The Korean Journal of Applied Statistics
2021, Vol. 34, No. 1, 99–114 DOI: http://dx.doi.org/10.5351/KJAS.2021.34.1.099
A case study on the application of process abnormal detection process using big data in smart factory
Hyunwoo Nam
1,aaDepartment of Applied Statistics, Gachon University
Abstract
With the Fourth Industrial Revolution based on new technology, the semiconductor manufacturing industry researches various analysis methods such as detecting process abnormalities and predicting yield based on equip- ment sensor data generated in the manufacturing process. The semiconductor manufacturing process consists of hundreds of processes and thousands of measurement processes associated with them, each of which has proper- ties that cannot be defined by chemical or physical equations. In the individual measurement process, the actual measurement ratio does not exceed 0.1% to 5% of the target product, and it cannot be kept constant for each measurement point. For this reason, efforts are being made to determine whether to manage by using equipment sensor data that can indirectly determine the normal state of each step of the process. In this study, the Functional Data Analysis (FDA) was proposed to define a process abnormality detection process based on equipment sensor data and compensate for the disadvantages of the currently applied statistics-based diagnosis method. Anomaly detection accuracy was compared using machine learning on actual field case data, and its effectiveness was verified.
Keywords: smart factory, semiconductor manufacturing process, equipment sensor data, abnormality detec- tion process, functional data analysis
1.
서론스마트 공장(smart factory) 또는 스마트 제조(smart manufacturing)란 디지털 정보 기술에 기초한 가상 기능을 활용하여 물리적 생산 시스템을 통합하고 향상된 융통성을 기반으로 신속한 설계 변경 및 높은 수준의 생산 능력을 유지하고자 하는 다양한 활동에 적용되는 용어이다 (Davis 등, 2012). 이는 정보 기술의 발전, 미세 공정에 필요한 측정 기술의 발전 그리고 데이터의 양, 속도, 다양성을 특징으로 하는 빅 데이터 수집, 관리, 분석 방법의 발전에 기초하여 여러 산업에서 다양한 방법으로 시도 되고 있다. 하지만 산업 기반, 공장 규모, 기업 문화 등의 사회적 요소와 고객, 공급자, 시장 규모, 제품 성장 정도 등의 시장 및 유통 관련 요소들로 인해 산업 군 또는 개별 기업마다 적용 속도와 규모가 다르게 나타날 수 있다 (Moyne와 Armacost, 2017). 이 중에 서 반도체 산업은 극한 경쟁, 한계 기술의 도래, 미세 공정 확대에 따른 다양한 생산 문제를 극복하기 위하여 스마트 제조 기술 적용 및 스마트 공장 조기 달성을 적극적으로 추진하고 있다.
반도체 분야에서 시장 우위를 달성하기 위해서는 새로운 제품의 개발과 함께 지속적인 수율 증대를 필 요로 하며 생산 환경의 가변성과 역동성을 감안할 때 지속적인 수율 학습 프로세스(yield learning process)
1Department of Applied Statistics, Gachon University, 1342 Seongnam-daero, Sujeong-gu, Seongnam-si, Gyeonggi-do 13120, Republic of Korea. E-mail: [email protected]
개선이 요구된다. 또한 지속적인 가격 변동을 극복하기 위해서는 전체 공정의 누적 수율은 최소 90% 이상이 어야 하며 이를 위하여 개별 공정의 수율은 99.9% 이상의 높은 달성도를 요구한다 (Moyne와 Iskandar, 2017).
반도체의 공정은 최초 원료 단계에서 최종 제품이 생산될 때 까지 수백 개 이상의 단위 공정으로 구성된다. 이 는 웨이퍼(wafer)의 형태의 재료에 반복적인 막 증착(deposition), 패터닝(patterning), 식각(etching) 단계 등을 거치며 대부분의 목표 패턴은 옹스트롬(10−10m) 단위의 규격 한계(specification limits)를 요구한다. 해당 공 정이 완료되면 이를 이용하여 칩(chip)을 생산하는 어셈블리(assembly), 테스트(test), 패키징(packaging) 등의 단계가 추가로 적용된다. 이러한 복잡한 공정 진행 과정에서는 다양한 종류의 장비가 적용되며 수많은 결함 기회(defect opportunities) 또는 오류 지점(failure points)이 발생할 수 있다 (May와 Spanos, 2006).
반도체 제조 공정 단계에서 적용되는 장비의 상태는 생산량과 생산 일정에 영향을 줄 수 있다. 따라서 장비 상태나 공정의 규격 이탈 및 이상 여부와 함께 장비 상태를 주기적으로 모니터링 해야 한다. 이때 장비의 센서(sensor) 데이터를 고장 감지 및 분류(fault detection & classification; FDC) 목적으로 수집한다. 장비 내 각 센서의 임의 인수(parameter; 이하 파라미터)는 status variable ID (SVID)이며 장비 내의 온도, 전압, 전류, 가스 유량 등으로 구성된다. 이와 관련된 정보는 장비 그리고/또는 공정 관리자가 장비의 상태를 진단하거나 이상 원인을 찾는데 도움을 준다 (Han과 Song, 2003).
개별 공정 실행 후 결과물에 대한 계측 검사와 관리는 생산 병목현상을 유발할 수 있으므로 공정 별로 소량의 웨이퍼만 선별하여 계측을 진행한다. 이는 공정 별 이상 상태를 올바로 진단하지 못하고 추가 공정을 진행하거나 최종 제품에서 불량 비중이 높아짐으로써 적정 수율을 유지하지 못하는 문제가 발생할 수 있다.
이러한 문제를 극복하기 위하여 장비의 센서 데이터를 활용하고 공정 상태를 간접적으로 진단하기 위한 다양 한 방법을 적용하고 있다. 예를 들어, 공정 이상을 판단하는 이상 탐지(fault detection; FD), 공정 진행 후 사후 계측 값을 예측하는 가상 계측(virtual metrology; VM), 장비 특정 구성 요소의 유지 보수 시기 예측과 유지 보수 절차를 향상을 위한 예측 장비 유지(predictive maintenance; PdM), 개별 또는 전체 공정에 대한 수율을 예측하는 수율 예측(yield prediction) 등을 들 수 있다 (Cheng 등, 2011; Chien 등, 2013; Han과 Song, 2003).
이는 공정 내의 모든 웨이퍼와 관련된 장비 센서 데이터를 수집할 수 있을 때만 적용할 수 있다.
장비 센서의 SVID는 웨이퍼가 장비에 투입(wafer in) 되는 순간부터 최종적으로 공정이 완료(wafer out) 될때 까지 모든 단계에 대하여 일정 시간 간격(예: 0.1∼1.0초 단위)으로 측정 된다. 또한 단위 공정 별 수십 분에서 수십 시간 까지 진행되기 때문에 일반적으로 장비 내 활동을 여러 단계(step)로 구분하여 수집한다.
또한 장비 내 웨이퍼에 대한 상태를 진단하고 관리하기 위하여 기술적으로 단계를 선택한다. 그 후 가용 데 이터로부터 웨이퍼 단위로 기술 통계량(예: 평균, 분산, 범위 등)을 계산하여 이상 탐지, 가상 계측, 예측 유지 보수, 수율 예측 등에 활용하고 있다. 하지만 이러한 방법은 (1) 중요 단계 선정, (2) 유용한 통계량 선택, (3) 정상/이상 판단 기준 등에서 관리자의 주관적 판단이 개입될 수 있다는 단점을 갖는다.
