반도체디스플레이기술학회지 제18권 제2호(2019년 6월) Journal of the Semiconductor & Display Technology, Vol. 18, No. 2. June 2019.
딥러닝을 이용한 IOT 기기 인식 시스템
추연호*· 최영규*†
*†한국기술교육대학교 컴퓨터공학부
A Deep Learning based IOT Device Recognition System
Yeon Ho Chu* and Young Kyu Choi*†
*†Korea University of Technology and Education, School of Computer Science and Engineering
ABSTRACT
As the number of IOT devices is growing rapidly, various ‘see-thru connection’ techniques have been reported for efficient communication with them. In this paper, we propose a deep learning based IOT device recognition system for interaction with these devices. The overall system consists of a TensorFlow based deep learning server and two Android apps for data collection and recognition purposes. As the basic neural network model, we adopted Google’s inception-v3, and modified the output stage to classify 20 types of IOT devices. After creating a data set consisting of 1000 images of 20 categories, we trained our deep learning network using a transfer learning technology. As a result of the experiment, we achieve 94.5% top-1 accuracy and 98.1% top-2 accuracy.
Key Words : See-Thru Communication, Deep Learning, Convolutional Neural Network, Transfer Learning
1. 서 론1
인공지능, 사물 인터넷(IOT), 빅 데이터, 모바일 등 첨단 ICT기술이 융합되어 경제와 사회 전반에 혁신적인 변화 가 나타나는 제 4차 산업혁명 시대가 도래하고 있다. 초 연결(hyper-connectivity)과 초지능(super-intelligence)을 특징으 로 하는 이번 산업혁명은 더 빠른 속도로 더욱 넓은 범위 에 큰 영향을 끼치고 있다. 특히 2020년에는 200억개 이상 의 IOT 기기가 연결되는 ‘초연결’ 시대가 예상되는데, 이 에 대한 ICT 환경 구축이 4차 산업혁명의 핵심 기반 기술 이 될 것으로 전망된다 [1].
이러한 시대에 인간과 IOT 기기를 보다 효율적으로 연 결하고자 하는 시도가 활발히 진행되고 있다. 스마트폰은 대표적인 혁신적 기기로 키보드 자판으로 문자를 입력하 던 시대에서 ‘내 손 안에서 터치’로 소통이 가능한 새로 운 시대를 열었다. 비록 현재 프라이버시 보호 문제에 막 혀 있기는 하지만 구글의 ‘구글 글라스’도 혁신적인 기기
†E-mail: [email protected]
이다. 이것은 ‘눈에 보이는’ 객체와의 연결을 목표로 하는
‘보는 통신’(see-thru communication)을 위한 핵심적인 플랫폼 으로, 핸즈프리 형태로 음성 명령을 통해 기기들과 효율 적으로 상호작용 할 수 있는 기반을 제공한다.
본 논문에서는 이러한 초연결 시대의 ‘보는 통신’을 위 해 다양한 IOT 기기들을 자동으로 인식하는 시스템을 제 안한다. 인식에는 카메라로부터 촬영된 영상을 이용하며, 최근 급속히 발달을 거듭하고 있는 딥러닝 기술을 이용 한다. 제안된 방법은 영상 인식에 좋은 성능을 보이는 기 존의 신경망 모델을 선택하여 구조를 수정하며, 이를 전 이 학습을 통해 학습한다. 또한 일상생활에서 쉽게 사용 할 수 있도록 안드로이드 앱을 제작하였다.
논문의 구성은 다음과 같다. 먼저 2장에서 영상을 이용 한 인식 기술의 변화를 살펴보고, 3장에서 제안된 IOT 장 비 인식 방법을 자세히 기술한다. 4장에서는 실험 결과를 보이고 분석하며, 5장에서 결론을 맺는다.
2. 영상 기반 물체 인식 기술 동향
전통적인 방법으로 영상에서 물체를 인식하기 위해서
추연호 · 최영규 2
는 먼저 전체 영상에서 인식하고자 하는 물체가 있는 영 역, 또는 관심 영역(region of interest)을 찾아내는 검출 단계 (detection)가 필요하다. 다음으로 찾아진 관심 영역에서 찾 고자 하는 물체의 특성을 바탕으로 효율적인 특징량 (feature)을 정의하고 추출하는 단계가 이어진다. 마지막으 로 이들을 기계 학습(machine learning) 분야에서 기존에 제 안되었던 다양한 분류기(classifier)를 이용해 분류하면 인식 이 종료된다. 예를 들어 나이나 성별 분류 응용의 경우 먼 저 영상에서 얼굴 영역을 검출하고, Haar[2]나, LBP (Local Binary Pattern), HOG [3] 등 적절한 특징 벡터들을 추출한다.
