비선형 회귀분석과 구조방정식을 이용한 지방부 4지 신호교차로의 사고요인분석
오주택*․권일․황정원 한국교통대학교 도시공학과
A Causation Study for car crashes at Rural 4-legged Signalized Intersections Using Nonlinear Regression and Structural Equation Methods
OH, Ju Taek*․KWEON, Ihl․HWANG, Jeong Won
Department of Urban Engineering, Korea National University of Transportation, Chungbuk 380-702, Korea
Abstract
Traffic accidents at signalized intersections have been increased annually so that it is required to examine the causation to reduce the accidents. However, the current existing accident models were developed mainly by using non-linear regression models such as Poisson methods. These non-linear regression methods lack to reveal the complicated causation for traffic accidents, though they are the right choice to study randomness and non-linearity of accidents. Therefore, it is required to utilize another statistical method to make up for the lack of the non-linear regression methods. This study developed accident prediction models for 4 legged signalized intersections with Poisson methods and compared them with structural equation models. This study used structural equation methods to reveal the complicated causation of traffic accidents, because the structural equation method has merits to explain more causational factors for accidents than others.
사고발생의 주요지점인 신호교차로 교통사고 발생건수는 해마다 증가하고 있어 교통사고를 감소시키기 위한 원인 규명이 매우 필요하다. 국내에서 연구되어진 기존의 교통사고예측 모형들은 대부분 Poisson 모형 등의 비선형 회귀 분석을 이용한 사고원인분석이 주를 이루고 있다. 비선형 Econometrics 분석기법들이 사고의 성격을 분석하는데 가 장 중요한 통계적 기법이기는 하지만, 도로에서 발생하는 교통사고의 원인분석적 차원에서 접근하면 이런 사고예측 모형들만 가지고 사고발생의 설명변수들을 규명하는데 구조적인 한계가 발생한다. 이는 이러한 통계적 방법들이 사 고의 예측력을 높이는데 중점을 두고, 이를 위해 소수의 유효한 설명변수들만을 모형식에 포함시키기 때문이다. 따 라서 사고에 대해 보다 구체적인 원인규명을 위해서는 비선형회귀분석모형의 개발과 동시에 비선형 Econometrics 분석기법의 단점을 보완하는 또 다른 통계적 노력이 필요하다. 이에 본 연구에서는 Poisson기법을 이용하여 지방부 4지 신호교차로의 사고예측모형을 개발하였고, 동시에 복합적인 인과관계를 증명하는데 다중변수관계를 포괄적으로 측정하여 탐색하는 구조방정식을 이용하여 사고모형을 개발하여 Poisson 모형의 결과값과 비교·분석하였다.
Key Words
Factor Analysis, Intersections, Nonlinear Regression, Structural Equation, Traffic Accident 요인분석, 교차로, 비선형 회귀분석, 구조방정식, 사고분석
* : Corresponding Author Received 9 August 2012, Accepted 7 January 2013
[email protected], Phone: +82-43-841-5158, Fax: +82-43-841-5410
Ⓒ Korean Society of Transportation
This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Article
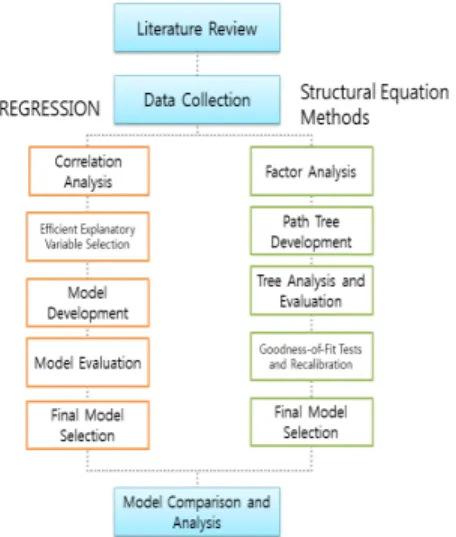
Figure 1. Research procedure flow
Ⅰ. 서론 1. 연구의 배경 및 목적
우리나라의 자동차 등록대수가 최근 10년간 지속적으 로 증가하여 2011년도에는 1800만대를 넘어섰다. 자동 차 등록대수와 함께 교통사고 또한 크게 늘어 국가적 문 제점으로 대두되고 있는 교통사고는 물적 손실 뿐 만 아 니라 국민의 인명과 고통이라는 피해를 발생시키고 있 다. 이를 반영하는 교통사고 발생건수를 살펴보면 2005 년에는 21만여건으로 2006, 2007년에는 발생건수를 유지하였지만 2008년 이후에는 증가 추세로 돌아섰고, 특히 2009년에는 231,900건으로 전년대비 7.5%가 상 승하였다. 특히 일반국도의 교통사고 발생건수는 다소 감 소 추세를 보이는 반면, 교차로 부근 또는 내에서 발생하 는 사고건수는 꾸준히 증가하고 있어 이에 대한 과학적인 분석을 요구하고 있다. 국토해양부에서 첨단안전장치로 교통사고 절반 줄이기 또는 첨단교통체계로 교통사고 줄 이기 등을 제시하고 있듯이 이들 내용에 바탕이 되는 근 원적인 교통사고의 원인을 알아야 할 필요성이 있다.
기존의 교차로 안전관련 논문들을 살펴보면 차량자체 요인보다는 인적 요인 그리고 도로 및 주변 환경요인 등 변수에 의해 발생하는 비율이 높다. 특히 도시부 및 지방 부 4지 신호 교차로에서의 교통사고에 관한 선행 연구들 에서는 사고와 관련이 있는 다양한 요인분석을 하고 있 는데, 이들 연구의 대부분은 Poisson 또는 Negative Binomial Methods의 비선형모형들을 이용하여 요인 분석을 하고 있다. 물론 이들 비선형 Econometrics 분 석기법들이 사고의 임의성과 비선형성을 분석하는데 가 장 기본이 되는 통계적 기법들이기는 하지만, 도로에서 발생하는 교통사고의 원인 분석적 차원에서 접근하면 이 런 사고예측 방법론들만으로는 사고발생의 설명변수들을 규명하는데 구조적인 한계가 발생한다. 이는 앞의 통계 적 방법들이 사고의 예측력을 높이는데 중점을 두고, 이 를 위해 소수의 유효한 설명변수들만을 모형식에 포함시 키기 때문이다. 따라서 이러한 소수의 설명변수들만을 가지고 이루어지는 사고의 요인분석은 도로의 많은 기하 구조들이 사고에 미치는 영향력을 개별적으로 분석하는 데 많은 문제점을 야기하고, 이러한 문제점들이 현재 개 발 중인 Highway Safety Manual의 각 기하구조별 Safety Performance Function (SPF)을 계산하는데
많은 어려움을 야기시키고 있다. 반면 구조방정식의 경 우, 여러 변수를 하나의 요인으로 포괄적으로 묶어 사고 를 설명할 수 있으며, 이로 인해 보다 많은 변수의 설명 력을 분석해 낼 수 있는 장점을 가지고 있다. 하지만 구 조방정식은 특정 잠재변수들 이외에도 어떤 잠재변수가 모형에 추가되면 직접 또는 간접효과가 달라질 수 있으 며, 인과관계 추론의 열악성과 자의성이 발생할 수 있다 는 한계점도 역시 가지고 있다.
