2018, 29
(4)
,903–913
소비자 물가지수 예측: 시계열 인과모델과 요인분석을 활용한 사례 연구 †
ᄇ ᅡ ᆨ노진
1
1단국대학교 응용통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2018ᄂ ᅧ ᆫ 6ᄋ ᅯ ᆯ 4ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 6ᄋ ᅯ ᆯ 27ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 6ᄋ ᅯ ᆯ 28ᄋ ᅵ ᆯ
요 약
ᄉ
ᅩᄇ ᅵᄌ ᅡ ᄃ ᅩ ᆼ ᄒ ᅣ ᆼ ᄌ ᅵᄉ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄃ ᅩ ᆨᄅ ᅵ ᆸᄇ ᅧ ᆫᄉ ᅮᄅ ᅩ ᄒ ᅡᄋ ᅧ ᄉ ᅩᄇ ᅵᄌ ᅡ ᄆ ᅮ ᆯ ᄀ ᅡᄌ ᅵᄉ ᅮᄋ ᅴ ᄋ ᅨᄎ ᅳ ᆨᄋ ᅳ ᆯ ᄉ ᅵᄃ ᅩᄒ ᅢ ᄇ ᅩᄋ ᅡ ᆻᄃ ᅡ. ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄎ ᅮ ᄌ ᅥ
ᆼᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅪᄌ ᅥ ᆼᄋ ᅦᄉ ᅥ ᄃ ᅩ ᆨᄅ ᅵ ᆸᄇ ᅧ ᆫᄉ ᅮᄃ ᅳ ᆯ ᄋ ᅵ ᄂ ᅥᄆ ᅮ ᄆ ᅡ ᆭᄋ ᅡ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄀ ᅮᄉ ᅥ ᆼᄒ ᅡᄂ ᅳ ᆫ ᄃ ᅦ ᄋ ᅥᄅ ᅧᄋ ᅮ ᆷ ᄋ ᅵ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ. ᄄ ᅡᄅ ᅡᄉ ᅥ ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥ ᄂ
ᅳ ᆫ ᄆ ᅥ ᆫᄌ ᅥ ᄋ ᅭᄋ ᅵ ᆫᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅢ ᄉ ᅩᄇ ᅵᄌ ᅡ ᄃ ᅩ ᆼ ᄒ ᅣ ᆼᄌ ᅵᄉ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅡ ᆸᄒ ᅡᄀ ᅩ ᄐ ᅩ ᆼ ᄒ ᅡ ᆸᄌ ᅵᄉ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄃ ᅩ ᆨᄅ ᅵ ᆸᄇ ᅧ ᆫᄉ ᅮᄅ ᅩ ᄒ ᅡᄋ ᅧ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄋ ᅵ ᆫᄀ ᅪ ᄆ
ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄎ ᅮᄌ ᅥ ᆼᄒ ᅡ ᆫ ᄒ ᅮ ᄋ ᅨᄎ ᅳ ᆨᄋ ᅳ ᆯ ᄉ ᅵᄃ ᅩᄒ ᅡᄋ ᅧ ᄇ ᅩᄋ ᅡ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄉ ᅡᄅ ᅨᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄉ ᅩᄇ ᅵᄌ ᅡ ᄃ ᅩ ᆼ ᄒ ᅣ ᆼᄀ ᅪ ᄀ ᅪ ᆫᄅ ᅧ ᆫᄃ ᅬ ᆫ ᄌ ᅵᄉ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄀ ᅢᄇ ᅧ ᆯᄌ ᅥ ᆨᄋ ᅳ ᄅ
ᅩ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅧ ᆼᄋ ᅮᄋ ᅦ ᄀ ᅳᄅ ᅢ ᆫᄌ ᅥ ᄋ ᅵ ᆫᄀ ᅪ ᄀ ᅪ ᆫ ᄀ ᅨᄀ ᅡ ᄉ ᅥ ᆼᄅ ᅵ ᆸᄃ ᅬᄌ ᅵ ᄋ ᅡ ᆭᄋ ᅡ ᆻᄋ ᅳᄂ ᅡ ᄇ ᅧ ᆫᄉ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅡ ᆸᄒ ᅡᄋ ᅧ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄒ ᅡ ᆯ ᄀ ᅧ ᆼᄋ ᅮᄋ ᅦᄂ ᅳ ᆫ ᄀ ᅳᄅ ᅢ ᆫ ᄌ
