水 工 學 大 韓 土 木 學 會 論 文 集
第28卷 第2B 號·2008年 3月 pp. 237 ~ 248
우리나라의 월강수량과 범지구적 해수면온도의 상관성 분석
Correlation Analysis between Monthly Precipitation in Korea and Global Sea Surface Temperature
오태석*·문영일**
Oh, Tae Suk·Moon, Young-Il
···
Abstract
Precipitation variability in Korea is mainly influenced by climate circulation such as sea surface temperature, not a local con- vection. Therefore, this study investigates relationship between monthly precipitation of 61 station observed by Korea Meteoro- logical Administration and global sea surface temperatures (SSTs). The main components of monthly precipitation in Korea are extracted by a method which consists of the principal analysis combined with the cluster analysis, to examine the correlation between monthly rainfalls and SSTs. The relationships between main components of monthly precipitation and SSTs exists in Pacific Ocean. At the result of Wavelet Transform analysis, The 2-4 year band have a strong wavelet power spectrum and the low frequency. the correlation coefficient between low frequency components of monthly rainfalls and SSTs calculated bigger then cor- relation coefficient between main components and SSTs. Hence, these results propose a prediction possibility of monthly precip- itations using the varition of SSTs.
Keywords : monthly precipitation, sea surface temperature, correlation analysis, cluster analysis, principal analysis, wavelet analysis
···
요 지
우리나라에서 발생하는 강수량의 특성은 지협적인 원인이기 보다는 해수면 온도와 같은 기상 현상에 많은 영향을 받고 있다.
따라서 본 연구에서는 우리나라의 기상청에서 관측하는 61개 강우관측소의 월강수량과 범지구적 해수면 온도와의 상관관계를 분석하였다. 우리나라 강우량과 범지구적 해수면 온도와의 상관성 분석을 위해 군집분석과 주성분 분석을 통해 월강우량의 주 요 성분을 추출하였다. 추출된 월강우량의 주요 성분과 범지구적 해수면 온도와의 상관성 분석을 통해 우리나라의 월강수량은 태평양에서 관측되는 해수면 온도와 통계적으로 유의한 상관관계를 갖는 해수면 온도 구역을 확인할 수 있었다. 또한, 월강수 량의 Wavelet Transform 분석을 통해 2년과 4년 사이의 주기에서 강한 주성분을 갖는 것으로 나타났으며, 월강수량의 저빈도 특성을 확인할 수 있었다. 월강수량의 저빈도 주기 성분과 해수면 온도와의 상관성 분석에서 큰 상관성을 갖는 것으로 나타났 으며, 이를 통해 해수면 온도를 이용한 강우량의 예측 가능성을 제시하였다.
핵심용어 : 월강수량, 해수면 온도, 상관 분석, 군집 분석, 주성분 분석, Wavelet 분석
···
1. 서 론
수문학적 순환과정에서 강수량은 수문해석의 기본적인 요 소라 할 수 있으며, 강수량은 여러 기상학적 요인과 복합적 인 관계를 가지며 다양한 발생형태를 보인다. 특히, 물의 순 환과정에서 해수면온도(Sea Surface Temperature, SST)는 매우 중요한 요소로 인식되고 있으며 최근에 비정상적인 강 우의 발생형태 및 강우량과 저빈도(low frequency) 상관성을 검토하기 위한 일환으로 강우량과 SST와의 공간적·시간적 변동성을 정량화 하고자 하는 노력이 이루어지고 있는 추세 이다.
강수량을 예측하기 위해서 기상인자와 수문사상과의 상관
성에 대해 많은 연구가 이루어지고 있다. 문영일 등(2005)는 전지구적인 SST를 대상으로 국내 주요 강우지점의 계절 강 우량과 SST와의 원격상관관계(tele-connection)를 검토하였으 며 권현한과 문영일(2005)은 Palmer 가뭄지수와 주요기상인 자간의 상관관계를 Wavlelet Transform분석과 교차상관분석 을 통해 저빈도의 상관성을 검토한바 있다. 또한, 유철상 등
(2000)은 한반도 근해의 해수면 온도와 우리나라의 기온 및
강수량과의 상관관계를 표본 교차 상관 함수와 교차 스펙트 럼 기법 등을 통하여 상관성이 있음을 밝혔으며 오태석 등
(2007)은 우리나라의 강수량과 한반도 근해의 수온 및 기온과
통계적으로 유의한 상관관계가 있음을 밝혔다. 또한, Klein과 Bloom(1987), Kiladis과 Diaz(1989), Cayan과 Peterson
*서울시립대학교 공과대학 토목공학과 박사과정 (E-mail : [email protected])
**정회원·교신저자·서울시립대학교토목공학과교수 (E-mail : [email protected])
(1989)은 북미의 저빈도 성향을 연구를 수행하여 해양과 대 기 성분이 많은 영향을 미침을 발견하였으며 Lall과 Mann (1995)은 SSA(Singular Spectrum Analysis)와 MTM(Multi- Taper Method)를 이용하여 Great Salt Lake의 월별 용적변 화에 대한 시계열, 월 강우량, 온도 그리고 대기순환의 관계 를 분석하였다. Moon과 Lall(1996)은 기후변동성과 수문학 적 시스템에 잠재된 동역학적 관계를 이해하기 위하여 미국 의 Great Salt Lake와 남방진동지수(Southern Oscillation
Index, SOI)를 포함한 여러 대기 순환지수를 이용한 저빈도
관계를 연구한 바 있다. Keppenne과 Ghill(1990)도 SSA와
MTM, 그리고 Maximum-Entropy Method를 이용하여 엘니
뇨 사상을 분석하고 예측하기도 하였다. Keppenne과
Ghil(1992)은 SSA를 이용하여 SOI와 연관성이 없는 잡음들
을 제거하고 라니냐 사상을 예측을 수행하였다. 따라서 우리 나라의 강수량은 여러 기상인자들과 공간적·시간적으로 밀 접한 관련을 갖으며 발생하는 것으로 나타났다. 이러한 기상 인자 중의 하나인 해수면 온도와 우리나라의 월강수량 사이 의 상관관계를 밝혀 수자원관리를 위한 기초자료로 활용 할 수 있다.
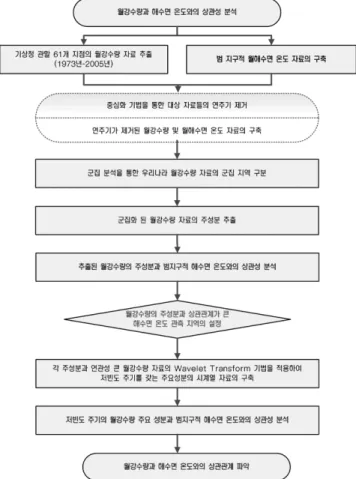
본 연구에서는 우리나라 강우사상과 밀접한 관련이 있는 것으로 알려진 해수면온도(Sea Surface Temperature; SST) 와 우리나라의 월강수량과의 상관관계를 분석하였다. 분석방 법으로는 군집분석과 주성분 분석 및 Wavelet Transform 분석 등을 활용하였으며, 강우자료는 우리나라의 기상청에서 관측하는 일강수량 자료 중에서 관측연수가 30년 이상인 61 개 지점의 자료를 활용하여 범지구적 해수면 온도와의 상관 관계를 분석하였다. 본 연구의 흐름도는 그림 1과 같다.
