증강현실 기술을 통한 건설 현장에서의
공정 정보 활용도 제고 방안
Augmented Reality Framework for Efficient Access to
Schedule Information on Construction Sites
DOI: https://doi.org/10.13161/kibim.2020.10.4.060
이용주
1), 김진영
2), Pham, Hung
3), 박만우
4)Lee, Yong-Ju
1)· Kim, Jin-Young
2)· Pham, Hung
3)· Park, Man-Woo
4)Received November 10, 2020; Received November 19, 2020 / Accepted November 20, 2020
ABSTRACT: Allowing on-site workers to access information of the construction process can enable task control, data integration, material and resource control. However, in the current practice of the construction industry, the existing methods and scope is quite limited, leading to inefficient management during the construction process. In this research, by adopting cutting edge technologies such as Augmented Reality(AR), digital twins, deep learning and computer vision with wearable AR devices, the authors proposed an AR visualization framework made of virtual components to help on-site workers to obtain information of the construction process with ease of use. Also, this paper investigates wearable AR devices and object detection algorithms, which are critical factors in the proposed framework, to test their suitability.
KEYWORDS: Digital twin, Augmented reality, Computer vision, Deep learning, Wearable device, Schedule 키 워 드: 디지털 트윈, 증강현실, 컴퓨터 비전, 딥러닝, 웨어러블 디바이스, 시공 공정 정보
1. 서 론
1.1 연구의 배경
현재 우리는 3차 산업 혁명인 정보화 시대를 지나 4차 산업 혁 명의 시대로 진입하고 있다. 이에 따라 타 산업은 물론 건설 산 업에도 패러다임의 변화가 진행 중이다. 기존의 아날로그적 건 설 기술들은 디지털 기반 기술로 융합 또는 전환되고 있다. 건 설 산업과 융합할 수 있는 대표적인 4차 산업 혁명 기술로는 드 론, BIM(Building Information Modeling), VR(Virtual Reality), AR(Augmented Reality), IoT(Internet of Things), 빅데이터/인공 지능 등이 있다. 이러한 기반 기술들의 발달로 인해 스마트 건설 기술 시장 또한 빠르게 성장하고 있다. 주요 발주국가들은 각종 사회기반시설부터 시작하여 BIM을 의무화하고 있으며 미국, 영 국, 일본 등의 주요 선진국들에서는 건설 현장에 적용될 수 있는 첨단 기술들에 대한 투자가 활발하게 이루어지고 있다. 4차 산업 의 주요 기술 중 하나인 디지털 트윈(Digital twin)은 제품에 대한 통합 데이터 모델인 동시에 시뮬레이션이다(Tao et al., 2018). 실 시간 데이터 수집을 통해 건설 자원들을 모니터링함으로써 공정 효율을 개선하도록 설계된 디지털화 기술로, 시뮬레이션을 통한 예측 유지 관리가 가능하고 정보에 입각한 의사 결정을 내릴 수 있도록 도와줄 수 있다(Khajavi et al., 2019). 특히 규모가 크고 다양한 데이터가 생성되는 건설 분야에서는 준공부터 유지관리 까지의 모든 생애주기에 걸쳐 디지털 트윈을 이용한 연계관리의 실현으로 공정 개선과 의사 결정에 있어서 그 효과를 극대화시킬 1)학생회원, 명지대학교 토목환경공학과 ([email protected]) 2)학생회원, 명지대학교 토목환경공학과 ([email protected]) 3)학생회원, 명지대학교 토목환경공학과 ([email protected]) 4)정회원, 명지대학교 토목환경공학과 ([email protected]) (교신저자)수 있을 것으로 예상된다. 본 연구에서는 스마트 건설 플랫폼 기 반 건설 현장 작업자용 AR 장치 개발에 앞서 해당 기술의 전체적 인 프레임워크를 제시하고, 이에 필요한 상용 장비들과 기술들의 연구 개발에 대한 적합성을 확인해보고자 한다.
1.2 연구의 목적 및 범위
