1. INTRODUCTION
Augmented reality (AR) has shown promising applications for education, industrial training, and even recreational purposes. For AR, the 3D camera (or object) pose has to be estimated using visual information from the camera images. In the liter- ature, there are two main approaches for camera pose estimation: marker-based[1,2] and markerless [3,4]. Marker-based methods use fiducial markers that usually have primitive shapes and discrim- inative colors, thus are easy-to-implement and robust. However, placing markers in the user space is visually disturbing, which makes users unpleasant. Also, marker-based methods are in- herently vulnerable to occlusion. Therefore, they
have become less attractive with time. Therefore, markerless methods use image features (such as corners or blobs) and their geometry instead of markers, to overcome the problems of marker- based methods. However, they require the target scene (or object) be rigid and of rich texture, and they are less reliable than marker-based methods.
Model-based methods[5,6,7] also do not require markers, so they can be considered as a kind of markerless methods. However, as model-based methods use 3D knowledge of the target scene (or object), i.e., 3D scene/object model, they are highly reliable and computationally efficient.
Model-based methods estimate the camera pose from 3D-2D correspondences between the 3D model data and its corresponding 2D observations
Combining an Edge-Based Method and a Direct Method for Robust 3D Object Tracking
Jean-Pierre Lomaliza
†, Hanhoon Park
††ABSTRACT
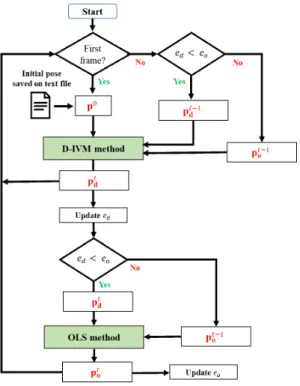
In the field of augmented reality, edge-based methods have been popularly used in tracking textureless 3D objects. However, edge-based methods are inherently vulnerable to cluttered backgrounds. Another way to track textureless or poorly-textured 3D objects is to directly align image intensity of 3D object between consecutive frames. Although the direct methods enable more reliable and stable tracking compared to using local features such as edges, they are more sensitive to occlusion and less accurate than the edge-based methods. Therefore, we propose a method that combines an edge-based method and a direct method to leverage the advantages from each approach. Experimental results show that the proposed method is much robust to both fast camera (or object) movements and occlusion while still working in real time at a frame rate of 18 Hz. The tracking success rate and tracking accuracy were improved by up to 84% and 1.4 pixels, respectively, compared to using the edge-based method or the direct method solely.
Key words: 3D Object Tracking, Camera Pose Estimation, Edge-Based Method, Direct Method, Textureless Object, Augmented Reality
※ Corresponding Author : Hanhoon Park, Address: (608- 737) Yongso-ro 45, Nam-gu, Busan, Korea, TEL : +82- 51-629-6225, FAX : +82-51-629-6210, E-mail : hanhoon.
[email protected]
Receipt date : Jan. 4, 2021, Revision date : Jan. 8, 2021 Approval date : Jan. 12, 2021
††
Dept. of Electronic Engineering, Pukyong National University (E-mail : [email protected])
††