2. 본 론
우리나라의 월강수량을 중심화한 시계열 자료를 군집분석 과 주성분 분석으로 차원을 축소시킨 anomaly 시계열 자료 를 구축하여 NOAA(National Oceanic & Atmoshperic
Administration)에서 관측하여 제공하고 있는 범지구적 월해
수면 온도와 상관 계수를 산정하였다. 또한, 월강수량 자료 의 anomaly 시계열 자료를 대상으로 Wavelet Transform 기법을 통해 저빈도 주기를 갖는 성분을 추출하여 해수면 온도와 상관관계를 분석하였다.
2.1 대상자료의 선정및연주기성분의 제거
본 연구에서는 그림 2와 같이 기상청에서 관할하고 있는 우리나라의 76개 강우 관측 지점 중에서 30년 이상의 일강 수량 관측 자료가 존재하는 61개 지점을 분석 대상 지점으 로 선정하였다. 선정된 대상 지점의 일강수량 자료를 이용하 여 월강수량을 계산하였으며, 1973년부터 2005년까지의 33 년간의 월강수량 자료를 분석에 활용하였다.
해수면 온도는 NOAA(Satellite and Information Service) 에서 관측한 Extended Reconstructed SST(ERSST)의 자료 중에서 60°S~60°N, 180°W~180°E 범위 내에서 관측된 월 해수면 온도 자료를 이용하였다. Smith 등(2003, 2004)에 따르면, ERSST는 1854년 1월부터의 관측자료를 제시하고 있으나 1880년 이전의 관측자료는 매우 부족하여 전지구적 변동을 거의 반영하지 못한 것으로 알려져 있으며, 최근에는
ERSST의 재구성 자료는 ERSST Version 2가 사용가능하도
록 제공되고 있다. ERSST Version 1에서 재구성한 자료에 비하여 ERSST Version 2는 공간적인 모형을 구성하여 해 수면 온도 관측 자료를 재구성한 것으로 관측 자료의 변동
그림 1. 연구의흐름도 그림 2. 강수관측소
에 취약한 지역의 자료를 실제에 보다 근사하게 향상 시킨 것으로 평가 받고 있다. 그림 3에서 나타낸 ERSST 자료에 서 해수면 온도의 관측 격자는 2o×2o이므로 총 격자의 개 수는 10,980개이며, 이중에서 육지 부분은 2,699개 격자를 제외한 8,281개 지점에서 관측한 1973년부터 2005년까지의 월해수면 온도 자료를 이용하였다.
그림 2와 그림 3에서 나타낸 분석 대상 자료인 월강수량 과 월해수면 온도 자료는 여러 개의 개체(observation unit, 관측 개체)가 있으며, 각 개체로부터 다수의 변수를 측정한 다변량 자료이다. 우리나라의 월강수량과 관측된 해수면 온 도는 그림 4와 그림 5에서 보듯이 뚜렷한 연주기를 가지고 있으므로, 실제로 상관관계가 크지 않더라고 연주기성분에 기인하여 큰 상관관계가 있는 것으로 분석될 수 있다. 따라 서 이와 같은 자료를 해석하기 이전 작업으로써 변수들이 갖고 있는 연주기를 제거할 필요성이 있다. 본 연구에서는 다음 식 (1)과 같은 중심화(centering) 기법을 이용해 월강수 량과 월해수면 온도 자료가 갖는 연주기를 제거하였다.
중심화 : (1)
여기서, xij는 각 관측 개체이며, i는 각 관측 개체의 발 생연도와 j는 관측한 월이다. mj는 관측 자료에서 각월의 평균이다. 연주기를 제거하기 위해서 1973년부터 1997년까 지의 25개년 자료를 이용하여 각 월별로 평균 강수량과 평균 해수면 온도를 산정하였다. 계산된 평균을 관측 개체 에서 빼 주는 중심화 방법을 통해 자료의 연주기를 제거 하였다.
그림 4와 그림 5는 연주기를 제거한 서울 지점의 월강수 량 자료와 우리나라의 남해안 지역에 위치한 동경 128o× 북위 34° 지점에서 관측된 중심화 시킨 월해수면 온도 자료 를 도시한 결과이다. 월강수량 및 월 해수면 온도 자료는 중심화 과정을 통해 연주기가 충분히 제거되었음을 확인할 수 있다. 이상과 같이 우리나라에서 관측된 61개 지점의 월 강수량 자료와 유효한 해수면 온도 관측 자료의 Anomaly 시계열을 구성하였다.
xij→yij(=xij–mj) 그림 3. 해수면온도관측지점의도시
그림 4. 서울지점의월강수량자료의중심화 그림 5. 월해수면온도관측자료의중심화
2.2 군집 분석과 주성분 분석을 이용한 월강수량 자료의 변환
우리나라의 기상청에서 관할하는 30년 이상 관측된 61개 지점의 1973년부터 2005년까지의 중심화된 월강수량 자료를 이용하여 군집분석을 통해 유사성이 높은 지점을 군집화 하 여 주성분 분석을 수행해 80% 이상의 분산을 설명할 수 있는 대표성분을 추출하였다.
군집 분석은 모집단에 소속된 많은 개체들의 특성인자를 통한 분류를 수행하기 위해서 사용되는 다변량 분석 기법이 군집분석(clustering analysis)이다. 군집 분석을 통해 개체를 분류하기 위해서는 Euclidean 거리를 계산(측정)하고 거리가 가까운(유사성이 높은) 개체끼리 묶어야 한다. Euclidean 거 리는 두 개체 사이의 유사 정도를 거리로 표현할 수 있으며 거리가 멀면 유사성이 떨어진다. 군집과 군집(혹은 개체)의 유사성(거리)을 측정하는 방법은 Nearest Neighbor, Furthest Neighbor, Centroid Neighbor, Average Neighbor, Ward's
Minimum Variance등의 기법이 있다. 이 중에서 Nearest
Neighbor 방법은 개체간의 거리가 가까워 개체를 묶는 경향
이 있어 군집의 수가 줄어들고 Furthest Neighbor는 군집간 거리가 최소화 하는 경향이 있어 개체수가 적은 군집을 얻 게 된다(권세혁, 2004). 다음 식 (2)은 r번째 개체와 s번째 개체의 Euclidean 거리를 나타낸다.