본 연구는 국토교통과학기술진흥원의 스마트 건설 기술 개발 사업 중 “스마트 건설 디지털 트윈 플랫폼 및 디지털 트윈 기반 관리 기술 개발” 연구의 일부이다. 스마트 건설 기술 개발 사업은 스마트 건설 디지털 플랫폼 및 디지털 트윈 기반 관리 기술을 개발하여 건설 전단계에 걸쳐 생 성되는 정보를 디지털화하여 건설 생산성과 안전성을 향상시키는 것이 목표이다. 하지만 기존의 선행 연구들과 상용 솔루션들은 대 부분 프로젝트 관리 및 의사 결정 등의 프로젝트 관리 목적에 적 합하게 발전되어 왔기 때문에 현장 작업자가 사용하기에는 부족 한 부분들이 존재하고, 현장 작업자의 정보 활용 목적으로 개발된 솔루션들도 제공되는 정보의 범위에 한계가 있다. 따라서, 건설 현장에서 현장 작업자의 공정 정보 활용도 제고를 위해 디지털 트 윈 모델 기반의 AR 시각화 기술을 개발하고자 한다. 이를 위해서 건설 현장의 구조물 및 자원(인력, 장비, 자재 등)에 대한 센싱 데 이터를 활용할 것이며 웨어러블 AR 기기와 사용자의 상호작용을 통해 디지털 트윈의 다양한 정보를 기반으로 사용자가 열람하고 자 하는 정보를 시각화할 수 있는 방법을 개발하고자 한다. 이에 앞서, 기존 관련 연구들과 상용 솔루션들을 확인할 필요가 있다. 따라서, 본 연구에서는 디지털 트윈 플랫폼의 AR 시각화에 대 한 기존 연구들과 상용 솔루션들을 비교하여 본 연구 목적에 적합 한 디지털 트윈 플랫폼 기반 AR 시각화 기술의 프레임워크를 제 시한다. 또한, 해당 과정에서 핵심이 되는 건설 현장의 구조물 및 자원에 대한 센싱 방법들을 소개하고, 이를 비교하여 본 연구에 가장 적합한 센싱 방법을 확인한다.2. 기존 연구
AR 기술은 VR 기술의 변형된 형태이다. VR은 사용자에게 가 상의 환경을 제공하는 기술로써, VR 영역 내의 모든 것은 가상의 정보로 대체 되기 때문에 그 안에서 사용자는 현실 세계를 보거 나, 상호작용할 수 없다. 반면, AR은 이러한 가상 환경의 일부만 을 현실 세계에 투영하여 제공하기 때문에 사용자는 현실 세계, 가상 세계 모두와 상호작용 할 수 있다(Azuma, 1997). 가상과 현 실 세계를 혼합할 수 있는 특징 덕분에 다양한 분야에서 해당 기 술의 활용 가치를 탐색하고 있다. 건설 분야의 AR 기술 활용에 대한 연구는 2000년대 초반부터진행되어 왔다(Dunston and Wang, 2005). 그 당시부터 AR 기 술을 통해 사용자들이 상황 인식과 정보 탐색 및 열람 등의 혜택 을 누릴 수 있을 것으로 기대해왔다(Azuma et al., 1999). Robert 는 2002년에 AR을 통해 지하 구조물의 사진을 확인할 수 있 는 시스템을 개발했다(Robert et al., 2002). 근래에 들어 컴퓨터 의 프로세싱 능력이 향상되고, VR/AR 관련 상용 제품들이 시중 에 보급되면서 이를 활용한 연구들이 다시 활발하게 진행되고 있 다(Hanna et al., 2018). 특히, 스마트폰의 보급으로 인한 모바일 AR 분야뿐만 아니라 웨어러블 AR 기기들의 등장으로 일선 작업 현장에서의 다양한 활용 방법들이 제시되고 있다(Chatzopoulos et al., 2017). 다만, 대부분의 연구가 현장 작업자의 정보 활용도 보다는 재해 관리, 안전 관리, 의사 결정 등 관리자 위주의 프로 젝트 관리 목적에 초점을 두고 있다(Li et al., 2018). 이 기술들을 뒷받침할 수 있는 하드웨어들 또한 시중에 나 와 있다. 2010년, 스마트폰이 대중에게 보급되기 시작하면서 스 마트폰(혹은 태블릿)을 기반으로 한 AR 서비스들이 Figure 1의 (a), (b), (c)와 같은 형태로 제공되기도 했다. 그러나, 이러한 형 태의 솔루션들은 사용자가 하드웨어를 손에 쥔 상태에서만 구동 이 가능한 핸드헬드 방식이기 때문에 건설 현장 작업자가 사용 하기에는 다소 불편함이 있는 것이 사실이다. 2013년, Google의 Google Glass가 출시되면서 웨어러블 기기를 통해 사용자에게 AR 컨텐츠를 제공하는 것이 용이해졌다. 2016년에는 Microsoft 의 Hololens(이하 홀로렌즈)가 출시되면서 홀로그래픽 AR 컨텐 츠를 제공할 수 있게 되었고, 이를 통해 웨어러블 AR을 통한 3D 모델의 접근성이 향상되었다. 이를 통해 Figure 1의 (d)처럼 웨어 러블 AR 기기를 통해 3D 모델을 확인하고, 장비를 착용한 사용 자끼리 해당 경험을 공유하는 것이 가능해졌다. 하지만, 대부분 의 소프트웨어가 3D 모델을 확인하는 정도에 그쳤으며, 의사 결 정 및 프로젝트 관리의 목적으로 개발되어 현장 작업자가 사용하 기에는 적합하지 않다. 건설 현장 작업자 사용 목적으로 설계된 Trimble의 XR10은 홀로렌즈가 안전모와 결합된 형태로 제공되는
Figure 1. Examples of commercial AR solutions(ART+COM
하드웨어/소프트웨어 솔루션이다(Figure 1 (e), Trimble(https:// mixedreality.trimble.com/)). 하지만, 이 또한 구조물의 3D 모델 을 확인하고 의사 결정을 위한 메신저 기능 정도만을 제공하기 때문에 현장 작업자의 공정 정보 접근에 제한이 있다.
디지털 트윈은 비교적 최근에 소개된 개념으로, 그동안 ‘virtual representation’, ‘virtual twin’, ‘cyber twin’ 등으로 표현되기도 했다(Lim et al., 2020). 현재는 ‘Digital twin’이라는 용어로 정립 된 이 개념은 현실의 물리적 사물을 가상의 공간에 투영한 가상 의 모델을 뜻한다. 현실 세계의 물리적 사물의 변화를 가상 세 계의 디지털 트윈에 반영, 디지털 트윈의 변화 또한 물리적 사 물에 반영될 수 있도록 하여 가상 세계를 통해 현실 세계를 시 뮬레이션하고, 분석하고, 관리하기 위한 목적이다(Barricelli et al., 2019). 이러한 디지털 트윈 기술은 주로 제품 생산 분야에 서 연구가 진행되어왔으며 시뮬레이션을 통해 생산물의 생애주 기를 예측하거나, 생산물의 거동 특성 등을 파악하고, 제품 설 계 및 생산 관리 등의 목적으로 사용되었다(Tuegel et al., 2011; Hochhalter et al., 2014; Tao et al., 2018). 이러한 디지털 트윈 기술을 건설 분야에 적용하여 BIM(3D 모델), 스케쥴 정보, 공정 정보, 시뮬레이션 정보 등이 통합된 종합 정보 플랫폼으로 활용 함으로써 다양한 정보에 대한 접근성을 확보하고, 웨어러블 AR 기기를 통해 디지털 트윈에 대한 현장 작업자의 정보 활용도를 제고할 수 있을 것으로 기대한다.
