현상이 나타나게 된다. 1장에서도 제시한 ‘家族’
은 한국어로 /가족/ 2음절의 한자어가 일본어로는 /かぞく/[kazoku]로, 한국어 와 유사한 음이라 할 수 있으나 음절 말에 모음이 삽입되어 3음절로 음절이 달라 짐을 알 수 있다. 이는 비단 한자어뿐만이 아닌 일본어의 외래어 발음에서 특징
7 우찬삼(1991)에서는 한국 한자음과 일본 한자음이 중국에서 유래되어 정착할 당시에는 오늘날에 비해 한자음의 일치도가 더 높았을 것이나 한국어와 일본어의 내부적인 음운변화로 인해 일치하지 않는 한 자의 비율이 높아졌다고 하며 한국어의 음운변화 중 한자음에 많은 영향을 준 음운변화로는 음운의 소 실, 구개음화, 두음법칙, 단모음화 등을 들고 있다.
8 한국어의 자음은 모두 21개로 장애음 15개와 공명음 6개로 구성된다. 한국어 장애음은 기의 세기에 의 한 대립이 특징적이라 할 수 있다. 이에 반해 일본어 자음은 14개로 장애음 9개와 공명음 5개로 구성 되며 일본어 장애음은 유무성에 의한 대립이 특징적이라 할 수 있다. 한국어는 단모음이 10개이고 일 본어는 모음이 5개에 불과하다. 일본어의 /あ, え, い, お/는 한국어 /ㅏ, ㅔ와 ㅐ, ㅣ, ㅗ/와 유사하다고 할 수 있고, /う/는 원순성이 약하여 원순모음 /ㅜ/보다 평순모음 /ㅡ/와 유사하다고 볼 수 있으나 일본 학계에서는 /ㅜ/와 /ㅡ/ 사이라고 보는 견해도 있다. /ㅟ/와 /ㅚ/는 단모음과 이중모음에서도 나타나지 않으나 일본어 외래어 발음 표기에서 변형된 발음 형태인 [うぃ]와 [おぇ]의 형태로 나타낼 수 있다. 이 중모음의 경우 /や, よ, ゆ, わ/는 /ㅑ, ㅛ, ㅠ, ㅘ/와 유사하다고 할 수 있다. 앞서 언급한 /ㅟ/, /ㅚ/와 같 이 /ㅖ, ㅒ, ㅝ, ㅙ, ㅞ/는 /いぇ, うぉ, おぇ, うぇ/등의 형태로 변형된 발음 형태로 제시할 수 있다.
적으로 나타나는 요소라 할 수 있다. 한국의 /김치/는 일본어 [kimuchi]로 종성/
ㅁ/에 모음 삽입 현상으로 한국어는 2음절이나 일본어는 3음절로 음절이 늘어남 을 알 수 있다. 따라서 본 연구에서는 한국어와 일본어의 한자음의 차이는 음절 이 가장 큰 영향이 미칠 것으로 보고 음절구조와 음절수, 음소에 따른 음절 별 음 소의 음운적 유사성으로 분류하여 동음동의어를 선정하고자 한다.
4. 초급 단계 동음동의 한자어 선정 기준
한국어 초급 동음동의 한자어 선정을 위 해 한국어는 국제통용 한국어교육 표준모형 2단계에 수록된 어휘 목록 중 초급 단계의 한자어9를 대상으로 하였고, 일본어는 일본 국립 국어연구소의 일본어 교과서 코퍼스 어휘표(2011)에 나타나는 한자어로, 한국어 한자어에 대응하는 한자어로 선정하였다.
먼저, 국제통용 한국어교육 표준모형 2단
계에 수록된 어휘 목록 중 초급 단계의 한자어를 일본어와 대조하여 동의어를 선 정한 후 음절구조를 기준으로 분류하였다.
(1) 음절구조에 따른 분류10
① (C)V+(C)V(개음절+개음절)
9 국제통용 한국어교육 표준모형 2단계에 수록된 어휘는 총 11,118어휘로 초급 1,683(15.1%), 중급 3,007(27%), 고급 이상 6,428(57.8%)이며, 초급 어휘 중 일반명사는 1,018(60.5%)로 나타났고, 일반명 사 중 한자어는 441(43.3%)로 나타났다. 비한자어 577개 중 64개는 외래어로, 비한자어 513(50.4%), 외래어 64(6.3%)로 나타난다.
10 한자어 441개의 어휘 중 음절기준을 통과한 한자어는 268(60.8%)로 나타났고, 그 중 일본 교과서 코퍼 스 어휘표(2011)과 대응되는 한자어는 228(85.1%)로 나타났다. 대응되지 않는 40(14.9%)개 어휘로는 주로 3음절 이상의 한자어가 많다. 일본 교과서 코퍼스 어휘표(2011)에서 /고속도로/에 /고속/과 /도 로/는 합성명사로 취급하여 각각 분류하고 있어 /고속도로/로 나타나지 않기 때문에 본 연구에서는 한
동의어 선정
⇩
음절 구조 분류
⇩
음절수 분류
⇩
음절 별 음소 분류
그림 1. 한일 동음동의 선정 순서
예) 가구, 무료, 우유
② (C)V+(C)VC(개음절+폐음절) 예) 가방, 기분, 이용
③ (C)VC+(C)V(폐음절+개음절) 예) 준비, 온도, 중요
④ (C)VC+(C)VC(폐음절+폐음절) 예) 운동, 안전, 공원
신지영(2011)에 따르면 한국어의 음절은 53.3%가 개음절이고 46.7%가 폐음 절로 그 비율이 크게 차이가 나지 않는 반면 일본어의 음절은 窪薗(1999: 223)에 서 언급한 바와 같이 개음절과 폐음절의 비율이 9:1로 압도적으로 개음절이 많 다11. 음절구조로 분류된 한자어는 음절수를 기준으로 동음어를 분류하였다.
