DOI: https://doi.org/10.13161/kibim.2018.8.3.012
도시 빅데이터를 활용한 스마트시티의 교통 예측 모델
- 환경 데이터와의 상관관계 기계 학습을 통한 예측 모델의 구축 및 검증 - Big Data Based Urban Transportation Analysis for Smart Cities
- Machine Learning Based Traffic Prediction by Using Urban Environment Data -
1)학생회원, 성균관대학교 건축학과 박사과정 ([email protected])
2)정회원, 단국대학교 건축학과 조교수 ([email protected]) (교신저자)
장선영1), 신동윤2)
Jang, Sun-Young1) · Shin, Dong-Youn2)
Received Juiy 11, 2018; Received August 16, 2018 / Accepted August 16, 2018
ABSTRACT: The research aims to find implications of machine learning and urban big data as a way to construct the flexible transportation network system of smart city by responding the urban context changes. This research deals with a problem that existing a bus headway model is difficult to respond urban situations in real-time. Therefore, utilizing the urban big data and machine learning prototyping tool in weathers, traffics, and bus statues, this research presents a flexible headway model to predict bus delay and analyze the result. The prototyping model is composed by real-time data of buses. The data is gathered through public data portals and real time Application Program Interface (API) by the government. These data are fundamental resources to organize interval pattern models of bus operations as traffic environment factors (road speeds, station conditions, weathers, and bus information of operating in real-time). The prototyping model is implemented by the machine learning tool (RapidMiner Studio) and conducted several tests for bus delays prediction according to specific circumstances. As a result, possibilities of transportation system are discussed for promoting the urban efficiency and the citizens’ convenience by responding to urban conditions.
KEYWORDS: Big Data, Bus Headway Prediction, Machine Learning, Public Transportation, Smart City, Information Architecture 키 워 드: 빅데이터, 머신러닝, 버스 배차간격 예측, 대중교통, 스마트 시티, 정보 건축
1. 서 론
1.1 연구의 배경
도시에서 이루어지는 다양한 활동들을 효율적으로 유지하 고 발전시키기 위해서는 이들 활동을 수용하고 지원해 줄 수 있 는 시설들이 필요하다. 도시시설은 일반적으로 건축적 시설, 교 통 시설, 평면적 시설의 유형으로 분류된다(Korea Planners Association, 2009). 특히, 교통 시설은 생산, 생활, 위락 등의 기 본적인 도시 활동을 기능적으로 분화시키거나 통합시킬 수 있도 록 하는 도시에서 매우 다이나믹한 요소이다.
대중교통 수단들 중에서 버스는 대중이 일상에서 빈번하게 활 용하는 필수적인 교통수단이다. 현재의 대중교통 시스템은 각 종 ICT (Information and Communications Technology)의 적용
으로 활용의 편의성이 높아졌다. 시민들은 버스정보 시스템(Bus Information System, BIS)으로부터 버스의 위치와 대기 시간, 남 아있는 좌석의 수와 같은 정보를 실시간으로 전달받을 수 있다.
이와 같은 버스정보 시스템은 정류장에 부착된 고정된 시간표와 노선 정보 외에 버스의 실시간 위치 정보를 전혀 알 수 없었던 몇 년 전의 과거에 비하면 비교적 스마트해졌다고 할 수 있다. 이러 한 BIS의 구축과 이를 통해 대중교통 이용의 편의성을 증진시키 는 것은 스마트 시티를 구축하기 위한 노력 중 하나이다(Gubbi et al., 2013).
버스 이용에 있어서 시민들이 취득할 수 있는 버스 정보는 많 아지고 있다. 그러나 버스 운행에 대한 문제가 발생했을 때 시 민들은 정보 이용의 편의성과 관계없이 그 문제에 종속되며, 속 수무책으로 부담을 떠안게 된다. 예를 들면, 기상 상황으로 인하
여 버스의 배차에 문제가 생기는 경우나 앞차와의 운행 간격 조 절 실패로 여러 대가 연달아 도착하여 그 다음 간격 조절에도 계 속 문제가 생기는 경우이다. 이는 현재의 버스 시스템이 도시에 서 일어나는 상황에 즉각적으로 대응하지 못하기 때문에 발생한 다. 버스 회사들은 오랜 시간 운행해온 경험을 바탕으로 상습적 으로 문제가 발생하는 부분에 대하여 대응하려고 노력한다. 그러 나 그 방법은 치밀하게 분석되지 못한 경우가 많으며, 대체로 버 스 회사의 의사결정자에 의해 드문 주기를 가지고 변경된다.