이에 본 연구에서는 기존 사고모형개발에 많이 사용 되는 비선형회귀분석과 구조방정식의 방법론을 비교·분 석하였고, 이들 모형방법들을 모두 이용하여 사고모형을 개발하였으며 모형결과들을 상호 비교하였다.
2. 연구 범위 및 수행방법
본 연구에서 사용한 사고 자료는 2006년도 지방부 국 도변 4지 신호교차로 117개 지점에서 발생한 교통사고 자료를 이용하였으며, 교통사고의 원인과 유발요인들의 관계를 규명하기 위하여 사고 예측 모형 연구에 주를 이 루는 Poisson 또는 Negative Binomial Methods 같 은 회귀분석모형과 회귀요인들 간의 상호관계를 분석할 수 있는 구조방정식(Structural Equation Modeling) 을 이용한 모형을 도출하였다. 두 모형을 통해 각 모형에 서 설명하는 변수를 비교·분석하였다. 분석 프로그램으로 는 LIMDEP 8.0, SPSS 20과 AMOS 20 프로그램을 이 용하였다. Figure 1은 본 연구의 수행절차를 나타낸다.
3. 관련 문헌 고찰
먼저 관련된 국내 논문을 살펴보면, Kim D. H.
(2008)은 총 247개 지점을 대상으로 지방부 신호·비 신호 3지 교차로의 안전성을 향상시키기 위하여 사고 예측모형을 개발하였다. 개발된 기본의 모형들이 특정 지역의 자료를 이용함으로 범용적으로 활용되지 못하 기 때문에 다수 지역의 다양한 조건을 이용하여 모형 을 개발하였다. 분석결과 지방부 3지 신호교차로에서 는 주도로 좌회전 전용차로 유무, 주도로 좌회전 시거, 부도로 횡단보도 유무, 부도로 조명시설 유무, 주도로 버스정류장 유무, ADT가 유의한 변수였고 3지 비신 호 교차로에서는 진출입구수, 주도로 좌회전 전용차로 유무, 주도로 우회전 전용차로 유무, 부도로 중앙분리 대 유무, 주도로 조명시설 유무, 주도로 길어깨 폭, ADT로 분석하였다.
Lee D. M. (2008)은 지방부 4지 비신호 교차로에 서의 사고빈도 예측모형 개발을 위해 98개 교차로를 대 상으로 하였다. 설명변수의 배제를 줄이기 위해 2개의 대안모형을 개발하였으며 그 결과 부도로 횡단보도 유 무, 주도로 조명시설 유무, 교차각, ADT로 분석되었다.
또한 대도시권외곽의 지방부 교차로와 전라북도의 광범 위한 지역의 지방부 교차로를 대상으로 하여 모형의 범 용성과 대표성을 높이고자 하였다.
Kim E. C. (2008)은 지방부 신호교차로의 안전성 판단을 위해 사고예측모형를 개발하였는데 이 논문을 통 해 지방부 신호교차로 사고예측에 이용한 변수들을 고찰 하고 사고예측모형을 통해 어떠한 변수들이 선정되었는 지 알아 볼 수 있었다.
Bark B. H. (2008)는 청주시를 사례로 4지 신호교 차로를 차종에 따른 사고모형을 개발하였다. 비선형 회 귀모형인 음이항 회귀사고모형을 개발하였는데 모든 공 통된 사고요인은 일평균교통량이며 소형차의 경우에는 주도로와 부도로의 차로수 차이, 승용차의 특정 사고요 인은 주도로 차로폭합, 그리고 대형승합차의 경우 평균 황색시간으로 분석하였다. 그리고 Park B. H. (2008) 는 4지 신호교차로에서의 사고유형에 따른 교통사고모 형 개발에서는 가산자료모형 선정을 위해 과산포 검정을 통해 음이항 회귀모형도 개발하였다.
Park J. S. (2007)은 청주시 4지 신호교차로를 중 심으로 도로환경요인과 교통사고의 관계에 대하여 상관
분석하고 회귀분석을 통해 사고추정모형을 개발하였다.
Lee J. Y. (2008)은 구조방정식을 이용한 고속도 로의 교통사고 심각도에 작용하는 요인들을 분석하였 다. 크게 도로 요인 및 운전자요인, 환경요인을 외생 잠재변수로 설정하고 사고 심각도를 내생 잠재변수로 설정하여 모형을 추정하였다. 모형 추정결과 도로요인 과 환경요인은 사고 심각도와 음의 관계에 나타났고, 운전사 요인은 사고 심각도와 양의 관계에 있는 것으 로 나타났다.
그외 해외 논문을 살펴보면 McCoy and Malone (1989)은 방향별 좌회전 차로 설치에 다른 교통사고 감 소에 대한 효과분석을 수행하였다. 그 결과, 추돌사고와 접촉사고 좌회전사고가 6-77%까지 감소하였으며 주도 로 일방향에서는 대략 20%내외, 주도로 양방향에서는 대략 40%내외의 감소가 나타났다.
Poch and Mannering (1996)은 비통제(비신호) 방식에서 안전성을 검토하였다. 그 결과, 교차로 내 통과 교통량이 적은 경우 총 사고건수와 직각 충돌사고가 감 소하는 것으로 분석되었다.
Bauer and Harwood (1996)는 미국 워싱턴주를 대상으로 기하구조와의 관계를 모형화하였다. 2년간 발 생한 사고를 기반으로 포아송 회귀모형 및 음이항 회귀 모형을 이용하여 사고등급 별, 지역 별로 사고예측모형 을 개발하였으며 그 결과 교통량, 연결로의 형식, 가감 속차로 길이, 연결로 길이, 유·출입여부가 연결로 교통 사고에 영향을 주는 것으로 나타났다. 본 연구에서는 포 아송 및 음이항 회귀모형 개발 방법에 초점을 두어 고찰 하였다.
Vogt A. (1999)는 3년간의 자료를 이용하여 총 205개소를 대상으로 모형을 개발하였다. 그 결과, 지방 부 4지 교차로에서 주도로의 좌회전 차로의 설치가 교통 사고를 38% 줄이는 것으로 분석하였다.