(2) 음절수 기준
a. 歌手 /가수/[ka su] /かしゅ/[ka shu]
b. 気分 /기분/[ki bun] /きぶん/[ki bun]
c. 価格 /가격/[ka gyʌk] /かかく/[ka ka ku]12
a와 b는 한국어로 2음절, 일본어도 2음절로 음절수가 일치하여 동음으로 분류
국어 어휘와 대응하지 않는 어휘로 간주하였다.
11 山口美佳, 閔光準(2009: 50) 재인용
12 한국어로는 2음절이나 일본어로는 모음 삽입 등으로 인해 3음절 또는 그 이상이 되는 어휘의 예로는 가족01, 경제04, 계속04, 계절01, 계획01, 과제04, 과학, 광고02, 교실, 교육, 교회02, 국민, 국적02, 국 제02, 극장, 기계07, 기억, 기초06, 기회03, 내과01, 내용02, 노력01, 녹차01, 능력02, 단체02, 대화06, 도착01, 동물, 무대06, 무역02, 문제06, 미래02, 반대03, 발달, 발음01, 부족01, 비교01, 비밀, 사실04, 사회07, 산책, 상태01, 생활, 선배, 선택, 설명, 성격02, 성적04, 세계02, 세탁, 소개02, 속도01, 수도09, 수술05, 시내03, 식당, 식사03, 식탁, 식품01, 실패02, 야채, 약국02, 약속, 양복01, 여성01, 연결01, 연 극, 연락02, 연말02, 연필, 예술, 예약, 유학04, 음악01, 이해06, 인생01, 일부02, 일상04, 입학, 작년, 재 산, 전체01, 졸업, 종류02, 주말02, 주제04, 지각05, 지식02, 초대06, 최고02, 출발, 친절, 친척, 태도03, 태양02, 태풍, 퇴원01, 필요, 학년, 학원, 현대, 현재02, 형제01, 경찰04, 국내02, 대학01, 대회02, 목적, 숙제03, 식물02, 실례01, 외국02, 제목02, 해외 등을 들 수 있다.
할 수 있다. 반면 c는 한국어는 2음절이나 일본어로는 모음 삽입으로 3음절이 되 므로 음절수가 일치하지 않는다. 동형동의어이나 본 연구의 동음의 기준에서 음 절수가 맞지 않아 c는 동음으로 간주하지 않고, a와 b만 동음으로 간주하였다.
이렇게 선정된 동음의 선정 기준인 음절수를 통과한 한자어는 음소를 기준으로 다시 분류하였다.
음소의 분류 기준은 각 음절을 기준으로 초성과 종성에서는 조음위치와 조음 방법을 주요 요소로, 중성에서는 혀의 높낮이, 혀의 최고점의 위치, 입술 모양을 주요 요소로 보고 분류하였다.
(3) 음소 기준
d. 気分 /기분/[ki bun] /きぶん/[ki bun]
e. 試験 /시험/[si həm] /しけん/[shi ken]
d와 e는 음절수 기준에서 한국어와 일본어 모두 2음절로 일치한다. d는 첫 번 째 음절은 한국어와 일본어 모두 [ki]로 조음위치가 연구개로 동일하고 조음방법 역시 장애음 및 파열음13으로 동일하며 중성도 고모음이며 전설모음 중 평순모 음 [i]로 동일하다. 또한 두 번째 음절에서도 /bun/으로 조음위치가 양순음이며 조음방법에서도 파열음으로 동일하고, 중성도 고모음이며 한국어는 원순모음, 일본어는 평순모음이나 후설모음 [u]14로 유사하고, 종성도 [n]15으로 유사하여
13 한국어 가구[kagu]의 첫 번째 음절의 /가/의 /ㄱ/는 무성음인 [k]로, 두 번째 음절의 /구/의 /ㄱ/는 유성 음인 [g]로 발음된다. 이는 한국어의 장애음은 모두 무성음으로 기의 세기의 의한 평음, 격음, 경음의 삼지적 대립을 이루며, 유성음 /b, d, g, z, ʤ/는 모음과 모음 사이에 위치할 경우 변이음으로만 나타난 다.
14 일본어 /う/는 후설모음으로 입술모양으로는 평순모음 /ㅡ/와 가장 유사하다고 할 수 있으나 한국어의 /ㅡ/에 비해 평순성을 가지지 않는 점과 한국어에 비해 원순성은 떨어지나 한국어 /ㅜ/와 유사한 점, 한국어 한자어에 /ㅡ/가 나타나지 않는 점으로 본 연구에서는 일본어 /う/와 한국어 /ㅜ/를 유사한 음 으로 설정하였다. 현재 외래어 표기법에 따르면 /す, ず, つ, づ/만을 /스, 즈, 쯔, 즈/로 표기하고 나머 지 /ㅜ/로 표기하고 있다.