지자체와 교통 연구 기관들은 이러한 문제점에 착안하여 도로 의 상황과 수요에 맞게 탄력 배차제의 시행을 연구하였으며, 현 재 일부 시행하고 있다(Lee, et al., 2009, Kim, 2012). 이 연구 들은 도시의 생활, 교통 현황과 과거 운행기록에 대한 다양한 통 계자료를 바탕으로 탄력배차 시행에 관한 모형을 구축하였다. 이 방법 또한 일종의 누적된 데이터들을 활용하여 상황에 맞게 모델 을 제시한 것이지만 도시 데이터의 실시간적인 분석과 적용에 있 어서는 한계가 있다.
그러나 현재 촉망받고 있는 기술적 가능성들, 구체적으로 빅 데이터(big data), 머신러닝(machine learning)과 같은 기술들의 활용은 좀 더 근본적으로 교통 체계를 도시 효율의 관점과 맞물 려 향상시킬 수 있다. 이는 이미 선진 국가에서 교통 시스템의 개 선을 위해 활용되고 있으며, 지능적인 교통 시스템 구축을 위해 더욱 적극적인 활용이 요구되고 있다(Lee, 2013). 이러한 데이터 분석 및 활용 능력을 기반으로 스마트 시티의 대중교통 시스템은 실시간적으로 변화하는 도시의 상황(예: 교통 정체, 대규모 이벤 트, 날씨, 수요 등)에 대응할 수 있는 유연성을 점차 갖추어 나갈 수 있을 것이다.
1.2 연구의 목적 및 방법
연구의 목적은 도시의 상황적 변화에 대응하는 유연한 체계를 가진 스마트 시티의 교통 네트워크를 구축하기 위한 방법으로서 도시 빅데이터와 머신러닝의 활용에 대한 시사점을 나타내는 것 이다. 구체적으로, 도시의 대중교통 시스템 중 버스를 대상으로 하여 기존의 배차 모델이 도시의 실시간적 상황에 대응하지 못하 는 고정형이라는 문제에 주목한다. 이에 대하여 교통, 날씨, 버스 상황에 관한 도시 빅데이터와 머신러닝 툴을 활용하여 버스 지연 예측에 관한 모델을 프로토타이핑(prototyping)한다.
제시하는 프로토타이핑 모델은 실제 운행하는 버스의 실시간 데이터를 기반으로 만들어진다. 데이터는 정부에서 제공하는 공 공 데이터 포털(Open Data Portal, Gyeonggi Bus Information System (GBIS), National Weather Center)의 오픈 데이터와 분 석 자료, 실시간 API (Application Program Interface) 데이터를 통해 수집한다. 이 데이터들은 날씨, 도로 속도, 정류소 상황, 실 시간 버스 운행정보와 같은 도시의 교통 환경 요소들로서 버스
운행의 인터벌 패턴을 구성하기 위한 기초적인 자료가 된다. 이 모델은 머신러닝 프로토타이핑 툴(RapidMiner Studio)을 활용 하여 구성되며 다양한 상황의 버스 지연 예측에 관하여 테스트 한다.
최종적으로, 연구결과를 바탕으로 도시 빅데이터와 머신러닝 의 활용을 통해 도시 상황에 유연하게 대처하는 교통 시스템과 그것이 도시 효율의 증대 및 시민의 편의성 증진에 기여하는 가 능성에 대해 논의한다.
2. 문헌고찰 및 사례연구
2.1 기존 배차 연구
시내버스의 배차 간격은 시민들의 버스 서비스 수준 평가에 서 편의성 및 운영 신뢰에 관한 중요한 요소이며, 버스 회사에서 는 운영 효율성 및 수익과 밀접한 연관을 가지는 요소이다(Yi &
Kim, 2013). 또한 지자체의 입장에서는 시내버스의 운영에 상당 량의 보조금을 지원하고 있기 때문에 다양한 입장과 환경적 요소 를 고려한 배차 간격의 설정은 중요하다.
따라서 배차에 관한 기존 연구들은 시민의 기준에서 서비스 수 준을 향상시키는 것을 목적으로(Eboli & Mazzulla, 2011, Friman, 2004)하거나 운송회사, 도시 전체적 측면에서 효율적인 배차 방 안과 최적 버스 노선 결정, 타당한 버스 대수 산정을 목적으로 (Liebig et al., 2017, Lee et al., 2006, Ruan & Lin 2009)하고 있다. 기존의 누적된 교통 상황을 기반으로 분석하여 탄력배차 운영 방안에 대하여 제시(Lee et al., 2009)하거나 실시간적 버스 의 상황을 반영하여 효율적인 배차를 위한 전략을 제시(Ko et al., 1999)하는 연구들은 모두 기존 데이터 기반의 수학적 통계 방법 을 활용하고 있다.
