2018, 29
(2)
,327–338
커널 밀도 추정치를 이용한 유한혼합모형의 초기화 방법과 모형기반 군집분석에의 응용 †
ᄌ
ᅩ현주
1
· 정여진2
· 김영민3
1투이컨설팅 ·2국민대학교 데이터사이언스학과 · 3경북대학교 통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2018ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 22ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 3ᄋ ᅯ ᆯ 16ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 3ᄋ ᅯ ᆯ 19ᄋ ᅵ ᆯ
요 약
ᄋ
ᅲᄒ ᅡ ᆫ ᄒ ᅩ ᆫ ᄒ ᅡ ᆸ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ ᄒ ᅪ ᆨᄅ ᅲ ᆯ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅦ ᄀ ᅵᄇ ᅡ ᆫᄒ ᅡ ᆫ ᄀ ᅮ ᆫᄌ ᅵ ᆸᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅢ ᄃ ᅡᄋ ᅣ ᆼᄒ ᅡᄀ ᅦ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄃ ᅬᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. EM ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆫ ᄋ
ᅲᄒ ᅡ ᆫᄒ ᅩ ᆫ ᄒ ᅡ ᆸᄆ ᅩᄒ ᅧ ᆼᄀ ᅪ ᄀ ᅡ ᇀᄋ ᅵ ᄉ ᅮ ᆷ ᄀ ᅧᄌ ᅵ ᆫ ᄀ ᅮᄌ ᅩᄋ ᅴ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅴ ᄎ ᅬᄃ ᅢᄋ ᅮᄃ ᅩᄎ ᅮᄌ ᅥ ᆼᄅ ᅣ ᆼᄋ ᅳ ᆯ ᄀ ᅨᄉ ᅡ ᆫᄒ ᅡᄂ ᅳ ᆫ ᄃ ᅦ ᄂ ᅥ ᆯᄅ ᅵ ᄊ ᅳᄋ ᅵ ᆫᄃ ᅡ. ᄒ ᅡᄌ ᅵᄆ ᅡ ᆫ EM ᄋ
ᅡ
ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆫ ᄎ ᅩᄀ ᅵ ᄀ ᅡ ᆹᄋ ᅦ ᄄ ᅡᄅ ᅡ ᄀ ᅳ ᄉ ᅥ ᆼᄂ ᅳ ᆼ ᄋ ᅵ ᄌ ᅪᄋ ᅮᄃ ᅬᄋ ᅥ ᄋ ᅮᄃ ᅩᄒ ᅡ ᆷᄉ ᅮᄋ ᅴ ᄎ ᅬᄃ ᅢᄀ ᅡ ᆹᄋ ᅵ ᄋ ᅡᄂ ᅵ ᆫ ᄀ ᅩᄌ ᅥ ᆼᄌ ᅥ ᆷᄋ ᅳᄅ ᅩ ᄉ ᅮᄅ ᅧ ᆷᄒ ᅡᄀ ᅥᄂ ᅡ ᄉ ᅮ ᄅ
ᅧ
ᆷ ᄉ ᅩ ᆨ ᄃ ᅩᄀ ᅡ ᄂ ᅳᄅ ᅧᄌ ᅵ ᆯ ᄀ ᅡᄂ ᅳ ᆼᄉ ᅥ ᆼᄋ ᅵ ᄋ ᅵ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄏ ᅥᄂ ᅥ ᆯ ᄆ ᅵ ᆯᄃ ᅩ ᄎ ᅮᄌ ᅥ ᆼᄎ ᅵᄋ ᅴ ᄌ ᅥ ᆼᄌ ᅥ ᆷᄋ ᅴ ᄋ ᅱᄎ ᅵᄅ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄋ ᅲᄒ ᅡ ᆫ ᄒ ᅩ ᆫ ᄒ ᅡ
ᆸᄆ ᅩᄒ ᅧ ᆼᄋ ᅴ ᄆ ᅩᄉ ᅮ ᄎ ᅮᄌ ᅥ ᆼᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅡ ᆫ EM ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆯ ᄎ ᅩᄀ ᅵᄒ ᅪ ᄒ ᅡᄂ ᅳ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡ ᆫᄃ ᅡ. ᄀ ᅵᄌ ᅩ ᆫ ᄋ ᅴ ᄆ ᅮᄌ ᅡ ᆨᄋ ᅱ ᄎ ᅩᄀ ᅵᄒ ᅪᄋ ᅦ ᄀ
ᅵᄇ ᅡ ᆫᄒ ᅡ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄃ ᅳ ᆯ ᄀ ᅪ ᄇ ᅵᄀ ᅭᄒ ᅡᄋ ᅧ ᄆ ᅩᄋ ᅴᄉ ᅵ ᆯᄒ ᅥ ᆷᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅢ ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡᄂ ᅳ ᆫ ᄎ ᅩᄀ ᅵᄒ ᅪ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅵ ᄋ ᅮᄃ ᅩᄒ ᅡ ᆷᄉ ᅮᄋ ᅴ ᄎ ᅬᄃ ᅢᄀ ᅡ ᆹ ᄋ
ᅳ ᆯ ᄎ ᅡ ᆽᄂ ᅳ ᆫ ᄃ ᅦ ᄃ ᅥ ᄋ ᅮᄋ ᅯ ᆯᄒ ᅡ ᆷᄋ ᅳ ᆯ ᄒ ᅪ ᆨ ᄋ ᅵ ᆫᄒ ᅡ ᆫᄃ ᅡ. ᄄ ᅩᄒ ᅡ ᆫ ᄎ ᅮᄌ ᅥ ᆼᄃ ᅬ ᆫ ᄋ ᅲᄒ ᅡ ᆫᄒ ᅪ ᆨᄅ ᅲ ᆯ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄀ ᅵᄇ ᅡ ᆫᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆫ ᄀ ᅮ ᆫᄌ ᅵ ᆸᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄀ ᅵᄋ ᅥ ᆸᄇ ᅮᄃ ᅩ ᄃ ᅦ ᄋ
ᅵᄐ ᅥᄋ ᅦ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄇ ᅩᄃ ᅡ ᄂ ᅡᄋ ᅳ ᆫ ᄀ ᅮ ᆫᄌ ᅵ ᆸ ᄀ ᅧ ᆯᄀ ᅪᄅ ᅳ ᆯ ᄀ ᅡᄌ ᅧᄋ ᅩ ᆷᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧᄌ ᅮ ᆫ ᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄆ ᅩᄒ ᅧ ᆼᄀ ᅵᄇ ᅡ ᆫ ᄀ ᅮ ᆫᄌ ᅵ ᆸᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄋ ᅲᄒ ᅡ ᆫᄒ ᅩ ᆫ ᄒ ᅡ ᆸᄆ ᅩᄒ ᅧ ᆼ, ᄎ ᅩᄀ ᅵᄒ ᅪ, ᄎ ᅬᄃ ᅢᄋ ᅮᄃ ᅩᄎ ᅮᄌ ᅥ ᆼᄅ ᅣ ᆼ, EM ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ.
