Korean Journal of Remote Sensing, Vol.35, No.6-1, 2019, pp.959~971
https://doi.org/10.7780/kjrs.2019.35.6.1.7 ISSN 1225-6161 ( Print )
ISSN 2287-9307 (Online)
Article
CNN 기반 초분광 영상 분류를 위한 PCA 차원축소의 영향 분석
곽태홍 1)·송아람 2)·김용일 3)†
The Impact of the PCA Dimensionality Reduction for CNN based Hyperspectral Image Classification
Taehong Kwak
1)·Ahram Song
2)·Yongil Kim
3)†Abstract: CNN (Convolutional Neural Network) is one representative deep learning algorithm, which can extract high-level spatial and spectral features, and has been applied for hyperspectral image classification. However, one significant drawback behind the application of CNNs in hyperspectral images is the high dimensionality of the data, which increases the training time and processing complexity. To address this problem, several CNN based hyperspectral image classification studies have exploited PCA (Principal Component Analysis) for dimensionality reduction. One limitation to this is that the spectral information of the original image can be lost through PCA. Although it is clear that the use of PCA affects the accuracy and the CNN training time, the impact of PCA for CNN based hyperspectral image classification has been understudied. The purpose of this study is to analyze the quantitative effect of PCA in CNN for hyperspectral image classification. The hyperspectral images were first transformed through PCA and applied into the CNN model by varying the size of the reduced dimensionality. In addition, 2D-CNN and 3D-CNN frameworks were applied to analyze the sensitivity of the PCA with respect to the convolution kernel in the model. Experimental results were evaluated based on classification accuracy, learning time, variance ratio, and training process. The size of the reduced dimensionality was the most efficient when the explained variance ratio recorded 99.7%~99.8%.
Since the 3D kernel had higher classification accuracy in the original-CNN than the PCA-CNN in comparison to the 2D-CNN, the results revealed that the dimensionality reduction was relatively less effective in 3D kernel.
Key Words: Principal Component Analysis, Convolutional Neural Network, Dimensionality Reduction, Hyperspectral Image Classification
Received November 26, 2019; Revised December 4, 2019; Accepted December 16, 2019; Published online December 18, 2019
1)
서울대학교 건설환경공학부 석사과정생 (Master Student, Department of Civil Engineering, Seoul National University)
2)
서울대학교 건설환경공학부 박사후연구원 (Postdoctoral Researcher, Department of Civil Engineering, Seoul National University)
3)
서울대학교 건설환경공학부 정교수 (Professor, Department of Civil Engineering, Seoul National University)
†
Corresponding Author: Yongil Kim ([email protected])
This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License
(http://creativecommons.org/licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in
any medium, provided the original work is properly cited.
1. 서 론
초분광 영상 (Hyperspectral Image)은 수백 개의 연속 적이고 좁은 분광 밴드(spectral band)를 가지는 영상을 말하며, 이를 바탕으로 탐지나 영상 분류에 효과적으로 활용된다 (Lillesand et al., 2015). 한편, 최근 딥러닝(deep learning) 기법은 많은 양의 데이터를 효과적으로 처리 함과 동시에 깊은 층을 통해 추상적인 특징을 추출할 수 있어 분류 , 영상인식 등 다양한 분야에서 우수한 성 능을 입증하고 있다 . 대표적인 딥러닝 기법 중 하나인 Convolutional Neural Network(CNN)는 고수준의 공간- 분광 특징을 추출할 수 있어 영상 분류 분야에서 두각 을 나타내고 있으며, 특히 초분광 영상에 대해서도 선 행 연구들을 통해 활발히 적용되고 있다. Slavkovikj et al.
(2015)와 Hu et al.(2015)는 CNN을 활용하여 초분광 영상 의 연속적인 분광 응답 함수 (spectral response function) 를 학습하였고 기존 전통적인 분류 기법 대비 우수한 성 능을 보여주었다 . Makantasis et al.(2015), Chen et al.(2016), Zhang et al.(2017) 등의 연구에서는 한 픽셀과 주변 픽셀 을 포함하는 패치 (patch)를 사용한 모델을 제안하여 효 율적이고 높은 정확도의 분류 결과를 보여주었다. 또한, 3차원 커널(3D kernel) 기반의 3D-CNN을 초분광 영상 의 3차원 데이터 큐브(data cube)에 적용하여 공간-분광 특징을 효과적으로 분석한 바 있다 (Li et al., 2017; He et al., 2017).