2.2 빅데이터를 활용한 교통 시스템에 관한 연구
최근에는 빅데이터를 활용한 교통 시스템 구축 사례가 늘고 있 다. 앞서 언급한 연구들 역시 데이터 기반의 통계이므로 예전부 터 이미 빅데이터와 맥락을 같이 하고 있었다고 볼 수 있다. 그러 나 빅데이터 활용 사례들은 초단위와 분단위로 생성되는 많은 양 의 정보에서 사람이 미처 고려하지 못한 복잡한 관계까지도 분석 하여 예측한다.
빅데이터를 활용한 교통 시스템 개선에 관한 해외 사례로써, 미국은 공공부문인 미국 교통부(Department of Transportation, DOT)와 민간부분이 합작하여 실시간 데이터 수집과 분석을 진행 하고 있다. 특히 민간 부문은 정부 부문에 비해 다양한 데이터 수 집방법(스마트폰의 GPS 정보, 블루투스, 카메라, 모바일 기기의 신호 등을 통한 추출)을 통해 대규모 교통 데이터를 실시간으로
수집하고, 데이터의 품질 또한 향상되고 있어 역할이 커지고 있 다. 이탈리아 밀라노의 지능형 교통 정보 시스템은 밀라노 시내 의 교통량, 기후변화, 속도 등에 관한 데이터를 5~15분 간격으로 관찰하고 분석했다. 이 축적된 데이터들로 향후 2~24시간의 교 통 상황을 예측한다.
국내 사례로써, 서울시는 빅데이터를 활용하여 유동 인구와 교 통 수요 패턴을 분석해 서울시 교통 서비스 최적 노선과 배차간 격 도출에 활용한 바 있다. 이 외에 과학기술정보통신부는 한국 교통방송(TBN)과 빅데이터 기반 교통사고 위험 예측 서비스를 개발했다. 이 서비스는 경찰청, 손해보험협회 등의 자료와 교통 량, 기상, 인구, 차량 통계 등 다양한 데이터를 수집 및 분석하여 교통사고 위험 시간대, 위험지역 등을 제공한다.
본 연구는 모든 상황을 고려하여 배차 간격을 새로이 제시해 주고 문제를 해결해 주는 것을 목적으로 하지 않는다. 버스 배차 간격을 설정하고 조정하는 수학적 알고리즘은 매우 복잡하며 상 호간에 영향을 미치는 요소가 상당히 많다. 다만, 본 연구는 도시 빅데이터의 실시간 분석과 반영을 통해서 버스가 배차간격을 지 키는데 그 정확도를 높여 문제를 완화시키는 데 기여한다. 빅데 이터 를 처리하여 예측하는데 의미가 있다. 따라서 이러한 분석 방법을 기반으로 버스 배차 지연에 관련된 여러 가지 도시데이터 를 활용하여 도시데이터와 머신러닝이 문제의 해결에 효율적으 로 활용될 수 있음을 나타내고자 한다.
3. 실시간 버스 데이터를 활용한 지연 예측 모델
3.1 도시 데이터의 수집과 추출
본 연구에서 활용한 도시 데이터는 실시간 날씨와 도로 속도, 버스 위치, 정류소 정보이다. 해당 데이터는 공공데이터 포털과 경기버스정보 시스템, 기상청의 기상자료개방포털을 통해 수집하 였다.
데이터의 수집 기간은 2017년 9월 14일부터 9월 27일로, 평일 을 대상으로 하였다. 시간대는 배차에 가장 문제가 생기는 출근 시간대(7~9시)와 퇴근 시간대(18~20시)를 중심으로 하였다. 공 공데이터 포털에서 제공하는 정보는 일일 트래픽이 1000으로 전 체 노선과 장시간의 데이터 수집에는 한계가 있다. 따라서 집중 적으로 데이터를 수집할 시간대를 설정하였다. 수집 대상은 경기 도 안산시의 시내 주요 구간을 경유하는 62번 시내버스이다. 62 번 버스는 상행 73개, 하행 77개의 정류소에 정차한다.
이 중에서 문제가 되는 구간인 하행 17개 정류소(총 5km 구간) 에 대한 정보를 수집하였다. 해당 노선은 학교 12곳(초등학교: 4, 중학교: 4, 고등학교: 3, 대학: 1)과 대형 교회, 시청, 경찰서, 시외 버스터미널, 지하철역 등 도심의 주요 밀집지역을 경유하는 도시
의 중심노선이다. 따라서 해당 노선은 시내를 경유하는 동안 버 스의 밀집과 정체가 빈번하게 발생한다(Figure 1).
