서 론
의료영상분석의 목적은 주어진 의료영상으로부터 효과적으
로 생체정보를 추출하거나, 이를 시각화 하는데 있으며, 이를 위해 영상 분류, 영상 분할, 영상 정합 등의 고차원 분석이 수 행된다. 이러한 의료영상분석의 성공적인 수행을 위해서는 영 상을 표현하는 특징을 효과적으로 추출해 내는 것이 필수적이 며, 지난 수십 년간 이를 위한 다양한 연구들이 수행되어 왔다.
하지만 대부분의 기존 의료영상분석 방법들은 컴퓨터 비전분 야에서 널리 쓰여 온 SIFT(Scale-Invariant Feature Transform), Harr Wavelet, HOG(Histogram of
의료영상 분석을 위한 딥러닝 기반의 특징 추출 방법
이예하1*∙김현준1∙김국배2∙김남국2
1뷰노코리아
2울산대학교 의과대학, 서울아산병원, 융합의학과
Deep Learning-based Feature Extraction for Medical Image Analysis
Yeha Lee1*, Hyun-Jun Kim1, Guk Bae Kim2, Namkug Kim21VUNO Korea Inc.
2Convergence Medicine, University of Ulsan College of Medicine, Asan Medical Center
= Abstract =
Extracting features that represents well the characteristics of medical image is critical for successful medical image analysis. However, most of the conventional medical image analysis methods rely on hand-crafted or case-specific feature extraction algorithms widely used in computer vision research which often lead to unstable or degraded results. This is because the assumptions or rules used for the design of hand-crafted features are not general enough to reflect the underlying image statistics or complex structure of the input data. Therefore, developing learning-based method which extracts most significant features automatically from the medical images is key to the success of robust and accurate medical image analysis. Recently, deep learning algorithms have attracted attentions from various fields for their remarkable performance gain on feature-based recognition problems. In both supervised and unsupervised manner, deep learning methods are capable of learning hierarchical representation of the patterns from low-level to high-level features.
To this end, in this paper, we introduce deep learning-based feature extraction method which adap- tively learns the most significant features for the given task using deep structure. We also introduce some recent literatures on medical image analysis such as image segmentation and image registra- tion using deep learning algorithms.
Key words: Deep learning, Representation learning, Medical image analysis
통신저자: 이예하, (135-545) 서울시 강남구 논현동 203번지 751빌딩 8층 802-14호, 뷰노코리아
Tel: 02-515-6646, Fax: 02-546-5559 E-mail: [email protected]
Oriented Gradients), LBP(Local Binary Pattern) 등의 고정적인 특징 추출 방법을 사용하거나, 각각의 작업 목표나 영상에 특화된 특징을 추출하는 방법을 사용하고 있으며, 이로 인해 영상별로 분석의 성능 편차가 크거나, 복잡하고 내재된 특징을 추출해 내지 못해 분석의 성능이 떨어지는 등의 한계를 나타내었다[1, 2].
이러한 한계를 극복하기 위해 다양한 특징 중, 분석에 목적 에 가장 부합하는 특징을 스스로 학습하는 기계학습 기반의 영 상분석방법이 개발되어 널리 활용되어 왔다[3]. 하지만 영상분 석모델을 학습하기 위한 학습데이터 생성을 위해서는 전문가 가 직접 영상에 관심 영역을 표시하거나 의학적 진단을 내려야 하는 등의 높은 비용이 들 뿐 아니라, 사람이 개입함으로써 다 양한 주관적이고 정성적인 요인이 개입하게 된다. 특히, 다양 한 영상장비에서 생산되는 수많은 의료영상들이 이러한 전문 가를 통한 부가적인 정보 없이는 모델의 학습에 활용될 수 없 다는 점에서 비효율성과 개선의 여지가 존재한다. 이러한 가운 데, 최근 깊은 구조의 인공신경망을 통해 주어진 다량의 데이 터로부터 특징을 자동적이고 계층적으로 학습하는 방법이 그 대안으로 주목받고 있다. 딥러닝이라 불리는 이러한 깊은 구조 의 인공신경망은, 출력값 없이도 입력 데이터의 비선형적 변환 을 반복하면서 하위 층의 단순한 특징들로부터 상위 층의 보다 복잡하고 구조적인 형태의 특징들까지를 추출해내는 비지도학 습(Unsupervised Learning)이 가능하다. 또한, 학습된 특징 들을 소량의 출력값을 이용하여 기존의 기계학습 모델의 입력 값으로 사용할 때, 분석 성능이 기존의 방법에 비해 대폭 향상 됨이 다양한 분야에서 확인되고 있다[4-6]. 특히, 전문가의 부 가적 정보 없이 다량의 영상으로부터 직접 영상을 표현하는 특 징을 학습하고, 소량의 전문가 판단 정보로 식별력을 최대화
하는 방법은 기존 의료영상분석 환경의 한계를 극복하고 워크 플로우를 개선하는데 큰 기여를 할 수 있을 것으로 기대된다.
본 리뷰에서는 깊은 구조를 가진 인공신경망을 통해 주어진 학습 영상 데이터로부터 복잡하고 다양한 수준의 특징을 학습 하는 딥러닝 기반 특징 학습 방법론들을 소개하고, 이를 활용 한 최신 연구 동향을 살펴보고자 한다. 2장에서는 단순한 특징 부터 복잡한 특징까지를 스스로 학습하는 다층적 깊은 구조에 대해 살펴보고, 3장에서는 이러한 구조를 가진 대표적인 알고 리즘들을 소개한다. 4장에서는 딥러닝 알고리즘을 활용한 의 료영상분석의 예시를 살펴보고, 5장에서 향후 연구 전망에 대 한 논의와 함께 끝맺고자 한다.