그러나 초분광 영상의 높은 분광 차원은 몇 가지 분 석의 문제점을 초래한다 . 고차원의 데이터는 분석 과정 을 복잡하게 만들어 학습시간을 증폭시킬 수 있다 . 뿐만 아니라 고차원의 변수는 그에 상응하는 다량의 학습 표 본을 필요로 하기 때문에 상대적인 학습 표본의 부족을 일으킬 수 있다. 이러한 문제를 해결하기 위해 다양한 차원축소 기법들이 초분광 영상에 적용되어왔다. 특히, Principal Component Analysis(PCA)는 데이터를 독립적 인 주성분의 축으로 변환시킬 수 있어 초분광 영상의 분 광 차원축소 기법으로써 활용되어왔다 . Rodarmel and Shan(2002)는 PCA가 소수의 주성분만으로도 원 영상과 유사한 분류 성능을 보여줄 수 있어 초분광 영상 분류 에 유용한 처리 기술이라고 분석하였다 . Lim et al.(2001) 은 신호 대 잡음비 (SNR: Signal to Noise Ratio)를 기반으 로 PCA의 데이터 압축 효과를 평가하였고, 이를 통해 초 분광 영상의 압축을 위한 PCA의 활용가능성을 증명하 였다. PCA가 초분광 영상을 효율적으로 압축할 수 있다 는 장점은 딥러닝 기반 초분광 영상 분류에서 더욱 부각 된다 . 딥러닝 네트워크 모수(parameter)의 개수는 필터 (filter)의 크기, 즉 너비(width), 높이(height), 채널(channel) 과 필터의 개수에 의해 결정된다 . 초분광 영상의 경우 높은 분광 차원에 의해 필터의 채널을 증폭시키고 이에 따라 연산의 복잡도가 증가한다. 이를 해결하기 위해 CNN 기반 초분광 영상 분류 연구들에서는 차원축소의 목적으로 PCA를 적용한 바 있다(Makantasis et al., 2015;
요약 : 대표적인 딥러닝 (deep learning) 기법 중 하나인 Convolutional Neural Network(CNN)은 고수준의 공간-
분광 특징을 추출할 수 있어 초분광 영상 분류(Hyperspectral Image Classification)에 적용하는 연구가 활발히 진
행되고 있다 . 그러나 초분광 영상은 높은 분광 차원이 학습 과정의 시간과 복잡도를 증가시킨다는 문제가 있
어 이를 해결하기 위해 기존 딥러닝 기반 초분광 영상 분류 연구들에서는 차원축소의 목적으로 Principal
Component Analysis (PCA)를 적용한 바 있다. PCA는 데이터를 독립적인 주성분의 축으로 변환시킬 수 있어 분
광 차원을 효율적으로 압축할 수 있으나, 분광 정보의 손실을 초래할 수 있다. PCA의 사용 유무가 CNN 학습의
정확도와 시간에 영향을 미치는 것은 분명하지만 이를 분석한 연구가 부족하다 . 본 연구의 목적은 PCA를 통한
분광 차원축소가 CNN에 미치는 영향을 정량적으로 분석하여 효율적인 초분광 영상 분류를 위한 적절한 PCA
의 적용 방법을 제안하는 데에 있다 . 이를 위해 PCA를 적용하여 초분광 영상을 축소시켰으며, 축소된 차원의
크기를 바꿔가며 CNN 모델에 적용하였다. 또한, 모델 내의 컨볼루션(convolution) 연산 방식에 따른 PCA의 민
감도를 분석하기 위해 2D-CNN과 3D-CNN을 적용하여 비교 분석하였다. 실험결과는 분류정확도, 학습시간,
분산 비율 , 학습 과정을 통해 분석되었다. 축소된 차원의 크기가 분산 비율이 99.7~8%인 주성분 개수일 때 가
장 효율적이었으며 , 3차원 커널 경우 2D-CNN과는 다르게 원 영상의 분류정확도가 PCA-CNN보다 더 높았
으며, 이를 통해 PCA의 차원축소 효과가 3차원 커널에서 상대적으로 적은 것을 알 수 있었다.
Zhao and Du, 2016; Chen et al., 2016; Liang and Li, 2016;
Zhang et al., 2017; Mei et al., 2019). 그러나 PCA를 사용한 기존의 CNN 기반 초분광 영상 분류 연구들은 PCA가 분 류결과에 미치는 영향에 대해 초점을 맞추지 않았으며 , PCA의 적용 방법에 대한 정량적 근거를 제시하지 않았 다는 점에서 한계점을 가진다 . PCA는 초분광 영상의 분 광 차원을 축소하여 딥러닝 네트워크의 복잡도를 낮출 수 있지만 , 원 영상의 풍부한 분광 정보를 그대로 보존 할 수 없어 분광 정보의 손실을 야기할 수 있다 . 이렇듯 PCA의 사용 유무는 학습의 정확도와 연산속도의 측면 에서 영향을 미치지만 이를 분석한 연구가 부족하다. 본 연구의 목적은 PCA를 통한 분광 차원축소가 CNN에 미치는 영향을 정량적으로 분석하여 효율적인 초분광 영상 분류를 위한 적절한 PCA의 적용 방법을 제안하는 데에 있다. 이를 위해 초분광 영상을 다양한 크기의 차 원으로 축소해가며 CNN에 적용하였다. 또한, 컨볼루 션 (convolution) 연산 방식에 따른 PCA의 민감도를 분석 하기 위해 2D-CNN과 3D-CNN, 두 가지 모델을 적용하 였다 . 본 논문은 다음과 같은 순서로 구성되어 있다. 2장 에서는 PCA와 CNN의 배경적 이론에 대해 설명한다. 3 장에서는 실험에 사용된 데이터와 방법론을 포함한 실 험 설계를 설명하고 4장에서 실험결과 및 결과 해석을 수행한다 . 마지막 5장에서는 본 연구의 결론과 함께 한 계점 및 향후 연구 방향을 제안한다.
