Nonparametric clustering of functional time series electricity consumption data
Jaehee Kim a,1
a
Department of Statistics, Duksung Women’s University
(Received November 15, 2018; Revised December 16, 2018; Accepted December 22, 2018)
Abstract
The electricity consumption time series data of ‘A’ University from July 2016 to June 2017 is analyzed via nonparametric functional data clustering since the time series data can be regarded as realization of continuous functions with dependency structure. We use a Bouveyron and Jacques (Advances in Data Analysis and Classification, 5, 4, 281–300, 2011) method based on model-based functional clustering with an FEM algorithm that assumes a Gaussian distribution on functional principal components. Clusterwise analysis is provided with cluster mean functions, densities and cluster profiles.
Keywords: ARIMA, electricity consumption, functional clustering, functional data analysis
1. 서론
2017년 우리나라의 전기 사용량이 세계에서 7번째로 많았다고 유럽계 에너지 분야 전문 컨설팅업체 에너데이터가 밝혔다. 우리나라의 전력 소비량은 총 534TWh(테라와트시)로, 2016년(522TWh)보다 2.3% 늘었다. 경제규모(국내총생산 기준 세계 12위)와 인구(27위)에 비해 전기 사용이 많은 편이다.
전력 소비량 증가율은 선진국 진영에서 두 번째로 높아 사실상 ‘전기 과소비국’이라는 지적이 나왔다.
우리나라의 전력 소비량 증가율이 높은 것은 철강과 석유화학, 반도체 등 전기를 많이 쓰는 산업의 비중 이 크기 때문으로 여겨진다. 지난 10년간 주택용과 일반용(상업용) 전기 소비는 완만한 증가세를 보였 으나 산업용의 증가율이 두드러졌으며 2017년 전체 전력 소비량에서 차지하는 산업용 비중은 56%이다.
현재 전기의 과도한 사용을 줄이기 위해서 전기 사용량 증가에 대해 비례 이상으로 세율을 증가시키는 전기 누진세 제도가 도입되었다. 그 결과 누진세 부과 등으로 전기 사용량이 높은 경향을 보이면 전기 사용량을 줄이는 것이 기업들과 개인 가구들의 관심사가 되었으며 국가 차원에서도 관리해야할 문제이 이다. 그러므로 한국전력공사 등 여러 기관에서는 전기 사용량에 대한 분석을 여러 각도로 심도있게 진 행하고 있다.
This research was supported by the Korea Institute of Energy Technology Evaluation and Planning (KETEP) and the Ministry of Trade, Industry & Energy (MOTIE) of the Republic of Korea (No. 20161210200610).
Also it was supported by Korea Electric Power Corporation (Grant number:R18XA01).
1
Department of Statistics, Duksung Women’s University, Samyang-ro 144-Gil 33, Dobong-Gu, Seoul 01369,
Korea. E-mail: [email protected]
전기사용량 데이터에 대한 시계열 분석으로 여러 가지 모형이 적합되었다. Chujai 등 (2013)은 2006년 부터 2010년까지 기간 동안 1분 단위로 샘플링이 된 한 가구의 전력 소비 데이터에 대해서 auto- regressive integrated moving average model (ARIMA) 모형으로 예측을 하였고, Abdel-Aal와 Al- Garni (1997) 는 사우디 아라비아 동부 주의 1987년 8월부터 6년간의 월간 전기 소비량에 대해 회귀분 모형과 generalized autoregressive conditional heteroskedasticity (GARCH) 네트워크 머신러닝 모형 을 비교하였다. 전기 사용량 시계열 데이터에 대한 예측 모형으로 ARIMA, 계절성을 포함한 seasonal ARIMA (SARIMA), 변동성을 포함한 GARCH 모형 등은 널리 활용되었다. 모형에 대한 자세한 설명 은 Cryer와 Chan (2008)을 참고하면 된다. 그외 시계열 분석 예로 Kim과 Kim (2013)는 원, 달러 데 이터에 대해 ARIMA + IGARCH 모형을 적합하고 환율을 예측하였다. Tan 등 (2010)은 2002년 스페 인의 전자상거래 데이터에 대해 ARIMA, ARIMA + GARCH, 그리고 소파동 변환(wavelet transfor- mation) 을 이용한 ARIMA + GARCH 등의 모형을 비교하였다.
지수적 스무딩 기법으로는 홀트-윈터스(Holt-Winters) 방법이 널리 이용된다. 홀트-윈터스 방법은 현 재 데이터와 가까울수록 과거 데이터의 가중값을 크게 주어 합산한 후 다음 데이터를 예측하는 지수평 활법의 여러 기법 중 하나이며, 다른 지수평활법의 종류로 단순 지수평활법, 이중지수 평활법, 삼중지 수 평활법 등이 있다 (Gardner, 1985). 홀트-윈터스 방법은 단순 지수평활법과 이중 지수평활법의 단 점을 보완한 모형으로 계절성과 추세를 동시에 고려하여 추정할 수 있다. 추세와 계절성 둘 다 가법 으로 적용한 모형은 가법 홀트-윈터스 방법, 추세는 가법, 계절성은 승법으로 적용한 승법 홀트-윈터 스 방법으로 분류된다. Gardner (1985)는 추세와 계절성에 따라 지수평활법을 자세하게 나타내었다.