이와 같이 교통사고 예측모형을 개발하는데 있어서 대 부분의 기존 연구들은 비선형 회귀분석을 이용한 연구 내 용들이 대부분을 차지하고 있다. 따라서 본 연구에서는 측 정모형(Measurement Model)과 이론모형(Structural Model)을 통하여 모형 간의 인과관계를 파악하는 구조 방정식의 장점을 살려 사고모형을 개발하였고, 비선형회 귀분석과 구조방정식을 이용한 사고예측 모형의 결과를 비교하여 사고발생에 대한 유의 변수들의 설명력을 비교 해보았다.
models
(1)
exp ․ ․ ․ ․
= 1 (equidispersion)
where,
: the dispersion parameter
Poisson
(2)
exp ․ ․ ․ ․
< 1 (overdispersion)
where,
: the dispersion parameter
Negative Binomial
(3)
exp ․ ․ ․ ․
>
1 (underdispersion)
where,
: the dispersion parameter
Gamma Table 1. Accident frequency prediction methods
Goodness-of-fit test
(1)
≤ ≤
where, log likelihood function restricted log likelihood
Likelihood ratio
(2)
where, : Dependent variable : The fitted value Y
MPB
(3)
where, : Dependent variable : The fitted value Y
MAD
(4)
RMSE =
where, : Dependent variable : The fitted value Y n :Validation data sample size
RMSE Table 2. Goodness-of-Fit for regression models
Ⅱ. 모형개발 이론 고찰 1. 비선형 회귀분석
신호교차로에서의 사고건수가 포아송 분포를 따른 다는 가정하에 번째 신호교차로에서 개의 변수에 의 해 사고가 발생할 확률의 일반식은 Table 1의 식(1)과 같다. 다시 말해서, 포아송 회귀모형은 종속변수가 일정 기간 동안 주어진 사건의 발생 횟수를 나타낸 것이며, 모 형계수인 는 Maximum-Likelihood 평가를 통해 계 산된 것이다.
교통사고는 불연속적이며 임의적, 산발적으로 발생하 는 특징을 가지고 있기 때문에 이러한 특징을 반영할 수 있는 모형으로 포아송 회귀모형이 대표적이다. 하지만 포아송 회귀모형은 평균과 분산이 동일하다는 전제가 이 루어질 때에만 적절하다. 포아송 회귀모형에서 the dispersion parameter()는 모형계수의 분산을 실제보 다 과소 또는 과다 예측되는 것을 나타내게 된다. 또한 이 것은 일부 변수들의 중요도를 과장하여 나타내는 결과를 초래하기도 한다. 자유도, n-p등에 의해 구분되는 모수를 포함하고 있는 모형의 편차는 과분산인지의 여부를 결정 할 수 있는 수치를 제공하는 것이다. 과분산은 조사되지 않은 다른 성질의 구간이 다양한 결과를 나타내기 때문이 며 분산이 포아송 분포보다 더 크거나 더 작은 경우는 포 아송 회귀모형이 적합하지 않음을 나타낸다. 따라서 과분 산 문제를 해결하기 위해 과분산 파라미터가 1보다 작으 면 음이항 회귀모형이 적합하며, 과분산 파라미터가 0에 가까우면 평균과 분산이 같아져 포아송 회귀모형이 적합 하다. 음이항 회귀분석은 분산을 나타내는 과분산이 포함 된 2차식의 형태이므로 식(1)과 같은 형태를 가진다.
․
(1)
여기서 K는 과분산계수이며, 그 분산은 식(2)를 통해 주어진다.
(2)
이와는 다르게 과분산 파라미터가 1보다 크면 감마분포 가 적합한 결과를 얻을 수 있다. Table 1은 포아송 회귀 모형식, 음이항 회귀모형식, 감마 회귀모형식을 나타낸다.
최종적으로 개발된 모형에 대하여 모형의 적합성을 검증하기 위해 (우도비)를 사용하며, 는 0과 1사이 의 값을 갖는데 1에 가까울수록 적합도가 높은 모형이라 고 할 수 있다. 그러나 교통사고분석의 특성상 교통사고 와 도로시설의 관계에 대한 모형의 값은 0.2와 0.4사 이의 값만 가져도 추정된 모형이 아주 좋은 적합도를 가 지는 것으로 평가할 수 있다(McFadden, 1976).
모형의 실제사고건수와 예측건수를 비교하기 위해서 일반적으로 MPB(Mean Prediction Bias)와 MAD
Figure 2. Structural equation modeling procedure flow (Mean Absolute Deviation)가 사용된다. MPB는 모 형을 만들기 위하여 종속변수로 사용된 자료에 대해서 모형에 의한 결과 값의 치우침 정도를 판단할 수 있는 기준을 제공해준다. 이 방법에 의한 결과 값이 작을수록 모형의 예측 값은 정확한 것을 의미한다. 또한 MAD는 모형의 예측 값이 평균적으로 얼마만큼의 오차가 포함 되었는지를 판단할 수 있는 척도를 제공해준다. 이 방법 이 MPB와 다른 점은 각 수치의 음과 양의 차이로 인해 상쇄되지 않는다는 점이다. 결과 값이 0에 가까울수록 실제로 관측된 자료에 부합되는 결과를 나타냄을 의미 한다.
2. 구조방정식
많은 변수를 사용하여 요약된 정보는 얻어내고자 할 때 요인분석을 사용한다. 요인분석(Factor Analysis) 은 여러 변수들 사이의 상관관계를 바탕으로 하여 정보 의 손실을 최소화하면서 변수의 개수보다 적은 수의 요 인(factor)으로 자료 변동을 설명하는 다변량 분석기법 이다. 요인으로 나누어진 변수들을 구조방정식을 이용하 여 모형의 해석 및 적합성을 알아내는 것이다.
구조방정식은 SEM(Structual Equation Model) 이라고 하는데 구성개념 간의 이론적인 인과관계와 상관 성의 측정지표를 통한 경험적 인과관계를 분석할 수 있 도록 개발된 통계기법이다. 다시 말해 확인요인분석을
통해서 측정오차가 없는 잠재요인을 발견하고 회귀분석 으로 잠재요인 간을 연결하는 방법으로 이해하면 된다.
연구자는 이를 통해 다중변수관계를 포괄적으로 측정하 고 탐색적인 분석에서 확인적인 분석까지 할 수 있다 (Kim K. S., 2010).
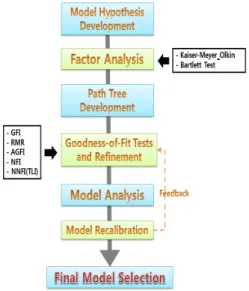
구조방정식3의 모형개발 절차는 Figure 2와 같다.