(2) 주성분분석은 차원축소를 통하여 저차원상에서 변수의 관 계를 규명하는 다변량 자료 분석기법이라 할 수 있다. 주성 분분석은 다변량기법에서 폭넓게 사용되는 기법중 하나이며 주성분분석은 평균과 분산까지의 통계적 성질을 이용한 2차 통계적 기법이다. 자료를 설명하기 위해 투영시켜 분산이 최 대가 되는 기본벡터를 찾게 되며 이들 가운데 서로 직교하 는 성질을 만족하는 기본벡터를 찾게 되는데 이 때 기본벡 터를 주성분이라고 하며 이 벡터를 자료로 취급해 분석하게
된다. 이는 입력 자료의 가장 중요한 축들을 찾아 효율적으 로 자료의 차원을 줄일 수 있는 장점을 갖게 됨을 의미한다.
주성분분석에 해석과정을 간단히 설명하면 다음과 같다.
다변량 X가 M×m의 행렬이라고 생각해보자(여기서, n은 관측된 자료의 수, m은 변수의 수를 의미한다). 주성분분석 은 X를 n×p차원의 행렬 T와 m×p차원의 행렬 S와 n×m 의 잔차(residual) 행렬로 분해할 수 있는 방법이다.
(3) 여기서, p는 새로 구성된 차원의 수이며, p<m의 크기를 갖 는다. 가장 최적으로 분할하는 조건은 주어진 요소에 대하여 잔차 행렬의 Euclidean 거리를 최소화하는 것이다. 이 기준 을 만족시키려면 S행렬의 행은 y의 공분산 행렬의
Eigenvalue 중에서 큰 순서대로 p만큼 택하여 이에 해당하
는 고유벡터로 구성하면 된다. 여기서, p는 주성분분석에서 나타내는 고유벡터의 개수가 된다. Eigenvalue는 PC로부터 데이터를 다시 복원할 때 해당하는 자료에 대한 가중치의 역할을 하게 된다. 이러한 관점에서 주성분분석은 차원 m을 차원 p로 줄이는 동시에 선형으로 재구성하는 것이므로
가 되고 식 (3)은 다음 식 (4)과 같은 형태가 된다.
(4) 여기서, 벡터 는 행렬 X의 열성분이며 단일 자료의 벡터 이며, 벡터 는 행렬 T혹은 특성 공간 에서 해당하는 열성분을 의미한다. 행렬 는 선형 변환의 계수를 의미한다.
군집분석을 수행하기 위한 기초 자료로는 각 강수관측소에 서 관측된 1973년부터 1997년까지 25개년의 월별 평균 강 수량 자료를 이용하였다. 따라서 하나의 관측소에는 1월의 평균강수량부터 12월의 평균강수량까지 총 12개의 변량을 입력하였다. 자료의 군집화를 위하여, Centroid Neighbor 기 법을 대상 자료에 적용해 군집간의 평균 거리를 산정하는 군집분석을 수행하였다.
군집분석 결과에서 우리나라의 월강수량 자료는 12개 성 drs [(xr–xs)′ x( r–xs)]
1 2---
=
X=TST+E
STS=I T=XS
X
T X
그림 6. 월강수량의군집분석을위한계층적나무다이어그램
분을 이용하여 우리나라 강수 관측소가 갖는 모든 분산을 설명할 수 있는 것으로 나타났으며, 주성분 8개로 99% 이 상의 분산을 설명할 수 있는 것으로 분석 되었다.
다음 그림 6은 각 개체간의 거리를 표현한 계층적 나무 다이어그램으로, 각 지점의 위도, 경도 및 시간강수량 자료 의 평균을 이용하여 개체간의 유사성(Norm Distance, 거리) 을 산정하여 군집화를 수행하였다. 적절한 군집갯수를 산정 하기 위한 Pseudo Hotelling's T2 계수는 두 다변량 정규 분포 집단의 평균을 비교하여 두 군집을 하나로 합칠 수 있 는가를 알아보는 기준이다. 이 값이 크다는 것은 군집간의 거리가 멀다는 것을 의미하게 된다. 따라서 그림 7에서 보 듯이 군집의 개수는 4, 5, 7 내지 11개가 적당한 것으로 분석 되었다.
군집 분석 결과는 Pseudo Hotelling's T2계수의 결과에 따 라 군집을 4, 5, 7, 11개로 구성하여 그 결과를 비교하여 보았다. 비교 분석 결과는 울릉도(115번 지점), 대관령(100번 지점), 성산포(265번 지점) 등에서 관측 자료의 유사성 거리 가 다른 자료들과 많이 멀기 때문에 이 한 지점씩이 하나씩 의 군집을 차지하고 나머지 지점들이 모여 하나의 군집을 설정하는 것으로 나타났다. 그러므로 군집의 개수가 적은 것
보다는 많은 것이 향후 분석에 보다 나은 분석을 수행할 수 있을 것으로 판단 되었으며, 군집 개수를 결정하기 위해 산 정한 통계치에서도 군집 개수가 11개일 때가 가장 나은 결 과를 보여주고 있다. 따라서 군집분석을 통한 우리나라 월강 우자료의 지역구분은 11개의 군집으로 구분하였다. 다음 표 1과 그림 8은 우리나라 강우관측소를 대상으로 군집분석을 수행하여 지역을 구분한 결과이다.
군집 분석 결과에서 우리나라의 월강수량 특성을 살펴보면 50% 이상인 33개 지점이 군집 2번에 포함된 것을 바탕으로 많은 지역의 월강우 특성이 비슷한 것으로 사료 되며, 군집 2번에 포함된 지점을 살펴보면 주로 경기도와 강원도 서부, 충청도 및 전라북도 지역에 분포하는 지점들이 많은 것으로 나타났다. 군집 1은 영남 지역의 강우 관측소 지점들이 주 로 포함되었으며, 군집 4는 남해안 지역의 강우 관측소가 많이 포함되었다. 나머지 군집은 포함된 강우 관측소의 개수 그림 7. Pseudo Hotelling's
표 1. 군집분석에따른강우자료의지역구분결과
군집 번호 군집에 포함된 강우 관측 지점 비고
1 대구, 영천, 구미, 의성, 포항, 영덕, 목포 7개 지점
2 원주, 이천, 춘천, 홍천, 천안, 보령, 대전, 부여, 제천, 양평, 광주, 임실, 청주, 보은, 영주, 합천, 군산,
부안, 금산, 남원, 수원, 충주, 전주, 거창, 서산, 서울, 추풍령, 문경, 인천, 정읍, 밀양, 강화, 인제 33개 지점
3 거제, 남해 2개 지점
4 여수, 고흥, 진주, 장흥, 통영, 완도, 울산, 해남, 부산 9개 지점
5 순천, 산청 2개 지점
6 속초, 강릉, 제주 3개 지점
7 서귀포 1개 지점
8 울진 1개 지점
9 성산포 1개 지점
10 대관령 1개 지점
11 을릉도 1개 지점
그림 8. 군집분석에따른강우관측소의구분
가 적어 지역적 특색을 파악하기는 다소 어려운 것으로 사 료 된다. 월강수량 자료를 이용한 군집분석 결과는 우리나라 의 남해안과 동해안 및 영남 일부지역을 제외하고는 거의 비슷한 월강우특성을 보인다. 이는 국토면적이 작고 반도국 가인 우리나라의 강우특성이 비슷한 경향을 보이는 것으로 판단 할 수 있다. 또한, 동해안 및 영남 지역은 산맥에 의 해 2번 군집과 구분된 지역에 위치하며, 강우관측소의 고도 등과 같은 지리적 위치도 어느 정도 영향을 미치고 있을 것 으로 추론된다. 군집 분석을 통해 설정된 군집 1부터 11 중 에서 강우 관측소가 2개 이상 포함된 군집 1, 2, 3, 4, 5, 6을 대상으로 주성분 분석을 수행하였다. 주성분 분석은 주 성분 변수 간에는 서로 상관관계가 전혀 존재하지 않으며, 첫 번째 주성분은 데이터의 변동(분산, 정보)을 가장 많이 설명하고 계속 구해지는 2, 3, …번째 주성분은 자료의 나머 지 정보들을 설명하고 크기는 점점 줄어든다. 따라서 금회 분석에서 추출된 주성분이 순서대로 전체 자료의 분산을 80% 이상 설명할 수 있는 주성분 까지만 추출하여 분석에 적용하였다.