Deep Architecture for Feature Learning
SVM (Support Vector Machine)으로 대표되는 얕은 구조 (Shallow Architecture)는 학습을 필요로 하는 대부분의 분 류 문제에 지금까지 활용되어오고 있다. 본 장에서는 깊은 구 조(Deep Architecture)의 발전과정과 더불어 얕은 구조보다 더 나은 성능을 보이는 이유를 설명하고자 한다.
1. 신경망(Neural Network)의 발전과 한계
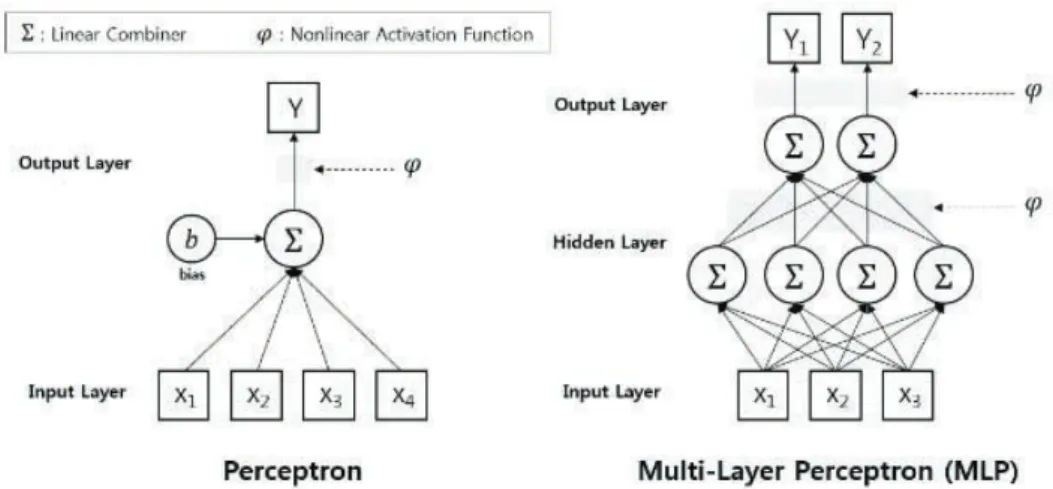
Warren McCulloch와 Walter Pitts은 1943년 인간의 신 경세포 학습에 대한 수학적 모델을 최초로 제안하였고[7], 이 후 Dornald Hebb은‘Hebbian Learning’이라 불리는 두 신 경세포 간 가중치를 기반으로 한 시냅스의 변화 규칙을 밝혀냈 다[8]. 이러한 이론적 발전을 토대로 1958년 Frank Rosenblatt은 두 층의 네트워크로 이루어진 최초의 학습기인 퍼셉트론(Perceptron)을 개발하였는데, 이는 AND/OR연산
그림 1. 퍼셉트론(Perceptron)과 다층 퍼셉트론(Multi-Layer Perceptron)
과 같은 선형분리만 가능한 한계가 있었다[9].
그러나, 1975년 Paul Werbos에 의해 목표값과 출력값 사 이의 오차를 토대로 각 층 사이의 연결강도를 갱신하는 방법인 오류역전파(Back-propagation) 알고리즘이 제안되었고[10], 1986년 Rumelhart 등은 오류역전파 방법을 적용한 다층 퍼 셉트론(Multi-Layer Perceptron)을 제안하면서[11], XOR 연산과 같은 비선형분리도 가능하게 됨에 따라 신경망 연구는 다시 발전하게 되었다. 하지만, 대체로 하나 이상의 은닉층을 가진 구조에서는 국소 최적해(Local Optima)에 빠지는 문제, 과적합(Overfitting) 문제, 너무 큰 계산량 등의 문제로 2006 년 Hinton의 사전 학습(Pre-training) 방법이 제안되기 전까 지는 정체기에 빠지게 되었다[12]. 한편, 1989년 Yann LeCun은 이미지 인식을 위해 오류역전파 알고리즘을 기반으 로 한 3개의 은닉층을 갖는 깊은 신경망(Deep Neural
Network)을 제안했는데 (그림 2), 사람이 쓴 숫자를 인식하 는 문제에서(Handwritten Zip Code Digit) 성공적으로 동작 하였다[13]. 하지만 10개 클래스를 갖는 9,298개 데이터를 학 습시키는데 3일 소요되는 등 너무 오랜 학습 시간이 소요됨에 따라 당시의 기술로서는 일반적으로 활용되는데 한계가 있었 고, 이에 따라 1970년대 Vladimir Vapnik 등이 개발한 SVM 과 같이 보다 효율적인 알고리즘이 최근까지 더 널리 활용되게 되었다.
2. 얕은 구조(Shallow Architecture)에서 깊은 구조 (Deep Architecture)로
신경망을 포함한 기존의 방법들이 주어진 데이터로부터 학 습 오류를 최소화하기 위한 목적으로 설계된 반면, SVM은 각 클래스 사이의 거리(Margin)를 최대화하는 것을 목표로 함으
그림 3. 얕은 구조의 대표적인 방법인SVM 중 선형SVM(좌) 비선형SVM(우) 그림 2. 깊은 구조 신경망을 이용한 우편 주소 분류 방법[13]
로써 다양한 문제에 보편적으로 사용될 수 있는 장점이 있었는 데, 목적함수와 데이터가 주어졌을 때 최적의 분류 초평면 (Optimal Separating Hyperplane)을 찾도록 해준다[14].
