논문 2016-53-2-7
Saliency Map 다중 채널을 기반으로 한 개선된 객체 추출 방법
( Enhanced Object Extraction Method Based on Multi-channel Saliency Map )
최 영 진*, 퀴 런*, 김 광 락**, 김 형 중*
( Young-jin Choiⓒ, Run Cui, Kwang-Rag Kim, and Hyoung Joong Kim )
요 약
영상으로부터 중요 객체를 구하는 Saliency Map은 현재 영상처리 분야에서 가장 활발한 연구 분야이다. 이와 관련한 여러 연구가 진행되어가고 있으나 Saliency Map의 객체를 추출하는 것이 어려운 상황이다. 본 논문에서는 제안하는 SLIC와 색상차, 영역간 거리, texture 정보를 이용하여 객체 추출하는 방법으로 Saliency Map을 개선하고자 한다. 실험결과는 본 논문에서 제 안하는 방법을 통해 영상의 모든 영역이 아닌 중앙에 있는 영역을 중점으로 주요 객체를 추출하는 결과를 보였다.
Abstract
Extracting focused object with saliency map is still remaining as one of the most highly tasked research area around computer vision for it is hard to estimate. Through this paper, we propose enhanced object extraction method based on multi-channel saliency map which could be done automatically without machine learning. Proposed Method shows a higher accuracy than Itti method using SLIC, Euclidean, and LBP algorithm as for object extraction. Experiments result shows that our approach is possible to be used for automatic object extraction without any previous training procedure through focusing on the main object from the image instead of estimating the whole image from background to foreground.
Keywords: Saliency Map, SLIC, LBP, Object Extraction
Ⅰ. 서 론
영상 분야에서는 ROI(Reason Of Interest or Interest points)라 표현하는 영역이 있다. 이미지와 같은 멀티미 디어로부터 원하는 데이터를 효율적으로 검색하기 위해 서는 영역 분할이나 관심 객체를 자동으로 추출하는 방
*정회원, 고려대학교(Korea University)
**정회원, 삼육대학교(Sahmyook University)
ⓒCorresponding Author(E-mail: [email protected]) Received ;August 20, 2015 Revised ;November 13, 2015 Accepted ; February 02, 2016
법이 연구되어야 한다. 이러한 문제는 기술적으로 어렵 지만 매우 중요한 부분이기 때문에 많은 연구가 진행되 고 있다. 단안 영상 ROI 영역 검출을 위한 Saliency map은 원본 영상 속에서 특정 객체들을 선별하여 Foreground와 Background으로 구분하고 중요 객체를 추출하는데 사용되고 있다.
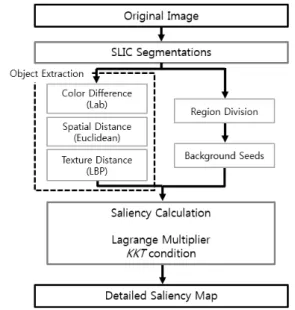
본 논문에서는 Saliency Map을 위한 개선된 객체 추 출 방법을 위하여 SLIC(Simple Linear Iterative Clustering)과 LBP(Complete Locl Binary Pattern)를 이용한다. 먼저 SLIC는 입력 영상을 downscaling하여 edge와 dark shade를 이용하여 객체들을 뚜렷하게 표
그림 1. 원본영상(좌)과 영역분할(우) 화면
Fig. 1. Original Image(left) and Segmented Image (right).
그림 2. 원본영상의 픽셀 수(좌)와 SLIC 슈퍼픽셀 수(우)
Fig. 2. Original Image Pixels(left) and SLIC Algorithm Pixel(right).
현하고, LBP는 히스토그램 기반의 블록간 색상차를 계 산하는 방법이다. 이에 대하여 제안하는 방법은 SLIC을 통한 영역구분 이후, Lab 도메인에서의 색상차, 영역간 거리, texture 정보를 통한 Saliency map을 구성한다.
본 논문의 구성은 다음과 같다. 2절에서는 기존의 영 역분할 방법들과 Saliency Map을 살펴보고, 3절에서는 제안하는 Saliency Map 다중 채널을 기반으로 한 개선 된 객체 추출 방법을 설명 한다. 4절에서는 제안한 방 법을 검증하기 위한 실험 결과를 기술하고, 마지막 5절 에서는 결론을 내린다.