군집분석 결과에서 입력자료로써 월강수량 자료만을 활용 하였기 때문에, 산정된 군집의 지리적 위치가 균일한 결과를 보여주지는 못하고 있다. 그러나 본 연구에서 살펴보고자 하 는 월강수량과 해수면 온도 사이의 상관성 분석을 위해서는 월강수량 자료만을 활용하는 것이 월강우특성이 유사한 지 점별로 군집을 형성하므로 각 군집의 주성분이 우리나라의 월강우특성을 보다 더 잘 반영할 수 있다.
아래 내용은 군집 2에 포함되는 강우관측소의 주성분을 추 출한 결과이다. 표 2는 군집 2에 포함된 중심화 과정을 통 해 표준화된 월강수량 자료의 평균과 표준편차를 산정한 결 과이다.
표 2에서 각 대상 지점들의 평균은 중심화 과정을 거쳤으 므로 영(zero)으로 산정되어야 하나, 중심화 과정에서는 전 자료기간의 월평균 자료를 이용하지 않고 1973년부터 1997 년까지 25개년 동안의 자료를 이용해 평균을 산정하여 중심 화를 하였으므로 각 지점에서 위의 표와 같이 산정된 평균 값이 영(zero) 이상이며 그 값이 클수록 최근에 내린 강수량 이 많이 증가한 것으로 판단 할 수 있다. 분석 대상 지점들 의 평균과 표준편차를 살펴 본 결과에서 모든 지점에서 최
근의 월강수량이 증가한 것으로 나타났다.
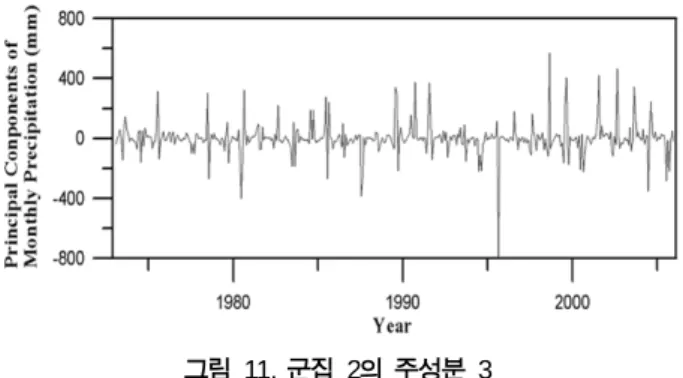
군집 2의 전체 분산은 221,594.7이며, 각 주성분이 설명하 는 분산은 아래의 표 3과 같다. 주성분 분석 결과에서 3개 의 주성분으로 전체 자료가 갖는 분산의 83.3%를 설명할 수 있는 것으로 나타났다. 따라서 군집 2에서는 주성분 3개 를 추출하여 분석에 적용하였다. 추출된 주성분 자료들을
표 2. 군집 2에포함된강우관측소의평균과표준편차
지점 원주 이천 춘천 홍천 천안 인천 보령 대전 인제
평균 2.779 2.104 3.789 5.581 2.994 4.482 1.615 4.839 4.402
표준편차 79.637 88.616 86.822 90.027 84.509 80.914 80.668 82.500 79.800
지점 부여 제천 양평 광주 임실 정읍 청주 보은 문경
평균 3.888 3.287 3.630 4.867 4.135 4.086 3.399 5.795 7.065
표준편차 85.376 88.353 94.898 79.747 77.276 69.698 74.062 83.755 75.688
지점 영주 합천 군산 부안 금산 밀양 남원 수원 추풍령
평균 6.983 5.313 4.681 3.540 3.580 3.689 5.838 3.111 4.362
표준편차 76.966 80.923 75.199 69.032 75.638 77.522 82.898 82.249 68.948
지점 충주 전주 거창 서산 서울 강화
총 33개 지점
평균 4.208 3.529 7.141 5.061 6.805 2.503
표준편차 81.724 73.141 82.331 83.625 100.635 99.634
표 3. 공분산행렬을통해산정된군집 2에포함된주성분들 의고유치
주성분 고유치 고유치 차이 고유치비율 고유치 누적비율
1 147254.8 122078.3 0.665 0.665
2 25176.5 13048.2 0.114 0.778
3 12128.3 6276.1 0.055 0.833
4 5852.2 1235.5 0.026 0.859
32 188.2 12.7 0.001 0.999
33 175.5 0.001 1.000
… … … …
그림 9. 군집 2의주성분 1
그림 10. 군집 2의주성분 2
그림 9에서 그림 11에 도시하였다.
이상과 같은 방법으로 주성분 분석 결과에서 군집 1에서 는 2개의 주성분을 추출하였으며, 군집 2는 3개, 군집 3은 1개, 군집 4는 2개, 군집 5는 1개, 군집 6은 2개로 총 11 개의 주성분 자료를 구성하였다. 또한, 군집 7부터 11까지는 포함된 강우관측소가 1개씩 존재하므로 별도의 주성분 분석 을 수행하지 아니하였다. 따라서 이번 분석에 추출한 11개의 주성분 자료와 5개의 중심화 된 월강수량 자료가 우리나라 의 월강수량 자료를 대표할 수 있는 것으로 나타났다.