SVM의 기본적인 아이디어는 퍼셉트론의 입력층을 커널함수 (Kernel Function)이라 불리는, 사람이 정의한 특징 추출 (Feature Extraction)함수를 갖는 층(Hand-Crafted Feature Layer)으로 대체한 것으로 볼 수 있는데, 이러한 얕 은 구조 덕분에 효율적인 학습이 가능하게 된 것이다. 예를 들 어, 입력 공간이 비선형인 경우 커널함수에 의해 고차원 벡터 공간으로 사상(Mapping)되고 선형적인 초평면에서 분류가 가능하게 되는 것이다.
특히, SVM은 패턴인식 분야에서 우수한 성능을 보였지만,
상기 구조적 한계에 따라 계층적이거나 복잡한 특징을 갖고 있 는 데이터의 경우 좋은 결과를 보여주지 못했다. 해결책으로 커널함수에서 입력값을 복잡한 고차원 벡터 공간으로 사상시 키려는 시도가 있었으나, 커널함수 자체가 사람에 의해 선택된 고정형태였기 때문에, 다양한 입력 데이터로부터 충분한 사전 지식(Prior Knowledge)을 학습하는 데에는 한계가 있었다 [4]. 다른 해결책으로, SVM 모델에 사전 지식을 부여하는 방 법도 제안되었으나[15], 이는 모델에 사람이 사전지식을 알려 주는 것으로서 궁극적으로 데이터로부터 모델을 학습하지 못 하는 문제는 여전히 존재했을 뿐 아니라, 이렇게 부여된 사전 지식은 매 문제마다 새로 정의되어야 하는 문제가 있었다. 한 편 딥러닝의 선진 연구자인 Yoshua Bengio와 Yann LeCun 교수는 2007년 인공지능 관점에서 그림 4와 같이 좋은 구조의 요건을 5가지 제시하였는데[16], 이 중 입력값을 통해 사전 지 식을 학습할 수 있어야 한다는 사항은 가장 중요한 요소로 꼽 힌다. 다시 말해, 주어진 데이터로부터 모델이 스스로 데이터 에 내재된 특징(Feature)을 학습할 수 있어야 한다는 의미로 해석될 수 있다.
결국 주어진 데이터로부터 특징을 학습할 수 있는 다층구조 의 필요성이 제기되었으며, 이에 따라 깊은 구조인인 다층신경 망(Multi-Layer Neural Network)에 대한 관심이 다시 높아 지기 시작했다. 깊은 구조는 층(Layer)이 많아짐에 따라, 상 위 층으로 올라갈수록 더욱 추상화된 형태의 특징을 학습할 수 있다. 각 층은 서로 계층적(Hierarchial)인 구조를 갖게 되는 데 이처럼 모델의 복잡도(Complexity)와 표현력이 높아짐에 따라, 다양한 클래스를 갖는 문제에 대한 분류능력이 좋아지게 된다. 그림 5의 단순한 예와 같이, 파라미터 수가 같은 두 개의 네트워크의 경우에도 은닉층의 수에 따라 경로(Path)의 개수 는 크게 차이가 남을 알 수 있다. 실제 각 층별 학습된 특징을 시각화한 경우, 하위에서 상위로 올라갈수록 보다 추상화된 수
�A highly flexible way to specify prior knowledge, hence a learning algorithm that can function with a large repertoire of architectures.
�A learning algorithm that can deal with deep architectures, in which a decision involves the manipulation of many in- termediate concepts, and multiple levels of non-linear steps.
�A learning algorithm that can handle large families of func- tions, parameterized with millions of individual parameters.
�A learning algorithm that can be trained efficiently even, when the number of training examples becomes very large. This excludes learning algorithms requiring to store and iterate multiple times over the whole training set, or for which the amount of computations per example increases as more examples are seen.This strongly suggest the use of on-line learning.
�A learning algorithm that can discover concepts that can be shared easily among multiple tasks and multiple modal- ities (multi-task learning), and that can take
그림 4. Bengio와LeCun이 제시한 좋은 학습기의 조건
그림 5. 얕은 구조와 깊은 구조 모델 비교. 같은 수의 파라미터에도 더 풍부한 표현력을 제공함.
준의 특징을 학습했음을 알 수 있는데, 맨 하위층은 다양한 각 도와 형태를 갖는 선이, 중간층은 객체를 구성하는 각 부분들 그리고 최상위층은 객체단위가 특징으로 학습된 것을 확인할 수 있다 (그림 6).
이처럼, 얕은 구조에 비해 더 큰 잠재력을 지닌 깊은 구조는 최근 GPU (Graphic Processing Unit)를 필두로 한 연산 성 능의 급격한 발전을 통해 큰 계산량에도 불구하고 개인이 직접 실험해 볼 수 있는 환경이 조성됨에 따라, 실세계의 다양한 문 제에 적용되면서 가능성을 인정받게 되었다.
Deep Learning Algorithms
콘볼루셔날 신경망(Convolutional Neural Network;
CNN)은 사전학습(Pre-training) 없이 역전파 알고리즘 (Back-propagation)을 활용하여, 지도학습(Supervised Learning)이 가능한 대표적 딥러닝 방법론 중 가운데 하나이 다. CNN은 영상 화소사이의 공간 정보를 활용하는 특징으로 인해, 다양한 비전 문제에 활용되고 있으며, 기존 방법론들의 성능을 넘고 있다 [5, 6, 17].
그림 6. 계층적 특징 학습. 학습 층에 따라 학습된 추상화 레벨이 다름.