3. 디지털 트윈 기반 AR 시각화 기술
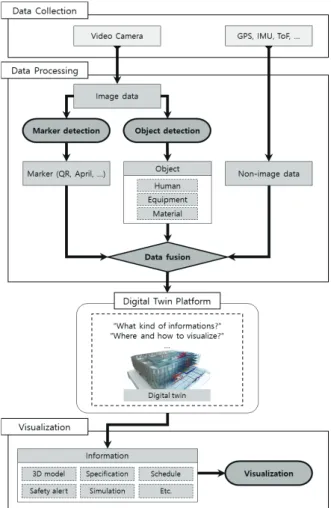
3.1 기술 개요
디지털 트윈 기반 AR 시각화 기술은 현장 작업자의 건설 현 장에서의 디지털 정보에 대한 접근성을 확보하기 위한 기술이다. 기존에는 현장 작업자가 원하는 정보를 건설 현장에서 확인하기 위해서는 도면, 시방서 등의 문서화 된 자료를 직접 가지고 다니 는 수밖에 없었으며 미리 준비된 자료가 없다면 정보에 대한 즉 각적인 접근 자체가 불가능했다. 하지만 스마트 건설 플랫폼이 성공적으로 개발된다면 플랫폼상의 디지털 트윈 모델로부터 건 설 현장의 다양한 정보들을 전자화된 형태로 실시간으로 제공받 을 수 있게 된다. 따라서, 건설 현장 작업자가 어떠한 정보를 열 람하기를 원하는지, 열람하고자 하는 정보의 대상이 무엇인지를 파악할 필요가 있으며 해당 정보를 디지털 트윈 모델로부터 받아 와 이를 건설 현장 작업자가 즉시 열람할 수 있도록 시각화해줄 방법 또한 필요하다. 디지털 트윈 기반 AR 시각화 기술은 Figure 2와 같이 크게 세 가지의 영역으로 나누어 볼 수 있다. 첫 번째는 시각화에 앞서 사용자가 원하는 건설 현장 객체를 탐지하거나 위 치 등을 특정하기 위해 AR 장치의 각종 센서를 통해 데이터를 습 득하는 ‘데이터 수집(Data collection)’ 단계이다. 두 번째는 앞에 서 습득한 데이터들을 후처리 과정을 통해 특별한 정보로 변환하 는 ‘데이터 처리(Data processing)’ 단계이다. 세 번째는 획득한 정보를 스마트 건설 플랫폼과 비교하여 객체를 매칭하고, 사용자 가 원하는 정보를 수신하여 AR 장치에 시각화하는 ‘데이터 시각 화(Visualization)’ 단계이다.3.2 데이터 수집 (Data collection)
본 연구에서 제안하는 기술은 AR 기기 특히 웨어러블 AR 기기 를 통해 이루어진다. 따라서, 건설 현장의 각종 데이터를 수집하 는 과정 또한 웨어러블 AR 기기에서 이루어지는 것이 효율적일 것이다. 다양한 웨어러블 AR 기기들이 존재하지만 모든 제품들은 기본적으로 카메라를 탑재하고 있다. 그렇기 때문에 카메라는 데 이터 획득 단계에서 가장 기본적인 센서로서 역할을 할 수 있다. 그 외에도 필요에 따라 GPS, Wi-Fi, IMU, ToF 센서 등이 사용될 수 있다. 획득한 데이터는 데이터 처리 단계를 통해 정보화 과정 을 거치게 된다. 특히 카메라를 이용해 획득한 데이터는 마커 인 식, 객체 인식 등의 알고리즘을 통해 영상 내의 마커와 사물을 판 별해내어 스마트 건설 플랫폼에서의 정보 검색에 활용된다.Figure 2. AR Visualization Framework of Virtual Component from Digital Twin for On-Site Worker
3.3 데이터 처리 (Data processing)
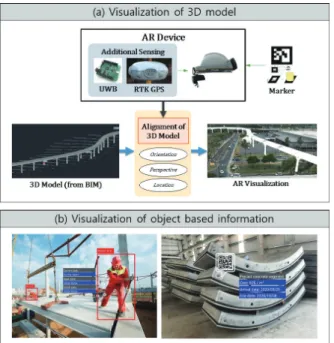
데이터 처리 단계는 웨어러블 AR 기기로 수집한 다양한 데이 터들을 후처리를 통해 유용한 정보로 전환하는 과정이다. 본 연 구에서 제시하고자 하는 방법은 주로 영상 데이터를 이용하는 방 법이기 때문에 수집한 데이터를 비(非)영상 데이터와 영상 데이 터, 두 가지로 구분하여 볼 수 있다. 비영상 데이터는 GPS, IMU 등의 별도의 센서를 통해 획득한 영상 데이터를 제외한 모든 데 이터를 의미한다. 영상 데이터는 특정 마커(Marker)를 인식하거 나 객체 인식 과정을 통해 건설 현장 객체들을 판별하고 위치를 특정하는데 사용할 수 있다. 3.3.1 마커 인식 마커 인식 기술은 영상으로부터 QR코드, April태그 등의 특정 마커를 인식하여 해당 마커가 가지고 있는 정보를 읽어내는 기술 이다. 본 연구에서 제시하고자 하는 방법에서 마커는 건설 자재처 럼 규격이 정해진 건설 현장 객체들을 빠르게 인식하는데 활용되 거나 AR 시각화 단계에서 3D 모델의 정확한 위치를 특정하는 앵 커(Anchor)로 사용된다. 3.3.2 객체 인식 본 연구에서의 객체 인식 기술은 영상 기반 객체 인식 기술을 뜻한다. 데이터 수집 단계에서 획득한 영상 데이터로부터 찾아내 고자 하는 객체의 영상 좌표를 계산하고 해당 객체가 무엇인지를 분류해내는 기술이다. 본 연구에서는 건설 인력, 건설 장비, 건설 자재가 인식 대상이다. 영상 기반 객체 인식 알고리즘은 상당히 다양한 방법들이 있다. 본 연구에서는 최근 관련 연구 분야에서 많이 사용되고 있는 딥러닝 기반의 객체 인식 알고리즘을 적용했 다. 딥러닝 기반의 객체 인식 알고리즘은 기존의 이미지 프로세 싱 방식의 객체 인식 방법들과 비교하여 속도가 빠르면서도 정확 한 편이다. 실시간 객체 인식을 구현하기 위해서는 기존의 이미 지 프로세싱 방식의 객체 인식 방법은 연산 시간의 한계로 적용 이 어렵다고 판단했다. 이에 관한 내용은 뒤에서 더 자세히 설명 하도록 한다. 3.3.3 데이터 융합 영상 데이터의 후처리를 통해 얻어낸 건설 현장 객체에 대한 정보를 비영상 데이터와 혼합하여 디지털 트윈 모델에서의 가상 객체와 매칭을 할 수 있는 형태로 가공하는 과정을 데이터 융합 과정(Data fusion)이라 정의했다. 