Ⅱ. 관련연구
본 절에서는 기존의 영역분할 방법들과 Saliency Map에 대해 알아본다.
1. 영역분할
본 논문에서 Saliency Map 다중 채널을 기반으로 한 개선된 객체 추출 방법을 제안하고자 한다. 우수한 Edge 추출과 texture 정보를 기반으로 객체를 추출하기 위해 SLIC와 색상차, 영역간 거리, texture 정보를 이용 하고자 한다. 그림 1.은 원본영상이 영역분할 될 경우 보여지는 결과에 대한 예시이다.
그림 3. Watershed 알고리즘(좌)과 SLIC 알고리즘(우)의 Segmentation 결과
Fig. 3. Watershed Algorithm(left) and SLIC Algorithm (right) segmentation comparison.
가. SLIC 알고리즘
기존의 영역분할을 위한 혹은 객체추출을 하기 위해 사용되던 알고리즘들과 다른 분야에서 나온 기법으로, Radhakrishna Achanta는 SLIC(Simple Linear Iterative Clustering)를 제안했다[1].
슈퍼픽셀은 영상에서 그 내부에 edge를 포함하지 않 는 작은 영역을 말한다. 그림 2.와 같이 일반 픽셀보다 슈퍼픽셀의 수가 현저히 적게 나오게 됨에 따라 이후 과정에서의 연산시간을 크게 줄일 수 있다. 모든 슈퍼 픽셀 알고리즘들 중에 Simple linear iterative clustering (SLIC) 기법은 영상 내에 균일하게 Super Pixel들을 대표하는 포인트를 지정하고, 각 포인트로부 터 영상의 모든 픽셀들과의 유사도를 측정하여 군집화 하는 방식이다.
Watershed 알고리즘에서 파생된 Lazy Snapping[2]
과의 큰 차이점은 nearest-neighbor를 검색하지 않고, grid성질을 이용하여 영역분할을 하면서 영상에서의 edge와 dark shade를 이용하여 사물들을 뚜렷하게 표 현하는 기법이다. 간혹 색상으로 인해 SLIC만 가지고서 는 영역 분할하는데 한계가 있다. 이를 보완하기 위해 본 논문에서는 LBP 알고리즘을 함께 활용하기로 한다.
나. LBP 알고리즘
SLIC를 통해 습득한 edge를 영상 속의 객체와 배경 으로 구분하기 위해 Ojala의 LBP(Local Binary Pattern)알고리즘을 이용한다[3]. LBP는 Ojala에 의해 1996년에 처음 소개 되었다. 이 때 소개된 연산자는 중 심픽셀의 값을 이용하여 8개의 이웃의 값을 측정하는 방식으로 작동한다. 기본 아이디어는 얼굴 이미지를 작 은 블록으로 나누어 LBP 히스토그램(Histogram)으로 만들어 히스토그램 간의 거리차이를 이용하여 영상 속 객체를 구별한다. 객체들은 Texture의 구성으로 볼 수 있기 때문에 LBP를 사용하면 객체의 질감 설명이 가능 하다.
그림 4. 원본영상(좌)과 LBP결과(우)
Fig. 4. Original Image(left) and LBP Image(right).
그림 5. 기본적인 LBP Fig. 5. Basic LBP.
LBP는 히스토그램을 이용하여 각 블록간의 색상차 이를 계산한다. 그림 4.를 보면 LBP는 영상의 밝기 변 화와는 무관하게 영상 내 내부 패턴 변화를 표현할 수 있는 장점이 있다. LBP 결과로 객체에 해당하는 Texture 정보를 이용해 객체 간의 식별이 가능함을 알 수 있으며 이는 객체와 배경을 분리하는데 좋은 특징이 된다. 이를 통해 나온 값을 각 픽셀에 Saliency 값을 적 용하여 최종으로 영상에서의 배경과 객체를 구분 할 수 있다.
LBP연산자는 중심픽셀의 값이 3×3의 경계의 값과 바이너리를 고려하여 이미지 각 픽셀의 Label을 지정한 다. 그림 5.와 같이 중심의 값을 이용하여 시계방향 혹 은 시계 반대방향으로 연산을 수행해 하나의 Label에서 0 또는 1의 값을 얻을 수 있다. 중심보다 주변의 값이 크다면 1을 작다면 0을 대입한다.