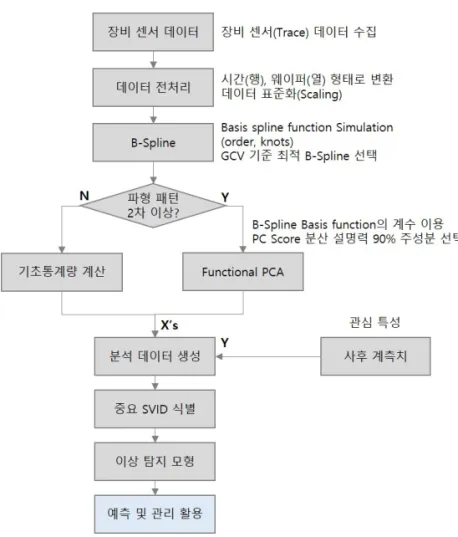
본 연구는 이러한 한계를 극복하기 위한 방법 중의 하나로 공정 내 단계별 중요 SVID를 선별하고 객관적 인 관리가 가능한 센서 데이터 기반의 이상 탐지 방법을 제시하기로 한다. 초 단위로 측정되는 센서 데이터의 차원 축소를 위하여 B-Spline과 함께 functional PCA (principal component analysis)를 적용하고 (1) 중요 변수 선택, (2) 예측 모델링, (3) 이상 탐지 기준 선정을 위해 기계 학습(machine learning) 알고리즘을 적용한다. 제 안된 방법을 비교한 결과 반도체 공정의 실측 데이터에서 기존의 방법보다 더 높고 일관적인 이상 탐지율을 보였고 객관적인 자동화가 가능한 것으로 확인되었다. 따라서 센서 데이터 기반의 스마트 제조를 적용하는 다양한 산업군에서 적용 가능할 것으로 판단된다.
제 2절에서는 반도체 분야의 공정 이상 탐지 방법의 종류와 발전 과정을 요약하고, 제 3절에서는 제시 된방법을 적용하기 위한 이상 탐지 프로세스에 대하여 소개한다. 제 4절에서는 실측 센서 데이터에 기반한 사례를 소개하고, 제 5절에서는 결론 및 향후 연구 방향에 대하여 논의한다.
A case study on the application of process abnormal detection process using big data in smart factory 101
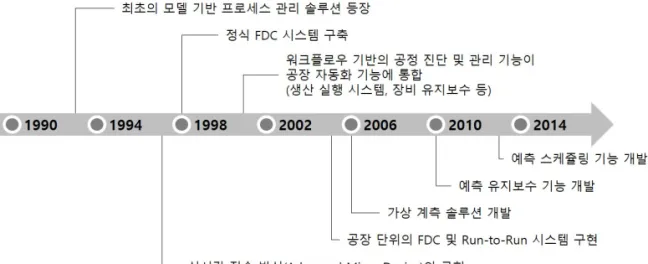
Figure 1:History of process analytics in semiconductor manufacturing.
2.
반도체 분야의 공정 이상 탐지 방법반도체 공정에서 수집 되는 전체 데이터 크기는 기술의 발전과 더불어 기하급수적으로 증가하고 있다. 공정 전반에 걸쳐 수집 되는 데이터의 크기는 1990년대를 기준으로 현재까지 10배 이상 증가하였고, 수년 내에 100∼1000배 이상 증가 할 것으로 예상된다. 주로 공정 이력, 장비 유지 보수, 계측, 생산량, 재고 관리, 제조 실행 시스템(MES), 전사적 자원 관리(ERP) 등의 데이터들이 오랜 기간 동안 저장되어 관리되고 있다. 이처럼 다양하게 수집된 데이터를 활용하고 데이터 간의 관계 및 이상치를 탐지하며 특정 이벤트를 예측하기 위해 노력하고 있다.
반도체 공정에서 장비 센서 데이터를 활용한 데이터 분석은 1990년대부터 시작되었고 2000년대 초반부 터 공정에 대한 이상 탐지(FD), 이상 탐지 및 분류(FDC), 공정 관리(run-to-run control; R2R)과 같은 advanced process control (APC) 기능이 널리 보급 되기 시작하였다. 반도체 생산 공정 분석의 발전 사항은 Figure 1과 같다 (Moyne와 Armacost, 2017).
반도체 제조에서 장비 및 공정 분석의 특징은 다음과 같다. 첫째, 공정 및 장비의 복잡성이다. 반도체 공 정의 장비는 수백 개의 구성 요소와 수 천 개의 오류 지점(failure points)이 존재한다. 특히 장비 내 구성요소 간의 교호작용(interaction)과 여러 이벤트(예: 가동 중지시간, 예방 정비 등)간의 교호작용으로 인해 세부 공 정을 간단히 정의하기 어렵다. 또한 복잡한 장비 및 공정에 대해 측정 되지 않거나 알려지지 않은(unknown) 특성들이 존재하기 때문에 기본적으로 긴 데이터 수집 기간이 필요하다. 둘째, 공정 내 프로세스 역동성이다.
프로세스 역동성은 시간이 지남에 따라 내부 프로세스 및 장비 요인으로 인한 부품 소모와 같은 내부 요인과 유지보수 이벤트 또는 생산 제품의 변경으로 인한 레시피 변경 등과 같은 외부 요인으로 구분할 수 있다. 셋째, 데이터의 품질이다. 분석의 정확도와 가용성 측면에서 데이터의 품질 문제가 지속적으로 발생한다. 데이터 처리 기술의 발달로 데이터 품질은 지속적으로 향상되고 있고 반도체 산업에서는 다른 산업들에 비해 높은 데이터 품질 수준을 유지하고 있지만 제조 과정에서 생성되는 데이터는 여전히 분석에서 맹목적으로 신뢰 할 수 없는 상황이다. 더불어 측정 센서의 위치에 따라 동종 장비에서도 서로 다른 값을 측정할 수 있고, 다 양한 장비에서 수집된 데이터를 중앙 서버로 전송하면서 네트워크 문제로 데이터가 유실될 수 있다. 따라서 데이터의 정확성, 완성도, 가용성, 데이터 저장 기간 같은 문제들을 해결하여 데이터 품질을 향상 시켜야 한다 (Romero-Torres 등, 2017). 반도체 업계에서는 Table 1과 같이 장비 센서 데이터를 이용하여 APC 기반의 데 이터 분석을 진행하고 있다. 이 중 FD, SPC, R2R Control, EHM과 같은 방법들은 오래 전부터 널리 보급되어
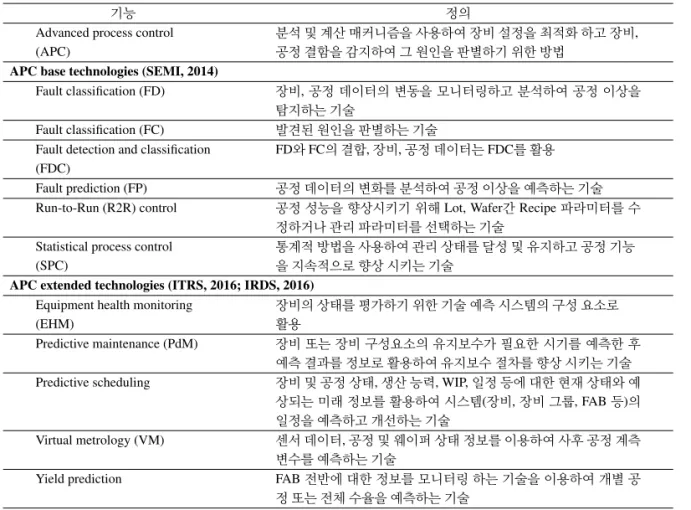
Table 1:Definitions of Advanced Process Control(APC) and APC extended capabilities
기능 정의
Advanced process control 분석 및 계산 매커니즘을 사용하여 장비 설정을 최적화 하고 장비,
(APC) 공정 결함을 감지하여 그 원인을 판별하기 위한 방법
APC base technologies (SEMI, 2014)
Fault classification (FD) 장비, 공정 데이터의 변동을 모니터링하고 분석하여 공정 이상을 탐지하는 기술
Fault classification (FC) 발견된 원인을 판별하는 기술