Bianchi 등 (1998)은 텔레 마케팅 센터에서 예산과 계획을 목적으로 전화가 걸려오는 수를 예측하기 위 해서 ARIMA 모형과 홀터-윈터스 방법을 이용한 모형으로 분석하였다. Kimball (1974)은 날짜에 따 라 함수량 등 재배학 변수들로 이루어진 변수들을 평활화 기법과 푸리에 변환으로 분석하였다. Fumi 등 (2013)은 푸리에 변환을 사용하여 패션 회사의 수요 예측을 분석하였다.
전기사용량 시계열 데이터는 연속인 함수데이터(functional data)로 간주할 수 있으며 이러한 관점으 로 최근 함수데이터분석(functional data analysis; fda) 기법 기반 분석에 대한 제안이 증가하고 있다.
일일 15분간으로 측정된 전기사용량 시계열 데이터는 하루내(intra-daily) 전기 사용 패턴을 사용량 곡 선(load curve)으로 함수적 자기회귀과정(functional autoregressive process)에 의해 발생한다고 볼 수 있다. 또한 이러한 곡선에 영향을 미치는 이산적 데이터의 집합으로 볼 수 있어 함수적 데이터로 다룰 수 있으며 함수회귀모형(functional regression model)을 이용해 분석할 수 있게된다. 비모수적 방법 적 용도 가능해지며 오차항의 비독립 구조에 대해서도 다양한 공분산 함수 구조를 고려할 수 있다.
Andersoon 과 Lillestøl (2010)은 fda 기법으로 일일 전기사용량 데이터에 대해 functional analysis of variance (FANOVA) 와 functional autoregressive (FAR) 모형을 적합하여 fda 기법의 유용성을 보였 다. Antoch 등 (2010)은 전기사용량 곡선데이터에 대해 함수선형모형(functional linear model)을 응 용하여 예측하였다. Goia 등 (2010)은 fda 기법 기반으로 군집화한 후 군집별 판별함수를 구하고 단기 최고점 사용량 예측을 하였다.
본 연구의 목적은 시계열데이터를 함수데이터로 간주하여 군집분석으로 군집화하는 것이다. 군집분석 의 목적은 비슷한 사용패턴을 갖는 함수데이터들을 같은 군집으로 묶고 군집별 적합한 모형을 찾는 것 이다. 또한 이러한 군집별 모형을 예측모형으로도 활용할 수 있게 된다. 본 논문의 구성은 다음과 같다.
제 2장에서는 본 연구에서 사용한 전기 사용량 데이터에 대해서 설명과 탐색을 한다. 제 3장에서는 fda
모형 기반 비모수적 군집분석에 대해서 설명하고 분석한다. 제 4장에서는 군집분석에 대한 결과를 설명
하고 함수적 판별분석을 적용하고 예측에 활용하는 방법을 제안한다. 마지막으로 간단한 결론을 5장에
서 내린다.
0 100 200 300
2000 3000 4000 5000 6000
electricity submeter data: U
2016 July to 2017 June
electr icity consumption
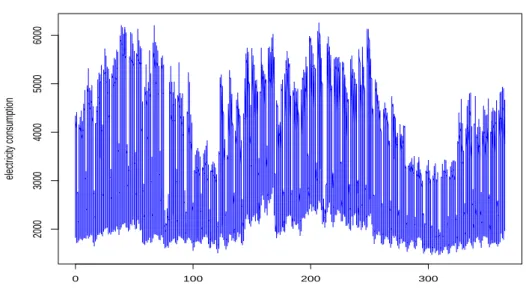
Figure 2.1. A University electricity consumption data.
2. 전기 사용 데이터
본 논문에서 사용한 데이터는 2016년 7월부터 2017년 6월까지 1년간 인천 소재 A 대학교의 15분 단위 의 일일 전기 사용량 시계열 데이터이다. 2만여명의 학생과 교직원이 있으며 연중으로 보면 개학기간과 방학기간이 있다. 전기사용 특성을 보면 보통 주말과 휴일에는 수업 등이 없으므로 전기사용이 적은 편 이고 평일에는 많은 편이다. 결측치에 대해서는 결측치가 포함된 해당 달의 평일/주말 여부를 고려하여 같은 요일의 전기 사용량의 평균을 구하여 대체하였다. 하루 동안의 전기사용량은 스무드한 흐름을 보 여주는 변수로 생각할 수 있으며 이러한 특성을 반영해 통계적 모형을 고려할 수 있다. 하루의 사용량 이 96개의 관측값을 가진 96차원에 놓인 값으로 보는 대신 한 개 곡선으로 고려하여 함수데이터로 다루 고자 한다. 하루 동안의 서로 다른 시점에서의 사용량은 서로 독립이 아니며 연속된 곡선으로 나타낼 수 있으며 이러한 smothness는 전기사용량에 대한 정보를 포함하므로 통계적 모형에 활용할 수 있다.