ᅥ ᄋ ᅵ ᆫᄀ ᅪ ᄀ ᅪ ᆫ ᄀ ᅨᄀ ᅡ ᄉ ᅥ ᆼᄅ ᅵ ᆸᄒ ᅡᄋ ᅧ ᆻᄀ ᅩ ᄋ ᅨᄎ ᅳ ᆨ ᄀ ᅡ ᆹ ᄄ ᅩᄒ ᅡ ᆫ ᄉ ᅩᄇ ᅵᄌ ᅡ ᄆ ᅮ ᆯ ᄀ ᅡᄌ ᅵᄉ ᅮᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄌ ᅡᄀ ᅵᄒ ᅬᄀ ᅱᄋ ᅵᄃ ᅩ ᆼᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅴ ᄋ ᅨᄎ ᅳ ᆨ ᄀ ᅡ ᆹᄇ ᅩᄃ ᅡ ᄃ
ᅥ ᄉ ᅵ ᆯᄌ ᅦᄀ ᅡ ᆹᄀ ᅪ ᄋ ᅲᄉ ᅡᄒ ᅡ ᆫ ᄋ ᅨᄎ ᅳ ᆨ ᄀ ᅡ ᆹᄋ ᅳ ᆯ ᄋ ᅥ ᆮᄋ ᅳ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄀ ᅳᄅ ᅢ ᆫᄌ ᅥ ᄋ ᅵ ᆫᄀ ᅪᄆ ᅩᄃ ᅦ ᆯ, ᄇ ᅦ ᆨᄐ ᅥᄋ ᅩᄎ ᅡᄉ ᅮᄌ ᅥ ᆼ ᄆ ᅩᄃ ᅦ ᆯ, ᄇ ᅦ ᆨᄐ ᅥᄌ ᅡᄀ ᅵᄒ ᅬᄀ ᅱ ᄆ ᅩᄃ ᅦ ᆯ, ᄇ ᅮ ᆫ ᄉ ᅡ ᆫ ᄇ ᅮ ᆫ ᄒ ᅢ ᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄉ ᅩᄇ ᅵᄌ ᅡ ᄃ ᅩ ᆼ ᄒ ᅣ ᆼᄌ ᅵ ᄉ
ᅮ, ᄉ ᅩᄇ ᅵᄌ ᅡ ᄆ ᅮ ᆯ ᄀ ᅡᄌ ᅵᄉ ᅮ, ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄎ ᅮ ᆼᄀ ᅧ ᆨ ᄇ ᅡ ᆫᄋ ᅳ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨ.
1. 서론 ᄉ
ᅵ계열 인과모델을추정하는경우 입력변수들을요인분석을활용하여 통합하여 사용함으로 보다 집약 되
ᆫ모델을구축하는방법을소비자 물가관련 데이터를사례로 들어 시도하여 보았다. 분석에 사용한 사 ᄅ
ᅨ는 한국은행이 전국을대상으로 2008년 07월부터 2017년 10월까지 조사한 소비자 동향 조사 데이터 ᄋ
ᅪ 같은기간 통계청에서 조사한 소비자 물가지수를 통합하여 만든데이터이다.
ᄉ
ᅩ비자 동향 조사에는 총 18개의 지수가 포함되는데 여기에 소비자 물가지수를 종속변수로 연동하여 ᄉ
ᅵ계열 인과모델을추정하고자 하였다. 이 경우 모델이 너무 커서 추정하기도 또한 설명하기도 용이하 ᄌ
ᅵ 않았다. 비록정보의 손실이 약간은 있으리라는우려가 있지만 입력변수들을요약하여 모델을추정 ᄒ
ᅢ 보고자 하였다. 먼저 요인분석을 이용하여 통합 변수들을도출하고 이들을 입력변수로 사용하여 소 ᄇ
ᅵ자 물가지수에 대한 시계열 인과모델 추정하여 보았다. 본연구에서는그랜저 (Granger) 인과관계에 ᄀ
ᅵ반을두는 벡터오차수정모델이라는다변량 시계열 모델을사례 데이터에 적용하여 보았다. 그 과정에 ᄉ
ᅥ 요인분석을활용해 보았다는점이 특별한 점이라고 하겠다.
노
ᆫ문은 먼저 벡터자기회귀모델, 그랜저인과모델, 공적분과 벡터오차수정모델에 대한 개념을 간단히 ᄉ
ᅥ술하고 소비자 동향/물가지수와관련된실제 데이터를이용하여 모델을추정하는 순서로 구성되어 있 ᄃ
ᅡ. 앞서 언급한 것처럼 요인분석을 통해 통합변수들을만들어 사용한 것이 현상을이해하는데 도움이 ᄃ
ᅬ리라는기대가 있었는데 적어도 주어진 사례에서는매우 효과적이었다고 하겠다.
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ 2018ᄂ ᅧ ᆫᄃ ᅩ ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭᄋ ᅴ ᄋ ᅧ ᆫᄀ ᅮᄇ ᅵᄋ ᅦ ᄋ ᅴᄒ ᅡᄋ ᅧ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ.