그림 7. 콘볼루션 신경망의 예[18]
그림 8. 희소 연결성(Sparse Connectivity)과 공유 가중치(Shared Weights) [18]
1. Convolution Layer
그림 7에서와 같이, CNN은 콘볼루션 층(Convolutional Layers)와 통합 층(Pooling Layers)으로 이루어진다. 콘볼루 션 층은 입력값에 대하여 콘볼루션 필터와 국지 수용장(Local Receptive Field)의 내적 및 비선형 활성 함수(Activation Function)을 취함으로서 특징지도(Feature Map)을 구한다.
fi, j,k= a(wTkxi, j)
위 식에서 (i, j)는 특징저도(Feature Map)에서의 색인, xi, j 는 해당 특징 지도를 구하기 위한 입력 데이터 영역, k는 특징 지도의 채널 색인, 즉 필터의 개수, 그리고a( )는 3.3장에서 설명될 비선형 활성 함수를 의미한다.
다른 네트워크 구조와 비교하여, CNN의 특징은 희소 연결 성(Sparse Connectivity)과 공유 가중치(Shared Weights) 를 들 수 있다. 이미지의 예를 들면, 각각의 콘볼루션 필터는 입력 영상의 화소마다 같은 가중치를 공유하여 특징 지도를 계 산한다. 즉 특징 지도를 구하기 위해, 전체 이미지가 아닌 일부 패치를 사용하고, 모든 영역에서 동일한 가중치를 적용한다.
이러한 특징은 학습할 모수의 개수를 줄여주고, 역전파 알고리 즘을 통한 학습을 가능하게 만든다. 그림 8은 CNN의 희소 연 결성과 공유 가중치를 보여준다.
2. Pooling Layer
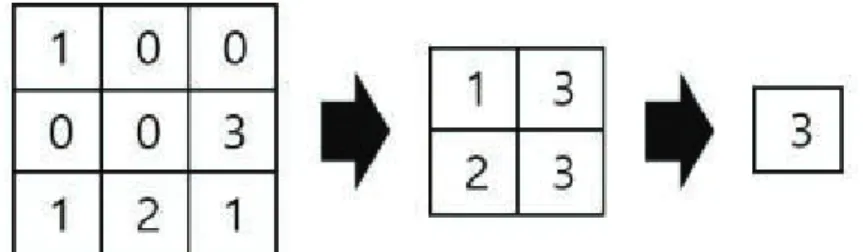
통합 층(Pooling Layer 또는 Subsampling Layer)는 이전 층에서 구해진 특징 지도의 지역정보를 활용하여 새로운 특징 지도를 생성한다. 일반적으로 통합 층에 의해 새로 생성된 특 징지도는 원래의 특징 지도보다 작은 크기로 줄어든다. 대표적 인 통합 방법은 최대 통합(Max Pooling)과 평균 통합 (Average Pooling) 등이 있다. 최대 통합은 아래와 같이 각각 의 영역에서 가장 큰 값을 택하는 모델이다.
평균 통합은 아래와 같이 각각의 영역의 평균값을 택하는 모 델이다.
bj=
∑
i∈Rjai
위 식에서Rj는 이전 특징지도에서 j번째 통합 영역을 나타 내며, i는 Rj안의 각각의 요소를 타나내는 색인이다. 그림 9는 최대 통합의 예를 보여준다.
통합 층의 특징지도는 일반적으로 이전 층의 특징 지도보다 입력 이미지에 존재하는 임의의 구조나 패턴의 위치에 영향을 적게 받는다. 즉, 통합 층은 입력 이미지 혹은 이전 특징 지도 에서의 노이즈나 왜곡과 같은 지역적 변화에 보다 강인한 특징 을 추출할 수 있게 되고, 이러한 특징은 분류 성능에 중요한 역
1
│Rj│ bj= max ai
i ∈ Rj
그림 10. 224×224×3 크기의 입력 영상으로부터 첫 번째 콘볼루션 층으로부터 학습 된11×11×3 크기의 콘볼루션 커널 예시[5]
그림 9. 최대 통합(Max Pooling) 예시. 이때, 필터 크기는2×2 이며, 단계 크기는1 임.
할을 한다.
또 다른 통합 층의 역할은 깊은 구조상에서 상위의 학습 층 으로 올라갈수록 더 넓은 영역의 특징을 반영할 수 있게 한다.
그림 9에서 볼 수 있듯이, 두 번째 층의 각각의 특징은 첫 번째 층의 2×2영역에 해당하는 정보를 가지고 있으며, 세 번째 층 의 경우 3×3영역의 정보를 반영하게 된다. 이러한 특징으로 CNN이 층이 쌓이면서, 아래쪽 특징은 지역적인 특징을 반영 하고 상위로 올라갈수록 보다 추상적인 전체 이미지의 특징을 반영하는 특징 생성할 수 있다. 그림 10은 첫 번째 층에서 학 습된 결과를 보여준다[5]. 모서리 탐지(Edge Detection)과 같은 국지 영역의 특징을 반영하는 특징이 학습되는 것을 볼 수 있다.
3. Activation Function
CNN을 포함한 대부분의 인공신경망 모델은 표현력 (Expressive Power)를 높이기 위해 특징 지도의 각각의 원소 에 비선형 함수를 적용한다. 일반적으로 신경망 논문들에서 사 용되는 활성 함수(Activation Function)으로는 Sigmoid 혹 은 Hyperbolic Tangents가 있다. 하지만 그림 11에서 볼 수 있듯이, 이러한 함수들은 생물학적 반응과 특성이 달라 인간의 뇌가 학습하는 방법을 모방하려는 인공신경망의 목표에 부합 되지 않는다 [19].