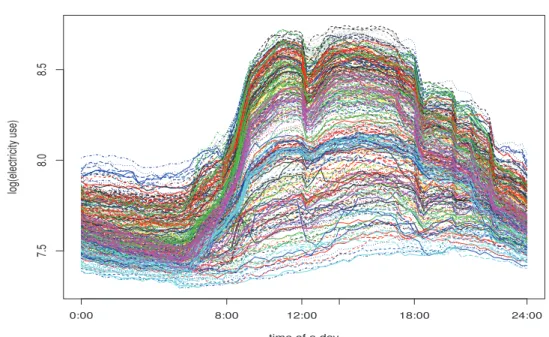
Figure 2.1은 1년 동안의 전기사용량 데이터의 움직임을 보여주는 시계열 그림으로 일, 주일, 월 등의 주기가 존재하는 것으로 보인다. 일주일 주기를 살펴보면 토, 일요일에는 평일보다 전기 사용량이 현저 히 줄기 때문에 그래프의 진폭이 크고 파장은 짧은 편이다. 그리고 1년 주기를 보면 매년 전기 사용량이 비슷한 편이며, 전력수요가 높은 여름과 겨울이 다른 계절에 비해서 사용량이 높다. 사용량의 큰 값과 분산 안정화를 고려하여 데이터의 로그변환을 하여 분석에 이용하고자한다. Figure 2.2는 365일 매일의 15분 단위 전력사용량으로 매일 96번 측정된 데이터에 대한 시계열그림이다(월별 다른 색깔). 사용량에 대한 히스토그램을 그려보면 비대칭적이다 (그림 생략). 지연효과(lag effect)를 보기위해 사용량에 대 한 lag 1 시점과의 산점도와 lag 2 시점과의 산점도를 그려보면 각각 상관성이 높다 (lag 그림 생략).
3. 전기 사용 데이터에 대한 함수데이터 기반 비모수적 군집분석
관측값이 확률적 집합(random family) {X(t
j) }
j=1,...,n에서 발생하고 데이터를 연속 곡선(curve)으로
7.5 8.0 8.5
time of a day
log(electr icity use)
0:00 8:00 12:00 18:00 24:00
Figure 2.2. Everyday electricity consumption plot.
볼 수 있는 경우가 여러 분야에서 발생한다. 이러한 데이터에 대해 데이터가 연속집합족(continuous family) χ = {X(t); t ∈ (t
min, t
max)}에서 발생한다고 고려할 수 있다. 여기서 χ는 함수적 변수(func- tional variable)라 하고 관측값은 무한 차원 공간(infinite dimensional space 또는 functional space)에 서 값을 가지며 이런 관측데이터를 함수데이터라고 한다.
함수데이터 x
i(t), i = 1, . . . , n = 365를 곡선 표본(sample of curve)이라고 놓는다. 정리통계량으로 표 본평균함수(sample mean function)와 분산함수(variance function)는 다음과 같다:
¯ x
t= 1
n
∑
i
x
i(t), s
t= 1 n − 1
∑
i
[x
i(t) − ¯x
t]
2. (3.1)
x
i(s) 와 x
i(t) 에 대한 이변량 공분산함수(bivariate covariance function) ν(s, t)는 시점 s와 t에서의 연 관성을 보여주며 다음과 같이 정의된다:
ν(s, t) = 1 n − 1
∑
i
[x
i(s) − ¯x(s)][x
i(t) − ¯x(t)]. (3.2)
X에 대한 주성분 {C
j}
j≥1은
C
j=
∫
T0
(X(t) − µ(t))ψ
j(t)dt (3.3) 와 같이 정의된다. 여기서 µ(t) = E[X(t)]는 X의 평균함수(mean function)를 나타낸다. ψ
j는 X의 공 분산에 대한 고유함수를 형성하는 orthonormal system이다.
∫
T0
Cov(X(t), X(s))ψ
j(s)ds = λ
jψ
j(t)dt, ∀t ∈ [0, T ].
주성분에 대한 분산은 고유값 λ
1≥ λ
2≥ · · · 으로 크기순을 갖는다. 주성분 {C
j}
j≥1는 평균 0을 갖고 서로 상관되지 않으며 분산 λ
j를 갖는다. Karhunen–Loeve expansion (Karhunen 1947; Loeve 1945) 으로
X(t) = µ(t) + ∑
j≥1
C
jψ
j(t), t ∈ T (3.4)
를 얻는다. 실제 계산시에는 다음과 같이 처음부터 q개를 사용하게 된다:
X(t) = µ(t) +
∑
q j=1C
jψ
j(t), t ∈ T . (3.5)
함수데이터에 대한 군집화 방법에는 일반적으로 다음과 같은 네 가지 접근법이 있다.
(i) raw data method: 곡선데이터를 구성하는 데이터 자체를 그대로 기저함수점으로 이용하여 군집 화한다.
(ii) filtering method: 곡선데이터를 구성하는 데이터를 선택한 기저함수(basis function) 기반으로 근사한 후 함수값으로 군집화한다.