모형과 연구가설 개발 다음 절차로 자료를 수집 후 분석 이 진행된다. KMO and Bartlett's Test는 수집된 자 료가 요인분석에 적합한지 여부를 판단하기 위한 통계적 인 과정이라고 할 수 있으며, Bartlett-검정은 뺵귀무가 설(H0) : 모상관행렬은 단위행렬이다.뺶여부를 판단하 는 것이다.
KMO(Kaiser-Meyer-Olkin)의 MSA(Measure of Sampling Adequacy)는 0.5이상이면 요인 분석을 계 속 진행 할 수 있다는 것을 나타내며, Bartlett-검정은 0.05이하이면 요인 분석을 계속 진행 할 수 있다는 것을 나타낸다. 또한 연구 데이터의 Rotation Component Matrix(a)(회전후 요인부하량)를 이용하여 연구모형을 개발할 수 있으며 그에 따른 연구가설을 설정할 수 있다.
요인분석의 과정을 거친 후 분석된 요인으로 자료파일을 불러온 상태에서 구조방정식모형 분석 패키지를 이용하 여 경로도형을 구축한다.
모형의 분석 및 인정(model identification)평가 단 계에서는 모형이 가치 있는 모형으로 받아들여질지 여부 를 평가하는 것을 말한다. 다시 말해서 모형을 수집된 자 료에 적용해 볼 수 있는지를 심사하는 과정이라고 할 수 있다. 모형의 적합도 지수에 의해서 모형의 적합도가 만 족하는 모형을 선정한 후 연구자는 각 추정치에 대한 해 석을 하고 결론을 논리적으로 도출한다. 이는 회귀분석 에서 분산분석표를 통해서 회귀모형의 유의성을 판단한 다음 각 변수의 유의성은 t값을 통해서 판단하는 절차와 동일하다고 하겠다.
인정평가를 통해 낮은 적합도가 명시될 경우 모델의 적합도를 개선하는 설명 가능한 또는 타당한 근거가 바 로 Modification Indices이다. 모형의 Modification Indices의 Covariances Data 중 M.I.를 검토하여 연 구모형을 수정할 수 있으며, 수정지수 처리할 때 주의할 사항은 논리적으로 변수간의 관계가 타당한지 여부를 고 려하여야 한다는 것이다. 즉, 공분산이 존재할 개연성이 있을 때 처리해야 하며, 연결하는 것이 비논리적이라면 연결하지 않도록 하여야 한다. 앞에서 기술한 단계를 거 쳐 연구자는 최종모형을 선정할 수 있다.
Fit Measures Worst Model
Titration Model
Optimum Model
Absolute Fit Measures
sig.> =
0.1
sig.> =
0.1
sig.> =
0.1 GFI
(Goodness of Fit Index)
0 above 0.9 1
AGFI
(Adjusted GFI) 0 above 0.9 1
Incremental Fit Measures
RMR (Root Mean-Square
Residual)
below
0.1 below 0.1 0 NFI
(Normed fit Index) 0 above 0.9 1 NNFI(TLI)
(Non-Normed fit Index)
0 above 0.9 1
Kim K. S.,(2010), AMOS 18.0 Table 3. Goodness-of-fit indexes
Variables Min. Max. Avg.
Frequency Accident Frequency for
4_lagged intersections 0 11 1.89
Lane Major·Minor Lane Major 1 4 2.82
minor 1 4 1.91 Entrances Major·Minor Entrances Major 0 9 1.66 minor 0 7 1.60 Lane_Left Major·Minor Lane_Left Major 0 2 1.23 minor 0 2 0.68 Lane_Right Major·Mino
Lane_Right
Major 0 2 0.82 minor 0 2 0.64 Cross walk Major·Minor Crosswalk
(none=0, yes=1)
Major 0 1 0.95 minor 0 0 0.85 Speed Major·Minor Speed
(Range 20-)
Major 2 3 2.72 minor 1 3 2.33 Lighting Major·Minor Lighting
(none=0, yes=1)
Major 0 1 0.87 minor 0 1 0.74 Traffic
Islands
Major·Minor Traffic Islands (none=0, yes=1)
Major 0 1 0.21 minor 0 1 0.48 Bus Stops Major·Minor Bus Stop
(none=0, yes=1)
Major 0 1 0.33 minor 0 1 0.13 Channelization Major·Minor Channelization
(none=0, yes=1)
Major 0 1 0.39 minor 0 1 0.38 ADT LN[Major·Minor ADT](vph) Major 7.9 10.4 9.04 minor 7.1 10.1 8.27 HV LN[Major·Minor Heavy
Vehicle](vph)
Major 7.0 9.5 8.09 minor 5.3 9.0 7.49 Table 4. Main explanatory variables
앞서 언급한 모형의 적합성 인정평가방법에는 절대부 합지수와 증분적합지수, 간명부합지수 등을 이용한다.
절대적합지수는 (카이제곱), GFI(Goodness of Fit Index, 적합도지수), AGFI (Adjusted GFI, 조정된적 합지수), RMR(Root Mean-Square Residual, 평균 제곱잔차제곱근)이 있으며, 증분적합지수는 NNFI(Non- Nonmed Fit Index, 비표준적합지수)가 있다. 간명적합 지수는 PGFI (Parsimonious Goodness-of-Fit Index, PGFI, 간명기초적합지수), PNFI (Parsimonious Normed- of-Fit Index, 간명표준적합지수), AIC(Akaike Information Criteria)가 있다.
그러나 앞에서 언급한 몇 가지 지수에 대한 판단기준 은 학자마다 의견이 서로 다르기 때문에 기본적인 요건 을 만족하지 못하는 경우 본 연구에서는 Table 3과 같 은 기준을 설정하여 모형의 적합성을 판단할 수 있도록 하였다.
Ⅲ. 연구모형 개발 1. 사고 자료의 수집 및 정리
본 연구에서는 지방부 국도변 4지 신호교차로의 교통 량 및 도로시설 및 환경을 조사하여 총 117개 교차로 데 이터를 취득하였다. 모형 개발에 사용한 변수로는 사고 빈도를 포함하여 주·부도로의 차선수, 주·부도로 진출입 로 수, 주·부도로 좌회전 전용 차선수, 주·부도로 우회전 전용 차선수, 주·부도로 횡단보도 유무, 주·부도로 제한 속도, 주·부도로 가로등 유무, 주·부도로 교통섬 유무,
주·부도로 버스정류장 유무, 주·부도로 도류화 유무, 주·
부도로 교통량, 주·부도로 중차량이다. 다음과 같은 24 개의 변수를 독립변수로, 총 사고빈도를 종속변수로 하 였으며 이 중 교통량과 중차량은 LN을 사용하여 변수의 자리 수를 맞추었다. 또 제한속도 또한 20km/h를 범위 로 척도를 변환하여 분석하는데 이용하였다.