2. 배경이론
1) PCA
PCA는 데이터를 작고 이해하기 쉬우며, 독립적인 정 보를 가진 변수들의 집합으로 바꿔주는 기법으로 초분광 영상 분석에 있어 차원을 줄이는 데 효과적이다 (Jensen and Lulla, 1987). 초분광 영상에서의 PCA 적용은 공분산 행렬의 고유분해에 따른 수학적 특성에 근거한다 . 원 영 상으로부터 주성분으로의 변환은 다음과 같은 고유분 해 Eq. (1)에 근거한다.
Σ = AΛA
T(1) Eq (1)에서 A=(a
1, a
2, …, a
N)는 고유벡터 행렬을 의미 하며 , and Λ는 고유값의 대각 행렬을 의미한다. 원 영상
의 I번째 픽셀 벡터(x
i)는 고유벡터 행렬을 통해 K번째 주성분까지의 픽셀 벡터 (z
i)로 변환된다(Eq. (2)).
z
i= [ ] = [ ][ ] (2) 변환된 주성분 밴드들 (PC bands)의 축은 고유벡터의 성질에 의해 서로 독립적이다 . 초분광 데이터는 연속적 인 분광 응답 함수를 가지기 때문에 , 주변 분광 정보가 중복되는 문제 (redundancy problem)를 내포하고 있는데, PCA의 특성은 이러한 중복을 제거해 줄 수 있다. 처음 K번째 주성분까지의 변환된 데이터로 설명되는 분산 비율 (explained variance ratio)은 Eq. (3)을 통해 계산될 수 있다 . 이때, 가장 처음의 주성분 밴드가 가장 많은 정보 량을 가지며 그 비율은 점점 감소하게 된다 . 효율적인 초분광 영상의 차원축소를 위해서는 적절한 주성분 밴 드를 선택하는 것이 중요하다 .
(3)
2) CNN
CNN은 대표적인 딥러닝 알고리즘 중 하나로 그리드 형태의 위상(grid-like topology)을 가진 데이터를 처리하 는데 널리 사용된다(Goodfellow et al., 2016). 영상 분류 의 맥락에서 CNN은 컨볼루션 커널(convolution kernel) 를 통해 공간적 특성을 고려할 수 있게 해준다. 컨볼루션 필터 연산의 모수는 필터의 크기와 개수로 결정되는데, 일반적으로 모수의 수가 많고 레이어 (layer)가 깊으면 모 델의 복잡도가 높다고 한다 . 초분광 영상의 경우 필터 의 크기 , 특히 채널을 증가시켜 모델의 복잡도를 높일 우려가 있다 . 모델의 복잡도가 높아지면, 연산 시간이 오래 걸리며 , 학습시킬 모수가 많아져 학습 표본의 상 대적 부족을 초래할 수 있다 .
한편 , 비디오와 같은 3차원 데이터 큐브를 효과적으 로 분석하기 위해 3차원 컨볼루션 필터가 적용된 3D- CNN이 발전해왔다(Ji et al., 2013; Tran et al., 2015). 3차원 컨볼루션 필터는 모수의 수를 더욱 증가시켜 모델의 복 잡도를 향상시키지만 , 분광 정보를 공간 정보와 함께 유 의미하게 추출할 수 있어 초분광 영상 분류에 3D-CNN 을 적용하기도 한다 . 2차원 컨볼루션 커널과 3차원 컨볼 루션 커널의 차이점은 Eq. (4)와 Eq. (5)를 통해 확인할
z
1z
2⋮ z
Ka
11a ⋮
K1… ···
… a
1Na ⋮
KNx
1⋮ x
N∑
Ki=1λ
iλ
1+ λ
2+ … + λ
N수 있다 .
v
lixy= f(∑
m∑
h=0Hi-1∑
w=0Wi-1k
limhwv
(l-1)m(x+h)(y+w)+ b
li) (4) v
lixyz= f(∑
m∑
h=0Hi-1∑
w=0Wi-1∑
r=0Rl-1k
hwlimv
(l-1)m(x+h)(y+w)+ b
li) (5) 여기에서 v
lixy는 l번째 레이어, i번째 특징맵(feature map)에서 (x, y)에서의 출력값을 의미하며, k와 f는 각각 커널 값과 활성함수 (activation function)을 의미한다. b
li는 바이어스 (bias value)를 의미하며, H, W, R는 각각 커 널의 높이와 너비, 채널을 의미한다.