1. 머리말 구
ᆫ집분석 (cluster analysis)은 범주에 대한 사전 정보가 없는 상태에서관측치들을 상호배타적인 그 루
ᆸ으로 구분하여 유사성이 높은 관측치들을 묶는방법론이다. 군집분석은고객세분화, 시장세분화, 이 ᄉ
ᅡᆼ 탐지 (anomaly detection)시스템, 유전자 분석 등 다양한 분야에서 널리 사용되고 있다 (Jeong, 2015; Woo 등, 2014).
구
ᆫ집분석의 방법 중 유한혼합모형 (finite mixture model)에 기반한 군집분석 (Fraley와 Raftery, 2002)은 모집단의 각 군집이 서로 다른확률분포를 따른다고 가정하고 관측치가 각 군집에 속할 사전 화
ᆨ률 (prior probability)을정의한다. 관측된데이터를사용하여 모형의확률분포의 모수와 사전확률을 ᄎ
ᅮ정한 후 각관측치가 개별 군집에 속할 사후확률 (posteriori probability)을계산하여 가장확률이 높 ᄋ
ᅳ
ᆫ 군집에 할당한다. 이는 확률모형을기초로 하기 때문에 AIC (Akaike, 1974) 또는 BIC (Schwarz, 1978)와 같은객관적인 모형 선택 기준을사용하여 군집 수와 군집 분포의 형태를결정할 수 있다는장 ᄌ
ᅥᆷ이 있다. 또한 데이터의 특성에 따라 각 군집의확률분포를적절히 결정할 수 있다. 상대적으로 수렴 ᄉ
ᅩ
ᆨ도 (convergence speed)는느리지만 (Ikeda, 1997) 여러 분야에서광범위하게 사용되는 k-means 군 지
ᆸ분석을포괄하면서 보다 유연한 성질을지닌다.
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅧ ᆫᄀ ᅮᄌ ᅢᄃ ᅡ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄇ ᅵ(NRF-2016R1C1B1010940)ᄋ ᅦ ᄋ ᅴᄒ ᅡᄋ ᅧ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ.
1
(07228) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄋ ᅧ ᆼᄃ ᅳ ᆼ ᄑ ᅩᄀ ᅮ ᄋ ᅧ ᆼᄉ ᅵ ᆫᄅ ᅩ 220, ᄐ ᅮᄋ ᅵᄏ ᅥ ᆫᄉ ᅥ ᆯᄐ ᅵ ᆼ ᄀ ᅩ ᆼᄀ ᅩ ᆼᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅡᄋ ᅥ ᆸᄇ ᅩ ᆫ ᄇ ᅮ, ᄏ ᅥ ᆫᄉ ᅥ ᆯᄐ ᅥ ᆫᄐ ᅳ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (02707) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥ ᆼᄇ ᅮ ᆨ ᄀ ᅮ ᄌ ᅥ ᆼᄅ ᅳ ᆼ ᄅ ᅩ 77, ᄀ ᅮ ᆨᄆ ᅵ ᆫᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄀ ᅧ ᆼᄋ ᅧ ᆼᄃ ᅢᄒ ᅡ ᆨ, ᄌ ᅩᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
3
(41566) ᄃ ᅢᄀ ᅮ ᄀ ᅪ ᆼᄋ ᅧ ᆨᄉ ᅵ ᄇ ᅮ ᆨ ᄀ ᅮ ᄃ ᅢᄒ ᅡ ᆨᄅ ᅩ 80, ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅡᄋ ᅧ ᆫᄀ ᅪᄒ ᅡ ᆨᄃ ᅢᄒ ᅡ ᆨ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄌ ᅩᄀ ᅭᄉ ᅮ.
호
ᆫ합모형의 최대우도추정량 (maximum likelihood estimator; MLE)은 EM (expectation-maximization;
Dempster 등, 1997) 알고리즘을 통해 계산된다. EM 알고리즘은 조건부 우도함수의 기댓값을계산하 ᄂ
ᅳᆫ E-step과 기댓값을 최대화 시키는 모수를 계산하는 M-step을 수렴 조건이 만족될 때까지 반복한 ᄃ
ᅡ. 이 때 모수의 초기 값 (initial value)은알고리즘의 성능에큰영향을주는 것으로 알려져있다. 특 ᄒ
ᅵ 우도 함수가 두 개 이상의 극댓값 (local maximum)을 가지고 있을 경우, 초기 값에 따라 최댓값 (global maximum)이 아닌극댓값으로 수렴할 수 있다. 또한 Ikeda (1997), Karlis와 Xekalaki (2003), Baudry와 Celeux (2015) 등다수의 연구에서는초기 값 선택에 따라 알고리즘수렴 속도가 느려질 수 이
ᆻ음을 나타냈고 Biernacki 등 (2003)의 연구에서는 EM알고리즘이 특히 다변량 (multivariate)에서 ᄎ
ᅩ기 값에 매우 의존함을보였다.
ᄇ
ᅩᆫ 논문에서는커널 밀도 추정치 곡선의 정점 (peak)의 위치를 EM알고리즘의 초기 값으로 설정하여 EM알고리즘을적용하고 이를 통해 모형 기반 군집분석을 진행하는방법을제안한다. 이 방법은비모수 호
ᆫ합모형 (nonparametric mixture model)에 적용되는 EM알고리즘 (Vardi와 Lee, 1993)이 특정 조건 ᄒ
ᅡ에서 언제나 최대값 (global maximum)으로 수렴한다는성질 (Chung과 Lindsay, 2015)에서 착안되 ᄋ
ᅥᆻ다. 사전정보가 전혀 포함되지 않은 균일분포를 혼합분포 (mixing distriubtion)의 초기값으로 사용 ᄒ
ᅡ여 비모수 혼합모형에 대한 EM 알고리즘을적용하면 가우시안 커널 함수를사용할 경우 첫 번째 단 ᄀ
ᅨ에서 업데이트된 혼합분포는커널 밀도 추정치의 형태를가진다. EM 알고리즘은매 단계에서 우도 ᄒ
ᅡᆷ수를 증가시키는성질을가지고 있기 때문에 균일분포보다 커널 밀도 추정치가 높은우도값을가진다.