15 발음(撥音) /N/의 경우 후행 자음에 따라 변이음으로 [m, n, ŋ] 중 하나로, 촉음(促音) /Q/의 경우도 후행 자음에 따라 변이음으로 [p, t, k] 중 하나로 실현된다. Yoshida(2003) 에 따르면 휴지 전 비음은 주의 깊게 발음할 경우 연구개 비음 [N], [ŋ]에 가까운 소리고 실현되는 반면 덜 주의 깊게 발음할 경
한국어와 일본어 모두 조음위치 및 조음방법이 유사하다고 할 수 있다. 그러나 e 의 경우 첫 번째 음절은 [si, shi]로 조음위치가 치조음이며 조음방법에서는 마찰 음으로 동일하고 중성 역시 고모음이며 전설모음 중 평순모음 [i]로 동일하나, 두 번째 음절에서 한국어는 [həm]으로 조음위치가 후음이며 조음방법으로는 마찰 음인 [h], 일본어는 [ken]으로 조음위치가 연구개음이며 조음방법으로는 파열음 인 [k]로 일치하지 않으며 중성에서도 한국어는 중모음이며 후설모음 중 평순모 음인 [ə]와 일본어는 중모음이며 전설모음 중 평순모음인 [e]로 일치하지 않다고 할 수 있다. 따라서 위계화 기준에서 d가 e보다 상위에 놓인다고 할 수 있다.
음소의 기준을 정리하면 다음과 같다.
① 초성: 조음위치와 조음방법이 동일할 경우
/g, k/, /d, t/, /b, p/, /j, ch/는 유사한 음으로 분류
② 중성: 일본어의 [u]는 한국어의 /ㅜ/와 유사한 음으로 분류
③ 종성: 일본어의 발음(撥音) /N/ → [ㄴ, ㅁ, ㅇ]
촉음(促音) /Q/ → [ㄱ, ㄷ, ㅂ]
④ 일본어의 /い, え/의 장음화 현상16은 음절로 미인정
이상의 분류 기준으로 음절 별 음소를 분류한 기준을 예로 들면 <표 1>과 같다.
순위 1번은 1음절과 2음절 모두 일치하여 발음의 유사도가 매우 높고, 순위 2 번은 1음절은 일치하나 2음절이 일치하지 않고 3번은 1음절은 일치하지 않으나
우 선행 모음에 동화되어 그 모음의 비음 형태로 나타난다(윤영해 2016: 56 재인용). 고혜정(2011)에 서는 일본어 교육학적 측면에서는 음절말 비음 /N/이 모음이나 반모음 앞에 올 경우와 어말에서는 한 국어 [ㄴ]과 [ㅇ]의 중간음으로 나타난다고 언급되고 있다고 하였다. 우찬삼(1991)에서는 한국어의 삼 (三) [sam], 산(山) [san]은 일본어로 [saN]과 같이 같은 음으로 나타난다고 하였다. 이는 일본 한자음 에서 구별이 있었던 –m, -n의 통합 과정을 거쳐 N으로 통합되었음을 이유로 들었다. 또한 한국 한자 음의 받침 /ㅁ/을 갖는 한자가 일본 상용한자 음훈표에 83자가 있고, 받침 /ㄴ/을 갖는 한자는 309자가 있으나 모두 일본 한자음에서는 /–N/으로 통합되어 나타나게 되었다고 언급하고 있다.
16 음절은 청각적으로 경계가 느껴지는 말소리의 기본 단위이므로 일본어의 /い, え/의 장음화는 음절로 간주하지 않았다. 장음화의 예로는 夫婦는 한국어로 /부부/의 2음절 단어이고, 일본어로는 /ふうふ/로 3모라 단어이나 [fuːfu]로 /う/가 장음화되어 2음절로 발음되는 것을 알 수 있다.
2음절이 일치하여 순위 1번에 선정된 어휘에 비해 발음의 유사도가 낮다. 마지막 순위 4번은 1음절과 2음절에서 모두 모어인 일본어와의 유사도가 낮아 동음 한 자어라 가장 인지하기 어려울 것이라 예상할 수 있다. 유사도가 높다는 것은 L1 의 배경지식을 토대로 매개체를 형성하여 L2의 어휘를 유추할 수 있는 가능성이 높아진다고 할 수 있고 유사도가 낮다는 것은 L1의 배경지식이 매개체를 형성하 지 못해 L2의 어휘를 유추할 수 있는 가능성이 낮아진다고 할 수 있다. 이는 곧 유사도가 높은 어휘는 습득하기 쉬울 것이나 유사도가 낮은 어휘는 습득에 어려 움이 있을 것이라고도 할 수 있을 것이다.
5장에서는 이상의 분류 기준으로 (C)V+(C)V(개음절+개음절), (C)V+(C)VC (개음절+폐음절), (C)VC+(C)V(폐음절+개음절), (C)VC+(C)VC(폐음절+폐음절) 로 분류하여 한국어 한자음과 일본어 한자음의 유사도에 따른 순서대로 초급 단 계 한국어 한자어를 제시하도록 하겠다.
5. 초급 단계 동음동의 한자어
국제통용 한국어교육 표준모형 2단계에 수록된 어휘 목록 중 초급 단계의 한 자어를 대상으로 일본 국립 국어연구소의 일본어 교과서 코퍼스 어휘표(2011)와 대응 여부를 확인하고 음절구조와, 음절, 음절 별 음소의 분류 기준으로 선정된 한일 동음동의 한자어는 <표 2>의 (C)V+(C)V 어휘, <표 4>의 (C)V+(C)VC 어휘,
<표 6>의 (C)VC+(C)V 어휘, <표 8>의 (C)VC+(C)VC 어휘17로 제시하였다.