(iii) adaptive method: 곡선데이터를 군집에 의존한 혼합모형 형태로 구성하며 차원축소와 군집화를 동시에 진행한다.
(iv) distance-based method: 함수데이터에 대해 특정한 거리함수를 선택한 후 거리 기반으로 군집화 한다.
우선 거리 기반 군집화에 대해 간단히 살펴보고자 한다. 함수데이터 {X(t
j) }
j=1,...,n에 대한 k-means 군집화는 L개 군집을 가정하고 L개 군집 중심 {µ
1, . . . , µ
L}을 찾고자 한다. 적절한 함수 거리측도 d를 사용하여 {X(t
j)}와 군집중심간의 제곱합을 최소화하도록 배정된 군집번호(cluster label) {C
j, j = 1, . . . , n}를 부여하게 된다. 군집 개수 L은 군집간의 차이가 유의하도록 하며 미리 정한다.
함수군집화(functional clustering)는 목적함수(object function) 1
n
∑
i
d
2(X
i, µ
cn),
여기서 µ
cn(t) = ∑
i
X
i(t)1
[Ci=c]/N
c, N
c= ∑
i
1
[Ci=c]를 최소화하도록 L개 그룹으로 나누게 된다.
일반적으로 무한 차원에 놓이는 함수데이터를 기저함수의 집합 공간으로 저차원(low dimension) 공간 으로 사영(project)하여 결과를 얻을 수 있다. 거리함수 d는 L
2거리를 널리 사용한다. L
2에서의 기 저함수 집합 {φ
1, φ
2, . . .}을 선택한 후 초기 K개 사영 B
k= ⟨X
c, φ
k⟩, k = 1, . . . , K으로 표현한다.
여기서 X
c는 평균을 보정한 X 값이다. 널리 쓰이는 한 예로 X
i에 대한 truncated Larhunen-Loeve expansion 을 들 수 있는데 여기서의 기저함수는 X 과정의 자가공분산(auto-covariance operator)의 고 유함수들 {ϕ
1, ϕ
2, . . .}이다. 함수데이터는 랜덤함수의 실현값으로 간주되므로 군집 중심을 결정할 때 고유함수 집합과 군집 평균에 의해 만들어지는 공간에서 랜덤함수의 확률구조를 고려해야한다. X
i에 대한 군집 소속 확률을 고려한다면 다음의 조건부확률 P
C|X(c |X
i) 을 활용한다.
c
∗(X
i) = arg max
c∈{1,...,L}
P
C|X(c|X
i).
Chiou 와 Li (2007)과 Chiou (2012)는 이러한 접근으로 multi-class 문제를 다룬다.
이번에는 본 연구에서 적용하고자 하는 adaptive method로 Bouveyron과 Jacques (2011) 기법을 설명 한다. 함수데이터에 대해 잠재적인 변수를 도입하여 모형기반 혼합 모형에 대해 functional EM (FEM) 알고리듬을 사용하여 군집을 정할 수 있다. Bouveyron과 Jacques (2011)은 FPCA에 대해 Gaussian 분포를 가정하고 확률모형 기반으로 혼합모형을 기반으로 군집기법을 제안하였다. 만일 X
i가 g번째 군 집에 속한다면 Z
i,g= 1, 1 ≤ g ≤ L이고 그외에는 Z
i,g= 0이다. Z
i= (Z
i,1, . . . , Z
i,L) ∈ {0, 1}으로 군 집에 속한 여부를 나타내는 지시변수이다. 군집분석에서는 (X, Z)에 대해
f
X(q)(x; θ) =
∑
L k=1π
k qk∏
j=1
f
Cj|Zk=1(c
jk(x); λ
jk),
여기서 θ = (π
k, λ
1k, . . . , λ
qk,k)
1≤k≤L는 모형의 모수로 군집비율(cluster proportion)과 주성분 분 산(principal component variance)을 나타낸다. q
k는 k번째 군집에 해당하는 Karhunen-Loeve ex- pansion 에서 차수(truncated order), f
Cj|Zk=1는 X의 j번째 주성분의 확률밀도함수이고 c
jk(x) 해 당 주성분점수(principal score)를 나타낸다. 근사우도함수(approximate likelihood)를 계산한 후 expectation-maximization (EM) 알고리듬을 이용하여 c
jk(x)가 계산되고 그룹에 포함 확률은 maxi- mum a posteriori (MAP) 규칙에 따른다.