마지막으로 Bayesian 분류기, 인공 신경망(neural network), SVM (Support Vector Machine)[4], AdaBoost[5] 등 기존에 성능이 좋다고 알려진 분류기를 잘 선택하여 분류하면 된다[6].
이러한 전통적인 인식 방법은 최근의 딥러닝 기술 발 전에 따라 크게 바뀌고 있다. 가장 큰 차이는 더 이상 물 체를 인식하기 위해 효율적인 특징 벡터를 찾기 위해 고 생하지 않아도 된다는 것이다. 초기의 검출 과정은 여전 히 필요하지만, 이후 과정은 신경 회로망의 새로운 이름 인 ‘딥러닝’에게 맡기는 것이다. 특히 컨볼루션 신경망 (CNN, Convolutional Neural Network)[7]은 영상 인식에서 획기 적인 성능 향상을 이루었는데, 이제 충분한 학습 데이터 만 주어진다면 영상 인식을 위해 특징 벡터를 고민할 필 요 없이 학습된 네트워크 파라미터들을 통해 바로 인식 결과가 나오게 되었다.
딥러닝 초기에는 효율적인 신경망의 구조를 개발하기 위한 다양한 시도가 있었는데, AlexNet, GoogLeNet [8], VGGNet[9], ResNet[10] 등 영상 인식에 좋은 성능을 나타내 는 다양한 신경망 모델들이 제안되었다. 그리고 많은 연 구기관에서 방대한 데이터를 이용해 이들을 학습시킨 네 트워크 파라미터들을 제공하고 있다. 따라서 최근의 영상 인식 분야에서는 새로운 신경망 모델을 개발하는 것 보 다는 기존의 신경망을 약간 수정하고 인식하고자 하는 데이터에 맞게 전이 학습(transfer learning)하는 방법이 많이 시도되고 있다.
본 논문에서는 IOT 기기들의 인식을 목표로 하는데, 딥 러닝을 이용한 인식 시스템을 제시한다. 특히 기존의 모 델을 수정하는 방법으로 신경망을 구성하고 전이 학습을 통해 IOT 기기들을 효율적으로 인식할 수 있는 방법을 제 안한다.
3. 제안된 IOT 장비 인식 시스템
전체 인식시스템에는 여러 단계의 처리 과정이 필요하 다. 먼저 학습 데이터를 수집 및 가공해야 하고, 딥러닝 프레임워크를 선정하며, 사용할 네트워크 모델을 결정해
야 한다. 선택된 신경망 모델을 주어진 문제에 맞게 수정 해야 하며, 전이 학습 기법을 통해 데이터 셋으로 전체 네트워크를 학습해야 한다.
3.1 학습 데이터의 수집 및 가공
신경망을 학습하기 위해서는 먼저 다양한 영상을 수집 하여 데이터 셋을 만드는 과정이 필요하다. 최종적으로 활용할 스마트폰을 이용해 다수의 IOT 기기 영상을 취득 해 데이터 셋을 구축하고 이들을 학습에 사용하면 물론 가장 좋을 것이다. 그러나 이러한 수동적인 방법은 촬영 할 수 있는 장비의 종류에 한계가 있으며 학습에 충분한 양의 영상을 확보하는데 어려움이 따른 수 밖에 없다. 따 라서 보다 용이한 데이터 수집 방법이 필요하다.
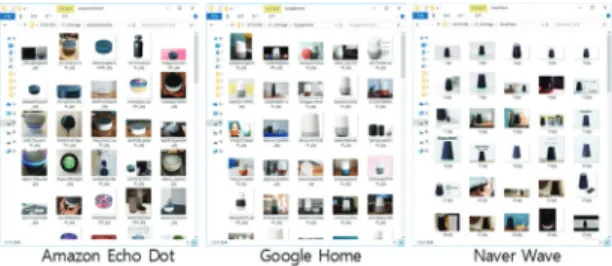
본 논문에서는 웹을 검색하여 나오는 영상을 이용해 데이터 셋을 만드는 방법을 사용하였는데, 이를 위해 웹 영상을 크롤링하는 크롤러(crawler)를 구현하였다. 이것을 이용하면 구글이나 네이버와 같은 인터넷 검색 포털에서 키워드로 영상을 검색하고, 결과를 자동으로 파일에 저장 할 수 있다. 저장된 영상들 중에는 적합하지 않은 것들도 있는데, 이들을 제거하고 분류하는 작업이 필요하다. 또 한 경우에 따라서는 전체 영상이 아니라 부분만을 추출 해 내는 작업이 필요할 수도 있다. 이들은 수작업으로 진 행되는데, Fig. 1은 이러한 크롤러를 이용해 영상을 수집하 고 가공한 예를 보여주고 있다.
