A Study on the Integration Between Smart Mobility Technology and Information Communication Technology (ICT) Using Patent Analysis
1)
전체 글
1)
수치
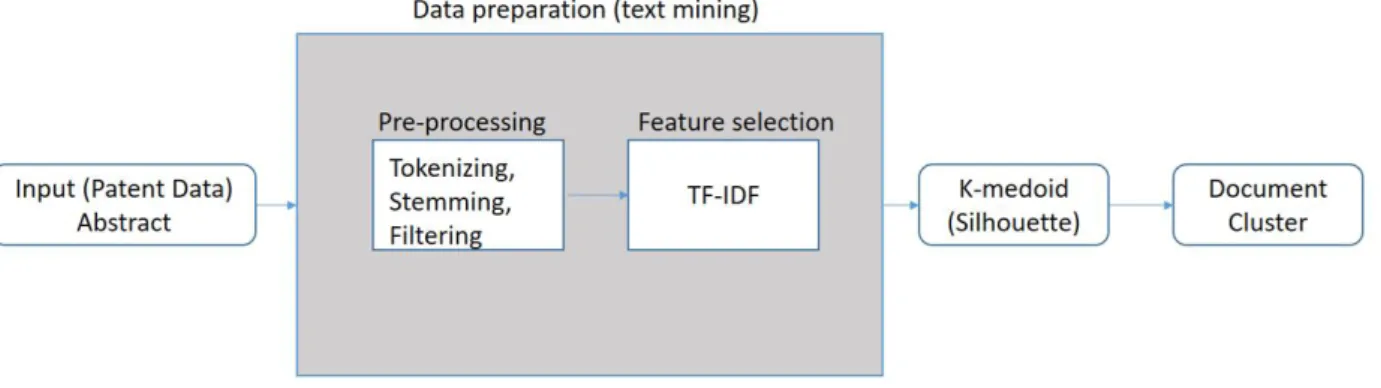
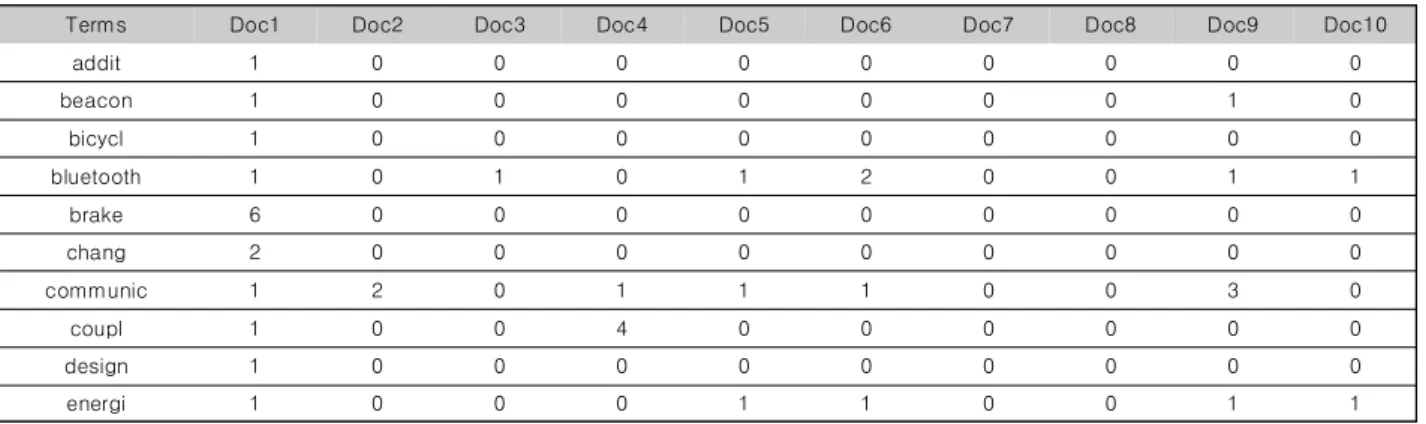
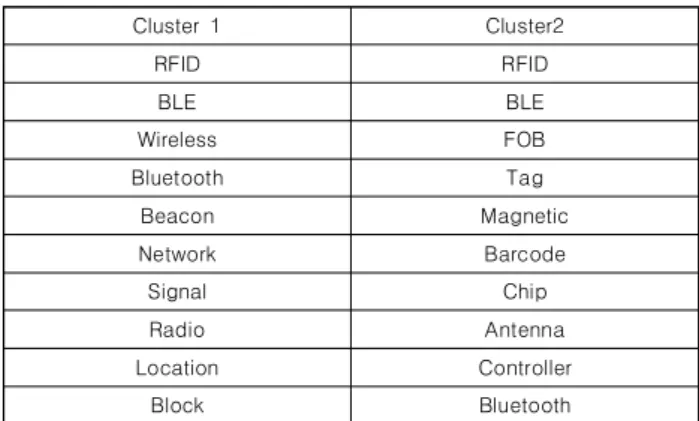
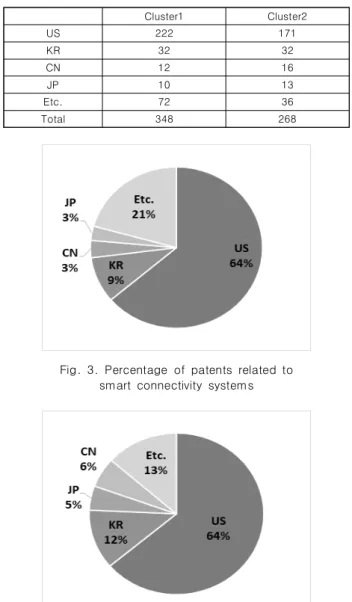
관련 문서
“Patent Analysis for Construction Technology Research Development” Journal of the Architectural Institute of Korea Structure &.
The objective of this study is to establish a direction for smart aquaculture technology development in the Republic of Korea through patent analysis and a demand survey of experts
This study depended mostly on literature review, supplemented by FGI(Focus Group Interview) for classification of the smart learning quality factors.. On a 5
While the first step of the comprehensive plan for educational informationization focused on the infrastructure establishment, the second step aims to develop
The purpose of this study is to investigate the possibility whether the technology studied in private sector by using augmented reality based on smart phone
Based on patent citation network analysis using 1,124 USPTO patents in the ICT convergence technology field of the smart factory, this study examined the proposed
Analysis of growth environment of Flammulina velutipes using the smart farm cultivation technology.. Kwan-Woo Lee 1, *, Jong-Ock Jeon 1 , Kyoung-Jun Lee 1 , Young-Ho Kim 1 ,
미 국과 영국에서는 GPS가 장착된 전자발찌로 아동 대 상 성범죄자나 보호관찰 대상자를 관리하는 것이 일 반화 되어 있으며, 최근 우리나라도 이러한 추세에 동참하기 위한