3. 실험설계
본 연구에서는, 2개의 서로 다른 토지 피복을 가지는
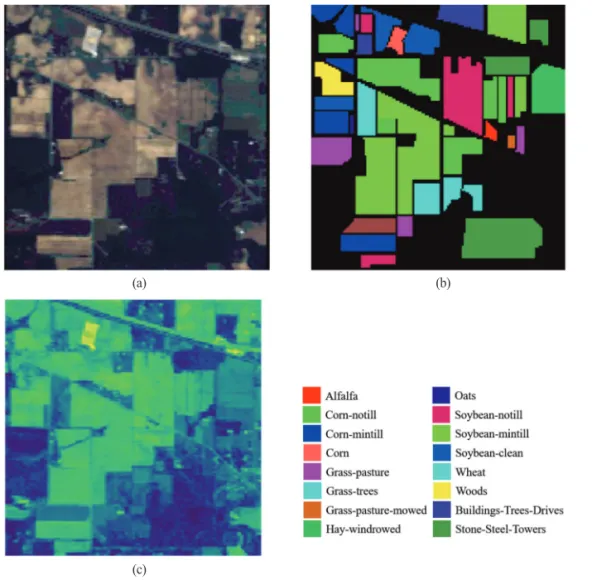
초분광 데이터셋 (dataset)을 사용하였다. 첫 번째 데이터 는 AVIRIS(Airbornes Visible Infrared Imaging Spectro - meter)를 통해 촬영된 IP(Indian Pines) 초분광 영상이다 (Fig. 1(a) and Fig. 1(b)). IP 영상은 145×145픽셀과 0.4~2.5 µm 구간의 220개의 분광 밴드로 이루어져 있다. IP의 토 지 피복은 주로 식생으로 이루어져 있으며 총 16개의 클 래스를 가진다. 두 번째 데이터는 ROSIS(Reflective Optics System Imaging Spectrometer)를 통해 촬영된 PU(Pavia University) 초분광 영상으로 610×340픽셀과 0.43~0.86 µm 범위의 104개의 분광 밴드로 구성되어 있다(Fig. 2(a) and Fig. 2(b)). PU는 도로, 건물과 같은 인공물의 토지 피 복을 포함하고 있으며 총 9개의 클래스를 갖는다.
먼저 차원축소를 위해 PCA를 두 데이터셋에 적용하 였다. Fig. 1(c)와 Fig. 2(c)는 PCA를 통해 분광 차원이 축
(c)
Fig. 1. Indian Pines hyperspectral dataset (a) true color image, (b) ground-truth image, (c) transformed image through PCA.
(a) (b)
소된 IP와 PU 영상으로, 첫 번째 주성분을 false color로 나타내었다 . 첫 번째 주성분에 대상 지역 주요 물질의 개략적 구분이 가능할 정도의 정보량이 포함되었음을 시각적으로 확인할 수 있다 . PCA를 통해 축소된 데이 터는 2D-CNN과 3D-CNN 모델을 학습시키는 데에 사 용된다 . 이를 위해 각각의 데이터를 학습표본(training sample), 검정표본(validation sample) 그리고 시험표본 (test sample)으로 분할하였으며, 정량적 비교를 위해 학 습표본과 검정표본을 모든 실험에 대해서 각각 2400개, 600개로 고정하였다. 이후 PCA의 영향을 분석하기 위 해 주성분의 개수를 바꿔가며 적용하였고 , 분류 결과를 비교 분석하였다 . 샘플링(sampling)과 학습의 무작위성 (randomness)을 배제하기 위하여 동일한 조건의 학습을 20번 반복한 뒤 상 하위 10%의 이상치를 제외한 나머지 의 평균값을 사용하였다. 추가로, PCA를 거치지 않은 원 영상으로도 CNN 모델을 학습시켰으며 PCA-CNN 의 분류 결과와 비교하였다 .
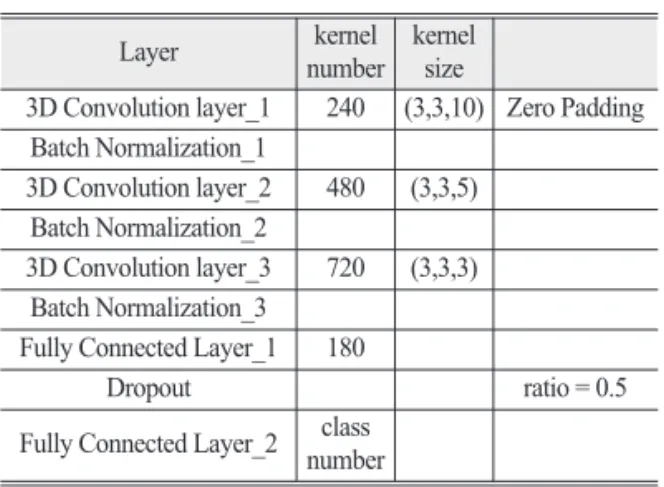
본 연구에서 사용된 CNN 모델은 Table 1과 같다. 모 델은 두 개의 컨볼루션 레이어 (convolutional layer)만으 로 구성되었는데 , 컴퓨터 비전(computer vision)에서 유 명한 GoogLeNet(Szegedy et al., 2015), VGGNet(Simonyan and Zisserman, 2014)과 같은 CNN 모델과 비교하면 그 깊이가 매우 얕다 . 이는 사용된 입력레이어의 크기 차 이 때문이다 . 유명한 CNN 모델들은 전체 영상을 입력
레이어 (input layer)로 사용하는 것과 달리, 본 연구에서 사용된 모델의 입력레이어는 한 픽셀과 주변 몇 개의 픽셀을 포함하는 패치 형태의 작은 데이터로 이를 학습 하기 위해서는 여러 층으로 깊게 쌓인 네트워크가 불필 요하다 . 따라서 두 개의 컨볼루션 레이어를 가지는 얕 은 모델을 설계하였고 컨볼루션 필터도 (3×3)의 작은 크기로 구성하였다 . 필터의 개수와 모델의 초모수 (hyperparameter)는 초기 실험을 통해 최적값으로 설정 되었다 . 컨볼루션 레이어 뒤에는 batch normalization layer(Loffe and Szegedy, 2015)가 이어지는데, 이 레이어 는 출력값을 정규화하여 편차가 커지는 것을 방지하는 역할을 한다 . 컨볼루션 과정을 통해 학습된 특징 (feature)은 전 연결 레이어를 통해 적절한 클래스로 분 (a) (b) (c)
Fig. 2. Pavia University hyperspectral dataset (a) true color image, (b) ground-truth image, (c) transformed image through PCA.