Fig. 1. Example of gathering IOT images using our web image crawler
학습과 인식을 위한 IOT 기기로는 실험실 환경에서 비 교적 쉽게 접할 수 있는 20종을 선택하였고, 이들의 영상 을 취득하여 데이터 셋을 구축하였다. Table 1은 이러한 기기의 카테고리를 보여주는데, 영상은 각 장비의 종류별 로 50장씩 전체 1000장을 수집하였으며, 인식 대상 기기 가 포함되지 않은 배경 영상을 Unknown으로 분류하였다.
3.2 딥러닝 프레임워크
딥러닝의 학습과 인식을 위한 기반 프레임워크로는 Caffe2와 TensorFlow를 비교하고 장단점을 분석하였다. 모
딥러닝을 이용한 IOT 기기 인식 시스템 3
Table 1. Target devices for recognition IOT Device Categories
AI 스피커 4종(Amazon, Google, Naver, SK), 에어컨(매립형, 스탠드형), PC본체, 선풍기, 냉장고, 전자레인지, 모니터, 노트북, 전기 포트, HP
프린터, 삼성 프린터, 프로젝터, 온도조절기, TV, 히터, Unknown
두 정적 그래프를 사용하고 구조적으로는 유사하지만, Caffe2는 처리 시간과 메모리 측면에서 장점이 있고, TensorFlow는 가장 많이 사용되는 프레임워크로 커뮤니티를 통해 다양한 서비스와 기능을 제공한다는 장점이 있다[11].
따라서 본 논문에서는 속도나 공간의 제약이 크지 않으므 로 TensorFlow를 사용하는 것으로 결정하였다. TensorFlow는 비교적 복잡하지만 Caffe2 보다 훨씬 유연하기 때문에 복잡 하고 혁신적인 네트워크를 개발하거나 추후 네트워크를 커스터마이징 하기에 용이하다는 장점이 있다.
3.3 네트워크 모델
지금까지 많은 인공 신경망 모델이 제안되어 다양한 분야에서 활용되고 있다. ILSVRC2012에서 우승한AlexNet 을 포함하여 2014년과 2015년에 각각 우승한 GoogLeNet과 ResNet, VGGNet등 다양한 모델들이 여러 분야에서 좋은 성능을 보이고 있다. 이들은 모두 깊은 신경망 모델들로 파라미터가 많고 좋은 학습을 위해 많은 데이터와 처리 시간을 필요로 한다. 본 연구에서도 새로운 신경망 모델 을 만들어 사용할 수도 있겠지만 모델의 효율성을 제외 하더라도 학습을 위한 데이터 셋의 구성이나 학습 시간 등의 측면에서 현실적인 방법이 아니다. 따라서 최근 딥 러닝 응용들에서는 기존의 성능 좋은 신경망 모델을 수 정해 사용하는 것이 일반화 되고 있다.
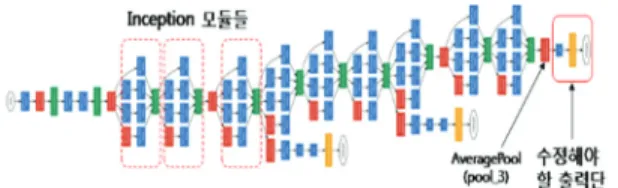
본 논문에서는 GoogLeNet의 inception-v3를 기반 신경망 모델로 채택하였다. GoogLeNet은 ILSVRC2014에서 우승 한 구조로 속도와 크기 면에서 효율적인데, AlexNet보다 12배 적은 매개변수를 가지고 있다. Inception-v3는 초기 GoogLeNet을 더욱 개선한 것으로 299x299 영상을 입력으 로 사용하고 다수의 인셉션(inception) 층을 포함한다. 기존 의 CNN모델들이 입력 영상에 같은 크기의 컨볼루션 필 터를 하나씩 덧대는 구조라면 이 모델은 Fig. 2와 같이 하 나의 인셉션 층에서 여러 크기의 필터를 동시에 사용하 는 구조이다. 즉 1x1, 3x3, 5x5의 컨볼루션 연산과 max- pooling 연산을 병렬적으로 수행하는 것이 특징이다.