4. 전기 사용 데이터에 대한 함수데이터 회귀 및 판별분석
4.1. 함수데이터 분류를 위한 회귀
회귀모형 기반 함수데이터 분류 모형을 고려해 보자. 함수이항회귀(functional binary regression)로 함 수로지스틱회귀(functional logistic regression)을 들 수 있다. {(Z
i, X
i); i = 1, . . . , n }은 랜덤표본집합 이다. 여기서 Z
i는 랜덤표본이고 Z
i∈ {1, . . . , L}는 X
i에 대한 그룹 라벨이다. 관측값 X
0에 대해 함수 로지스틱회귀 분류 모형은
log P (Z
i= k|X
0)
P (Z
i= L |X
0) = γ
0k+
∫
T0
X
0(t)γ
1k(t)dt, k = 1, . . . , L − 1,
여기서 γ
0k는 절편항, γ
1k는 회귀계수이다. 함수데이터에 대한 기저 오즈 모형(baseline odds model in multinomial regression) 으로 P (Z
i= L |X
i) = 1 − ∑
Lk=1
P (Z
i= k |X
i) 를 계산할 수 있다 (McCul- lagh 등, 1983). 새로운 관측값 X
0에 대해 모형기반 베이즈 분류규칙은 다음과 같다: 군집 라벨 Z
0는 {P (Z
0= k|X
0); k = 1, . . . , L} 중 사후 확률이 가장 큰 그룹으로 분류하면된다. Leng과 Muller (2006) FPCA 접근법으로 일반화 함수 선형회귀를 사용했고 Araki 등 (2009), Matsui 등 (2011), Wang 등 (2007), Zhu 등 (2010), 그리고 Rincon과 Ruiz-Medina (2012)은 함수로지스틱회귀 모형에 대한 여러 형태를 제안하였다.
4.2. 함수데이터 분류를 위한 판별분석
베이즈 규칙에 의해서 새로운 관측이 주어졌을때 그룹 라벨 변수에 대해 가장 큰 확률을 갖는 그룹으로 분류할 수 있다. k번째 그룹이 사전확률 π
k, ∑
k
π
k= 1 을 갖는다. k번째 그룹에 대한 확률밀도함수는 f
k로 놓는다. X
0에 대한 사후 확률은 다음과 같이 주어진다.
P (Z = k|X
0) = π
kf
k(X
0)
∑
Lk=1
π
kf
k(X
0)
0.0 0.2 0.4 0.6 0.8 1.0
7.58.08.5
2016 July
time
value
0.0 0.2 0.4 0.6 0.8 1.0
7.58.08.5
2016 August
time
value
0.0 0.2 0.4 0.6 0.8 1.0
7.58.08.5
2016 September
time
value
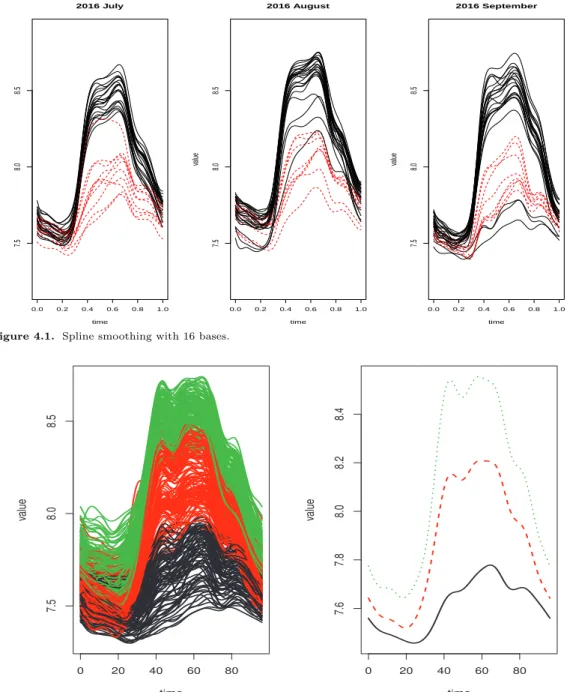
Figure 4.1. Spline smoothing with 16 bases.
0 20 40 60 80
7.5 8.0 8.5
time
value
0 20 40 60 80
7.6 7.8 8.0 8.2 8.4
time
value
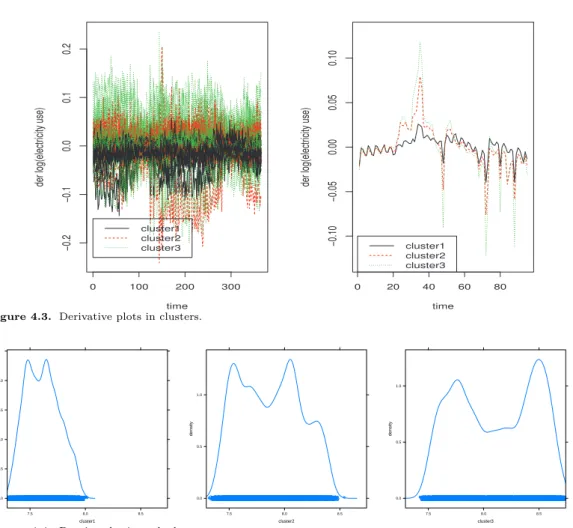
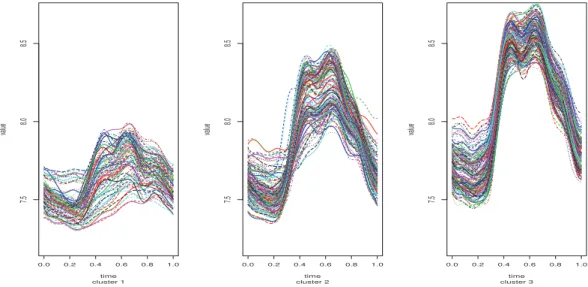
Figure 4.2. Cluster plot with smooth curves (left: 365 curves, right: cluster means).