ᄇ
ᅵ모수 혼합모형의 MLE는 언제나 이산형 분포함수라는 사실이 알려져 있으므로 (Lindsay, 1995) 커 너
ᆯ 밀도 추정치의 정점은 혼합분포의 MLE가 0보다큰확률값을 가지는정의역 값인 받침점 (support point)에 대한 좋은예측값이 된다. 따라서 이는 군집분석을 목적으로 하는유한혼합모형의 모수의 초 ᄀ
ᅵ값으로 사용되기 적당하다.
보
ᆫ 논문은이러한 초기값을 사용한 EM알고리즘을 통해 추정도 유한혼합모형의 모수가 다른초기화 ᄇ
ᅡᆼ법을사용한 경우보다 높은우도값을가진다는것을모의실험을 통해 보여준다. 또한 이를기업부도 ᄃ
ᅦ이터의 군집분석에 적용하여 그 결과를비교한다.
보
ᆫ 연구는 다음과 같이 구성된다. 1절에서는 연구의 배경, 연구의 목적, 연구의 구성과 방법에 대해 ᄉ
ᅥ술하였다. 2절에서는 가우시안 혼합 모형과 EM 알고리즘에 대한 설명과 초기 값 선택에 관련된 기 조
ᆫ선행연구에 대해 요약한다. 3절에서는비모수 혼합모형과 커널 밀도 추정치와의관계를설명하고 이 ᄅ
ᅳᆯ바탕으로 EM 알고리즘의 초기화 방법을제안한다. 4절에서는모의 실험을 통해 기존초기화 방법과 ᄌ
ᅦ안된방법을비교한다. 5절에서는앞절에서 진행한 모의실험 방법을 실제 기업 부도 데이터에 적용한 ᄃ
ᅡ. 마지막으로 6절은 본연구에 대한 결론과 의의를서술한다.
2. 선행연구
2.1. 가우시안 혼합모형과 EM알고리즘 ᄀ
ᅡ우시안 혼합 모형 (gaussian mixture models; GMM)은각 모집단이 서로 다른다변량 정규분포를 ᄄ
ᅡ른다고 가정하며 다음과 같은 식으로 정의된다.
f (x; θ) =
K
X
k=1
πkϕ(x; µk, Σk) (2.1)
ᄋ
ᅧ기서 πk는 k번째 군집에 속할 사전 확률로 0 ≤ πk ≤ 1, PK
k=1πk = 1를만족하고, ϕ(x; µk, Σk)은 ᄀ
ᅮ성분포 (component density)로서 평균 µk와 공분산 Σk를가지는다변량 정규분포의확률밀도함수를
ᄂ
ᅡ타낸다. θ = {π1, ..., πK−1, µ1, ..., µK, Σ1, ..., ΣK}는모수, K는 총 군집의 개수를나타낸다.
ᄆ
ᅩ수 θ의 MLE는 EM알고리즘 (Hartley, 1958; Dempster 등, 1997)을사용하여 추정된다. EM 알 ᄀ
ᅩ리즘은 확률모형이 관측되지 않는 잠재변수 (latent variable)에 의존할 때 우도함수의 최댓값을 찾 ᄀ
ᅵ 위한 방법이다. 잠재변수의 현재 값이 주어졌을 때의 조건부 우도함수의 기댓값을 계산하는 과정 (E-step)과 그 기댓값을최대화하는모수를찾는과정 (M-step)을반복적용한다.
GMM에 대한 EM 알고리즘은다음과 같은절차로 요약된다 (McLachlan과 Peel, 2000). 무작위 표 보
ᆫ yi ∼ f (y; θ), i = 1, . . . , n과 초기값 dθ(0) = ( dπ(0)1 , . . . , dπ(0)K , dµ(0)1 , . . . , dµ(0)K, dΣ(0)1 , . . . , dΣ(0)K )이 주어졌 으
ᆯ때 r번째 단계는아래와 같다.
E-step : dzik(r)=
πdk(r)ϕ(yi;d µ(r)k ,d
Σ(r)k ) PK
k=1
πdk(r)ϕ(yi;d µ(r)k ,d
Σ(r)k )
, i = 1, . . . , n, k = 1, . . . , K,
M-step: \πk(r+1)=
Pn i=1
zdik(r)
n , \µ(r+1)k =
Pn i=1
zd(r)ikyi nk , Σ\(r+1)k =
Pn i=1
zdik(r)(yi−\
µ(r+1)k )(yi−\ µ(r+1)k )′
nk .
ᄋ
ᅵ때, nk=Pn
i=1zdik(r)이다.
2.2. Finite mixture model의 초기값 선정 호
ᆫ합 모형에서 MLE를 추정하는 데에 있어서 초기 값 선택의 문제는많은 연구자들에 의해 중요성 ᄋ
ᅵ 부각되고 연구되었다. Grid search 방법 (Laird, 1978), 주성분 분석의 활용 (McLachlan, 1988), ᄇ
ᅮ트스트랩 루트 검색 유형 방법 (Markatou 등, 1998), Poission 분포의 적률추정치의활용 (Karlis와 Xekalaki, 2003),회귀적 초기화 (recursive initialization) 방법 (Baudry와 Celeux, 2015) 등다양한 시 ᄀ
ᅡ
ᆨ에서 초기값 선정 문제를해결하기 위한 방법이 제안되었다. 하지만 R을비롯한 여러 통계분석 패키 ᄌ
ᅵ에서는초기 군집을무작위로 할당하거나, 이러한 무작위 할당을 일정횟수만큼반복하여 그 중가장 ᄋ
ᅮ도함수 값이큰추정치를사용하는방법이 기본으로 사용되고 있다.
Biernacki 등 (2003)은이러한 무작위 초기값 선정 방법을보다 효율화하기 위해 EM을개선한 형태 ᄋ
ᅵᆫ classification EM (Celeux와 Govaert, 1992; CEM) 또는 stochastic EM (McLachlan과 Krishnam, 1997; SEM)과 합성하는 방법을 제안하였다. CEM은 E-step에서 yi가 k번째 그룹에 할당될 조건부 화
ᆨ률 ˆ
zik(r)를업데이트 한 후 이확률값이 가장 큰그룹으로 yi를 할당하는 C-step이 추가된 형태이다.