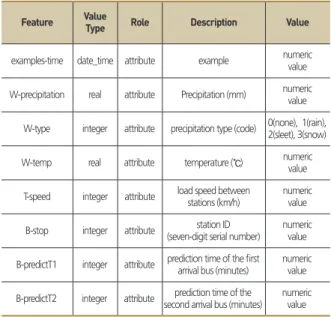
데이터 셋의 메타 데이터 속성 정의는 Table 1과 같다.
‘examples-time'은 각각의 데이터 사례가 발생한 순간의 날 짜와 시간이다. 날씨 데이터는 강수유형(없음/비/진눈깨비/
눈), 강수량(mm), 온도(℃)를 포함한다. 변수 목록에서 강수량은
‘W-precipitation', 강수유형은‘W-type', 온도는‘W-temp'로 각각 나타내었다.
도로 속도 데이터(T-speed)는 경기버스정보 시스템에서 정 류소를 중심으로 나누어진 구간별 속도를 실시간으로 수집하였 다. 버스 데이터는 공공데이터 포털에서 제공하는 노선에 관한 정보와 경기버스정보 시스템에서 제공하는 API를 통해 각 정류 소별 2분 간격의 데이터를 수집하였다. 이 데이터에는 정류소 아 이디(ID), 노선 아이디, 첫 번째 차량과 두 번째 차량의 위치정보, 도착예상시간, 저상버스 여부, 차량번호 등이 포함되어 있다. 이
Figure 1. The target route of data collection and the situation of density (map: daum portal site, real-time bus information: GBIS)
들 중 변수로 사용된 항목은 정류소 아이디(B-stop), 첫 번째 차 량의 도착예상시간(B-predictT1), 두 번째 차량의 도착예상시간 (B-predictT2), 첫 번째 도착예정 버스와 두 번째 도착예정 버스 의 간격(B-interval), 버스의 지연여부(IntervalType2)이다. 수집 된 데이터는 Table 1과 같이 버스 지연 예측에 필요한 항목들로 선별되었으며, 함께 수집된 불필요한 자료들을 삭제하여 하나의 데이터 셋으로 정리하였다.
데이터의 보정과 관련하여 특히, 날씨 데이터는 정류소의 위치 마다 다를 수 있다. 그러나 기상자료 개방포털을 통해서는 정류 소 기준의 날씨 데이터를 획득하는데 한계가 있어 본 연구에서는 개방된 날씨실황 분석자료를 사용하되 대상 구간의 해당 행정동 들(고잔1동, 고잔2동, 호수동)을 기준으로 데이터를 각 구간에 일 괄적으로 적용하였다.
3.2 버스 지연 예측 모델 구성
버스 지연에 관한 예측 모델의 구축은 머신러닝 프로토타이핑 툴(RapidMiner Studio)을 활용하였다. 이 모델은 버스의 누적된 운행 정보와 당시의 날씨, 속도 정보 등을 패턴화하여 이를 바탕 으로 현재의 도로상황에서 버스가 지연될 것인지를 예측한다. 62 번 버스는 공식적으로 평일 배차 간격을 5~10분으로 명시하고 있다. 따라서 버스 지연에 대한 기준은 수집된 버스의 운행 간격 이 3분 이하일 때 밀집된 것으로, 11분 이상일 때 지연되는 것으 로 판단하였다.
제시되는 예측 모델은 다음과 같은 결과를 추출 한다; 1) 버스 의 지연 예측 여부, 2) 버스 지연에 영향을 미치는 조건 요소들 의 가중치(weight value)와 이를 통한 주요 영향 요소(influence factor)들의 도출, 3) 상관관계 매트릭스(Correlation Matrix)를 통
한 영향 요소의 분석. 컴포넌트의 구성과 작동 프로세스는 다음 과 같다(Figure 2).
트레이닝 데이터 셋(training data set)은 프로그램 내의‘Read Excel’오퍼레이터를 통해 로드된다. 트레이닝 데이터 셋과 테스 트 데이터 셋(test data set)은 Table 1에서 설명한 10개 유형의 메타 데이터를 포함한다.
버스의 지연 예측 여부를 알기 위해서 누적된 데이터로 예측 모델을 트레이닝 시킨다. 제시된 모델은 네이브 베이즈(Naïve Bayes)의 방식을 활용해 트레이닝 하였다. 이 방법은 확률기반으 로 네이브 베이즈 분류 모델(Naïve Bayes classification model) 을 생성하여 사례가 부정 또는 긍정으로 분류되고 그 확률 중 높 은 쪽으로 결과를 예측한다. 이 과정으로 트레이닝 된 모델은 테 스트 데이터 셋의 사례에 대하여 버스가 지연될 것인지를 예측한 다. 예측값은 0(Yes) 또는 1(No)로 표현되며, 레이블(label)의 판 단에 대한 신뢰도가 도출된다. 예측된 결과는 실제 버스의 지연 여부와 비교되어 예측의 정확도를 판단한다.