융합된 정보에는 객체의 판별 정보는 물론, 사용자가 해당 객체에 대해 필요로 하는 정보가 무 엇인지, 사용자가 추가하고자 하는 정보는 무엇인지 등을 포함한 사용자와 디지털 트윈 간의 상호작용에 필요한 모든 정보들이 포 함된다. 예를 들어, Figure 3의 (b)에서처럼 카메라를 통해 특정 건설 인력을 인식했을 때, 해당 인력의 현재 위치를 파악하기 위 해서 사용자의 GPS, IMU 데이터 등이 활용될 수 있다. 다시 말 해, 인터넷 검색 엔진에 비유하자면 사용자가 원하는 정보를 디 지털 트윈 플랫폼이라는 검색 엔진으로 검색하여 가져오기 위한 일종의 검색어를 만들어내는 과정이라고 할 수 있다.3.4 정보 시각화 (Visualization)
데이터 융합을 통해 가공된 사용자 데이터는 디지털 트윈 플랫 폼에 전달되고, 이 정보를 토대로 디지털 트윈 모델에서 해당하 는 정보를 탐색한다. 정보는 공정, 안전, 시뮬레이션에 대한 정보 가 될 수도 있으며 복잡한 3D 모델이 될 수도 있으며 어떠한 형 태로든 사용자에게 시각화될 수 있다. Figure 3의 (a)의 예와 같 이, 사용자가 특정 구조물의 완성된 형태의 3D 모델을 열람하기 를 원한다면 디지털 트윈 모델로부터 이를 불러와 웨어러블 AR 기기를 통해 원하는 위치에 원하는 크기로 시각화할 수 있다. 혹 은 건설 장비와 자재의 규격, 건설 인력의 일반사항, 공정 진행 정보 등의 일반 정보들을 도표, 그래프 등의 일반적인 형태로 시 각화할 수도 있다.4. AR 기기 및 객체 인식 알고리즘 비교
4.1 웨어러블 AR 기기 비교
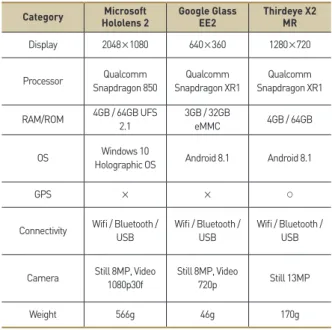
본 기술 개발에 필요한 웨어러블 AR 기기는 건설 현장 작업자 가 착용하기에 무리가 없으며 시각화를 포함한 사용자와의 상호 작용 전반에 큰 불편함이 없어야 한다. 상용 웨어러블 AR 기기 중본 연구 목적에 가장 적합한 기기를 찾기 위해 현재 시판 중인 후 보 기기들을 비교 검토했다. 시중에 나와 있는 웨어러블 AR 기기의 종류가 상당히 많은 편 이긴 하지만 대부분은 엔터테인먼트 목적으로 출시된 제품들이기 때문에 본 연구의 목적에는 적합하지 않다. 본 연구에 맞는 웨어 러블 AR 기기는 소프트웨어 개발을 위한 SDK나 API가 제공될 필 요가 있다. 이러한 목적에 맞는 웨어러블 AR 기기는 총 세 가지로 압축할 수 있었으며 Google의 Glass Enterprise Edition 2(이하 구글 글래스), Microsoft의 Hololens 2(이하 홀로렌즈), Thirdeye 의 X2 MR(이하 X2)이 해당된다. 각기 다른 장단점을 보유하고 있 기 때문에 이에 대한 충분한 이해가 필요하다. 각 기기의 기본 사 양은 Table 1에 나타냈다. 홀로렌즈(https://www.microsoft.com/en-us/hololens)는 디 스플레이 해상도가 다른 기기들보다 높은 편이고, 양안 디스플레 이로 구성되어 있어 홀로그래픽 정보를 표현할 수 있으므로 사용 자에게 더 많은 정보를 정확하게 보여줄 수 있다는 장점이 있다. 또한, 프로세서를 포함한 전체적인 성능이 비교적 뛰어나기 때문 에 소프트웨어 측면에서 조금 더 유연하게 대처하는 것이 가능하 고, 홀로그래픽 컨텐츠 제작과 홀로렌즈 제어에 대한 SDK와 API 들을 다른 어떤 운영체제보다도 월등하게 많이 제공하고 있다. 다 만 크기와 무게로 인해 실제 현장 적용 시 사용자의 불편이 예상 되며 안전모와 함께 착용하는데 제한이 있을 수 있다. 홀로렌즈는 세 가지 장비 중 운영체제로 윈도우즈를 채택한 유일한 장비이므 로 Microsoft에서 제공하는 Azure 등의 클라우드 기반 서비스를 이용하기 위해서는 홀로렌즈를 사용할 수밖에 없다. 구글 글래스(https://www.google.com/glass/start)는 작은 크 기와 가벼운 무게가 장점이다. 이름처럼 안경 정도의 크기와 무게 를 가진 덕분에 착용에 큰 불편함이 없으며 안전모와 함께 착용하 기에도 무리가 없다. 하지만 그만큼 디스플레이, 프로세서를 포함 한 모든 성능이 다른 기기들보다 떨어진다. 특히 저해상도 디스플 레이로 인해 정확한 정보 전달에 어려움이 있을 것으로 예상되며 단안 구성의 디스플레이로 홀로그래픽 정보를 표현할 수 없어서 AR 컨텐츠의 활용에 제한이 있다. X2(https://thirdeyegen.com/x2-smart-glasses)는 모든 면에 서 홀로렌즈와 구글 글래스의 중간에 위치해 있다고 볼 수 있다. 양안 디스플레이를 가지고 있어, 홀로그래픽 정보를 표현할 수 있 으면서도 크기와 무게는 홀로렌즈보다 작은 편이다. 게다가 유일 하게 GPS를 장착하고 있는 기기로, 별도의 외부 기기 없이도 위 치 정보를 이용할 수 있다. 단, 운영체제로 안드로이드만을 지원 하고 제공되는 SDK와 API가 비교적 적은 편이기 때문에 소프트 웨어 개발이 다른 웨어러블 AR 기기들보다 제한적일 수 있다.