2. 비선형 회귀분석 모형 개발
지방부 4지 신호교차로의 사고예측 모형을 개발하기 위하여 통계패키지인 LIMDEP 8.0을 이용하여 분석하 였다. 선정되는 독립변수에 따라 종속변수에 영향을 미 치기 때문에 모형의 설명력에 큰 차이가 난다. 상관성이 과도하게 떨어질 경우 변수의 신뢰성이 낮아지기 때문에 독립변수의 중복을 방지하고 각 변수의 독립성을 위해서 상관관계를 사전분석하고, Type I 에러와 Type II 에러 를 고려하여 신뢰수준 90%(=0.1)에서 모형개발을 하였다. 모형개발결과, 도로의 기하구조와 관련한 다수 의 변수 중 부도로 차선수, 주도로 우회전 전용 차선수, 횡단보도 유무, 제한속도, 가로등 유무, 버스정류장 유 무, 교통량이 선정되어 모형으로 개발되었다. 모형식결 정과 관련해서는 과분산(Overdispersion)검증을 수행
Kaiser-Meyer-Olkin Measure of Sampling
Adequacy. 0.726
Bartlett's Test of Sphericity
Approx. Chi-Square 674.667
df 66
Sig. 0.000
Table 6. KMO and bartlett's test
Component
1 2 3 4
Major Lane .255 .731 .205 .172
Manor Lane .797 .262 .163 .184
Major Lane_Left - .202 .461 .719 .046 Manor Lane_Left .528 .057 .684 .009 Major Lane_Right .002 .074 .842 .057 Manor Lane_Right .530 - .028 .693 .032 Major Speed - .164 .171 .003 .873 Manor Speed .407 -.108 .117 .767
Major HV .309 .816 .004 .015
Manor HV .712 .337 .059 .005
Major ADT .197 .876 .055 .032
Manor ADT .781 .100 .003 .043
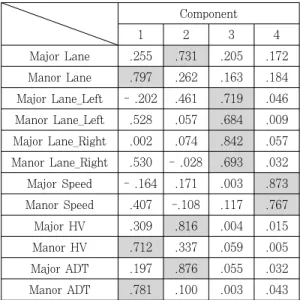
Table 7. Rotation component matrix
Variables Final Model
Constant
Coefficient -2.617
t-ratio -1.723
p-value 0.085
Minor Lane
Coefficient 0.284
t-ratio 3.327
p-value 0.001
Major Lane_Right
Coefficient -0.190
t-ratio -1.892
p-value 0.059
Major Crosswalk
Coefficient -0.557
t-ratio -2.258
p-value 0.024
Major Speed
Coefficient 0.552
t-ratio 3.252
p-value 0.001
Major Lighting
Coefficient -0.518
t-ratio -2.381
p-value 0.017
Minor Lighting
Coefficient -0.336
t-ratio -1.905
p-value 0.057
Major Bus Stop
Coefficient -0.303
t-ratio -1.953
p-value 0.051
ADT (Major+Minor)
Coefficient 0.274
t-ratio 1.690
p-value 0.091
Overdispersion 0.000167
Table 5. Poisson regression results
한 결과, 평균과 분산의 차이가 거의 없어 음이항 모형보 다 포아송 모형이 더 적합한 것으로 나타났다.
모형 결과, 최종모형에는 부도로 차선수, 주도로 우회 전 전용 차선수, 주도로 횡단보도, 주도로 제한속도, 주 도로 가로등, 부도로 가로등, 주도로 버스정류장, ADT (주도로+부도로)가 유의한 설명변수들로 선정되었다.
Table 5는 지방부 4지 신호교차로 대상자료를 통해 나 온 포아송 회귀모형의 결과를 보인다.
3. 구조방정식 모형 개발
데이터 수집을 통해 입력한 원자료는 분석을 위해 SPSS 20을 이용하였다. KMO and Bartlett's Test 및 Bartlett-검정 분석 결과는 Table 6과 같다.
KMO(Kaiser-Meyer-Olkin)의 MSA(Measure of Sampling Adequancy)는 0.726으로 분석되어 MSA
> α = 0.500를 만족하므로 요인분석을 계속 진행할 수 있다는 결론이 도출되었으며, Bartlett-검정 또한 Sig.(p)
=0.000 < α= 0.05이므로 단위행렬이 아니라는 충분 한 증거를 보여주고 있다. 따라서 본 연구의 데이터는 KMO의 MSA와 Bartlett-검정 모두를 만족하므로 요인분석을 계속하여 진행 할 수 있다는 결과가 도출 되었다.
본 연구의 연구모형 및 연구가설을 개발하기 위하여 Rotation Component Matrix(회전후 요인부하량)분 석을 시행하였다. 분석결과 주도로의 차선수, 중차량, 교 통량이 요인1, 부도로의 차선수, 중차량, 교통량이 요인 2에 속하였고 요인 3으로는 주·부도로 좌회전 전용 차선 수, 주·부도로 우회전 전용 차선수가, 요인 4는 주·부도 로의 제한속도가 속해 있는 것을 Table 7을 통해 확인 할 수 있다.
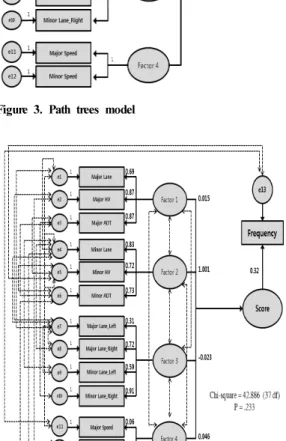
Table 7의 Rotation Component Matrix(회전후 요인부하량) 분석 결과를 이용하여 각 요인이 사고발생 정도에 영향을 미칠 것이라는 연구모형 가설을 설정할 수 있으며 Table 7의 Rotation Component Matrix (회전후 요인부하량)와 연구가설의 결과를 반영하여 경 로모형은 AMOS 20을 이용하여 Figure 3과 같이 구축 하였다.
Fit Measures
Worst Model
Titration Model
Basic Model
Final Model
Absolute Fit Measures
sig.> = 0.1
sig.> =
0.1 0.000 0.233 GFI 0 above 0.9 0.814 0.948 AGFI 0 above 0.9 0.698 0.873 RMR below 0.1 below 0.1 0.061 0.037 Incremental
Fit Measures
NFI 0 above 0.9 0.734 0.941 NNFI
(TLI) 0 above 0.9 0.705 0.981 Table 8. Goodness-of-Fits for the final model
formula
Score 0.015*Factor1+1.001*Factor2+
(-0.023)*Factor3+0.046*Factor4 Factor1 Major Lane*0.687+Major HV*0.870
+Major ADT*0.872
Factor2 Minor Lane*0.834+Minor HV*0.724 +Minor ADT*0.733
Factor3
Major Lane_Left*0.311+Minor Lane_Left*0.716+ Major Lane_Right*0.592+
Minor Lane_Right*0.912 Factor4 Major Speed*0.056+Minor Speed*7.127 Table 9. Weights for the latent factors
Figure 3. Path trees model
Figure 4. Standardized estimates for the final model
분석결과 기초모형은 , RMR, GFI, AGFI, RMR, NFI, NNFI 모두 적정모형 기준에 미치지 못하 였다.