버스 지연에 영향을 미치는 조건 요소들의 가중치를 알기 위해 서‘Calculate Weights’오퍼레이터를 활용하였다. 이는 정보 획득 을 기반으로 속성(attribute)들의 관계성을 계산한다.
마지막으로, 상관관계 매트릭스를 통하여 영향 요소들을 분석 한다. 이 과정은 레이블에 영향을 주는 요소를 판단하고 독립변 수들 간의 상관관계를 나타낸다.
3.3 예측 모델의 적용과 유형별 테스트
수집된 데이터와 예측 모델의 테스트는 그 목적에 따라 유형을 분류하여 여러 번 시행되었다. 유형은 크게 날씨의 영향과 예측 당일의 데이터 포함여부, 데이터의 누적 양에 따른 예측 정확도 의 차이로 구분된다. 각각의 테스트는 실제 운행 상태와 비교하 여 지연 여부를 정확하게 예측하였는지 판단된다.
Figure 2. Process of bus delay prediction model (RapidMiner Studio)
Feature Value
Type Role Description Value
examples-time date_time attribute example numeric
value W-precipitation real attribute Precipitation (mm) numeric
value W-type integer attribute precipitation type (code) 0(none), 1(rain), 2(sleet), 3(snow)
W-temp real attribute temperature ( ) numeric
value T-speed integer attribute load speed between
stations (km/h) numeric value
B-stop integer attribute station ID
(seven-digit serial number) numeric value B-predictT1 integer attribute prediction time of the first
arrival bus (minutes) numeric value B-predictT2 integer attribute prediction time of the
second arrival bus (minutes) numeric value Table 1. Meta data of the data-set for predicting bus delay
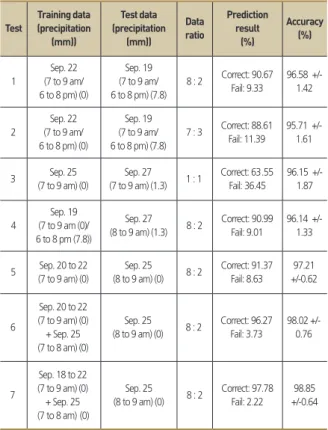
기상 환경과 도로의 상황은 밀접한 상관관계가 있다(Maze et al., 2006). 강수량은 도로 정체에 영향을 주며, 이는 버스가 배 차 간격을 유지는 데 문제가 생길 수 있다는 가정 하에 시행되었 다. Test 1은 비가 오지 않은 날의 데이터로 비가 온 날의 예측이 가능한지에 대한 것이다. Test 2와 Test 3은 Test 1의 예측 결과 에 대하여 데이터의 양과 비율의 영향을 확인한다. Test 4는 비 가 온 날의 데이터로 비가 온 다른 날의 예측이 첫 번째 테스트와 예측 결과에서 차이를 가지는지 판단한다. Test 5, 6, 7은 데이터 의 양, 즉 사례수의 증가에 따른 예측 결과를 비교하기 위함이다.
각 테스트의 예측 결과는 Table 2와 같다.
누적된 데이터는 분 단위이고, 시간의 흐름에 따라 연속된 정 보이다. 그리고 공간적으로 연속된 정류장을 대상으로 한다. 따 라서 데이터 셋의 사례 수를 정확하게 동일한 양으로 맞추기에는 한계가 있어 시간대를 중심으로 하여 데이터의 트레이닝과 테스 트 비율에 중점을 두었다.
Test 1과 Test 2는 큰 차이는 아니지만 트레이닝 데이터의 비 율이 높은 사례가 예측 결과의 성공(correct) 비율이 높았다.
Test 3은 1:1의 비율로 강수량이 없는 날과 비교하였다. 그러나 데이터의 수량이 많더라도 트레이닝 데이터의 비율과 테스트 데 이터의 비율이 적절하지 않아 예측 결과의 성공 비율은 다른 사 례에 비해 현저하게 낮았다. 이는 반대로 조건이 완전히 같지 않
더라도 누적된 사례의 수가 충분하다면 예측 성공의 결과치는 높 아질 수 있음을 의미한다.