2. Saliency Map
주의집중 이론은 입력되는 수많은 영상 중 의미 있는 일부 특징만을 선택적으로 선별하여 보다 빠르고 많은 처리를 수행하게 된다는 이론이다. Laurent Itti는 이를 바탕으로 영상 각 영역의 시각적 중요도를 맵의 형태로 표현하는 Saliency Map을 제안하였다[5].
Itti에 의해 Neuromorphic Vision C++ Toolkit(NVT) 이 제안되었고 Walther는 이 모델을 확장하여 Saliency Toolbox(STB)를 만들었다[6]. 이들 모델은 색상, 방향, 밝기 특징을 사용하며 중심-주변 차이(center-surround difference) 연산을 수행하여 돌출지점을 찾아내고 이 지점을 중심으로 일정한 크기의 원을 그려 주의가 가해 지는 영역을 표시하였으며, 시간의 흐름에 따라 승자전
그림 6. Laurent Itti가 제안한 Saliency Map 시스템 흐름 도
Fig. 6. Laurent Itti proposed Saliency Map.
그림 7. 원본영상(좌)과 Itti Saliency Map(우)
Fig. 7. Original Image(left) and Itti Saliency Map(right).
취망(winner-take-all network)을 통해서 다른 영역으 로 주의가 옮겨지도록 한다.
그림 6.과 같이, Itti 방법은 맨 처음 지형적인 특징 지도들의 집합으로 분해한다. 각각의 지도에서 중요한 부분은 주변의 특징들과 확연한 차이로 추출해 낼 수 있다. 모든 특징 지도들은 상향식 방법으로 중요한 특 징이 필터링 되어 Saliency Map을 생성한다.
그림 8. 본 논문에서 제안하는 객체 추출 알고리즘 Fig. 8. Proposed Object Extraction Algorithm.
이 방법은 저단계 특징 즉, 색상, 명암도, 방위 정보 에 대해 각 특징의 스케일이 9단계인 가우시안 피라미 드를 생성하여 조합하므로 연산량이 많은 단점이 있다.
그림 7.과 같이 저단계 특징으로 각각의 특징 지도들 을 생성하고 이들의 평균값으로 Saliency Map을 구성 하므로 노이즈 또는 중요도가 낮은 객체로 마스크된 지 도들은 중요한 영역에 강하게 나타나는 원인이 된다.
본 논문에서는 SLIC와 색상차, 영역간 거리, texture 정보를 이용하여 객체 추출 과정을 개선하여 Itti에 적 용하고자 한다.
Ⅲ. 제안하는 Saliency Map을 위한 개선된 객체 추출 방법
본 논문에서 제안하는 방법은 아래의 그림과 같다.
원본 영상을 받은 후 이를 SLIC의 Segmentation 기법 을 이용하여 초기 영역분할을 한다. 두 번째 과정으로 분할된 영역들의 색상차, 영역간 거리, texture 정보를 종합하여 원본영상 속의 중요 객체와 배경을 구분한다.
원본영상의 중요 객체에 더 중점을 줄 수 있도록 ROI 구간을 생성한다. Segmentation 된 결과는 개선된 객체 추출 방법을 이용하여 다시 하나의 Segmentation Image가 된다. 본 논문에서 최종으로 나올 Saliency Map은 영상 정보를 기계학습이나 다른 사전정보 없이 자동으로 추출된 영상이다.
본 논문은 그림 8.과 같이 초기 영역분할로 찾은 각 집단의 정보를 이용하여 서로의 관련성과 유사성, 그리
고 배경 혹은 중요 객체 여부 등을 판별하기 위해 색상, 간격, Texture에 대한 정보를 각각 정리하도록 한다.
1. Color Difference
Lab 색 공간의 가장 큰 장점은 RGB나 CMYK와 달 리 매체에 독립적이라는 것이다. 디스플레이 장비나 인 쇄 매체에 따라 색이 달라지는 색 공간과 달리 Lab 색 공간은 인간의 시각에 대한 연구를 바탕으로 정의되었 다. 특히 휘도 축인 L 값은 인간이 느끼는 밝기에 대응 하도록 설계되었다.
