Adaboost 와 깊이 맵 기반의 블록 순위 패턴의 템플릿 매칭을 이용한 얼굴검출
김 영 곤a), 박 래 홍a)‡, 문 성 수a)
Face Detection Using Adaboost and Template Matching of Depth Map based Block Rank Patterns
Young-Gon Kima), Rae-Hong Parka)‡, and Seong-Su Muna)
요 약
흑백 혹은 컬러 영상과 같은 2차원 정보를 사용한 얼굴 검출 알고리즘에 관한 연구가 수십 년 동안 이루어져 왔다. 최근에는 저가 range 센서가 개발되어, 이를 통해 3차원 정보 (깊이 정보: 카메라와 물체사이의 거리를 나타냄)를 손쉽게 이용함으로써 얼굴의 특징을 높은 신뢰도로 추출하는 것이 가능해졌다. 대부분 사람 얼굴에는 3차원적인 얼굴의 구조적인 특징이 있다. 본 논문에서는 흑백 영상과 깊이 영상을 사용하여 얼굴을 검출하는 알고리즘을 제안한다. 처음에는 흑백 영상에 adaboost를 적용하여 얼굴 후보 영역을 검출한다.
얼굴 후보 영역의 위치에 대응되는 깊이 영상에서의 얼굴 후보 영역을 추출한다. 추출된 영역의 크기를 5×5 영역으로 분할하여 깊이 값의 평균값을 구한다. 깊이 값들의 평균값들 간에 순위를 매김으로써 블록 순위 패턴이 생성된다. 얼굴 후보 영역의 블록 순위 패턴 과 학습 데이터를 사용하여 미리 학습된 템플릿 패턴을 매칭함으로써 최종 얼굴 영역인지 아닌지를 판단할 수 있다. 제안하는 방법의 성능을 Kinect sensor로 취득한 실제 영상으로 실험하였다. 실험 결과 true positive를 잘 보존하면서 많은 false positive들을 효과적으 로 제거하는 것을 보여준다.
Abstract
A face detection algorithms using two-dimensional (2-D) intensity or color images have been studied for decades. Recently, with the development of low-cost range sensor, three-dimensional (3-D) information (i.e., depth image that represents the distance between a camera and objects) can be easily used to reliably extract facial features. Most people have a similar pattern of 3-D facial structure. This paper proposes a face detection method using intensity and depth images. At first, adaboost algorithm using intensity image classifies face and nonface candidate regions. Each candidate region is divided into 5×5 blocks and depth values are averaged in each block. Then, 5×5 block rank pattern is constructed by sorting block averages of depth values. Finally, candidate regions are classified as face and nonface regions by matching the constructed depth map based block rank patterns and a template pattern that is generated from training data set. For template matching, the 5×5 template block rank pattern is prior constructed by averaging block ranks using training data set. The proposed algorithm is tested on real images obtained by Kinect range sensor. Experimental results show that the proposed algorithm effectively eliminates most false positives with true positives well preserved.
Keyword : Face detection, depth map, block rank pattern, template matching, adaboost, Kinect sensor 특집논문 (Special Paper)
방송공학회논문지 제17권 제3호, 2012년 5월 (JBE Vol. 17, No. 3, May 2012) http://dx.doi.org/10.5909/JBE.2012.17.3.437
a)서강대학교 전자공학과 (Department of Electronic Engineering, School of Engineering, Sogang University)
‡교신저자 : 박래홍 (Rae-Hong Park) E-mail: [email protected]
Tel: +82-2-716-4514, Fax: +82-2-716-4514
※ 본 연구는 Second Brain Korea 21 Project의 지원에 의한 것입니다.
․접수일(2012년3월15일),수정일(2012년4월27일),게재확정일(2012년4월27일)
Ⅰ. Introduction
Face detection is used as preprocessing of face related applications such as recognition, tracking, and so on [1].