Test 4는 트레이닝 데이터와 테스트 데이터 모두 강수량이 있 는 날의 조건으로 트레이닝 데이터와 테스트 데이터는 각각 서 로 다른 날의 데이터이다. 이 테스트는 트레이닝 데이터와 테스 트 데이터의 비가 온 시간대가 다르다. 본 실험에서는 시간이 속 성(attribute)으로 작용하였기 때문에 강수량이라는 요소가 두 데 이터 셋 모두 포함하고 있더라도 Test 1과의 예측 성공 확률과 비 교하였을 때 극명한 차이를 나타내진 않았다. Test 4는 강수량의 시간대가 달라 그 영향은 미미한 수준으로 나타났지만 강수량이 있는 날의 데이터가 더 누적된다면 비 오는 날에 대한 예측 성공 의 정확도는 더 높아지리라 예상된다.
Test 5, 6, 7은 버스 지연 예측에 실시간 데이터를 포함하면 예측 성공률을 얼마나 높일 수 있는지를 테스트하기 위함이다.
Test 6은 Test 5의 조건에서 테스트 데이터의 직전 1시간을 더 하여 트레이닝 하였다. 이 테스트는 과거 데이터만으로 트레이닝 하여 현재의 상황을 예측한 것과 과거 데이터와 테스트 날의 직 전 시간대가 포함된 트레이닝 데이터를 학습시켰을 때의 차이를 관찰하기 위함이다. 직전 시간대를 포함하여 실험하는 이유는 이 데이터의 특성이 시간적, 공간적 연속성을 가지고 있으며, 이 특 성이 결과에 주요한 영향을 줄 수 있으리라 예상하기 때문이다.
정확도(Accuracy)는 예측 모델에 대한 정확도를 나타낸 것으로, 트레이닝 데이터를 학습하여 모델이 훈련되고 그 훈련된 모델이 어느 정도의 정확도를 가지는지를 나타낸다.
4. 버스지연 예측에 대한 결과
강수량을 중심으로 한 테스트에서는 다음과 같은 결과를 얻었 다. 먼저, 강수량이 없더라도 트레이닝을 위한 누적된 데이터의 양이 많아질수록 예측 정확도는 높게 나타남을 발견할 수 있었 다. 또한 테스트 데이터에 강수가 있는 날의 데이터를 포함하면 더 높은 예측 정확도의 결과를 도출할 수 있었다.
Test
Training data (precipitation
(mm))
Test data (precipitation
(mm))
Data ratio
Prediction result
(%)
Accuracy (%)
1
Sep. 22 (7 to 9 am/
6 to 8 pm) (0)
Sep. 19 (7 to 9 am/
6 to 8 pm) (7.8)
8 : 2 Correct: 90.67 Fail: 9.33
96.58 +/- 1.42
2
Sep. 22 (7 to 9 am/
6 to 8 pm) (0)
Sep. 19 (7 to 9 am/
6 to 8 pm) (7.8)
7 : 3 Correct: 88.61 Fail: 11.39
95.71 +/- 1.61
3 Sep. 25
(7 to 9 am) (0)
Sep. 27
(7 to 9 am) (1.3) 1 : 1 Correct: 63.55 Fail: 36.45
96.15 +/- 1.87 4
Sep. 19 (7 to 9 am (0)/
6 to 8 pm (7.8))
Sep. 27
(8 to 9 am) (1.3) 8 : 2 Correct: 90.99 Fail: 9.01
96.14 +/- 1.33
5 Sep. 20 to 22 (7 to 9 am) (0)
Sep. 25
(8 to 9 am) (0) 8 : 2 Correct: 91.37 Fail: 8.63
97.21 +/-0.62
6
Sep. 20 to 22 (7 to 9 am) (0) + Sep. 25 (7 to 8 am) (0)
Sep. 25
(8 to 9 am) (0) 8 : 2 Correct: 96.27 Fail: 3.73
98.02 +/- 0.76
7
Sep. 18 to 22 (7 to 9 am) (0) + Sep. 25 (7 to 8 am) (0)
Sep. 25
(8 to 9 am) (0) 8 : 2 Correct: 97.78 Fail: 2.22
98.85 +/-0.64 Table 2. Test results focusing on the correlation between
weather and road condition
Attribute Weight value of test 1 Weight value of test 4
B-interval 1 1
B-predictT2 0.36 0.33
examples-time 0.04 0.08
W-temp 0.03 0.07
W-precipitation 0 0.03
W-type 0 0.02
T-speed 0.01 0.02
B-predictT1 0.02 0.01
B-stop 0 0
Table 3. Comparison of the weight value between test 1 and test 4
Test 1과 Test 4의 예측 정확도는 비슷하지만 가중치 분석을 통해 트레이닝 데이터 셋을 살펴보면 다음과 같은 차이가 나타 난다(Table 3). Test 1과 Test 4의 주요한 차이는 강수량의 여부 이다. 이는 가중치에서도 나타난다. Test 4는 Test 1 보다 강수 량(W-precipitation), 강수유형(W-type), 도로 속도(T-speed) 가 더 중요하게 나타났다. 두 데이터 셋은 인터벌을 중심으로 한 연착 여부를 살펴보는 것이므로, 공통적으로 버스 인터벌 (B-interval)이 중요하게 나타났으며, 다음 순서로 두 번째 버스 의 예측시간(B-predictT2)이 중요한 요소로 판단되었다.