2.3 월강수량과범지구적해수면온도와의지체상관계수의 산정
군집 분석과 주성분 분석 과정을 거쳐 우리나라의 월강수 량을 대표할 수 있는 16개의 시계열 자료를 구축하였다. 16 개의 시계열 자료에 대해서 분석의 용이함을 위하여 P011부 터 P111로 표시하였다. 앞의 P는 강우량을 의미하며 앞의 숫자 두자리는 군집 번호이고, 마지막 숫자는 각 군집에서 추출한 주성분의 순서를 의미한다. 단, 군집 7에서 11까지는 주성분 분석을 하지 아니하였으므로 주성분을 나타내는 마 지막 숫자를 “1” 기입하였다.
상관계수 산정을 위해서 1973년부터 2005년까지 33년 동 안의 관측된 월자료를 이용하였으며, 상관 계수는 선형적인 상관관계를 나타낼 수 있는 Pearson 상관계수를 산정하였다.
또한, 해수면 온도 자료에 지체 시간을 영(zero)개월부터 11 개월까지 주면서 상관계수를 산정하여 비교하였다. 산정된 상 관계수는 유의수준 5%에서 t-분포를 이용하여 검정하였다. 이 검정 방법은 산정된 상관계수가 자료의 개수에 따라 어느 정도의 값 이상일 때, 통계적인 유의성이 있음을 나타낸다.
따라서 지체시간을 주지 않은 경우에 1973년부터 2005년까 지는 총 396개의 시계열 자료로 구성되므로 상관계수가
0.098이상일 때는 통계적인 유의성이 있는 것으로 나타났다.
또한, 지체 시간이 11개월일 때는 자료의 개수가 385개이므 로 상관계수가 0.1이상이어야만 통계적 유의성이 있는 것으 로 판단 할 수 있다.
이와 같은 방법으로 우리나라의 월강수량 자료와 범지구 적 해수면 온도와의 상관계수를 산정하였다. 산정된 상관 계수를 바탕으로 우리나라의 월강수량과 해수면 온도 사이 의 합리적인 지체시간과 우리나라 강수량과 상관계수가 큰 해수면 온도 관측 지역을 설정하여야 하므로 다음과 같은 기준을 설정하였다. 첫 번째는 산정된 상관계수의 크기로, 산정 된 상관계수가 적절한 통계적 유의성을 갖는 크기 이상을 확보하여야 한다. 두 번째로 양(+)와 음(−)의 상관
계수가 가장 크게 산정된 지점들이 어느 정도 같은 범위 의 해수면 온도 관측 지점에 포함되어야 한다. 세 번째는 첫 번째와 두 번째의 기준에 의해 선정된 지체 시간을 갖 는 상관계수가 큰 지역의 우리나라 인근에 분포되어 있는 경우를 설정하였다. 위의 세 가지 기준에 의해 우리나라의 강수량과 상관계수가 큰 지역을 설정하여 아래의 표와 같 이 나타내었다.
그림 11. 군집 2의주성분 3
표 4. 양(+)의상관관계가가장큰지체시간과해수면온도관 측지역
Name of Monthly Precipitation
Lag Time (Month)
Regions of Maximum Correlation Coefficient at Observed Sea
Surface Temperature
P011 2 150°E~170°E, 30°N~40°N
P012 5 150°E~170°E, 15°N~25°N
P021 4 160°W~180°W, 35°S~45°S
P022 6 150°W~170°W, 25°S~35°S
P023 2 140°W~160°W, 35°N~45°N
P031 3 170°E~170°W(190°E), 25°S~45°S P041 3 170°E~170°W(190°E), 35°S~50°S
P042 5 90°E~110°E, 10°N~5°S
P051 2 160°E~180°E, 37°S~47°S
P061 2 155°E~175°E, 35°N~45°N
P062 2 150°E~170°E, 45°S~55°S
P071 0 20°W~10°E, 5°N~5°S
P081 2 155°E~175°E, 35°N~45°N
P091 5 140°W~160°W, 50°N~60°N
P101 5 60°E~80°E, 3°N~7°S
P111 4 30°W~60°W, 15°N~25°N
표 5. 음(−)의상관관계가가장큰지체시간과해수면온도관 측지역
Name of Monthly Precipitation
Lag Time (Month)
Regions of Minimum Correlation Coefficient at Observed Sea Surface
Temperature
P011 6 120°W~140°W, 50°S~60°S
P012 6 130°E~140°E, 23°N~33°N
140°W~155°W, 5°S~15°S
P021 4 150°W~170°W, 15°S~25°S
P022 3 120°W~140°W, 45°S~55°S
P023 6 125°W~145°W, 43°S~53°S
P031 3 125°W~145°W, 45°S~55°S
P041 3 125°W~145°W, 45°S~55°S
P042 5 150°E~170°E, 20°N~30°N
P051 3 125°W~145°W, 47°S~57°S
P061 4 75°W~95°W, 30°S~45°S
P062 2 170°E~170°W(190°E), 15°N~30°N
P071 5 30°W~50°W, 35°S~45°S
P081 0 145°W~165°W, 18°N~28°N
P091 1 160°W~180°W, 22°N~32°N
P101 1 10°W~30°W, 40°S~50°S
P111 1 10°W~20°E, 40°S~55°S
위의 표에서 설정한 해수면 온도가 평년보다 증가하거나 감소할 때에 각 군집의 주성분과 연관성이 큰 월강수량 관 측 지역은 월강수량이 증가하거나 감소할 가능성이 매우 크 다고 할 수 있다.
위와 같은 지역으로 설정된 상관계수가 큰 지역을 도시하 였다. 도시 방법은 다음과 같은 두 가지 방법을 이용하였다.
첫 번째는 해수면 온도의 관측 자료가 존재하는 8,281개 중 에서 상관계수가 양(+)의 값을 가지며 가장 큰 400개의 관 측 지점을 추출하였다. 추출된 관측 지점들에서 상관계수가 크기 순서별로 1~5, 6~10, 11~30, 31~50, 51~100, 101~200,
201~300, 310~400 등까지를 도시하여 상관계수가 큰 지역
을 설정하였다. 상관계수가 음(−)의 값을 가지는 경우도 음 의 상관계수가 가장 큰 순서대로 400등까지 추출하여 도시 하였다. 두 번째는 선정된 지체시간에서 모든 지점에서의 상 관계수를 도상에 도시하였다. 이와 같은 도시를 통해 적절한 지체시간과 상관계수가 큰 지역을 설정하였다.
다음 그림은 군집 1의 첫 번째 주성분은 P011과 상관성이 큰 지역을 도시한 결과이다. P011성분과 해수면 온도와의 상 관계수는 해수면 온도를 2개월 지체시켰을 때에 양의 상관계 수가 가장 큰 지역을 선정할 수 있었으며, 6개월 지체 시켰을 때에 음(−)의 상관계수가 가장 큰 것으로 나타났다.