1
(16890) ᄀ ᅧ ᆼᄀ ᅵᄃ ᅩ ᄋ ᅭ ᆼᄋ ᅵ ᆫᄉ ᅵ ᄉ ᅮᄌ ᅵᄀ ᅮ ᄌ ᅮ ᆨᄌ ᅥ ᆫᄅ ᅩ 152, ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅳ ᆼᄋ ᅭ ᆼᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
2. 시계열 인과모델 ᄋ
ᅧ러 가지 변수들 간의 시간상 인과관계를 추정하는 시계열 인과모델은 환율 (Shin, 2009), 금리 (Kim 등, 2012)그리고 부동산 가격 (Lim, 2016)같은경제지표들을다루는데 널리 적용되어왔다. 본 ᄂ
ᅩᆫ문에서는 모수적 통계의 관점에서의 추정을 다루겠으나 비모수적 관점에서의 연구도 있다 (Jeong, 2007).
2.1. 벡터자기회귀모델 베
ᆨ터자기회귀 (vector autoregressive; VAR) 모델을추정하기 위해서는몇 가지 단계를거쳐야 한다.
ᄀ
ᅳ 단계는단위근검정, 공적분검정, 그랜저 인과관계 검정, 시차의 결정, 그리고 마지막으로 추정이 되 게
ᆻ다. 사후 분석으로 충격반응함수 분석과 분산분해 과정을 통해 변수들의관계를 파악하며 끝으로 예 ᄎ
ᅳ
ᆨ이 이루어진다.
VAR모델은 Sims (1980)에 의해 개발된다변량 자기회귀모델이다. 간단하게 말하면 서로 인과관계 ᄀ
ᅡ 있는변수들의 시계열 모델을 벡터 형태로 결합한 모델이라고 할 수 있다.
k변량 VAR(p)모델은다음과 같이 정의된다.
Xt= Φ0+ Φ1Xt−1+ · · · + ΦpXt−p+ εt. (2.1) ᄋ
ᅱ의 식 (2.1)에서 Xt는 (k × 1)-변수벡터, Φi는 (k × k)-계수 (모수)행렬이고 ε은 (k × 1)-백색잡음벡 ᄐ
ᅥ이다. 만일 Xt에서 k가 1이라면 VAR(p)은 AR(p)모델이된다. VAR은몇 개의 AR모델을엮어 벡 ᄐ
ᅥ 형태로 표시한 것이라고 생각하면 되겠다. 추정은 일반화 최소 제곱추정법에근거하여 주로 이루어 ᄌ
ᅵᆫ다.
2.2. 단위근 검정 ᄉ
ᅵ계열 자료의 분석은 기본적으로 시계열의 정상성을 전제로 한다. 어떤 시계열이 정상적이라면 평 ᄀ
ᅲᆫ, 분산이 해당 기간 동안 일정하고 두 시점간의 공분산이 시차에만 의존한다는의미이며 이러한 조건 으
ᆯ 만족하지 못할 때 비정상 시계열이라고 한다. 비정상 시계열의 대표적인 예가 단위근이 있는 시계 여
ᆯ이다. 일반적으로 단위근의 존재 여부를 검정하기 위해 가장 널리 사용되는 방법은 확대 디키-풀러 (augmented Dickey-Fuller; ADF) 검정과 필립-페론 (Phillips-Perron; PP) 검정이 있다 (Cho, 2006).
2.3. 공적분 검정
Engle과 Granger (1987)는 개별 시계열이 비정상계열로 추세변동 등이 있더라도 이들 시계열 간에 ᄌ
ᅡᆼ기적으로 정상적인 균형관계를 갖도록 하는 선형결합이 존재한다면 이 선형결합은 정상계열이 되며 ᄋ
ᅵ 경우 시계열은 공적분 (cointegration)관계가 있다고 한다. 즉, 비정상시계열 Xt와 Yt가 있을 때, Zt= Xt− βYt 를만족하는 β가 존재하여 Zt가 정상시계열이된다면 Xt와 Yt는 공적분관계에 있다고 ᄒ
ᅡ며 β를 공적분계수, 혹은경우에 따라 벡터라고 한다. Johansen과 Julius (1990)와 Johansen (1991, 1995)에 의해 소개된 검정이 공적분관계를검정하는데 가장 널리 사용되고 있는방법이다.
2.4. 그랜저 인과관계 검정 ᄀ
ᅳ랜저 인과관계 검정은한 변수가 다른변수의 예측에 도움이 되는지를검정하는방법이다. Granger (1969)에 의해서 예측관계에 대한 검정방법이 처음제시되었기 때문에 이러한 유형의 예측관계를나타
ᄂ
ᅢᆯ 때에는 ‘그랜저 인과 (Granger-cause)’라는 용어를사용한다. 만일 Xt의 시차값들이 다른변수 Yt를 ᄋ
ᅨ측하는데 도움이된다면, ‘X는 Y 를그랜저 인과 한다.’라고 말한다.
거
ᆷ정의 과정을간단히 설명하면 시계열 Y 에 대하여 유효한 차수가 m이라하고 다른시계열 X에 대하 ᄋ
ᅧ 차수 p, q (p ≤ q)를가정한 귀무가설과 대체가설을
H0: yt= a0+ a1yt−1+ · · · + amyt−m+ et,
H1: yt= a0+ a1yt−1+ · · · + amyt−m+ bpxt−p+ · · · + bqxt−q+ et
ᄋ
ᅪ 같이 세우고 모델을적합한 후 F -검정을 통해 귀무가설을채택 혹은기각하는과정에서 인과성을 불 ᄋ
ᅵᆫ정 혹은 인정하는판단을하게된다.