Lab 색 공간의 영역은 컴퓨터 디스플레이나 인쇄 매 체는 물론 인간이 지각할 수 있는 색 영역보다도 훨씬 크다. 따라서 RGB나 CMYK보다 더 정밀한 값으로 표 현해야 한다. 80년대까지 대부분의 이미지 포맷은 8비 트만을 지원하였으므로 Lab 색 공간을 표현하기에 부 적합했으나, 지금은 대부분의 포맷이 16비트 이미지를 / 지원하므로 이러한 문제가 없다.
Lab 색 공간에서 L 값은 밝기를 나타낸다. L = 0 이 면 검은색이며, L = 100 이면 흰색을 나타낸다. a는 빨 강과 초록 중 어느 쪽으로 치우쳤는지를 나타낸다. a값 이 음수이면 초록에 치우친 색깔이며, 양수이면 빨강/
보라 쪽으로 치우친 색깔이다. b는 노랑과 파랑을 나타 낸다. b가 음수이면 파랑이고 b가 양수이면 노랑이다.
각 영역간의 색상 차이를 계산하고 이를 표현한 것이 식(1)이다. C는 Color, L1, L2는 Lab color space의 color channel, a1, a2, b1, b2는 두 객체간의 Lab 거리 를 의미한다.
(1)2. Spatial Difference
유클리드 거리(Euclidean distance)는 두 점 사이의 거리를 계산할 때 흔히 쓰는 방법이다. 이 거리를 사용 하여 유클리드 공간을 정의할 수 있다. 식(2)의 S는 Spatial을, x1, x2, y1, y2, z1, z2 6개 모두 픽셀 거리를 의 미한다. 두 영역간의 거리를 3차원으로 계산하여 관계 가 밀접한지 아닌지를 판별하는데 사용한다.
(2)3. Texture Distance
질감분석 기법에는 구조적(Structural) 접근법, 스펙 트럼(Spectral) 접근법, 그리고 통계적(Statistical) 접근 법이 있다. 그 중에서도 질감은 랜덤하나 어떤 일관된 속성을 가지므로 통계적 접근법이 널리 이용되고 있다.
Gray Level Co-occurrence Matrix(GLCM)이 질감분 석에 많이 이용되고 있다[7]. 하지만 GLCM에서는 입력 영상의 명암레벨에 따라 행렬의 크기가 정해지고 그 계 산부하도 달라지는 제약이 있다. 이러한 GLCM의 제약 을 해결할 수 있는 대안으로 Local Binary Pattern (LBP)가 제안되었다[8].
LBP는 계산이 간단하고 상대적으로 우수한 성능을 가지므로 질감특성을 표현하는 뛰어난 방법 중 하나로 영상의 명암과는 무관하게 영상 내 내부패턴 변화를 표 현할 수 있는 장점이 있다. 식(3)은 LBP를 이용한 질감 차이 판단 수식이고 T는 Texture를 의미한다.
(3)
4. Saliency Map
본 논문은 위의 분할된 영역들의 색상(Lab), 영역간 거리(Euclidean), 질감(LBP)을 이용하여 Saliency Map 을 개선된 객체 추출 방법을 아래와 같이 제안하고자 한다. 색상을 통한 값 C와 영역간 거리 값 S, 그리고 질 감에 따른 분류인 T를 이용하여 Saliency Map으로 넣 을 최적의 Foreground 객체를 찾아낸 후, Foreground 를 제외한 모든 영역은 Background으로 정리한다.
min
≠
∈
≤≤
where (4)
B is background regions.
식(4)에서 W는 KKT를 이용한 라그랑주 승수법
그림 9. Berkeley Segmentation Dataset 자료 Fig. 9. Berkeley Segmentation Dataset Source.
그림 10. 사진기반 CAPTCHA 예시 Fig. 10. Image Based CAPTCHA Example.
(Lagrange Multiplier)이다. 이를 통해 각 영역간의 최 적 Saliency 값을 구할 수 있다.
5. Region Division
본 논문에서 제안하는 개선된 객체 추출 방법은 중요 객체가 영상의 테두리에 겹치지 않아야한다는 전제를 둔다. 이러한 이유는 아래의 그림들과 함께 설명하고자 한다.