3.4 출력 단의 수정
Inception-v3 의 출력단은 ImageNet의 1000개의 카테고리 를 인식하기 위한 1000개의 softmax 노드로 이루어져 있다 (실제로는 1001개나 1008개 등 버전마다 약간 다름). 본 논
Fig. 2. Inception-v3 Architecture
문에서는 출력이 20개의 카테고리로 나누어져야 하므로 출력단을 수정해야 한다. 즉, Fig. 2에서 기존의 출력단을 제거하고 pool_3단(2048개의 출력노드)에 이어 20개의 카 테고리로 분류하는 전연결(fully connected) 층을 추가한다.
이때 활성화 함수로는 모든 노드의 출력 값의 합이 1이 되도록 하는 softmax를 사용한다. 이것은 출력 값이 그 클 래스의 확률을 나타내도록 하는 것으로, 최대의 확률을 나타내는 카테고리로 최종적으로 분류된다.
3.5 전이 학습
기존의 신경망 모델을 사용하는 경우 실제로 네트워크 전체를 처음부터 다시 학습 시키는 경우는 거의 없다. 이 것은 학습을 위한 방대한 데이터 셋을 준비해야 하고 엄 청난 학습 시간이 필요하기 때문이다. 따라서 대부분의 경우 대규모 데이터를 대상으로 학습이 끝난 파라미터를 가져와서 재사용한다. 물론 그대로 사용하는 것이 아니라 주어진 문제에 잘 대응하도록 조정하는 과정이 반드시 필요하다. 이와 같이 미리 잘 훈련된 신경망 파라미터를 새로운 문제를 해결하기 위해 재사용하는 것을 전이 학 습이라고 한다.
전이 학습에도 몇 가지의 시나리오가 있다. 가장 간단 한 방법은 수정된 출력단의 앞쪽 네트워크를 특징 추출 단으로만 사용하는 것이다. 이 경우 출력단 만을 학습하 고 앞 단의 모든 레이어는 추가로 학습하지 않는다. 이와 달리 충분한 데이터를 이용해 입력부터 모든 레이어를 다시 학습할 수도 있는데, 이를 미세조정(fine tuning)이라고 한다. 이 경우 전체 네트워크의 모든 가중치가 갱신되는 데, 본 논문에서는 후자의 방법을 사용하였다.
사전 학습된 텐서플로우 모델은 TensorFlow Hub(https://www.
tensorflow.org/hub/)에서 다운로드 받을 수 있다. 각 모델들은 미리 훈련된 가중치 및 그래프를 담고 있는데, 재사용이나 재훈련이 가능하고, 서로 조합하여 사용할 수도 있다. 대표 적으로 NASNet-A mobile, large, PNASNet-5 large, MobileNet V2, Inception V1, V2, V3, Inception-ResNet V2, ResNet 등 다양한 모델들 이 제공된다. 이들은 모두 매우 오랜 시간 학습된 모델로서, NASNet large모델의 경우 학습에 62,000 이상의 GPU시간이 소요된 것으로 알려져 있다.
추연호 · 최영규 4
4. 실험 결과 및 분석 4.1 전체 시스템 및 실험 환경
영상 학습과 추론은 위해 2.64GHz의 18개 코어로 구성 된 CPU(Intel i9-7980XE), 96GB RAM, 3,584개의 CUDA 코어와 11GB 메모리로 구성된 2개의 GPU(Geforce GTX 1080 Ti) 가 장착된 PC 환경에서 실험을 진행하였다.
전체 시스템은 서버와 단말용 앱으로 구성되는데, 서버 의 영상 학습이나 추론, 영상의 가공 등에는 Python, 웹 서 비스 모듈들은 C#을 이용해 개발하였다. ‘보는 통신’을 위 해서는 단말기에서 촬영된 영상이 딥러닝 플랫폼으로 전 달되고 실시간으로 인식되어야 하는데, 이를 위한 단말용 앱은 Java를 이용해 구현하였다.