이러한 문제를 해결하기 위해 정류 선형 유닛(Rectified Linear Units; ReLU)이 제안되었다 [19, 20]. Rectifier Function (=max(0,x))은 기존의 비선형 함수보다 생물학적 모델의 특성과 유사한 반응 형태를 가지고 있으며 [19], 계산 복잡도가 낮아 다양한 딥러닝 모델에서 사용되고 있다. 또한 ReLU는 네트워크 학습에서 중요한 몇 가지 장점을 가지고 있 는데, 첫 번째로, ReLU는 네트워크의 희소 표현을 가능하게 만든다. 만약 가중치가 균등 분포(Uniform Distribution)로 초기화 되어있다면, 약 50%의 은닉 유닛(Hidden Units)이 0
값을 가지게 되며, 이러한 희소 표현은 네트워크를 학습하는데 있어 중요한 특징으로 작용한다. 다음으로, ReLU는 네트워크 의 일부 경로만 활성화(즉 0의 값을 가지지 않음) 시키며, 이 러한 하위 집합에서 네트워크는 선형적인 특징을 가지게 된다.
선형성으로 인해, 딥러닝 학습의 어려움중의 하나인 기울기 소 실(Vanishing Gradient)문제를 해결하여 학습을 가능하게 만든다.
4. Regularization
하나 이상의 은닉 층을 가진 다층 퍼셉트론은 이론적으로 임 의의 함수를 근사(Approximation)할 수 있다 [21]. 이 때문 에 깊은 구조는 쉽게 과적합문제에 빠지게 된다. 즉, 학습 데이 터에서는 낮은 오류를 가지도록 학습되지만, 테스트 데이터 (Unseen Data)에서는 높은 오류율을 가지게 된다. 이와 같은 문제를 해결하고 네트워크의 일반화(Generalization) 성능을 높이기 위해 가중치 감쇠(Weight Decay), 조기 정지(Early Stopping)와 같은 다양한 정규화(Regularization)기법이 연 구되어 왔다 [22].
최근 위의 문제를 해결하기 위해 Dropout 기법이 제안되었 다 [23]. 그림 12에서 볼 수 있듯이, 네트워크 학습 단계에서 Dropout은 임의로 확률(예를 들어, 0.5)로 은닉 유닛을 네트
그림 11. (좌) 생물학적 데이터를 기반으로 한 활성 함수. (우) 인공 신경망 연구에서 주로 사용되는 활성 함수[19]
그림 12. Dropout. 은닉 노드가 임의로 제거 됨
워크에서 제거한다. 이것은 특징 탐지기(Feature Detector) 사이의 지나친 동시적응(Co-adaptation)을 막고, 임의로 선 택된 특징 집합들이 올바른 정답을 찾도록 도와준다. 또한 그 림 12에서 볼 수 있듯이, 실제로 Dropout기법은 추계적 기울 기 하강법(Stochastic Gradient Descent) 학습 기법에서 정 규화 항으로 해석될 수 있다. CNN에서 Dropout은 일반적으 로 마지막 단계인 완전 연결층(Fully Connected Layer)에 적용된다 [24].
Dropout의 또 다른 역할은 테스트 단계에서 찾아 볼 수 있 다. 테스트 오류를 줄이는 좋은 방법가운데 하나는 무수히 많 은 서로 다른 네트워크로부터의 결과를 평균하는 것이다. 하지 만 모든 네트워크들을 일일이 학습하고 테스트하는 것은 실제 로 불가능하다. 그러나 Dropout은 매 학습 단계마다 임의의 은닉 노드를 제거함으로써, 새로운 네트워크를 생성하고 학습 한다. 즉 서로 다른 N네트워크들이 가중치를 공유하며 학습된 다. 이것은 Dropout을 통하여 학습된 모델은 테스트 단계에서 가중치를 일정 비율로 나누어 주는 것으로서, 가능한 모든 하 위 모델들의 기하평균 연산을 수행(또는 근사화)하는 것을 의 미한다.
Medical Image Analysis using Deep Learning
본 장에서는 딥러닝 모델을 이용한 의료영상분석을 영상 분 할을 통한 특정 생체 기관 표시, 영상 정합을 통한 의료 영상의 합성 및 변환, 영상 분류를 통한 질병 진단 등에 대한 최신 적 용 사례들을 통해 알아보고 연구 동향을 파악하고자 한다.
1. 영상 분할을 통한 생체 기관 표시
영상 분할(Image Segmentation)은 디지털 영상을 여러 개
의 화소 집합으로 나누는 과정을 말하며, 특히 의료영상분할은 의료영상을 보다 의미있고 해석하기 용이하도록 대상 영역의 경계선을 찾아내는 것을 목적으로 한다. 이는 임상에서 진단 및 분석, 고차원 시각화 등을 위해 필수적인 과정이다.