Face detection algorithms using two-dimensional (2-D) in- tensity or color images have been studied for decades. The purpose of face detection is to detect location of face in image. However, in real images, face detection is very dif- ficult because real images have large variability of illumi- nation and complex background, giving a lot of false positives. Various conditions (i.e., illumination, face pose and expression, and occlusion by glasses or mustache) are considered [1] as causes of failure in face detection.
There are two approaches to face detection using 2-D images: example-based and template matching. Example- based algorithms automatically compute parameters and threshold values from a number of true and false examples.
The most widely used algorithm to detect face is adaboost algorithm [2], where Haar-like based features are used. To reduce the computation time, rectangular integral image and cascade structure are used. The performance of this al- gorithm is very high even if it is a simple real-time method.
A strong classifier consists of a number of weak classifiers.
Rowley et al. [3] proposed a neural network (NN) based algorithm, in which a lot of data set (i.e., faces or nonfaces) are learned using an NN with intensity information. Huang et al. [4] improved Rowley et al.’s algorithm using differ- ent features (i.e., gradient, 2D wavelet features, and Gabor features). Sung and Poggio [5] proposed a face detection algorithm using Gaussian clusters of distances from mean samples.
Other face detection approach is template matching, in which the template (constructed from training set) and a pattern of candidate region (detected from input image) are compared to classify face and nonface. Various algorithms using template matching have been studied. Predefined fixed-size windows were used as templates to detect facial features [6]. Then, the template matching algorithm using variable size window that can detect faces of varying sizes was presented [7]. To construct a template of accurate face region, Kherchaoui and Houacine [8] proposed a template matching algorithm using a model of skin color with constraints. Template matching algorithms using skin in- formation and lines of face template was also presented [9].
Liu et al. [10] proposed a template matching algorithm us- ing radial template to detect rotated face in any orientation.
Jeng et al. [11] proposed a template matching algorithm using a geometrical face model using relative distance be- tween facial features. Hiremath and Danti [12] improved Jeng et al.’s algorithm using additional color information.
Wang [13] proposed a 3×3 block model for face detection using wavelet coefficients for robustness to illumination.
Ahonen et al. [14] proposed a template matching algorithm using local binary patterns to reduce the sensitivity to illumination. Nilsson et al. [15] improved Ahonen et al.’s algorithm using local successive mean quantized transform (SMQT), where quantized intensity levels are used in local SMQT patterns.
Because of a lot of false positives that are detected in
images with complex background, three-dimensional (3-D)
information (i.e., depth image that represents the distance
between a camera and objects) is also used to reliably per-
form face detection. Kosov et al. [16] proposed a depth
map based face detection algorithm using principal compo-
nent analysis (PCA), where the depth map is generated
from captured stereo images. To reduce search region, Wu
et al. [17] used constraints that the distance between a cam-
era and face is limited. Jan et al. [18] proposed a depth
그림 1. 제안하는 얼굴 검출 알고리즘의 블록 다이어그램
Fig. 1. Block diagram of the proposed face detection algorithm
map based face detection algorithm using adaboost
algorithm. A lot features generated using Haar-like features are extracted from both intensity image and depth image.
Firstly, one cascade constructed from intensity image clas- sifies face and nonface candidate regions, where cascade consists of stages that contain a number of weak classifiers.
Each stage of cascade is to classify whether a given sub-window is definitely a face or nonface candidate region. Then, another cascade constructed from a depth im- age classifies face and nonface regions. Qian et al. [19]
proposed a depth map based face detection algorithm using variance of depth values. Face candidate regions are firstly classified by adaboost using intensity image. Then, var- iance of depth values corresponding to location of skin tone in a face is used to classify face and nonface (e.g., nonface including face drawn on paper). These algorithms for re- jecting false positives are not robust to round object or lim- ited size of face.