<표 2>의 순위 1번의 ‘家具, 歌謡, 道路, 都市, 無料, 宇宙, 調査, 治療’는 한국 표 1. 음절 별 음소 분류 기준
순위 1음절 2음절
1 O O
2 O X
3 X O
4 X X
표 2. (C)V+(C)V 한자어의 난이도 위계
음절순위 어휘
1 가구0418 가요02 도로07 도시03 무료01
우주02 조사30 치료
2
가수11 교사09 교수06 구두01 기사10
기자05 기차01 야구02 주소01 주차04
지구03 지구04 지도03 지하
3
거리08 요리05 위치01 의미 이유04
자세02 자유03 지도09 *추카(축하) 취미04
포도06
4
과거03 과자02 *다너(단어)19 두부01 배우01
보호01 부부03 소녀02 *어너(언어01) 어휘02
여자02 오후02 우유02 의사12 의자03
이후02 주부03 주위02 초기04 치과
포기02 화가03 휴가01
어로 /가구/, /가요/, /도로/, /도시/, /무료/, /우주/, /조사/, /치료/는 일본어로는 /かぐ/, /かよう/, /どうろ/, /とし/, /むりょう/, /うちゅう/, /ちょうさ/, /ちりょ う/로 한국어는 모두 2음절 한자어이고 본 연구에서는 일본어의 /い, え/의 장음 화 현상은 음절로 인정하지 않는다는 분류 기준에 따라 일본어도 /kagu, kayo-, do-ro, toshi, muryo-, uchu-20, cho-sa, chiryo-/로 2음절로 분류하였다. 4 장에서 밝힌 바와 같이 순위 1번은 1음절과 2음절의 발음 일치도가 상당히 높아
17 일본 교과서 코퍼스 어휘표(2011)과 대응되는 한국 한자어 228(85.1%)개의 어휘 중 (C)V+(C)V는 56(24.6%), (C)V+(C)VC는 60(26.2%), (C)VC+(C)V는 56(24.6%), (C)VC+(C)VC는 56(24.6%)로 나타 났다.
18 표준국어대사전의 체계에 따른 동형어번호로 동음이의어를 구분하기 위한 것이다.
19 ‘*’의 어휘 /단어/, /언어/, /축하/, /군인/, /금연/, /환영/의 경우 연음으로 표기와 발음이 달라져 음절 구조에 영향을 미치는 음운현상이 일어나는 어휘를 의미하며 발음을 기준으로 음절구조를 분류하였 다. 추가적으로 표기법을 표기하도록 하였다. 그러나 신랑[실랑], 국가[국까]와 같은 유음화와 경음화 의 경우 표기와 발음은 상이하게 나타나나 음절구조에 영향을 미치지 않으므로 ‘*’으로 표기하지 않았 고, 경음화에 비해 발음이 난해한 유음화 어휘만 표기법을 참고로 표기하도록 하였다.
20 현대국어에서 ‘ㅈ, ㅊ’ 다음에 이중모음이 결합된 ‘쟈, 져, 죠, 쥬, 챠, 쳐, 쵸, 츄’와 같은 발음은 단모음이 결합된 ‘자, 저, 조, 주, 차, 처, 초, 추’와 구분이 되지 않으므로 일본어의 /uchu-/, /cho-sa/는 한국어 의 /우주/, /조사/와 동음으로 분류하였다.
일본인 학습자의 모어인 일본어와 가장 동음에 가까운 한국어 한자어라고 할 수 있다. 따라서 순위 1번의 /가구/, /가요/, /도로/, /도시/, /무료/, /우주/, /조사/, / 치료/의 한국어 한자 어휘는 모어와의 유사도가 가장 높기 때문에 습득하기 쉬울 것이라 예상21할 수 있다. 순위 2번의 ‘歌手’는 한국어 /가수/로 2음절이 [su], 일 본어 /かしゅ/는 2음절이 [syu]로, ‘教師’는 한국어 /교사/로 2음절이 [sa], 일본어 /きょうし/는 2음절이 [shi]로 유사도가 낮아 일본인 학습자가 유추하기에 순위 1번의 어휘에 비해 어렵다고 볼 수 있다. 순위 3번의 ‘料理’와 ‘理由’는 한국어로 /요리/, /이유/, 일본어로는 /りょうり/[ryo:ri], /りゆう/[riyu:]로, 2음절에서는 [ri]와 [yu]로 일치하나 1음절에서 [요]는 [ryo]로, [이]는 [ri]로 일치도가 낮음을 알 수 있다. 이는 한글 맞춤법 규정의 두음법칙으로 인해 어두에서 한자어의 소 리가 변화된 것으로 일본어와의 유사도가 낮게 나타났다. 순위 4번의 경우 ‘単語’
는 /단어/[danə]와 /たんご[taŋgo]로, ‘豆腐’도 /두부/[tubu]와 /とうふ/[to:hu]
로 1음절과 2음절 모두 모어인 일본어와 유사도가 낮아 순위 2번과 3번에 비해 가장 유추하기 어려운 한자어라고 할 수 있다.