그림 13에서는 전립선 T2 MR 영상의 자동 분할을 위한 특 징 추출을 위해 비지도 학습 방법 중 하나인 다층 ISA (Independent Space Analysis)[26]를 사용하였다. ISA는 두개의 층을 가진 네트워크로서, 학습 영상으로 부터 샘플 된 영상 패치들 간의 제곱 비선형성을 학습하는 첫 번째 층의 단 순 유닛들과 이들 단순 유닛들의 반응 값들을 통합하여, 보다 넓은 영역간의 비선형성을 학습하는 두 번째 층의 통합 유닛들 로 구성되어 있다. 이러한 모델 구조에 주어진 학습 영상 전체 에 대한 네트워크의 에너지 함수를 최소화 하도록 하는 가중치 행렬을 구하면, 이것이 영상에서 특징을 추출하는 학습된 필터 가 된다. 해당 논문에서는 이러한 특징 학습 방법이 Harr Wavelet, HOG나 LBP 등과 같은 기존의 고정적인 특징 추출 방법에 비해 높은 분할 성능을 나타냄을 실험을 통해 보였으 며, 특히 단층 ISA에 비해 다층 ISA가 일관성 있게 분할 정확 도 비교에서 보다 높은 성능을 보임으로써, 깊은 구조가 계층 적으로 의미있고 중요한 특징을 추출하는데 보다 효과적임을 확인하였다.
또한, 7.0T MR 영상에서 알츠하이머병과 같은 뇌질환과 매 우 밀접한 연관이 있는 뇌 내 해마의 위치를 분할하기 위해 복 층의 콘볼루셔날 ISA이 사용된 바 있다 [25]. 기존의 저해상 도 MR에 비해 해상도가 높은 7.0T MR은 보다 세부적이고 다 양한 정보를 포함하고 있으며, 따라서 기존의 고정적인 특징 추출방법이 가정으로 하는 영역 내 밝기 균일성이나 구조적 단 순성이 유지되지 않는다. 또한, 기존의 기계 학습 방법을 기반 으로 하는 영상 분할 방법은 일정 수준 이상의 정확도를 위해 많은 수의 수동 분할된 학습 데이터를 보유해야 하는데, 이는
그림 13. Independent Subspace Analysis 네트워크 구조[1]
비용이 높을 뿐 아니라 분할되지 않은 많은 양의 영상을 활용 할 수 없다는 비효율성을 지닌다. 이러한 한계를 극복하기 위 해서 해당 논문에서는 비지도 학습 방법인 ISA를 이용하여 분 할되지 않은 MR 영상을 기반으로 특징을 학습하였으며, 특히 영상의 해상도가 높을 경우 증가하는 계산량을 효과적으로 다 루기 위해서 복층의 콘볼루셔날 ISA를 사용하였다. 새로운 7.0T MR영상이 주어지면, 학습된 콘볼루셔날 ISA를 이용해 특징을 추출해내고, 이 특징을 입력값으로 하여 Multi-Atlas 기반 분할 방법[27]을 통해 해마의 영역을 분할해 낸다. 실험 을 통해 다층 구조의 특징 학습 방법이 기존의 수동 추출 특징 을 이용한 분할 방법에 비해 여러 성능 측정 지표에서 일관되 게 높은 성능을 보임을 확인하였다.
2. 영상 정합을 통한 의료 영상의 합성 및 변환
영상 정합(Image Registration)은 서로 다른 시점이나 시 간에서 촬영된 영상을 변형하여, 하나의 영상 내에 표현하는 방법으로 의료영상에서는 서로 다른 장비에서 측정된 영상을 결합하여 보다 정확한 해부학적 정보를 제공하거나, 정상적인 영상과 비교하여 비정상 영역을 강조하는데 사용된다. 이를 위 해서는 정합을 위한 두 영상으로부터 해부학적 대응도를 밝혀 내어, 각각의 영상에서 추출된 특징들 간의 유사도를 최대화하 는 과정이 필요하다.
Wu 등은 뇌 MR 영상의 변형 정합을 위해, 가버 필터 (Gabor Filter) 등의 고정적 특징 추출 방법이나 전문가에 의 해 학습에 필요한 대응점 정보가 필요한 지도학습 방법이 아 닌, 다층 콘볼루셔날 ISA기반의 비지도 학습을 통해 특징을 학습하는 방법을 제안하였다 [2]. 특히, 고해상도 뇌 MR 영상 에서 영역별로 대형 영상 패치를 생성하고, 각 대형 영상 패치
별로 이동 창(Sliding Window) 방식으로 다수의 소형 영상 패치를 생성하여 이를 ISA의 입력으로 사용함으로써, 전체 뇌 MR 영상이 아닌, 영역별 대형 패치의 특징을 학습하게 한다.
따라서 한 쌍의 뇌 MR 영상이 주어지면, 각 영역별로 대형 영 상 패치를 생성하고, 다시 이를 이동 창을 통해 다수의 소형 영 상 패치화 한 후, 이를 학습된 다층 콘볼루셔날 ISA 네트워크 를 통과시켜 특징 계수 벡터로 변환한다. 변환된 특징 계수 벡 터 간 비교를 통해 각 영역별 대형 영상 패치 간 유사도를 측정 할 수 있으며, 유사도가 높은 두 대형 패치 쌍을 영상 정합을 위한 대응점으로 활용하게 된다. 해당 논문에서는 IXI와 ANDI 영상 데이터를 이용한 실험을 통해, 다층 ISA를 이용한 특징 학습 방법이 기존의 수동적 특징 추출방법에 비해 전반적 으로 가장 높은 정합 성능을 보이는 것을 확인하였다.
3. 영상 분류를 통한 질병 진단
의료 영상 분류는 영상의 분석을 통해 특정 질병이나 암과 관련된 종양이나 변이를 찾아내고, 이들의 유무나 정도에 따라 해당 질병 여부, 암 발생 여부 등을 진단하는 과정으로서, 전문 가의 최종 의사 결정의 보조수단이나 대체 수단으로 활용된다.