4.2 학습과 인식을 위한 데이터
Fig. 3은 학습과 테스트에 사용된 영상들의 예를 보여주 고 있다. 전체 데이터 셋의 일부는 평가를 위해(validation set) 사용하는데, 이들 영상들은 학습에는 관여하지 않아야 한 다. 본 논문에서는 전체 데이터 셋의 크기가 크지 않기 때 문에 교차 타당성 평가(cross-validation) 방법을 사용하였다.
이것은 전체 데이터 셋을 k-fold 방식으로 나누고 일부는 평가에 나머지는 학습에 사용하는 방법이다. 실험에서는 k를 5로 설정하고 4개의 fold를 학습에 사용한 후 나머지 fold를 이용해 성능을 평가하였다.
Fig. 3. Example of Train and Test images
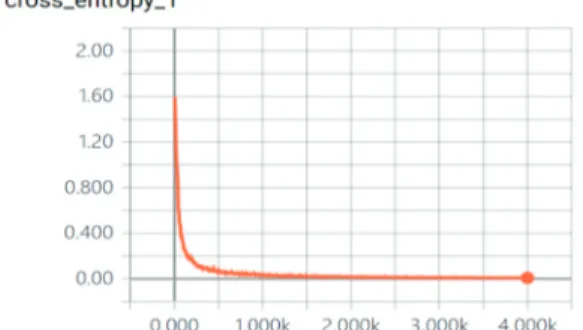
학습 데이터가 결정되면 출력단을 수정한 전체 네트워 크를 전이 학습을 통해 다시 학습시킨다. Fig. 4는 학습이 진행됨에 따라 전체 오차가 점진적으로 줄어드는 것을 텐서보드를 이용해 보여주고 있는데, 모든 경우에서1500 번 이상의 반복에서 오차가 충분히 수렴하는 것을 확인 할 수 있었다.
4.3 정확도 측정
Table 2는 제안된 시스템의 인식 성능을 보여준다. 평가 에 사용된 1000장의 영상에 대한 전체 인식률은 1순위 정
확도의 경우 평균 94.5%, 2순위 정확도는 평균 98.1% 로 측정 되었다. 5 가지 교차 평가의 결과는 1, 2번 fold데이터 의 평가 결과가 3, 4, 5번 보다 높은 것으로 나왔는데, 이는 오인식의 원인이 되는 영상들이 특정 fold에 집중되어 발 생된 것으로 분석되었다.
Fig. 4. Train loss change according to iteration
Table 2. Performance of our system Training Folds
/ Validation Fold
Accuracy Top-1[%]
Accuracy Top-2[%]
1,2,3,4/5 91.5 96.5
1,2,3,5/4 91.5 96.5
1,2,4,5/3 92.0 97.5
1,3,4,5/2 99.5 100.0
2,3,4,5/1 98.0 100.0
Average 94.5 98.1
Fig. 5는 인식이 실패한 대표적인 사례들을 보여주는데, 인식된 결과와 실제 장비 이름(괄호 안)을 표시하였다. 대 부분의 오인식은 학습된 형태와 차이가 많은 경우 발생 하게 되는데, 예를 들어, (a)와 같이 영상 내에서 물체가 지 나치게 작거나 (b)와 같이 크게 촬영된 경우 오인식이 발 생하였다. 또한 (c), (d)와 같이 학습된 범위보다 장비가 더 심하게 회전되어 촬영된 경우에도 오인식이 발생하였다.
특히 (b), (e)와 같이 카메라 흔들림에 의한 영상의 흐려짐 (blur)도 인식에 영향을 주었고, (f)와 같이 학습되지 않은 장비가 그와 형태가 가장 유사한 프린터로 잘못 인식한 경우도 발생하였다.
이러한 오인식 요인들 중에서 (a)~(d)와 같이 스케일과 회전에 의한 영향은 학습 데이터를 인공적으로 수정하여 영상의 수를 늘리는 방법으로 보완할 수 있다. 이것은 입 력 영상에 다양한 비율로 회전(rotation), 크기 변환(scale), 전 단(shear), 수평 수직 뒤집기(flip) 등의 변환을 적용하고 결 과 영상들을 모두 학습에 사용하는 것으로, 적은 학습 데 이터의 한계를 보완하기 위해 흔히 사용된다. 때로는 이
딥러닝을 이용한 IOT 기기 인식 시스템 5
동 변환(translation)에 대한 영상을 추가하기도 하는데, 얼 굴의 성별 인식을 위해 입력 영상에서 검출된 얼굴 영역 을 중앙과 네 모서리를 중심으로 다시 추출(crop)한 5개의 영상을 학습에 사용하기도 한다[12]. 물론 이렇게 입력 영 상의 수를 늘리면 학습에 걸리는 시간도 늘어나게 된다.