표 3. (C)V+(C)V 한자어 어휘 수와 비율
순위 어휘 수 비율(%)
1 8 14%
2 14 25%
3 11 20%
4 23 41%
합계 56
(C)V+(C)V 음절 구조는 개음절이 가장 많은 일본어와 유사도가 가장 높게 나 타날 수 있는 구조라 할 수 있다. 그러나 <표 3>에 제시한 바와 같이 1음절과 2음 절의 유사도가 가장 높은 순위 1번의 어휘는 전체 56개 중 8개로 14%의 비율로
21 대조분석가설의 대표적인 학자인 Lado(1957)는 모어와 유사한 요소들은 L2 학습자에게 더 쉽게 느껴 질 것이라고 주장하였으며, Prator(1967)는 L2 학습에서 나타날 수 있는 난이도를 난이도 위계(Hier- archy of difficulty)로 제시하여 Level 0에서 5까지 총 6단계로 분류하여 L1과 L2 간에 차이가 없는 경 우를 Level 0 단계로 보고 L1과 L2가 유사한 경우 긍정적인 전이가 일어나 학습에 어려움이 없을 것이 라고 보았다.
나타나 일본인 학습자가 모어인 일본어와 동음동의어라 불리는 한국어의 한자 어를 유추할 수 있는 비율이 10개의 어휘 중 1개 정도에 그친다고 할 수 있다. 1 음절과 2음절의 유사도가 가장 낮은 순위 4번은 전체 56개 중 23개로 41%의 비 율로 나타났고, 각각의 음절에서 한 개씩만 일치하는 순위 2번과 3번은 전체 56 개 중 25개로 45%의 비율로 나타나 절반의 유사성의 정보만으로 유추해야 할 어 휘와 유사성의 정보가 전혀 없는 상태에서 유추해야 할 어휘의 비율이 비슷한 것 으로 나타났다.
표 4. (C)V+(C)VC 한자어의 난이도 위계
음절순위 어휘
1 가방01 계산01 기분01 기온 부분01
시민
2
가정06 고향02 기간07 기본 기업01
모양02 부장07 시인10 시장03 시장04
시청03 시험03 유명01 이상05 이상12
이전03 조건02 주문04 지방05
3 수단01
4
개인02 과장07 교통01 *구닌(군인) *그면(금연)
노인01 부인01 부인02 부정09 사건01
사업04 사장15 사전22 사진07 서양
서점03 수업04 수영02 수입02 시간04
여행02 오전02 위험 *이붠(입원01) 이용01
자신01 자연01 주변04 주인01 주장03
포장10 표현 *화녕(환영02) 희망
<표 4>의 순위 1번의 ‘鞄, 計算, 気分, 気温, 部分, 市民’는 한국어로 /가방22/, /계산23/, /기분/, /기온/, /부분/, /시민/는 일본어로는 /かばん/, /けいさん/, /き ぶん/, /きおん/, /ぶぶん/, /しみん/으로 한국어는 모두 2음절 한자어이고 본 연
22 /가방/과 /구두/(표 2)는 국립국어원 표준국어대사전에서 어원 정보를 일본어 ‘鞄’ ‘靴’로 싣고 있다. 일 본어에서 차용된 어휘로 볼 수 있다. 본 연구에서는 한일 동음동의어가 주요 주제인 만큼 여타의 한자 어와 같이 취급하도록 하였다.
23 표준 발음법에서는 ‘예, 례’이외의 ‘ㅖ’는 [ㅔ]로도 발음한다고 규정되어 있다.
구의 일본어의 /い, え/의 장음화 현상은 음절로 인정하지 않는다는 분류 기준에 따라 일본어도 /kaban, ke-san, kibun, kion, bubun, simin/으로 2음절로 분 류하였다. 1음절과 2음절의 발음 일치도가 상당히 높아 일본인 학습자의 모어인 일본어와 가장 동음에 가까운 한국어 한자어라고 할 수 있다. 순위 2번의 ‘基本, 注文’는 한국어로 /기본/의 2음절은 [bon], 일본어로 /きほん/의 2음절은 [hon]
으로, /주문/의 2음절은 [mun], 일본어 /ちゅうもん/의 2음절은 [mon]으로 1음 절은 일치하나 각각 2음절에서 유사도가 낮다. 순위 3번의 ‘手段’은 한국어로 / 수단/, 일본어로 /しゅだん/으로 2음절은 [dan]으로 일치하나 1음절에서 [su]와 [syu]로 유사도가 낮다고 할 수 있다. 순위 4번의 경우 ‘写真’는 /사진/과 /しゃし ん[syashin]으로, ‘時間’도 /시간/[sigan]과 /じかん/[jikan]으로 1음절과 2음절 모 두 모어인 일본어와 유사도가 낮아 순위 2번과 3번에 비해 가장 유추하기 어려운 한자어라고 볼 수 있다.
표 5. (C)V+(C)VC 한자어 어휘 수와 비율
순위 어휘 수 비율(%)
1 6 10%
2 19 31%
3 1 2%
4 34 57%
합계 60
(C)V+(C)VC 음절 구조에서는 <표 5>에 제시한 바와 같이 1음절과 2음절의 유 사도가 가장 높은 순위 1번의 어휘는 전체 60개 중 6개로 10%의 비율로 나타났 다. 또한 각각의 음절에서 한 개씩만 일치하는 순위 2번과 3번은 전체 60개 중 20 개로 33%의 비율로 나타났고, 1음절과 2음절의 유사도가 가장 낮은 순위 4번은 전체 60개의 어휘 중 34개로 57%의 비율로 나타나 일본인 학습자가 모어인 일 본어와 동음동의어라 불리는 한국어의 한자어를 유추하기에는 어려운 비율이 절반 이상을 차지하는 것을 알 수 있다.