This paper proposes a face detection algorithm using a depth map based 5×5 block rank pattern that is robust to complex background or varying sizes of face. This paper is an extended version of our previous algorithm [20], in which modification of block rank pattern and performance comparison with conventional algorithm using PCA in depth map [16] are added. At first, adaboost algorithm us- ing intensity image classifies face and nonface candidate regions because adaboost algorithm can rapidly classify candidate regions in an input image. Each candidate region is split into 5×5 blocks and depth values are averaged in each block. Then, 5×5 block rank pattern is constructed by
sorting block averages of depth values in each block.
Finally, each candidate region is classified as a face and nonface region by matching the constructed depth map based block rank patterns and a template that is generated from training data set. For template matching, the 5×5 tem- plate block rank pattern is a priori constructed by averaging block ranks of training data set. To obtain training and test data set, we use Kinect range sensor [21]. Infrared projec- tor projects infrared patterns that people cannot see.
Infrared image is obtained by infrared camera and used to generate depth map. However, the regions that are not pro- jected by occlusion have no depth data.
The rest of the paper is structured as follows. Section
Ⅱ presents the proposed algorithm. Section Ⅲ gives ex- perimental results and discussions. Section Ⅳ concludes the paper.
Ⅱ. Proposed algorithm
Fig. 1 shows the block diagram of the proposed face de- tection algorithm, which consists of four parts: window scanning, extraction of facial features and classification, construction of block rank pattern, and template matching.
At first, a whole intensity image is scanned by windows with various sizes. Then, a number of features are extracted by using Haar-like features from ith sub-window
of in-
tensity image. The facial features are used to classify face
and nonface candidate regions. Then, each depth map
그림 2. 블록 순위 패턴의 생성에 대한 블록 다이어그램
Fig. 2. Detailed block diagram for construction of block rank pattern
based block rank pattern is calculated from the candidate
regions of previous results. Lastly, face and nonface re- gions are classified by matching each block rank pattern and the template that is generated from training data set.
1. Window scanning
In the window scanning step, a whole region of intensity image is scanned by windows of various sizes, where information including each coordinate and size of ith sub-window is defined as
. Intensity image of each sub-window
is generated by cropping the region corre- sponding to
from intensity image . If
is considered as a face candidate region in the extraction of facial fea- tures and classification step,
will be passed to the con- struction of block rank pattern step. Then, in the con- struction of block rank pattern step, in our previous algo- rithm [20], depth map of sub-window
is generated by cropping the region corresponding to
from the depth im- age , while in the proposed algorithm width and height of candidate region are increased to include background around a face. If the block rank pattern
of
satisfies inequality predefined by learning, the region corresponds to
is considered as a face region.
2. Extraction of facial features and classification
As mentioned previously, we used the adaboost algo- rithm to select face candidate regions. In the extraction of facial features and classification step, three steps are
needed. At the first step, a large number of features from a lot of training sets are extracted by Haar-like features, where integral image that can quickly compute a large number of features is used [1]. Then, a strong classifier is constructed from a lot of weak classifiers by adaboost algorithm. Lastly, using strong classifiers, cascade structure is constructed from coarse to fine, where a large fraction of nonface regions are rejected as nonface regions at the first stage of cascade.
3. Construction of block rank pattern
Coordinates and size of ith sub-window
are passed to construction of block rank pattern step. Construction of block rank pattern consists of three steps: region split, cal- culation of block average, and sorting of block averages.
Fig. 2 shows the structure for construction of block rank pattern. In the region split step, ith depth map based on sub-window
is obtained by using
and depth map im-
age , where width and height of candidate region are ex-
panded to contain the background around a face. Some
blocks include facial features [22] if
is a real face
region. Each of
in depth image is split into 5×5 square
blocks, because depth image based face gives a discrim-
inative pattern of facial features, in which nose and mouth
are closer to a camera than eyes and cheek. Fig. 3 shows
an example of region split. Fig. 3(a) shows a result of ada-
boost algorithm using intensity image, where detected
sub-window is marked with red square. Fig. 3(b) shows
face region in depth map whereas Fig. 3(c) shows an exam-
(a) (b) (c)
그림 3. 분할 영역에 대한 연산 결과. (a) adaboost 알고리즘의 결과, (b) sub-window 기반의 깊이 맵, (c) sub-window를 5×5 블록으로 분할하는 예 Fig. 3. Processing results of region split. (a) result of adaboost algorithm, (b) depth map based sub-window, (c) example of divided sub-window into 5×5 blocks
ple of sub-window divided into 5×5 blocks.