Table 1. 2D-CNN model architecture
Layer kernel
number kernel size
2D Convolution layer_1 240 (3,3) Zero Padding Batch Normalization_1
2D Convolution layer_2 720 (3,3) Batch Normalization_2
Fully Connected Layer_1 180
Dropout ratio = 0.5
Fully Connected Layer_2 class
number
류된다. 전 연결 레이어에서 과적합(overfitting)을 방지 하기 위한 dropout 기법(Srivastava et al., 2014)을 추가로 적용하였다 . 설계된 2D-CNN 모델은 결과의 정량적 비
교를 위하여 모든 실험에 동일한 조건으로 적용되었다 . 본 연구에서는 3D-CNN의 적용을 통해 PCA 기반의 분광 차원축소가 컨볼루션 연산에 미치는 영향을 비교 분석하였다 . Table 2는 본 연구에서 사용된 3D-CNN의 모델을 보여준다 . 필터의 크기와 모델의 깊이는 초기 실 험을 통해 적절하게 설정되었으며 2D-CNN과 마찬가 지로 각 실험에서 모두 동일한 모델이 적용되어 정량적 비교가 가능하도록 하였다 .
4. 실험결과 및 논의
1) 실험결과
Tables 3 and 4는 본 연구의 실험결과를 보여주며, 각 Table 2. 3D-CNN model architecture
Layer kernel
number kernel
3D Convolution layer_1 240 (3,3,10) Zero Padding size Batch Normalization_1
3D Convolution layer_2 480 (3,3,5) Batch Normalization_2
3D Convolution layer_3 720 (3,3,3) Batch Normalization_3
Fully Connected Layer_1 180
Dropout ratio = 0.5
Fully Connected Layer_2 class number
Table 3. Experimental results of 2D-CNN
IP dataset PU dataset
PC bands Test Accuracy (%) Training Time (s) PC bands Test Accuracy (%) Training Time (s)
1 68.58357 10.7819 1 73.39879 9.531505
2 82.04981 9.319522 2 88.39931 10.27563
3 86.95915 10.16325 3 91.21051 8.925627
4 88.42005 9.306988 4 93.64954 8.852819
5 89.95604 9.6452 5 94.46073 8.807688
6 90.20286 9.433867 6 95.43359 8.908297
7 89.93603 9.097101 7 95.39018 8.797963
8 90.53281 9.408797 8 96.21277 8.802705
9 90.24767 9.184494 9 96.42326 8.79535
10 90.33388 9.009693 10 97.0598 8.106314
11 90.59284 9.119733 11 97.45585 9.09013
12 91.70703 8.913344 12 97.72101 9.23948
13 91.85516 8.753643 13 97.58899 9.754672
14 92.33084 8.871147 14 97.738 9.693834
15 93.43579 8.594756 15 97.57624 9.176777
16 93.42057 8.783003 16 97.69358 9.538138
17 93.74743 8.895328 17 97.75354 9.871401
18 93.63968 9.009649 18 97.90262 9.014591
19 93.71459 8.807592 19 97.85116 9.778179
20 93.77685 8.846275 20 97.81144 9.325327
25 94.15931 9.096915 25 97.9205 9.849349
30 94.297 9.112585 30 97.86782 9.481554
35 94.40288 9.145552 35 97.90702 10.23832
40 95.14453 9.641937 40 98.00065 9.036345
50 95.81554 10.19339 50 97.89919 8.836493
60 95.96504 9.984912 60 9807365 9.95363
70 96.04988 9.541723 70 98.19356 9.990177
Original 95.33131 25.30892 Original 96.75034 16.68179
실험의 시험정확도 (test accuracy)와 학습시간(training time)을 나타낸다.