James 등 (2000)은 FPCA를 사용하여 함수적 선형 판별기법(functional linear discriminant ap- proach)를 제안했고 Hall 등 (2006)은 FPCA 기반 차원 축소법을 제안했다. Ferraty와 Vieu (2003, 2006), Chang 등 (2014) 그리고 Zhu 등 (2012)은 비모수적 커널함수적 분류기법을 제안했다.
Figure 4.1 에서는 16개 기저함수를 사용하여 스플라인 함수를 적합시켜 7, 8, 9월에 속한 날짜에 대한
0 100 200 300
−0.2 −0.1 0.0 0.1 0.2
time
der log(electr icity use)
cluster1 cluster2 cluster3
0 20 40 60 80
−0.10 −0.05 0.00 0.05 0.10
time
der log(electr icity use)
cluster1 cluster2 cluster3
Figure 4.3. Derivative plots in clusters.
cluster1
density
0.0 0.5 1.0 1.5 2.0
7.5 8.0 8.5
cluster2
density
0.0 0.5 1.0
7.5 8.0 8.5
cluster3
density
0.0 0.5 1.0
7.5 8.0 8.5
Figure 4.4. Density plot in each cluster.
적합곡선을 보여준다(검정 실선: 주중, 빨간 점선: 주말). 9월 중 아래쪽에 평일 3개선이 주말 패턴과 비슷해 보이는데 2016년 9월 14(수), 15(목), 16일(금)이 추석 연휴이기 때문이다. Figure 4.2는 군집 분석 결과 군집별 곡선을 보여준다. 평균법을 이용한 계층적 군집화 방법에 의한 시간점을 변수로 간 주한 다변량데이터에 대한 덴드로그램으로 군집 개수 3개를 선택하고자한다(덴드로그램 생략). Figure 4.3에서는 군집별 1차 미분 데이터로 매 시점에서 뿐만아니라 최고점(peak)에 이르는 속도가 다름을 알 수 있다. Figure 4.4는 군집별 확률밀도함수를 보여주는데 군집1의 전기 사용량은 군집2와 군집3에 비 해 범위가 다르고 분포함수 모양도 다름을 알 수 있다. Figure 4.5는 군집별 스플라인 기저함수에 적합 된 모양을 보여준다.
본 연구에서는 Bouveyron 등 (2014)이 제안한 방법으로 판별분석에 함수적 혼합 모형 기반 군집화방
법으로 funFEM 알고리듬을 적용하였다. 이 방법을 시계열 데이터를 함수데이터로 볼 수 있는 경우에
도 적용가능하며 시점에 많은 시계열 데이터에대해서도 적용가능하다. Table 4.1에서는 군집별 주중과
주말의 분포를 보여준다. 군집1에는 주말이, 군집3에는 주중이 대부분이고 군집2에는 주중평일 일부
가 포함되어 있다. Table 4.2에서는 군집마다 월별 분포를 보여준다. 군집1에 주말이, 군집3에는 주중
이 대부분이고 군집2에는 4, 5, 6월, 그리고 9, 10, 11월 등 개학기간중 평일이 주로 포함되어있다. 군
0.0 0.2 0.4 0.6 0.8 1.0
7.58.08.5
cluster 1 time
value
0.0 0.2 0.4 0.6 0.8 1.0
7.58.08.5
cluster 2 time
value
0.0 0.2 0.4 0.6 0.8 1.0
7.58.08.5
cluster 3 time
value
Figure 4.5. Smooth functions in each cluster (16 spline bases).
Table 4.1. Comparison of clusters via distribution according to weekdays
Cluster Mon Tue Wed Thr Fri Sat Sun Cluster total Prop
1 2 2 3 1 3 31 40 82 0.225
2 24 16 17 21 27 21 12 138 0.378
3 26 34 32 30 23 0 0 145 0.397
Table 4.2. Comparison of clusters via distribution according to month
Cluster Jan Feb Mar Apr May Jun July Aug Sep Oct Nov Dec
1 6 2 8 11 11 9 5 2 8 11 6 3
2 6 6 8 19 19 17 12 9 4 18 10 10
3 19 20 15 0 1 4 14 20 18 2 14 18
Table 4.3. Classification according to functional linear discriminant functions obtained
True cluster / Classified 1 2 3 Total
1 80 2 0 82
2 4 127 7 138
3 0 5 140 145
집3에서의 전기사용량이 군집2 보다 큰 편인데 기온이 높은 여름 6, 7월과 기온인 낮은 겨울철 11, 12,
1, 2 월의 평일들이 주로 포함되어 계절의 영향으로 군집2와 분리된 것으로 여겨진다. Table 4.3은 분
류된 군집을 참 군집(true cluster)으로 놓고 훈련데이터(train data)를 시험 데이터(test data)로 간주
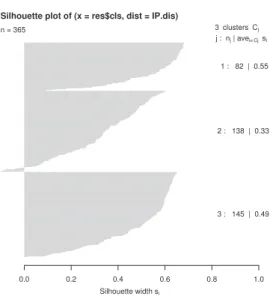
하여 재분류한 결과로 정확한 분류율은 95.1%이고 오류율은 4.9%이다. Figure 4.6에서는 실루엣 그
림(silhouette plot)을 보여주며 군집내 연결성 측도로 각 군집의 실루엣 값이 큰 편이며 평균 실루엣
값은 0.44이다 (−1.0 ≤ silhouette ≤ 1.0 : 값이 클수록 내부 연결성 좋다). 다른 군집 연결성 측도
로 connectivity = 43.727을 얻었으며 상대적으로 작은 값이므로 연결성도 좋은 편이라고 할 수 있다
(0 ≤ connectiity < ∞: 값이 작을수록 연결성 좋다). 참고로 군집 개수 L = 4인 경우 평균 실루엣값은
0.42, 연결성 측도값은 46.042이다.