In the calculation of block average step, block average
is produced by computing average depth values in each block, which is described as,
(1)
where m and n represent the row and column indices of twenty five (5×5) blocks in depth map based sub-window,
≤ ≤
, respectively. and denote width and height of depth map based sub-window
, respectively, and are assumed to be multiples of five.
represents the total number of pixels except for pixels with no depth data. In Fig. 3(b), as mentioned, previously, black pixels denote pixels without depth data due to occlusion, registra- tion error, sampling error, and so on. Then, in the sorting of block average step, 5×5 block rank pattern
is con- structed by sorting block averages of depth values in de- scending order.
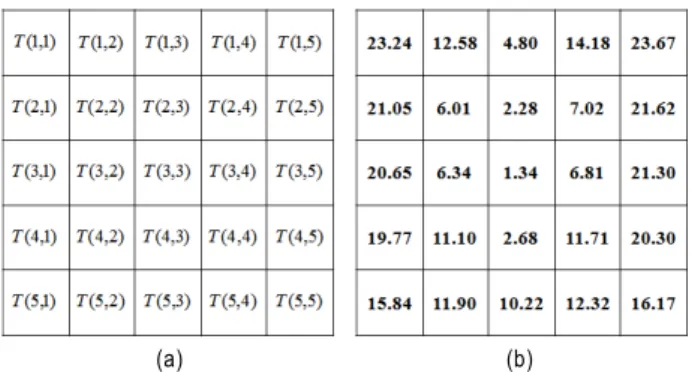
Fig. 4 shows an example of block rank pattern. Fig. 4(a) shows block rank pattern
and Fig. 4(b) shows an exam- ple of Fig. 4(a).
represents the rank of average depth values,
≤ ≤ . As mentioned, a block rank pattern
generated from a sub-window of Fig. 4(b) is to be matched with 5×5 template block rank pattern
.
(a) (b)
그림 4. 테스트 얼굴 영역에 대한 블록 순위 패턴. (a) 블록 순위 패턴, (b) 블론 순위 패턴에 대한 예
Fig. 4. Block rank pattern for a test face region. (a) block rank pattern, (b) example of a block rank pattern
4. Template matching In template matching,
are classified as face and non- face regions by matching the constructed depth map based block rank pattern
and 5×5 template block rank pattern
. To construct 5×5 template block rank pattern
that is calculated by averaging block ranks, training data set is needed. Training data used in our experiments are depth maps of candidate face regions
obtained by adaboost algorithm using intensity image. Fig. 5(a) shows 5×5 tem- plate block rank pattern
. Fig. 5(b) shows an example of average rank of 5×5 template block rank pattern
computed from 305 depth maps of real face sub-windows,
where
represents the average rank at
of
5×5 template block,
≤ ≤ . Forehead, nose, and mouth are closer to a camera than eyes, cheek, and background. Thus, blocks corresponding to forehead, nose, and mouth have relatively high ranks (small values) than other blocks corresponding to eyes, cheek, and background. Blocks corresponding to background have relatively low ranks (large values) than other block as shown in Fig. 5(b). The 5×5 average template block rank pattern
shown in Fig. 5(b) is matched with the block rank pattern generated from
using
and
.
represents the sum of squared absolute differences (SAD) of ith block between block rank patterns which explain 3-D facial structure and template block rank pat- tern, which is expressed as
≤ ≤
≠
(2)
denotes the sum of block ranks in background around a face, which is computed as
≤ ≤
(3)
If
is smaller than threshold
and
is larger than threshold
, candidate region is considered as a face where two thresholds
and
are computed from a number of training sets. Using
and
signify that the block rank patterns of 3-D facial structure and background around a face, as shown in 4(b) dark and light gray, respectively, are considered as significantly useful information to classify face or nonface. At first, all the candidate regions are classified as face or nonface candidate regions by comparison of
with
. Then, face or nonface regions are classified by comparison of
with
.