2.5. 차수 결정 이
ᆯ변량 시계열의 AR모델에 대한 차수 는편자기상관함수에 의해 결정한다. 그런데 VAR은구조적으 ᄅ
ᅩ 매우 복잡하고 따라서 추정 역시 매우 계산상으로 복잡하여 모든변수에 대한 동일한 차수를사용하 느
ᆫ것이 보편적이다. 일반적으로 추정된모델의 적합도에 기초한 아카이케정보기준 (Akaike informa- tion criterion; AIC)이나 슈발츠정보기준 (Schwarz information criterion; SIC)을사용하는경험적 방 버
ᆸ을사용하는것이 선호된다. 즉,가능한 많은 p에 대하여 모델을적합하고 최적의 적합도를가질 때의 p값을찾아 사용한다 (Burnham과 Anderson, 2002; Claeskens과 Hjort, 2008).
2.6. 벡터오차수정모델 (vector error correction model; VECM) ᄋ
ᅡ래와 같이 정의된VAR모델이 비정상적이라면
Xt= Φ1Xt−1+ · · · + ΦpXt−p+ ϵϵϵt. (2.2) 시
ᆨ (2.2)의 Xt에 대하여 차분을취하여 정상화시키면서 공적분의관계를반영하기 위하여 아래와 같 ᄋ
ᅳ
ᆫ모델이 제안되었다 (Granger, 1981; Engle과 Granger, 1987). 아래 식 (2.3)에서 오른쪽첫 번째 항 ᄋ
ᅵ 공적분관계를반영하고 있다.
∆Xt= ΠXt−1+
p−1
X
j=1
Φ∗j∆Xt−j+ ϵϵϵt, ∆Xt= Xt− Xt−1,
Φ∗j= −
p
X
i=j+1
Φi, j = 1, · · · , p − 1; Π = −(1 − Φ1− · · · − Φp). (2.3)
2.7. 충격반응분석 및 분산분해 ᄎ
ᅮᆼ격반응분석은모델 내의 어떤 변수에 대하여 일정한 크기의 충격이 가해질 때 모델의 모든변수들이 ᄉ
ᅵ간의 흐름에 따라서 어떻게 반응하는지 살펴보는것이다. 특히 출력변수의 반응에관심이 있다. 모델 ᄋ
ᅵ 추정된 후관심이 되는변수에 대하여 다른변수에 한 단위의 충격 (변화)이 주었을때관심 변수의 ᄇ
ᅧᆫ화를 시간에 따라 추적하는것이다 (Chung과 Kim, 2011). 수학적으로는함수의 순간 변화율을 미 ᄇ
ᅮᆫ을 통해 구하는 것과 같다. 예컨대 t시점에서관심 있는 변수 Yi의 s시점 후에 대한 Xj의 변화량은
∂Yi,t+s/∂Xj,t로 계산할 수 있다.
부
ᆫ산분해 분석은관심 있는변수에 대한 예측을수행하는과정에서 모델 내의 각 변수의 변동을자기 ᄌ
ᅡ신을포함한 다른변수들의 변동으로 분리해 내는 분석 방법이다. 그 과정은 t시점에서 i번째 변수의 s시차 후의 평균제곱오차를 구하면 다른변수들의 평균제곱오차들도 합의 형태로 포함된 식을 얻게 되 ᄀ
ᅩ 전체 평균제곱오차에서 예건대 j번째 변수에 해당하는평균제곱오차의 비를구하면 i번째 변수에 대 ᄒ
ᅡᆫ 상대적 비율을계산해 낼 수 있다.
3. 데이터 분석 부
ᆫ석에 사용한 데이터는 한국은행이 전국을 대상으로 2008년 07월부터 2017년 10월까지 조사한 소 ᄇ
ᅵ자 동향조사와 동기간 통계청이 조사한 소비자 물가지수이다. 데이터의 출처는 통계청 사이트 (http:
//kosis.kr)이다.
ᄉ
ᅩ비자 동향은경제 인식, 경제 전망, 소비자 지출전망, 가계 저축 및 부채, 인플레이션 전망으로 구 서
ᆼ된다섯 가지 범주로 나뉘어 조사된다. 각 범주마다 구체적인 문항들이 고안되어 총 18개의 지수 - 현 ᄌ
ᅢ 생활조건, 현재 경제 상황, 미래 경제 전망, 고용전망,금리 전망, 가구 소득전망, 소비자 전망, 현 ᄌ
ᅢ 가계 저축,가구 현재 가계부채, 가계 부채 전망, 물가 수준전망, 주택가격 전망, 임금수준전망, 물가 ᄋ
ᅵᆫ식, 기대인플레이 등-으로 구성된다 (Table 3.1). 소비자동향지수의 산출식은각 문항에 대하여긍정 ᄇ
ᅮ터 부정으로 다섯 범주의 응답을받아 각 범주에 응답한 가구수를이용하여 다음과 같이 계산한다.
