ADD-Net: Attention Based 3D Dense Network for Action Recognition
1)
전체 글
1)
수치
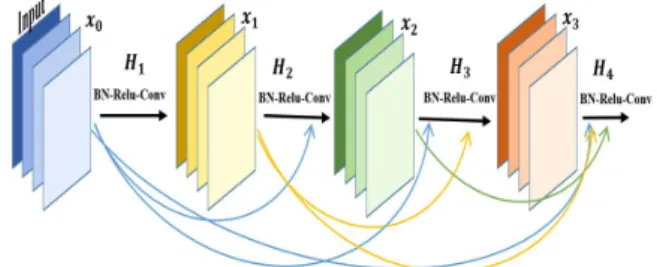

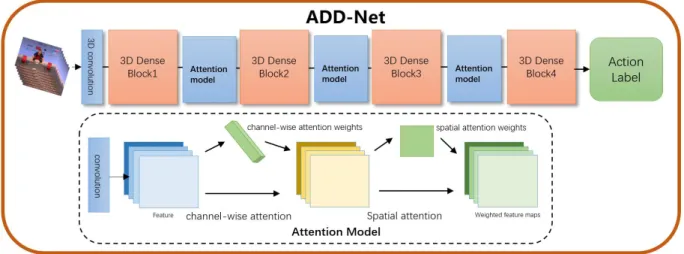
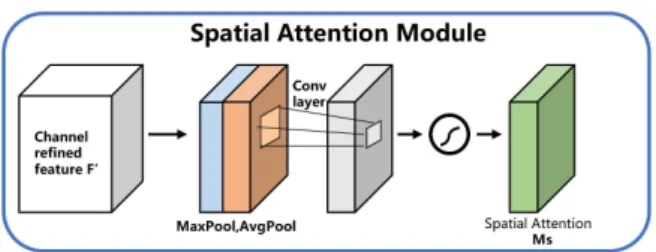
관련 문서
In order to further boost the performance of NMF, we propose a novel algorithm in this paper, called Dual graph-regularized Constrained Nonnegative Matrix Factorization
In this study, we propose a reliability demonstration test plan based on the accelerated random-effects Wiener process model.. First, we present a motivating
A Study on the Evaluation of Space Recognition Space Recognition Space Recognition in the Space Recognition in the in the in the Concourse of Hospital using the
The purpose of this study was to investigate the effects of sound-finding strategies based on phonological awareness on word recognition, oral reading
In order to conduct a more detailed and dense analysis of the overall operation of the Creation & Production Center, the case of the creation
In this chapter, we introduce unsupervised pattern recognition using a spiking neural network (SNN) based on the proposed synapse device and neuron circuit.. Unsupervised
Pitas, "Minimum Class Variance Extreme Learning Machine for Human Action Recognition,"IEEE Transactions on Circuits and Systems for Video Technology,
Based on the analyses method adopted in this paper for estimating the convective heat transfer coefficient in the cold chamber, a closed-system, the