(a) (b)
그림 5. 테스트 얼굴 영역에 대한 블록 순위 패턴. (a) 5×5 템플릿 블록 순위 패턴, (b) 트레이닝 이미지에 대한 평균 순위 패턴
Fig. 5. Block rank pattern for test face regions. (a) 5×5 template block rank pattern, (b) average rank pattern using training test sets
Ⅲ. Experimental results and discussions
Test set is collected from Kinect range sensor for per- formance evaluation of the proposed face detection algorithm. Test set consists of 340 images containing vari- ous face size. Image size is 640×480 that contains a single or multiple faces per image. Threshold of
=7.5 and
70 are used for
and
, respectively, in clas- sifying face and nonface regions in the template matching step. We use a PC with a 2.67GHz Core i5 CPU and source code is coded by C language using OpenCV library [23].
As we mentioned, Kosov et al. [16] improved a real-time face detection algorithm by evaluating the eigenfaces of depth map, which are generated from captured stereo images. This method focuses on significantly removing in- correctly detected faces compared to previous 2-D face de- tection algorithms. The classification approach consists of two stages. First, this method trains boosted classifiers us- ing Haar-like features and identifies potential face candidates. Second, it performs PCA classification on the disparity map in order to detect correct face regions and reduces false positive face candidates.
We use true positive (TP) and false positive (FP) as per-
(a) (b) (c) (d)
그림 7. 얼굴 영역과 비얼굴 영역에 대한 블록 순위 패턴의 예. (a) 얼굴 영역에 대한 sub-window의 깊이 맵, (b) (a)에 대한 블록 순위 패턴, (c) 비얼굴 영역에 대한 sub-window의 깊이 맵, (d) (c)에 대한 블록 순위 패턴
Fig. 7. Examples of block rank patterns for face and nonface regions. (a) depth map based sub-window for a face region, (b) block rank pattern for (a), (c) depth map based sub-window for a nonface region, (d) block rank pattern for (c)
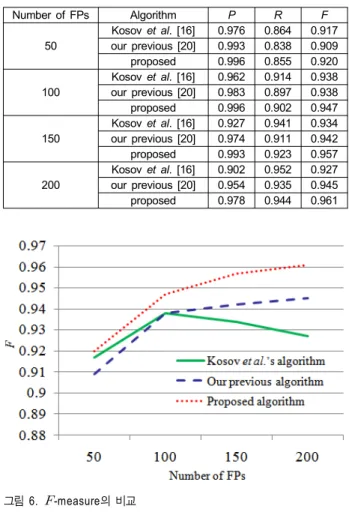
그림 6.
-measure의 비교 Fig. 6. Comparison for
-measureNumber of FPs Algorithm P R F
50
Kosov et al. [16] 0.976 0.864 0.917 our previous [20] 0.993 0.838 0.909 proposed 0.996 0.855 0.920
100
Kosov et al. [16] 0.962 0.914 0.938 our previous [20] 0.983 0.897 0.938 proposed 0.996 0.902 0.947
150
Kosov et al. [16] 0.927 0.941 0.934 our previous [20] 0.974 0.911 0.942 proposed 0.993 0.923 0.957
200
Kosov et al. [16] 0.902 0.952 0.927 our previous [20] 0.954 0.935 0.945 proposed 0.978 0.944 0.961 표 1. Kosov 등이 제안한 알고리즘 [16], 우리의 이전 연구 알고리즘 [20], 제안하는 알고리즘의 성능 비교
Table 1. Performance comparison of Kosov et al.’s algorithm [16], our previous algorithm [20], and proposed algorithm
formance indicators of face detection. TP represents the area containing a face correctly detected as face region, whereas FP denotes the area containing a nonface in- correctly detected as face region.