ᄉ
ᅩ비자동향지수 (Customer survey index; CSI) =
(매우긍정× 1.0+약간긍정× 0.5+비슷함×0.0-약간부정×0.5-매우부정×1.0) ᄌ
ᅥᆫ체 응답 가구수 × 100 + 100.
ᄌ
ᅵ수가 100보다큰경우긍정적으로 응답한 가구 수가 부정적으로 가구 수보다 많다는것을의미한다.
보
ᆫ연구에서는위 데이터에 소비자 물가지수를추가하여 여러 가지 소비자 동향 전망치들이 소비자 물가 ᄋ
ᅦ 어떻게 반영되는지를추정하고 예측하고자 한다.
ᄇ
ᅮᆫ석을위해 R 프로젝트 (버전 3.0.0) 패키지를설치하여 사용하였다. 그랜저 인과관계 검정, 최적의 ᄉ
ᅵ차선택, 벡터자기회귀, 충격반응분석과 분산분해분석은 vars-패키지의 causality, VARselect, VAR, irf와 fevd를사용하여 분석하였다. 정상성 검정에는 fUnitRoots-패키지의 adfTest를사용하였고, 공적 부
ᆫ검정은 urca-패키지의 ca.jo를사용하였다. 패키지의 자세한 사용법은 Pfaff (2008)을참조하였다.
3.1. 차원축소 ᄉ
ᅩ비자 물가지수 (customer price index; CPI)를 출력 변수로 18개 소비자 동향지수를 입력변수로 ᄒ
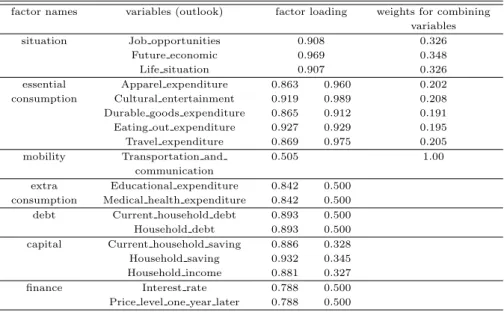
ᅡ여 물가지수를예측함에 있어서 입력변수의 차원을요인분석을 통하여 축소하여 보았다. 요인분석 결 과를바탕으로 상황 (situation), 필수소비 (essential consumption), 부가소비 (extra consumption), 부 ᄎ
ᅢ (debt), 자산 (captial), 재정 (finance)과 같은여섯 개의 요인 혹은 통합변수를도출하였다 (Table 3.1). 필수소비에 해당하는변수들 중에서 교통/통신 (mobility)지수는따로 고려해도될만큼다른양 ᄉ
ᅡᆼ을보여 하나의 요인으로 처리했다. Table 3.1에 교통/통신을포함한 요인 적재치와 제외한 적재치를 ᄉ
ᅮ록하였다. 지수들에 대한 요인분석을 통한 통합변수는해당 요인의 하위 변수 (지수)들의 요인 적재 ᄎ
ᅵ들의 상대비율을이용한 가중치를이용한 가중평균으로 정의하였다.
Table 3.1 Factor analysis for the customer survey indices
factor names variables (outlook) factor loading weights for combining variables
situation Job opportunities 0.908 0.326
Future economic 0.969 0.348
Life situation 0.907 0.326
essential Apparel expenditure 0.863 0.960 0.202
consumption Cultural entertainment 0.919 0.989 0.208 Durable goods expenditure 0.865 0.912 0.191 Eating out expenditure 0.927 0.929 0.195
Travel expenditure 0.869 0.975 0.205
mobility Transportation and 0.505 1.00
communication
extra Educational expenditure 0.842 0.500 consumption Medical health expenditure 0.842 0.500 debt Current household debt 0.893 0.500 Household debt 0.893 0.500 capital Current household saving 0.886 0.328 Household saving 0.932 0.345 Household income 0.881 0.327
finance Interest rate 0.788 0.500
Price level one year later 0.788 0.500
3.2. 단위근 검정
Figure 3.1에서 볼수 있듯이 지수들이 상승 혹은하강 경향을보이고 있다. 원시계열 자료에 대한 차 부
ᆫ을 일회 실시하고 단위근검정 (augmented Dickey-Fuller test)을 실시한 결과 검정통계량이 -4.0에 ᄉ
ᅥ -6.0의 값을갖고 p-값이 모두 0.01이하가 되어 정상시계열이됨을알 수 있었다.
