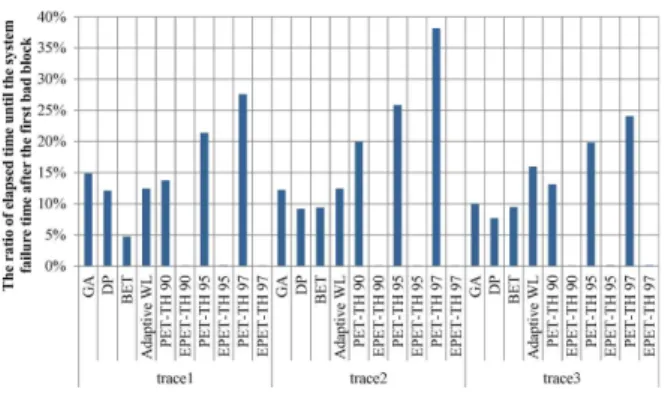
EPET-WL: Enhanced Prediction and Elapsed Time-based Wear Leveling Technique for NAND Flash Memory in Portable Devices
1)
전체 글
1)
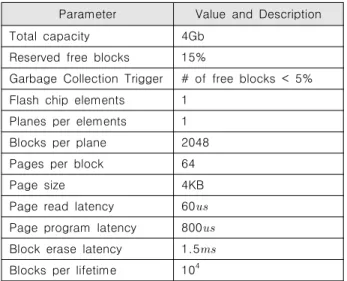
수치
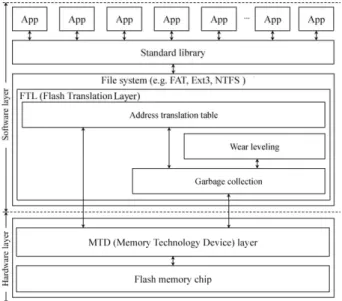
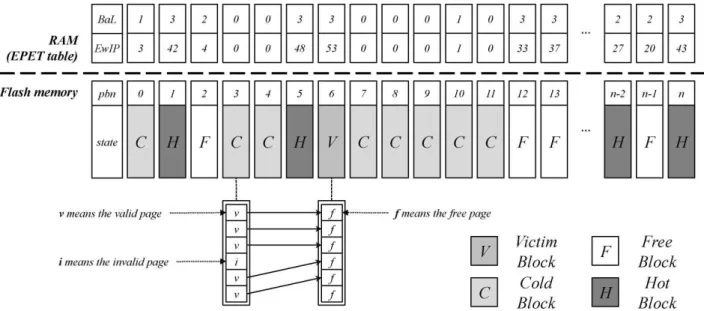
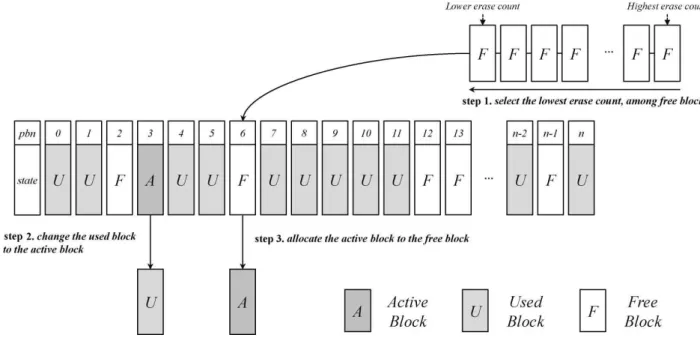
관련 문서