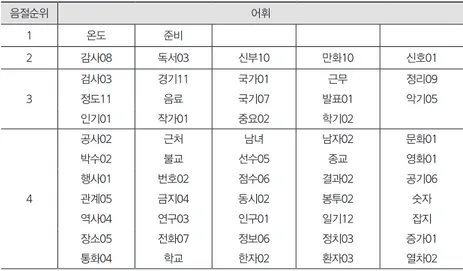
표 6. (C)VC+(C)V 한자어의 난이도 위계
음절순위 어휘
1 온도 준비
2 감사08 독서03 신부10 만화10 신호01
3
검사03 경기11 국가01 근무 정리09
정도11 음료 국기07 발표01 악기05
인기01 작가01 중요02 학기02
4
공사02 근처 남녀 남자02 문화01
박수02 불교 선수05 종교 영화01
행사01 번호02 점수06 결과02 공기06
관계05 금지04 동시02 봉투02 숫자
역사04 연구03 인구01 일기12 잡지
장소05 전화07 정보06 정치03 증가01
통화04 학교 한자02 환자03 열차02
<표 6>의 1음절과 2음절이 모두 일치하는 어휘는 ‘温度, 準備’로 한국어로는 / 온도/, /준비/, 일본어로는 /おんど/, /じゅんび/로 단 2개로 나타났다. 순위 2번 의 ‘感謝’는 한국어로 /감사/, 일본어로 /かんしゃ/로 2음절이 [sa]와 [sya]로 유사 도가 낮고, 순위 3번의 ‘人気, 楽器’는 한국어 /인기/, /악기/로 일본어 /にんき/, /がっき/로 1음절이 [in]과 [nin], [ak]과 [gak]으로 유사도가 낮다. 1음절과 2음 절 모두 일치하지 않는 순위 4번은 ‘文化’는 한국어로 /문화/ 일본어로는 /ぶんか /[bunka]로 [mun]은 [bun]으로 [hwa]는 [ka]로, ‘学校’는 한국어로 /학교/ 일본 어로는 /がっこう/[gakko:]로 [hak]은 [gak]으로 [kyo]는 [ko:]로 유사도가 매우 낮게 나타났다.
표 7. (C)VC+(C)V 한자어 어휘 수와 비율
순위 어휘 수 비율(%)
1 2 4%
2 5 9%
3 14 25%
4 35 62%
합계 56
(C)VC+(C)V 음절 구조에서는 <표 7>에 제시한 바와 같이 1음절과 2음절의 유 사도가 가장 높은 순위 1번의 어휘는 전체 56개 중 단 2개로 4%의 비율로, 각각 의 음절에서 한 개씩만 일치하는 순위 2번과 3번은 전체 56개 중 19개로 34%의 비율로, 1음절과 2음절의 유사도가 가장 낮은 순위 4번은 전체 56개 중 35개로 62%의 비율로 나타났다. 이는 1음절과 2음절의 모든 유사성 정보와 절반의 유사 성 정보만으로 유추해야 할 어휘의 비율이 유사성의 정보가 전혀 없는 상태에서 유추해야 할 어휘의 비율에 비해 현저히 낮게 나타났음을 알 수 있다.
표 8. (C)VC+(C)VC 한자어의 난이도 위계
음절순위 어휘
2 신문10 실랑(신랑02) 심장02 안전03 운동02
운전02
3 관심01 중심01
4
건강03 결혼 경험 공연02 공원03
공장02 공항02 관광02 금년 남성01
동양03 등산 문법01 문장02 발전01
방문03 방송01 방향01 병원02 불편01
불행 상상07 상품03 상황02 선생01
성공01 연습03 월급 은행02 인간01
인삼 인형01 일반02 전공05 전쟁
전통06 정문03 정원03 정원06 중간01
중앙 청년 출근 특성01 학생
항공 행동 현금04
<표 8>에서는 1음절과 2음절이 모두 일치하는 순위 1번에 해당하는 어휘는 없 는 것으로 나타났다. 이는 앞서 언급한 일본어의 음절의 비율이 폐음절에 비해 개음절이 압도적으로 많고, 이는 종성이 영향을 미치기 때문이라 볼 수 있는데, 그 예로 한국어의 종성 ‘ㅇ’는 일본어에서는 거의 모든 어휘에서 개음절로 나타나 는 것을 들 수 있다. 순위 2번의 ‘運動’은 한국어 /운동/ 일본어 /うんどう/로 /동/
은 /どう/[do:]로 장음화되었고, 순위 3번의 ‘中心’ 역시 한국어로 /중심/ 일본어 로 /ちゅうしん/으로 /중/이 /ちゅう/[chu:]로 장음화됨을 알 수 있다. 순위 4 번의 ‘空港’은 /공항/이 /くうこう/[ku:ko:]로 1음절과 2음절의 종성 ‘ㅇ’이 모두
장음화되었고, ‘放送’도 /방송/이 /ほうそう/[ho:so:]로 모두 장음화로, ‘学生’도 /학생/이 /がくせい24/[gakse:]로 /생/의 종성 ‘ㅇ’이 장음화 되었다. 한국어 종성
‘ㅇ’의 어휘는 예외 없이 일본어의 장음화로 나타난 것을 알 수 있다.