Test 5와 Test 6는 학습 모델에 의한 레이블의 예측 결과이다.
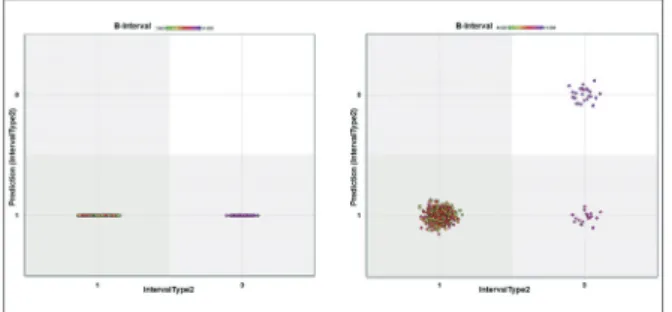
이는 0(Yes/Delay)과 1(No)에 대한 각각의 신뢰도(confidence) 와 함께 표현되며, 이 신뢰도에 근거하여 레이블이 최종적으로 판단된다. Test 5의 잘못된 예측은 510개의 사례 중에서 44개였 으며, Test 6은 19개였다.
Figure 3은 Test 5와 Test 6의 결과를 바탕으로 레이블인 IntervalType2와 IntervalType2의 예측결과, B-interval의 관계 를 산포도(scatter graph)로 나타낸 것이다. Test 5는 0으로 분류 한 사례가 없었다. 이는 20~22일에 누적된 데이터 셋 전체(2397 개)에서 테스트에 맞는 사례가 없어 분류가 제대로 되지 않은 것 이다. 트레이닝 데이터 셋의 규모를 18~22일(6500개)로 확장하 였을 때 510개의 테스트 사례 중에서 잘못된 예측은 4개로 도출 되었다. Figure 4는 데이터의 양이 많이 누적될수록 옳은 예측을 할 수 있음을 보여준다.
5. 결론 및 논의
다양한 산업군에서 빅데이터와 머신러닝의 도입은 이미 활발 하게 이루어지고 있다. 도시 분야 역시 효율적인 자원의 활용과 관리를 지원하기 위한 연구를 활발히 진행하고 있다. 도시는 매 순간 많은 데이터가 생산된다. 이 데이터들은 도시민들의 삶의 흔적이며 다양한 지표를 알 수 있는 척도가 된다. 하지만 도시 데 이터는 많은 양의 데이터들이 상호간의 보이지 않는 복잡한 관계 를 가지고 영향을 주고받기 때문에 쉽게 그 관계를 알기 어렵다.
빅데이터 분석은 다양하고 복잡한 관계를 가진 많은 양의 데이터 를 처리해서 예측하는데 의미가 있다. 따라서 보이지 않는 도시 의 관계들을 찾아내고 이를 관통하는 통찰력을 가지기 위해서는 필수적으로 빅데이터의 활용이 이루어져야 한다.
본 연구는 버스의 지연 예측이라는 구체적인 문제에 대하여 이 에 관련된 여러 가지 도시데이터를 활용하여 도시데이터와 머신 러닝이 문제해결에 효율적으로 활용될 수 있음을 나타내고자 하 였다. 연구에서 다루어진 대중교통은 도시에서 매우 동적인 요소 로 겉으로만 파악하기에는 그 연관성이 상당히 복잡한 영역이다.
Attribute Weight value of test 5 Weight value of test 6
B-interval 1 1
B-predictT2 0.29 0.27
examples-time 0.04 0.05
W-temp 0.05 0.03
B-predictT1 0.02 0.02
T-speed 0.01 0.01
B-stop 0 0
W-type 0 0
W-precipitation 0 0
Table 4. Comparison of the weight value between test 5 and test 6
Figure 3. Scatter graphs about the relations of IntervalType2, Prediction, and B-interval of test 5 and test 6
Figure 4. Changes of the prediction result according to the amount of data of test 5
(the relations of IntervalType2, Prediction, and B-interval)
Figure 5. Correlation matrix of test 5 and test 6
연구의 핵심은 과거에 누적된 데이터뿐만 아니라 실시간으로 수 집되는 데이터를 통해 그 다음 순간의 상황을 예측하고, 사람들 이 이에 대응할 수 있도록 지원하는데 있다. 본 연구는 약한 인 공지능의 가능성과 방법론에 초점이 맞추어져 있으므로 프로토 타이핑의 수준으로 이루어졌다. 그러나 데이터 수집에 양과 유형 의 제약이 없는 공공기관에서 본 연구와 같은 방법론을 활용한다 면 향후 도래하게 될 지능형 교통 체계의 구현에 유용하게 활용 될 수 있을 것이다. 구체적으로 도출된 연구결과는 자율주행 자 동차, 버스가 보편화 될 앞으로의 시대에 도시의 상황을 고려한 실시간 버스 배차 간격을 설정하는데 있어 기초 연구로서 활용될 수 있을 것이다.