그림 9.과 같이 Berkely Segmentation Dataset[9]에서 많은 원본영상의 주요객체를 테두리가 아닌 안쪽에 담 는 경우를 볼 수가 있다. 이는 실험용 영상뿐만 아니라 실생활에서도 사용자가 원하는 주요객체는 중앙에 집중 하고 주변에 여백을 주는 현상에 의해 나오는 특징이라 할 수 있다.
또한, 보안에서 사진기반 캡챠(Image Based CAPT CHA)의 경우, 사용자 인증을 하는 수단으로 문자 혹은 객체를 인간만 판별 가능한 수준으로 만든 영상들로 구 성이 되어 있으며 이 또한 그림 10.과 같이 주요객체 혹 은 주요문자는 영상의 안쪽에 배치되어 있는 것을 볼 수 있다.
그림 11. 원본영상(좌)과 테두리를 자른 Region Division 영상(우)
Fig. 11. Original Image(left) and Region Division Image (right).
그림 12. 본 논문 및 연구를 위해 구현한 프로그램에서 보여지는 원본영상(좌)와 Background Seeds 및 주의집중 영역을 Marking한 영상(우)
Fig. 12. Original Image(left) and Background Seeds with dots marked on concentrated area(right).
본 논문에서는 이러한 주요객체 특징을 보다 빠르게 추출하기 위해 Region Division을 하고자 한다. 그림 11.와 같이 SLIC로 분할된 영역들 중에서 1차로 원본의 테두리를 Background로 지정하여 보다 개선된 객체 추 출을 가능토록 Region Division을 생성하고 본 논문 6 절 Background Seeds에서 최종 Background를 정리하 게 된다.
6. Background Seeds
본 논문 5절에서 잡은 Background영역을 SLIC로 나 눠진 영역별로 각각 구분하여 그림 12.과 같이 어느 객 체가 Background인지를 표기해준다.
그림 12.에서 노랑점으로 표현된 부분은 Background 을 의미하며, 이를 Background Seeds라고 부른다.
Background Seeds와 4절에서 나온 Saliency 값을 이용 하여 원본영상에서의 나머지 영역들이 붉은점으로 잡힌 주요객체와 노랑점으로 잡힌 배경 중에 어디에 해당되 는지를 정리한다.
그림 13. 좌부터 순서대로 원본영상, 개선된 객체추출 방 법을 이용한 Saliency Map, 개선된 객체 추출 방법, Berkeley Dataset Ground Truth
Fig. 13. (From left) Original Image, Saliency Map using Enhanced Object Extraction Method, Enhanced Object Extraction Method, Berkeley Dataset Ground Truth.
Ⅳ. 실험 및 결과
본 논문에서 제안하는 방법을 통해 SLIC와 색상차, 영 역간 거리, texture 정보를 이용하여 얼마만큼 정교하게 Saliency Map을 추출할 수 있는지를 보여주고자 한다.
실험결과는 SLIC Segmentation를 하고, Lab, Euclidean, LBP를 이용하여 영상 속의 객체를 정교하게 추정 및
그림 14. 제안하는 방법(파랑) 및 GBVS(빨강)의 평균 정 확도
Fig. 14. Average Precision Rate of GBVS(red) and Proposed Method(blue).
그림 15. 제안하는 방법(파랑) 및 GBVS(빨강)의 객체 내 객체제거 평균 결과
Fig. 15. Average Recall Rate of GBVS(red) and Proposed Method(blue).
Background Region을 이용한 개선된 객체 추출 정보를 이용한 최종 결과물이다.
본 실험에서는 주요객체에 근접한 색상일 경우 높은 Saliency 값을 주고, 배경과 유사할수록 낮은 Saliency 값 을 주고자 한다. 실험에 사용된 영상은 모두 Berkeley Segmentation Dataset을 기반으로 하였다[9].
그림 13.와 같이 Berkeley Segmentation Dataset의 Ground Truth와 유사한 수준으로 자동 객체 추출이 가 능함을 확인 할 수 있다. 그러나 맨 마지막과 같이 중요 객체와 색상, 질감이 유사한 경우에는 함께 다른 영역 도 함께 중요 객체로 인식하는 것을 확인 할 수 있었다.