다음 그림은 군집 2의 첫 번째 주성분은 P021과 상관성 이 큰 지역을 도시한 결과이다. P021성분과 해수면 온도와 의 상관계수는 해수면 온도를 4개월 지체시켰을 때에 앞에 서 제시한 3가지 기준에 가장 합리적인 상관계수가 큰 지역 그림 12. 양의상관계수가큰지역(지체2)
그림 13. 지체 2개월에서해수면온도의상관성분석결과
그림 14. 음의상관계수가큰지역(지체6)
그림 15. 지체6개월에서해수면온도의상관성분석결과
그림 16. 양의상관관계지역
그림 17. 음의상관관계지역
그림 18. 상관계수산정결과의도시
을 구분할 수 있었다.
2.4 Wavelet Transform 기법을 이용한 저빈도 상관성 분석
Wavelet Transform의 기저 함수로 사용되는 ψ(t)를 모
Wavelet 함수라고 하며 다음의 식 (5)와 식 (6)의 두 가지
조건을 만족시키면 모 Wavelet 함수가 될 수 있다. 이러한 조건을 만족하는 함수는 조그만 파형의 모양을 가지기 때문 에 Wavelet이라고 한다.
(5)
(6) Wavelet Transform은 식 (7)에서 모 Wavelet을 b만큼 이 동하고 a에 의해 크기를 변화시켜가는 기저 함수를 사용한 다. 이는 고주파로 갈수록 Wavelet은 함수의 폭이 좁아지고, 저주파로 갈수록 함수의 폭이 넓어지는 것을 나타낸다.
Wavelet Transform은 Wavelet 기본 함수들의 중첩으로 임
의의 함수를 표현하는 것인데 이러한 Wavelet 기본 함수들 의 중첩은 각각 다른 스케일 레벨을 가지고 임의의 함수를 만들어 내며, 각 레벨은 그 레벨에 맞는 해상도를 가지게 된다. 연속적인 신호의 Wavelet Transform(continuous Wavelet
Transform, CWT)은 식 (7)과 같이 정의되며 그것의 역 변
환은 식 (8)과 같이 정의 된다. 여기서 X(t)는 원자료를 나 타내며 W(a, b)는 에너지 스펙트럼을 의미한다. ψ*는 ψ의 복소공액을 의미한다.
(7)
(8) 여기서 k는 (0, …, T)의 주파수 지수를 나타내며 ψ(sωk)는 Wavelet Transform의 Fourier Transform을 나타낸다. Wavelet 스펙트럼은 다음 식 (9)의 이산 스케일을 이용하여 계산된다.
(9) 여기서, s0는 추출 가능한 가장 작은 스케일을 나타나며 δj
는 추출간격을 의미하고 모 Wavelet 함수의 특성에 따라 다 른 값을 나타낸다. 일반적으로 많이 사용되는 Morlet 모함수 의 경우 0.6의 값을 갖는다. 표 6은 일반적인 모 Wavelet 함수와 유도된 인자를 나타낸다.
Wavelet Transform 방법은 우리가 알고 있는 모 Wavelet 함수를 통하여 스펙트럼을 추정하기 때문에 원시계열로 다 시 재구성이 가능하다. Wavelet Transform을 통하여 보다 효율적으로 주기 및 시간에 따라 보다 효과적으로 스펙트럼 을 검토할 수 있는 방법이 있다. 즉 주기 및 시간에 따라 각각의 스펙트럼을 평균하는 것이다. 먼저 주기에 대해서 평 균값을 식으로 나타내면 다음과 같다.
(10) 위의 식 (10)을 일반적으로 Global Wavelet Power(GWP)이 라 한다. 이와 함께 식 (11)은 시간에 따른 평균값을 추정 하기 위한 식을 나타내며, Scaled Average Wavelet Power (SAWP)라 한다.
(11) 여기서 Cδ는 재구성 계수를 나타내며 모 Wavelet 함수에 따라 다른 값을 제시하고 있으며 표 6에 나타내었다. δj는 스케일을 평균하기 위한 계수를 의미하며 j1과 j2는 찾고자 하는 스케일, 즉 주기의 범위를 나타낸다.
신뢰구간 추정은 어떤 시간과 스케일에서의 참값을 갖는 Wavelet Power가 추정된 Wavelet Power에 어떤 구간 안에 위치하게 될 확률로서 정의되며 다음 식 (12)로 나타낼 수 있다. 여기서 p는 유의수준을 나타내며 는 χ2에서의 의 값을 나타낸다.
(12) 우리나라에서 관측된 61개 지점의 월강수량 자료를 이용 하여 주성분 분석을 통해 16개의 주성분을 추출하였다. 각각 의 추출된 주성분은 군집 분석을 통해 우리나라 월강수량의 특성이 비슷한 지점끼리 군집화를 수행한 자료로부터 작성 되었다. 따라서 본 분석에서 이용한 61개 지점의 월강수량 중에서 군집 1, 2, 4에 총 49개의 지점에 대한 자료가 포 함되어 있다. 그러므로 본 연구에서는 군집 1, 2, 4에서 주 성분 분석을 통해 산정된 각 지점의 고유벡터값이 각각의 주성분에서 상관성이 가장 큰 지점을 선정하여 Wavelet Transform을 적용하였다.
주성분 P011 성분과 가장 유사한 월강수량 관측 지점은 138(포항) 지점이며, P012 성분과는 165(목포), P021 성분 과는 108(서울), P022 성분과는 285(합천), P023 성분과는 ψ( ) ttd
∞ –
∫
∞ =0ψ( ) t 2dt
∞ –
∫
∞ <∞W a b( , ) X t( )ψa b*,
( ) ttd
∞ –
∫
∞=
X t( ) 1
C---- 1 a 2 ---
∞ –
∫
∞∞ –
∫
∞ W a b( , )ψa b, ( )dadbCt --- wψ( ) ww 2d∞ –
∫
∞≡
=
sj=s02jδj
W t 2( )s 1
T--- Wt( )s 2
n 0= T 1–
∑
=
W i2 δjδt
Cδ
--- Wt( )sj 2 sj ---
j j=1 j2
∑
=
χ2 2(p 2⁄ )
2 χ2
2(p 2⁄ )
--- Wn( )s 2 ωn
2( )s 2 χ2
2(1 p– ⁄2) --- Wn( )s 2
≤ ≤
표 6. 일반적인모 Wavelet 함수와유도된인자
모 Wavelet 함수 함수 형태 τs Cδ γ δj0
Morlet (ω 0=frequency) 0.776 2.32 0.6
Paul (m=order) 1.132 1.17 1.5
DOG (m=derivative) 1.966 1.37 0.97
τs : e-folding 시간, Cδ : 재구성 계수, γ : 시간평균 Decorrelation factor, δj0 : 스케일 평균 계수 π–1 4⁄ eiω0ηeη2⁄2 2s
2mimm!
π(2m)!