2) 학습시간과 분류 정확도
먼저 , 학습시간의 경우 IP, PU에서 모두 PCA를 적용 하였을 때 8~9초가 소요되었지만, 원 영상을 활용하였 을 때에는 25초(IP)와 16초(PU)가 소요되어 학습시간이 약 2~3배 증가함을 알 수 있다. 본 연구에서 사용된 영 상의 크기가 비교적 작으며 표본을 3000개의 적은 개수
로 설정한 점을 고려하면 경우에 따라서 학습 시간의 차이는 더욱 증가될 우려가 있다 . Fig. 3은 두 영상에서 의 2D-CNN 분류정확도를 시각적으로 보여준다. 특정 주성분 밴드부터는 원 영상을 활용하였을 때보다도 높 은 정확도를 보였으며 그 때의 주성분 개수는 각각 IP 50개, PU 10개이다. Table 5는 각 영상에 대해서 처음 부터 해당 주성분까지의 데이터로 설명되는 분산 비율 (explained variance ratio)을 보여준다. 원 영상 정확도 를 넘는 주성분에서의 분산 비율은 각각 99.72%(IP), Table 4. Experimental results of 3D-CNN
IP dataset PU dataset
PC bands Test Accuracy (%) Training Time (s) PC bands Test Accuracy (%) Training Time (s)
10 92.50701 137.4466 10 97.56093 159.945
11 92.34178 144.2866 11 97.95016 167.2459
12 92.85133 144.7644 12 97.88376 136.3261
13 93.24011 158.7674 13 97.75819 158.7389
14 93.23105 137.0639 14 97.69589 144.283
15 94.26416 169.5158 15 97.43767 133.9101
16 94.22756 156.6929 16 97.59275 146.2795
17 94.52176 182.8659 17 97.8085 159.8528
18 93.94362 155.7501 18 97.51405 145.7445
19 94.38697 194.0764 19 97.1249 166.0927
20 94.74411 201.3764 20 97.3633 182.1997
25 95.19089 217.2179 25 97.44907 234.3092
30 95.21141 252.28 30 97.1053 255.2466
35 95.21415 313.7612 35 97.27543 266.3736
40 95.77826 335.9471 40 97.05902 267.1381
50 96.43131 423.7522 50 96.9789 490.4673
60 96.81582 422.7957 60 96.30074 372.7869
70 97.11002 527.0681 70 96.5536 489.5065
Original 96.704 2714.685 Original 97.584 1380.545
(a) IP (b) PU
Fig. 3. Result graphs of test accuracy in 2D-CNN (a) Indian Pines, (b) Pavia University.
99.81%(PU)로 유사한 값을 보인다. 즉, 누적정보량이 99.7~8% 이상이 될 때의 주성분에서부터는 원 영상과 비교해도 충분한 분류 성능을 보일 수 있다는 것을 의 미한다 . 주성분의 개수에 따른 시험정확도 그래프는 두 영상에서 유사한 양상을 보인다 . 처음에는 주성분의 개수가 증가함에 따라 시험정확도도 함께 증가하지만 , 일정 수준부터는 유의미한 정확도 상승을 관찰하기 어 렵다 . 시험정확도가 수렴할 때의 주성분 개수는 각각 IP 에서 50~60개, PU에서 10~12개로, 앞서 원 영상만큼의 분류 성능을 보일 수 있는 주성분의 개수와 유사한 것 을 알 수 있다 . 즉, PCA를 통해 99.7~8%의 분산 비율을 포함하는 주성분으로 차원을 축소하면 , 학습시간을 1/2~1/3까지 단축함과 동시에 높은 시험정확도를 유 지할 수 있어 효율적인 영상 분류를 수행할 수 있다 .
3) CNN의 분류 성능
Fig. 4는 주성분 개수에 따른 2D-CNN과 다른 기존 전 통적인 분류 기법들의 결과를 보여준다. 사용된 기법은 초분광 영상 분류에 사용되는 대표적인 감독분류 기법 들로 최대우도분류 (MLC: Maximum Likelihood Classifi - cation)와 결정 트리(DT: Decision Tree) 기법이다. Fig. 4
를 통해 2D-CNN이 모든 경우에서 MLC와 DT보다 분 류 정확도가 높다는 것을 확인할 수 있다. 2D-CNN은 분류 정확도가 95% 이상에서 수렴하는 반면, MLC와 DT는 70~80%의 정확도에서 수렴한다. 따라서, 본 연구 에서 사용된 CNN 모델의 우수한 분류 성능을 기존 기 법과 비교하여 증명할 수 있었다 .
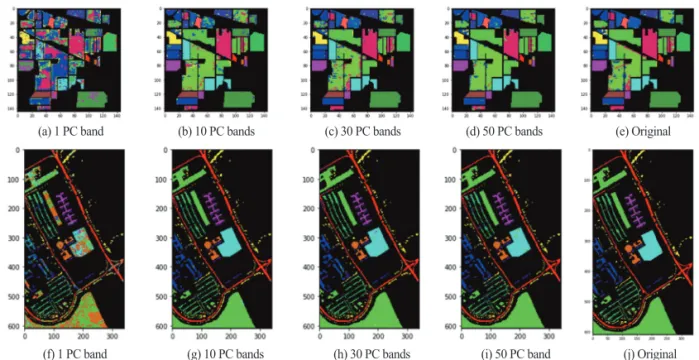
4) 분류 결과 영상
Fig. 5는 분류 결과의 정성적 평가를 위한 분류 결과 영상을 나타내며 , 각각 첫 번째 주성분을 적용한 경우, 10번째까지의 주성분을 적용한 경우, 30번째까지의 주 성분을 적용한 경우, 50번째까지의 주성분을 적용한 경우, 원 영상을 적용한 경우의 결과를 보여준다. 첫 번 째 주성분 만을 사용한 경우에는 ground-truth의 클래스 와 색이 다른 다수의 오분류 픽셀을 관찰할 수 있다 . IP 결과 영상에서는 주성분의 개수가 늘어남에 따라 오분 류 픽셀들이 점차 감소하는 것을 확인할 수 있는 반면 , PU 결과 영상의 경우 10 PC bands 이후로는 눈에 띄는 변화를 확인하기 어렵다 . 이러한 양상은 정량적으로 분 류 정확도가 각각 10~15 PC bands(PU)와 50~60 PC bands (IP)에서 수렴한다는 점과 일치하는 결과이다.