Fault detection and classification FD와 FC의 결합, 장비, 공정 데이터는 FDC를 활용 (FDC)
Fault prediction (FP) 공정 데이터의 변화를 분석하여 공정 이상을 예측하는 기술 Run-to-Run (R2R) control 공정 성능을 향상시키기 위해 Lot, Wafer간 Recipe 파라미터를 수
정하거나 관리 파라미터를 선택하는 기술
Statistical process control 통계적 방법을 사용하여 관리 상태를 달성 및 유지하고 공정 기능
(SPC) 을 지속적으로 향상 시키는 기술
APC extended technologies (ITRS, 2016; IRDS, 2016)
Equipment health monitoring 장비의 상태를 평가하기 위한 기술 예측 시스템의 구성 요소로
(EHM) 활용
Predictive maintenance (PdM) 장비 또는 장비 구성요소의 유지보수가 필요한 시기를 예측한 후 예측 결과를 정보로 활용하여 유지보수 절차를 향상 시키는 기술 Predictive scheduling 장비 및 공정 상태, 생산 능력, WIP, 일정 등에 대한 현재 상태와 예
상되는 미래 정보를 활용하여 시스템(장비, 장비 그룹, FAB 등)의 일정을 예측하고 개선하는 기술
Virtual metrology (VM) 센서 데이터, 공정 및 웨이퍼 상태 정보를 이용하여 사후 공정 계측 변수를 예측하는 기술
Yield prediction FAB 전반에 대한 정보를 모니터링 하는 기술을 이용하여 개별 공 정 또는 전체 수율을 예측하는 기술
활용 중이며 빅 데이터 기술의 발전과 함께 개선이 이루어지고 있다 (Moyne과 Iskandar, 2017).
최근의 공정 관리는 사후 대응적인 접근 방식에서 예측 기반의 사전 예방적인 접근 방식으로 변하고 있 다 (Moyne와 Armacost, 2017). 예를 들어 FD, PdM 등이 고장 예측으로 발전하고 있으며 가상 계측(virtual metrology; VM)과 같은 사후 계측치 예측 방법을 활용하여 계측 지연 최소화와 생산 시간 단축을 통해 공정 능력을 향상 시키고 있다 (Khan 등, 2008; Cheng 등, 2014). 또한 효과적인 장비 모니터링을 통한 제조비용 절감과 생산품질 개선 등의 연구가 진행되고 있다 (Han과 Song, 2003; Dalpiaz와 Rivola, 1997). 하지만 수율 예측과 같은 경우에는 데이터 품질 문제로 인하여 정확도가 높지 않은 상황이다 (Moyne와 Iskandar, 2017).
반도체 공정은 제품 별로 공정(process), 레시피(recipe), 장비(equipment) 요소로 구성되어 있고 복잡하고 긴 웨이퍼 공정이 순차적으로 진행된다. 장비에 설치된 센서는 FDC를 목적으로 데이터를 수집하고, 센서 데이터의 시간적 패턴은 장비 상태의 신호로 볼 수 있으며 초기 고장 감지 및 프로세스 이상에 대한 신속한 진단은 장비 효율성, 공정 운영 제어, 비용 손실 감소에 매우 중요하다 (Fan 등, 2020; Chien 등, 2013).
반도체 산업에서 활용하고 있는 센서 데이터를 활용한 이상 탐지 방법은 비지도(unsupervised) 방법이고, 단변량(univariate)이다. 공정 또는 장비의 이상 징후를 탐지하기 위해서 개별 웨이퍼에 대한 공정이 끝날 때 마다 데이터를 분석한다 (Moyne 등, 2016). 이러한 분석 방법들은 효과적이지만 (1) 프로세스의 동적 특성 및 지도(supervised) 데이터와의 상관관계 부족으로 인해 정확한 관리 한계를 정할 수 없기 때문에 miss/false alarm이 많이 발생하고, (2) 공정 모니터링을 통해 모델 또는 관리선을 재설정 하는데 많은 시간이 소요된다는
A case study on the application of process abnormal detection process using big data in smart factory 103
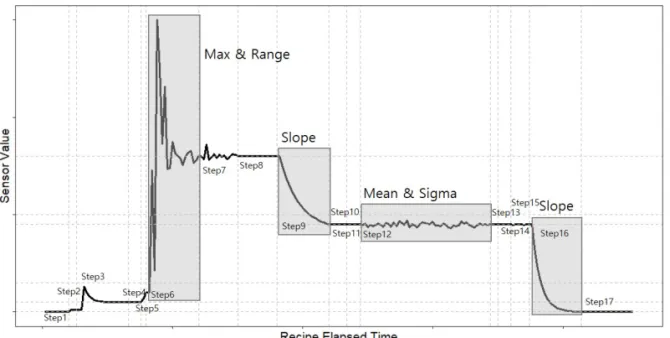
Figure 2:Process monitoring windows defined based on the trace for each sensor.
문제점이 존재 한다 (Moyne와 Iskandar, 2017).
Figure 2는 이상 탐지를 위해 장비 및 공정 관리자가 정성적으로 각 공정의 센서 데이터의 패턴을 파악하고 모델링을 수행하는 방법을 보여준다. 먼저 단계(step)로 표시된 부분은 모델링해야 할 영역과 경계를 뜻한다.
주로 장비 내부에서 웨이퍼 상태에 따라 구분하는 경우가 많다. 또한 정성적으로 특정 영역의 경계에 따라 단계 내에서도 모델링의 방법의 변경 여부 등의 의사결정이 필요하다. 예를 들면 파형의 크기와 형태에 따 라 평균(mean), 최대(max), 최소(min), 중위수(median), 범위(range), 표준편차(stdev), 기울기(slope) 등 알맞은 기술 통계량이 결정되어야 한다. 일반적으로 모델링 시 동일한 센서에 대하여 공정 반복 시뮬레이션을 통해 분석하고 장비 및 공정에 대한 전문 지식을 결합하여 결정한다 (Moyne 등, 2016). 주로 장비 센서 데이터에서 계산된 기술 통계량을 통해 웨이퍼 단위의 데이터로 변환 후 사후 계측치를 예측하거나 장비의 정비 주기 예측 등에 활용한다. 하지만 장비 이상이 감지될 경우 기술 통계량을 계산하기 이전의 정확한 파형 변화를 파악하는데 어려움이 있다.