이에 본 연구에서는 Modification Indices의 Covariances 를 이용하여 최적모델에 가장 부합할 수 있도록 모형을 수정하였다. Modification Indices의 Covariances데 이터를 이용하여 총 2번의 수정을 통해 본 연구의 최종 모형이 설정되었으며, 그 결과는 Figure 4와 같다.
Figure 4의 최종모형의 분석결과 RMR이 0.037로 본 연구에서 설정한 충족 여건을 만족하였을 뿐만 아니 라 : 0.233, GFI: 0.948, AGFI: 0.873, NFI:
0.941, NNFI: 0.981로 모든 부합지수가 적정모형의 충족 요건을 만족하는 것으로 분석되었다. 특히 NNFI (TLI)와 같은 경우는 최종모형이 0.981의 높은 값으로 최적모형에 만족하는 것으로 분석되었다. 인정평가 분석 수치는 Table 8 확인 할 수 있다.
최종 모형에 대한 Standardized estimates분석 결 과를 요약하면 Figure 4와 같이 나타낼 수 있으며, 잠재 요인을 수식화하여 표현하면 Table 9과 같이 나타낼 수 있다.
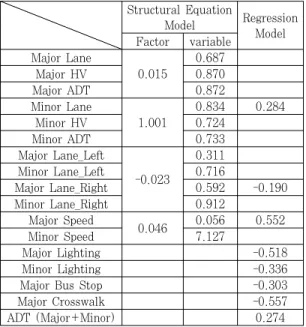
모형 결과, 총 4개의 Factor으로 구분되었으며 Factor 1: 0.015, Factor 2: 1.001, Factor 3: -0.023, Factor 4: 0.046으로 사고발생에 영향을 주는 것으로 나타났다. Factor 1은 주도로와 연관되는 변수로써 0.015로 가중치가 낮게 분석 되었지만 많은 논문의 사 고예측모형 변수로 분석된다는 점과 다른 변수와 인과관 계가 높다는 점에서 결코 무시할 수 없는 요인이다. 주도 로 차선수, 주도로 중차량, 주도로 교통량이 0.687, 0.870, 0.872로 세 변수 중에서는 교통량이 가장 큰 영 향을 미치는 것으로 나타났다. Factor 2는 부도로와 연
Structural Equation
Model Regression
Model Factor variable
Major Lane
0.015
0.687
Major HV 0.870
Major ADT 0.872
Minor Lane
1.001
0.834 0.284
Minor HV 0.724
Minor ADT 0.733
Major Lane_Left
-0.023
0.311
Minor Lane_Left 0.716
Major Lane_Right 0.592 -0.190
Minor Lane_Right 0.912
Major Speed
0.046 0.056 0.552
Minor Speed 7.127
Major Lighting -0.518
Minor Lighting -0.336
Major Bus Stop -0.303
Major Crosswalk -0.557
ADT (Major+Minor) 0.274
Table 10. Comparison of the regression and structural equation model
관된 변수로 부도로 차선수와 부도로 중차량, 부도로 교 통량이 영향을 주었다. Factor 1과 비교하면 주도로와 부도로의 차이 외에 변수의 차이가 없는 것으로 나타났 다. 차선수와 중차량 수와 교통량은 노출과 관계가 있는 데 노출이 사고빈도에 많은 영향을 주는 것으로 분석된 다. Factor 3은 –0.023으로 차량의 선회와 관련된 변 수로 사고발생 정도에 음(-)적 영향을 보이는 변수로 나 타났다. 이는 차량의 선회에 대한 대책을 마련한다면 사 고빈도를 줄일 수 있다는 것을 보여준다. 마지막을 Factor 4는 0.046으로 주도로와 부도로의 제한속도로 구성되었다. 특히 부도로가 7.127로 높은 값을 보였는 데 이는 교차로에서 주도로와 부도로의 속도 위계 차이 가 없다면 사고에 영향이 있다고 나타난 것이다.
4. 모형 결과에 대한 비교·분석
비선형 회귀모형은 유의한 소수의 설명변수들을 가지 고 사고를 직접 예측하는 반면, 구조방정식은 상관관계 가 높은 변수끼리 Grouping하여 요인들을 나눈 후 종속 변수인 사고빈도와의 관계를 회귀모형으로 나타내는 이 중구조를 가지고 있다. 따라서 비선형 회귀모형과는 방 법이 다른 요인분석이라는 과정을 거쳐 가중치를 구하기 때문에 두 모형의 가중치를 서로 비교하는 것은 큰 의미 를 가지고 있지 않다.
따라서 본 연구에서는 비선형 회귀모형과 구조방정식 모형의 유의성을 판단하고 가중치의 크기를 비교하기보 다는 두 모형에서의 변수들이 사고발생 빈도에 양(+)적 영향과 음(-)적 영향 중 어떠한 영향을 미치는지 확인 · 비교하였다.
구조방정식에 의한 모형과 비선형 회귀모형에서 사고 빈도 예측에 선정된 변수와 그 가중치를 비교하면 Table 10과 같다.
구조방정식에 의한 예측모형에서는 주도로 차선수, 중차량, 교통량과 부도로 차선수, 중차량, 교통량이 사고 발생에 양(+)적 영향을 주는 것으로 나타났으며 비선형 회귀모형에서도 부도로 차선수와 ADT(주도로+부도로) 가 사고발생에 양(+)적 영향을 주는 것으로 나타났다.
이는 교차로에 차량 노출이 많을수록 사고발생 확률이 높아지는 것을 나타낸다. 청주시의 4지 신호교차로로 사 고예측모형을 개발한 Park B. H. (2008)의 다수 논문 에서도 교통량은 사고빈도에 양(+)적 영향을 주는 것으 로 분석한 바 있고, Lau and May(1988) 논문에서도
교차로 차량 노출관련 변수가 양(+)적 영향을 주는 것 으로 나타났다. 교통량 뿐만 아니라 교차로에서의 차량 노출과 연관된 변수는 사고발생을 증가시키는 요인이라 고 볼 수 있는 것이다.