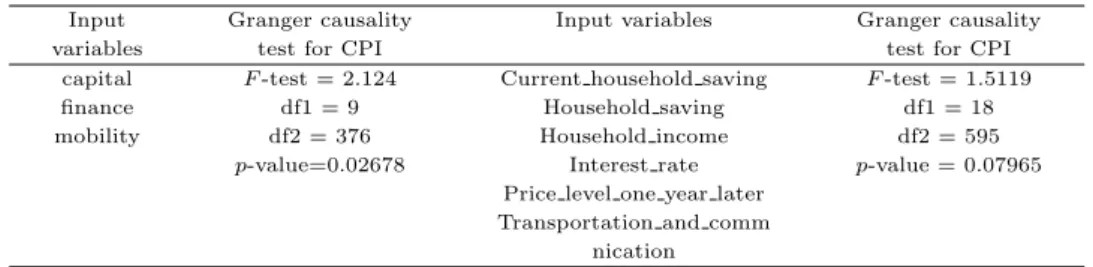
3.3. 그랜저 인과관계와 공적분 분석 ᄌ
ᅥ
ᆨ정차수를도출하기 위한 AIC, HQ (Hannan-Quinn), SIC와 FPE (final prediction error)의 수치 르
ᆯ보면 1 또는 3이 적절한 것으로 판단되고 우선 차수를 3으로 놓고 그랜저 인과관계와 공적분 분석을 ᄉ
ᅮ행하였다 (Table 3.2).
ᄉ
ᅩ비자 물가지수를 출력변수로 상황을비롯한 여섯 개의 통합변수와 교통/통신지수를 입력변수로 하 ᄋ
ᅧ 그랜저 검정을수행한 결과 유의확률이 0.2519로 보통의 유의수준보다 커서 인과관계를받아드릴 수 어
ᆹ는반면에 재정, 자본,교통/통신만을고려한 경우 유의확률이 0.0267로 인과관계를 인정할 수 있다고 ᄒ
ᅡ겠다 (Table 3.3).
Table 3.2 Model adequacy statistics for the order of 1, 2 and 3
n 1 2 3
AIC(n) 0.560 0.508 0.356
HQ(n) 0.770 0.886 0.901
SIC(n) 1.078 1.440 1.702
FPE(n) 1.751 1.665 1.435
ᄒ
ᅡᆫ편 통합변수들이 아닌 하위 지수들을 입력변수들로 사용하여 인과성을검정하면 인과관계가 유의하 ᄌ
ᅵ 않음을알 수 있었다 (Table 3.4). 나름요인분석을 통한 변수 통합이 적어도 본사례에서는의미가 이
ᆻ다고 하겠다.
Figure 3.1 Time plots for various indices
Table 3.3 Test for the Granger-causality
H0: situation, essential, extra consumption, debt, finance, capital, mobility, do not Granger-cause CPI
F -test = 1.190 df1 = 21 df2 = 656 p-value = 0.251
H0: finance capital mobility do not Granger -cause CPI
F -test = 2.124 df1 = 9 df2 = 376 p-value = 0.026
Table 3.4 Granger causality test for three integrated variables and six indices
Input Granger causality Input variables Granger causality
variables test for CPI test for CPI
capital F -test = 2.124 Current household saving F -test = 1.5119
finance df1 = 9 Household saving df1 = 18
mobility df2 = 376 Household income df2 = 595
p-value=0.02678 Interest rate p-value = 0.07965
Price level one year later Transportation and comm
nication
3.4. 벡터오차수정모델 ᄋ
ᅡ
ᇁ서 7가지 변수 중 3가지 변수 (capital, finance, mobility)가 유의미한 것으로 판단되어 해당 통합 ᄇ
ᅧᆫ수들에 차분을 수행하여 정상화된 데이터를 이용하여 소비자 물가지수에 대하여 재정, 자본 그리고 ᄀ
ᅭ통/통신을 입력으로 하는 경우를고려하면 검정 통계치가 유의수준의 임계치보다 비로소 작게 되는
‘r ≤ 2’의 경우와 ‘r ≤ 3’ 택하여 유의한 공적분이 2개 이상 존재한다고 판단된다 (Table 3.5).
Table 3.5 Test for the cointegration
no. of cointegration significant level
test statistics 10% 5% 1%
r ≤ 3 2.50 7.52 9.24 12.97
r ≤ 2 6.97 13.75 15.67 20.20
r ≤ 1 15.46 19.77 22.00 26.81
r ≤ 0 52.66 25.56 28.14 33.24
ᄋ
ᅵ제, 재정, 자본그리고 교통/통신을 입력으로 소비자 물가지수를 출력으로 시차가 3인 VECM을추 저
ᆼ한 후 유의한 추정치들에 대한 통계수치들을 Table 3.6에 기록하였다. 즉,추정식을
∆CP It= 0.237∆CP It−1− 0.518∆CP It−2+ 0.025∆financet−1− 0.041∆capitalt−2+ et
ᄋ
ᅪ 같이 추정하였고 소비자 물가지수 (CPI)는차분했음을감안할 때 자체적으로 1∼4개월 전 자료까지 여
ᆼ향을받고 있으며 재정 (finance)은 1∼2개월 전, 자본 (capital)은 3∼4개월 전 자료에 영향을받고 있 ᄋ
ᅳ
ᆷ을 알 수 있다. 소비자 물가지수의 변화량은차분을감안하여 재정 전망은양의 효과로 자본전망은 ᄋ
ᅳ
ᆷ의 효과로 소비자 물가지수에 영향을 준다고 하겠다. 즉, 소비자 물가지수 변화량이 주로 과거 자체 ᄇ
ᅧᆫ화량에 영향을받고 있고 예금같은자산의 변화는양의 방향으로 이자율같은재정 지수의 변화에는 ᄋ
ᅳ
ᆷ의 방향으로 영향을받는다고 하겠다.