Three performance measures [24] (i.e., precision rate, re- call rate, and -measure) based on the number of FPs gen- erated from adaboost algorithm are computed by varying parameter value of scale factor from 1.05 to 1.1. The pre- cision rate is defined by (number of TPs)/(number of faces) and the recall rate is defined by (number of TPs)/(number of TPs + number of FPs). The -measure
is defined as
(4)
where and represent precision and recall rate, respectively. Table 1 and Fig. 6 show that of adaboost algorithm is higher than Kosov et al.'s algorithm and our previous algorithm for different number of FPs. It tells us that the proposed algorithm using expanded block rank pat- tern that includes background can effectively eliminate a lot of FPs that are incorrectly generated in adaboost algo- rithm due to complex background.
Fig. 7 shows examples of block rank patterns for face
and nonface regions. Figs. 7(a) and 7(c) show depth map
based sub-windows for a face and nonface region,
(a)
(b)
그림 8. 실제 영상에 대한 얼굴 검출 알고리즘 결과 비교. 첫 번째 열은 입력 영상. 나머지 열은 왼쪽부터 Kosov 등이 제안한 알고리즘 [16], 우리의 이전 연구 알고리즘 [20], 제안하는 알고리즘에 의해 생성되는 결과 영상
Fig. 8. Comparison of face detection algorithms for real images. First column is input images. The remaining columns are result images, from left to right, detected by Kosov et al.’s algorithm [16], our previous algorithm [20], and proposed algorithm
respectively. Figs. 7(b) and 7(d) show block rank pattern for Figs. 7(a) and 7(c), respectively. Block rank patterns in Figs. 7(b) and 7(d) are matched with 5×5 template block rank pattern shown in Fig. 5(b). A block rank pattern shown in Fig. 7(a) is classified as a face region because it satisfies
<
and
>
, whereas another block rank pattern in Fig. 7(b) is classified as a nonface region because it does not satisfy predefined inequality.
Fig. 8 shows comparison of face detection results of three algorithms: Kosov et al.'s algorithm [16], our pre- vious algorithm [20], and proposed algorithm. Fig. 8(a) shows, from left to right, the first test image and its face detection results by Kosov et al.'s algorithm, our previous algorithm, and proposed algorithm. Kosov et al.'s algo- rithm produces two detected faces (one true positive and one false positive). However, our previous algorithm and proposed algorithm detects one detected face (one true pos- itive). Fig. 8(b) shows the second test image and three face detection results. Kosov et al.'s algorithm detects one de- tected face (one false positive), and our previous algorithm detects two detected faces (one true positive and one false
positive). In contrast, our proposed algorithm detects one detected face (one true positive). Because Kosov et al.'s al- gorithm chooses the larger feature values and vectors to build the eigenface space for PCA and selects threshold of Mahalanobis distance to accept all face candidate regions that locate within the 99% range of all training sets, there is a possibility that non-faces will be accepted as faces in test sets. In contrast, our previous and proposed algorithms use depth map based block rank pattern, which have sim- ilar pattern of 3-D facial structure, to reject most of false positives in complex background. Experimental results show that the proposed algorithm is more robust to com- plex background than our previous algorithm because of employing expanded block rank pattern that contains back- ground around a face.
Ⅳ. Conclusions
In this paper, we propose a face detection algorithm us-
ing adaboost and template matching of depth information
using 5×5 block rank pattern, where a lot of FPs can be effectively eliminated, while true positives are well preserved. Depth map based 5×5 block rank pattern that reflects 3-D facial structure is used to effectively reject most of false positives in complex background. Experi- mental results show the effectiveness of the proposed algo- rithm, i.e., the proposed algorithm is robust to complex background and correctly detects faces. Isolated noise of depth map can be eliminated by median filter for perform- ance improvement before construction of block rank pattern. Future research will focus on the performance im- provement of the proposed algorithm for various complex images such as face images with glasses and profile face.