이상 탐지에 대한 모델링 방법은 모형 기반, 지식 기반, 데이터 기반으로 구분된다. 모형 기반과 지식 기반 방법은 물리적인 공정에 대한 전문 지식과 특정 공정에 대한 입력과 출력 사이의 수학적인 기능 관계 측면에서 접근한다. 모형 기반 방법이 잘 설계된 경우 이상 탐지에 대한 높은 정확도를 달성할 수 있지만 관리하기 위한 적절한 SVID를 선정하는데 많은 시간이 소요된다는 단점이 있다. 지식 기반 방법은 전문 지식을 활용하여 공정 내 각각의 센서들 사이에 복잡한 관계를 신속하게 파악하기 어렵기 때문에 정확한 원인을 파악하지 못할 수 있다. 데이터 기반 방법으로는 과거의 공정 및 장비 상태에 대한 데이터를 활용하여 통계 분석, 데이터 마이 닝, 기계 학습과 같은 방법들을 활용한다. 대량의 장비 센서 데이터를 분석하기 위해서는 중요 변수(feature)를 추출하거나 주성분 분석(PCA), 부분 최소 제곱(PLS) 등을 이용한 다변량 관리도가 널리 사용되고 있다. 하지 만 각 센서 값은 정규 분포 가정을 따르지 않아 복잡한 제조 시스템을 사용한 이상 감지 및 공정 모니터링에는 적합하지 않다. 이에 대한 대안으로 최근에는 회귀 모형을 이용한 이상 탐지 및 진단을 사용하는 연구가 많이 진행되고 있고, 기계 학습 기반 모형이 이상 감지 및 진단에 대한 예측 모델을 학습하는데 더 적합한 것으로 나타났다 (Choqueuse 등, 2011; Gertler과 Cao, 2004; Li 등, 2010; Fan 등, 2020).
현대의 자동화된 생산 공정은 일반적으로 각 단계에서 공정에 대한 많은 변수를 측정한다. 따라서 수백 개의 중요한 변수를 모니터링 해야 하는 생산 공정에 단변량 관리도를 적용하는 경우 많은 수의 false alarm을 발생 시키기 때문에 핵심 SVID의 선정과 다변량 접근 방법이 필요하다. 효과적인 SVID 선별을 위해 대량의 복잡하고 고차원적인 데이터를 처리하도록 설계된 기계 학습 기법을 적용할 수 있다. 기계 학습 기법은 인과 관계를 파악하는 전통적인 통계적 모형에 비해 다양한 영역에서 고차원 데이터에 대해 변수 선택 및 분류 예측 모델 구축에 활용되고 있다 (Chen 등, 2017). 또한 기계 학습으로부터 계산된 변수 중요도(feature importance) 를 이용하면 공정 이상에 영향을 미치는 핵심 SVID를 선별하여 관리해야 할 SVID의 수를 현저히 줄일 수 있기 때문에 많은 시간과 노력을 절약할 수 있다.
3.
센서 데이터 기반의 이상 탐지 프로세스일반적으로 반도체 제조에서 장비 센서 데이터를 활용한 이상 탐지 프로세스는 다음과 같다. 공정의 장비 센서 데이터로부터 단계별 SVID의 기술 통계량을 계산한 후 기술적인 지식을 활용해 관리가 필요한 단계별 SVID 와 적절한 기술 통계량를 선정하고 공정을 반복적으로 모니터링하여 공정 이상과 정상의 경계를 파악한다.
이는 앞서 기술했던 것처럼 많은 시간이 소요되고 정확한 관리 한계를 정할 수 없기 때문에 miss/false alarm이 많이 발생할 수 있다. 다른 방법으로는 사후 계측 값과의 상관관계를 파악하여 유의미한 단계별 SVID와 기술 통계량을 선별하는 방법이 있다. 하지만 이 방법은 공정 내 다양한 교호작용을 반영하지 못한다는 단점이 있 다. 또한 여러 공정과 단계별 SVID의 파형 특성을 검토할 자원이 충분하지 않기 때문에 실제 공정에 적용하는 기술 통계량은 평균과 표준편차만을 이용하는 경우가 대부분이다.
이러한 문제점을 해결하기 위해 장비 센서 데이터의 시간적 형태에 대한 분석인 functional data analysis (FDA)를 적용해 파형을 새로운 값으로 요약 할 수 있다. FDA는 데이터의 연속적인 특성을 분해하고 각 데이 터들을 일종의 함수로 간주하여 분석하는 방법이다. 이를 통해 기존에 활용되고 있는 일반적인 기술 통계량 계산 방법보다 정교한 이상 탐지가 가능하다. 또 다른 장비 센서 데이터의 특징 중 하나는 급격한 증감 또는 진 동과 같은 미분 불가능한 형태의 시계열 성이다. 시간 단위의 센서 데이터들을 미분 가능한 형태로 smoothing 하여 basis function과 같은 기초적인 함수의 조합으로 나타내 분석 가능한 형태로 변환이 가능하며 예측 모 형의 설명력을 높일 수 있다. Functional data의 추세(trend)를 손실하지 않으면서 분석 가능한 형태로 만들기 위해서 B-Spline smoothing을 적용할 수 있다. 이는 basis spline function의 계수들(coefficients)을 이용하여 functional data를 표현하는 방법이다. 여기서 단계 내 구간 설정(knots) 및 함수의 최대 차수(order)에 대하여 시뮬레이션을 통해 최적의 람다(λ)값을 도출한다. B-Spline의 각 계수 추정 시 smoothing penalty를 이용하며 식은 다음과 같다.
c= arg min
n
X
i=1
(yi− x(ti))2+ λZ
[Lx(t)]2dt, (3.1)
여기서 Lx(t)는 x의 roughness를 측정하는 함수이고, λ는 smoothness의 정도를 표현하는 튜닝 파라미터이다.
B-Spline에서는 yi에 대한 적합값과 roughness의 트레이드-오프(trade-off)가 발생하게 되는데 최적의 람다를 선택하기 위한 수단으로 일반화 교차 검증(generalized cross validation; GCV)를 이용한다. 교차 검증은 가장 많은 수의 기본 함수를 정량적으로 찾는 방법이다. 이를 적용하여 장비 센서 데이터에서 나타날 수 있는 단순 증가/감소 형태부터 다항 차수로 이루어진 복잡한 함수 형태의 변동에 대해 smoothing을 적용하고 데이터에 내포된 시계열성에 대한 설명력을 높일 수 있게 된다. 각 Spline의 coefficient function에 대해 multivariate PCA 를 수행 하는데 이를 functional PCA라고 한다. PCA가 고차원 공분산을 요약하는 수단이라고 하면 functional PCA는 PCA를 무한 차원의 공분산으로 확장하는 개념이다. 각 단계별 SVID의 센서 데이터를 functional PCA 를 통하여 도출된 PC score로 변환한다 (Ramsay 등, 2009).
A case study on the application of process abnormal detection process using big data in smart factory 105
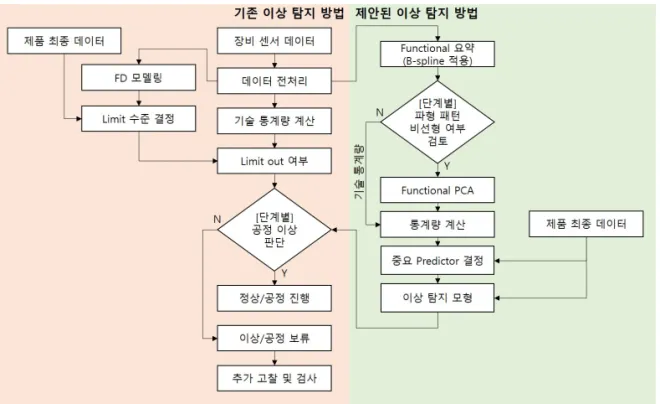
Figure 3:Comparison of anomaly detection method.
