http://dx.doi.org/10.17703/JCCT.2021.7.2.437
JCCT 2021-5-52
*정회원, 광운대학교 대학원 실감융합콘텐츠학과 박사과정 (제1저자)
**정회원, 광운대학교 대학원 실감융합콘텐츠학과 박사과정 (참여저자)
***정회원, 광운대학교 대학원 전자재료공학과 석박통합과정 (참여저자)
****정회원, 광운대학교 스마트융합대학원 교수(참여저자)
*****정회원, 광운대학교 대학원 실감융합콘텐츠학과 박사과정 (교신저자)
접수일 : 2021년 4월 20일, 수정완료일: 2021년 4월 30일 게재확정일 : 2021년 5월 7일
Received: April 20, 2021 / Revised: April 30, 2021 Accepted: May 7, 2021
*Corresponding Author: [email protected]
Dept. of Realistic Convergence Content, KWANGWOON Univ, Korea
딥러닝 기반의 소비자 데이터를 응용한 외식업체 추천 시스템 구현에 관한 연구
Study on Implementation of Restaurant Recommendation System based on Deep Learning-based Consumer Data
김희영*, 정선미**, 김우석***, 류기환****, 손현곤*****
Hee-young Kim*, Sun-mi Jung**, Woo-suk Kim***, Gi-hwan Ryu****, Hyeon-kon Son*****
요 약
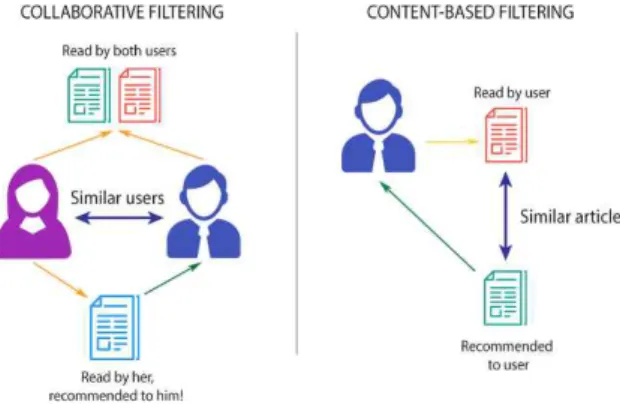
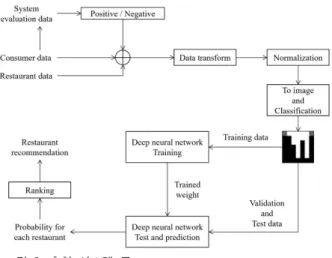
본 연구에서는 소비자 데이터를 딥러닝 기반의 분류(Classification) 모델을 학습 시켜 추천 알고리즘을 구현하 였다. 이를 위하여 사용자 데이터를 이미지로 변환 시켜 분류 과제에서 보편적으로 사용되는 ResNet50을 사용하여 학습한 결과로서 유의미한 결과에 대하여 제시함
주요어 :