직관적으로 알아보기 힘든 Ground Truth와 제안하 는 방법의 유사도는 아래의 그림들을 이용하여 설명하 고자 한다. 본 실험결과는 MATLAB으로 작성되어 있 으며, Itti가 제안한 saliency toolbox(GBVS)와 결과를
비교하고자 한다.[22]
본 논문에서 제안하는 객체 추출 방법은 그림 14.와 같은 평균 정확도를 보였다. Average Precision Rate는 제안하는 방법이 Ground Truth와 얼마만큼 근접한지를 Threshold수치에 따른 평균값으로 보여주고 있다. 최고 로 높은 정확도를 선보인 것은 Threshold가 0.7일 경우 였으며 정확도 수치가 0.9570이 나왔다.
그림 15.은 본 논문에서 제안하는 개선된 객체 추출 방법의 객체 내 객체제거 평균 결과를 나타내고 있다.
Average Recall Rate는 Ground Truth에서 제공하는 객 체에서 어느 정도의 부분객체를 제안하는 방법이 제거 했는지를 Threshold수치에 따른 평균값으로 보여주고 있다.
Ⅴ. 결 론
본 논문은 깊이 맵을 생성하는 연구에서 시작되었다.
객체 추출이 불가능한 상황 속에서 얼마나 정교하게 중 요 객체를 추출하고 깊이 맵으로 표현이 가능한지 연구 하면서 본 논문에서 제안하게 되었다.
GBVS의 결과가 본 논문에서 제안하는 방법에 비해 객체 내 객체제거 평균 결과가 더 좋게 나온다. 이는 GBVS의 경우 salinecy 영역이 더욱 세밀하기 때문이 다. 반대로, 본 논문의 결과는 평균 정확도에서 Itti의 방법보다 더 좋은 결과를 보여주고 있다. Threshold가 높아질수록 그 결과를 극명하게 차이를 보이게 됨을 알 수 있다.
개선된 객체 추출 방법으로 Saliency Map을 만들 경 우, 장점으로 기계학습과 같은 training 과정 없이 높은 정확도를 가지고서 객체들을 표현이 가능하다는 것이 다. 그러나, 몇 가지 제약조건이 따른다. 첫째는 중요 객체는 원본 영상의 테두리(Edge)에 닿으면 Background Region과 겹치기 때문에 결과를 제대로 추출 할 수 없다.
둘째는 중요 객체와 주변의 다른 객체들의 색상 차이가 명확해야 정교한 객체 추출이 가능하다.
감사의 글
이 논문은 2015년도 정부(교육과학기술부)의 재원으 로 한국연구재단의 지원을 받아 수행된 연구임 (NRF-2015R1A2A2A01004587).
REFERENCES
[1] Achanta, Radhakrishna.Slic superpixels.Ecole Polytechnique Fédéral de Lausssanne (EPFL), Tech. Rep 2(3), 2010.
[2] Felke, P. Bruckschwaiger, M. Wegenkitt,
“Implementaion and complexity of watershed-from-markers algorithm computed as a minimal cost forest”, Computer Graphics Forum, 20(3), 26-35, 2001
[3] T.Ojala, M.Pietik¨ainen, and D.Harwood.A comparative study of texture measures with classification based on feature distributions”, Pattern Recognition vol.29,1996.
[5] L. Itti, C. Koch, and E. Nieber, “A Model of Saliency-Based Visual Attention for Rapid Scene Analysis, IEEE Trans. on Pattern Analysis and Machine Intelligence.(PAMI), pp.1254-1259, 1998.
[6] Dirk Walther and Christof Koch, “Modeling attention to salient proto-objects”. Neural Networks 19, 1395-1407, 2006
[7] Leen-Kiat Soh, Costas Tsatsoulis, “Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices”, IEEE Trans on Geoscience and Remote Sensing, vol. 37, no. 2, pp. 780-795, 1999
[8] T. Ojala, M. Pietikainen, and T. Maenpaa,
“Multiresolution gray-scale and rotation invariant texture classification with local binary patterns”, IEEE Trans. PAMI, vol. 24, pp. 971-987, 2002.