Cruz-Roa 등은 피부 기저세포암을 판별하기 위해 콘볼루셔 날 오토 인코더(Convolutional Auto-Encoder)를 활용한 암 탐지와 시각적 해석 방법을 제안하였다. 기저세포암의 경우 구 조학 및 형태학상의 이유로 병리조직학 영상은 매우 다양한 패 턴을 가지고 있으며, 특히 암 조직 뿐 아니라 정상 조직 내에서 도 다양한 변형된 형태를 가지고 있어 공통된 특징을 추출하는 것이 쉽지 않다. 기존에는 이를 위해 이산 코사인 변환 (Discrete Cosine Transformation)이나 웨이블렛 변환 (Wavelet Transform), 가버 필터(Gabor Filter) 등의 고정
그림 14. 뇌영상 정합을 위한 다층ISA의 구조[2]
적인 특징 추출 방법을 사용해 왔으나, 이는 패턴에 따른 성능 의 편차가 심해 다양한 패턴을 가진 기저세포암 판별에 부적합 한 특성을 가진다. 이를 극복하기 위해 해당 논문에서는 오토 인코더(Auto-Encoder)를 이용한 비지도 학습과 콘볼루션 층 을 이용한 지도 학습을 결합하였는데 (그림 15), 우선 오토 인 코더를 이용하여 병리조직학 영상들로부터 영상 복원 능력이 높은 특징을 학습한다. 이어지는 콘볼루션 층에서는 앞서 오토 인코더를 통해 구해진 가중치 벡터를 필터로 활용하여 다양한 특징 지도를 생성하고, 이를 다시 통합하는 통합층에서는 각 특징지도별로 영역별 반응값을 평균하여 저차원의 최종 특징 값으로 변환한다. 최종적인 분류 단계에서는 앞서 구해진 특징 값을 분류 모델의 입력값으로 활용하고, 암 여부를 출력값으로 활용하여 지도학습으로 분류 모델을 학습 시킨다. 이러한 과정 을 통해 학습된 전체 시스템은 새로운 조직병리학 영상이 주어 지면, 학습된 가중치 벡터로 특징 지도로 변환이 되고, 이를 입 력값으로 하는 학습된 분류 모델에 의해 최종 암 여부가 자동 적으로 결정된다. 실험을 통해 딥러닝을 이용한 피부 기저세포 암 판별 정확도가 기존의 고정적 특징 추출 방법에 비해 통계 적으로 유의하게 높은 것으로 나타났으며, 이를 암조직 시각화 에도 효과적으로 적용할 수 있음을 보였다.
결 론
본 논문에서는 기존의 고정적인 특징 추출을 통한 의료영상 분석방법의 한계를 극복하는 새로운 딥러닝 기반 모델을 소개 하고, 이를 활용한 의료영상분석 연구의 예시를 살펴보았다.
자연 영상과 달리 의료영상은 해부학적 다양성과 여러 촬영 장 비에 따른 변수들로 인해 복잡한 패턴을 가지고 있어, 기존의 전통적인 고정적 특징 추출방법을 통한 분석 성능에 한계가 있 다. 따라서 다층의 구조를 통해 기본적이고 단순한 특징부터 구조적이고 복잡한 특징까지를 계층적으로 추출해낼 수 있는 딥러닝 방법이 효과적인 대안이 될 수 있음이 다양한 연구 사 례를 통해 입증되고 있다. 또한 딥러닝 방법은 이러한 특징을 학습하기 위해서 비용이 높은 전문가의 개입이나 노력이 필요 없는 비지도 학습 방법을 사용하기 때문에, 다양한 장비를 통 해 촬영된 대량의 영상에 비해 전문가에 의해 판별된 영상의 비율이 매우 작은 의료영상분석의 환경에 매우 효율적으로 적 용될 수 있다. 따라서 의료 영상 분석에서 딥러닝을 활용한 연 구가 보다 확산될 것이며, 높아진 분석 정확도와 효율성으로 인해 의료영상분석 분야에 새로운 도약이 찾아 올 것으로 예상 된다.
그림 15. 기저세포암 진단을 위한Deep Convolutional Auto-Encoder [28].
References
1. Liao S., Gao Y., Oto A. and Shen D. Representation Learning:
A Unified Deep Learning Framework for Automatic Prostate MR Segmentation. Lecture Notes in Computer Science 2013;8150:254-261
2. Wu G., Kim M., Wang Q., Gao Y., Liao S., and Shen D.
Unsupervised Deep Feature Learning for Deformable Image Registration of MR Brains. Lecture Notes in Computer Science 2013;8150:649-656
3. Meyer-Base A., and Schmid V. J. Pattern Recognition and Signal Analysis in Medical Imaging. Elsevier 2014
4. Dandan M. A survey on deep learning: one small step toward AI. 2012
5. Krizhevsky A., Sutskever I., and Hinton G. E. ImageNet Classification with Deep Convolutional Neural Networks.
Advances in Neural Information Processing Systems 2012;25:1106-1114
6. Goodfellow I. J., Bulatov Y., Ibraz J., Arnoud S., and Shet V.
Multi-digit Number Recognition from Street View Imagery us- ing Deep Convolutional Neural Networks. 2014;
arXiv:1312.6082
7. McCulloch W. S., Pitss W. A Local Calculus of Idean Immanent in Nervous Activitiy. Bulletin of Mathmatical Biophysics 1943;5(4):115-133