--- 1 i( –η)–(m 1+ ) s⁄ 2 1m 1+
– Γ⎝⎛m+12---⎠⎞ ---dm
dηm --- eη
2⁄2
( – )
2s
288(밀양), P041 성분과는 170(완도), P042 성분과는 159 (부산) 지점의 고유벡터값이 가장 크게 산정되었다.
본 연구에서 주성분 자료를 이용하여 Wavelet Transform 을 적용하지 아니한 이유는 추출된 주성분 자료는 우리나라 의 월강수량을 대표할 수 있는 통계적 특성을 가지고 있지 만, 통계적 처리를 통해 자료가 갖고 있는 편차가 어느 정 도 제거된 자료이다. 따라서 Wavelet Transform을 적용하여 자료가 갖고 있는 저빈도 주기 특성을 보다 정확하게 파악 하기 위해서는 원자료를 이용하는 것이 보다 나을 것으로 판단하였기 때문이다. 그러나 앞에서 수행한 연구는 우리나 라의 월강수량에 주성분 분석을 통해 차원을 축소하여 적용 하였으므로 일관성을 유지하기 위해서 각 주성분과 가장 유 사한 지점의 월강수량 자료를 이용하였다. 또한, 모든 지점 의 월강수량 또는 포함된 지점 개수가 적은 주성분을 분석 하지 않은 이유는 Wavelet Transform을 적용하여 저빈도 주기를 갖는 시계열 자료가 군집 1, 2, 4의 자료에 총 49 개 관측소가 포함되므로 월강수량과 해수면 온도 사이의 저 빈도 상관성을 파악하는데 충분하다고 사료되기 때문이다.
따라서 Wavelet Transform을 월강수량의 주성분과 유사한 7개 지점의 1973년부터 2005년까지 중심화로 연주기를 제거 한 월강수량 자료에 적용하여 유의한 저빈도 주기를 갖는
SAWP(Scaled Average Wavelet Power) 성분을 추출하여
범지구적 해수면 온도와의 상관성 분석을 수행하였다.
Wavelet Transform과 같이 시계열을 분석할 때 일반적으
로 유한한 길이의 자료를 대상으로 하며 또한 Fourier
Transform처럼 자료가 일정한 주기를 가지고 있다고 가정하
기 때문에 자료의 처음과 끝의 파워스펙트럼에서 오차가 발 생하게 된다. 이러한 문제를 해결할 수 있는 하나의 방법인 Wavelet Transform을 실시하기 전에 자료의 끝을 영(zero) 으로 대체시키거나, Wavelet Transform 분석 후에 이를 제 거하는 방법이 있으며 또 다른 방법으로 Meyers 등(1993) 은 Cosine Damping 방법을 제시하기도 하였다. 본 논문에 서는 영(zero)으로 자료의 끝은 대체시켰으며 모 Wavelet 함수는 Morlet 함수를 적용하였다.
분석 대상 시계열에 대하여 Morlet 함수를 적용하여 스펙 트럼을 추정하고 원시계열로 재구성을 수행하였다. 재구축된 시계열 자료와 원자료가 갖는 분산은 138(포항)에서 5574.8 과 5772.3으로 이에 대한 비율이 0.97로 거의 같은 통계적 인 특성을 갖고 있다. 165(목포) 지점은 재구축된 시계열 자
료의 분산은 5001.8이며 원자료는 5151.7로 이에 대한 비율 은 0.97이다. 나머지 지점에서도 거의 비슷한 결과를 보였으 며, 108(서울) 지점의 분산에 대한 비율은 0.97, 285(합천) 지점은 0.97, 288(밀양)지점은 0.97, 170(완도) 지점은 0.95, 159(부산) 지점은 0.97의 비율은 갖는 것으로 나타났다. 다 음 그림 19은 부산 지점의 재구성 된 시계열 자료와 원자 료를 도시한 결과이다.
지점들의 월강수량에 대한 원자료의 시계열과 Wavelet
Transform으로 재구축한 시계열을 도시한 결과는 서로 잘
일치하는 것으로 나타났다. 다음 그림 20는 부산 지점에
Wavelet Transform을 적용하여 각 빈도에 대한 스펙트럼을
확인한 결과이다.
Wavelet Transform을 적용하여 각 빈도에 대한 스펙트럼
을 분석한 결과에서 108(서울) 지점에서는 2-4년의 저빈도 주기를 갖는 것으로 나타났으며, 나머지 지점에서는 5년 내 외의 저빈도 주기를 갖는 것으로 나타났다.
각각의 지점에서 저빈도 주기를 갖는 SAWP(Scaled
Average Wavelet Power)를 추출하여 해수면 온도와의 상관
계수 산정을 통한 상관성 분석을 수행하였다. 아래 그림들에 서 보는 바와 같이 저빈도 주기를 추출하여 상관성 분석을 수행한 결과에서 우리나라 강수량의 저빈도 성분들은 해수 면 온도와 원격 상관관계에 있음을 알 수 있었다. 또한, 산 정된 상관계수는 저빈도 주기성분을 추출하지 않고 원자료 의 중심화를 통해 연주기를 제거한 자료를 이용한 것보다 훨씬 더 큰 상관 계수가 산정되었다. 따라서 우리나라 강수 량의 저빈도 주기 성분은 해수면 온도와 밀접한 관련이 있 으며, 이를 통해 우리나라 장기 강수량의 예측 가능성을 확 그림 19. 부산지점의원자료와 Wavelet Transform으로재구
축한시계열
그림 20. 부산지점월강수량의 Wavelet Transform 분석결과
인할 수 있었다.
해수면 온도와 Wavelet Transform을 이용하여 추출한 저빈 도 주기를 갖는 월강수량 자료의 SAWP 시계열 간의 상관계 수를 산정하여 비교하여 보았다. 해석의 일관성을 유지하기 위 하여 앞에서 분석한 지체 상관계수를 산정했을 때와 동일한 지 체시간을 주어 분석을 수행하였다. 산정된 상관계수를 검토한 결과에서 저빈도 주기를 갖는 월강수량의 시계열은 해수면 온 도와 보다 밀접한 상관관계가 있는 것으로 나타났다.
3. 결 론
본 연구에서는 NOAA(National Oceanic & Atmoshperic
Administration)에서 관측하고 있는 범지구적 월해수면온도와
우리나라의 기상청에서 관측하는 30년 이상 관측된 월강수 량과의 상관관계에 대해 분석하였다. 분석 방법으로는 먼저, 중심화 과정을 통해 1973년부터 2005년까지 33년 동안 관 측된 월강수량과 월해수면온도의 연주기 성분을 제거하였다.
연주기 성분을 제거한 월강수량을 군집분석과 주성분 분석 을 통해 월강수량 자료의 차원을 축소하여 범지구적 해수면 온도와 상관계수를 산정하여 우리나라 월강수량과 상관관계 가 큰 해수면 온도 관측 지역을 선정하였다. 마지막으로
Wavelet Transform 기법을 이용해 월해수면 온도 자료의 저
빈도 주기 성분을 추출하여 월해수면 온도와 상관관계를 분 석하였다.