4.2 딥러닝 기반의 객체 인식 알고리즘 분석
앞서 3.3.2에서 설명한 객체 인식을 위해서 본 연구에서는 AR 기기에서 획득한 건설 현장의 영상 데이터로부터 객체의 위치 정 보와 해당 객체가 무엇인지를 분류하기 위한 기술로 딥러닝 기반 의 객체 인식 알고리즘을 적용하고자 한다. 더 나아가 디지털 트 윈 모델과 연계하여 사용자에게 Figure 2의 Information과 같이 다양한 정보를 제공할 수 있을 것이다. 딥러닝 기반의 객체 인식 알고리즘에는 객체의 위치를 탐색하 는 Regional proposal network와 객체를 분류하는 Classification network가 서로 독립적으로 진행되는 2-Stage Detection 방식 인 Faster R-CNN 네트워크(Ren et al., 2015)와 동시에 진행되 는 1-Stage detection 방식인 SSD, YOLO 네트워크(Redmon & Farhadi, 2018; Liu et al., 2016)가 있다(Liu et al., 2020).Table 2는 Faster R-CNN, SSD, YOLO 네트워크의 mAP(mean average precision)와 연산 시간 결과표이다. mAP를 알기 위해선 우선 알고리즘의 성능 척도로 사용되는 정밀도(precision)와 재현 율(recall)을 알아야 한다. 정밀도란 Figure 4의 (a)와 같이 Positive 라고 예측한 것(predicted label-positive) 중에서 실제 Positive인 것(true positive)의 비율로, 객체를 얼마나 잘 분류하는지에 대한 알고리즘의 객체 판별력을 보여준다. 재현율은 Figure 4의 (b)와 같 이 실제 Positive인 것(real label-positive) 중에서 Positive라고 예 측한 것(true positive)의 비율로, 객체를 얼마나 잘 찾는지에 대한 알고리즘의 객체 인식력을 보여준다. 정밀도와 재현율은 서로 상충 관계(trade-off)로 알고리즘이 객체를 정확히 판별(정밀도)해도 인 식률(재현율)이 낮거나, 인식률(재현율)이 높아도 객체를 잘못 판별 (정밀도)하면 객체 인식 방법으로 적합하지 않다는 것이다.
Category Hololens 2Microsoft Google Glass EE2 Thirdeye X2 MR
Display 2048×1080 640×360 1280×720
Processor Snapdragon 850Qualcomm Snapdragon XR1Qualcomm Snapdragon XR1Qualcomm RAM/ROM 4GB / 64GB UFS 2.1 3GB / 32GB eMMC 4GB / 64GB
OS Holographic OSWindows 10 Android 8.1 Android 8.1
GPS × × ○
Connectivity Wifi / Bluetooth / USB Wifi / Bluetooth / USB Wifi / Bluetooth / USB Camera Still 8MP, Video 1080p30f Still 8MP, Video 720p Still 13MP
Weight 566g 46g 170g
mAP는 모든 class의 재현율을 0.0~1.0까지 0.1단위로 나눈 후, 각각의 재현율에 따른 정밀도 값을 평균으로 내어 재현율과 정밀도 사이의 성능을 표현한다. 따라서 mAP는 알고리즘이 얼마 나 객체를 잘 인식하고 판별하는지에 대한 성능 지표로 사용된다. 즉, 재현율에 따른 정밀도의 평균값으로 mAP가 높은 알고리즘일 수록 좋은 성능을 가지게 된다. 연산 시간은 네트워크가 사진 한 장당 객체를 인식하는데 걸리 는 시간의 평균값이다. YOLOv3는 다른 네트워크에 비해 mAP 성 능의 차이는 다소 낮지만, Faster R-CNN과 SSD 네트워크와 비 교해 객체 인식을 하기 위한 연산 시간이 매우 짧기 때문에 실시 간으로 객체 인식해야 하는 연구 목적상 YOLOv3를 사용하여 객 체 인식을 해보고자 한다. 4.2.1 YOLOv3 네트워크 구조
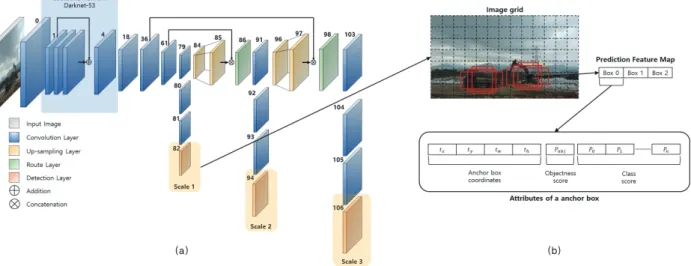
YOLOv3는 Figure 5 (b)의 이미지 그리드(image grid)처럼 사 진을 그리드(grid) 영역으로 나누어 각 영역에 대해 빨간색 사각 형과 같이 사전에 크기가 지정된 경계 사각형 박스(이하 앵커 박 스)를 사용해 그리드의 신뢰도를 예측하는 알고리즘이다.