8. Hebb, D. O. The Organization of Behavior. New York: Wiley 1949
9. Rosenblatt, F. The Perceptron: A Probalistic Model For Information Storage And Organization In The Brain.
Psychological Review 1958;65(6):386-408
10. Werbos, P. J. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. thesis 1974;
Havard University
11. Rumelhart, D. E. and McClelland J. L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition.
Cambridge: MIT Press 1986
12. Hinton, G. E. and Salakhutdinov R. R. Reducing the dimen- sionality of data with neural networks. Science 2006;313(5786):504-507
13. LeCun Y., Boser B., Denker J. S., Henderson D., Howard R.
E., Hubbard W. and Jackel L. D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation 1989; 1(4):541?551
14. Cortes C., and Vapnik V. Support-vector Networks. Machine Learning 1995;20(3):273-297
15. Lauer F. and Bloch G. Incorporating Prior Knowledge in Support Vector Machines for Classification: a Review.
2008;71(7-9):1578-1594
16. Bengio, Y. and LeCun Y. Scaling learning algorithms towards AI. Large-Scale Kernel Machines 2007;34:1-41
17. Szegedy C., Liu W., Jia Y., Sermanet P., Reed S., Anguelov D., Erhan D., Vanhoucke V. and Rabinovich A. Going Deeper with Convolutions. 2014;arXiv:1409.4842
18. http://deeplearning.net/tutorial/lenet.html
19. Glorot X., Bordes A. and Bengio Y. Deep Sparse Rectifier Neural Networks. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics 2011;
15:315-323
20. Nair V. and Hinton G. E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of ICML 2010;807-814
21. Hormik K., Stinchcombe M. and White H. Multilayer Feedforward Networks Are Universal Approximators. Neural Networks 1989;2(5):359-366
22. Bishop C. M. Neual Networks for Pattern Recognition. Oxford University Press 1995
23. Hinton G. E., Srivastava N., Krizhevsky A., Sutskever I. and Salakhutdinov R. R. Improving Neural Networks by Prevent- ing Co-adaptation of Feature Detectors. 2012;arXiv:1207.0580 24. Baldi P. and Sadowski P. J. Understanding Dropout. Advances
in Neural Information Processing Systems 2013;26:2814-2822 25. Kim M., Wu G. and Shen D. Unsupervised Deep Learning for
Hippocampus Segmentation in 7.0 Tesla MR Images. Lecture Notes in Computer Science 2013;8184:1-8
26. Le Q. V., Zou W. Y., Yeung S. Y. and Ng A. Y. Learning Hierarchical Invariant Spatio-temporal Features for Action Recognition with Independent Subspace Analysis. Computer Vision and Pattern Recognition (CVPR) 2011;3361-3368 27. Aljabar P., Heckemann R. A., Hammers A., Hajnal J. V. and
Rueckert D. Multi-atlas Based Segmentation of Brain Images:
Atlas Selection and Its Effect on Accuracy. NeuroImage 2009;46(3):726-738
28. Cruz-Roa A. A., Ovalle J. E. A., Madabhushi A and Osorio F.
A. G. A Deep Learning Architecture for Image Representation, Visual Interpretability and Automated Basal-Cell Carcinoma Cancer Detection. Lecture Notes in Computer Science 2013;8150:403-410
대한의학영상정보학회지 2014;20:1-12
=초 록=
의료영상으로부터 효과적으로 생체정보를 추출하거나, 이를 정교하게 시각화하여 진단 등에 활용하기 위해서 는, 의료영상이 표현하는 특징을 효과적으로 추출해 내는 것이 필수적이다. 하지만 대부분의 의료영상분석 방법 들은 컴퓨터 비전분야에서 널리 쓰여 온 고정적인 특징 추출 방법이나, 각 영상에 특화된 특징을 추출하는 방법 을 사용하고 있으며, 이로 인해 영상 분석의 성능 편차가 크거나, 분석의 성능이 떨어지는 문제를 가지고 있다.
따라서 다양한 장비에서 생산되는 수많은 의료영상들에서 분석의 목적에 가장 부합하는 특징을 스스로 학습하는 특징 학습 방법의 중요성이 부각되고 있다. 최근, 딥러닝(Deep Learning)이라 불리는 깊은 구조의 인공신경망 을 통해 주어진 다량의 데이터로부터 특징을 계층적으로 학습하는 방법이 그 주목받고 있다. 특히, 이 방법은 전 문가의 개입을 통한 부가적 정보 없이, 다량의 영상으로부터 직접 이를 표현하는 특징을 학습하고, 소량의 전문 가 판별 정보로 식별력을 최대화 하는 방법이다. 이 기법은 정확도와 효율성 측면에서도 기존 방법들에 비해 우 수함이 다수의 연구사례를 통해 입증되고 있다. 본 논문에서는 깊은 구조를 가진 인공신경망을 통해 주어진 학습 영상 데이터로부터 복잡하고 다양한 수준의 특징을 학습하는 딥러닝 기반 특징 학습 방법론들을 소개하고, 이를 활용한 최신 연구 동향을 제시하고자 한다.

![그림 8. 희소 연결성(Sparse Connectivity)과 공유 가중치(Shared Weights) [18]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5501741.675410/5.892.103.773.404.643/그림-희소-연결성-sparse-connectivity-가중치-shared-weights.webp)
![그림 13. Independent Subspace Analysis 네트워크 구조 [1]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5501741.675410/8.892.180.699.852.1093/그림-independent-subspace-analysis-네트워크-구조.webp)
![그림 14. 뇌영상 정합을 위한 다층 ISA의 구조 [2]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5501741.675410/9.892.222.637.109.357/그림-뇌영상-정합을-위한-다층-isa의-구조.webp)
![그림 15. 기저세포암 진단을 위한 Deep Convolutional Auto-Encoder [28].](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5501741.675410/10.892.170.716.111.493/그림-기저세포암-진단을-위한-deep-convolutional-auto-encoder.webp)