이상 탐지를 위해 공정의 결과물인 개별 공정의 사후 계측치, 최종 수율, 불량 특성 등 관심 특성을 정의 하고 functional PCA로 도출된 PC Score들을 이용해 분석 가능한 데이터 셋을 생성한다. 주요 단계별 SVID를 선별하기 위해 기계 학습 방법 중 하나인 랜덤포레스트(random forest) 알고리즘을 이용한다. 랜덤포레스트 는 분류, 회귀 모형이 적합 가능한 앙상블 학습 방법의 일종이며 훈련 과정에서 임의로 구성한 의사결정나무 (decision tree)들로 구성된 모형이다. 일반적으로 의사결정나무를 이용하는 경우 그 결과 또는 성능의 변동 폭이 크다는 단점이 있지만 이를 보완하기 위해 의사결정나무를 임의로 선택된 변수들에 적합하고 수많은 의사결정나무를 생성하여 모든 결과를 취합해 결과를 투표(voting)하는 배깅(bagging) 방법을 사용한다. 랜 덤포레스트의 장점은 의사결정나무에 비해 월등히 높은 정확성과 변수 제거 없이 수천 개의 입력 변수들을 다루는 것이 가능하다. 또한 랜덤화를 통해 좋은 일반화 성능을 보이며 간편하고 빠르게 학습이 가능하고 순열 매커니즘을 통해 분류와 회귀 문제에서 변수의 중요성을 평가할 수 있기 때문에 근본 원인 식별이 가능하다 (Breiman, 2001).
식별된 중요 단계별 SVID를 이용하여 단변량 또는 다변량 관리 방법을 적용할 수 있다. 공정 모니터링을 통해 단변량 관리 방법이 장비 내 다양한 교호작용을 반영하지 못한다고 판단되는 경우에는 기계 학습 방법을 활용한 다변량 관리 방법을 적용한다. 식별된 주요 단계 별 SVID를 이용해 관심 특성의 이상 여부를 기계 학습 예측 모형을 통해 공정 이상 여부를 예측하고 이상 감지를 할 수 있다. 사후 계측치의 경우 전체 생산량 대비 소량만 측정하기 때문에 실제로 분석 가능한 관측치는 매우 적다. 이와 같이 관측치 대비 분석 변수가 더 많은 고차원 데이터의 경우 기계 학습 방법론을 적용하기 용이하다 (Shang과 You. 2019). 따라서 사후 계측치만을 이용한 공정 이상 탐지의 경우 전체 웨이퍼에 대한 이상 여부 확인이 불가능하지만 예측 모형을 활용하면 전체 웨이퍼에 대해 관리가 가능하다. 또한 중요 단계별 SVID를 선별해 불필요한 데이터의 계산으로 인한 불합리를 사전에 방지할 수 있기 때문에 효율적으로 장비 데이터를 관리할 수 있다. 기존의 이상 탐지 방법과 본 논문에서 제안하고 있는 이상 탐지 방법에 대해 비교 하여 Figure 3과 같이 나타내었다.
Figure 4:Anomaly detection procedure.
4.
사례제안된 이상 탐지 방법을 적용하기 위해 반도체 공정 중 식각(etch)공정을 선정하여 장비 센서 데이터와 사후 계측 데이터를 수집하였고 일정 기간 동안 계측된 292장의 웨이퍼를 분석하였다. 분석 장비에서 생성되는 데 이터 중 장비 가동 시간, 데이터 수집여부, 웨이퍼 정보 등 공정 상태와 무관한 SVID를 제외한 210개의 SVID 와 공정이 진행되는 8개의 세부 단계에 대해 총 1,680개의 SVID/단계를 최종 분석 대상으로 선정하였다.
단계 별 SVID 데이터에 대한 파형 분석을 위해 표준화(centering, scaling)하여 B-Spline을 적용해 basis function의 차수(order)와 구간(knots) 설정을 시뮬레이션 하였고 각 조합의 Spline 결과로 부터 평균 GCV값을 계산하여 GCV값이 가장 작은 차수와 구간을 최적의 파라미터로 선정하였다. 이 때 knots의 수가 0이고 order 가 1 또는 2인 경우에는 0차 또는 1차 함수 형태이기 때문에 파형이 일정한 패턴을 갖는다고 할 수 있으며 파형이 0차 함수 형태인 경우 평균과 표준편차를, 1차 함수 형태의 경우 평균과 기울기를 계산하여 변환하였 다. 2차 함수 이상의 파형 패턴과 1개 이상의 knots가 존재하는 경우 B-Spline과 functional PCA로 누적 분산 설명력이 90% 이하인 PC score들을 이용해 변환하였다. 위와 같은 방법을 이용해 약 4,500개의 새로운 변수를 생성하였고 관심 특성인 사후 계측치와 결합하여 분석 데이터를 생성하였다.
다음으로 중요 단계별 SVID 식별을 위해 랜덤포레스트 알고리즘을 적용하였다. 최적의 모형을 도출하기
A case study on the application of process abnormal detection process using big data in smart factory 107
위해 하이퍼파라미터 랜덤 검색(random search)을 50회 진행하였다. 모형 평가를 위한 리샘플링(resampling) 방법은 5-겹 교차 검증(cross validation)을 이용하였으며 이상 탐지 모형의 경우 이상 데이터의 비율이 매우 작기 때문에 오버샘플링(oversampling) 방법 중 Synthetic Minority Oversampling TEchnique (SMOTE)를 방 법을 적용하였다 (Chawla 등, 2002). 마지막으로 모형에 대한 성능 지표는 이진 분류 문제에서 일반적으로 사용하는 성능 지표인 area under curve (AUC)를 이용하였다. 이진 분류 모형의 성능 지표의 경우 혼동 행 렬(confusion matrix)을 이용하여 민감도(sensitivity)와 특이도(specificity)를 계산하여 활용하지만 민감도와 특이도 간의 트레이드-오프(trade-off) 정도를 평가하기 위해 receiver operating characteristic (ROC) 곡선을 사용하고 ROC 곡선의 하단부의 넓이를 이용하여 수치적으로 분류 성능에 대해 평가한다. 이 때 두 클래스를 완벽하게 분류 한 경우 AUC 값은 1이고 완전히 잘못 분류한 경우 AUC 값은 0.5이다. 이와 같은 지표는 특히 고도로 불균형한 데이터(class imbalance)에 사용하기 좋은 지표이다 (Lujan-Moreno 등, 2018). 성능이 가장 좋은 하이퍼파라미터 조합을 이용해 최종 모형을 도출하고 변수 중요도(feature importance)를 계산하여 변수 중요도 기준 상위 20개의 단계별 SVID를 선별하였다. 데이터 수집부터 최종 모형을 도출하는 과정은 Figure 4과 같다.