본 연구에서 사용한 YOLOv3 네트워크는 Figure 5의 (a)와 같 이 Darknet-53을 사용하는 106개의 레이어(layer)를 가진 기본적 인 구조이다. 416×416 크기의 사진이 입력 레이어(input layer)를 통해 입력되고 Darknet-53을 통해 feature map의 크기를 줄여 나간다. 이후 YOLOv3는 Multi-scale prediction으로 크기가 다른 총 3가지의 스케일 레이어(scale layer)에서 분류한다. 분류는 이 미지 그리드에 포함된 셀(cell)에 각각 3개의 앵커 박스를 사용하 여 Figure 5 (b)의 Prediction feature map을 만든다. Prediction feature map에서 앵커 박스의 위치는 시그모이드 함수를 통해 중 심 좌표를 예측하여 객체의 중심 좌표가 언제나 셀에 유지될 수 있게 한다. Objectness score는 시그모이드 함수를 통해 객체 가 앵커 박스에 포함될 확률을 나타낸다. Class score는 객체가 특정 class(굴삭기, 덤프트럭)로 예측될 확률을 나타낸다. 하나의 사진에서 나오는 Prediciton feature map 구성요소는 셀의 개수 (3549개) × 앵커 박스의 개수(3개) × 앵커 박스의 구성요소(7개) 로 74,529개의 출력이 나오게 된다. 이후 객체 탐지를 위해서 구 성요소의 Objectness score와 Class score를 사용하여 인식된 객체 하나당 Bounding box 하나만 위치시키게 된다.
4.2.2 실험 구성
본 연구의 네트워크의 학습 환경에서는 실험 장비로 CPU: Intel Xeon(R) E5-1660 v3, VGA Nvidia Geforce RTX 2080, RAM: 16GB를 사용했으며, 프로그램으로 Python 3.7, Pytorch 1.6.0, CUDA 10.2, OpenCV 4.1.2 버전을 사용했다. 테스트 환경에서는
Performance Faster-RCNN SSD513 YOLOv3-416
mAP(%) 36.2 33.2 31.0
Processing
time(ms) 172 156 29
Table 2. Comparison of detection algorithm (Redmon & Farhadi, 2018)
Figure 4. Precision (a) and Recall (b)
실험 장비로 CPU: Intel core i9 10900k, VGA: Nvidia Geforce RTX 3090, RAM: 32GB를 사용했으며, 프로그램으로 Python 3.8, Pytorch 1.8.0, CUDA 11.1, OpenCV 4.2.0 버전을 사용했다.
본 연구에서 사용한 데이터는 Table 3과 같이 총 3가지이다. 첫 번째로 사용한 데이터는 Figure 6과 같이 현장 시공 영상으로 네트워크 학습에 사용한 데이터이다(이하 데이터 A). 해당 영상 은 해상도 1280×720, 길이 1시간 20분, 프레임 속도 10 fps을 가 지고 있으며, Figure 6과 같이 각 사진 데이터마다 객체를 레이블 링하여 굴삭기 사진 43,924개와 덤프트럭 사진 34,643개로 분류 한다. 이후 Table 3의 데이터 A와 같이 분류된 사진의 20%(굴삭 기 사진 8,784개, 덤프트럭 사진 6,943개)는 네트워크의 오버피팅 상태를 확인할 테스트 세트(testing set)로 활용하고, 나머지 60% 는 학습 세트(training set)로 20%는 네트워크를 검증하기 위한 검증 세트(validation set)로 나눠 오버피팅 현상을 방지한다. 굴 삭기의 객체 경계 박스(이하 레이블링 박스)의 크기는 310×200, 덤프트럭의 레이블링 박스의 크기는 310×145이다. K-means clustering를 통해 앵커 박스의 크기를 48×96, 93×70, 69× 104, 98×78, 111×73, 102×86, 101×104, 123×100, 104×119으 로 결정하였으며, 101×104, 123×100, 104×119의 크기를 가진 앵커 박스는 Scale 1에서 98×78, 111×73, 102×86의 크기를 가 진 앵커 박스는 Scale 2에서 48×96, 93×70, 69×104의 크기를 가진 앵커 박스는 Scale 3에서 사용한다. 두 번째로 사용한 데이터는 Figure 7과 같이 다양한 각도와 형 태로 촬영된 굴삭기, 덤프트럭 사진이다(이하 데이터 B). 총 2,850 개의 사진을 사용하며, 장비 객체는 굴삭기 사진 2,000개, 덤프 트럭 사진 2,700개로 분류한다. 이후 Table 3의 데이터 B와 같이 분류된 사진의 80%(굴삭기 사진 1,600개, 덤프트럭 사진 2,160 개)는 학습 세트로 20%는 검증 세트로 나눠 네트워크의 오버피팅 현상을 방지한다. K-means clustering를 통해 나온 앵커 박스의 크기는 24×32, 51×71, 92×99, 90×188, 158×152, 148×263, 249×224, 226×331, 343×345로 다양한 각도와 형태로 촬영되 었기 때문에 앵커 박스의 크기가 데이터 A보다 다양한 것을 확인 할 수 있다. 세 번째로 사용한 데이터는 데이터 A와 데이터 B로 학습한 네 트워크를 실험하기 위한 영상 데이터로 Figure 8과 같이 현장 시 공 영상이다(이하 데이터 C). 해당 영상은 길이 3분, 해상도 1280 ×720, 프레임 속도 30 fps, 굴삭기의 크기는 400×230, 덤프트 럭의 크기는 375×140이다. 데이터 C는 홀로렌즈 카메라의 해상 도와 프레임 속도가 같기 때문에 YOLOv3가 해당 영상의 해상도 와 프레임 속도에도 빠른 연산 시간이 나온다면, 홀로렌즈에서 실 시간 객체 인식으로 YOLOv3를 활용할 수 있을 것이다. 4.2.3 YOLOv3 네트워크 훈련 네트워크의 초매개변수는 입력 사진 크기 = 416×416, RGB 채 널 = 3개, batch 크기 = 64, learning rate = 0.001, 최대 batch = 8000, 활성 함수 = leaky ReLU, class = 2(굴삭기, 덤프트럭)