또 구조방정식 모형에서 주·부도로 제한속도와 비선형 회귀모형에서 주도로 제한속도가 사고발생을 증가시키는 것으로 나타났는데 차량속도는 증가할수록 운전자가 돌 발 상황 발생 시 제동거리가 증가하여 사고 발생확률을 높일 뿐만 아니라 주도로와 부도로의 속도 위계가 구분이 되지 않을 경우 주도로에 대한 인지가 낮아져 사고에 양 (+)적 영향을 준다. Garrentt D. B. and Thomas H.
M. (2006)의 연구에서도 제한속도가 높으면 차량운전 자가 돌발상황 발생 대처가 어려우며 제동거리는 증가하 여 사고발생확률을 높인다고 하였다. 이를 해결하기 위 해서는 과도한 차량 제한속도는 낮추고 주·부도로의 속 도 위계를 설정하여 사고를 줄여야 할 것이다.
그에 반해 구조방정식에서는 주·부도로 좌회전 전용 차선수와 주·부도로 전용 우회전 전용 차선수가 사고발생 에 음(-)적 영향을 나타내었고 비선형 회귀모형에서는 주 도로 우회전 차선수와 주·부도로 가로등, 주도로 버스정 류장, 주도로 횡단보도로 나타났다. 우선 좌·우회전 전용 차선수는 차량 선회와 관련된 변수로 대향차랑 및 동일한 방향의 직진차량과 구분하여 전용차로로 이동함으로써 후면추돌사고와 측면추돌사고 발생확률을 감소시키는 것
으로 분석된 것이다. 전용차로에 관한 변수가 사고발생을 감소시킨다는 것은 지방부를 대상으로 사고빈도 예측모 형을 개발한 Kim D. H. (2008)의 논문, Harwood et al. (2002)과 Vogt (1999)의 연구 다수에서 분석된 바 있다. 이외 비선형 회귀모형에서만 선정된 변수를 보면 교 차로 야간운전 시에 운전자에게 가시범위가 한정되어 있 어, 돌발 상황에 대한 충분한 조치가 어렵다. 주·부도로의 가로등이 바로 야간 시야 확보를 도와줌으로 사고발생 빈 도를 감소하는 요인으로 작용하는 것이다. 이 외에도 교차 로 내에 설치된 버스정류장과 횡단보도가 교통사고 발생 빈도에 영향을 미침을 모형식에서 확인 할 수 있다.
구조방정식 모형과 비선형 회귀모형 비교를 통해 두 모형의 변수가 교통사고빈도를 예측하는 설명이 다르지 않음을 확인할 수 있다. 하지만 구조 방정식 모형을 개발 할 때 요인분석에서 명목척도는 측정할 수 없으며 간격척 도 혹은 비율척도에 의해 측정된다는 점과 비선형 회귀모 형이 사고의 예측력을 높이기 위해 소수의 유효한 설명변 수만을 모형에 포함시킨다는 점 때문에 선정된 변수가 달 라지는 것을 확인 할 수 있다. 이 점에서 사고 데이터 수 집 과정에서 변수를 간격척도 혹은 비율척도로 수집이 이 루어진다면 사고 예측을 설명하는데 두 모형이 다르지 않 기 때문에 구조방정식이 더 많은 설명이 가능하다.
Ⅳ. 결론 및 향후 연구과제
도로구간의 교통사고가 줄어드는 반면 교차로에서의 사고는 해마다 증가하고 있어 사회·경제적으로 많은 손 실을 보고 있다. 또한 사고는 인적요인, 환경적 요인, 차 량자체요인으로 구분하는데 차량자체 요인이나 인적요인 으로 인한 사고발생보다는 도로 환경적 요인으로 인한 사고가 매우 높은 것으로 나타나고 있어 교차로에서의 사고발생 원인을 규명하고 안전성을 증대시키기 위해 지 방부 4지 신호교차로의 안전성을 평가할 수 있는 모형을 개발하였다. 현재 주를 이루고 있는 연구 되어진 사고예 측 모형들은 비선형 회귀분석으로, 사고의 예측력을 높 이는데 중점을 두고 이를 위해 소수의 유효한 설명변수 들만을 모형식에 포함시키기 때문에 사고발생의 설명변 수들을 규명하는데 구조적인 한계를 가지고 있다. 반면, 구조방정식은 사고와 설명변수들 간의 인과관계를 규명 하는데 많은 장점을 가지고 있지만, 사고빈도의 예측력 에 있어서는 기존 비선형 회귀모형에 비교하여 우수하다 고 단정 지을 수는 없다.
본 연구에서는 비선형 회귀방법과 구조방정식방법의 장단점을 비교하여 우열을 결정하기보다는 각각의 특성 을 설명하고 교통운영자가 필요에 따라 선택할 수 있는 모형 선택의 다양성을 보여주고자 하는 목적에서 연구를 시작했다. 예로서 사고의 빈도를 예측하고자 할 경우에 는, 소수의 설명변수만을 가지고 보다 높은 예측을 가능 케 하는 비선형 회귀방법을 선호할 수 있고, 반면 보다 많은 설명변수들의 설명력을 찾고자 할 경우에는 여러 변수를 하나의 요인으로 포괄적으로 묶어 많은 변수로 사고를 설명할 수 있는 구조방정식의 유의성을 선호할 수도 있을 것이다. 따라서 이러한 통계분석 방법들 간의 차이는 사용자의 선택 사안이라고 생각한다.
본 연구에서는 구조방정식 모형과 비선형 회귀모형을 개발하여 각 주요 설명변수들이 사고에 영향을 미치는 설명력을 분석하였다. 구조방정식 모형은 총 12개의 변 수가 4개의 요인으로 나누어 분석되었으며 비선형 회귀 모형은 8개의 변수로 모형이 구성되었다. 구조방정식 모 형과 비선형 회귀모형이 나타내는 변수의 설명은 계수의 값의 차이는 있었지만 사고빈도를 설명하는데는 동일한 분석이 되었다. 이들 설명변수들을 살펴보면 교통량, 주 부도로 차선수, 중차량 비율 등 교통 Exposure관련 변 수들, 차량의 운행속도를 제한하는 속도관련 변수들, 차 량의 회전과 관련한 좌우회전 전용차선 관련 변수들, 그 리고 야간의 야간 시야 확보에 도움이 되는 가로등 유무, 교차로내외에 설치되는 버스정류장과 횡단보도관련 변수 들은 사고의 위험성과 관련이 깊은 설명변수들인 것으로 판단되어 이들 변수들에 대한 면밀한 주의가 필요할 것 으로 판단된다.
향후 연구과제로는 지방부 4지 신호교차로 뿐만 아니 라 지방부의 다양한 도로 유형에서 일어나는 사고분석의 필요성을 제기하고자 한다. 이는 아직 국내의 안전성 관 련 연구가 주요 도로 선진국에 비해 분석기법의 다양성, 응용성 등이 상대적으로 부족하다는 것을 의미한다. 또 한 사고는 기하구조적 요인들 뿐만 아니라 그 외 다양한 요인에 의해서 발생하게 된다. 많은 연구자들이 지적하 고 있는 바와 같이 사고발생에 대한 인적, 기후적 요인들 의 영향력 분석 역시 구체적으로 이루어져야 할 것이다.