표 9. (C)VC+(C)VC 한자어 어휘 수와 비율
순위 어휘 수 비율(%)
1 0 0%
2 6 11%
3 2 4%
4 48 85%
합계 56
(C)VC+(C)VC 음절 구조에서는 <표 9>에 제시한 바와 같이 1음절과 2음절의 유사도가 가장 높은 순위 1번의 어휘는 전체 56개 중 단 한 개도 나타나지 않았 다. 1음절과 2음절의 모든 유사성 정보를 바탕으로 유추할 수 있는 어휘는 (C)VC +(C)VC 음절 구조에서는 나타나지 않았다. 반면, 1음절과 2음절의 유사도가 가 장 낮은 순위 4번은 전체 56개 중 43개로 85%의 높은 비율로 나타났다. 절반의 유사성 정보만으로 유추해야 할 각각의 음절에서 한 개씩만 일치하는 순위 2번 과 3번은 전체 56개 중 8개로 15%의 비율로 나타났다. 10개의 어휘 중 유사성 정 보가 전혀 없는 상태에서 유추해야 할 어휘가 8개 이상인 것을 알 수 있다.
표 10. 난이도 위계에 따른 동음동의 한자어 어휘 수와 비율
순위 어휘 수 비율(%)
1 16 7%
2 44 19%
3 28 12%
4 140 62%
합계 228
24 /がくせい/는 /ga ku se i/로 4박(拍)어이나 /ku/는 일본어의 모음 탈락 현상으로 촉음(促音)과 유사음 으로 나타나므로 [gakse:]로 2음절로 분류하였다.
이상으로 난이도 위계에 따른 동음동의 한자어를 정리하면 1음절과 2음절의 유사도가 가장 높은 순위 1번의 어휘는 총 228개 중 16개로 7%로, 각각 한 개씩 만 일치하여 순위 1번에 비해 유사도가 낮은 어휘는 총 228개 중 73개로 31%로, 1음절과 2음절의 유사도가 가장 낮은 순위 4번의 어휘는 총 228개 중 140개로 62%의 비율로 나타났다. 이는 1음절과 2음절의 모든 유사성 정보를 가지고 유추 할 수 있는 어휘가 10개 중 채 1개가 되지 않는다고 할 수 있고, 절반의 유사성 정 보로 유추할 수 있는 어휘는 10개 중 3개 정도에 그치며, 나머지 6, 7개는 유사성 정보가 전혀 없는 상태에서 유추해야 할 어휘라 할 수 있다.
기존의 연구에서는 한국어와 일본어의 기초한자의 유사성으로 일본인 학습자 의 한국어 어휘 습득에 관해 동음동의어는 학습에 어려움이 없을 것으로 보고 주 로 동음이의어를 중심으로 이루어져 왔다고 할 수 있다. 그러나 동음동의어라고 는 하나 본 연구에서 제시한 음절구조와 음절, 음절 별 음소의 음운적 차이에 따 른 유사도로 제시된 동음동의 한자어의 결과를 바탕으로 역설하면, 기존의 연구 에서 제시된 동음동의 한자어는 과연 일본인 학습자에게 동음 한자어로 인지될 수 있을지 한일 동음 한자어에 관한 연구가 재조명되어야 한다고 할 수 있을 것 이다.
6. 결론
본 연구에서는 한일 동의 한자어 중 음절 구조와 음절, 음절 별 음소의 음운적 유사성을 기준으로 분석하여 동음어를 선정하고 일본인 학습자의 모어인 일본 어와의 유사도에 따라 초급 한국어 한자 어휘를 위계화하여 제시하였다. 일본인 학습자는 한자어라는 공통 요소가 모어에 존재하여 한국어 어휘 습득에 용이하 다고 할 수 있으나 음운적 차이로 모어와의 매개체 생성이 어렵다고 할 수 있다.
기존의 한일 동음동의 한자어 연구에서는 한국어의 한자음을 기준으로 일본어 한자음의 대조분석을 통해 한일 동음동의 한자 어휘를 분석하여 제시하고 있고, 대부분 한국 한자 어휘의 한 가지 음에 일본 한자 어휘의 몇 가지 음이 일대다대
응으로 제시되어 있어 이러한 분석은 한국어와 일본어에 대한 지식이 바탕이 되 어야 유용하게 활용할 수 있는 제한된 지식이라 볼 수 있다. 이에 본 연구에서는 음절 구조, 음절, 음절 별 음소의 대조분석을 통해 발음의 유사성을 바탕으로 일 본인 학습자의 어휘 능력 향상에 유용한 학습 자료로써 활용할 수 있도록 유사도 에 따른 한자 어휘와 그 순서를 제시하여 어휘 습득에 있어 형태적 요소, 의미적 요소뿐만 아니라 음운적 요소의 활용 역시 주요한 요소로 교육적인 가치가 있을 것이라는 근거로 삼고자 하였다. 본 연구에서는 초급 어휘만을 대상으로 분석하 였으나 향후 중급과 고급 이상의 한자어 분석도 어휘 습득 향상에 기여할 수 있 는 학습 자료가 될 것으로 예상하며 향후의 연구 과제로 남기고자 한다.