Table 5. Explained variance ratio according to the number of PC bands in Indian Pines and Pavia University dataset
PC bands 1 2 3 4 5 6 7 8 9
Variance ratio IP 68.49 92.02 93.51 94.33 95.03 95.55 95.95 96.31 96.62
PU 58.31 94.41 98.85 99.15 99.36 99.54 99.66 99.73 99.78
PC bands 10 15 20 25 30 40 50 60 70
Variance ratio IP 96.91 98.01 98.65 99.00 99.24 99.54 99.72 99.83 99.90
PU 99.81 99.89 99.93 99.95 99.96 99.98 99.99 99.99 99.99
(a) IP (b) PU
Fig. 4. Result graphs of test accuracy in 2D-CNN, MLC, DT (a) Indian Pines, (b) Pavia University.
5) 분류결과의 안정성
원 영상과 비교했을 때 PCA의 영향은 모델의 학습 과정을 통해서도 확인할 수 있다. Fig. 6는 IP에서의 2D-
CNN 학습 과정을 나타내며, 각각 첫 번째 주성분 밴드 를 적용할 경우(Fig. 6(a)), 50번째 주성분 밴드까지 적용 할 경우(Fig. 6(b)), 원 영상을 적용할 경우(Fig. 6(c))의 학
(c)
Fig. 6. Training process of 2D-CNN in Indian Pines (a) first PC band, (b) 50 PC bands (c) Original-CNN.
(a) (b)
(a) 1 PC band (b) 10 PC bands (c) 30 PC bands (d) 50 PC bands (e) Original
(f) 1 PC band (g) 10 PC bands (h) 30 PC bands (i) 50 PC band (j) Original
Fig. 5. Classification Images of 2D-CNN in IP and PU.
습 과정을 보여준다 . 붉은색 그래프와 녹색 그래프는 각 각 반복 횟수(epoch)에 따른 검정표본의 손실과 정확도 를 보여주며 , 노란색 그래프와 파란색 그래프는 각각 시 험표본의 손실과 정확도를 보여준다. Fig. 6(a)는 1 PC band에서 검정정확도가 60~70% 수준으로 머물며 더이 상 상승하지 않는 것을 보여준다 . 실제 1 PC band의 시 험정확도는 68.5%(Table 3)로, 검정표본과 유사하게 제 대로 분류가 수행되지 않았으며 이는 부족한 분광 정보 로 인해 충분한 학습이 이루지지 않았기 때문이다. 반 면 50개까지의 주성분을 사용한 경우와 원 영상을 활용 한 경우에서는 모두 시험정확도가 95% 수준으로 우수 한 분류 성능을 보였다 . 하지만 학습과정은 두 경우가 다른 양상을 보이고 있다 . 50 PC bands에서는 검정정확 도가 큰 변동없이 안정적인 분류 결과를 보이고 있으나, 원 영상을 활용한 경우에는 비교적 검정정확도의 변동 폭이 크고 불안정한 것을 확인할 수 있다 (Fig. 6(b) and
6(c)). 검정정확도의 폭이 커진다는 것은 훈련 표본을 통 해 학습된 모델이 다른 분포를 가진 표본에 적용되었을 때 안정적인 성능을 보장하기 어렵다는 것을 의미한다 . 즉, 원 영상을 활용한 경우 분류 결과의 안정성이 떨어 진다고 할 수 있는데 , 이는 원 영상의 차원이 매우 높으 며 또한 다수의 정보량이 중복되어 상대적으로 부족한 학습 표본에 모델이 과적합되었기 때문이다. 반면 PCA 를 적용한 경우에는 이러한 중복도를 줄여주고 차원을 축소시켰기 때문에 안정적인 분류 성능을 보여줄 수 있 었다 .
Fig. 7는 IP에서의 PCA50-2D-CNN과 Original-2D- CNN의 중간레이어의 활성화 값을 시각화하여 보여준다.
Fig. 7(a)와Fig. 7(c)는 첫번째컨볼루션레이어(convolution layer)의 활성화 값이며, Fig. 7(b)와 Fig. 7(d)는 마지막 컨 볼루션 레이어의 활성화 값을 보여준다 . 각각의 패치들 은 하나의 패치가 해당 레이어의 각 필터를 거친 결과
(c) (d)
Fig. 7. Activation results of the convolution layer of 2D-CNN in Indian Pines (a) first convolution layer of PCA-CNN, (b) last convolution layer of PCA-CNN, (c) first convolution layer of Original-CNN, (d) last convolution layer of Original-CNN.
(a) (b)
를 보여준다 . 밝은 값은 해당 필터가 설명하는 특징이 활성화된 것을 의미하며 , 이는 최종 분류 수행에 영향을 미치는 특징이 된다 . Fig. 7에 사용된 패치 기반 픽셀의 경우 첫 번째 레이어에서는 활성화 정도가 유사하지만 , 분류 결과에 직접적인 영향을 미치는 마지막 레이어의 경우 PCA에서 활성화된 패치가 원 영상에서보다 많은 것을 확인할 수 있다 .