ACKNOWLEDGEMENTS
This work was supported by National Research Foundation of Korea Grant funded by the Korean
Government(Ministry of Education, Science and Technology.(2012R1A1A4A01010102)
REFERENCES
Bauer K. M., Harwood D. W. (1996), Statistical Models of At-grade Intersection Accident, Federal Highway Administration, FHWA-RD-96-125.
Garrett D. B., Maze T. H. (2006), Rural Expressway Intersection Characteristics as Factors in Reducing Safety Performance, Transportation Research Board, TRB, Record 1953, pp.71-80.
Ha O. G. (2005), Development of Accident Prediction Models and Accident Injury Severity for Rural Signalized Intersections, Hanyang University graduate school, A master Dissertation.
Ha T. J., Kang J. K., Park J. J. (2001), Development and Application of Traffic Accident Forecasting Model for Signalized Intersections -Four-Legged Signalized Intersections In Kwang-Ju-, J. Korean Soc. Transp., Vol.19, No.6, Korean Society of Transportation, pp.207-218.
Harwood D. W., Council F. M., Hauer E., Hughes W.
E., Vogt A. (2002), Prediction of the Expected Safety Performance of Rural Two-Lane Highways, Federal Highway Administration, FHWA-RD-99-207.
Hong J. Y., Doh C. W. (2002), Development of a Traffic Accident Prediction Model and Determination of the Risk Level at Signalized Intersection, J. Korean Soc. Transp., Vol.20, No.7, Korean Society of Transportation, pp.155-166.
Kim D. H., Lee D. M., Sung N. M.(2010), A Development of Traffic Crash Frequency Prediction Models for Rural 3-Legged Intersections, Journal of Transport Research, Vol.17, No.1, The Korea Transport Institute, pp.36-48.
Kim E. C., Lee D. M., Kim D. H. (2008), Development of Traffic Accident Frequency Model for Evaluating Safety at Rural Signalized Intersections, J. Korean Soc. Transp., Vol.10, No.4, Korean Society of Road Engineers, pp.53-63.
Kim K. S. (2010), AMOS 18.0, Hannarae Academy.
Korea
Kim S. R., Bae Y. K., Jeong J. H., Kim H. J. (2011), Factor Analysis of Accident Types on Urban Street using Structural Equation Modeling(SEM), J.
Korean Soc. Transp., Vol.29, No.3, Korean Society of Transportation, pp.93-101.
Kim W. C., Lee S. B., Namgung M, Hirofumi I. (2001), Constructing Method of Traffic Accidents Prediction Model for Safety Evaluation at Intersections, KSCE Journal of Civil Engineering, Vol.21, No.4-D, korean society of civil engineers, pp.427-435.
Lau M. Y., May A. D. (1988), Accident Prediction Model Development for Intersection : Final Report, California Department of Transportation, ITS-UCB-RR-88-7.
Lee D. M., Kim D. H. (2008), Development of Traffic Accident Frequency Prediction Models at Rural Four Legged Non-Signalized Intersections, Journal of Transport Research, Vol.15, No.2, The Korea Transport Institute, pp.17-26.
Lee H. S., Lim J. H. (2011), SPSS 18.0 Manual, Korea.
Lee J. Y., Chung J. H., Son B. S. (2008), Analysis of Traffic Accident Severity for Korean Highway Using Structural Equations Model, J. Korean Soc.
Transp., Vol.26, No.2, Korean Society of Transportation.
pp.17-24.
McCoy P. T., Malone M. S. (1989), Safety Effects of Left-Turn Lanes on Urban Four-Lane Roadways, Transportation Research Board, TRB, Record 1239, pp.17-22
Neter J., Michael H. K., Nachtsheim C. J. William W.
(1996), Applied Linear Statistical Models-four edition, A Division of the McGraw-Hill Companies.
USA
O I. S., Kim S. S., Sin C. H.(2007), Development of Traffic Accident Forecasting Model for Signalized Intersections -Focusing National Highway in Kyonggi Province-, The 57th Conference of Korean Society of Transportation, Korean Society of Transportation, pp.315-322.
Oh J. T., Kim D. H., Lee D. M. (2012), Development of the Expected Safety Performance Models for Rural Highway Segments, Journal of the Korean
Society of Road Engineers, Vol.14, No.2, Korean Society of Road Engineers, pp.131-143.
Park B. H., Han S. W., Kim T. Y., Kim, W. H. (2008), Traffic Accident Models of Cheongju Four-Legged Signalized Intersections by Accident Type, J.
Korean Soc. Transp., Vol.26, No.5, Korean Society of Transportation, pp.53-162.
Park B. H., Park G. S., In B. C. (2008), Accident Models of 4-Legged Signalized Intersections by Vehicle Type in the Case of Cheongju(2008), Journal of the Korean Society of Road Engineers, Vol.10, No.4, Korean Society of Road Engineers.
pp.161-170.
Park J. S., Kim T. Y., Yu D. S. (2007), Correlation Analysis and Estimation Modeling Between Road Environmental Factors and Traffic Accidents -The
Case of a 4-legged Signalized Intersections in Cheongju-, J. Korean Soc. Transp., Vol.25, No.2, Korean Society of Transportation. pp.63-72.
Park J. T., Lee S. B., Kim J. W., Lee D. M. (2008), Development of a Traffic Accident Prediction Model for Urban Signalized Intersections, J.
Korean Soc. Transp., Vol.26, No.4, Korean Society of Transportation, pp.99-110.
Poch M., Mannering F. L. (1996), Nagative Binomial Analysis of Intersection Accident Frequencies, Journal of Transportation Engineering, ASCE, Vol.122, No.2, pp.105-113
Vogt A. (1999), Crash Models for Rural Intersection:
Four-Lane by Two-Lane Stop Controlled and Two-Lane Signalized, FHWA-RD-98-128.
알림 : 본 논문은 제 14회 한국도로학회 학술대회 (2012.09.26.)에서 발표된 내용을 수정.보완 하여 작성된 것입니다.
♧ 주 작 성 자 : 오주택
♧ 교 신 저 자 : 오주택
♧ 논문투고일 : 2012. 8. 9
♧ 논문심사일 : 2012. 11. 6 (1차) 2012. 12. 11 (2차) 2013. 1. 7 (3차)
♧ 심사판정일 : 2013. 1. 7
♧ 반론접수기한 : 2013. 6. 30
♧ 3인 익명 심사필
♧ 1인 abstract 교정필