교신: 김선정(계명대학교 한국문화정보학과 교수, 언어학) (kimsj@kmu.ac.kr, 전화: 053-580-6310) Correspondence: Kim, SeonJung(Keimyung University, Professor, Languistics)(kimsj@kmu.ac.kr,
phone: 053-580-6310)
2018.05.15 접수, 2018.05.23 심사, 2018.06.15 게재확정
참고문헌
고혜정, 2011, 한국인의 일본어 음절말 비음에 관한 음향적 특징, 일본어교육, 56, 115-126.
사노 데루아키, 2004, 일본인 학습자를 위한 한국어 한자교육 방안 연구, 선문대학교 석사학 위논문.
신용태, 1999, 十五(六)世紀 韓国漢字音과 日本漢字音의 比較研究: 訓蒙字会漢字音을 중 심으로, 日本文化学報, 6, 327-351.
신지영, 2010, 한국어 사전 표제어 발음의 음소 및 음절 빈도, Communication Sciences and Disorders, 15(1), 94-106.
山口美佳·閔光準, 2009, 韓日両言語における外来語の音韻体系: 音節構造·母音·子音の 対照, 日本語文学, 41, 한국일본어문확회, 47-66.
우찬삼, 1991, 한일 양어의 음운변화에 대하여(Ⅰ), 日本語学研究, 1, 109-123.
윤영해, 2016, 한국어 학습자들의 종성 발음 연구: 중국어, 태국어, 프랑스어, 일본어 화자를 중심으로, 한국외국어대학교 박사학위논문.
윤혜숙, 2003, 베트남 학습자를 위한 어휘 교육 방안: True Friends와 False Friends 목록 활
용, 28, 145-168.
이동은, 2002, 일본인 학습자를 위한 한국어 한자 발음 교재 개발 방안 연구, 이화여자대학교 석사학위논문.
이이다 사오리, 2005, 韓日 同型異義 漢字語에 관한 一考察. 語文論叢, 16, 3-63.
조현용, 2000, 한국어 어휘교육 연구, 서울: 박이정.
카이모리 토키코, 2005, 일본어 모어 화자를 위한 한국 한자어 교육 방안 연구: 초급 어휘를 중심으로, 경희대학교 석사학위논문.
丹原邦博, 2009, 韓日兩語의「漢字語」對照硏究: 同形異義語·異形同義語를 中心으로, 한 국외국어대학교 박사학위논문.
한여빈, 2009, 중국인 한국어 학습자를 위한 한자어 교육 방안 연구, 계명대학교 석사학위논 문.
허용·김선정, 2013, 대조언어학. 안양: 소통.
菅野裕臣, 2004, 朝鮮の漢字音の話, 東京:神田外語学韓国語学科.
窪薗晴夫, 1999, 日本語の音声(現代言語学入門2), 東京:岩波書店.
海野和三郎·大原荘司, 1993, わたしの韓国語自修法, 東京:東京書店.
Lado, R. 1957, Linguistics across cultures. Ann Arbor: The University of Michigan.
Nation, I. S. P. 2001, Learning Vocabulary in Another Language, Cambridge University Press.
Prator, C. H. 1967, Hierarchy of difficulty. Unpublished classroom lecture, University of Cali- fornia, Los Angeles.
Yoshida, S. 2003, The syllabic nasal in Japanese, Stefan Ploch(ed), Living on the Edge: 28 Papers in Honour of Jonathan Kaye, Mouton de Gruyter, 527-542.
A Study on Setting Difficulty Hierarchy for Sino-Korean Words for Korean Language Education
- Focusing on Japanese Learners
Kim, Eun Jung* · Kim, Seon Jung**
Abstract_The purpose of this study is to categorize Korean-Japanese synonyms into similar and different in terms of pronunciation, and to show a degree of difficulty of Sino-Korean words for beginners according to their degree of simi- larity. This is done to propose that phonological information may also be edu- cationally valuable as an element of vocabulary acquisition. It is a common view that Japanese speakers learn Korean vocabulary easily because the two languages share common vocabulary originating from Chinese. However, it can also be said that it is difficult to create a medium between the target language and the learner’s native language because of the phonological differences between the two languages. Accordingly, in this study, we classify similar Chinese words into 4 levels of difficulty hierarchy according to their syllable structure, syllables, and segments, so that the Japanese learners are able to guess the meaning of Sino- Korean words based on their similarity with Japanese. As a result of the difficulty hierarchy analysis, vocabulary having high similarity both in the first and second syllable was found to be 7%, and vocabulary having only one high similarity in either the first or second syllable was found to be 31%. Finally, vocabulary hav- ing low similarity both in the first and second syllable was found to be 62%. This result means that less than one word among ten vocabularies can have its mean- ing predicted basing on the similarity of the first and second syllable. It can also be said that only three words were predictable based on their similarity of only one syllable in the two languages, and the remaining six or seven words were not
* Keimyung University, Teaching Korean as a Foreign Language, jungatess@daum.net
** Keimyung University, Professor, Linguistics, kimsj@kmu.ac.kr
predictable at all.
This study is meaningful due to the fact that the Chinese words used in both Korean and Japanese were classified into difficulty hierarchy based on their pho- nological similarity. Moreover. it also provides useful information for Japanese speaking Korean language learners.
Keywords_ Vocabulary Acquisition, Aocabulary, Syllable, Phoneme, Japanese, Hierarchy, Sino-Korean Words, Synonym, Homophone