6) 3D-CNN과의 비교
전술한대로 3차원 컨볼루션 연산이 포함된 3D-CNN 은 공간 정보와 함께 초분광 영상의 풍부한 분광 정보 를 유의미하게 추출할 수 있다 . 실제 원 영상의 분류 정 확도 (Table 4)는 각각 IP에서 96.704%, PU에서 97.584%
로 2D-CNN의 원 영상 정확도보다 높은 값을 기록했다.
하지만 PCA를 적용하였을 때에는 이러한 경향이 유지 되지 않는 것을 확인할 수 있다 . Fig. 8은 주성분 개수에 따른 2D-CNN과 3D-CNN의 시험정확도를 보여준다.
IP의 경우에는 PCA를 적용하여도 3D-CNN이 2D-CNN 보다 높은 정확도를 보인 반면 , PU에서는 처음 몇 개의 주성분을 제외하고는 2D-CNN의 정확도가 3D-CNN보 다 높은 것을 확인할 수 있다 . 두 그래프의 양상이 다른 것은 각각의 주성분 밴드가 포함하고 있는 누적정보량 의 차이에서 기인한 것으로 분석된다 . IP의 60개의 주성 분이 포함하고 있는 누적정보량은 PU에서는 10~15개 의 주성분에 충분히 포함된다 . 즉, IP의 그래프 양상은
PU 그래프의 초반 부분인 10~15개 주성분 부분에 해당 한다고 할 수 있다 . 결론적으로 3D-CNN에서는 PCA를 적용할 때 2D-CNN에 비해 분류 성능이 더욱 감소한다 고 할 수 있는데 , 이는 3D 컨볼루션의 연산 방식과 PCA 의 특성에 의한 것으로 분석된다 . 3D 컨볼루션 커널은 분광 차원의 위상 정보를 학습하게 되는데 PCA를 적용 할 경우 주성분 축이 물리적인 의미를 갖지 않기 때문 에 주성분 밴드 간의 무의미한 위상 정보를 학습하게 된 다 . 또한 그러한 경향은 주성분의 개수가 많아질수록 증 폭되어 분류 성능을 저하시킬 수 있다 . 결론적으로, PCA를 적용하여 초분광 영상을 압축하는 방법은 3D- CNN에서는 오히려 악영향을 미칠 가능성이 있으며, 3D 컨볼루션을 활용할 경우 원 영상을 사용하는 것이 유리하다 . 학습시간의 관점에서는 원 영상에 3D-CNN 을 적용한 경우가 학습시간이 80~100배 가량 늘지만 정 확도는 1~2%가 향상된 점을 고려하면 비효율적이라고 할 수 있다.
5. 결 론
본 논문에서는 효율적인 CNN 기반 초분광 영상 분 류를 위한 PCA의 영향을 분석하였다. 이를 위해 IP, PU 두 초분광 영상에 CNN을 적용하였고 결과를 비교 분 석하였다 . 두 지역 모두에서 PCA를 기반으로 축소된 차
Fig. 8. Test accuracy of 2D-CNn and 3D-CNN in Indian Pines and Pavia University.
원의 크기가 커짐에 따라 정확도도 증가하였지만 , 특정 수준부터는 유의미한 증가가 없이 수렴했으며 이때의 주성분 개수는 설명되는 분산 비율이 99.7~8%인 구간 이었다 . 또한, 이때의 정확도는 원 영상을 활용한 CNN 분류 결과보다 높은 수치를 기록하였으며 , 학습시간 역 시 PCA를 적용하였을 때가 더욱 적었다. 따라서 CNN 기반 초분광 영상 분류 시 , 99.7~8%의 분산비율을 포함 하는 주성분으로 PCA를 적용하는 것이 시간과 정확도 측면에서 효율적일 수 있다 . 또한, 분류 결과의 안정성 은 학습 과정을 통해 시각적으로 확인할 수 있었는데 , 원 영상의 학습 과정이 PCA를 기반으로 축소된 데이터 의 학습 과정에 비해 더욱 불안정한 것을 관찰할 수 있 었다. 한편, 3D-CNN의 경우, 원 영상을 활용하면 높은 정확도를 얻을 수 있지만, PCA가 적용된 영상을 활용하 면 오히려 2D-CNN보다 낮은 정확도를 얻어 PCA의 적 용 효과가 미미한 것으로 분석되었다 .
향후 연구로는 , 본 연구의 한계점인 한정적인 데이터 에 착안하여 , 더욱 다양한 데이터셋 활용을 통한 실험 결과의 신뢰도 확충이 진행될 수 있다 . 본 연구에서는 CNN 기반 초분광 영상의 차원축소 기법으로 가장 대 표적인 PCA를 선정하여 CNN의 성능에 미치는 영향을 분석하였으나 , 이 외에도 ICA(Independent Component Analysis), feature selection, MNF(Minimum Noise Fraction) 와 같은 다양한 차원축소 기법들이 CNN 기반 분류에 미치는 영향도 분석할 수 있다 . 마지막으로 CNN 이외 에도 최근 다양하게 제안되고 있는 초분광 영상 분류 딥 러닝 네트워크에서 역시 PCA가 효율적으로 적용될 수 있는지에 관한 연구도 진행될 수 있다 .
사 사