1. 우리나라의 61개 강우관측소에 측정한 월강수량 자료를 군집분석을 통해 11개의 군집을 구성하였으며, 11개의 군 집 중에서 2개 이상의 강우관측소를 포함하고 있는 군집 1부터 6까지에 포함된 월강수량 자료를 대상으로 주성분
그림 21. 포항지점의 SAWP와 2개월지체된해수면온도의
상관성분석
그림 22. 목포지점의 SAWP와 5개월지체된해수면온도의
상관성분석
그림 23. 서울지점의 SAWP와 4개월지체된해수면온도의
상관성분석
그림 24. 합천지점의 SAWP와 6개월지체된해수면온도의
상관성분석
그림 25. 밀양지점의 SAWP와 2개월지체된해수면온도의
상관성분석
그림 26. 완도지점의 SAWP와 3개월지체된해수면온도의
상관성분석
그림 27. 부산지점의 SAWP와 5개월지체된해수면온도의
상관성분석
을 추출하였다. 각 군집의 전체 분산의 80% 이상을 설명 할 수 있는 주성분을 추출한 결과에서 군집 1에서는 2개 의 주성분을 추출하였으며, 군집 2는 3개, 군집 3은 1개, 군집 4는 2개, 군집 5는 1개, 군집 6은 2개로 총 11개 의 주성분 자료를 구성되었으며, 군집분석에서 그룹화되지 않은 군집 7부터 11까지를 고려하였을 때에, 우리나라의 61개 강우관측소의 월강수량 자료를 16개의 주요 성분으 로 대표할 수 있는 것으로 나타났다.
2. 중심화 된 월강수량에서 추출한 16개 주요 성분과 범지 구적 해수면 온도와 11개월까지 지체상관계수를 산정하여 분석하였다. 산정 결과에서 양(+)의 상관관계가 음(−)의 상관관계보다 큰 것으로 나타났으며 대부분 태평양 지역 의 해수면 온도가 다른 지역보다 높은 상관관계를 갖고 있는 것으로 나타났다.
3. 우리나라 월강수량의 16개 주요 성분과 해수면 온도 사 이에서 통계적으로 유의한 상관계수가 산정되었으나 상관 계수의 절대값의 크기가 다소 작게 산정되었다. 따라서 각 각 주요성분 중에서 우리나라 강우관측소 61개 중 41개 를 포함하고 있는 군집 1과 군집 2 및 군집 4의 주성분 과 시계열의 변동이 가장 유사한 7개 지점의 중심화된 월 강수량 자료를 대상으로 Wavelet Transform 변환을 통해 저빈도 주기 성분을 갖는 SAWP를 추출하였다. 추출된 저빈도 주기 성분과 해수면 온도와의 상관성 분석 결과에 서 각 지점별로 지체시간을 갖으며 보다 높은 상관관계를 갖는 것으로 나타났다.
그러므로 이 같은 기상인자를 이용한 우리나라의 장기 강 수량을 예측하는데 보다 많은 연구를 수행한다면, 안정적인 수자원의 확보 및 운영을 위한 기초자료로 충분히 활용 할 수 있을 것으로 예측 되며, 이에 대한 추가적인 연구가 필 요한 것으로 사료 된다.
감사의글
본 연구의 일부는 건설교통부 한국건설교통기술평가원의 이 상기후대비시설기준강화 연구단에 의해 수행되는 2005 건설기 술기반구축사업(05-기반구축-D03-01)에 의해 지원되었습니다.
참고문헌
권세혁 (2004) 다변량분석. 자유아카데미.
권현한, 문영일(2005) Palmer 가뭄지수(PDSI)와 ENSO 지수와 의 상관성 분석. 대한토목학회논문집, 대한토목학회, 제25권, 제5B호, pp. 355-364.
문영일, 권현한, 김동권(2005) 해수면온도와 우리나라 강우량과의 상관성 분석. 한국수자원학회논문집, 한국수자원학회, 제38권, 제12호, pp. 995-1008.
오태석, 안재현, 문영일 권현한(2007) 우리나라 강수량과 한반도 근해의 수온 및 기온의 상관성 분석. 대한토목학회논문집, 대 한토목학회, 제27권, 제2B호, pp. 1-15.
유철상, 정건희, 김중훈(2000) 우리나라 근해 해수면 온도와 기 온 및 강수량과의 상관관계에 관한 연구. 2000년 한국수자 원학회학술발표회논문집, 한국수자원학회, pp. 145-150.
Cayan, D.R. and Peterson, D.H. (1989) The influence of North Pacific atmospheric circulation on streamflow in the west, Aspects of climate variability in the Pacific and Western Amer- icas. American Geophysical Union, Washington, D.C.
Keppenne, C.L. and Ghil, M. (1990) Adaptive spectral analysis of the Southern Oscillation Index. Proceedings of the XVth Annual Climate diagnostics Workshop, U.S. Department of Com- merce, NOAA, Springfield, pp. 30-35.
Keppenne, C.L. and Ghil, M. (1992) Adaptive filtering and predic- tion of the Southern Oscillation index. Journal Geophysical Research, Vol. 97, No. D18, pp. 20449-20454.
Kiladis, G.N. and Diaz, H.F. (1989) Global climatic anomalies asso- ciated with extremes in the Southern Oscillation. Journal of Climate, Vol. 2, pp. 1069-1090.
Klein, W.H. and Bloom, H.J. (1987) Specification of monthly pre- cipitation over the United States from the surrounding 700 mb height field. Month Weather Review, Vol. 115, pp. 2118-2132.
Lall, U. and Mann, M.E. (1995) The great salt lake: a barometer of low frequency climatic variability. Water Resources Research, Vol. 31, No. 10, pp. 2503-2516.
Meyers, S.D., Kelly, B.G., and O'Brien, J.J. (1993) An introduction to wavelet analysis in oceanography and meteorology: With application to the dispersion of Yanai waves. Month Weather Review, Vol 121, pp. 2858-2866.
Moon, Y.I. and Lall, U. (1996) Atmospheric flow indices and inter- annual Great Salt Lake variability, Journal of Hydrologic Engi- neering, Vol. 1, No. 2, pp 55-61.
Smith, T.M. and Reynolds, R.W. (2003) Extended reconstruction of global sea surface temperatures based on COADS Data (1854- 1997). Journal of Climate, Vol. 16, pp. 1495-1510.
Smith, T.M. and Reynolds, R.W. (2004) Improved Extended Recon- struction of SST (1854-1997). Journal of Climate, Vol. 17, pp.
2466-2477.
(접수일: 2007.11.13/심사일: 2008.1.5/심사완료일: 2008.2.18)