SEM은 E-step 후 yi를 조건부확률 dzik(r)이 가장 큰 그룹으로 할당하지 않고 다항분포 (multinomial distribution)를사용하여확률적으로 그룹에 할당하는 S-step을사용한다.
Biernacki 등 (2003)은 알고리즘의 최대 반복 횟수를 1000으로 고정하고 여러 가지 조합으로 합성 ᄒ
ᅡᆫ 알고리즘을사용하여 성능향상을시도했다. 10개의 서로 다른무작위 초기값을사용하여 1) 100번 ᄋ
ᅴ EM step을 적용하는 방법 (10EM), 2) 50번의 CEM step 후 50번의 EM step을 적용하는 방법 (10CEM-EM), 3) 50번의 짧은 EM step 후 긴 EM step을 50번 반복하는 방법 (10em-EM), 4)50번 ᄋ
ᅴ SEM step 중 우도함수 값이 최대가 되는 추정치를 시작으로 50번의 EM step을 적용하는 방법 (SEMmax-EM) 등을고려하였다. 그 결과 CEM-EM이 적은반복횟수에서 상대적으로 성능이 좋다는 겨
ᆯ론을보여주었다.
3. 비모수확률밀도함수 추정치를 활용한 EM 알고리즘의 초기값 선정 ᄇ
ᅩᆫ절에서는 GMM의 MLE 추정을위해 커널 밀도 추정치 곡선의 정점의 위치를초기값으로 사용하 느
ᆫ방법을제안한다. 이러한 방법은커널 밀도 추정치를비모수 혼합모형의 혼합분포 추정치로 보는시
ᄀ ᅡ
ᆨ에서 착안되었다. 비모수 혼합모형의 MLE와 커널 밀도 추정치의관계에 대해 설명하고 이를이용한 EM알고리즘의 초기값 선정 방법에 대해 서술한다.
3.1. 비모수 혼합모형과 커널 밀도 추정치 ᄇ
ᅵ모수 혼합모형은유한 혼합모형의확장된형태로 유한 개의 분포가 혼합된형태가 아닌 무한 개의 부
ᆫ포가 혼합분포 (mixing distribution)을 통해 혼합된다음과 같은형태를지닌다.
f (x; Π) = Z
K(x; φ)dΠ(φ), ᄋ
ᅧ기서 Π는연속형 혹은이산형확률분포함수를모두 포함한다. 만일 Π가 유한 개의 받침점을가지는 ᄋ
ᅵ산형확률분포함수라면 위의 식은유한혼합모형과 동일하다.
ᄋ
ᅵ 때 혼합분포 Π의 MLE (nonparametric MLE; NPMLE)를추정하기 위한 방법으로 Vardi와 Lee (1993)는 EM알고리즘을선형역문제 (linear inverse problem)의관점에서 해석하였다.
EM 알고리즘은 매 단계에서 우도함수를 반드시 증가시키는 방향으로 전개되는데 Chung과 Lind- say (2015)는 Π에 대한 EM알고리즘이 특정한 정칙조건 하에서 언제나 최대값 (global maximum)으 ᄅ
ᅩ 수렴함을 증명하였다. Chung과 Lindsay (2011)은 NPMLE가 언제나 이산분포라는 성질 (Lind- say, 1995)에 착안하여 연속형 균일분포를초기값으로 하여 EM 알고리즘을적용하면 우도함수를 증가 ᄉ
ᅵ키는 방향으로 업데이트가 진행되면서 이산형 NPMLE의 받침점의 위치를 나타내는 정보를 제공한 ᄃ
ᅡ는것을보였다. 그리고 가우시안 커널을사용할 경우 균일분포인 초기값으로부터 한 단계의 EM 알 ᄀ
ᅩ리즘을적용하게 되면 ˆΠ의확률밀도함수가 아래와 같은커널 밀도 추정치 (kernel density estimate;
KDE)의 형태가됨을보였다.
fˆh(x) = 1 n
n
X
i=1
ϕ(x; xi, h2I),
ᄋ
ᅧ기서 가우시안 커널함수 ϕ(x; xi, h2I)는각 차원이 서로 독립적인 정규분포의확률밀도함수를나타낸 ᄃ
ᅡ. 평활모수 h가 작으면 분포 추정치의 형태가 정점이 많은 울퉁불퉁한 모양으로 나타나고 h가 크면 ᄉ
ᅡᆼ대적으로 매끄러운 형태가된다. 초기값인 균일분포는사전정보가 전혀 없는 분포이지만 한 단계의 EM단계를 통해 도출된 KDE 형태의 ˆΠ은 울퉁불퉁한 형태를 보이며 혼합분포의 정의역의 어떤 지점 ᄋ
ᅴ 가중치가 증가되어야 우도함수 값이 증가하여 NPMLE에 가까워 질수 있는지에 대한 정보를제공한 ᄃ
ᅡ. 따라서 KDE의 정점의 위치를유한 혼합모형의 EM 알고리즘에 대해 초기값으로 사용한다면 유한 호
ᆫ합모형의 EM 알고리즘이 최대값이 아닌극댓값으로 수렴하는 문제를해결하는데 도움이될 것이다.
3.2. 커널 밀도 추정치를 활용한 GMM의 초기 값 선택
KDE의 정점의 위치를 계산하기 위해 modal EM (MEM) 알고리즘 (Li 등, 2007)을 활용할 수 있 ᄃ
ᅡ. MEM 알고리즘은 KDE을 기반으로 한 모형 기반 군집분석을 위해 개발된것으로 유한 혼합모형 ᄋ
ᅴ 정점을찾는방법이다. 특정관측치를시작점으로 하여 매 MEM 단계에서 혼합모형의 정점 방향으 ᄅ
ᅩ 움직이고 정점에 다다르면 알고리즘이 종료된다. KDE는유한 혼합모형의 특수한 형태이기 때문에 MEM알고리즘을적용하여 KDE의 정점을찾을수 있다. 초기값 m(0)가 주어질 때, MEM 알고리즘을 KDE에 적용하면 아래와 같다.
1) Let pk= n1ϕ(m
(r);xk,h2I) Pn
i=11
nϕ(m(r);xi,h2I), k = 1, 2, ..., n.
