Development of a Personalized Similarity Measure using Genetic Algorithms for Collaborative Filtering
1)
전체 글
1)
수치
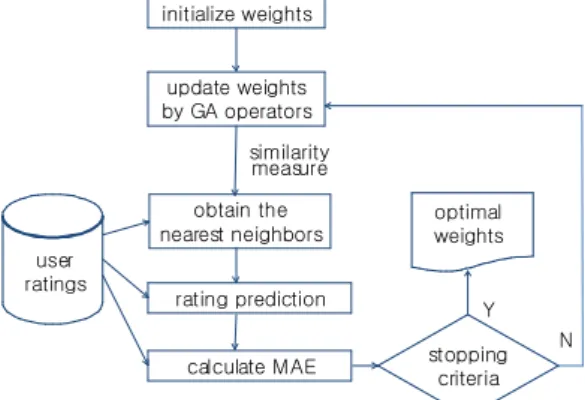

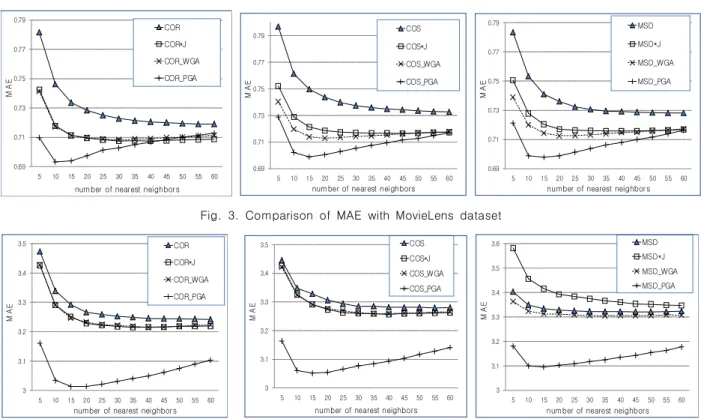
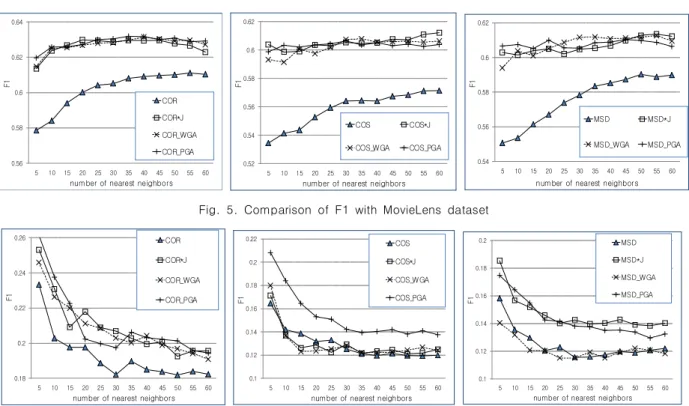
관련 문서
We present a method for recognizing the underlying sparsity structure of a nonlinear partially separable problem, and show how the sparsity of the Hessian matrices of the
The proposed approach is to compare Hindi contexts from the largest available Hindi Corpus with the Human judgments of degree of similarity existing between the benchmark word
SSID MEZ30K-****** here ****** is the last 6digits of MAC address Firewall Port forwarding/MAC filtering/IP filtering/URL filtering. # of
relative contributions of differences in genetic and non-genetic factors to the total phenotypic variance in a population. For instance, some
4.7.3 Summary of Steps for Filtering in the
– 예: 함수 spfilt는 예제 2.9의 기하 평균 필터를 imfilter와 MATLAB의 log 함수와 exp 함수를 사용해서 구현. • 이게 가능할 때, 성능은 항상 훨씬 빠르고, 메모리
DNA-based testing includes pre- and postnatal genetic testing for the diagnosis of genetic diseases, carrier testing for genetic diseases, susceptibility genetic testing
Ad-hoc search: Find relevant documents for an arbitrary text query. Filtering: Identify relevant user profiles for