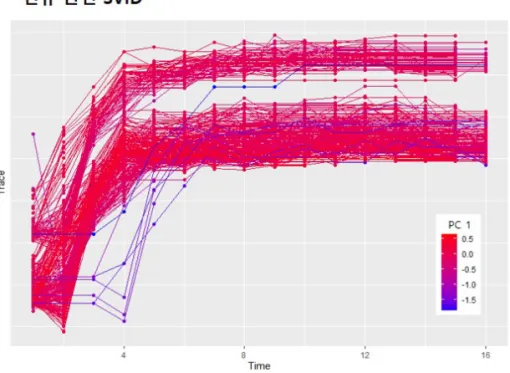
B-Spline과 functional PCA을 적용 후 식별된 핵심 SVID에 대해 시간에 따른 실제 파형과 PC Score를 Figure 5와 같이 표현하였다. 상단은 전류와 관련된 SVID이고 하단은 가스 유량과 관련된 SVID이다. 각 선은 장비 내 특정 단계에서의 웨이퍼에 대한 파형이고 PC Score를 색으로 표현하여 파형 변화에 따른 PC Score의 변화를 쉽게 파악할 수 있도록 하였다. 첫 번째 전류 관련 SVID의 경우 대부분의 웨이퍼는 공정 진행과 동시에 상승 후 수렴하는 형태이지만 특정 웨이퍼의 경우 공정 시작 후 2∼3초가 지연된 후 상승하는 형태를 보인다.
이와 같은 웨이퍼들과 공정 결과와의 연관 관계 분석을 통해 해당 단계의 SVID가 실제로 공정 이상에 영향을 미치는지 확인할 필요가 있다. 두 번째 가스 유량과 관련된 SVID는 대부분의 웨이퍼들이 공정 시작과 함께 하락 후 수렴하는 형태를 보이고 있으나 특정 웨이퍼들은 일정한 수준을 유지한 후 하락하는 형태를 보인다.
이러한 형태의 경우 일반적인 기술 통계량을 이용하여 계산하였을 때에는 위와 같은 이상 패턴을 감지하지 못하지만 functional PCA를 활용하여 PC Score를 계산하는 경우 해당 웨이퍼들에 대한 이상 감지가 가능하다.
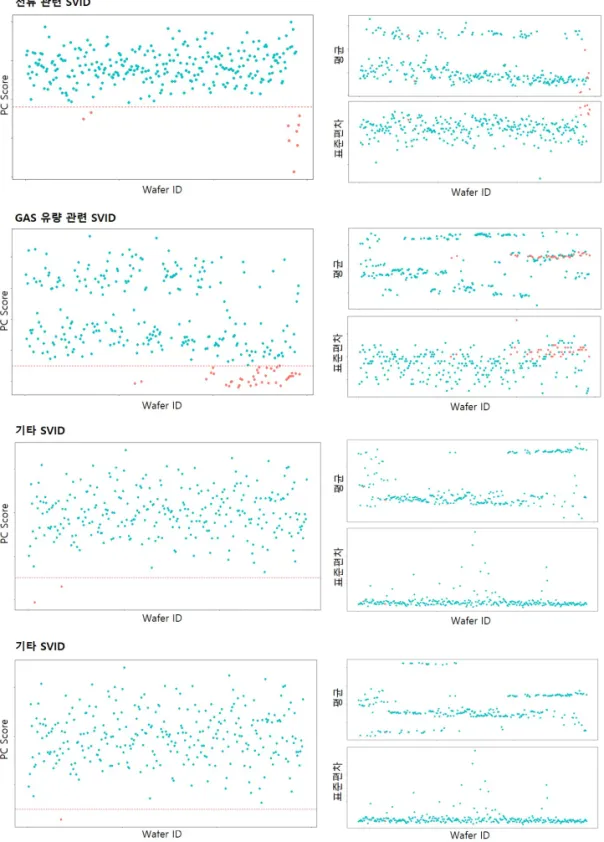
선별된 주요 단계별 SVID와 공정에 영향을 미치지 않는 단계별 SVID를 Figure 6과 같이 표현하였다. 전류 관련 SVID의 경우 실제 파형이 수 초 후에 상승하는 형태를 보이는 웨이퍼들에 대해 빨간색으로 표시하였다.
우측 그림과 같이 평균과 표준편차를 이용한 경우 이상 탐지가 불가능하지만 PC Score를 계산한 경우에는 이상 탐지가 가능했다. 가스 유량 관련 SVID도 마찬가지로 평균과 표준편차를 이용한 경우에는 이상 탐지가 불가능하지만 PC Score를 이용한 경우 이상 감지가 가능했다. 하지만 하단 그림과 같이 선별되지 않은 SVID 의 경우 PC Score, 평균, 표준편차 모두 특이한 이상 값이 감지되지 않는 것으로 나타났다. functional PCA 를 적용해 도출된 PC score를 이용하여 사후 계측치와 같은 제품의 결과 변수와 일정한 관계가 도출된다면 단변량(univariate) 관리도를 이용하여 이상 감지에 활용할 수 있다.
이처럼 PC Score를 이용한 단변량 관리도 가능하지만 선별된 중요 단계별 SVID들 이용하여 다변량 관리 도 가능하다. 다변량 관리는 일반적으로 고차원의 데이터를 모델링하여 모형의 예측값을 이용하는 방법이다.
일반적으로는 Lasso와 같은 고차원 회귀분석을 이용하지만 예측 변수들 간의 다중 공선성이 존재하는 경우 무작위로 한 개의 변수를 선택하고 나머지는 무시하는 경향이 있다. 하지만 기계 학습 모형의 경우에는 고 차원 데이터에서 예측 변수들 간의 공선성을 처리할 수 있으며 분류에서 높은 정확성을 달성할 수 있다는 장점이 있다 (Wuest 등, 2014). 식별된 핵심 SVID들에 대해 사후 계측치의 limit out 여부를 종속 변수로 하여 5 개의 분류(classification) 모형을 적용하였다. 분류 모형은 support vector machine (SVM), random forest, C5.0, eXtreme gradient boosting (XGBoost), flexible discriminant analysis (FDA)로 선정하였다. 이와 같은 모형들은 트리 기반의 모형이거나 도출된 모형에 대해 해석이 가능하다는 특성이 있다 (Kuhn과 Johnson, 2013).
SVM은 두 집단 간 가장 먼 거리에 위치하는 초평면(hyperplane)을 찾는 방법이다. SVM의 초기 단계에
Figure 5:Example of functional PCA results.
서는 선형 분류만 지원되었지만 데이터가 선형 구분이 되지 않는 문제를 해결하기 위해 데이터를 더 높은 차원으로 대응시켜 분리를 쉽게 하는 방법이 제안되었다. 하지만 그 과정에서 계산량이 늘어날 수밖에 없었 고 이를 해결하기 위해 적절한 커널 함수를 정의한 SVM 구조를 설계하여 효과적으로 계산할 수 있게 되었다.
A case study on the application of process abnormal detection process using big data in smart factory 109
Figure 6:Comparison between PC score and descriptive statistics.