Table 3.6 Significant VECM test statistics for the CPI
Estimate Std. Error t-value Pr(> |t|)
∆finance
t−10.025 0.008 2.901 0.004
∆CPI
t−10.237 0.088 2.674 0.008
∆capital
t−2-0.041 0.015 -2.701 0.008
∆CPI
t−2-0.518 0.087 -5.924 0.000
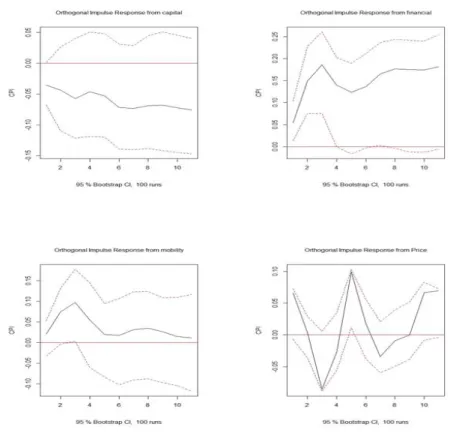
3.5. 충격분석, 분산분해 및 예측 추
ᆼ격분석 (Figure 3.2)에 의하면 가계예금과 같은자산, 이자율과 같은재정 상태에 대하여 소비자 물 ᄀ
ᅡ지수는 일관되게 양 혹은 음으로 영향을받으나 교통비/통신비에 대하여는그 영향이 시간에 흐름에 ᄄ
ᅡ라 0에 다가감을 볼수 있다. 한편, Figure 3.2에서 ‘price’로 표기된소비자 물가지수 자체는시간이 ᄒ
ᅳ름에도 영향력이 다른변수들과 달리 0을기점으로 위와 아래 변화하고 있다. 이는소비자 물가지수 ᄋ
ᅦ 대하여 그 자체만으로는안정된예측이 어렵고 안정된예측을위해 자산 혹은재정과 같은다른변수 ᄃ
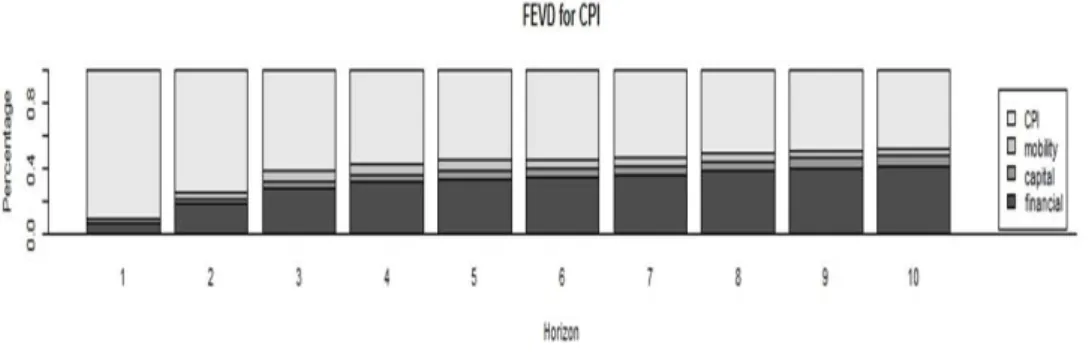
ᅳ
ᆯ이 도움이됨을의미한다고 하겠다. 분산분해 (Figure 3.3)에 의하면 막대기 면적의 비율로 볼때, 과 ᄀ
ᅥ 소비자 물가지수의 분산이 현재 소비자 물가지수 분산 혹은변화에 가장큰영향을주고 있다고 하겠 ᄃ
ᅡ.
ᄒ
ᅡᆫ편 소비자 물가지수 (Zt)에 대하여 자기회귀이동평균모델을
(1 + 0.580B12)(1 − B12)Zt= (1 + 0.384B4)(1 − B)et
ᄋ
ᅪ 같이 추정할 수 있었다. 2017년 11월부터 2018년 4월까지의 소비자 물가지수 실제값, 인과모델에 ᄋ
ᅴ한 예측값과 자기회귀이동평균에 의한 예측값을비교하여 보았다. 인과모델에 의한 예측값이 자기회 ᄀ
ᅱ이동평균모델에 의한 예측값보다 실제값에 매우 유사하게 형성되고 있음을 볼수 있다 (Figure 3.4).