Silhouette width si
0.0 0.2 0.4 0.6 0.8 1.0
Silhouette plot of (x = res$cls, dist = IP.dis)
Average silhouette width : 0.44
n = 365 3 clusters Cj
j : nj | avei∈Cj si
1 : 82 | 0.55
2 : 138 | 0.33
3 : 145 | 0.49
Figure 4.6. Silhouette plot for cluster validity.
군집이 결정된 후에는 군집별 시계열 모형을 적합할 수 있으며 이와 같이 추정한 모형 기반 예측이 가능 하다. 월과 일 그리고 휴일여부 등으로 사용량 패턴에 영향을 주는 변수들을 사용하여 의사결정나무를 만들어 속하는 군집모형에 따른 예측을 할 수 있다. 또한 새로운 날의 시계열 데이터를 함수데이터로 간 주하여 함수적 판별분석으로 군집에 배치한 후 해당 군집에서의 모형을 기반으로 예측할 수도 있다. 그 외의 다른 단계적인 방법 등을 이용해 군집후 예측까지 가능하다.
5. 결론
본 연구에서는 대학교 건물 전체에 대해 15분마다의 일일 사용되는 전기 사용량 데이터에 대한 분석으 로 적절한 모형을 찾고 이를 기반으로 사용량 예측을 하였다. 로그변환 데이터를 사용하여 함수데이터 기법으로 3개의 군집으로 나누고 각 군집의 대표함수와 군집에 속한 일 사용량에 대해 분석하고 이를 기 반으로 예측에 활용할 수 있도록 하고자 한다. 이와 같이 군집분석후 군집별 모형기밥 예측이 가능하므 로 후속연수가 필수적이라 생각된다.
일반적으로 전기 사용량은 건물의 이용 특성과 이용자 특성에 따라 다른 패턴을 보여준다. 그러므로 건 물의 전기사용적 특성과 데이터 특징을 잘 파악하고 탐색적 분석을 한후 적절한 모형을 찾아야한다. 전 기사용량 분석은 전기수급 조절과 사용 예측 및 준비 등에 매우 중요한 연구이므로 지속적인 데이터 수 집과 분석이 필요하다. 또한 전기 사용량은 외부상황 즉 기온, 습도, 휴일여부 등에 영향을 받으므로 향 후 연구로는 이런 설명변수들을 포함한 함수데이터 기법으로 모형 기반 군집화에 대한 연구가 필요하다.
References
Abdel-Aal, R. E and Al-Garni, A. Z. (1997). Forecasting monthly electric energy consumption in eastern Saudi Arabia using univariate time-series analysis, Energy, 22, 1059–1069.
Andersson, J. and Lillestøl, J. (2010). Modeling and forecasting electricity consumption by functional data analysis, Journal of Energy Markets, 3, 3–14.
Antoch, J., Prchal, L., De Rosa, M., and Sarda, P. (2010). Electricity consumption prediction with func-
tional linear regression using spline estimators, Journal of Applied Statistics, 37, 2027–2041.
Araki, Y., Konishi, S., Kawano, S., and Matsui, H. (2009). Functional logistic discrimination via regularized basis expansions, Communications in Statistics-Theory and Methods, 38, 2944–2957.
Bianchi, L., Jarrett, J., and Hanumara, R. C. (1998). Improving forecasting for telemarketing centers by ARIMA modeling with intervention, International Journal of Forecasting, 14, 497–504.
Bouveyron, C. and Jacques, J. (2011). Model-based clustering of time series in group-specific functional subspaces, Advances in Data Analysis and Classification, 5, 281–300.
Chang, C., Chen, Y., and Ogden, R. T. (2014). Functional data classification: a wavelet approach. Com- putational Statistics, 29, 1497–1513.
Chiou, J. M. (2012). Dynamical functional prediction and classification, with application to traffic flow prediction, Annals of Applied Statistics, 6, 1588–1614.
Chiou, J. M. and Li, P. L. (2007). Functional clustering and identifying substructures of longitudinal data, Journal of the Royal Statistical Society, Series B, 69, 679–699.