2) Update m(r+1)=Pn k=1pkxk. ᄋ
ᅱ의 단계를 m(r)의 변화가 ϵ(> 0)보다 작아질 때까지 반복한다. 각 관측치를초기값 m(0) = xi로 설 저
ᆼ하여 MEM을 반복하고 유일한 수렴값의 집합을찾아내면 이것이 KDE의 정점의 집합이라고 할 수 이
ᆻ다. 본 논문에서는이를활용하여 GMM의 초기값을제안하고자 한다.
GMM을구성하는성분의 수 K는사전에 결정되어 있다고 가정하자. KDE의 정점의 수는 h의 값에 ᄄ
ᅡ라 달라지기 때문에 K개의 정점을발생시키는 h를찾기 위해서 그리드 서치 (grid search)방법을사 ᄋ
ᅭ
ᆼ한다. 각 차원의 분산이 크게 다를경우 동일한 h가 나타내는평활 정도가 상이할 수 있기 때문에 알 ᄀ
ᅩ리즘의 적용전에 분산이 1을갖도록표준화하는과정을적용한다. GMM을구성하는정규분포의 평 규
ᆫ µk에 대한 초기값을결정하는알고리즘은아래와 같다.
알고리즘: 커널 기반 초기 값 (Kernel-based initial value) 선택 1) h의 그리드를 등간격으로 설정한다.
h0< h1< ... < hm.
2)각 h = hl, l = 1, ..., m에서 KDE를추정하고 MEM 알고리즘으로 정점을찾는다.
ᄋ
ᅵ 중 유일한 정점의 개수를 kl, 정점의 집합을{m(l)1 , m(l)2 , . . . , m(l)k
l}이라고 하자.
3)만일, K ∈ {k1, ..., km}이면 kl= K인 최소 hl에 대해 GMM의 구성분포의 평균의 ᄎ
ᅩ기값을아래와 같이 설정한다.
{µ(0)1 , ..., µ(0)K } = {m(l)1 , . . . , m(l)K}.
ᄆ
ᅡᆫ일, K /∈ {k1, ..., km}라면 kl< K < kl+1인 l에 대하여 구간 (hl, hl+1)을 분할하여 2)부터 반복한다.
ᄋ ᅡ
ᆯ고리즘의 단순화를위해 GMM의 각 구성분포의 사전확률에 대한 초기값 π(0)k 는 1/K로, 구성분포 ᄋ
ᅴ 공분산 행렬에 대한 초기값 Σ(0)은데이터의 공분산행렬 S로 설정한다.
4. 모의실험
4.1. 모의실험 개요 보
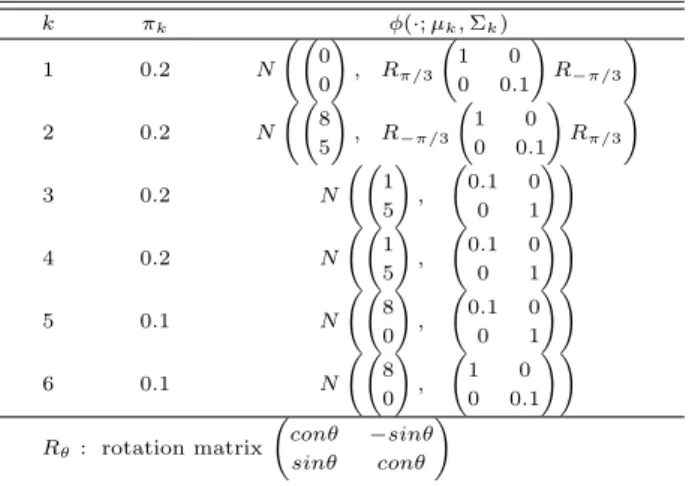
ᆫ절에서는 Baudry와 Celeux (2015)의 연구에서 사용된 6개의 구성분포로 이루어진 GMM에서 발 새
ᆼ시킨 데이터를대상으로 각 초기값의 성능을비교한다. Table 4.1은 GMM을 이루는각 구성분포의 ᄐ
ᅳᆨ성을나타낸다. Figure 4.1은모의실험 모형에서 발생된무작위 데이터셋의 산점도와 각 집단 구성분 ᄑ
ᅩ의 95% 등고선 그림을나타낸다.
보
ᆫ 연구에서는 위의 모형에서 200개 관측치 (n = 200)를 가진 데이터를 100번 (rep = 100) 반복 새
ᆼ성하여 무작위한 초기화에 기반을 둔 10EM, 10CEM-EM, 10em-EM, SEMmax-EM (Biernacki 등, 2003)과 본연구에서 제안하는 kernel-based initial value방법을비교한다. 모의실험은 R 3.4.2버전을 ᄉ
ᅡ용하였으며 Biernacki 등 (2003)의 방법을 구현한 Rmixmod (Lebret 등, 2015) 패키지를활용하였 ᄃ
ᅡ.
Table 4.1 Component densities for simulation study
k π
kϕ(·; µ
k, Σ
k)
1 0.2 N
0 0
!
, R
π/31 0 0 0.1
! R
−π/3!
2 0.2 N
8 5
!
, R
−π/31 0 0 0.1
! R
π/3!
3 0.2 N
1 5
!
, 0.1 0
0 1
!!
4 0.2 N
1 5
!
, 0.1 0
0 1
!!
5 0.1 N
8 0
!
, 0.1 0
0 1
!!
6 0.1 N
8 0
!
, 1 0
0 0.1
!!
R
θ: rotation matrix conθ −sinθ sinθ conθ
!
Figure 4.1 Scatter plot of simulation data
4.2. 모의실험 결과
Table 4.2는 각 초기화 방법을 사용하여 도출된 최종모형의 loglikelihood 값의 평균과 표준편차를 ᄂ
ᅡ타낸다. 기존의 초기화 방법에 비해 kernel-based 방법을사용할 때 loglikelihood의 평균이 표준편차 ᄋ
ᅴ 두 배 이상큰것으로 나타나기 때문에 유의적으로 높은 loglikelihood값에서 모수 추정이 이루어 졌 ᄋ
ᅳ
ᆷ을알 수 있다. 따라서 알고리즘이 최대값으로 수렴될가능성이 더 많다고 판단할 수 있다.