SVM에 사용되는 커널함수는 다양한 종류가 있지만 본 연구에 사용될 커널 함수는 radial basis function으로 rbf-SVM이라고 한다 (Cortes와 Vapnik, 1995). 랜덤포레스트는 분류, 회귀 모형이 적합 가능한 앙상블 학습 방법의 일종이며 훈련 과정에서 임의로 구성한 의사결정나무들로 구성된 모형이다. 일반적으로 의사결정나 무는 성능의 변동 폭이 크다는 단점이 있지만 이를 보완하기 위해 배깅(bagging)방법을 사용한다 (Breiman, 2001). C5.0은 C4.5 분류 모형에 부스팅과 각 오차 별로 각각 다른 비용을 산정하는 방식 등의 기능을 추가하 여 개선한 모형이다. C5.0은 여러 범주의 분할에 대해 충돌을 야기하지 않은 조건들을 결합하고 비용 복잡도 방식으로 하위트리를 제거하는 방법으로 최종 전역 가지치기 과정을 진행하기 때문에 더 단순한 나무(tree)를 만들 수 있다 (Quinlan, 1997). XGBoost는 gradient boosting 알고리즘을 분산된 환경에서 실행할 수 있도록 구 현한 모형으로 병렬 처리가 가능해 신속한 모형 구축이 가능하다. boosting 모형은 라운드가 지날수록 모델의 오차를 줄이는 과정으로 어떤 모델이 유효한지 또는 적절한 지를 찾아낸다. 또한 약한 예측 모형들을 결합해 강한 예측 모형을 만드는 알고리즘으로 배깅 방법과 유사하게 초기 샘플 데이터로 다수의 분류기를 만들지 만 배깅과 다르게 순차적이며 자동 가지치기 기능이 있어 과적합(overfitting)이 잘 일어나지 않는다 (Chen과 Guestrin, 2016). FDA는 총 오분류율을 최소화 하기 위해 multivariate adaptive regression splines (MARS)를 이용하여 예측 변수의 비선형 조합인 경첩 함수 세트를 만든다. 그리고 이를 판별 함수로 사용하거나 Lasso 를 사용해 변수를 선택(variable selection)하여 판별 함수를 만드는 모형이다. 기본적으로 MARS는 예측변수 공간 내의 다차원상 다각형 구역으로 분리하는 경첩 함수를 사용하는데 이를 활용하여 각 변수에 대한 해석이 가능하다는 장점이 있다 (Hastie 등, 1994).
각 모형에 대해 학습/테스트 데이터 셋의 비율은 5 : 5로 임의 추출하여 분할하였으며, 하이퍼파라미터 최 적화 방법은 랜덤 검색 50회, 5-겹 교차검증, SMOTE 오버샘플링 방법을 적용하였으며 모형 성능 지표는 AUC 를 이용하였다. 위와 같은 과정을 각 모형 당 5번을 반복하여 가장 좋은 성능을 내는 모형을 선정하였다. 5개 의 모형 중 모형 성능 지표인 AUC가 가장 높은 모형은 랜덤포레스트로 이상탐지력(sensitivity)이 85.71%이고 overkill(1 − specificity)은 5.12%로 고려된 5개의 모형 중 이상탐지력이 가장 높은 것으로 나타났다. overkill이 가장 낮은 FDA의 경우 이상탐지력이 68.57%로 상대적으로 낮았다. 이상탐지력이 가장 좋은 랜덤포레스트 는 overkill도 다른 모형들에 비해 낮은 수준이어서 최종 모형으로 선정하였다. 5개 모형에 대한 최종 결과는 Table 2와 같다.
이와 같이 다변량 분석을 통한 이상 탐지 모형을 구축하는 경우 최종 모형을 기준으로 이상 탐지 정확도는 약 85.7%, overkill은 5.12% 수준을 기대할 수 있다. 일반적인 기술 통계량을 이용한 경우와 FDA를 적용해 PC Socre를 이용한 경우의 모형 예측 정확도를 비교한 결과 기술 통계량을 이용한 경우의 이상 탐지력은 모형 별로 약 30∼40% 수준이었고, 정상을 이상으로 예측하는 overkill은 약 17∼30% 수준이었다.
제안된 방법을 활용하여 전통적인 통계적 관리 기법인 계측치를 이용한 공정 관리가 아닌 limit out 여부 를 예측하는 공정 관리가 가능하다. 장비 센서 데이터의 경우 모든 웨이퍼에 대한 데이터가 저장되기 때문에 전체 생산 웨이퍼에 대해 보다 신속하게 공정 이상을 탐지할 수 있다. 실제 사례 분석에 사용된 데이터의 경우 실제 공정을 진행한 웨이퍼의 수는 약 12,000장이지만 사후 계측치는 292장으로 약 2.4%의 계측률을 보였다.
따라서 이상 탐지 모형을 이용해 계측 되지 않은 나머지 웨이퍼에 대해 이상 탐지 모형을 이용하여 계측 소요 시간을 단축할 수 있고 공정 이상 웨이퍼들을 구분하거나 공정 이상에 생산 기간 등을 빠르게 파악할 수 있 다. 또한 이상 발생으로 인한 웨이퍼의 처리도 즉각적으로 이루어질 수 있으므로 전체적인 공정 능력 향상을 기대할 수 있다.
A case study on the application of process abnormal detection process using big data in smart factory 111
Table 2:Anomaly detection model performance comparison results
Model 하이퍼파라미터 이상탐지력
(Sensitivity)
Overkill
(1 − Specificity) AUC rbf-SVM sigma : 0.0078
C : 0.1050 0.7047 0.1427 0.7810
랜덤 포레스트
mtry : 13
ntree : 500 0.8571 0.0512 0.9030
XGBoost
nrounds : 959 max depth : 6 eta : 0.4018 gamma : 3.5424 colsample bytree : 0.6214 min child weight : 2 subsample : 0.5696
0.7238 0.0634 0.8302
FDA degree : 2
nprune : 23 0.6857 0.0488 0.8185
C5.0
trials : 12 model : 2 winnow : FALSE
0.8381 0.0720 0.8831
5.
결론 및 보언스마트 제조를 구현하기 위해 제조 공정의 장비 센서와 관련된 다양한 데이터들이 수집되고 있다. 이를 효율적 으로 분석할 수 있는 방법에 대해서 다양한 연구가 진행되고 있다. 본 연구는 스마트 공장을 구현하기 위하여 통계적 방법과 기계학습 방법을 적용하여 다양한 공정의 수많은 장비 센서로 부터 추출된 데이터를 분석할 수 있는 방안을 반도체 제조 공정 사례를 통해 제안하였다. 연구 결과 기존 반도체 생산 공정에서 사용하는 기술 통계량을 사용한 방법 보다 FDA를 적용해 센서의 파형을 새로운 값으로 요약하는 데이터 변환 방법을 사용했을 경우 공정 상태에 대한 설명력을 높일 수 있는 것으로 나타났다. 이와 같은 방법을 활용해 수많은 계측 공정 단계들을 생략하거나 계측 수량을 줄이면서 생산성의 극대화를 기대할 수 있다.
분석사례의 경우 단일 공정에 대한 사후 계측치에 대한 이상 탐지 모형으로 rbf-SVM, 랜덤포레스트, XGBoost, FDA, C5.0을 적용하였다. 이상탐지력은 모형에 따라 대체로 70∼80% 수준이었다. 그 중 가장 좋은 모형의 이상탐지력은 85.71%이고 overkill은 5.12%로 나타났다. 이상탐지력을 향상시키기 위한 방안으로 제 안된 분석 방법을 확장하여 반도체 공정 모듈 단위로 분석하는 방법을 적용할 수 있다. 반도체 공정 특성상 수백 개 이상의 공정이 진행되기 때문에 공정 간 교호작용으로 인해 불량이 발생하거나 공정에 이상이 생길 수 있기 때문이다. 이와 같은 방법을 적용할 경우 더 높은 이상탐지력을 기대할 수 있을 것이다. 또한 반도체 공정 뿐 만 아니라 장비를 활용하는 다른 산업군에서도 이와 같은 방법을 통해 공정에 대한 이상 탐지가 가능할 것으로 예상된다.