Chujai, P., Kerdprasop, N., and Kerdprasop, K. (2013). Time series analysis of household electric consump- tion with ARIMA and ARMA models, The International MultiConference of Engineers and Computer Scientists, 1, 295–300.
Chang, C., Chen, Y., and Ogden, R. T. (2014). Functional data classification: a wavelet approach, Com- putational Statistics, 29, 1497–1513.
Cryer, J. and Chan, K. (2008). Time Series Analysis (2nd ed), Springer, New York.
Ferraty, F. and Vieu, P. (2003). Curves discrimination: a nonparametric functional approach, Computa- tional Statistics & Data Analysis, 44, 161–173.
Ferraty, F. and Vieu, P. (2006). Nonparametric Functional Data Analysis, Springer, New York.
Fumi, A., Pepe, A., Scarabotti, L., and Schiraldi, M. M. (2013). Fourier analysis for demand forecasting in a fashion company, International Journal of Engineering Business Management, 5, 1–10.
Gardner, E. S. (1985). Exponential smoothing: the state of the art, Journal of Forecasting, 4, 1–28.
Goia, A., May, C., and Fusai, G. (2010). Functional clustering and linear regression for peak load forecasting, International Journal of Forecasting, 26, 700–711.
Hall, P., Muller, H. G., and Wang, J. L. (2006). Properties of principal component methods for functional and longitudinal data analysis, Annals of Statistics, 34, 1493–1517. sampled curves, Journal of the Royal Statistical Society Series B-Statistical Methodology, 63, 533–550.
James, G. M., Hastie, T., and Sugar, C. (2000). Principal component models for sparse functional data, Biometrika, 87, 587–602.
Karhunen, K. (1947). On linear methods in probability theory, Annales Academiae Scientiarum Fennicae, AI 37, 3–79.
Kim, B. and Kim, J. (2013). Time series models for daily exchange rate data, The Korean Journal of Applied Statistics, 26, 14–27.
Kimball, B. A. (1974). Smoothing data with Fourier transformations, Agronomy Journal, 66, 259–262.
Leng, X. and Muller, H. G. (2006). Time ordering of gene co-expression, Biostatistics, 7, 569–584.
Loeve, M. (1945). Nouvelles classes de lois limits, Bulletin de la S. M. F., 73, 107–126.
Matsui, H., Araki, T., and Konishi, S. (2011). Multiclass functional discriminant analysis and its application to gesture recognition, Journal of Classification, 28, 227–243.
McCullagh, P. (1983). Quasi-likelihood functions, Annals of Statistics, 11, 59–67.
Ramsay, J. and Silverman, B. (1997). Functional Data Analysis. Springer.
Rincon, M. and Ruiz-Medina, M. D. (2012). Wavelet-RKHS-based functional statistical classification, Ad- vances in Data Analysis and Classification, 6, 201–217.
Tan, Z., Zhang, J., Wang, J., and Xu, J. (2010). Day-ahead electricity price forecasting using wavelet transform combined with ARIMA and GARCH models, Applied Energy, 87, 3606–3610.
Wang, X. H., Ray, S., and Mallick, B. K. (2007). Bayesian curve classification using wavelets, Journal of the American Statistical Association, 102, 962–973.
Zhu, H. X., Brown, P. J., and Morris, J. S. (2012). Robust classification of functional and quantitative image data using functional mixed models, Biometrics, 68, 260–1268.
Zhu, H. X., Vannucci, M., and Cox, D. D. (2010). A Bayesian hierarchical model for classification with
selection of functional predictors, Biometrics, 66, 463–473.
전기 사용량 시계열 함수 데이터에 대한 비모수적 군집화
김재희 a,1
a
덕성여자대학교 정보통계학과
(2018 년 11월 15일 접수, 2018년 12월 16일 수정, 2018년 12월 22일 채택)
요 약
본 연구는 2016년 7월부터 2017년 6월까지 인천 소재 A 대학교의 15분 단위의 일일 전기 사용량 시계열 데이터 에 대해 functional data analysis 기법을 적용하여 군집화하고 각 군집의 특성을 파악하고 예측에 활용하고자 한다.
하루동안의 A 대학교의 전기 사용량은 패턴은 주중과 주말 에 큰 차이를 보이며 스플라인 기저함수로 FPCA 구한 후 이들에 대한 가우시안 분포의 혼합모형 기반 군집분석으로 3개의 군집화가 적절해 보인다. 각 군집에 대해 평균 함수, 확률밀도함수, 일들의 분포 등을 정리해 각 군집에 대한 정보와 특징을 보여준다.
주요용어: 군집분석, 시계열모형, 스플라인 스무딩, 예측모형, 전기 사용량, 함수데이터분석
이 논문은 산업통상자원부(MOTIE)와 한국에너지기술평가원(KETEP) 의 지원을 받아 수행된 연구과제입니다 (No. 20161210200610). 또한 본 연구는 한국전력공사의 2018년 착수 에너지 거점대학 클러스터 사업에 의해 지원되었습니다.
1