Component Excavator Dump Truck
Data A
Training set 28,110 22,160 Validation set 7,030 5,540
Testing set 8,784 6,943
Data B Training set 1,600 2,160
Validation set 400 540
Data C The video for testing network
Table 3. Composition of Data set
Figure 6. Data A (video) and Data labeling example
Figure 7. Examples of Data B
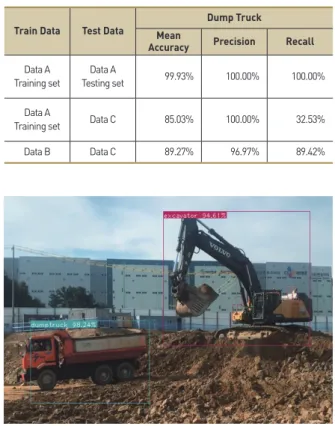
이다. 첫 번째 네트워크 훈련은 데이터 구성의 데이터 A를 사용하 여 학습하고, 두 번째 네트워크 훈련은 데이터 B를 사용하여 학습 한다. 결과는 Figure 9, 10과 같이 데이터 A를 학습한 네트워크는 batch가 2400번일 때 mAP 최대 성능이 100%가 나왔고, 데이터 B를 학습한 네트워크는 batch가 4000번일 때 mAP 최대 성능이 94%가 나왔다 4.2.4 실험 결과 실험 결과는 Table 4, 5과 같이 나왔으며 데이터 A의 학습 세 트로 훈련된 네트워크를 데이터 A의 테스트 세트로 실험 결과 굴 삭기와 덤프트럭의 정밀도와 재현율 모두 100%로 네트워크의 성 능이 높은 것을 볼 수 있다. 하지만 데이터 A의 학습 세트와 테스 트 세트는 같은 영상에서 나눴기 때문에 데이터가 유사하여 네트 워크의 성능을 확신할 수 없다. 때문에, 데이터 C로 네트워크의 성능을 실험하고자 한다. 데이터 A로 훈련된 네트워크를 데이터 C로 실험한 결과 굴삭기와 덤프트럭의 정밀도는 모두 100%로 사진에서 객체를 인식할 때 실제로 해당 class로 판별할 확률이 높은 것을 보여준다. 하지만 굴삭기의 재현율 96.4%, 덤프트럭의 재현율 32.53%로 네트워크가 덤프트럭을 인식할 확률이 매우 떨 어진다. 데이터 A와 데이터 C의 건설 장비의 크기가 1.3~1.4배 차이 나기 때문에 실험할 때 앵커 박스의 크기를 1.5배 키워 데이 터 C의 덤프트럭이 앵커 박스 안에 들어갈 수 있게 초매개변수 를 변경하여 실험을 진행하였지만, 굴삭기의 재현율 99.2%, 덤프 트럭의 재현율 44.4%로 낮은 성능을 보여줬다. 본 연구에서 정 밀도는 재현율보다 더욱 중요한 성능 지표인 것은 사실이지만 너
Figure 11. Sample image of test result
Figure 9. First train loss graph chart
Figure 10. Second train loss graph chart
Train Data Test Data Mean Excavator
Accuracy Precision Recall
Data A Training set
Data A
Testing set 99.55% 100.00% 100.00% Data A
Training set Data C 98.64% 100.00% 100.00%
Data B Data C 87.97% 100.00% 99.80%
Table 4. Test result of Excavator
Train Data Test Data Mean Dump Truck
Accuracy Precision Recall
Data A Training set
Data A
Testing set 99.93% 100.00% 100.00% Data A
Training set Data C 85.03% 100.00% 32.53%
Data B Data C 89.27% 96.97% 89.42%
무 낮은 재현율은 객체 인식을 통해 얻는 데이터의 양 자체를 제 한하기 때문에 일정 수준 이상의 재현율을 확보할 필요가 있다. 재현율 저하의 원인으로 덤프트럭의 학습 데이터와 테스트 데이 터의 차이에서 비롯된 것으로 예상된다. 굴삭기는 구조상 상부가 회전하며 움직이기 때문에 고정된 시각에서도 다양한 형태의 굴 삭기 사진을 확보할 수 있지만 덤프트럭의 경우는 그렇지 못하 다. 따라서, 학습 데이터를 확보할 때 덤프트럭의 다양한 형태가 반영되지 못했고 테스트 데이터의 변화된 덤프트럭의 형태에 대 해 인식률이 떨어진 것으로 예상된다. 따라서, 덤프트럭의 재현 율을 높이기 위해 더 다양한 형태의 건설 장비 사진이 포함된 데 이터 B를학습한 네트워크를 사용한다. YOLOv3 객체 인식 알고리즘을 사용한 결과 이미지 중 하나 를 Figure 11에 표기했다. 데이터 B로 훈련된 네트워크의 실험 역 시 데이터 A의 실험과 동일하게 진행했다. 실험 결과 굴삭기, 덤 프트럭의 정밀도는 각각 100%, 96.97%와 굴삭기, 덤프트럭의 재 현율은 각각 99.80%, 89.42%로 1차 네트워크 학습 결과와 비교 하여 덤프트럭의 정밀도는 3.1%p 낮아지고 재현율은 53.9%p 상 승했다. 정밀도가 낮아지긴 했으나 그에 비해 다소 높은 재현율 의 상승을 확인할 수 있다. 또한, 한 프레임당 연산 시간은 평균 21ms로, 30fps 이하의 영상 데이터에 한해서는 실시간 처리가 가능한 것으로 볼 수 있다.