향후 도시는 전체적으로 교통의 효율을 추구하는 지능형교 통체계를 필연적으로 받아들이게 될 것이다. 지능형교통체계 (Intelligent Transport System, ITS)란, 교통수단과 교통시설에 전자ㆍ제어 및 통신 등 첨단교통기술과 교통정보를 개발ㆍ활용 함으로써 교통체계의 운영 및 관리를 과학화ㆍ자동화하고, 교통 의 효율성과 안전성을 향상시키는 교통체계이다(Dobre & Xhafa, 2014, Intelligent Transport Society of Korea). 이 지능형 교통 체계는 교통상황에 따라 실시간으로 대응하는 신호의 운영 또는 교통 소통 개선과 같이 도시 시스템 전체를 대상으로 기능하여 도시 전체의 효율 향상을 목표로 한다. 뿐만 아니라 자율주행 자 동차의 연구는 상승세이며 머지않아 도시에 적용될 예정이다. 이 미 미국과 스위스 등 유럽 국가들은 공공도로에서 자율주행 버스 를 시범 운영하였으며 한국도 추진하고 있다. 따라서 본 연구의 성과는 이러한 지능형 교통 체계의 도입에 힘입어 도시 데이터를 적극적으로 활용하여 스마트 시티의 편의성 향상을 구현하는 기 초적인 방법론으로써 유용하게 참고 될 수 있을 것이다.
감사의 글
이 성과는 2016년도 정부(미래창조과학부)의 재원으로 한국연 구재단의 지원을 받아 수행된 연구임(No. 2016R1C1B2013424).
References
Dobre, C. & Xhafa, F. (2014). Intelligent services for big data science, Future Generation Computer Systems, 37, pp.
267-281.
Eboli, L. & Mazzulla, G. (2011). A Methodology for Evaluating Transit Service Quality Based on Subjective and Objective Measures from the Passenger’s Point of View, Transport Policy, 18(1), pp. 172-181.
Friman, M. (2004). Implementing Quality Improvements in Public Transport, Journal of Public Transportation, 7(4), pp. 49-65.
Gubbi, J., Buyya, R., Marusic, S. & Palaniswami, M. (2013).
Internet of Things (IoT): A vision, architectural elements, and future directions, Future generation computer systems, 29(7), pp. 1645-1660.
Gyeonggi Bus Information System (GBIS), www.gbis.go.kr/
(Aug. 14. 2018)
Intelligent Transport Society of Korea, www.itskorea.kr/02 _ sta/sta1.jsp (Aug. 14. 2018)
Kim, K. (2012). Study on the city bus use demand and flexible service during precipitation, Ph. D. Dissertation, Busan National University.
Ko, S., Ko, J. & Jeon, J. (1999). Development of Real Time Vehicle Scheduling Model for Public Transportation, Journal of the Research Institute of Industrial Technology, 18, pp. 181-186.
Korea Planners Association (2009). Urban Planning, Bosunggak, 2009, pp. 36-37.
Lee, H., Park, J., Jo, S. & Yun, B. (2006). Development of Optimal Bus Scheduling Algorithm with Multi-constraints, Journal of Korean Society of Transportation, 24(7), pp.
129-138.
Lee, S. (2013). Big Data for Transportation Policies and Their Applications, The Korea Transport Institute.
Lee, W., Kim, M., Kim, Y. & Lee, J. (2009). Study on implementation plan of flexible headway service of city bus, Busan Development Institute.
Liebig, T., Piatkowski, N., Bockermann, C. & Morik, K. (2017).
Dynamic route planning with real-time traffic predictions, Information Systems, 64, pp. 258-265.
Maze, T., Agarwai, M. & Burchett, G. (2006). Whether weather matters to traffic demand, traffic safety, and traffic operations and flow, Transportation research record:
Journal of the transportation research board, 1948, pp.
170-176.
National Weather Center, https://data.kma.go.kr/cmmn/main.
do (Aug. 14. 2018)