References
Breiman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over- sampling technique, Journal of Artificial Intelligence research, 16, 321–357.
Chen, Y. J., Wang, B. C., Wu, J. Z., Wu, Y. C., and Chien, C. F. (2017). Big data analytic for multivariate fault
detection and classification in semiconductor manufacturing. In 2017 13th IEEE Conference on Automation Science and Engineering (CASE)(pp. 731–736). IEEE.
Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining(pp. 785–794).
Cheng, F. T., Huang, H. C., and Kao, C. A. (2011). Developing an automatic virtual metrology system. IEEE Transactions on Automation Science and Engineering, 9, 181–188.
Cheng, F. T., Kao, C. A., Chen, C. F., and Tsai, W. H. (2014). Tutorial on applying the VM technology for TFT-LCD manufacturing. IEEE Transactions on Semiconductor Manufacturing, 28, 55–69.
Chien, C. F., Hsu, C. Y., and Chen, P. N. (2013). Semiconductor fault detection and classification for yield enhancement and manufacturing intelligence. Flexible Services and Manufacturing Journal, 25, 367–388.
Choqueuse, V., Benbouzid, M. E. H., Amirat, Y., and Turri, S. (2011). Diagnosis of three-phase electrical ma- chines using multidimensional demodulation techniques. IEEE Transactions on Industrial Electronics, 59, 2014–2023.
Cortes, C. and Vapnik, V. (1995). Support vector machine. Machine Learning, 20, 273–297.
Dalpiaz, G. and Rivola, A. (1997). Condition monitoring and diagnostics in automatic machines: comparison of vibration analysis techniques. Mechanical Systems and Signal Processing, 11, 53–73.
Davis, J., Edgar, T., Porter, J., Bernaden, J., and Sarli, M. (2012). Smart manufacturing, manufacturing intelli- gence and demand-dynamic performance. Computers & Chemical Engineering, 47, 145–156.
Fan, S. K. S., Hsu, C. Y., Tsai, D. M., He, F., and Cheng, C. C. (2020). Data-Driven Approach for Fault De- tection and Diagnostic in Semiconductor Manufacturing. IEEE Transactions on Automation Science and Engineering.
Gertler, J. and Cao, J. (2004). PCA based fault diagnosis in the presence of control and dynamics. AIChE Journal, 50, 388–402.
Han, Y. and Song, Y. H. (2003). Condition monitoring techniques for electrical equipment-a literature survey.
IEEE Transactions on Power Delivery, 18, 4–13.
Hastie, T., Tibshirani, R., and Buja, A. (1994). Flexible discriminant analysis by optimal scoring. Journal of the American Statistical Association, 89, 1255–1270.
International Roadmap for Devices and Systems (IRDS): Factory Integration White Paper, 2016 Edition.Avail- able online: http://irds.ieee.org/images/files/pdf/2016 FI.pdf (accessed on 1 June 2017).
International Technology Roadmap for Semiconductors (ITRS): Factory Integration Chapter, 2016 Edition.Avail- able online: www.itrs2.net (accessed on 1 June 2017).
Khan, A. A., Moyne, J. R., and Tilbury, D. M. (2008). Virtual metrology and feedback control for semiconductor manufacturing processes using recursive partial least squares. Journal of Process Control, 18, 961–974.
Li, G., Qin, S. J., and Zhou, D. (2010). Geometric properties of partial least squares for process monitoring.
Automatica, 46, 204–210.
Lujan-Moreno, G. A., Howard, P. R., Rojas, O. G., and Montgomery, D. C. (2018). Design of experiments and response surface methodology to tune machine learning hyperparameters, with a random forest case-study, Expert Systems with Applications
, 109, 195–205.
May, G. S., and Spanos, C. J. (2006). Fundamentals of Semiconductor Manufacturing and Process Control. John
A case study on the application of process abnormal detection process using big data in smart factory 113
Wiley & Sons.
Moyne, J. and Armacost, M. (2017, March). Big Data Analytics Applied to Semiconductor Manufacturing. In 2017 Spring Meeting and 13th Global Congress on Process Safety. AIChE.
Moyne, J. and Iskandar, J. (2017). Big data analytics for smart manufacturing: Case studies in semiconductor manufacturing. Processes, 5, 39.
Moyne, J., Schulze, B., Iskandar, J., and Armacost, M. (2016, May). Next generation advanced process control:
Leveraging big data and prediction. In 2016 27th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC) (pp. 191–196). IEEE.
Quinlan, J. R. (1997). C5.0. http://www.rulequest.com/see5-info.html.
Ramsay, J. O., Hooker, G., and Graves, S. (2009). Functional data analysis with R and MATLAB: Springer Science & Business Media.
Romero-Torres, S., Moyne, J., and Kidambi, M. (2017). Towards Pharma 4.0; Leveraging Lessons and Innovation from Silicon Valley. American Pharmaceutical Review, 5.
SEMI, S. (2014). E133-1014-SEMI Standard Specification for Automated Process Control Systems Interface.
Milpitas, CA,(Semiconductor Equipment and Materials.)
Shang, C. and You, F. (2019). Data analytics and machine learning for smart process manufacturing: recent advances and perspectives in the big data era, Engineering, 5, 1010–1016.
Wuest, T., Irgens, C., and Thoben, K. D. (2014). An approach to monitoring quality in manufacturing using supervised machine learning on product state data. Journal of Intelligent Manufacturing, 25, 1167–1180.
Received October 5, 2020; Revised November 4, 2020; Accepted December 3, 2020
Smart Factory Big Data를 활용한 공정 이상 탐지 프로세스 적용
사례 연구남현우1,a
a가천대학교 응용통계학과
요 약
반도체 제조 산업에서는 Big Data에 기초한 Smart Factory 도입과 적용이 가시화되면서 생산 공정의 각 단계에서 수집 가능한 다양한 센서(sensor) 데이터를 활용하여 공정 이상 탐지 및 최종 수율 예측 등에 다양한 분석 방법을 시도하고 있다. 현재 반도체 공정은 원료인 잉곳(ingot)에서 패키징(packaging) 작업 이전의 웨이 퍼(wafer) 생산까지 500 600개 이상의 세부 공정과 이와 연계된 수천 개의 계측 공정으로 구성된다. 개별 계측 공정 내의 실제 계측 비율은 대상 제품 대비 0.1%에서 최대 5%를 넘지 못하고 계측 시점별로 일정하게 유지할 수 없다. 이러한 이유로 공정 각 단계의 정상 상태를 간접적으로 판단할 수 있는 장비 센서(sensor) 데이터를 활용하여 관리 여부를 판단하고자 하는 노력이 계속되고 있다. 본 연구에서는 장비 센서 데이터 기반의 공정 이상 탐지 프로세스를 정의하고 현재 적용 되고 있는 기술 통계량 기반 진단 방법의 단점을 보완하기 위해 FDA(Functional Data Analysis)방법을 활용하였다. 실제 현장 사례 데이터에 머신러닝을 이용하여 이상 탐지 정확도 비교를 통해 효과성을 검증하였다.
주요용어: smart factory, 반도체 제조 공정, 장비 센서 데이터, 이상 탐지 프로세스, functional data analysis
(13120) 경기도 성남시 수정구 복정동 성남대로 1342, 가천대학교 응용통계학과. E-mail: [email protected]