참 고 문 헌
[1] M.-H. Yang, D. J. Kriegman, and N. Ahuja, “Detecting faces in im- ages: A survey,” IEEE Trans. Pattern Anal. Machine Intell., vol. 24, no.
1, pp. 34–58, Jan. 2002.
[2] P. Viola and M. Jones, “Robust real-time face detection,” Int. J.
Computer Vision, vol. 57, no. 2, pp. 137–154, May 2004.
[3] H. A. Rowley, S. Baluja, and T. Kanade, “Neural network-based on face detection,” IEEE Trans. Pattern Anal. Machine Intell., vol. 20, no.
1, pp. 22–38, Jan. 1998.
[4] L.-L. Huang, A. Shimizu, and H. Kobatake, “Robust face detection us- ing Gabor filter features,” Pattern Recognition Letters, vol. 26, no. 11, pp. 1641–1649, Aug. 2005.
[5] K.-K. Sung and T. Poggio, “Example-based learning for view-based human face detection,” IEEE Trans. Pattern Anal. Machine Intell., vol.
20, no. 1, pp. 39–51, Jan. 1998.
[6] R. Brunelli and T. Poggio, “Face recognition: Features versus tem- plates,” IEEE Trans. Pattern Anal. Machine Intell., vol. 15, no. 10, pp.
1042–1052, Feb. 1993.
[7] A. Yuille, P. Hallinan, and D. Cohen, “Feature extraction from faces using deformable templates,” Int. J. Computer Vision, vol. 8, no. 2, pp.
99–111, Nov. 1992.
[8] S. Kherchaoui and A. Houacine, “Face detection based on a model of the skin color with constraints and template matching,” in Proc. Int.
Conf. Machine and Web Intelligence, Algiers, Algeria, pp. 469–472, Oct. 2010.
[9] Y. Hori, K. Shimizu, Y. Nakamura, and T. Kuroda, “A real-time multi face detection technique using positive-negative lines-of-face tem- plate,” in Proc. Int. Conf. Pattern Recognition, vol. 1, pp. 765–768, Cambridge, UK, Aug. 2004.
[10] H. Liu, S. Yan, X. Chen, and W. Gao, “Rotated face detection in color images using radial template (RT),” in Proc. Int. Conf. Acoustics,
Speech, and Signal Processing, vol. 3, pp. 213–216, Hong Kong, China, Apr. 2003.
[11] S.-H. Jeng, H.-Y. M. Liao, C.-C. Han, M.-Y. Chern, and Y. T. Liu,
“Facial feature detection using geometrical face model: An efficient ap- proach,” Pattern Recognition, vol. 31, no. 3, pp. 273–282, Mar. 1998.
[12] P. S. Hiremath and A. Danti, “Detection of multiple faces in an image using skin color information and lines-of-separability face model,” Int.
J. Pattern Recognition and Artificial Intell., vol. 20, no. 1, pp. 39–61, Jan. 2006.
[13] J.-W. Wang, “Precise face segmentation for recognition,” in Proc. Int.
Conf. Image Processing, pp. 2045–2048, Atlanta, GA, USA, Oct.
2006.
[14] T. Ahonen, A. Hadid, and M. Pietikäinen, “Face description with local binary patterns: Application to face recognition,” IEEE Trans. Pattern Anal. Machine Intell, vol. 28, no. 12, pp. 2037–2041, Dec. 2006.
[15] M. Nilsson, J. Nordberg, and I. Claesson, “Face detection using local SMQT features and split up snow classifier,” in Proc. IEEE Int.