Table 4.2 Loglikelihood of estimated GMM
10EM 10CEM-EM 10em-EM SEMmax-EM Kernel-based
ean -673.9577 -670.7941 -674.0121 -682.0986 -630.0280
d 18.1936 17.9406 18.2012 19.5725 16.6311
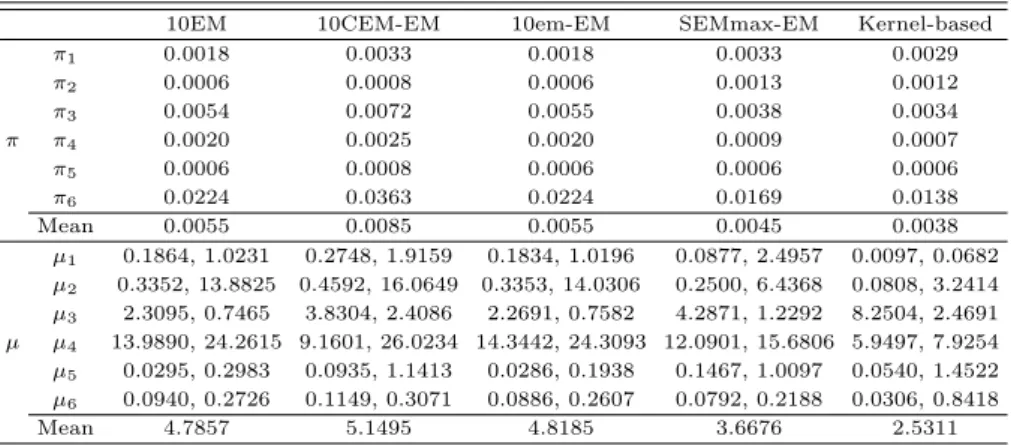
Table 4.3은추정치의 정확도를비교하기 위해 µ와 π의 root mean square error (RMSE) 추정치를 ᄂ
ᅡ타내고 있다. 모의실험의 모형은 6개의 구성분포로 이루어져 있기 때문에 추정치의 정확도를비교하 ᄀ
ᅵ 위해서는각 µ1,. . . , µ6,π1,. . . , π6이 Table 4.1의 어느 구성분포에 해당하는지 결정할 필요가 있다.
ᄋ
ᅵ를위해 각 µk추정치와 참값과의 거리를계산하여 가장 거리가 가까운 µk에 해당하는구성분포로 할 ᄃ
ᅡᆼ한 뒤 RMSE를계산하였다.
Table 4.3 RMSE estimates of parameters
10EM 10CEM-EM 10em-EM SEMmax-EM Kernel-based
π
10.0018 0.0033 0.0018 0.0033 0.0029
π
20.0006 0.0008 0.0006 0.0013 0.0012
π
30.0054 0.0072 0.0055 0.0038 0.0034
π π
40.0020 0.0025 0.0020 0.0009 0.0007
π
50.0006 0.0008 0.0006 0.0006 0.0006
π
60.0224 0.0363 0.0224 0.0169 0.0138
Mean 0.0055 0.0085 0.0055 0.0045 0.0038
µ
10.1864, 1.0231 0.2748, 1.9159 0.1834, 1.0196 0.0877, 2.4957 0.0097, 0.0682 µ
20.3352, 13.8825 0.4592, 16.0649 0.3353, 14.0306 0.2500, 6.4368 0.0808, 3.2414 µ
32.3095, 0.7465 3.8304, 2.4086 2.2691, 0.7582 4.2871, 1.2292 8.2504, 2.4691 µ µ
413.9890, 24.2615 9.1601, 26.0234 14.3442, 24.3093 12.0901, 15.6806 5.9497, 7.9254 µ
50.0295, 0.2983 0.0935, 1.1413 0.0286, 0.1938 0.1467, 1.0097 0.0540, 1.4522 µ
60.0940, 0.2726 0.1149, 0.3071 0.0886, 0.2607 0.0792, 0.2188 0.0306, 0.8418
Mean 4.7857 5.1495 4.8185 3.6676 2.5311
RMSE는 값이 작을수록 추정의 정확도가 높다고 판단된다. π 추정치에 대한 RMSE 값을 보면 π3, π4, π5, π6에 대해 kernel-based 초기화 방법이 좋은성과를나타내는것을확인할 수 있다. 총 6개의 π추정치의 RMSE의 평균역시 kernel-based가 가장 낮은값을보인다. 구성분포의 평균은 2차원데이 ᄐ
ᅥ이기 때문에 µk의 RMSE는각 2개의 값을가진다. Kernel-based 방법은 총 6개의 µ 추정치 벡터 중 4개가 적어도 한 차원에서 비교대상 중 최소 RMSE값을나타냈다. 총 12개의 RMSE 값의 평균역시 kernel-based방법이 가장 작았다.
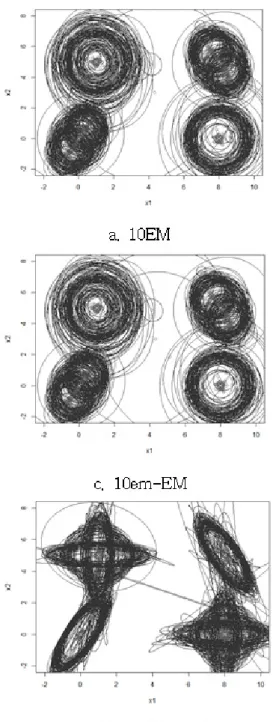
ᄀ
ᅮ성분포의 공분산행렬 Σk에 대한 추정치의 정확도는 각 Σk가 2 × 2의 행렬이기 때문에 개별 RMSE로 비교할 경우 복잡도가 증가된다. 공분산행렬 추정치가 결정하는 구성분포의 모양을 비교 ᄒ
ᅡ기 위해 데이터로 추정된 GMM의 6개의 정규분포에 대해 95% 확률영역을나타내는 등고선 그림을 ᄀ
ᅳ리는 것을 100개의 모의실험 데이터에 대해 반복하였다 (Figure 4.2). 이를 Figure 4.1이 나타내는 ᄎ
ᅡ
ᆷ 분포의 모양과 비교하여 추정치의 성능을비교하고자 한다.
Figure 4.2의 그래프를살펴보면 대체적으로 우상과 좌하에 위치하는 k = 1, 2구성분포의 특징인 비 ᄃ
ᅢ각 공분산행렬의 특성을 Figure 4.2-a, b, c, d의 기존초기화 방법은뚜렷하게 나타내지 못한다. 상대 ᄌ
ᅥᆨ으로 Figure 4.2-e의 kernel-based 방법은 45도와 135도 방향으로 뚜렷한 타원형 형태를가진 등고선 ᄋ
ᅳᆯ보여주어 Figure 4.1의 참 분포와 가장 가까운것을알 수 있다. Figure 4.1에서 k = 3, 4, 5, 6 구성 부
ᆫ포의 등고선은 동일한 평균을 중심으로 두 개의 서로 다른타원으로 이루어져 있다. Kernel-based 방 버
ᆸ은이러한 특성을뚜렷하게 재현해주는반면 나머지 네 개의 초기화 방법은 k = 3, 4와 k = 5, 6 구성
부
ᆫ포를거의 구분하지 못하는것으로 보인다.