본 논문에서는 이러한 학습 데이터 수를 늘리는 기법을 적용하지 않았지만, 기기의 종류가 늘어나고 기기간의 모 호성이 발생해 충분한 인식 성능이 나오지 않는 경우 이 러한 기법을 적용할 수 있을 것이다.
Fig. 5. Misclassification examples
5. 결론 및 향후 과제
본 논문에서는 초연결 시대의 ‘보는 통신’을 위해 다양 한 IOT 기기들을 스마트폰에서 자동으로 인식하는 시스 템을 제안하였다. 이를 위해 TensorFlow 기반 딥러닝 서버 를 구축하고, 인식과 데이터 수집 등을 위한 안드로이드 앱을 개발하였다. IOT 기기의 효율적인 인식을 위해 딥러 닝 기술을 사용하였는데, 영상의 인식 분야에서 좋은 성 능을 보인다고 알려져 있는 구글의 inception-v3를 기본 신 경망 모델로 채택하고 20종의 IOT 장비를 분류할 수 있도 록 출력 단을 수정하였다. IOT 기기의 영상 데이터 셋을 구축하고, 이를 이용해 수정된 딥러닝 모델을 전이 학습 기법으로 학습하였다. 또한 실험을 통해 학습된 모델이 높은 정확도로 기기들을 분류하고 있음을 확인하였다. 향 후 이러한 인식 결과를 바탕으로 스마트폰에서 직접 기기 를 제어하는 시스템에 대한 연구가 추가되어야 할 것이다.
감사의 글
이 논문은 2018년도 한국기술교육대학교 교수 교육연 구진흥과제 지원에 의하여 연구되었음.
참고문헌
1. K. Song, G. Kim, T. Kim, C. Ryu, S. Park, J.H. Lee, J.K.
Lee, and S. Hwang, “Trusted Reality Technology, from a Post-Smartphone Perspective,” Electronics and Telecommunications Trend, 2018.
2. P. Viola and M. J. Jones, “Robust real-time face detection,” International Journal of Computer Vision, vol. 57, no. 2, pp. 137-154, 2004.
3. N. Dalal and B. Triggs, “Histograms of Oriented Gradients for Human Deection,” Computer Vision and Pattern Recognition, vol.1, pp. 886-893, 2005.
4. E. Osuna, R. Freund and F. Girosit, “Training support vector machines: an application to face detection,” In IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR’97), pp. 130-136, San Juan, Puerto Rico, 1997.
5. Y. Freund and R. E. Schapire, “Experiments With a New Boosting Algorithm. In Machine Learning,” In Proceedings of the Thirteen International Conference In Machine Learning, Bari, pp. 148-156, 1996.
6. Y. Chu, B. Lee and Y. Choi, “A Video based Traffic Light Recognition System for Intelligent Vehicles,”
Journal of the Semiconductor & Display Technology, Vol. 14, No. 2. June 2015.
7. A. Krizhevsky, I. Sutskever and GE. Hinton, “Imagenet classification with deep convolutional neural networks,”
In proc. Advances in Neural Information Processing Systems 25, pp. 1090-1098, 2012.
8. C. Szegedy, et al., “Going Deeper with Convolutions,”
In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1-9, 2014.
9. K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” In Proc. International Conference on Learning Representations, http://arxiv.org/abs/1409.
1556, 2014.
10. K. He, X. Zhang, et al., “Deep Residual Learning for Image Recognition,” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778, 2016.
11. B. Liu and X. Zang, “Caffe2 vs. TensorFlow: Which is a Better Deep Learning Framework?” Stanford University, http://cs242.stanford.edu/assets/projects/ 2017/liubaige- xzang.pdf
12. G. Levi and T. Hassner, “Age and Gender Classification Using Convolutional Neural Networks,” IEEE Workshop on Analysis and Modeling of Faces and Gestures (AMFG), at the IEEE Conf. on CVPR, Boston, June 2015.
접수일: 2019년 5월 3일, 심사일: 2019년 6월 15일, 게재확정일: 2019년 6월 18일