[9] Berkeley Segmentation Dataset, http://www.eecs.
berkeley.edu/Research/Projects/CS/vision/bsds/
[10] Zhenhua Guo,and Lei Zhang “A Completed Modeling of Local Binary Pattern Operator for Texture Classification”, IEEE Trans. on Image Processing, vol. 19, no. 6, pp. 1657-1663, 2010.
[11] T. Tuceryan and A. K. Jain,Texture Analysis,
The Handbook of Pattern Recognition and Computer Vision (2nd Edition), World Scientific Pub. Co., pp. 207-248, 1998
[12] T. Randen and J.H. Husy, “Filtering for texture classification: a comparative study”, IEEE Trans.
PAMI, vol. 21, pp. 291-310,1999.
[13] T. Ahonen, A. Hadid, and M. Pietikainen, “Face Recognition with Local Binary Patterns,” ECCV 2004, LNCS 3021, pp. 469-181, 2004
[14] T. Ojala, M. Pietikäinen and T. Mäenpää, “Gray Scale and Rotation Invariant Texture Classification with Local Binary Patterns‘,”
Computer Vision-ECCV 2000, pp. 404-420, 2000 [15] uceryan M, Jain A K. Texture Analysis. Chen C
H, Pau L F, Wang P S. Handbook of Pattern
Recognition an Computer Vision. 2nd ed.
Singapore: World Scientific Publishing Co., pp:207-248, 1998.
[16] Haralick R M, Shanmugam K, Dinstein I H.,
“Textural features for image classification”.
IEEE Trans.on SMC, 3(6):610-671,1973.
[17] Varma, M., Zisserman, A. “A statistical approach to material classification using image patch examplars”, IEEE Trans. On Pattern Analysis and Machine Intelligence, vol. 31, no. 11, pp.
0162-8828, Nov. 2009.
[18] P. Mohanaiah, P. Sathyanarayana, and L.
GuruKumar, “Image Texture Feature Extraction Using GLCM Approach,” International Journal of Scientific and Research, Pub. Vol 3, Issue 5, pp.
1-5, May. 2013
[19] LBP Library for MATLAB, https://github.com/
adikhosla/feature-extraction/tree/master/features [20] Kyungwon Jeong, Nahyun Kim, Seoungwon Lee,
and Joonki Paik, “Multi-Object Detection and Tracking Using Dual-Layer Particle Sampling“, Journal of The Institute of Electronics and Information Engineers Vol. 51, NO. 9, pp.
2025-2033, Sep. 2014.
[21] Ki Tae Park, Jong Hyeok Kim, and Young Shik Moon, “Extraction of Attentive Objects Using Feature Maps”, Journal of The Institute of Electronics and Information Engineers Vol. 43, NO. 5, pp. 425-434, September 2006.
[22] GBVS Algorithm for MATLAB, http://www.
vision.caltech.edu/~harel/share/gbvs. php
저 자 소 개 최 영 진(정회원)
2012년 한국외국어대학교 정보통 신공학과 학사 졸업.
2013년~현재 고려대학교 정보보 호학과 석사과정.
<주관심분야 : 컴퓨터비전, 컴퓨 터보안, 기계학습>
퀴 런(정회원)
2008년 하얼빈공업대학교 컴퓨터 공학과 학사 졸업.
2008년~현재 고려대학교 정보보 호학과 석박통합과정.
<주관심분야 : 분산컴퓨팅, 컴퓨터 보안, 컴퓨터비전>
김 광 락(정회원)
1978년 서울대학교 전기공학과 학 사 졸업.
1980년 KAIST 전기전자과 석사 졸업.
1983년 미국 San Jose 현대전자 2002년 Hitachi America Principal Engineer
2013년 ITT Senior Staff Engineer 현재 삼육대학교 컴퓨터학부 조교수
<주관심분야 : 기계학습, 인공지능>
김 형 중(정회원)
1978년 서울대학교 전기공학 학사 졸업.
1986년 서울대학교 제어계측공학 석사 졸업.
1989년 서울대학교 제어계측공학 박사 졸업.
1989년~2006년 강원대학교 교수
2006년~현재 고려대학교 정보보호대학원 교수
<주관심분야 : 컴퓨터보안, 패턴인식, 가역정보은닉>