Figure 4.2 Contour plot of estimated GMM: p = 0.95, rep= 100
5. 기업부도 데이터에의 적용 보
ᆫ절에서는서로 다른초기화 방법으로 추정된GMM을사용하여 모형기반 군집분석을기업부도 데 ᄋ
ᅵ터에 적용하고 그 성능을비교하고자 한다. 2000년 1월부터 2016년 3월까지 KISVALUE에 등재된 ᄉ
ᅡᆼ장기업 중금융회사를제외한 1257개 기업의 재무자료를사용하였다. 전체 대상 기업 중부도기업은 414개, 정상기업은 843개이다. 각 기업의 재무비율자료 수집 일은부도기업의 경우 부도가 발생한 시 ᄌ
ᅥ
ᆷ을포함하는 분기의 재무비율자료를수집하였고 정상기업의 경우 자료 수집 기간 중가장 최근 분기 ᄋ
ᅴ 재무비율자료를선택하였다. 이 중결측값이 존재하는데이터를제외한 총 902개 기업에 대한 재무 ᄇ
ᅵ율 자료를 본 절에서 사용한다. 군집분석을위해 사용된 8개의 재무비율 변수는매출액증가율, 매출 ᄎ
ᅢ권회전율,부채비율,자기자본순이익율, 자기자본회전율, 재고자산회전율, 총자본순이익율, 총자산증 ᄀ
ᅡ율이다.
ᄇ
ᅩᆫ데이터는 기업의 부도 여부에 대한 정보를가지고 있기 때문에 K = 2인 GMM 모형을추정하고 loglikelihood를비교하여 추정 모형의 가능도를비교한다. 추정된 모형을바탕으로 군집분석을시행하 ᄀ
ᅩ 그 결과를 실제 부도여부와 비교하는외부적 군집분석 타당성 지표로 Rand index (RAND; Rand, 1971), adjusted Rand index (ARI; Hubert와 Arabie, 1985), normalized mutual information (NMI;
Wagner와 Wagner, 2007), Fowlkes와 Mallows의 index (FM; Fowlkes와 Mallows, 1983), Jaccard index를 사용하였다. 각 지표는 0과 1 사이의 값을가지며, 미리 정의된 군집과 군집 결과와 일치할수 ᄅ
ᅩᆨ 1에 가까운값을가진다.
ᄃ
ᅮ 개의 구성분포를 가지는 GMM을 앞에서 사용한 초기화 방법을 사용하여 추정한 결과 loglike- lihood를 비교하면, 기존 연구의 초기 값 선택 방법들은 소수점 셋째자리까지 모두 동일한 값 (- 5229.447)을 가졌다. 이 값은 kernel-based 방법에 의한 loglikelihood 값 (-3561.659)에 비해 1600 ᄋ
ᅵ상 작은결과로 kernel-based 방법에 의한 추정값이 더 우월한 것으로 판단된다.
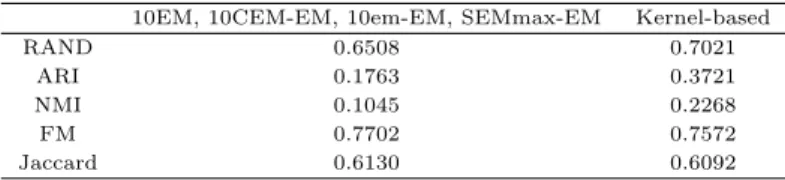
Table 5.1 Comparison of clustering performance
10EM, 10CEM-EM, 10em-EM, SEMmax-EM Kernel-based
RAND 0.6508 0.7021
ARI 0.1763 0.3721
NMI 0.1045 0.2268
FM 0.7702 0.7572
Jaccard 0.6130 0.6092
Table 5.1는 군집 결과를평가하는지표값을비교한다. 네 개의 기존초기화 방법은모두 동일한 군집 부
ᆫ석 결과를나타내었기 때문에 동일한 지표값을가진다. RAND, ARI, NMI 지표는 kernel-based방 버
ᆸ이 우월함을나타낸다. FM과 Jaccard 지표를기준으로 판단하면 기존의 방법이 더 양호한 결과를보 ᄋ
ᅵ지만 그 값의 차이 (0.0130, 0.0038)가 RAND, ARI, NMI 지표의 차이 (0.0513, 0.1958, 0.1223)에 비 ᄒ
ᅢ 미미하다.
최종 군집 결과를 실제 부도 여부와 비교해 보았을때 기존의 초기화 방법에 의한 군집은 77.5%의관 ᄎ
ᅳ
ᆨ치가 실제 부도 여부와 일치했고 kernel-based 방법에 의한 군집은 81.8%의관측치가 일치했다.
ᄋ
ᅱ의 loglikelihood 값, 군집분석 타당성 지표, 군집 정확도를 종합적으로 판단해 볼때 모형 기반 군 지
ᆸ분석 시 kernel-based initial value 방법이 기존무작위 초기화 방법보다 타당성을가지는것으로 보 ᄋ
ᅵᆫ다.
6. 결론 보
ᆫ 논문에서는커널확률 밀도 추정치를바탕으로 GMM의 모수 추정을위한 EM 알고리즘의 초기값 으
ᆯ제안하였다. 현재 여러 소프트웨어에서 널리 사용되는무작위 초기값 선정 방법과 이를개선한 기존 ᄇ
ᅡᆼ법에 비해 kernel-based 방법이 높은우도함수 값을가지는추정치로 EM알고리즘이 수렴하도록하는 겨
ᆼ향이 있다는것을모의실험과 기업부도 데이터를 통해확인하였다. 또한 GMM을기반으로 한 군집 부
ᆫ석에 적용하였을때 군집결과를비교하는여러 지표를 통해 kernel-based 방법이 보다 우위에 있다는 거
ᆺ을보여주었다.