Conf.Acoustics, Speech, and Signal Processing, vol. 2, pp. 589–592, Honolulu, HI, USA, Apr. 2006.
[16] S. Kosov, K. Scherbaum, K. Faber, T. Thormahlen, and H.-P. Seidel,
“Rapid stereo vision enhanced face detection,” in Proc. Int. Conf.
Image Processing, vol. 4, pp. 1221–1224, Cairo, Egypt, Nov. 2009.
[17] H. Wu, K. Suzuki, T. Wada, and Q. Chen, “Accelerating face detection by using depth information,” Advances in Image and Video Technology, Third Pacific Rim Symposium, PSIVT 2009, Lecture Notes in Computer Science, pp. 657−667, Tokyo, Japan, Jan. 2009.
[18] F. Jan, S. Daniel, and V. Alexander, “Face detection using 3D time of flight and colour cameras,” in Proc. 41st Int. Symposium and 6th German Conf. Robotics, pp. 112−116, Frankfurt, Germany, June 2010.
[19] J. Qian, S. Ma, Z. Hao, and Y. Shen, “Face detection and recognition method based on skin color and depth information,” in Proc. Consumer Electronics, Communications and Networks, pp. 345−348, XianNing, China, Apr. 2011.
[20] Y.-G. Kim and R.-H. Park, “Face detection using adaboost and template matching of depth map based 3˟3 block rank pattern,” in Proc. The 2012 Int. Workshop Advanced Image Technology, p. 51 (51:1-6), Ho Chi Minh City, Vietnam, Jan. 2012.
[21] http://www.xbox.com/en-US/kinect.
[22] K.-S. Park, R.-H. Park, and Y.-G. Kim, “Face detection using the 3×3 block rank patterns of gradient magnitude images and a geometric face model,” in 2011 Digest of Technical Papers Int. Conf. Consumer Electronics, pp. 818−819, Las Vegas, NV, USA, Jan. 2011.
[23] G. Bradski and A. Kaehler, Learning OpenCV: Computer Vision with the OpenCV Library, Sebastopol, CA, USA: O’Reilly Media Inc., 2008.
[24] T. C. W. Landgrebe, P. Paclik, R. P. W. Duin, and A. P. Bradley,
“Precision-recall operating characteristic (P-ROC) curves in imprecise environments,” in Proc. Int. Conf. Pattern Recognition, vol. 4, pp. 123 –127, Hong Kong, China, Aug. 2006.
저 자 소 개
김 영 곤
- 2010년 : 한림대학교 전자공학과 (공학사) - 2010년 ~ 현재 : 서강대학교 전자공학과 석사과정 - 주관심분야 : 컴퓨터 비젼 및 영상 처리
박 래 홍
- 1976년 : 서울대학교 전자공학과 (공학사) - 1979년 : 서울대학교 전자공학과 (공학석사)
- 1981년 : Stanford University (Stanford, CA) 전기공학과 (공학석사) - 1984년 : Stanford University (Stanford, CA) 전기공학과 (공학박사) - 1984년 ~ 현재 : 서강대학교 전자공학과 교수
- 1990년 : University of Maryland (College Park, MD) 방문교수 - 주관심분야 : 영상통신, 컴퓨터 비젼 및 패턴인식
문 성 수
- 2007년 ~ 현재 : 서강대학교 전자공학과 학사과정 - 주관심분야 : 컴퓨터 비젼 및 영상 처리



![그림 8. 실제 영상에 대한 얼굴 검출 알고리즘 결과 비교. 첫 번째 열은 입력 영상. 나머지 열은 왼쪽부터 Kosov 등이 제안한 알고리즘 [16], 우리의 이전 연구 알고리즘 [20], 제안하는 알고리즘에 의해 생성되는 결과 영상](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4804845.522226/8.892.133.769.694.953/영상에-알고리즘-왼쪽부터-알고리즘-알고리즘-제안하는-알고리즘에-생성되는.webp)