5. 결론
본 연구의 목적은 건설 현장 작업자의 공정 정보 활용도 제고 를 위한 디지털 트윈과 웨어러블 AR 기기 연계에 대해 전체적인 프레임워크를 제시하고, 이에 필요한 상용 장비들과 기존 기술들 의 적용 가능성을 확인해보는 것이다. 먼저, 스마트 건설 플랫폼 의 디지털 트윈과 현장 작업자가 서로 상호작용을 통해 정보를 활용할 수 있도록 디지털 트윈 기반 AR 시각화 기술의 프레임워 크를 제시했으며 이에 필요한 AR 기기, 특히 웨어러블 AR 기기 들을 비교하여 개발 목적에 적합한 AR 기기들을 확인했다. 또한, 제시한 프레임워크의 데이터 처리 단계에서 중요한 역할을 하 게 될 객체 인식 방법으로 영상 기반의 객체 인식 방법들을 소개 했고, 본 연구의 목적에 가장 적합하다고 판단된 딥러닝 기반의 YOLOv3 네트워크를 사용하여 객체 인식을 수행해봄으로써 사용 가능성을 확인했다. 하지만, 본 연구에서 객체 인식이 가능한 범 위는 건설 장비 2종(굴삭기, 덤프트럭)으로 제한되어 있다. 건설 기계부품 연구원에 따르면 건설 장비로 분류되는 것은 총 27종이 며 건설 장비뿐만 아니라 건설 인력, 자재 등 다양한 객체를 인식 할 수 있어야 하는 만큼 여러 종류의 건설 장비 사진 데이터를 선 별하고 확장시켜 나아갈 필요가 있다. 이를 위해 객체 인식 대상 을 명확하게 설정하여 구분하고 충분한 데이터를 수집 및 네트워 크에 학습하여 다양한 건설 현장 객체를 인식할 수 있는 수준이 된다면 데이터 융합 과정을 통해 디지털 트윈과의 연계에 적합한 형태로 데이터를 가공할 수 있어야 할 것이다.감사의 글
본 연 구 는 국 토 교 통 부 / 국 토 교 통 과 학 기 술 진 흥 원 의 지 원 으 로 수 행 되 었 음 ( 스마 트 건 설 기 술 개 발 사 업 : 과 제 번 호 20SMIP-A157351-01)References
ART+COM STUDIOS (2013). Augmented reality, https://artcom. de/en/?research_focus=augmented-reality (Dec. 28. 2020).Azuma, R. T. (1997). A Survey of Augmented Reality. PRESENCE: Virtual and Augmented Reality, 6(4), pp. 355-385. Azuma, R., Lee, J. W., Jiang, B., Park, J., You, S., Neumann,
U. (1999). Tracking in unprepared environments for augmented reality systems. Computers & Graphics, 23, pp. 787-793. https://doi.org/10.1016/S0097-8493(99)00104-1
Barricelli, B. R., Casiraghi, E., Fogli, D. (2019). A Survey on Digital Twin: Definitions, Characteristics, Applications and Design Implications. IEEE Access, 7, 167653-167671, doi: 10.1109/ACCESS.2019.2953499
Chatzopoulos, D., Bermejo, C., Huang, Z., Hui, P. (2017). Mobile Augmented Reality Survey: From Where We Are to Where We go. IEEE Access, 5, pp. 6917-6950.
Dunston, P. S., Wang, X. (2005). Mixed Reality-Based Visualization Interfaces for Architecture, Engineering, and Construction Industry. Journal of Construction Engineering & Management, 131(12), pp. 1301-1309.
Hanna, M. G., Ahmed, I., Nine, J., Shyam, P., Pantanowitz, L. (2018). Augmented Reality Technology Using Microsoft HoloLens in Anatomic Pathology. Archives of Pathology & Laboratory Medicine, 142, pp. 638-644.
Hochhalter, J. D., Leser, W. P., Newman, J. A., Glaessgen, E. H., Gupta, V. K., Yamakov, V., Cornell, S. R., Willard, S. A., Heber, G. (2014). Coupling Damage-Sensing Particles to the Digitial Twin Concept. NASA Center for AeroSpace Information
Khajavi, S. H., Motlagh, N. H., Jaribion, A., Werner, L. C., Holmstrom, J. (2019). Digital Twin: Vision, Benefits, Boundaries, and Creation for Buildings. IEEE Access 7, 147406–147419. https://doi.org/10.1109/ ACCESS.2019.2946515
Li, X., Yi, W., Chi, H. L., Wang, X., Chan, A. P. C. (2018). A critical review of virtual and augmented reality (VR/ AR) applications in construction safety. Automation in Construction, 86, pp.150-162.
Lim, K. Y. H., Pai, Z., Chen, C. H. (2020). A state-of-the-art s u r v e y o f D i g i t a l T w i n : t e c h n i q u e s , e n g i n e e r i n g product lifecycle management and business innovation perspectives. Journal of Intelligent Manufacturing, 31, pp. 1313-1337. https://doi.org/10.1007/s10845-019-01512-w Liu, L., Ouyang, W., Wang, X., Fieguth, P., Chen, J., Liu, X.,
Pietik inen, M. (2020). Deep learning for generic object detection: A survey. International journal of computer vision, 128(2), pp. 261-318.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., Berg, A. C. (2016). Ssd: Single shot multibox detector. In European conference on computer vision, pp. 21-37. Redmon, J., Farhadi, A. (2018). Yolov3: An incremental
improvement, https://arxiv.org/abs/1804.02767 (Sep. 03. 2020).
Ren, S., He, K., Girshick, R., Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pp. 91-99.
Robert, G. W., Evans, A., Dodson, A. H., Denby, B., Cooper, S., Hollands, R. (2002). The Use of Augmented Reality, GPS and INS for Subsurface Data Visualisation. FIG XXII International Congress, Washington, D.C. USA, April 19-26 2002
Souza, E. (2019). 9 Augmented reality technologies for architecture and construction, https://www.archdaily. com/914501/9-augmented-reality-technologies-for-architecture-and-construction (Dec. 28. 2020).
Tao, F., Cheng, J., Qi, Q., Zhang, M., Zhang, H., Sui, F. (2018). Digital twin-driven product design, manufacturing and service with big data. International Journal of Advanced Manufacturing Technology, 94, pp. 3563-3576. https:// doi.org/10.1007/s00170-017-0233-1
Trimble (2019). Trimble connect for HoloLens, https:// mixedreality.trimble.com (Dec. 28. 2020).
Tuegel, E. J., Ingraffea, A. R., Eason, T. G., Spottswood, S. M. (2011). Reengineering Aircraft Structural Life Prediction Using a Digital Twin. International Journal of Aerospace Engineering, 2011, doi:10.1155/2011/154798