Figure 3.2 Impulse reponses for CPI
Figure 3.3 Forecast error variance decomposition for the CPI
Figure 3.4 Forecasted CPIs by the AR model and by Granger model and the real CPIs
4. 결론 이
ᆸ력변수가 다수인 경우 차원 축소를 통해 새로운 통합 변수들을 추출하고 이들을이용하여 인과모 ᄃ
ᅦᆯ을 추정할 경우 개별 변수들을 사용한 경우 보다 모델 추정이나 예측이 보다 타당할 수도 있음을 예 르
ᆯ 통하여 보였다. 실제로 본 논문에서 자본과 재정이라는두 가지 통합변수의 하위 개별 변수들과 교 ᄐ
ᅩᆼ/통신지수를 입력변수로 소비자 물가지수를 출력 변수로 하는그랜저 검정을수행하면 인과관계가 유 ᄋ
ᅴ하지 않다고 판명된다. 생각건대 통합 변수를 만드는과정에서 개별 변수들의 경중을 가중치를 통해 ᄇ
ᅡᆫ영함으로써 개별 변수들을그대로 사용하는경우 보다 유의미한 결과가 도출되었다고 보인다. 위의 겨
ᆯ과는 본 논문의 예제에서만 가능한 현상일 수 있음으로 추후 보다 심도 깊은연구가 필요할 것 같다.
References
Burnham, K. P. and Anderson, D. R. (2002). Model selection and multimodel inference: A practical information-theoretic approach, 2nd ed. Springer-Verlag, New York.
Cho, D. (2006). Introductory finance econometrics, Chong Ram, Seoul.
Chung, J. H. and Kim, H. C. (2011). A study on the causality and dynamic relation between the housing price and the trade volume in the metropolitan area. Journal of Korean Planners Association, 46, 131-148.
Claeskens, G. and Hjort, N. L. (2008). Model selection and model averaging, Cambridge University Press, Cambridge.
Engle, R. F. and Granger, C. (1987). Co-integration and error correction: Representation, estimation and testing. Econometrica, 55, 251-276.
Granger, C. (1969). Investigating casual relations by econometric models and cross-spectral methods.
Econometrics, 37, 111-120.
Granger, C. (1981). Some properties of time series data and their use in econometric model specification.
Journal of Econometrics, 16, 121-130.
Jeong, K. H. and Nishiyama, Y. (2007). Nonparametric granger causality test. Journal of the Korean Data
& Information Science Society, 18, 195-210.
Johansen, S. (1991). Estimation and hypothesis testing of cointegration vectors in Gaussian vector autore- gressive models. Econometrica, 59, 1551-1580.
Johansen, S. (1995). Likelihood-based inference in cointegrated vector autoregressive models, Oxford Uni- versity Press, Oxford.
Johansen, S. and Juselius, K. (1990). Maximum likelihood estimation and inference on cointegration with application to the demand for money. Oxford Bulletin of Economics and Statistics, 53, 169-209.
Kim, J. H., Jin, D. L., Lee, J. S., Kim, S. J. and Son, Y. S. (2012). Prediction of the interest spread using VAR model. Journal of the Korean Data & Information Science Society, 23, 1093-1102.
Lim, S. S. (2016). Comparison of the forecasting models with real estate price index. Journal of the Korean Data & Information Science Society, 27, 1573-1583.
Pfaff, B. (2008). VAR, SVAR and SVEC models: Implementation within R package vars. Journal of Statistical Software, 27, 1-32.
Shin, Y. G. (2009). Study on the causality between call rate and exchange rate under global economic crisis. Journal of the Korean Data & Information Science Society, 20, 655-660.
Sims, C. A. (1980). Macroeconomics and reality. Econometrics, 48, 1-48.
Statistics Korea. http://kosis.kr
2018, 29
(4)
,903–913
Forecasting consumer price indices: A case study using the time series causal model and factor analysis †
Ro Jin Pak
1
1Department of Applied Statistics, Dankook University
Received 4 June 2018, revised 27 June 2018, accepted 28 June 2018
Abstract
We tried to predict the consumer price index. The eighteen consumer survey in- dices associated with the consumer price index were used as the independent variables.
However, there were too many independent variables in estimating the predictive model so that it turned out to be difficult to construct the model itself. In this paper, we first tried to combine the consumer survey indices through time series factor analysis, and then tired to construct the model with less independent variables. The causal model with the consumer survey indices as the independent variables was not feasible, but the model for the consumer price index with the combined indices have been established well. Even, the predictions by the proposed method for the consumer price index were more like the actual value than those by an ARIMA model.
Keywords: Customer price index, customer survey index, Granger causal model, im- pulse response analysis, variance decomposition, vector autoregressive model, vector error correction model.
†
The present research was conducted by the research fund of Dankook University in 2018.
1