보
ᆫ 논문에서는 알고리즘의 단순화를위해 GMM의 각 구성분포의 평균 (µ)의 초기값에 집중하여 커 너
ᆯ확률 밀도함수 추정치의 정점의 위치를그 초기값으로 사용하는방법을제안하였다. 하지만 구성 비 유
ᆯ (π) 역시 커널확률 밀도함수 추정치의 정점의 높이를사용하여 초기값으로 사용한다면 보다 나은결 ᄀ
ᅪ를기대할 수 있을것이다. 무작위 초기화 방법에 비해 비록계산 시간은더 길어지는경향은 있지만 EM알고리즘이 우도함수의 최대값이 아닌 점으로 수렴하는 문제가 상당히 중요하게 다뤄지는점을고 ᄅ
ᅧ할 때 본 논문이 제안하는방법이 GMM의 우도함수의 최대값을찾는 좋은대안으로 받아들여 질 것 ᄋ
ᅳ로 기대한다.
References
Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control , 19, 716-723.
Baudry, J. P. and Celeux, G. (2015). EM for mixtures. Statistics and Computing, 25, 713-726.
Biernacki, C., Celeux, G. and Govaert, G. (2003). Choosing starting values for the EM algorithm for getting the highest likelihood in multivariate Gaussian mixture models. Computational Statistics &
Data Analysis, 41, 561-575.
Celeux, G. and Govaert, G. (1992). A classification EM algorithm for clustering and two stochastic versions.
Computational Statistics & Data Analysis, 14, 315-332.
Chung, Y. and Lindsay, B. G. (2011). A likelihood-tuned density estimator via a nonparametric mixture model, in: D. R. Hunter, D. Richards, J. L. Rosenberger (Eds.), Nonparametric statistics and mixture models: A festschrift in honor of Thomas P. Hettmansperger , World Scientic, Singapore, 69-89.
Chung, Y. and Lindsay, B. G. (2015). Convergence of the EM algorithm for continuous mixing distributions.
Statistics and Probability Letters, 96, 190-195.
Dempster, A. P., Laird, N. M. and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B , 39, 1-38.
Fowlkes, E. B. and Mallows, C. L. (1983). A method for comparing two hierarchical clusterings. Journal of the American Statistical Association, 78, 553-569.
Fraley, C. and Raftery, A. E. (2002). Model-based clustering, discriminant analysis and density estimation.
Journal of the American Statistical Association, 97, 611-631.
Hartley, H. O. (1958). Maximum likelihood estimation from incomplete data. Biometrics, 14, 174-194.
Hubert, L. and Arabie, P. (1985). Comparing partitions. Journal of Classification, 2, 193-218.
Ikeda, S. (1997). Acceleration of the EM algorithm. Systems and Computers in Japan, 31, 10-18.
Jeong, D. (2015). A study on cluster and positioning of domestic electronic commerce based on purchasing motivation. Journal of the Korean Data & Information Science Society, 26, 841-856.
Karlis, D. and Xekalaki, E. (2003). Choosing initial values for the EM algorithm for finite mixtures. Com- putational Statistics & Data Analysis, 41, 577-590.
Laird, N. (1978). Nonparametric maximum likelihood estimation of a mixing distribution. Journal of the American Statistical Association, 73, 805-811.
Lebret, R., Iovleff, S., Langrognet, F., Biernacki, C., Celeux, G. and Govaert, G. (2015). Rmixmod: The r package of the model-based unsupervised, supervised and semi-supervised classification mixmod library.
Journal of Statistical Software, 67, 241-270.
Li, J., Ray, S. and Lindsay, B. G. (2007). A nonparametric statistical approach to clustering via mode
identification. Journal of Machine Learning Research, 8, 1687-1723.
Lindsay, B. G. (1995). Mixture models: Theory, geometry and applications, in: NSF-CBMS regional con- ference series in probability and statistics, Institute of Mathematical Statistics.
Markatou, M., Basu, A. and Lindsay, B. G. (1998). Weighted likelihood equations with bootstrap root search. Journal of the American Statistical Association, 93, 740-750.
McLachlan, G. J. (1988). On the choice of starting values for the EM algorithm in fitting mixture models.
Journal of the Royal Statistical Society: Series D , 37, 417-425.
McLachlan, G. J. and Krishnan, T. (1997). The EM algorithm and extensions, Wiley Interscience.
McLachlan, G. and Peel, D. (2000). Finite mixture model , John Wiley & Sons.
Rand, W. M. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66, 846-850.
Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6, 461-464.
Vardi, Y. and Lee, D. (1993). From image deblurring to optimal investments: Maximum likelihood solutions for positive linear inverse problems. Journal of Royal Statistical Society: Series B , 55, 569-612.
Wagner, S. and Wagner, D. (2007). Comparing clusterings - An overview , Technical report 2006-04, ITI Wagner, Faculty of Informatics, Universitat Karlsruhe (TH).
Woo, S. Y., Lee, J. W. and Jhun, M. (2014). Microarray data analysis using relative hierarchical clustering.
Journal of the Korean Data & Information Science Society, 25, 999-1009.
2018, 29
(2)
,327–338
Initialization method of finite mixture model using kernel density estimation and application on
model-based clustering †
Hyun-ju Cho
1
· Yeojin Chung2
· Youngmin Kim3
12e Consulting
2College of Business Administration, Kookmin University
3Department of Statistics, Kyungpook National University
Received 22 February 2018, revised 16 March 2018, accepted 19 March 2018
Abstract
The finite mixture model is widely used for model-based cluster analysis. The EM algorithm finds the maximum likelihood estimates of the finite mixture model. Since the performance of the EM algorithm is largely influenced by its initial value, the choice of the initial value has been regarded as an important factor for EM. This study proposes a new initialization method for the EM algorithm using the kernel density estimator. The location of modes of the kernel density estimate is calculated by the MEM algorithm and set as an initial value for component means for Gaussian mixture model. Simulation study and application on corporate default data show that the proposed method gives parameter estimates higher than the exising methods. In addition, we apply the model-based clustering based on the estimated mixture model and compare the performance of clustering.
Keywords: EM algorithm, finite mixture model, initial value, maximum Likelihood Estimation, model-based clustering.
†
This research was supported by Basic Science Research Program through the National Research Foun- dation of Korea (NRF) funded by the Ministry of Education (NRF-2016R1C1B1010940).
1
Consultant, Public Financial Business Unit, 2e Consulting, Korea. Seoul 07228, Korea.
2
Corresponding author: Assistant professor, College of Business Administration, Kookmin University, Seoul 02707, Korea. E-mail: [email protected]
3